Abstract
隐式神经表示 (INR) 已成为使用神经网络将离散信号编码为连续、可微函数的强大工具。然而,不幸的是,这些模型通常依赖单体架构来表示高维数据,随着维度的增长,导致计算成本过高。我们提出了 F-INR,这是一个框架,它通过函数张量分解 重新制定 INR 学习,将高维任务分解为轻量级的、特定于轴的子网络。每个子网络学习一个低维数据组件(例如,空间或时间)。然后,我们通过张量运算组合这些组件,降低前向传递的复杂性,同时通过专业学习提高准确性。F-INR 是模块化的,因此与架构无关,与 MLP、SIREN、WIRE 或其他最先进的 INR 架构兼容。它还与分解无关,支持 CP、TT 和 Tucker 模式,并具有用户定义的等级以进行速度精度控制。在我们的实验中,F-INR 在视频任务上的训练速度比现有方法快 100×,同时实现更高的保真度 (+3.4 dB PSNR)。图像压缩、物理模拟和 3D 几何重建也具有类似的收益。通过这种方式,F-INR 为高维信号建模提供了一种新的可扩展、灵活的解决方案。
1. Introduction
隐式神经表示(INRs)是离散信号(如图像60, 61, 76、视频4, 7, 17, 80、三维场景5, 22, 42, 43和几何形状35, 47)的连续、函数式表示。通过神经网络实现,这些方法将离散结构化数据映射到连续的函数空间中,便于进行平滑插值。这种通用性促进了架构设计和实际应用的进步42, 47, 53, 57。与离散的基于网格的表示相比,连续参数化具有诸多优势,包括更高的内存效率、能够在无界域上定义以及分辨率不变性13。具体来说,这种方法能够捕捉到细节,其分辨率由网络的容量和表达能力决定,而不是由网格决定57。此外,这些表示的可微性在使用自动微分计算梯度和高阶导数方面发挥着关键作用,这对于逆向建模是相关的55, 56, 67。
另一种表示多维数据的形式是张量分解,通常用于信号和图像处理与分析2, 3, 29, 30, 58, 63, 70, 79。它将高维信号建模为低秩、低维成分的组合。然而,这些方法局限于离散网格设置,限制了它们的适用性。
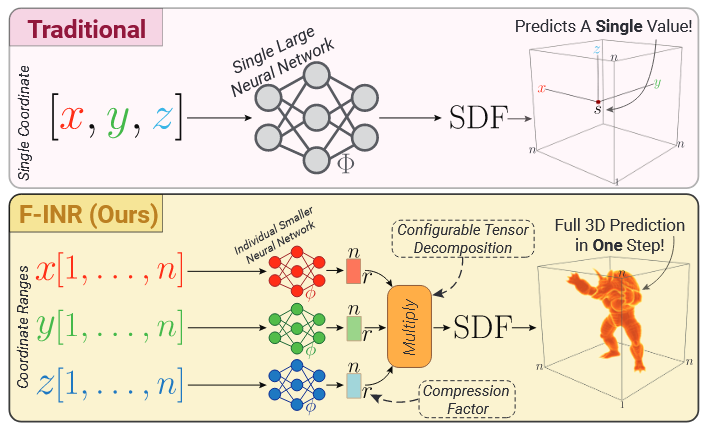 图 1.通过函数张量分解实现高效的 INR:INR 模型使用单个大型网络一次预测一个值(一批值)。我们的方法将函数分解为更小的网络,通过可配置的张量分解模式和压缩等级,在单个步骤中实现全面预测
图 1.通过函数张量分解实现高效的 INR:INR 模型使用单个大型网络一次预测一个值(一批值)。我们的方法将函数分解为更小的网络,通过可配置的张量分解模式和压缩等级,在单个步骤中实现全面预测
INR和张量分解各有优势,将它们结合起来可以高效地表示复杂数据。因此,我们提出了F-INR,这是一种利用张量分解优势的INR重新表述。F-INR使用专门的单变量神经网络来学习INR的可变分离形式,通过促进低维成分的使用,保留了连续表示的好处。图1提供了这种设置的一般说明。在这项研究中,我们专注于将神经网络与三种张量分解技术结合起来,特别是CP20、TT45和Tucker64。我们在各种INR实验中建立了多功能性,包括图像和视频编码、通过SDFs的形状表示以及用于超分辨率的物理模拟编码。F-INR在训练速度(高达100倍)、特定任务的指标和定性结果方面优于传统的INR。这表明,除了网络架构修改之外,还可以实现改进。
总结来说,我们的主要贡献有四个方面:
- 通过函数张量分解对INR进行了新的表述,为连续信号表示提供了新的视角。
- F-INR框架,它利用三种特定的分解模式与现有的网络架构相结合,提供了灵活且高效的建模方式。
- 在关键的INR应用中对F-INR的强大性能进行了实证展示。
- 开源我们的框架,以推动F-INR研究领域的发展。
2. Related Work
