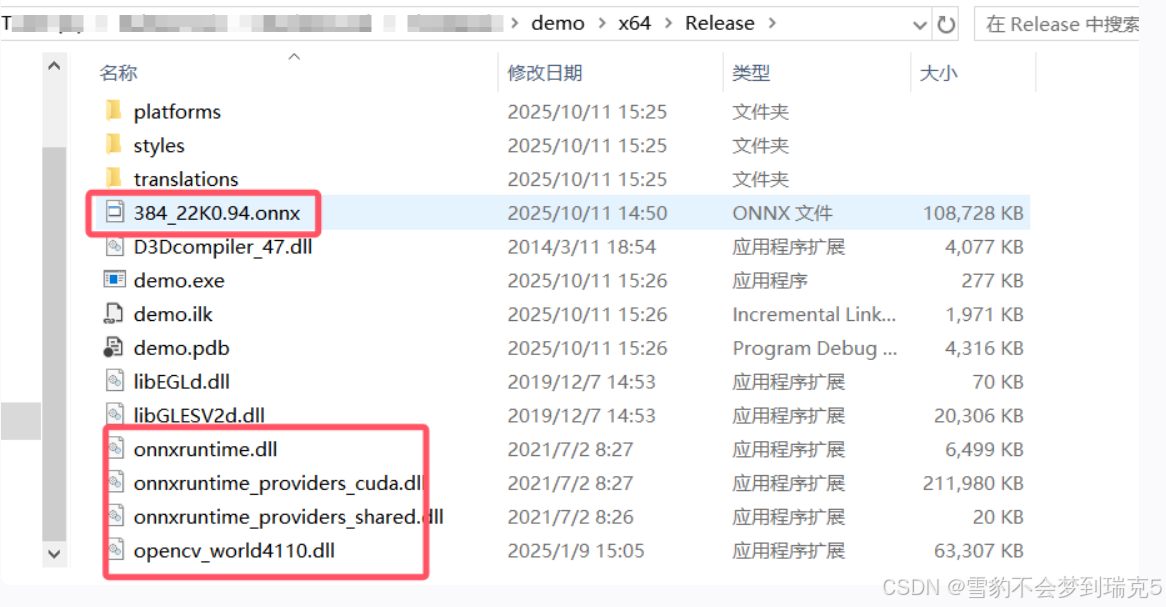
opencv 使用
下载opencv 4.11 ,选择版本下载,下载exe版本安装即可
包含目录添加E:\APP\opencv4.11\opencv\build\include\opencv2,E:\APP\opencv4.11\opencv\build\include
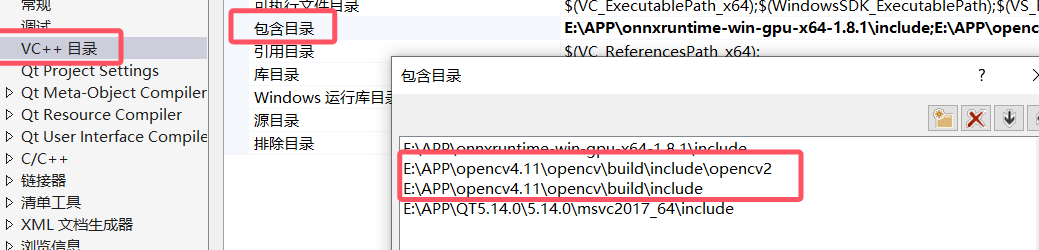
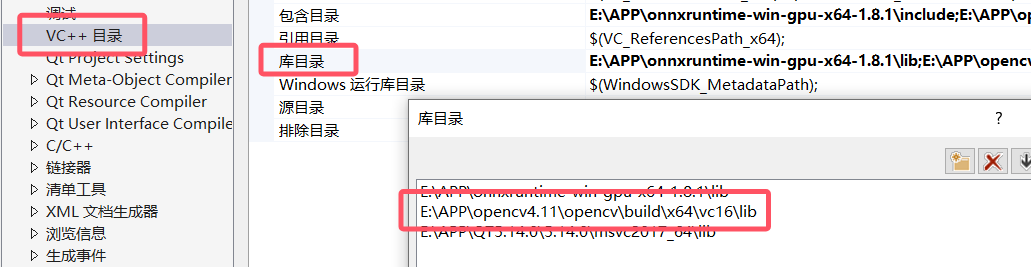
库目录添加E:\APP\opencv4.11\opencv\build\x64\vc16\lib
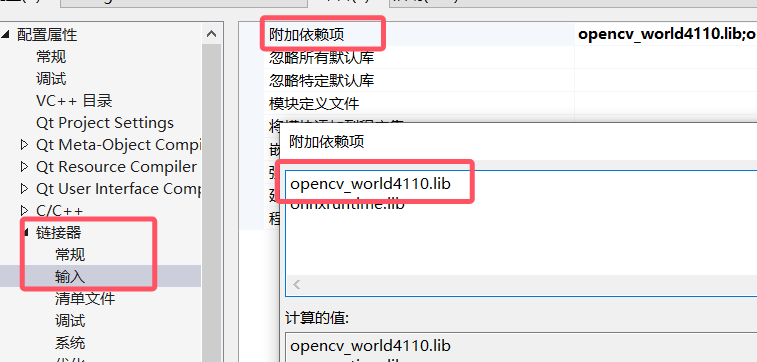
链接器-附加依赖项,输入opencv_world4110.lib(对应release版本),opencv_world4110d.lib(对应debug版本),两个只能放一个,对应版本,同时把这个.lib放到对应的debug和release文件夹下
onnxRuntime 使用
cuda11.2+ onnxRuntime1.8.1
训练好的python模型,转换为onnx,即可使用onnxRuntime运行,相比于dnn更加快速方便,兼容性更强.并且不像opencvdnn需要编译cuda版本,这个直接下载gpu版本配置就能够使用gpu.
下载和安装,打开cmd输入nvcc -V查看cuda版本根据对应的下载版本对比地址,下载地址
包含目录添加E:\APP\onnxruntime-win-gpu-x64-1.8.1\include
库目录添加E:\APP\onnxruntime-win-gpu-x64-1.8.1\lib
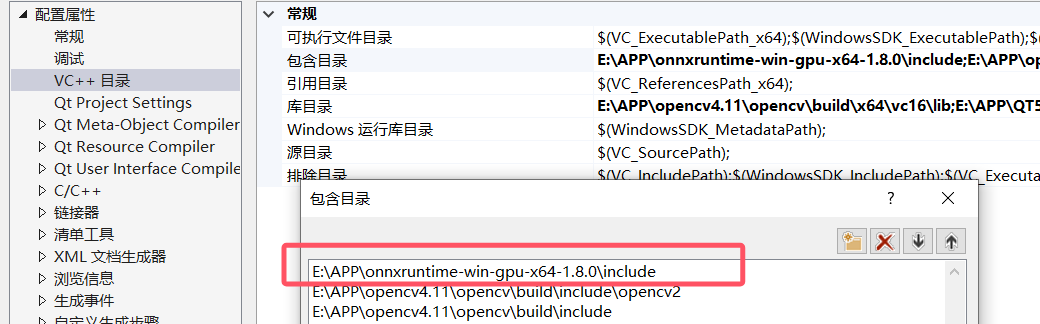
在把lib文件放入附加依赖项
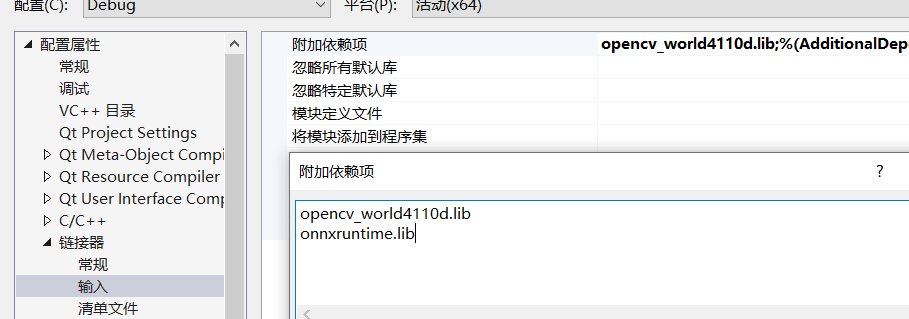
把三个.dll文件放到debug的有exe文件夹下,这样启动程序不会报错
c++
#include <onnxruntime_cxx_api.h>
#include <onnxruntime_c_api.h> // ✅ 必须包含这个头文件,声明 CUDA Provider API
#include <cuda_provider_factory.h> // ✅ 1.8 GPU 版本额外需要这个头
QString opencvManger::getClassificaitonResult(const string & imgPath)
{
//答应cuda环境
std::cout << "Available providers:\n";
auto providers = Ort::GetAvailableProviders();
for (auto &p : providers)
std::cout << " - " << p << std::endl;
// ==================== 1. 初始化 ONNX Runtime 环境 ====================
// 创建一个全局环境对象,记录日志等级和模型名称
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "ConvNext");
// 创建会话选项对象
Ort::SessionOptions session_options;
// 设置线程数,控制 CPU 并行计算
session_options.SetIntraOpNumThreads(4);
// 设置图优化等级,可以提高推理速度
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
// ==================== 2. 设置 GPU / CPU 推理设备 ====================
// 如果你在编译时定义了 USE_CUDA,则使用 GPU,否则默认 CPU
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);
// ==================== 3. 加载 ONNX 模型 ====================
