隧道转发传送带一共 4 个线程,分别是 tun2buffer,buffer2socket,socket2buffer,buffer2tun,占据 4 个 CPU 核心,将处理性能榨干到极限,然而还是遇到了瓶颈,tun2buffer 所在的 CPU 增至 100% 时,其它 3 个线程的 CPU 才 70~80%,原来是隧道转发的 TCP pure ACK 小包太多。
作为缓解,自然有以下规则过滤并丢弃一些 pure ACK:
bash
# TCP 头长度 + IP 头长度 = 整个包长度,确保没有数据
iptables -A FORWARD -p tcp --tcp-flags ACK ACK \
-m u32 --u32 "0>>22&0x3c@12>>26&0x3c@-3&0xff=0:0xff" \ # 然而 u32 不支持负数 :-(
-m statistic --mode nth --every 4 --packet 0 -j DROP但即使 u32 支持负数,也是治标不治本,且万一丢了最后一个 ACK,还会引发 TCP 超时。
随带宽越来愈大,越来越频的 ACK 榨干 CPU 时,不是设计更好的转发程序,也不是更换更快的处理器,而是要从根本原因入手,即 TCP pure ACK 频率的不可扩展性,所有类似的 "随规模扩大而增长的因素" 都是不可扩展的。
TCP pure ACK 频率的不可扩展性说的是,TCP 段的到达和 ACK 的发送是耦合的,因此到达越快,ACK 越频,随着带宽提高越发频繁的 pure ACK 是吞噬处理资源的元凶,它与带宽的提高形成负反馈,阻碍了 TCP 吞吐的进一步提高。
不触及 TCP 协议本身的前提下,一些转发设备会采取更加直接的方式对抗这一负反馈,比如 WiFi 的帧聚集,或者直接间隔丢掉一些 pure ACK,但千万不要并行处理 pure ACK,特别在 sender 启用 RACK 时,这只会弄巧成拙,乱序 ACK 的到达甚至比乱序 Data 段后果更严重,因为它会触发不必要的 RACK 重传,进一步加重网络和主机的负担。
在早期,为了减少 pure ACK,引入了很多措施,比如 nagle 算法,delayed ack,GRO/LRO 等,但它们也引入了很多问题,最大的问题就是复杂性,与此同时它们也并没有从根本上解决问题。
治本方案仍然得是修改 TCP 本身,让 TCP ACK 可扩展。仅列举两例:
- Big TCP,虽然数据到达越来越快,每次处理的数据量也越来越多,限制了 ACK 数量增长;
- Tame ACK (TACK),当带宽足够高,以周期 ACK 替代 2 full-sized 计数 ACK,限制 ACK 数量;
若继续深究,TCP pure ACK 的不可扩展性也只是果而不是根因。
根因在于 TCP stream 和 CPU 串行指令流之间的 match 度,当 stream 比 CPU 指令流更快时,CPU 就满了,这种情况下,要么用更快的 CPU,要么并行多个慢速 CPU 而将串行 TCP stream 拆分为多个并行 subflow,非常类似将单线程应用拆分成多线程应用,都是在解决两个串行执行绪之间的 match 度问题。
幸运的是,在可以替代互联网语境的广域网场景,受主机 CPU 限制的 TCP stream 与网络串行处理之间在 40 余年间非常默契,我此前写过一篇随笔讲这个:TCP/IP 的韧性:网络的无限扩展 & 主机的有限能力。
广域网上这 40 年的默契给了系统一个很具有扩展性的优化框架,即 5 元组 hash 式负载均衡。当某个处理核遭遇瓶颈时,可按照 stream 的 5 元组做 hash key,将不同的 stream 分发到不同的处理核,因为 stream 和处理核之间的默契,这种扩展是线性的,1000 个 stream 用 1000 个处理核,10 个 stream 只需要 10 个处理核。stream 在广域网及其成功。
