上一篇我们介绍了 Webpack 的基本概念和基础使用,了解到它是一个静态模块打包工具,通过入口、出口、Loader 和插件四大核心概念完成构建工作。这一篇我们将深入 Webpack 的编译过程,按照「初始化→构建依赖图→代码转换→Chunk 分割→优化处理→资源输出」的完整流程,深入拆解 Webpack 的编译细节。

初始化
此阶段将完成环境准备和配置整合,为后续流程奠定基础。
1. 配置收集与合并
启动webpack的方式主要分为Node API和CLI两种方式。
1. Node.js API方式
js
const webpack = require('webpack');
let config = require('./webpack.config.js') // 配置文件
// 通过使用yargs等工具解析命令行参数
// config= mergeConfig({...config, ...{命令行参数}})
const compiler = webpack(config)2. CLI方式
在输入命令时(如webpack --mode=development),webpack-cli将开始运行,其内部处理流程为:

2. 执行webpack函数
js
// lib/webpack.js 简化版本
const webpack = (options, callback) => {
const create = () => {
if(!Array.isArray(options)) {
getValidateSchema(options) // 通过schema-utils库配置验证
}
const compiler = createCompiler(options) // 创建编译器对象 编译核心对象
return compiler
}
// 判断回调函数
if(callback) {
const compiler = create()
compiler.run((err, stats) => {
// 编译器关闭时执行回调函数
compiler.close((err2) => {
callback(err || err2, stats)
})
})
} else {
return create() // 返回编译器对象
}
}核心初始化 createCompiler函数
js
// lib/webpack.js 简化版本
const createCompiler = (rawOptions, compilerIndex) => {
// 将配置转换为标准配置
const options = getNormalizedWebpackOptions(rawOptions);
applyWebpackOptionsBaseDefaults(options);
// 创建compiler对象 它是webpack的核心控制中枢
// 它继承了Tapable库 具有强大的发布订阅能力,贯穿着Webpack整个构建过程
const compiler = new Compiler(options);
// 初始化 NodeEnvironmentPlugin
// 这个插件为 compiler 挂载了 Node.js 环境下的文件系统(fs)和输入输出系统
new NodeEnvironmentPlugin({
infrastructureLogging: options.infrastructureLogging,
}).apply(compiler);
// 遍历配置中的plugins数组,并调用每个插件的apply方法,从而挂载插件
if (Array.isArray(options.plugins)) {
for (const plugin of options.plugins) {
if (typeof plugin === "function") {
plugin.call(compiler, compiler);
} else if (plugin) {
plugin.apply(compiler);
}
}
}
// 根据归一化后的 options,调用 applyWebpackOptionsDefaults 函数。
// 这个函数非常重要,它根据 `mode`(development/production/none)等设置,
// 为所有未指定的配置项填充智能默认值。
// 例如,在生产模式下,会自动开启 TerserPlugin 进行代码压缩。
const resolvedDefaultOptions = applyWebpackOptionsDefaults(
options,
compilerIndex
);
if (resolvedDefaultOptions.platform) {
compiler.platform = resolvedDefaultOptions.platform;
}
// 这是插件生命周期中的早期钩子,表示环境已经准备就绪。
compiler.hooks.environment.call();
compiler.hooks.afterEnvironment.call();
// 根据配置决定启用哪些内置功能
