【开发AI】Windows安装和使用Milvus的保姆级教程
-
- 引言
- 一、Milvus简介
- [二、Docker Desktop安装与配置](#二、Docker Desktop安装与配置)
- [三、Milvus standalone模式部署](#三、Milvus standalone模式部署)
-
- [1. 获取Milvus部署脚本](#1. 获取Milvus部署脚本)
- [2. 启动Milvus服务](#2. 启动Milvus服务)
- [3. 常用Milvus脚本命令](#3. 常用Milvus脚本命令)
-
- [1. `restart` 命令](#1.
restart命令) - [2. `start` 命令](#2.
start命令) - [3. `stop` 命令](#3.
stop命令) - [4. `delete` 命令](#4.
delete命令)
- [1. `restart` 命令](#1.
- 四、安装Attu可视化管理工具
-
- [1. 下载Attu安装包](#1. 下载Attu安装包)
- [2. 连接Milvus服务](#2. 连接Milvus服务)
- 五、Python客户端连接测试(可忽略)
-
- [1. 安装pymilvus库](#1. 安装pymilvus库)
- [2. 简单向量操作示例](#2. 简单向量操作示例)
- 六、常见问题解决
-
- [1. Docker启动失败](#1. Docker启动失败)
- [2. Milvus启动后容器状态异常](#2. Milvus启动后容器状态异常)
- [3. Attu连接超时](#3. Attu连接超时)
- 七、总结与后续学习
引言
