在搭建完全分布式集群前,通常需要先在一台基础节点(可作为主节点或模板节点) 上完成基础环境配置,后续再通过克隆或批量操作同步到其他节点。以下是详细的实操步骤(以 CentOS 7 为例,其他 Linux 发行版操作类似):
一、准备工作
操作系统:确保基础节点已安装好 Linux 系统(推荐 CentOS 7/8、Ubuntu 20.04 等),并配置好静态 IP(避免 IP 动态变化影响集群通信)。
查看 IP:ip addr
配置静态 IP(CentOS 7):编辑 /etc/sysconfig/network-scripts/ifcfg-ens33(网卡名可能不同),设置:
bash
BOOTPROTO=static #(更改)
IPADDR=192.168.1.101 # 虚拟机在安装的时候选择了下图:(新增)
NETMASK=255.255.255.0 # 新增
GATEWAY=192.168.1.1 # 新增
DNS1=114.114.114.114 # 新增
ONBOOT=yes # (注意)设置完之后,保存。重启网络:systemctl restart network
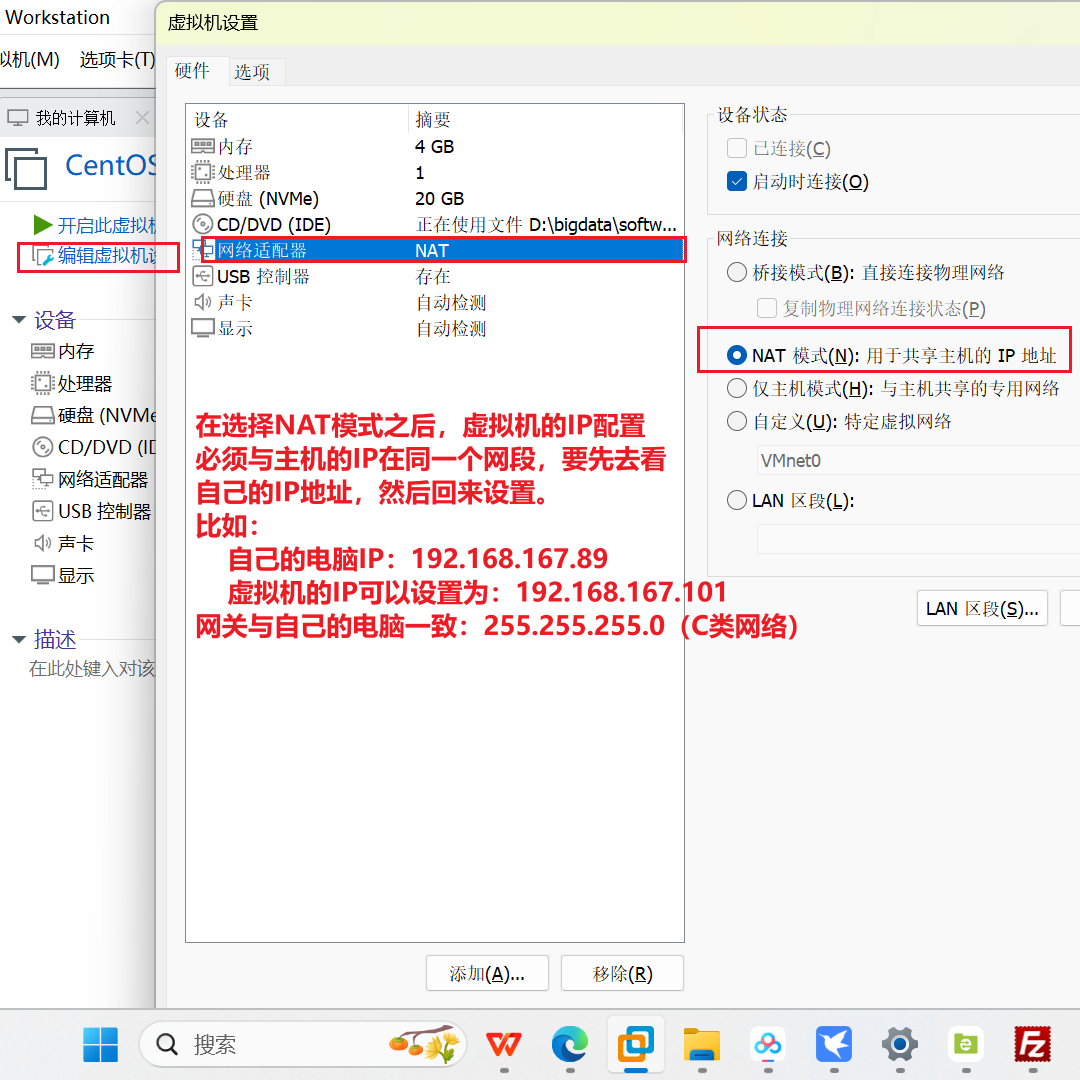
如果网络ping不通百度 那边也是因为 主机、虚拟机、网关 三点不在一个网段。
二、创建集群专用用户(非 root)
为了安全和权限管理,建议创建一个专用用户(如hadoop),并赋予 sudo 权限:
1.创建用户:
bash
useradd hadoop # 创建用户hadoop
passwd hadoop # 设置密码(输入两次确认)2.赋予 sudo 权限:
bash
visudo # 编辑sudo配置文件,找到 "root ALL=(ALL) ALL" 行,添加:
hadoop ALL=(ALL) NOPASSWD:ALL # 允许hadoop免密sudo(方便操作)
// 保存退出:按 Esc,输入 :wq 回车。三、安装 SSH 服务并配置免密登录
集群节点间需要通过 SSH 通信,需配置基础节点到自身及其他节点的免密登录。
- 安装 SSH 服务(通常系统已预装,若没有则安装):
bash
yum install -y openssh-server openssh-clients # CentOS
apt install -y openssh-server openssh-client # Ubuntu查看虚拟机是否安装SSH(服务端、客户端)
bash
# 或用 dnf(Fedora/CentOS 8+ 推荐)
dnf list installed | grep openssh-client
dnf list installed | grep openssh-server2.启动 SSH 服务并设置开机自启:
bash
systemctl start sshd
systemctl enable sshd3.生成 SSH 密钥(切换到hadoop用户操作):
bash
su - hadoop # 切换到hadoop用户
ssh-keygen -t rsa # 一路回车,不设置密码(生成id_rsa私钥和id_rsa.pub公钥)- 配置免密登录到自身(后续克隆节点后,需同步公钥到其他节点):
bash
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 将公钥添加到授权列表
chmod 600 ~/.ssh/authorized_keys # 权限必须为600,否则免密失效5.测试免密登录:
bash
ssh localhost # 首次登录需输入yes,后续无需密码
exit # 退出登录四、安装并配置 Java 环境
Hadoop 等分布式框架依赖 Java,需安装 JDK(推荐 JDK 8)。
下载 JDK(以jdk-8u361-linux-x64.tar.gz为例,需提前从 Oracle 官网或镜像站下载):待完成
