2015 CVPR
文章链接https://openaccess.thecvf.com/content_cvpr_2015/papers/Misra_Watch_and_Learn_2015_CVPR_paper.pdf
创新点
- 本文提出了一种可在视频中定位多个未知目标的半监督学习框架。该框架从少量稀疏标注的目标出发,通过迭代方式在视频中标记出新的、有用的训练样本。
- 解决了在稀疏标注视频中检测多个目标的半监督学习问题
- 提出了一种通过融合视频中的多类弱线索 ,并利用多特征空间中的数据建模来挖掘不相关误差,从而约束半监督学习过程的方法,且通过实验证明了该方法相较于传统基于检测的跟踪方法更具有效性
- 鉴于视频数据中存在冗余信息,我们需要一种能够自动判断训练样本与目标检测任务相关性的方法,为此我们提出了在半监督学习的每次迭代中纳入训练样本相关性和多样性考量的策略,最终形成了一种可扩展的增量学习算法。
问题
- 直观地说,处理视频的算法应该分别使用**外观和时间线索,前者通过检测实现,后者通过跟踪实现。**人们可能会认为,将检测与跟踪进行简单组合就能构成一个可防止偏移的半监督框架,然而,正如我们在实验中所展示的,对这两种技术进行朴素组合的效果并不理想。从长远来看,在耦合系统中,检测和跟踪各自存在的误差会被放大。
- 我们也可以考虑采用纯检测方法或纯跟踪方法来解决该问题,但纯检测方法会忽略时间信息,而纯跟踪方法在长时间序列中则容易出现偏差。
- 去除冗余信息
解决方法
- 本文提出了一种可扩展的框架,该框架利用半监督学习(SSL)实现视频中的目标检测
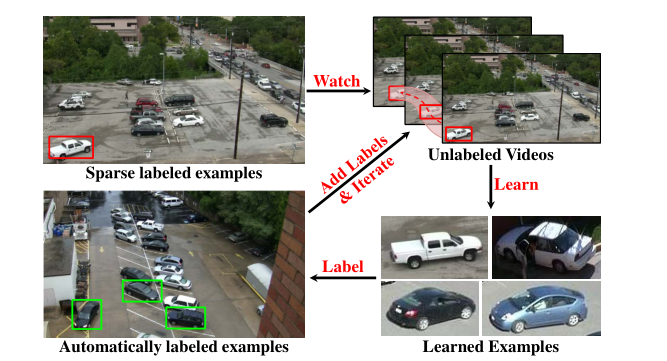
图 1:本文提出一种新颖的半监督学习框架 ,用于从视频中自动学习的目标检测器。该方法适用于长视频,能够自动生成多个目标实例的边界框级标注。其无需假设输入视频中每个目标实例都经过详尽标注,仅通过少量带标签实例,即可自动标注数十万个目标实例。
Sparse labeled examples
这是半监督学习的起点------ 仅需人工标注极少量的目标实例("稀疏标注"),无需对视频中所有目标或所有帧进行详尽标注。
Unlabeled Videos + "Watch"
多帧未标注的视频画面,其中用红色虚线框标记了目标的运动 / 出现区域。算法会 "观察" 这些未标注的长视频,利用视频的时间连续性(如目标运动、外观变化)来挖掘潜在的目标实例。
Learned Examples
算法通过学习,能够识别同一类别下的不同实例 (即使外观、车型有差异,也能归类为 "汽车" 目标),体现了对目标类别的泛化能力。
Automatically labeled examples
算法通过迭代学习,在未标注视频中自动生成大量精准的边界框标注,实现了从 "少量人工标注" 到 "大规模自动标注" 的跨越。