向量数据库是一种将数据存储为高维向量的数据库,是语义搜索和检索增强生成(RAG技术)的基石。目前主流的开源向量数据库有Chroma, Milvus, Faiss,Weaviate等。
高维向量是特征或属性的数学表示,每个向量都有一定数量的维度,根据数据的复杂性和粒度,可以从数十到数千不等。它通常是通过对原始数据(如文本、图像、音频、视频等)应用某种转换或嵌入函数来生成的。嵌入函数可以基于各种方法,如机器学习模型、词嵌入和特征提取算法。
向量数据库的主要优点是,它允许基于数据的向量距离或相似性进行快速和准确的相似性搜索和检索。这意味着不用使用基于精确匹配或预定义标准查询数据库的传统方法,而是可以使用向量数据库根据语义或上下文含义查找最相似或最相关的数据。
一、Milvus简介
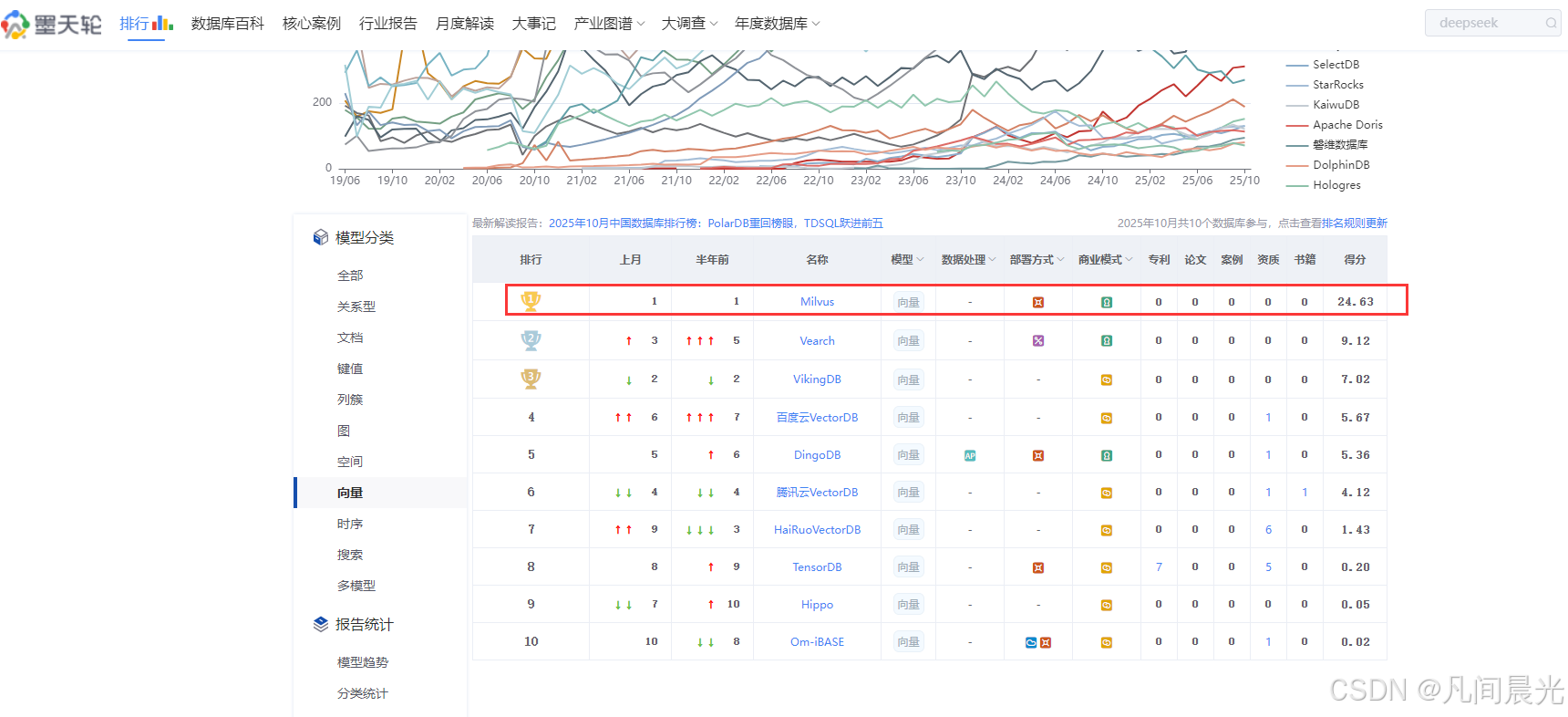
Milvus目前在墨天轮向量数据库中排名第一。作为目前最受欢迎的开源向量数据库,在相似性搜索、AI应用开发中被广泛使用。
在Windows环境下搭建Milvus需要通过Docker容器实现,因此必须先完成WSL2和Docker Desktop的配置。本文将带你避开90%的常见坑点,从环境准备到实际操作一步到位。
二、Docker Desktop安装与配置
参考Windows安装Docker到非C盘的全新教程(Windows版)

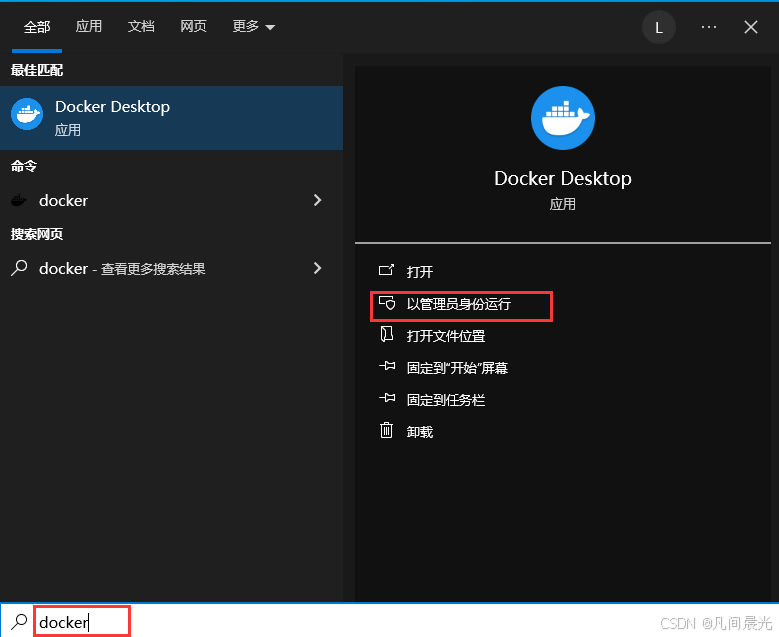
安装完成后,以管理员身份运行 Docker Desktop。
三、Milvus standalone模式部署
可以参考官方文档在各类系统中进行部署,这里以Windows为例,如果遇到网络问题,建议开启科学上网。
我使用 Docker Compose 部署 Milvus时出现了错误,就直接采用Milvus部署脚本的方式了