**隐式神经表示(INR)**经历了几个发展阶段。最初的想法引入了明确的坐标机制,如位置编码42和随机傅里叶特征映射62,以提高多层感知机(MLP)的表示能力。随后的研究集中在激活函数和模型架构上:SIREN引入了正弦激活函数57,WIRE引入了Gabor小波激活函数53,InstantNGP引入了基于哈希的编码43。值得注意的是,这些方法显著增强了INR的表达能力。最近的研究是应用驱动的,例如数据压缩13, 17, 61、计算机视觉1, 4, 9, 15, 47、图形学35, 42, 44, 55, 56, 77和机器人学6, 33, 54。
张量分解将高维数据表示为较小因子的组合。经典的分解形式将数据拆分为模态成分20, 29, 30, 45, 64。早期的研究应用了固定的函数基(例如,高斯、傅里叶或切比雪夫展开)来在连续域中表示每个因子18, 27, 76,但这些方法的表达能力有限。最近的方法使用神经网络作为可学习的函数基,将深度学习与张量分解结合起来以克服这一限制。例如,一些方法用神经网络替换了手工制作的成分(Tucker因子或PCA/SVD向量)8, 10, 24, 52。在物理信息学习中,张量分解被用于通过将解拆分为低维神经成分来求解偏微分方程(PDE)。这带来了更快的训练速度和更高的准确性11, 26, 66, 68。然而,据我们所知,没有先前的工作以一般的方式将INR与函数张量分解统一起来。
对于INR的张量分解 最近作为一种结合了低秩张量分解与INR特定应用(如NeRF42)的方法出现。像TensoRF这样的工作将辐射场分解为紧凑的低秩成分5, 22。这实现了快速且内存高效的视图合成,这是一种有效但特定于领域的解决方案。此外,MLP不是直接用于学习张量分解的成分,而只是用于特征解码。同样,CoordX为每个坐标维度使用了分割的MLP和低秩表示34。它们在更深的层中被融合,省略了不同的分解模式。使用MLP来表示低秩张量函数(而不是固定的基)在像38, 39, 69这样的工作中被提出。它们连续地表示多维数据,实现了最先进的图像修复和点云上采样38, 39, 69。
F-INR 将先前的方法统一并概括为一个单一的、模块化的范式。类似于CoordX34,分离的MLP处理专门的输入维度,利用较小的子网络来提高效率。它包含了在LRTFR22或TensoRF5中发现的低秩结构,减少了冗余,同时保留了表达能力11, 66。与这些方法不同,F-INR不受限于特定的张量分解或应用领域。它本身支持几种分解模式和可适应任务数据结构的秩。由于F-INR与后端无关,它受益于架构方面的进展,如SIREN57或傅里叶特征62,并使结构化的INR表示更具模块化、可扩展性、效率和多功能性,适用于许多任务。
3. Functional Tensor Decomposition for INRs
真实世界的信号,如图像或视频,必须以离散的值网格形式存储。这些离散化的信号是d维和c变量的,面临分辨率和内存的限制。神经网络通过建模这些信号的连续版本提供了解决方案,称为隐式神经表示(INR),它们既与分辨率无关又具有内存效率。因此,INR任务是一个函数 :
,这里由神经网络
:
估计,将坐标向量
映射到c变量输出信号。
我们反而提出将问题重新表述为d个较小神经网络的张量积:
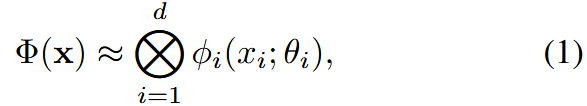
其中 表示第 i 维的单变量神经网络,具有可学习的参数
。每个网络产生一个特定秩的张量,通过经典的张量分解模式20, 45, 64,记为⊗,来恢复原始信号。分解张量具有连续函数作为基68,该方法被认为是功能性张量分解。因此,我们的重新表述引入了功能性INRs(F-INRs)的概念。
值得注意的是,这种方法是模型无关的,任何最先进的INR架构都可以作为后端,继承其优势42, 53, 57, 62。我们的方法是两个更多的超参数:模式和秩。模式指的是使用的张量分解类型。在这项研究中,我们考虑了张量理论中三种已建立的模式:
1.正多元分解(CP) 20涉及将d维张量分解为d因子矩阵,秩为R,如图2a 所示。
-
张量序列分解(TT) 45涉及d个连接链(列车)的低秩张量,如图2b 所示。
-
Tucker分解64 与CP类似,使用因子矩阵分解张量。不过,它还包括一个较小的核心张量C,捕捉每个模式组件之间的交互,如图2c所示。
下一个可选参数是秩,它指定了分解的秩,并决定了模型可以学习的表达性和复杂性。这种后端、模式和秩的组合为特定应用需求的复杂性、压缩和性能提供了精确控制。
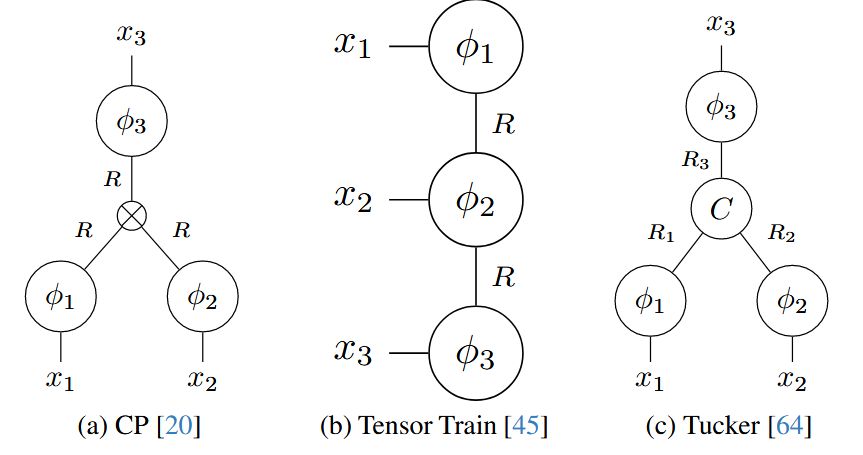 图2 三种分解的张量图(a)-(c):该示意图29,48将每个圆描述为一个分量,辐条决定其尺寸。辐条连通性显示了如何进行分解以及如何获得原始张量。在 F-INR 中,每个组件都由单独的神经网络学习。补充中提供了更多的可视化和数学公式。