但在网络硬件收发能力远超主机 CPU 处理能力的数据中心,数据直接源自硬件和非 CPU,这种默契不复存在,就势必需要拆分 stream 为并行方式,由于 RTT 范围极小(bounded),在 receiver 处乱序重组行为就是自约束的。这意味着数据中心存在传输乱序并行化的趋势,取消了 stream 后,message 就是首选,我们已经看到,诸如 SRD,Homa,falcon 等都这么做。也难怪 TCP 在数据中心总是 "被 replace",而在广域网,即使 Quic 也只是 yet another TCP,保留了 TCP 大多数的 feature 和 issue。
回到文初的问题,CPU 被小包处理压满了,由于保序约束又没法并行多 CPU 核一起处理,按照管理,应该把对小包的处理时间进一步压缩,再加一个流水线级,用 buffer 隔离开,将 1 个 CPU 干的活分到 2 个 CPU 接力干,但如果已经无法进一步压缩呢,或者说拆分流水线的工作开销抵消了收益呢,这里再次推荐 wireguard 中 "多核处理和单队列保序相分离" 的做法:
c
void process(int cpu)
{
struct entry *ent;
while (ent = get_local_head(cpu)) {
process_internal(ent); // 多核心同时处理稍微耗时的操作
unlock(ent); // 处理完 unlock,保序队列才能取走
}
}
void egress()
{
struct entry *ent;
while (ent = get_global_head()) {
lock(ent); // 若对应核心尚未处理完,lock 阻塞
output(ent); // 处理完毕,按序发出
enqueue_pool(ent); // 回归 pool
}
}
void ingress()
{
struct entry *ent;
while (ent = get_pool_head()) { // 从 pool 取出一个空闲 entry
cpu = next_cpu(cpu); // 获得一个相对空闲的处理核
get_and_fill(ent); // 填充数据
enqueue_global_queue(ent); // 同时链入保序队列
enqueue_local_queue(ent, cpu); // 同时链入不同核心的处理队列
}
}后记:iptables u32 match 对字节回退的支持
iptables u32 match 不支持字节倒退会阻碍很多很酷的事,比方说我希望从 TCP Payload 前面 3 个字节开始读一个 uint,目前就不支持。
很是不服,于是花几分钟两行代码改了它,iptables 版本 v1.8.8,下面是内核的 xt_u32.c:
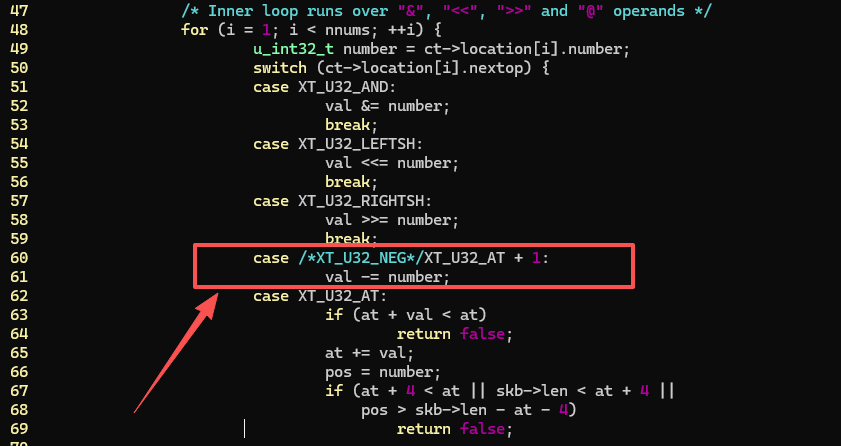
下面是 iptables 的 libxt_u32.c:
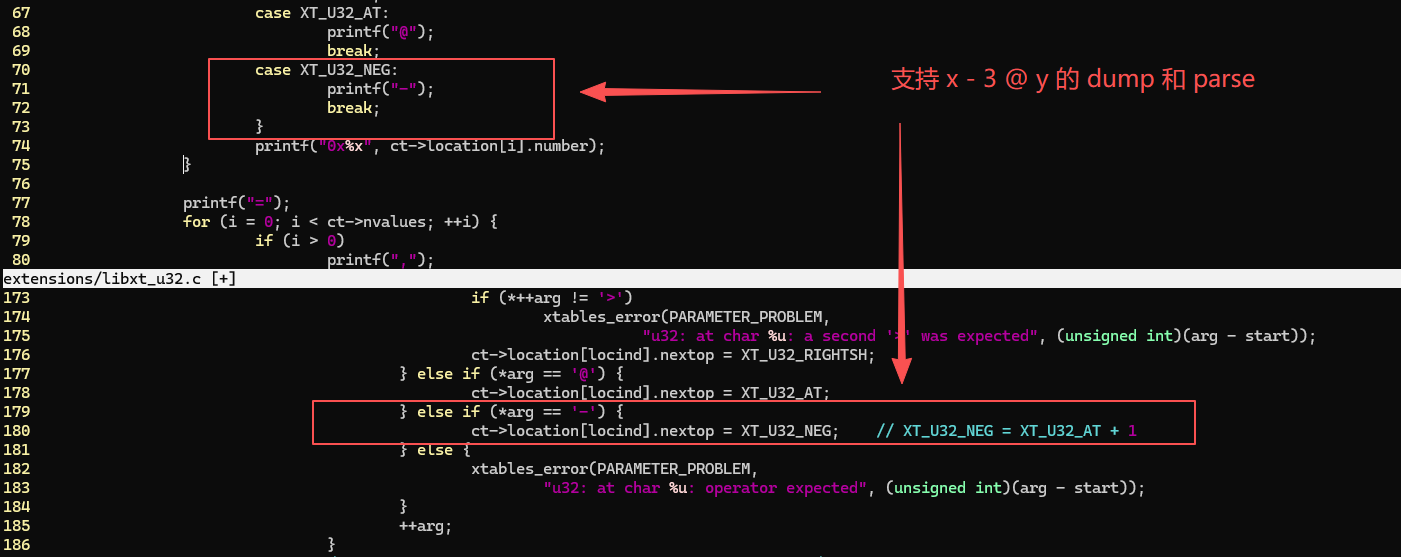
现在它可以支持下面的 match 了:
bash
# 0>>22&0x3c 跳过 IP 头,12>>26&0x3c 跳过 TCP 头,22,26 而不是 20,24 是因为 4 字节为单位,>> 合并了
# -3 表示后退 3 个字节
# 从 TCP 头末尾后退 3 字节读取一个 u32,如果没有 paylaod,最后一个字节会越界,返回 false
-m u32 --u32 "0>>22&0x3c@12>>26&0x3c-3@0&0xff=0:0xff"用它来过滤 TCP Pure ACK 简直相当方便了,小场面,大制作 。
下面是以上 match 生效的依据,来自 iptables-extensions 的 manual:

浙江温州皮鞋湿,下雨进水不会胖。