1. 获取Milvus部署脚本
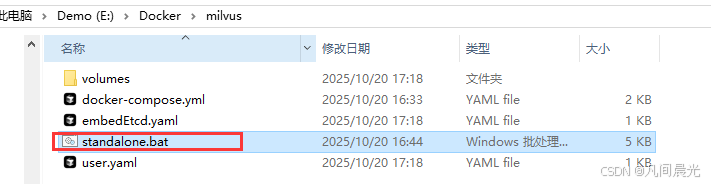
在任意位置新建文件夹(建议路径不要有中文),例如E:\Docker\milvus,在该文件夹中打开cmd,执行以下命令:
powershell
# 下载Milvus部署启动脚本
certutil -urlcache -split -f "https://raw.githubusercontent.com/milvus-io/milvus/refs/heads/master/scripts/standalone_embed.bat" standalone.bat下载后会出现一个standalone.bat脚本文件
2. 启动Milvus服务
在当前目录执行standalone.bat start命令
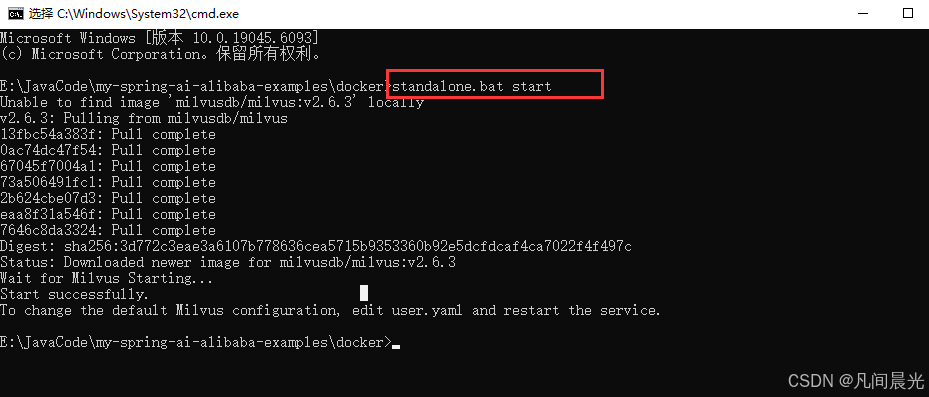
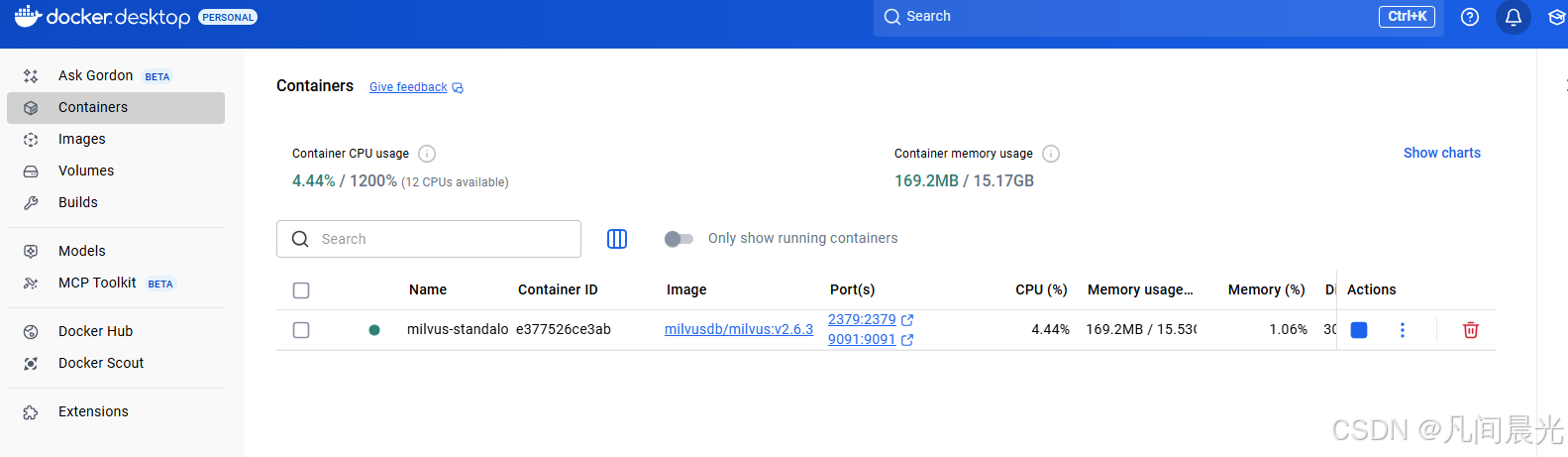
首次启动会自动拉取Milvus相关镜像并部署相关容器,根据网络情况可能需要5-10分钟。可以通过docker ps命令查看容器状态。也可以通过docker客户端直接查看:
3. 常用Milvus脚本命令
这个 standalone.bat 是一个 Windows 批处理脚本,用于管理 Milvus 向量数据库的独立模式(standalone)服务,支持以下 4 个核心命令,分别用于启动、停止、重启和删除服务:
1. restart 命令
作用 :重启 Milvus 独立模式服务(先停止再启动)。
执行流程:
- 先调用
stop命令停止运行中的 Milvus 容器; - 再调用