- 在最初为数不多的 "带标签" 帧中,并非所有目标都经过了标注 。这种场景设定放宽了 "给定帧内所有目标实例都已被详尽标注" 这一假设,意味着我们无法确定帧中未标注的区域属于目标类别还是背景 ,因此也不能将输入中的任何区域用作负样本。尽管以往的大部分研究都忽略了这类稀疏标注场景(以及缺乏显式负样本的问题),但我们提出了克服这一缺陷的方法。
- 我们不尝试解决数据关联问题 ,即框架不会去识别之前是否见过某个特定的目标实例 (传统方法会花精力做这件事------跟踪时要记住每个目标的身份,避免把同一个目标当成新目标,本文不做这件事,不管当前框出来的目标之前见没见过,都只把它当成 "一个需要标注的新实例",由于稀疏标注,这样可以避免前面某帧漏标了目标,就没法关联后续帧)
- 由于算法适用于稀疏标注场景,因此**不假设可以从当前边界框周围采样负样本,**我们不需要显式的负样本或任何预训练的目标模型
- 我们将高开销的计算限制在输入帧的一个子集上(关键帧) ,从而能够扩展到百万帧规模的视频处理。(传统方法对视频里的每一帧都做高开销计算,遇到百万帧的长视频就会算力不够,本文算法只挑一部分帧做高开销计算,剩下的帧用低成本操作处理。)
框架
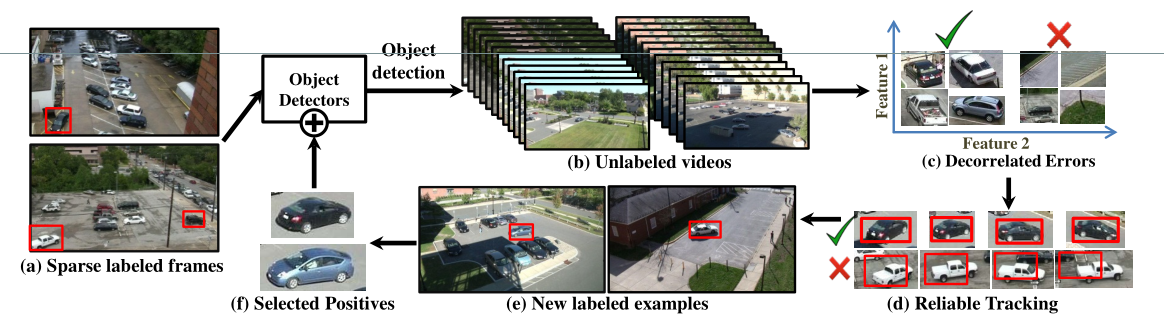
图 2:我们的方法通过精心融合检测、鲁棒跟踪、重定位以及正样本数据的多视角建模技术,以迭代方式发现新的边界框,进而完成样本选择。该图展示了如何通过这些技术之间的协同作用,从大规模未标注视频语料库中学习有效信息。
- (a):Sparse labeled frames(稀疏标注帧)
两帧视频画面,仅对少数汽车用红色边界框做了标注。 仅需人工标注极少量目标("稀疏标注"),无需对所有帧或所有目标详尽标注。 - (b):Unlabeled videos + Object detection
多帧未标注的视频画面,通过 "目标检测器" 进行检测。基于初始稀疏标注训练的检测器,对大规模未标注视频进行检测,初步识别潜在的目标实例。 - (c):Decorrelated Errors(去相关误差)
利用 "多特征空间去相关误差 " 的原理,过滤检测结果中的假阳性。
不同特征空间中,检测器的错误是 "不相关" 的 ------ 若一个区域在多个特征空间中都被识别为目标,才是可靠的真目标;若仅在某一特征空间中被识别为目标,则是假阳性 - (d):Reliable Tracking(可靠跟踪)
绿色对勾代表可靠跟踪的真目标,红色叉代表被过滤的假阳性。对 "去相关误差" 过滤后的真目标进行短期可靠跟踪,标记新的目标实例。不追求长时间跟踪,只关注 "可靠标记新样本",且能识别跟踪失败(避免将假阳性或跟踪漂移的结果纳入训练)。 - (e):New labeled examples(新标注样本)
通过可靠跟踪,在未标注视频中自动生成大量新的目标标注,实现从 "稀疏人工标注" 到 "大规模自动标注" 的扩展。 - (f):Selected Positives + Object Detectors(目标检测器更新)
