文章目录
- 0.前言
- 1.准备项目
- 2.准备环境
-
-
- [2.1 获取项目](#2.1 获取项目)
- [2.2 docker里面配置redis](#2.2 docker里面配置redis)
-
- 前提条件
- 通过Docker部署Redis步骤
-
- [2.2.1 拉取Redis官方镜像](#2.2.1 拉取Redis官方镜像)
- [2.2.2 运行Redis容器](#2.2.2 运行Redis容器)
- [2.2.3 验证Redis是否启动成功](#2.2.3 验证Redis是否启动成功)
- [2.2.4 (可选)采用持久化数据](#2.2.4 (可选)采用持久化数据)
- [2.3 项目配置](#2.3 项目配置)
-
- 3.项目使用
0.前言
如题 ,简而言之 ,这个项目就是防止你爬数据爬太多给你ip封了的。
1.准备项目
1.Proxy_Pool(代理池)项目 是一个用来采集、验证和管理大量代理IP的开源项目,主要目的是为爬虫或其他应用提供高质量、可用的代理IP,从而帮助用户绕过目标网站的IP限制、反爬虫机制,实现更稳定和高效的数据抓取。
git clone git@github.com:jhao104/proxy_pool.git2.Redis 在代理池项目中主要作为高速缓存数据库和队列系统来使用,原因如下:
-
高速读写性能: 代理池需要频繁插入、读取、更新大量代理IP数据,Redis基于内存,读写速度非常快,适合实时性要求较高的场景。
-
支持多种数据结构: Redis支持字符串、列表、集合、有序集合等多种数据结构,方便实现代理IP的存储、排序(按速度或评分)、去重等功能。
-
轻量级且易部署:Redis部署简单,资源占用低,适合搭建高效的代理池服务。
-
支持过期时间和自动淘汰: 可以为代理IP设置过期时间,自动剔除失效IP。
2.准备环境
2.1 获取项目
git clone https://github.com/ZHHUAZH/Proxy_pool_Python3122.2 docker里面配置redis
在macOS上通过Docker部署Redis,步骤非常简单。下面是详细的操作流程:
前提条件
- 你的macOS已经安装好Docker Desktop。如果未安装,可以去 Docker官网下载页面 下载并安装。
通过Docker部署Redis步骤
2.2.1 拉取Redis官方镜像
打开终端,执行:
bash
docker pull redis这条命令会从Docker Hub拉取最新的Redis官方镜像。
2.2.2 运行Redis容器
执行以下命令启动Redis容器:
bash
docker run -d --name my-redis -p 6379:6379 redis参数说明:
-d:后台运行容器--name my-redis:给容器命名为my-redis,你也可以改成自己喜欢的名字-p 6379:6379:将容器内6379端口映射到宿主机的6379端口,Redis默认端口是6379redis:使用的镜像名称
2.2.3 验证Redis是否启动成功
你可以用两种方式检测:
- 方式一: 通过Docker命令查看容器状态
bash
docker ps如果看到my-redis容器正在运行,说明启动成功。
- 方式二: 使用redis-cli连接测试
如果你本机没有安装redis-cli,可以用docker命令进入容器测试:
bash
docker exec -it my-redis redis-cli进入后,执行:
bash
ping如果返回PONG,说明Redis服务正常。
2.2.4 (可选)采用持久化数据
默认容器里的数据是临时的,容器删除后数据会丢失。可以挂载本地目录实现数据持久化:
bash
docker run -d --name my-redis -p 6379:6379 -v /path/on/host/redis-data:/data redis redis-server --appendonly yes/path/on/host/redis-data替换成你mac上一个真实存在的目录路径,用于存放Redis数据快照和AOF文件。redis-server --appendonly yes表示开启AOF持久化。
2.3 项目配置
3.项目使用
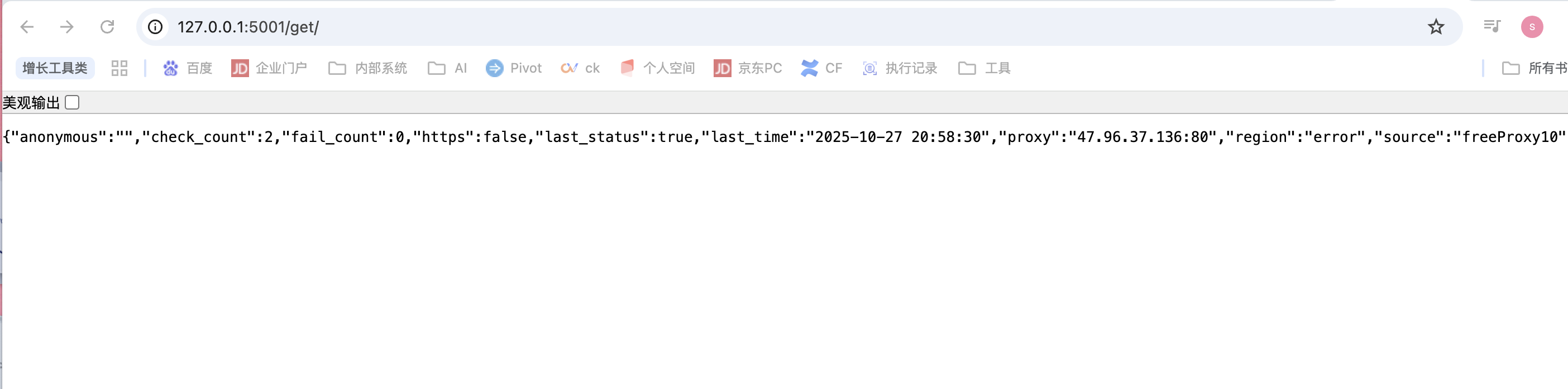
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
# your spider code
def getHtml():
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)})
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy)
return None