图2 三种分解的张量图(a)-(c):该示意图29,48将每个圆描述为一个分量,辐条决定其尺寸。辐条连通性显示了如何进行分解以及如何获得原始张量。在 F-INR 中,每个组件都由单独的神经网络学习。补充中提供了更多的可视化和数学公式。
3.1. Advantages
F-INR通过采用有效的变量分离方法来缓解维度灾难,这使得高维函数的有效表示成为可能16, 21, 78。最近的研究已经证明,通过张量分解形式连接的多个神经网络是通用逼近器11, 26, 68。即使不存在精确的、可分离的解决方案,足够大的秩也可以逼近解决方案,利用神经网络的通用逼近能力68。先前的研究16, 21, 49表明,函数逼近所需的参数数量随着维度的增加而呈指数增长,这阻碍了神经网络学习高维函数的能力。
这在F-INR中得到了缓解,它采用了分而治之的方法,其中每个神经网络学习一个低维函数,聚合这些函数以重建完整的高维函数。我们方法的另一个好处是,在一个网格()上的点训练的案例在前向传递期间只需要
个数据点。这导致了显著的加速,这在每个模式的前向传递的复杂性中显而易见;对于d = 3的例子,见表1。

4. Experiments
我们评估了功能性张量分解(FTD)方法在提高计算效率和准确性方面对不同应用中隐式神经表示(INR)问题的性能。我们在实验中研究了关键参数对F-INR的影响,以展示我们方法的通用性:
- 后端:学习分解组件的神经网络架构。
- 模式:特定的张量分解技术。
- 秩:分解张量组件的秩。
我们选择了标准的基于ReLU的多层感知机(MLP)41,以及有无位置编码(PE)42的版本。此外,我们使用了SIREN 57,它利用周期性激活和专门的初始化,以及WIRE 53,它结合了自定义的Gabor小波激活。这些后端在广泛的INR应用中被认为是表现最好的方法。我们测试了三种张量分解模式在不同INR问题任务中的适用性:正多元分解(CP)20、张量序列(TT)45和Tucker 64。在我们的所有实验中,我们评估了不同组合模式和后端在各种秩下的性能。评估指标包括特定领域的度量,如用于编码图像和视频的峰值信噪比(PSNR),以及与未压缩原始记录的比较。对于物理模拟,我们使用真实值和预测之间的L2误差;对于使用符号距离函数(SDFs)进行几何学习的交并比(IoU)。此外,我们还提供了每次实验的训练时间。我们将结果与没有张量分解的相同后端的基线版本进行比较,使用一致的超参数以确保观察到的改进是由于功能性张量分解。我们使用具有三个层的标准MLP架构,每层有256个特征,并使用Adam 28进行50,000次迭代训练,除非另有说明,否则进行十次独立运行。我们在本节中呈现关键结果,补充材料中提供了不同秩、模式和后端的额外消融研究。训练时间是在NVIDIA GTX 1080上测量的,证明了F-INR即使在中等硬件上也能实现快速且计算效率高的公式,并且不需要依赖于适应和定制的硬件内核43。
4.1. Image and Video Encoding
我们首先通过展示F-INR在编码图像中的应用来开始。图像是二阶张量;一个简单的矩阵分解模式就足够了。我们不是使用单个神经网络来表示整个图像,而是训练两个单变量神经网络,每个网络负责一个空间维度,以学习更小的图像块。它们的矩阵乘积重建原始图像。在传统的INR设置中,图像表示为:
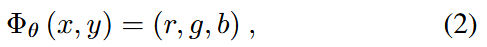
其中 表示网络,(x, y)是像素坐标,(r, g, b)代表像素颜色值。相比之下,我们学习图像的方式为:
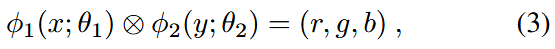
其中⊗运算符表示矩阵乘法。这里,x和y是图像坐标;输出是像素颜色。
我们选择了一张公开可用的猫的图像,其特征是精细图案的围巾和胡须。编码图像及其各自的PSNR(以dB为单位)值表明,基于F-INR的表示在相同的后端架构下实现了更高的PSNR,同时在计算效率上提供了100倍的速度提升。图3展示了真实图像和编码图像。详细的数值结果可以在表2中找到。我们还包括了LIIF 76,它使用像素的邻近信息作为基线进行图像编码。此外,DeepTensor 52类似于使用ReLU后端。我们还采用了基于哈希的编码 43 作为额外的后端。请注意,我们没有依赖于用于哈希编码的CUDA内核 43。为了确保运行时间的公平比较,我们的实现细节遵循了原始算法43。我们将图像编码框架应用于单图像超分辨率和图像去噪等任务。这展示了F-INR如何受到后端强大架构属性的影响,以及我们如何在其基线实现上进行改进,详细内容见补充材料。