new WebpackOptionsApply().process(options, compiler);
compiler.hooks.initialize.call();
return compiler;
};createCompiler函数是初始化的心脏。主要做了如下几件事情:
- 配置归一化: 调用
getNormalizedWebpackOptions将配置转换为Webpack内部标准配置 - 应用默认配置 执行
applyWebpackOptionsDefaults对配置集中管理,根据mode值的不同设置不同的默认配置,这就是为什么生产环境下会自动开启 TerserPlugin 进行代码压缩的原因 - 应用内置插件 根据配置,决定启用哪些内置功能
构建依赖图
构建依赖图是整个构建过程中的核心,依赖图是 Webpack 在打包过程中建立的一个内部图谱,它清晰地描述了项目中所有模块(文件)之间的依赖关系。底层逻辑如下:
1. 入口点开始
Webpack根据配置的entry字段的值开始
js
module.exports = {
entry: './src/index.js' // 解析的起点
}1. 解析入口文件
根据配置entry的入口路径读取入口文件内容,使用JS解析器(如acorn)将文件内容转换为AST(抽象语法树),遍历AST识别依赖声明,找到所有ImportDeclaration和CallExpression(callee.name为require)的节点。

2. 依赖解析
获取入口所有依赖声明节点后,将依赖模块路径转换为绝对路径,这个过程由enhanced-resolve包完成,遵循如下策略:
-
解析绝对路径: 如果是绝对路径,直接使用。
-
解析相对路径:
Webpack依据当前所在文件的目录为上下文与相对路径拼接,形成绝对路径 -
解析第三方路径: 当遇到类似
import _ from lodash这样的情况,Webpack会模拟Node.js的模块解析策略:- 查找
node_modules目录:从当前目录开始,向上递归查找,直到文件系统的根目录。例如在src/index.js中引入import _ from lodash,查找顺序:
-
src/node_modules/lodash
-
/project_name/node_modules/loadsh
-
.../.../node_modules/lodash
- 处理
package.json:在找到第三方库目录后,查看package.json的main或module字段,以确定入口文件。如没有package.json则尝试查找index.js等默认文件。
- 查找
-
别名: 在解析过程中,
Webpack还会检查配置中的resolve.alias。如匹配后将别名替换别名指向的路径。
js
resolve: {
alias: {
'@': path.resolve(__dirname, 'src/'), // 将 @ 映射到 src 目录的绝对路径
}
}
// 之后就可以使用:import '@/utils' 来代替 './src/utils'- 扩展名处理: 如果路径中没有文件扩展名,
Webpack会按照resolve.extensions配置的列表依次尝试添加扩展名,直到找到存在的文件。
js
resolve: {
extensions: ['.js', '.jsx', '.ts', '.tsx', '.json'] // 默认值包含这些
}
// 当遇到 `import './utils'` 时,会依次查找 `./utils.js`, `./utils.jsx`, ... 直到找到 `./utils.js` 文件。3. 文件类型识别与 Loader 匹配
确定了文件的绝对路径后,Webpack会读取文件内容。在转化为AST之前,会根据文件扩展名(.css,.scss,.png,.ts,.jsx)来判断是否需要使用Loader进行预处理转换为JS模块。
⚠️ 注意
此时Loader尚未真正执行转换工作。此阶段会根据配置的
module.rules确定文件需要哪些Loader,为后续做好准备。
4. 递归依赖收集
Webpack会依次根据入口文件的所有依赖路径,按照解析入口类似操作,Webapck会:
- 将内容转换
AST(抽象语法树) - 遍历AST,找出所有的
import、require等依赖声明 - 对找到每个依赖声明,重复步骤2(依赖解析)和步骤3(文件类型识别与 Loader 匹配) 即递归地解析路径、文件类型识别、收集依赖。 在上述过程会持续进行,直到从项目入口文件出发找到所有的模块和解析即依赖收集。形成一棵完整的
模块树即依赖图。
5. 创建模块对象
在递归收集依赖的同时会对每个解析到的模块,创建一个Module对象。此对象包含了如下信息:
id:通常为模块的绝对路径dependencies:该模块直接依赖的其他模块的路径列表request:原始的依赖路径resource:解析后的绝对路径loaders:需要应用到的Loader列表;结构类似
js
{
id: `/src/style.css`,
dependenices: ['/src/global.css'],