// ONNX 模型文件路径
std::string model_path = "./convnext.onnx";
// 将 std::string 转为 std::wstring(Windows 文件路径需要)
std::wstring w_model_path(model_path.begin(), model_path.end());
// 使用 env 和 session_options 创建 ONNX Runtime 会话,完成模型加载
Ort::Session session(env, w_model_path.c_str(), session_options);
// ==================== 4. 获取模型输入输出信息 ====================
// 获取默认分配器,用于分配和释放字符串等资源
OrtAllocator* allocator;
Ort::GetApi().GetAllocatorWithDefaultOptions(&allocator);
// 获取模型的输入节点数量和输出节点数量
size_t num_input_nodes = session.GetInputCount();
size_t num_output_nodes = session.GetOutputCount();
// 存储输入输出节点名称
std::vector<std::string> input_node_names;
std::vector<std::string> output_node_names;
// 输入图像尺寸
int input_h = 0, input_w = 0;
// ---- 获取输入信息 ----
for (size_t i = 0; i < num_input_nodes; i++) {
// 获取输入节点名称
char* input_name = session.GetInputName(i, allocator);
input_node_names.push_back(input_name);
allocator->Free(allocator, input_name); // 释放临时分配的内存
// 获取输入节点的形状 [N, C, H, W]
auto input_shape = session.GetInputTypeInfo(i)
.GetTensorTypeAndShapeInfo()
.GetShape();
int ch = input_shape[1];
input_h = static_cast<int>(input_shape[2]);
input_w = static_cast<int>(input_shape[3]);
std::cout << "Input shape: " << ch << "x" << input_h << "x" << input_w << std::endl;
}
// ---- 获取输出信息 ----
int num = 0, nc = 0;
for (size_t i = 0; i < num_output_nodes; i++) {
// 获取输出节点名称
char* output_name = session.GetOutputName(i, allocator);
output_node_names.push_back(output_name);
allocator->Free(allocator, output_name);
// 获取输出节点的形状
auto out_shape = session.GetOutputTypeInfo(i)
.GetTensorTypeAndShapeInfo()
.GetShape();
num = static_cast<int>(out_shape[0]); // 批大小
nc = static_cast<int>(out_shape[1]); // 类别数
std::cout << "Output shape: " << num << "x" << nc << std::endl;
}
// ==================== 5. 图像预处理 ====================