 图 3.图像编码的 F-INR:此处显示了图像编码的可视化效果,以及插图中的 PSNR (dB) 值。所有第一行图像都没有使用任何分解,第二行是不同后端和等级的图像的 F-INR。此处介绍了 PSNR 最高的组合。其他结果见补充
图 3.图像编码的 F-INR:此处显示了图像编码的可视化效果,以及插图中的 PSNR (dB) 值。所有第一行图像都没有使用任何分解,第二行是不同后端和等级的图像的 F-INR。此处介绍了 PSNR 最高的组合。其他结果见补充
我们将实验扩展到视频编码,沿用之前的方法,但增加了一个时间维度。具体来说,表示为:
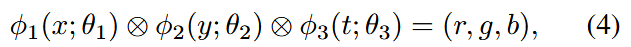
其中 t 表示时间维度(帧索引)。我们为这项任务采用了所有指定的张量分解模式 。我们使用一个256×256分辨率的人物视频80,包含300帧,面部表情和头部动作变化如图4 所示。F-INR的模块化特性允许灵活地整合不同的编码策略和网络后端,优化任务性能。与单一的、受限于固定编码或架构的单一神经网络不同,F-INR支持即插即用的方法,其中不同的编码可以针对特定维度进行定制。这种适应性在这里得到了体现。最佳性能是通过使用哈希编码对空间网络、
和傅里叶特征对时间网络
进行编码实现的,利用每种编码在其各自领域的优势。我们不包括现有的基于神经网络的视频压缩算法,如NeRVs或COIN++ 7, 13, 40。这些算法涉及视频的逐帧学习和随后的神经网络量化。定量结果在补充材料中提供。
 图 4.使用F-INR对具有细微面部特征的视频进行编码80(公开):平均PSNR(dB)和模型显示在第一列中;训练时间在最后。SIREN 57 和 ReLU 41 具有位置编码 42 的表现优于其基线,捕捉面部细节并保持时间一致性,而 WIRE 53 的表现更差。最佳性能(第五行)分别使用哈希43和空间和帧维度的位置编码相结合,突出了F-INR的模块化。其他结果见补充
图 4.使用F-INR对具有细微面部特征的视频进行编码80(公开):平均PSNR(dB)和模型显示在第一列中;训练时间在最后。SIREN 57 和 ReLU 41 具有位置编码 42 的表现优于其基线,捕捉面部细节并保持时间一致性,而 WIRE 53 的表现更差。最佳性能(第五行)分别使用哈希43和空间和帧维度的位置编码相结合,突出了F-INR的模块化。其他结果见补充
4.2. Signed Distance Functions for Geometries
符号距离函数(SDF)是一个连续函数,它为3D空间中的每个点分配一个相对于最近表面点的值。虽然从点云学习和解决 **Eikonal偏微分方程(PDE)**以获得SDF已经取得了显著成功47, 53, 57,但使用体素网格进行SDF学习仍然是一个相对较少探索的领域。体素网格提供了结构化和密集的表示,使其特别适合需要空间一致性和高效3D卷积的应用36, 74, 75。
我们利用F-INR来解决Eikonal PDE,并直接从基于体素网格的SDF数据中学习几何表示,基于15, 46, 47, 57的基础公式。我们的损失函数定义为:
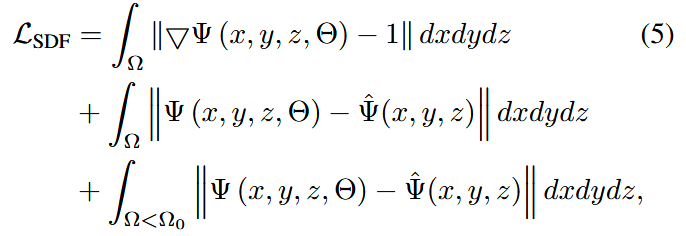
其中Ω表示学习SDF Ψ的空间域。损失函数由三个部分组成。第一项执行Eikonal PDE约束。第二项最小化预测SDF值Ψ和域Ω内的真实值Ψ̂之间的差异。第三项优先考虑在指定阈值Ω < Ω_0内的表面附近的数据点。根据59,我们将SDF值截断到0.1的阈值之外。
为了评估F-INR在几何形状上的性能,我们使用了来自Stanford 3D Scan Repository的模型12, 14, 31, 65。我们选择了一组具有复杂几何形状和不同细节级别的对象,为评估我们基于SDF的方法的准确性和效率提供了一个稳健的测试。实验使用了相同的底层模型架构、基线配置和分解秩,这些在更广泛的实验部分中有所描述。我们没有在这项任务中使用哈希编码,因为它缺乏全局可微分性,使其不适合需要良好梯度的应用.