从 "新标注样本" 中筛选多样、优质的正样本,用于增量更新目标检测器(无需从头重训)。避免冗余样本(视频中大量相似帧的标注无需重复训练),只选择 "新的、多样的" 样本,保证每次更新都能为检测器引入有效信息。
稀疏标注(缺乏显式负样本)
我们从U的一个随机子集中选取少量稀疏标注的帧作为起点 。与其他方法不同,稀疏标注意味着我们不假设输入帧被详尽标注,因此无法从标注正样本的附近区域采样负样本。我们使用互联网上的随机图像作为负样本 ,基于这些稀疏标签训练目标检测器 ;再用这些检测器在视频的一个子集上进行目标检测,例如每 30 帧检测一次。仅用少量正样本且无 "领域负样本" 训练的检测器,会出现如图 3 所示的高置信度假阳性。移除这类假阳性非常重要,因为如果对其进行跟踪,会引入更多劣质训练样本,导致检测器性能在迭代中不断下降。

图 3:稀疏标注的正样本(如上图所示)被用于训练示例检测器 。由于我们不假设图像中每个实例都被详尽标注,因此 无法从输入边界框周围采样负样本。当使用这些(未结合领域负样本训练的)检测器时,它们可能会学习到背景特征(例如同时出现的黄色条纹或道路分隔带 ),并产生高置信度的假阳性结果(如下图所示)。我们通过利用去相关误差来解决这一问题
我们从一个包含少量边界框的稀疏标注集 (L_0) 和未标注输入视频集 U 开始。在每次迭代 i 时,利用基于 (L_{i-1}) 训练的模型,在输入视频 U 中标记新的边界框,将其添加到标注集 (L = L \cup L_i) 中,并迭代重复这一过程。
时间一致性检测
我们首先利用检测结果运动的平滑先验,移除时间上不一致的检测结果 。
在视频中,目标的运动通常是连续且平滑的(比如汽车不会突然从画面左侧瞬移到右侧)那些运动规律不符合 "连续性、平滑性" 的检测结果是不满足时间一致性的。某帧检测到汽车在画面左下角,下一帧却突然出现在画面右上角(不符合现实中汽车的运动逻辑),这样的检测结果就是 "时间不一致" 的。
去相关误差
为移除高置信度假阳性(图 3),我们采用 "去相关误差" 原理(类似多视角半监督学习 )。其核心是:检测器的错误与其特征表示相关,不同的特征表示会导致不同的错误;因此,若不同特征空间中的错误是去相关的,就可以对其进行修正并移除假阳性 。通过这一步骤,我们得到过滤后的检测结果集合。只用 "颜色 + 车型" 这个特征空间,可能会把 "黑色的黄条纹" 误判成汽车(因为颜色和车型很像);但如果换用 "轮廓 + 运动轨迹" 这个特征空间,黄条纹的轮廓和运动(不动)就会暴露它不是汽车。
用"无约束最小二乘重要性拟合(uLSIF)" 的工具,来实现 "跨特征空间过滤"
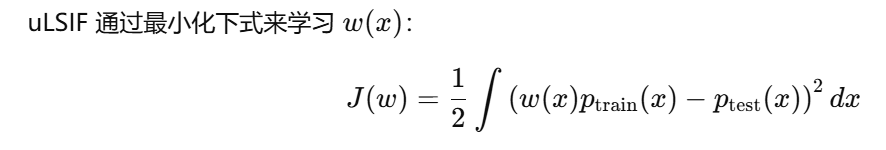
P (train):训练集的分布 = 「视频正样本(汽车)的特征规律」 + 「Flickr 负样本(风景 / 动物)的特征规律」;
P (test):测试集的分布 = 「视频场景样本(马路汽车 + 黄条纹背景的特征规律」。