start命令重新启动服务。
2. start 命令
作用 :启动 Milvus 独立模式服务(若已运行则提示,若未运行则启动或创建容器)。
执行流程:
- 检查 Milvus 容器(
milvus-standalone)是否已处于"健康运行"状态,若是则直接提示"Milvus is running"; - 若容器存在但未运行,直接启动现有容器;
- 若容器不存在,执行以下操作:
- 生成
embedEtcd.yaml(配置嵌入式 Etcd,包括监听地址、存储配额等)和user.yaml(用户自定义配置); - 通过
docker run启动 Milvus 容器(镜像为milvusdb/milvus:v2.6.3),映射端口(19530 为客户端端口、9091 为健康检查端口、2379 为 Etcd 端口),并挂载本地目录(volumes/milvus存储数据,配置文件映射到容器内);
- 生成
- 等待容器进入"健康"状态,成功后提示"Start successfully"。
3. stop 命令
作用 :停止运行中的 Milvus 容器。
执行流程:
- 调用
docker stop milvus-standalone停止容器; - 若停止成功,提示"Stop successfully";若失败,提示"Stop failed"。
4. delete 命令
作用 :删除 Milvus 容器及关联数据(需手动确认,操作不可逆)。
执行流程:
- 提示用户确认(输入
y确认,n取消); - 若确认(
y):- 先检查容器是否运行,若运行则提示"请先停止服务";
- 调用
docker rm删除容器; - 删除本地数据目录
volumes/、配置文件embedEtcd.yaml和user.yaml; - 提示"Delete successfully";