// 读取图像
cv::Mat image = cv::imread(imgPath);
if (image.empty()) {
std::cerr << "❌ Failed to read image: " << imgPath << std::endl;
return -1;
}
// BGR 转 RGB
cv::Mat rgb, blob;
cv::cvtColor(image, rgb, cv::COLOR_BGR2RGB);
// 调整图像大小到模型输入尺寸
cv::resize(rgb, blob, cv::Size(input_w, input_h));
// 转为 float 并归一化到 [0,1]
blob.convertTo(blob, CV_32F, 1.0 / 255.0);
// 减均值
cv::subtract(blob, cv::Scalar(0.485, 0.456, 0.406), blob);
// 除以标准差
cv::divide(blob, cv::Scalar(0.229, 0.224, 0.225), blob);
// HWC -> CHW 并增加 batch 维度 [1,3,H,W]
cv::Mat input_blob = cv::dnn::blobFromImage(blob);
// ==================== 6. 构造输入张量 ====================
// 定义输入张量形状
std::array<int64_t, 4> input_shape = { 1, 3, input_h, input_w };
// 张量元素个数
size_t tensor_size = 3 * input_h * input_w;
// 分配 CPU 内存信息
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(
OrtArenaAllocator, OrtMemTypeDefault);
// 创建输入张量并绑定内存
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info, input_blob.ptr<float>(), tensor_size,
input_shape.data(), input_shape.size());
// ==================== 7. 推理 ====================
const char* input_names[] = { input_node_names[0].c_str() };
const char* output_names[] = { output_node_names[0].c_str() };
// 执行推理
std::vector<Ort::Value> output_tensors = session.Run(
Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names, 1);
// ==================== 8. 后处理推理结果 ====================
// 获取输出数据指针
const float* pdata = output_tensors[0].GetTensorMutableData<float>();
// 包装成 cv::Mat 方便后处理
cv::Mat logits(1, nc, CV_32F, (float*)pdata);
// softmax 计算概率
cv::Mat expScores;
cv::exp(logits, expScores);
float sumExp = static_cast<float>(cv::sum(expScores)[0]);
cv::Mat softmax = expScores / sumExp;
// 找到最大类别及其概率
cv::Point classIdPoint;
double confidence;
cv::minMaxLoc(softmax, nullptr, &confidence, nullptr, &classIdPoint);