可靠跟踪
我们对过滤后的检测结果进行跟踪,以标记新样本。我们的最终目标不是对目标进行长时间跟踪,而是可靠地跟踪并为目标检测器标记新的、且有望具有多样性的样本。(视频里目标容易出问题比如汽车被树挡住、行人转身,长时间跟踪很容易 "跟错"------树当成汽车)会产生 "跟踪漂移"。)为了获得这类可靠的跟踪片段,我们设计了一种保守的短期跟踪算法 来识别跟踪失败。(跟踪时发现目标轮廓变了,或者位置动得太奇怪,算法就会判定 "跟踪失败",直接放弃这个跟踪片段,不会硬着头皮继续标。)传统的基于检测的跟踪方法严重依赖检测先验来识别跟踪失败;而在我们的场景中,跟踪的目标是改进(性能较弱的)检测器本身,因此过度依赖检测器的输入会违背我们使用跟踪的初衷。
我们用颜色 / 纹理一致性:目标的颜色、纹理;目标置信度(判断一个区域 "像不像目标" 的概率,汽车的轮廓、大小是否符合目标的概率);光流(目标运动的 "流动轨迹")来确保可靠跟踪
我们重点解决两类跟踪失败模式
1.虚假运动导致的漂移 (背景运动 / 遮挡引发的错误)
这种漂移发生在对非目标区域的特征点计算光流 时(例如,运动背景或遮挡区域上的特征点)。为修正这一问题,我们先将每个跟踪框划分为四个象限,计算每个象限内的平均光流 ;**再根据每个象限内特征点与其他象限光流的一致性为其分配权重;最终跟踪框的主导运动方向,由所有特征点光流的加权平均值确定。**这一简单高效的方案能有效修正非目标特征点带来的异常运动信息。(比如树影的运动和汽车不一致,权重就低,不会被当成目标运动)
2.外观变化导致的漂移
在每帧中,我们将各类边界框 (检测边界框、跟踪边界框、目标提议边界框)作为图的节点,并连接连续帧中的节点形成网格图;边的权重由框的主导运动差异决定、空间邻近性和面积变化的线性组合构成。
主导运动差异:相邻帧节点的运动是否一致(比如第 1 帧汽车向右开,第 2 帧突然向左,运动差异大);
空间邻近性:相邻帧节点的位置是否接近(比如第 1 帧框在画面左,第 2 帧框在画面右,空间远);
面积变化:相邻帧节点的大小是否合理(比如第 1 帧汽车框很大,第 2 帧突然变小,面积突变)。
用于更新检测器的多样正样本选择
以往的工作会对视频中的边界框进行时间子采样,并将每个框视为同等重要。但由于这些框来自视频,其中大量框是冗余的,对训练检测器的重要性并不相同;此外,第i次迭代添加的样本是否相关,取决于之前的迭代是否添加过相似样本。理想情况下,我们希望仅在新的、多样的样本上进行训练(增量更新),而非在数千个高度冗余的框上从头重训。我们通过样本选择策略解决这一问题,提出了仅在多样新框上训练的方法。在基于多样本训练检测器后,我们重复半监督学习过程以迭代标记更多样本。通过贪心策略选择一组既与当前检测器不相似、彼此之间也不相似的边界框。
更正式地说,设 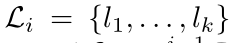 为迭代 i 时的标注框集合,