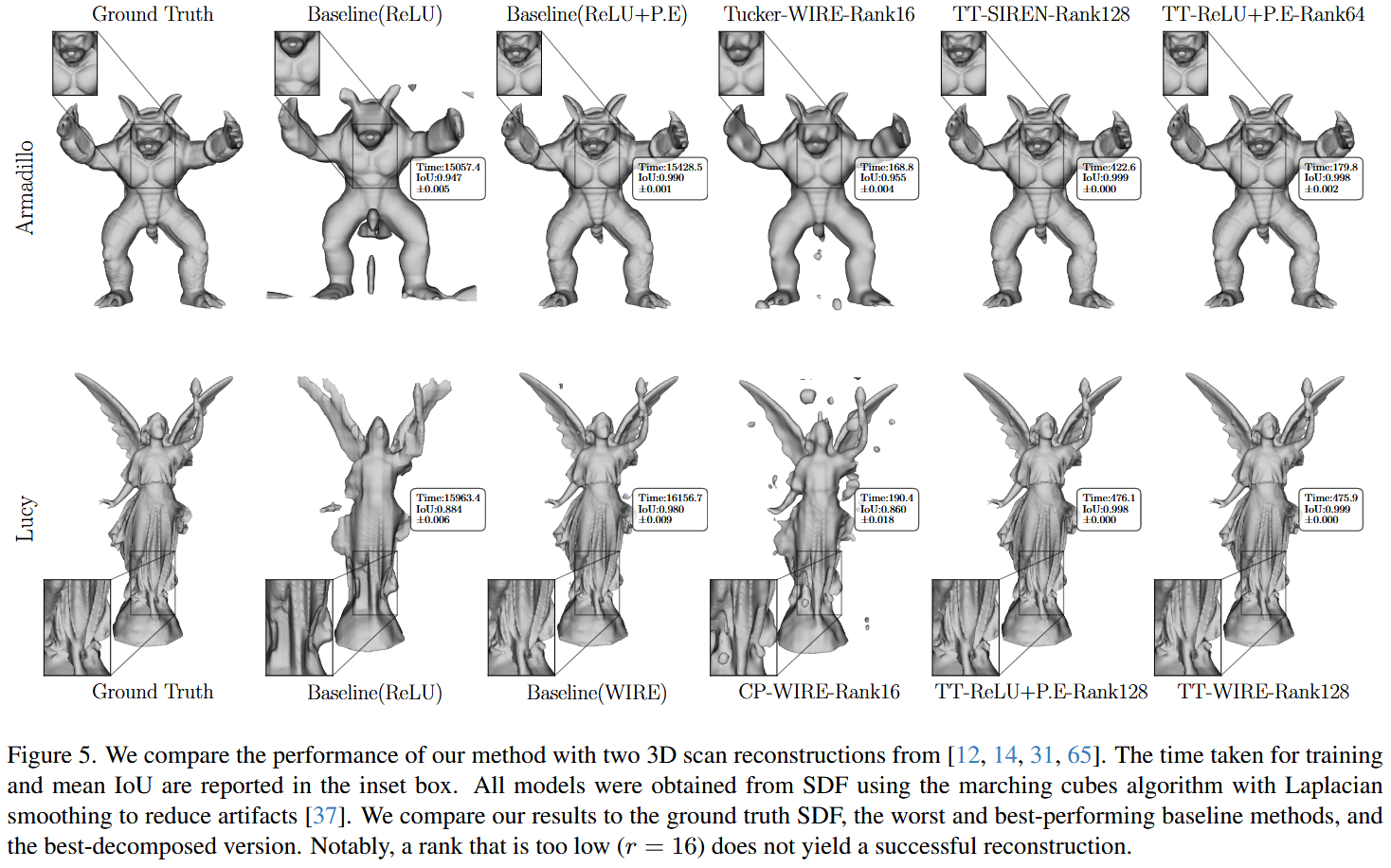 图 5.我们将我们的方法的性能与12,14,31,65中的两个3D扫描重建进行了比较。训练所需的时间和平均 IoU 报告在插入框中。所有模型都是使用行进立方体算法和拉普拉斯平滑从SDF获得的,以减少伪影37。我们将我们的结果与地面实况 SDF、最差和表现最好的基线方法以及最佳分解版本进行了比较。值得注意的是,秩太低 (r = 16) 不会产生成功的重建。
图 5.我们将我们的方法的性能与12,14,31,65中的两个3D扫描重建进行了比较。训练所需的时间和平均 IoU 报告在插入框中。所有模型都是使用行进立方体算法和拉普拉斯平滑从SDF获得的,以减少伪影37。我们将我们的结果与地面实况 SDF、最差和表现最好的基线方法以及最佳分解版本进行了比较。值得注意的是,秩太低 (r = 16) 不会产生成功的重建。
如图5 所示,F-INR生成了更详细和准确的对象表示。所有学习到的SDF体素网格都是使用相同的行进立方体算法设置获得的结果37。在补充材料中提供了原始学习到的SDF结果的概述,并与其他方法如DeepSDF47和IGR15进行了进一步比较。为了比较不同的模式,我们为Lucy SDF改变了秩和模式,使用了表现最佳的后端,如图6所示。结果表明,张量序列(Tensor-Train)在稳定性和准确性指标上都优于其他方法,这归因于其连接结构45。有趣的是,随着秩的增加,Tucker模式的性能变差,这归因于其大核心,如29, 45, 70中解释的那样,形成了一个瓶颈。我们还观察到,对于TT模式,秩的影响是显著的,性能在秩达到64时有所提升,并在此之后保持不变。所有后端、模式和几何形状的额外结果在补充材料中提供。
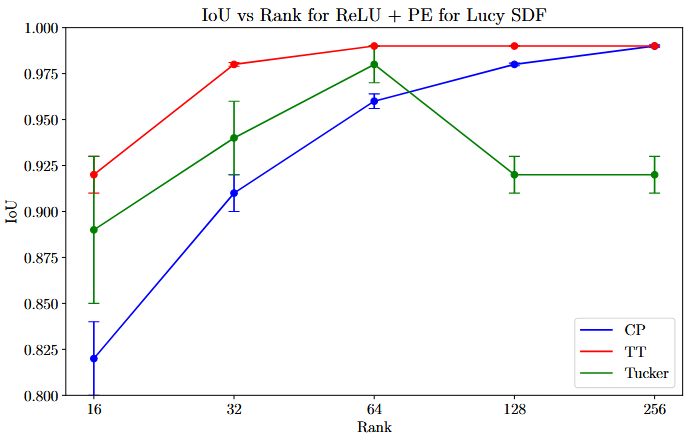 图6.后端所有张量分解模式的 IoU 与 Rank 的关系 ReLU + 学习 Lucy SDF 的位置编码。张量训练优于其他两种模式,而塔克模式会降低较大等级的性能。相比之下,TT模式表现出稳定的性能,秩的增加