request: './style.css',
resource: 'src/style/css',
loaders: [
{loader: /project_name/node_modules/style-loader/dist/index,js, options: {}},
{loader: /project_name/node_modules/css-loader/dist/index,js, options: {}}
]
}6. Loader处理
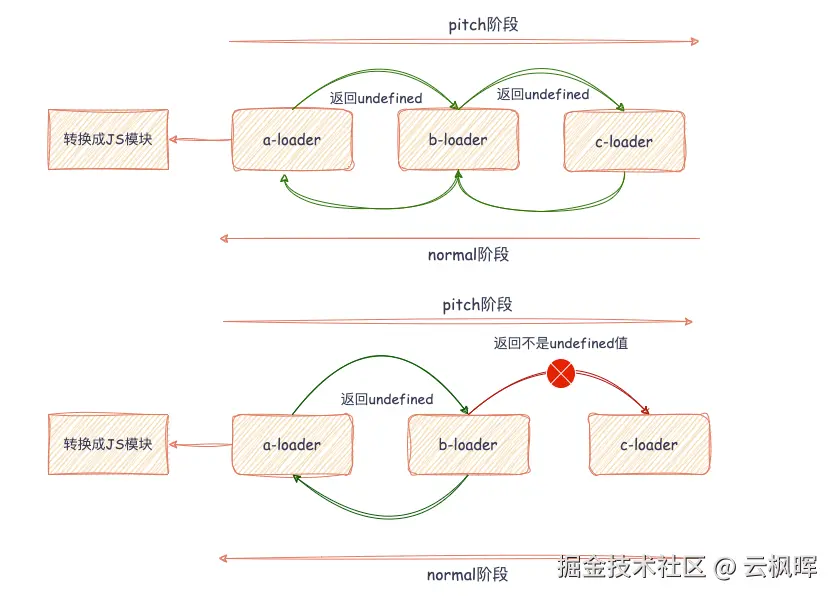
在递归收集依赖中,会创建Module对象,匹配到了需要执行的loader。它们放入到了Module对象中的loaders数组中。通过Module.loaders数组进行loader的执行。流程如下:
- 首先进入pitch 阶段,从
左到右执行。 若某个pitch返回非undefined值,则触发短路逻辑:- 跳过后续所有
loader的pitch - 跳过模块本身的读取文件内容
- 直接返回值作为
模块内容交给当前loader的Normal阶段处理。
- 跳过后续所有
- 读取模块原始内容:如果在
pitch阶段没有发生短路,Webpack将读取模块原始内容,作为后续处理的输入 - 进入Normal阶段,从右到左执行(最后一个loader最先处理,第一个loader最后处理)
- 输出转化后的JS模块代码
经过上述以递归遍历找到所有依赖,构建一个有向图数据结构的依赖图,以便后续处理。
代码转换
此阶段Webpack将一个个独立的、遵循各种规范的模块源文件,进行转换、封装成能够在一个作用域中协同工作并能在浏览器中执行的代码。
Webpack不会执行运行ES Module的import/export,而是将其替换成自身实现的模块系统。大致代码如下:
js
// 这是一个简化到极致的示例,用于说明原理
(function(modules) { // webpackBootstrap 启动函数
// 1. 模块缓存
var installedModules = {};
// 2. Webpack 自定义的 require 函数
function __webpack_require__(moduleId) {
// 检查缓存
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
// 创建新模块(并放入缓存)
var module = installedModules[moduleId] = {
i: moduleId,
l: false, // 是否已加载
exports: {} // 模块的导出对象
};
// 执行模块函数
// modules[moduleId] 就是我们下面看到的被封装后的函数
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
module.l = true; // 标记为已加载
// 返回该模块的 exports
return module.exports;
}
// 3. 加载入口模块
return __webpack_require__(__webpack_require__.s = "./src/index.js");
})({
// modules 对象:一个字典,key 是模块ID(通常是路径),value 是一个函数
"./src/index.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
// 1. 标记 __webpack_exports__ 为 ES Module
// 2. 通过 __webpack_require__ 加载依赖模块 './greet.js'
var _greet_js__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__("./src/greet.js");
// 3. 使用被导入的内容
console.log(_greet_js__WEBPACK_IMPORTED_MODULE_0__["greet"]('World'));
}),
"./src/greet.js": (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
// 1. 将 greet 函数挂载到 __webpack_exports__ 上
__webpack_exports__["greet"] = (function(name) {
return `Hello, ${name}!`;
});
})
});该阶段主要是将多种模块规范组成的依赖图中每个模块的导入/导出,重写为Webpack自定义的__webpack_require__和__webpack_exports__语句,并将每个模块包裹成一个函数。形成一个完整的、自包含的、键值对形式的 modules 对象,以及驱动这个对象的运行代码。
Chunk分割
Chunk分割阶段从"模块化"思维转向"交付"思维的关键一步,直接决定了最终生成的资源文件(Bundle)的数量和内容。
什么是Chunk?