为迭代 i 时的标注框集合,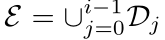 为所有先前迭代(0 至 (i-1))中与示例检测器相关联的边界框 (bn) 的集合。我们计算一个
为所有先前迭代(0 至 (i-1))中与示例检测器相关联的边界框 (bn) 的集合。我们计算一个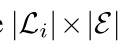 维度的检测器响应矩阵 R:矩阵元素 (R(m, n)) 表示与框 (bn) 相关联的检测器对框 (lm) 的响应值(也称为检测特征向量 )。对矩阵 R 进行行归一化处理后,框 (lm) 的检测特征向量由其对应的行向量 (R(m)) 表示。我们初始化集合
维度的检测器响应矩阵 R:矩阵元素 (R(m, n)) 表示与框 (bn) 相关联的检测器对框 (lm) 的响应值(也称为检测特征向量 )。对矩阵 R 进行行归一化处理后,框 (lm) 的检测特征向量由其对应的行向量 (R(m)) 表示。我们初始化集合 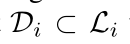 ,包含所有响应值较低的框 (lj)------ 即先前迭代的检测器均无法自信地检测这些框(ESVM 得分 < -0.8 且交并比(IOU)< 0.4)。我们通过迭代方式扩展集合 (Di),每次添加能最小化以下目标函数的检测器:
,包含所有响应值较低的框 (lj)------ 即先前迭代的检测器均无法自信地检测这些框(ESVM 得分 < -0.8 且交并比(IOU)< 0.4)。我们通过迭代方式扩展集合 (Di),每次添加能最小化以下目标函数的检测器:
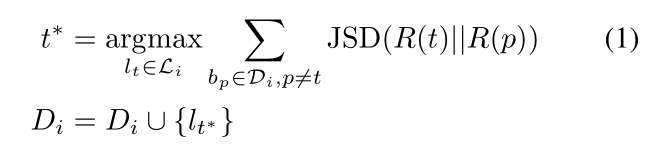 该目标函数通过计算检测特征向量的詹森 - 香农散度(JSD),优先选择与现有检测器具有多样性的边界框。每次迭代中,我们将选中的边界框数量限制为 10 个。当该选择方法无法找到新的边界框时,我们认为半监督学习已达到饱和点,以此作为算法的停止准则。
该目标函数通过计算检测特征向量的詹森 - 香农散度(JSD),优先选择与现有检测器具有多样性的边界框。每次迭代中,我们将选中的边界框数量限制为 10 个。当该选择方法无法找到新的边界框时,我们认为半监督学习已达到饱和点,以此作为算法的停止准则。
- (R(t)) :候选目标框 (lt) 的检测特征签名(由检测器响应矩阵的行向量表示,反映该框的特征模式)。
- (R(p)) :已选优质框 (lp) 的检测特征签名(同样由检测器响应矩阵的行向量表示,是 "已有知识" 的特征模式)。
实验
表 1:我们的方法与 5.1 节所述基准方法的对比。我们在所有自动标注数据上训练一个 LSVM 模型 ,并在保留的全标注测试集上计算其检测性能 (交并比(IOU)为 0.5 时的平均精度(AP))。

Boot.:基准方法 1(Bootstrap,自举法);
