10月21号,DeepSeek-OCR发布的第二天,我发了一个朋友圈说:
DeepSeek-OCR,yesterday发布,今天就6.5k Star,Downloads 32k+。已经不需要多说什么了。一句话类比就是昨天刚宣布要拍《三体》电视剧,今天就已经全集上线,并且每一帧画面都是你想要的字幕和解析。
对我这种长期和OCR打交道的人来说,这是一个非常震惊的消息。因为他的功能很强大,不只是识别数学公式,也能识别化学公式(公式里面有中文,很多团队在攻克,并打算借此引爆行业)。关键是你知道吗?OCR上的进步,并不是他的目的,它的初心是信息压缩。我担心朋友们体会不到它的价值,又在朋友圈下给自己评论说:
大语言模型目前有个问题,内存爆炸(健忘)。也就是你和他聊了半个小时,他只记得最近十分钟的事情。那我有几百页的报告,一部百万字的小说,它很崩溃。于是,这个方案将聊天生成图像数据。前特斯拉AI总监也说过,像素可能比文本更适合做输入,因为"一图胜千言"。我们人类的脑海就是浮现画面而非字符。于是,图表、表格、图像它是理解后记忆的,是读懂了的。这应该是一项"核心技术机密",DeepSeek选了开源(免费公开),因此立即获得全球关注和赞誉。
现在一周过去了,DeepSeek-OCR在Github上已经有17.6k Star,Downloads也超过73万次了。我当然是其中一员。
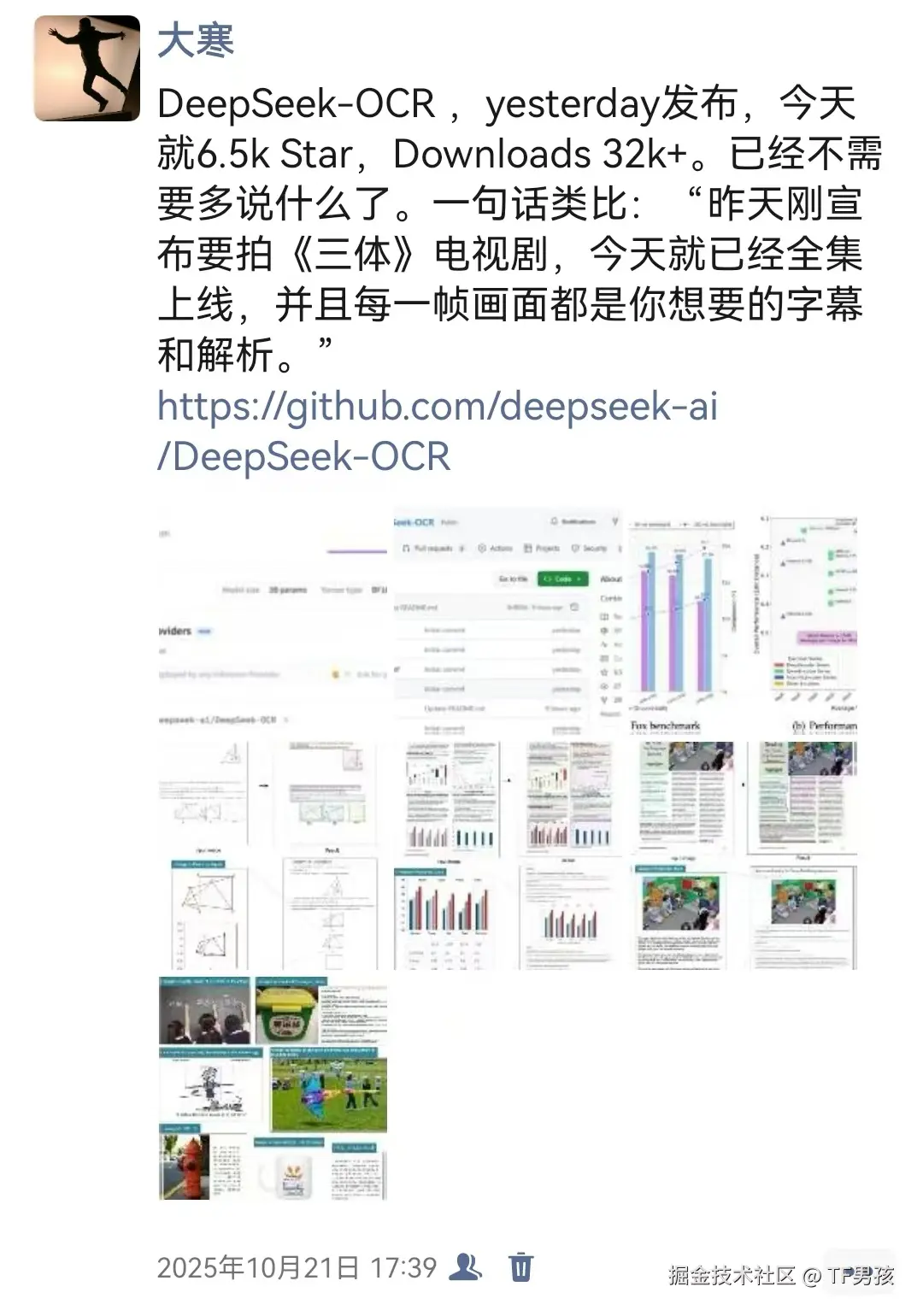
每一个新模型出来,我都会试试。因为所有的模型宣传的都很好,实际效果可能一般。很多模型会拿自己跟其他火热的模型去比,强调自己哪些方面胜过它们。这是一种"我没说第一,但是我打败了武林第一"的宣传。当然,DeepSeek-OCR也如此。
这里面什么"GOT-OCR"、"dots.ocr"都曾经是OCR的"武林第一"。我也曾一次次研究并实践过它们。不得不承认,他们各有千秋,但仅仅是在某一方面比较强。比如有的人单刀很厉害,有的人则长拳很棒。这两者如何对决?