- 若取消(
n),提示"Exit delete"并退出。
四、安装Attu可视化管理工具
1. 下载Attu安装包
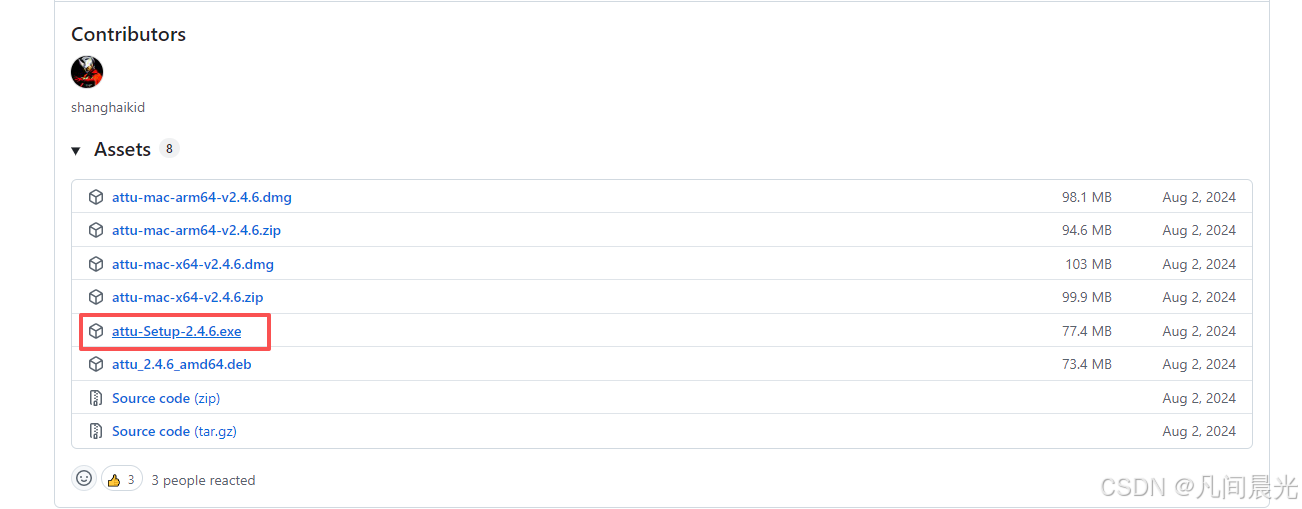
点击Attu的下载页面,下载Windows系统对应的exe安装包,双击安装即可。(默认用户名密码为root/milvus)
2. 连接Milvus服务
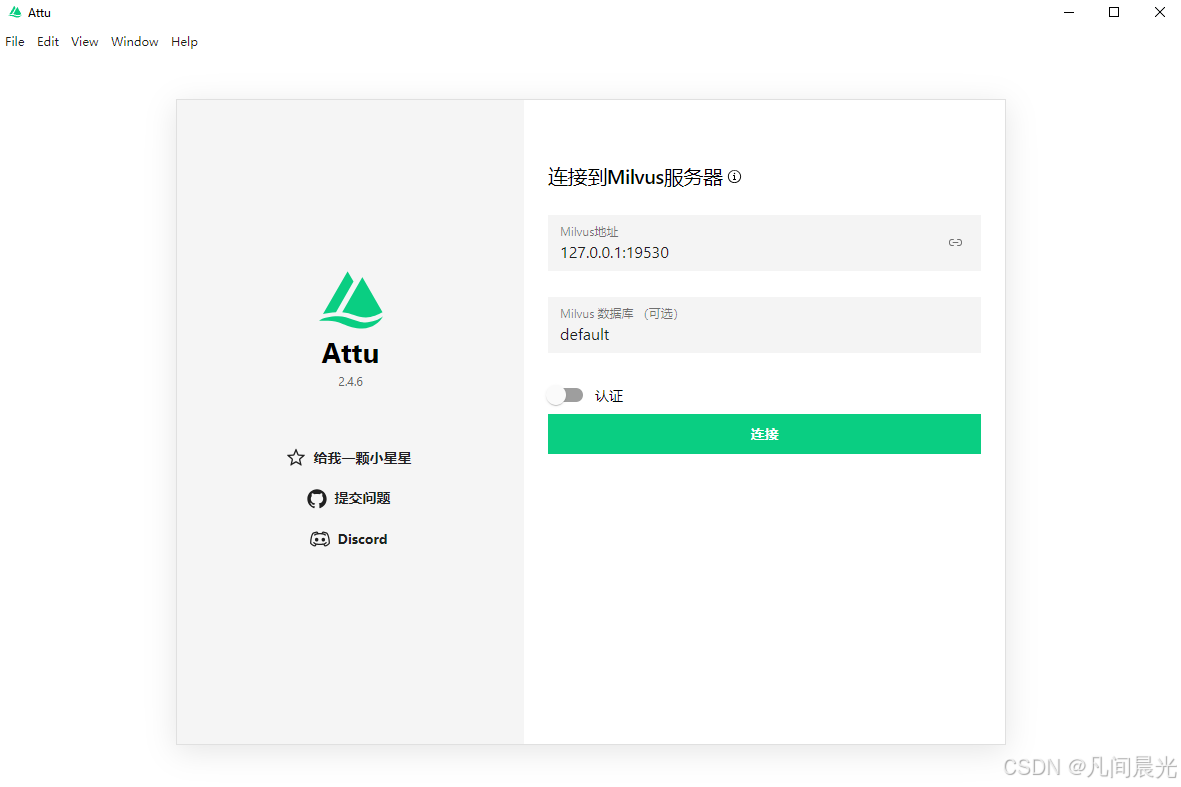
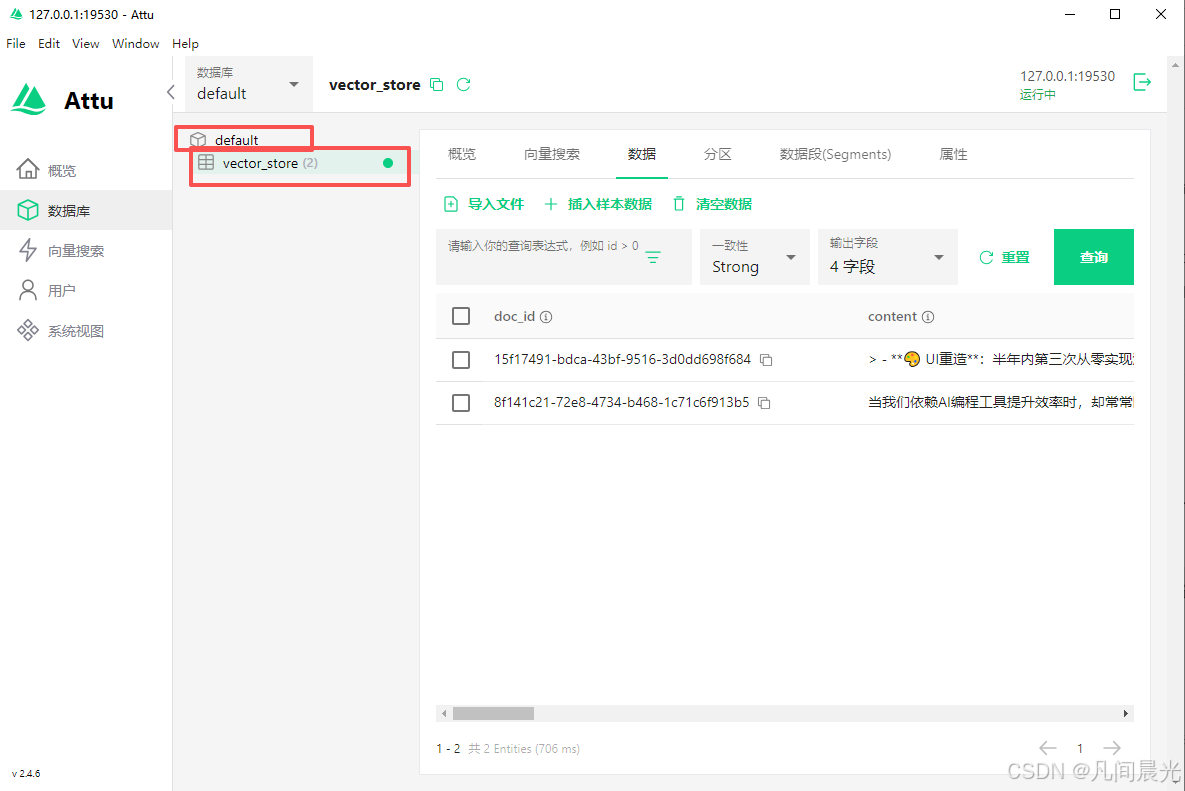
点击连接,如果出现数据库连接成功的界面,说明Attu已正常工作。通过Attu可以直观地管理Milvus中的集合、分区和向量数据,非常适合新手操作。
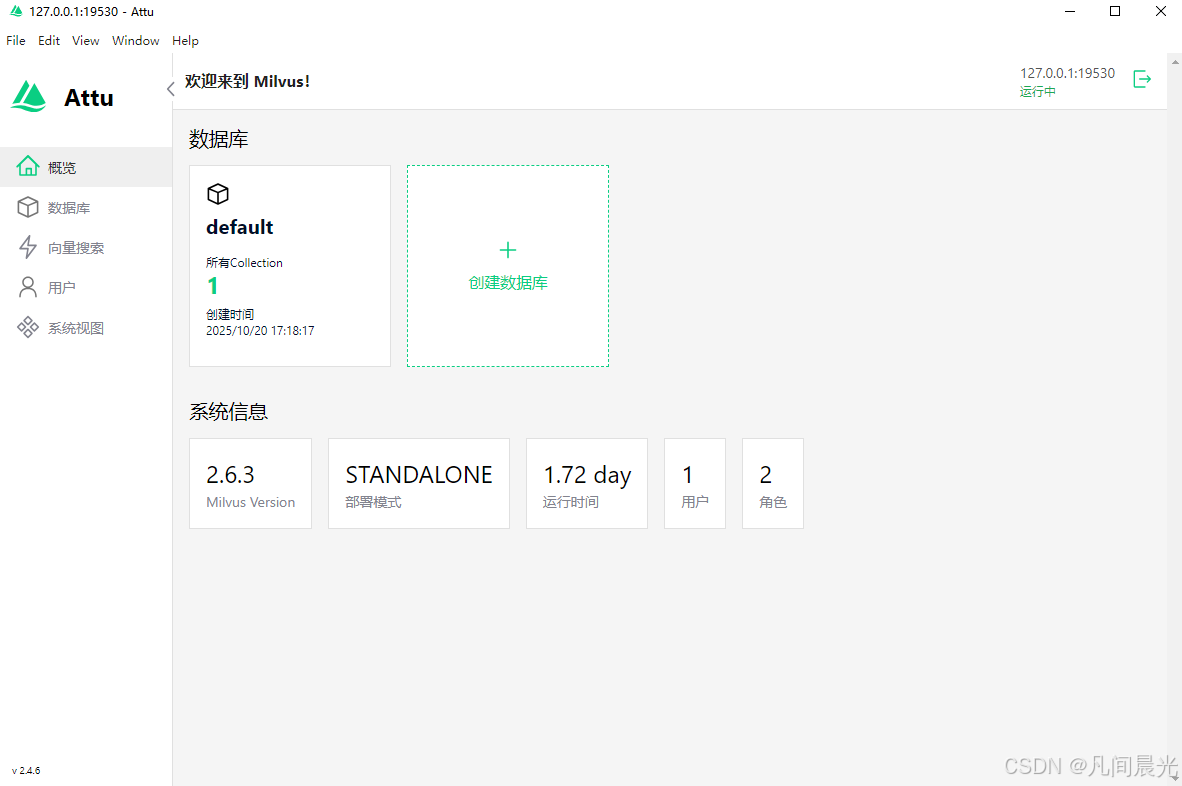
默认数据库为default,初始时无collection,可以自己配置,也可以后续通过代码生成。
五、Python客户端连接测试(可忽略)
1. 安装pymilvus库
打开命令提示符,执行:
bash
pip install pymilvus==2.4.5 # 版本需与Milvus服务匹配2. 简单向量操作示例
创建test_milvus.py文件,输入以下代码:
python
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType
# 连接Milvus服务
connections.connect("default", host="localhost", port="19530")
# 定义集合结构
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=2)