Boot.+Sel.:基准方法 2(Bootstrap + 样本选择);
Det+Track:基准方法 3(检测 + 跟踪);
O w/o Sel:本文方法变体(去除样本选择);
O w/o Outlier:本文方法变体(去除异常值过滤);
Ours:本文提出的完整方法。
Pascal LSVM:在 Pascal 数据集上训练的 LSVM 方法;
Pascal DPM:在 Pascal 数据集上训练的 DPM(可变形部件模型)方法;
VIRAT LSVM:在 VIRAT 数据集上训练的 LSVM 方法。

我们观察了不同迭代中用于训练 ESVM 的边界框子集。每行对应一种消融方法。第一行展示了随机选择的初始正样本边界框 (所有方法的初始框相同)。其他方法在迭代中快速偏离,这表明约束条件对于保持纯度 非常重要。 (假阳性的消融)
Ours w/o Outlier:本文方法变体(去除异常值过滤)
Ours w/o Selection:本文方法变体(去除样本选择)
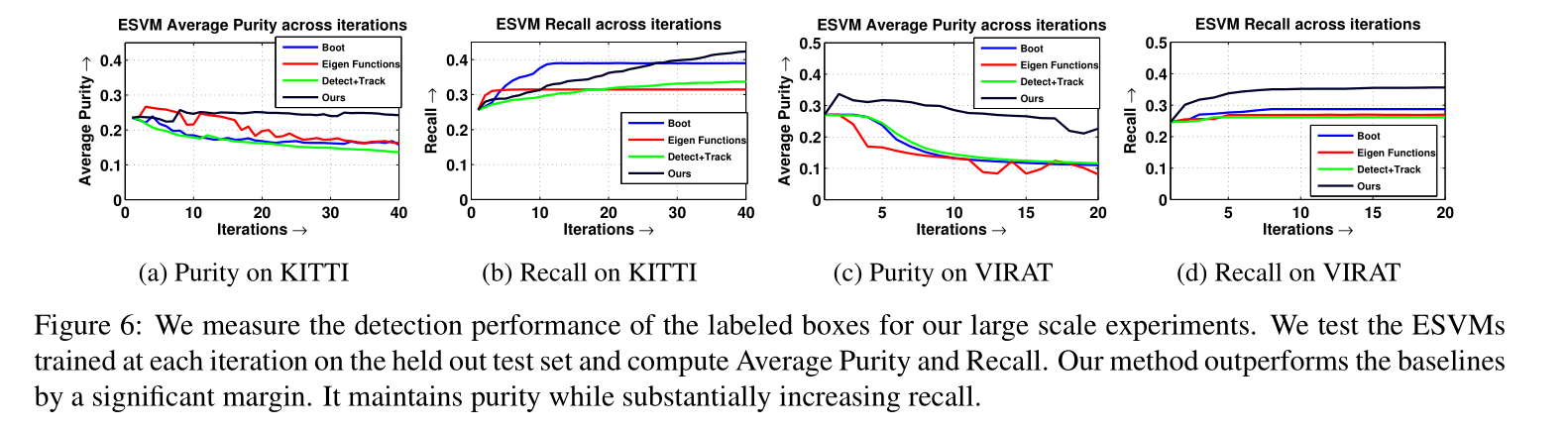
"我们在大规模实验中衡量标注框的检测性能。我们在保留的测试集上测试每次迭代训练的 ESVM 模型,计算平均纯度(Average Purity)和召回率(Recall)。我们的方法显著优于基准方法,在保持纯度的同时大幅提升召回率。"
Average Purity(平均纯度):衡量标注框的 "准确性"------ 有多少标注框是真目标(不是假阳性);
Recall(召回率):衡量检测的 "全面性"------ 有多少真实目标被检测到。

"KITTI 数据集自动标注中的姿态变化。对于每种算法,我们绘制其在 30 次迭代后标注的所有边界框的 3D 姿态分布 。第一张和最后一张图分别展示初始标注框和真实标注(Ground Truth)的姿态分布。我们方法标注的边界框分布与真实分布接近。
(a) Initial boxes(初始标注框)
初始稀疏标注的框姿态非常有限(仅覆盖少数几个角度),说明初始标注的目标视角很单一。
(b) Bootstrapping(自举法)
标注框的姿态分布极其狭窄,仅集中在极少数角度,说明该方法标注的目标视角多样性差,容易 "偏向性学习"。
© Eigen Functions(特征函数法)
姿态分布虽有扩展,但仍远未覆盖真实场景的多样视角,存在明显的分布偏差。
(d) Detect+Track(检测 + 跟踪)
姿态分布的多样性有所提升,但与真实分布相比,仍缺乏对部分关键视角的覆盖(比如极端角度的目标)。
(e) Ours(本文方法)
姿态分布广泛且均匀,几乎覆盖了真实场景中目标的各类视角,与最后一张 "Ground Truth" 的分布高度相似。

我们观察了 KITTI 和 VIRAT 两个数据集上,各基准方法在不同迭代中选择的正样本。我们注意到,随着迭代进行,标注集的纯度显著下降。这表明,需要针对视频的特定约束条件,才能在迭代中实现有意义的学习。