上传 JDK 到hadoop用户的/home/hadoop/software目录(需先创建目录):
bash
mkdir -p /home/hadoop/software /home/hadoop/app # software放安装包,app放解压后的程序 #####假设通过 Xftp 等工具上传 JDK 到/home/hadoop/software- 解压 JDK 到app目录:
bash
cd /home/hadoop/software
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /home/hadoop/app/- 配置 Java 环境变量(切换到hadoop用户,编辑.bashrc):
bash
su - hadoop # 确保是hadoop用户
vi ~/.bashrc # 末尾添加以下内容添加:
bash
# Java Environment
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_361 # 注意路径与实际解压的一致
export PATH=$PATH:$JAVA_HOME/bin
bash
生效配置:source ~/.bashrc4.验证 Java 安装:
bash
java -version # 输出JDK版本信息即成功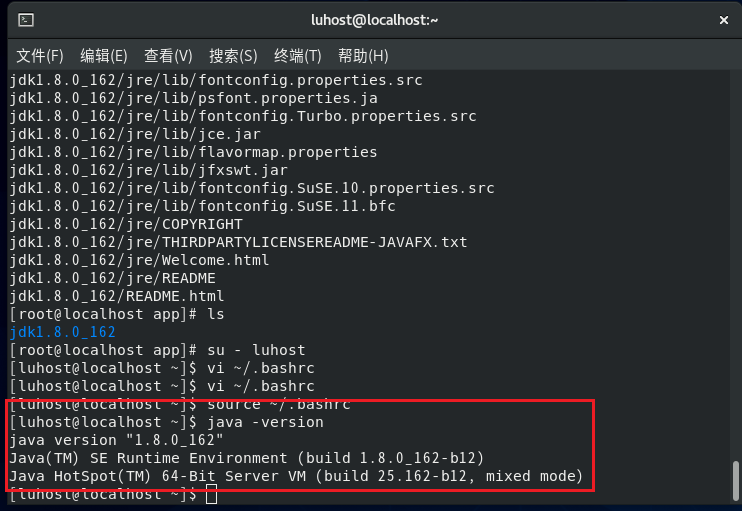
五、后续操作(为分布式集群准备)
完成以上步骤后,这台基础节点已具备基础环境,后续需:
克隆节点:通过 VMware 等工具克隆出其他节点(如从 node1 克隆 node2、node3),并修改各节点的主机名和IP(避免冲突)。
修改主机名(以 node1 为例):
克隆完虚拟机之后需要自己对node2和node3的虚拟机进行手动修改IP地址:
bash
# 找到对应的配置文件ifcfg-ens33(ensxx)
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 修改里面的IPADDR (如下👇)
# node1 -> ip addr:192.168.1.101
# node2 -> ip addr:192.168.1.102
# node3 -> ip addr:192.168.1.103 == 修改完配置文件后,必须重启网络服务才能应用新配置 ==
适用于 CentOS 7/8、RHEL 7/8 等使用 NetworkManager 的系统
bash
sudo systemctl restart NetworkManager若上述命令无效,尝试重启传统 network 服务(适用于 CentOS 6 或部分老系统)
bash
sudo systemctl restart network
bash
对node1:hostnamectl set-hostname node1 # 永久生效
对node2:hostnamectl set-hostname node2 # 永久生效
对node3:hostnamectl set-hostname node3 # 永久生效配置主机名与 IP 映射(所有节点一致):
bash
sudo vi /etc/hosts # 添加
192.168.1.100 node1
192.168.1.101 node2
192.168.1.102 node3设置完之后,在node1中可以ping通node2和node3的IP 地址。
也就是node1、 node2、node3三台主机之间是能够互ping成功的。
同步免密登录:将基础节点(node1)的公钥id_rsa.pub分发到其他节点(node2、node3)的authorized_keys中,实现跨节点免密。
同步 Java 环境:若通过克隆,Java 环境已同步;若手动安装,需在其他节点重复步骤四。
完成以上步骤后,集群的基础环境就准备好了,接下来可安装 Hadoop、Spark 等分布式框架。操作时注意保持各节点的用户、路径、环境变量一致,避免权限问题。