想要体验DeepSeek-OCR,你可以去它的Github仓库(github.com/deepseek-ai...
很多算力平台提供这项服务,类似于拎包入住,自动给你部署好你需要的模型环境。我也是用这种方式尝试DeepSeek-OCR。
先说结论,再说效果,最后说取舍。
结论是如果要求不高的话,DeepSeek-OCR基本上可以替换你现有收费的OCR服务。替换的前提是你得有量,因为部署需要成本,你得采购2.2万元的显卡设备,然后每月1000左右的电费、网络、机房成本。如果你调用一次哪怕1块钱,每年才调用10000次,那也不过是1万块钱,没必要花彩礼、投感情,直接快餐就好。
下面说效果,首先尝试手写中文和手写英文。
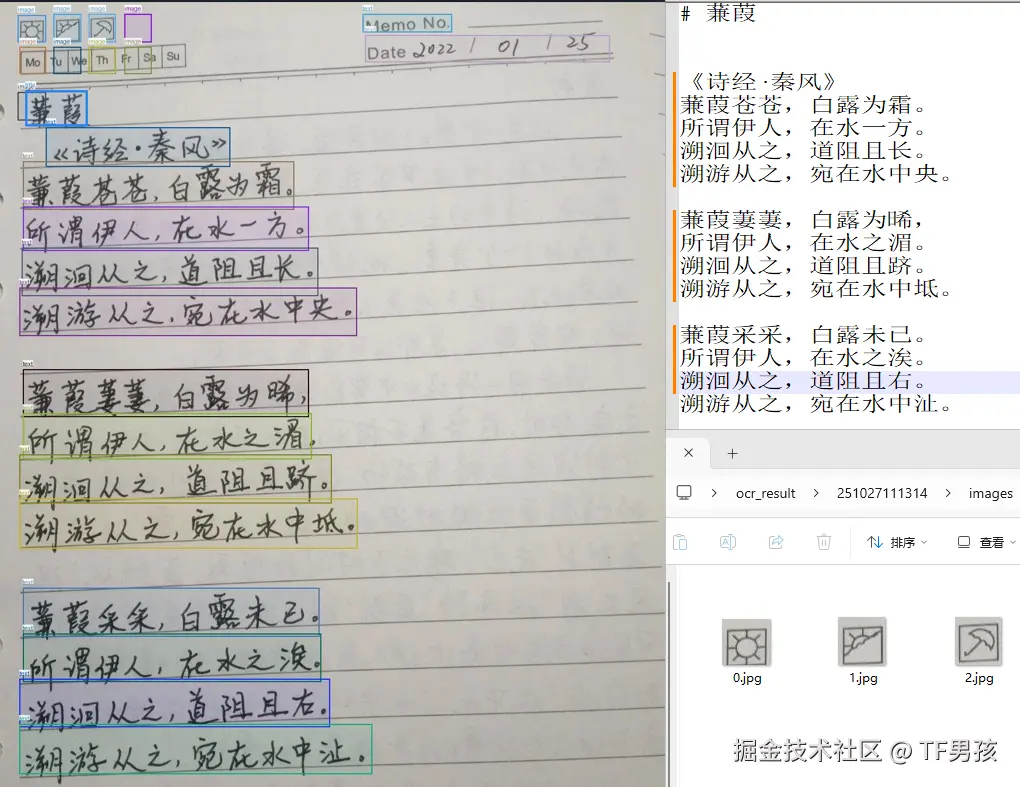
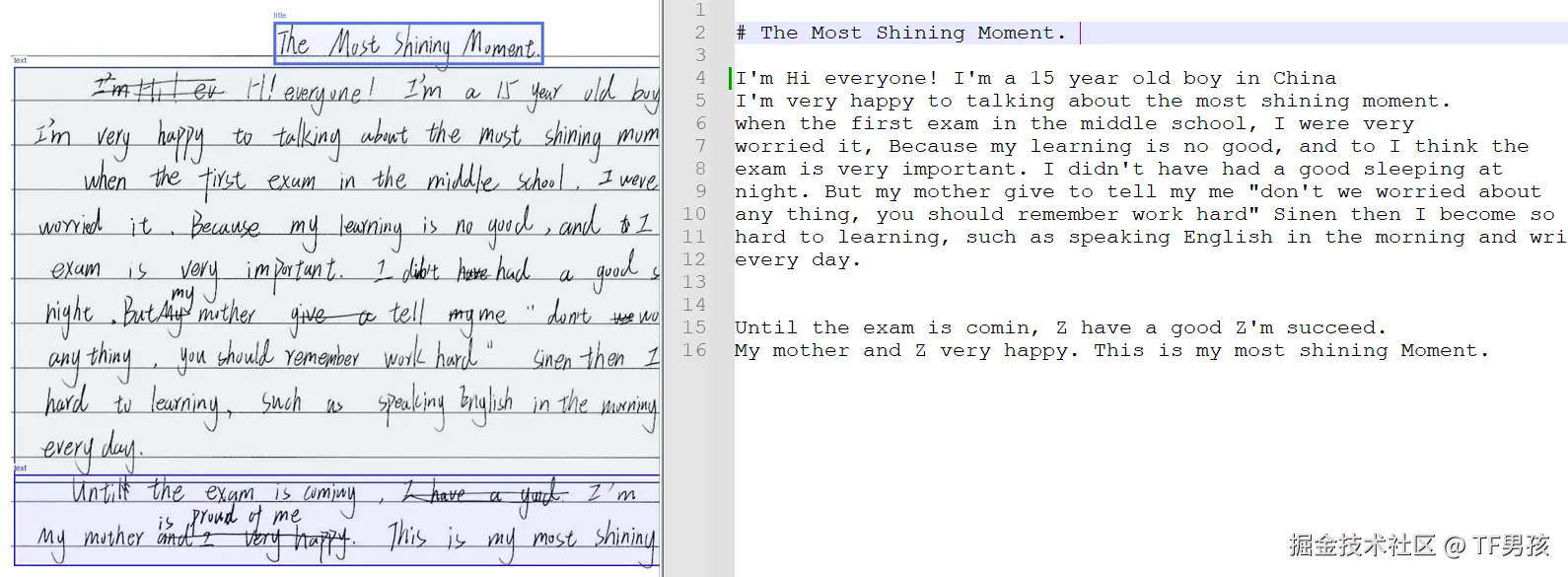
它基本能准确识别手写的中文和英文。
然后,看看它对于文档,尤其我这种经常处理考试文档的人来说,效果如何。

相比较于目前收费的OCR,它对于数学图表的识别较为准确。这原来可是一个难题。
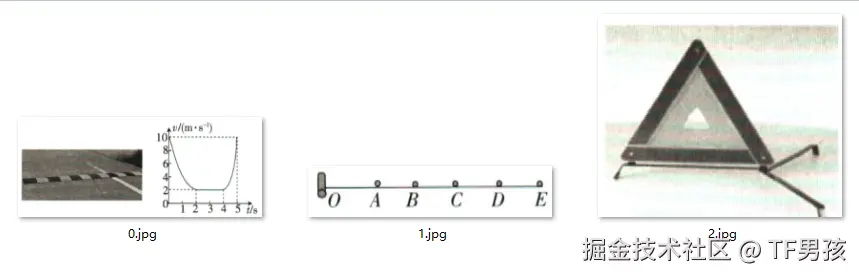
因为数学的图表和正常文字,区分度不大,很容易混淆。就像是上图中间的ABCDE,你说它是文本,好像也可以。
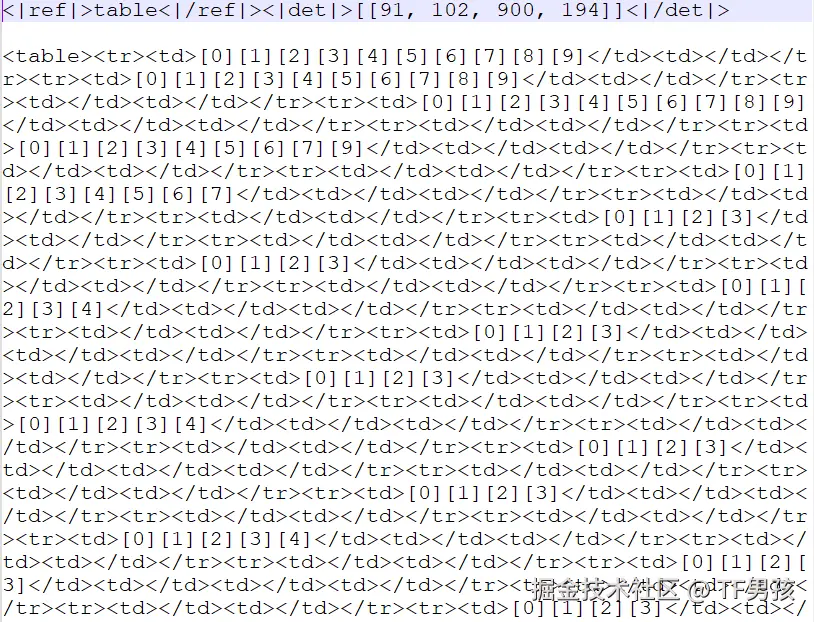