图6.后端所有张量分解模式的 IoU 与 Rank 的关系 ReLU + 学习 Lucy SDF 的位置编码。张量训练优于其他两种模式,而塔克模式会降低较大等级的性能。相比之下,TT模式表现出稳定的性能,秩的增加
4.3. Super Resolution of Simulations
高保真模拟计算量大,通常受到传统数值方法分辨率的限制。虽然物理信息神经网络(PINNs)50, 68 是一个有前景的替代方案,但它们在增加配点数量或处理复杂模拟时也面临可扩展性挑战32, 71, 72。因此,两种方法之间的权衡是有帮助的:粗略模拟对于数值方法更易访问,而INRs可以使用PINN损失学习无分辨率限制的形式。我们的方法,F-INR,使用低分辨率数据和物理信息损失函数进行训练。我们在一个具有精细涡旋耗散细节的数据集上,通过一个衰减湍流模拟来验证这种方法。我们根据真实高分辨率基准和我们预测的高分辨率输出之间的L2误差来评估性能。模拟的偏微分方程(PDE)是不可压缩Navier-Stokes方程的涡度形式73,表达为:
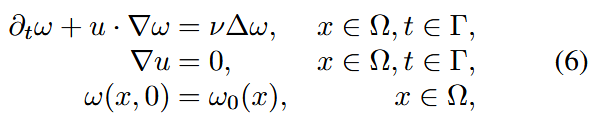
其中 表示速度场,
是涡度,
表示初始涡度,
是粘性系数。空间域是
,时间域是
。
原始数据集的分辨率为 。我们使用分辨率较低的
来训练我们的F-INR模型,这对应于大约40倍的稀疏性。我们的损失函数定义为:
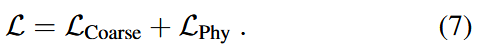
其中 对应于在粗略模拟数据上计算的损失,而
是物理信息损失项,用于执行方程(6)中的PDE约束。值得注意的是,我们不需要诸如时间步进32等技术,这些技术将域划分为更小的时间间隔,因为我们在整个域中学习解决方案。
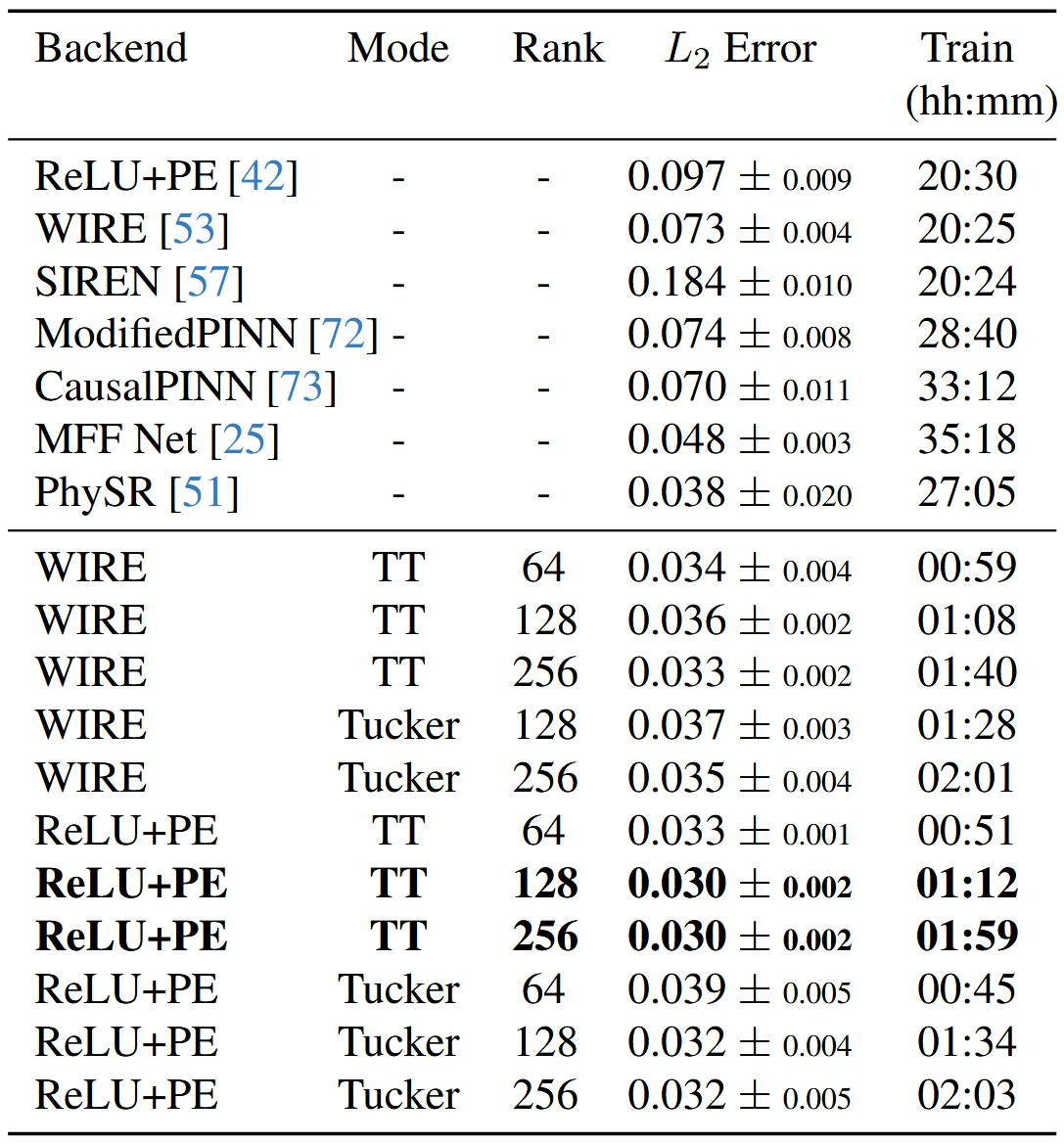 表 3.比较 F-INR 的 L2 误差和使用 Navier Stokes 方程进行衰减涡度超分辨率模拟的基线实现。我们在这里只列出了平均 L2 误差小于 0.04 的最佳性能设置,所有设置都优于基线实施(保留在补充材料中)。F-INR 始终表现出色,L2 误差和收敛时间更短。