int classId = classIdPoint.x;
// 打印预测结果
std::vector<std::string> labels = { "A", "B", "C" };
std::cout << "✅ Predicted class: " << labels[classId]
<< " (id=" << classId << ", conf=" << confidence << ")" << std::endl;
// 转为 QString 返回
QString result = QString("✅ Predicted class: %1, conf=%2")
.arg(QString::fromStdString(labels[classId]))
.arg(confidence);
return result;
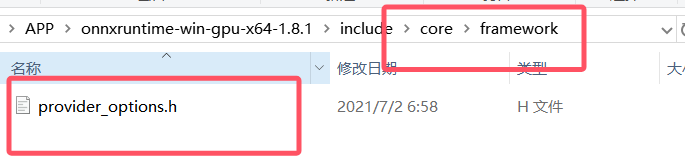
}同时需要把provider_options.h移动到core/framework文件夹,没有就创建
整体流程概览
整个推理流程分为 8 个主要步骤:
| 步骤 | 内容 | 作用 |
|---|---|---|
| 1 | 初始化 ONNX Runtime 环境 | 创建推理引擎运行环境 |
| 2 | 设置 GPU / CPU 推理设备 | 决定模型运行在 CPU 还是 GPU 上 |
| 3 | 加载 ONNX 模型 | 把 .onnx 模型文件载入内存 |
| 4 | 读取输入输出信息 | 获取模型的输入维度、输出维度等元信息 |
| 5 | 图像预处理 | 把原始图片转成模型需要的张量格式 |
| 6 | 构造输入张量 | 把预处理好的图像绑定为 ONNX 输入 |
| 7 | 执行推理 | 调用 session 运行模型前向推理 |
| 8 | 后处理结果 | softmax 计算类别概率,输出预测结果 |
🧩 详细讲解每个部分
🔹 1. 初始化 ONNX Runtime 环境
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "ConvNext");
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(4);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);Ort::Env:全局环境对象,负责管理日志、错误、资源等。SessionOptions:控制会话行为,比如多线程、优化等级等。SetIntraOpNumThreads(4):设置在 CPU 上同时运行的线程数。SetGraphOptimizationLevel(...):启用图优化,加速推理。
🔹 2. 设置 GPU / CPU 推理设备
OrtSessionOptionsAppendExecutionProvider_CUDA(session_options, 0);- 如果编译时启用了
USE_CUDA,就使用 GPU 加速; - 否则会自动回退到 CPU 模式。
注意:这句只有在你的项目链接了 CUDA 版本的 ONNX Runtime 才生效。
🔹 3. 加载 ONNX 模型
std::string model_path = "./convnext.onnx";
std::wstring w_model_path(model_path.begin(), model_path.end());
Ort::Session session(env, w_model_path.c_str(), session_options);- ONNX 模型路径从字符串转为
wstring(Windows 路径要求)。 - 用
Ort::Session创建推理会话,模型被加载进内存。
🔹 4. 获取模型输入输出信息
size_t num_input_nodes = session.GetInputCount();
size_t num_output_nodes = session.GetOutputCount();然后依次获取:
- 输入名(input_node_names)
- 输出名(output_node_names)
- 输入尺寸