]
schema = CollectionSchema(fields, "测试集合")
collection = Collection("test_collection", schema)
# 插入测试数据
data = [
[1, 2, 3], # id字段
[[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]] # vector字段
]
collection.insert(data)
# 创建索引并加载集合
index_params = {"index_type": "IVF_FLAT", "metric_type": "L2", "params": {"nlist": 1024}}
collection.create_index("vector", index_params)
collection.load()
# 向量搜索
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(
data=[[0.2, 0.3]],
anns_field="vector",
param=search_params,
limit=2
)
print("搜索结果:", results)
# 释放资源
collection.release()运行代码,如果输出包含搜索结果,说明Python客户端已成功连接Milvus并执行了向量操作。
六、常见问题解决
1. Docker启动失败
- 检查WSL2是否启用:
wsl --list --verbose确保状态为Running - 检查虚拟化是否开启:任务管理器→性能→CPU→虚拟化显示"已启用"
- 尝试以管理员身份重启Docker服务:
net stop com.docker.service && net start com.docker.service
2. Milvus启动后容器状态异常
- 查看详细日志:
docker compose logs milvus-standalone - 检查端口是否冲突:使用
netstat -ano | findstr "19530"查看端口占用情况 - 删除volumes重新启动:
docker compose down -v && docker compose up -d
3. Attu连接超时
- 确认Milvus服务正常运行:
docker compose ps - 检查防火墙设置,确保19530端口开放
- 尝试使用127.0.0.1代替localhost作为主机地址
七、总结与后续学习
通过本文步骤,你已经成功在Windows环境下搭建了Milvus向量数据库单机版。后续可以:
- 学习Milvus数据模型:理解Collection、Partition、Segment的概念
- 尝试不同索引类型:IVF_FLAT、HNSW、ANNOY等性能对比
- 开发实际应用:结合OpenAI Embeddings实现文本相似性搜索,基于SpringAi+SpringBoot+Milvus开发一套支持RAG的私有化问答服务。
- 了解集群部署:当数据量增长时,如何扩展Milvus服务
Milvus官方文档和GitHub仓库提供了丰富的学习资源,建议新手从简单的向量插入和搜索开始,逐步掌握高级功能。如果在使用过程中遇到问题,Milvus社区论坛和GitHub Issues是获取帮助的好地方。
祝你的向量数据库之旅顺利!有任何问题欢迎在评论区留言讨论。