表 3.比较 F-INR 的 L2 误差和使用 Navier Stokes 方程进行衰减涡度超分辨率模拟的基线实现。我们在这里只列出了平均 L2 误差小于 0.04 的最佳性能设置,所有设置都优于基线实施(保留在补充材料中)。F-INR 始终表现出色,L2 误差和收敛时间更短。
除了稀疏数据外,我们每维采样200个点用于共定位以计算物理信息损失。我们结果的 误差在表3 中呈现。我们将结果与诸如Modified PINNs 72 和 CausalPINNs 73 等架构进行比较,这些架构旨在增强原始PINN公式,并可以直接应用于超分辨率任务。我们还与MeshFreeFlowNet 25 和 PhySR 51 进行比较,这些架构是专门为模拟超分辨率开发的。我们的发现表明,F-INR始终提供更快和更好的解决方案。我们还希望强调,这项工作是首次展示WIRE 53 在物理模拟场景中的适用性。图7中展示了一个代表性解决方案,它比较了F-INR使用模式TT、后端WIRE和秩128在高保真数据上训练后的预测涡度。这里仅展示了表现最佳的F-INR结果。各种秩、后端和稀疏度级别的消融研究在补充材料中提供。
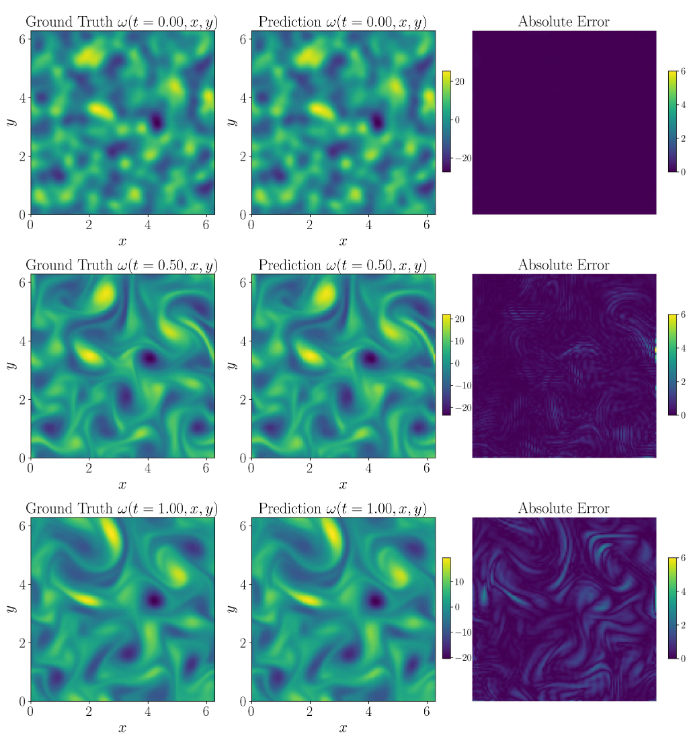 图7.F-INR-TT 线等级 128 在时间步长 0.0(开始)、0.5(中间)和 1.0(结束)处的涡度可视化。第一列是地面实况涡度,第二列是根据粗略数据和底层纳维-斯托克斯偏微分方程训练的预测高保真涡度。最后一列是基本事实和预测之间的绝对逐点误差。我们看到,在不采用时间行进方案的情况下,基本事实和预测之间高度一致32
图7.F-INR-TT 线等级 128 在时间步长 0.0(开始)、0.5(中间)和 1.0(结束)处的涡度可视化。第一列是地面实况涡度,第二列是根据粗略数据和底层纳维-斯托克斯偏微分方程训练的预测高保真涡度。最后一列是基本事实和预测之间的绝对逐点误差。我们看到,在不采用时间行进方案的情况下,基本事实和预测之间高度一致32