客观地说,DeepSeek-OCR也有问题。比如遇到表格时,尤其表格开头时,它会发生问题。
比如类似如下的图(以表格开头):

那么它会认为全文都是表格,输出的内容会一直table下去。
除此之外,我们需要有一个清醒的人认识。DeepSeek-OCR的起源是信息压缩,OCR只是在这个过程中的一个副产物。
它要把上下文压缩,它就需要对这个世界有个基础的认识。例如,让它在下面这张图片上框出看到的物体,它能清晰地找到"人"、"椅子"等物体。

同时,让它找到"11-2="这个算式在哪里。它也可以做到。
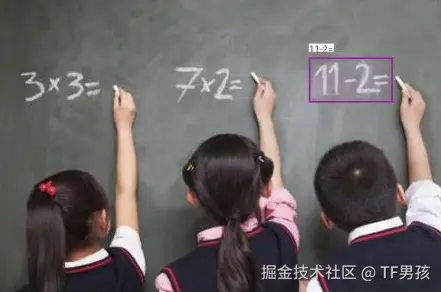
做到上面行为的一个基础,就是先OCR识别出文字。因此,我们说OCR是它的一个副产物。
而它的核心是信息压缩。
再举个例子,你写了很长一段话:
有一个红色的消防栓。消防栓上有一个笑脸,显得非常友好和亲切。消防栓的顶部有一个黑色的盖子,周围有一些金属铆钉。在消防栓的底部,有一个粉红色的贴纸,上面写着"bowtie"。背景中可以看到一条街道,街道上有几辆停放的汽车和一些树木......
不是这么短,而是非常长,它包含了很多信息,DeepSeek-OCR将它压缩为如下图像的形式。

这很像将全本的《水浒传》原著转换为薄薄的手掌连环画。而经过训练的DeepSeek-OCR变为一个老评书艺人,它可以将这本连环画再恢复为原著文字的鸿篇巨著。10倍压缩比,恢复率是97%,也就是1000个文字token可以用100个视觉token来表示。压缩比提升到20倍,准确率在60%左右。