[N, C, H, W] - 输出尺寸
[N, num_classes]
输出:
Input shape: 3x384x384
Output shape: 1x3🔹 5. 图像预处理
cv::Mat image = cv::imread(imgPath);
cv::cvtColor(image, rgb, cv::COLOR_BGR2RGB);
cv::resize(rgb, blob, cv::Size(input_w, input_h));
blob.convertTo(blob, CV_32F, 1.0 / 255.0);
cv::subtract(blob, cv::Scalar(0.485, 0.456, 0.406), blob);
cv::divide(blob, cv::Scalar(0.229, 0.224, 0.225), blob);
cv::Mat input_blob = cv::dnn::blobFromImage(blob);这部分作用是:
- 读取图片;
- 转为 RGB;
- resize 到模型输入大小;
- 转 float、归一化;
- 用 ImageNet 均值方差标准化;
- HWC → CHW,并加 batch 维度(变成
[1,3,H,W])。
🔹 6. 构造输入张量
std::array<int64_t, 4> input_shape = { 1, 3, input_h, input_w };
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info, input_blob.ptr<float>(), tensor_size,
input_shape.data(), input_shape.size());- 创建一个 Tensor 对象,绑定预处理后的图像数据;
- 这相当于把图像数据送入 ONNX Runtime 的输入节点。
🔹 7. 执行推理
const char* input_names[] = { input_node_names[0].c_str() };
const char* output_names[] = { output_node_names[0].c_str() };
std::vector<Ort::Value> output_tensors = session.Run(
Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names, 1);session.Run()执行一次前向推理;- 返回一个
output_tensors列表; - 其中第一个元素即模型输出。
🔹 8. 后处理推理结果
const float* pdata = output_tensors[0].GetTensorMutableData<float>();
cv::Mat logits(1, nc, CV_32F, (float*)pdata);
cv::exp(logits, expScores);
float sumExp = static_cast<float>(cv::sum(expScores)[0]);
cv::Mat softmax = expScores / sumExp;
cv::minMaxLoc(softmax, nullptr, &confidence, nullptr, &classIdPoint);- 取出输出张量数据;
- 用
cv::Mat包装; - 计算 softmax → 转为概率;
- 找出最大概率及对应类别;
- 打印或返回结果。
输出:
✅ Predicted class: B (id=1, conf=0.932)✅ 总结:执行顺序图
[开始]
↓
初始化 ONNX 环境
↓
配置 GPU/CPU
↓
加载 convnext.onnx 模型
↓
读取输入输出形状
↓
预处理图像 (resize+normalize)
↓
构建输入张量
↓
执行推理 session.Run()
↓
后处理结果 (softmax + argmax)
↓
输出预测类别与置信度
[结束]onnx模型Release版本
把onnxRuntime的三个dll复制到release文件夹,opencvword.dll,把模型复制
再导出qt库