Chunk是什么呢?理清几个概念:
- Module(模块) :你的源代码文件,无论是 ESM、CommonJS 还是 AMD,经过 Loader 转换后都成为 Webpack 内部的模块。它是构建依赖图的基本单位
- Chunk 一个或多个模块(Module)的集合。它是分割和合并的中间产物
- Bundle 最终被写入输出目录的物理文件。通常情况下,一个 Chunk 会对应一个 Bundle,但也有例外(如
devtool配置为'source-map'时,一个 Chunk 会对应一个.jsBundle 和一个.js.mapBundle)
Chunk分割处理
Chunk 分割不是随机进行的,在Chunk分割阶段主要处理入口和动态导入。
- 入口点分割: 这是基础分割方式,在
webpack.config.js中定了几个入口就有几个Chunk。 这指的是初始Chunk,后续可能通过SplitChunksPlugin进一步分割。
js
modules.exports = {
entry: {
app: './src/app.js',
user: './src/user.js'
}
}在这种情况下,Webpack 会创建两个 Chunk:
appChunk: 包含./src/app.js以及所有依赖(除非有其他的规则分割出去)userChunk:包含./src/user.js以及所有依赖
- 动态导入分割: 这是实现代码分割最常用、最有效的方式。通过 ES2020 的
import()语法或 Webpack 特定的require.ensure,可以显式地告诉 Webpack:"这里应该分割出一个新的 Chunk"。
优化处理
优化处理阶段主要根据Webpack内部的optimizationPlugins和webpack.config.js中配置的optimization的选项进行优化处理。 当所有模块都被编译、转换并组织到不同的 Chunk 中后,就进入了 优化处理 阶段。这个阶段的核心目标是:通过各种智能手段,减小最终输出文件的体积、提升应用程序在浏览器中的运行性能。
常见的优化手段:
- Tree Shaking(摇树优化):移除 JavaScript 上下文中未引用(dead code)的代码
- Scope Hoisting(提升作用域):将模块打包到一个函数作用域内,减少函数声明和闭包的数量,从而减小包体积并提升运行速度
- Code Splitting(代码分割):在Chunk分割阶段进行初步的分割,在优化阶段会进行更加智能的合并和拆分。主要依靠
Webpack的**SplitChunksPlugin**内置插件处理。 - Minification(代码压缩):通过删除空白符、注释、缩短变量名等方式,极小化 JavaScript 和 CSS 代码的体积
- Module and Chunk IDS:为模块和 Chunk 分配合适的 ID,以优化长期缓存
- Side Effects:跳过整个未使用的模块/库,实现更极致的 Tree Shaking。在
package.json中声明sideEffects:false
注意 📢
不管
webpack的mode是生产还是开发模式都会进入优化处理阶段,只是优化的策略不同:
- 开发模式:以构建速度和调试体验优先
- 生成模式:以代码体积和运行性能优先
资源处理
资源输出 发生在 Webpack 完成了所有模块的编译、转换、依赖图构建、代码分割和优化之后。此时,在内存中已经存在一个或多个准备就绪的 Chunk (代码块)。这个阶段的任务就是将这些内存中的 Chunk 转换成最终的 Asset(资源文件),并按照配置将它们写入到项目的输出目录中。
资源输出基本流程:
- 确定输出路径和文件名 Webpack 需要知道把文件写到哪里,以及叫什么名字。这由
webpack.config.js中的output配置项决定 - 模板替换和文件生成 Webpack 会根据上一步的文件名模板,结合每个 Chunk 的具体信息,进行占位符替换,最终生成确定的文件名。
例如,一个名为 main 的入口 Chunk,其内容哈希为 a1b2c3d4,那么根据 [name].[contenthash].js 模板,最终文件名就是 main.a1b2c3d4.js。 3. 文件发射 这是将内存中的 Chunk 内容真正写入到磁盘的步骤。在 Webpack 的源码中,这个动作由 compiler 对象上的 emit 钩子触发。
- 资源写入磁盘 Webpack 通过 Node.js 的
fs模块,将每个 Chunk 和 Asset 的内容(已经是字符串或 Buffer 形式)写入到指定的文件路径。
小结
Webpack 的编译过程是一个精密的工业化流水线。它从初始化 配置开始,通过构建依赖图 精准地描绘出项目的模块脉络。接着,Loader 作为"翻译官"将各类资源转换为 JavaScript,代码转换 阶段则用统一的模块系统将其封装。随后,Chunk 分割 根据入口和动态导入策略,将模块组织成利于交付的代码块,再经过优化处理 (如 Tree Shaking、压缩等)剔除冗余、提升性能。最终,在资源输出阶段,将所有处理完毕的 Chunk 转换为最终的 Bundle 文件并写入磁盘。
理解这套从"模块"到"资源"的完整转换流程,是进行高效配置优化和性能调优的基石