第一,这很强大,解决了大语言模型内存爆炸的问题。它不会忘了你们是因什么开始聊天的。
第二,它丢失了信息。在人工智能领域,97%是极低的一个消极的正确率。
拿我现在做考号识别来说,如果数字识别率是97%,这会是很糟糕的一种情况。
一个班里有50个学生,一个学生有6位考号,那么一次考试就是300个数字。97%的正确率,那么就会有9个数字识别错误。每个学生但凡错了一个数字,就会导致考号错误。50个人有9个出错,这几乎没法用。
另一方面,从信息学我们也知道,信息冗余才是保证信息稳定的关键,而信息细节更为重要。人工智能为什么要用浮点数做计算?拿厨房举例子:研究时要求FP64(研发添加剂,精密天平),训练时要求FP32(制作料包,厨房电子秤),推理时可以FP16(做饭,小勺或瓶盖)。
我觉得它的进步体现在AI开始更像人一样思考。它将记忆转换为画面,而且会长期记忆一些印象深刻的事件,扔掉一些自己认为不重要的事件。
你选它也是一样。你是选一个无比细心但是只有三分钟热度的男朋友,还是选一个记不住你生日但知道你对什么过敏的男朋友。
最后说一下测试结果,如果你买24G的一台显卡比如RTX 4090,再配上CPU、内存、硬盘、电源等形成工作站,理想状态是10秒钟并发处理30张图片。如果你有200张图片,得1分钟以后处理完。因此,是租是买,是用它还是用别家,还是看需求与实力。
你看,最终它仍然是一个取舍。并不是万能方案。