5. Limitations and Future Directions
尽管F-INR提供了几个优势,但它目前仅限于结构化数据格式,这使得将其应用于点云或光线追踪等非结构化场景变得具有挑战性。与结构化网格不同,非结构化数据需要特定于应用的修改,这通常会增加计算复杂性5, 38。在这种情况下调整我们的框架将需要将单个数据点映射到额外的张量组件,降低前向传递效率。虽然这个方向很有前景,但它需要进一步研究以平衡效率和表示质量,我们将其留待未来研究。
另一个有趣的方向是探索更具有表现力的张量分解,例如张量环或拓扑感知张量网络29, 30,以增强压缩-准确性权衡。探索自适应秩选择技术以实现自动复杂性控制也很有趣。此外,将张量分解与基于CUDA的优化(如InstantNGP 43中所见)集成,可以进一步加速推理,同时保留结构化表示的好处。
最后,我们的工作在很大程度上仍然是经验性的。虽然分解神经网络是有效的通用逼近器11, 19, 26, 68,但需要更深入的理论见解来更好地理解张量分解如何影响基于坐标的隐式神经表示的表达能力和效率。
6. Conclusions
我们介绍了基于功能性张量分解的隐式神经表示(F-INR),这是一个统一张量分解与隐式神经表示的框架,用于高效的高维函数建模。通过利用单变量神经网络来学习低维组件,F-INR缓解了维度灾难并加速了训练。
F-INR的一个关键优势是其模块化。与单一的INR不同,它无缝集成了各种张量分解(CP、TT、Tucker)和神经架构(具有位置编码的ReLU、哈希编码、SIREN、WIRE)。这种灵活性允许轻松适应新的分解策略和网络后端。
我们的实验表明,在训练速度(高达100倍)和准确性方面都有显著提高,涵盖了包括图像和视频编码、基于PDE的超分辨率和基于SDF的几何编码在内的任务。虽然目前仅限于结构化数据,但将F-INR扩展到非结构化设置是一个有前景的方向。这项工作为通过桥接张量分解与隐式神经表示来进一步推进可扩展高维函数学习奠定了基础。