引言: 本文用通俗简练的语言又不失细节(自认为doge)地介绍TCP/UDP、HTTP、HTTPs、DNS、CDN、Websocket和SSE等。本文面向求职面试人群,比较全面的归纳了面试中计算机网络涵盖的面试点,你可以结合本文自行拓展深度和广度。如果你准备时间不够,更加推荐你看这篇文章! 如果错误或侵权之处欢迎指正和联系我。
一、OSI 七层模型
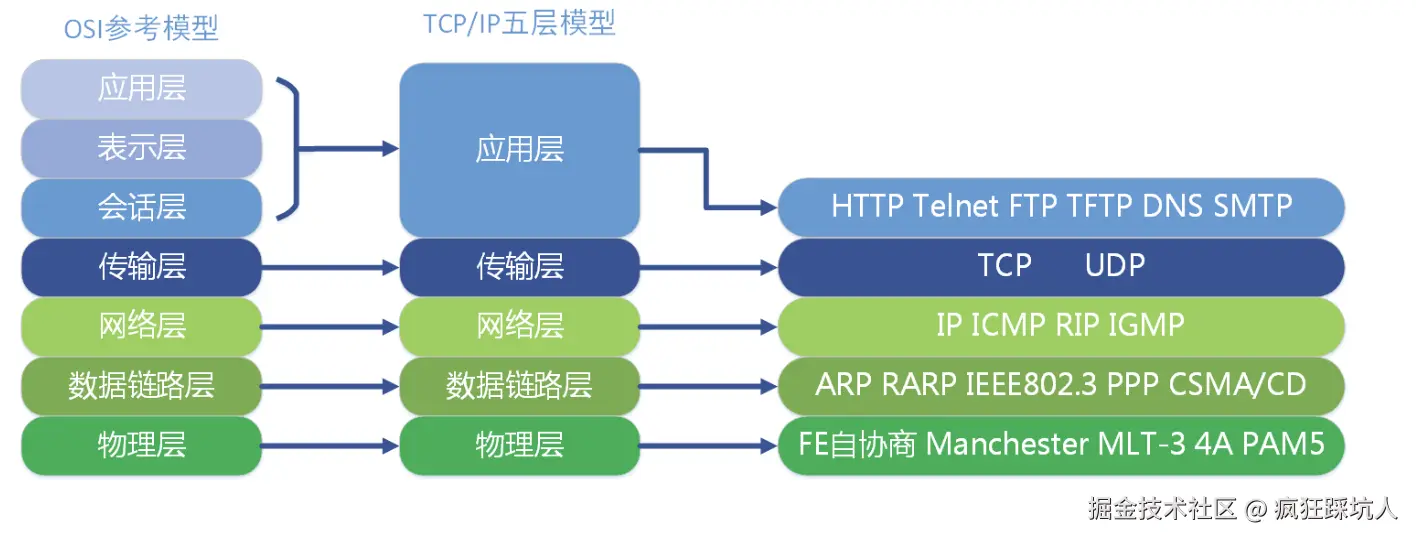
计算机网络的7层模型,也称为OSI七层参考模型 ,是一个概念框架,它将网络通信功能划分为七个抽象层,从下到上分别是:物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。 在实际应用中,通常抽象为5层模型,如下图所示:
二、TCP和UDP
TCP和UDP的区别
1.总体
- TCP是基于连接的可靠的传输协议
- UDP是不基于连接的不可靠传输协议
2.报文头
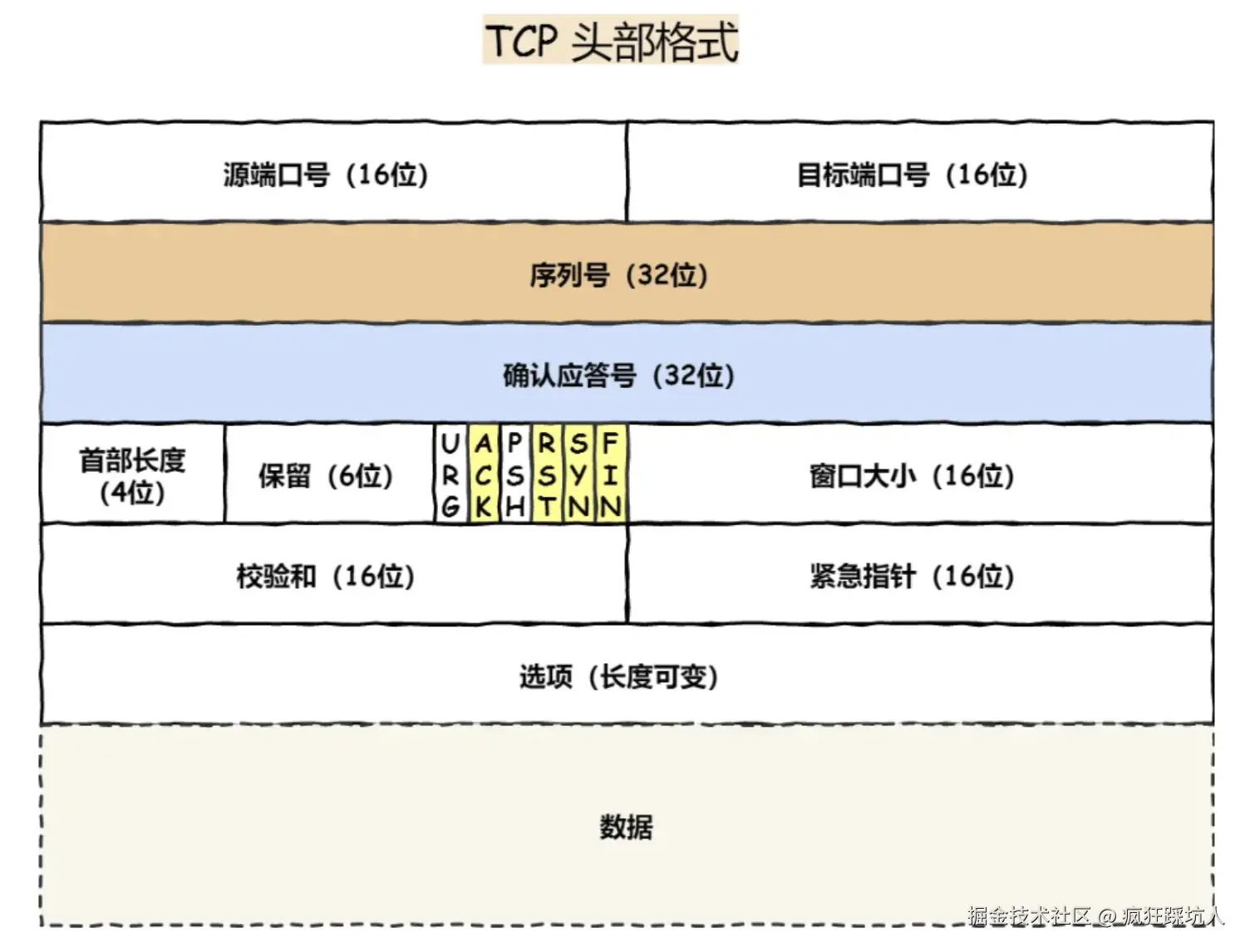
- TCP报文头20个字节,除了端口、校验和字段,还有seqNum, ackNum,标记位和窗口大小等。
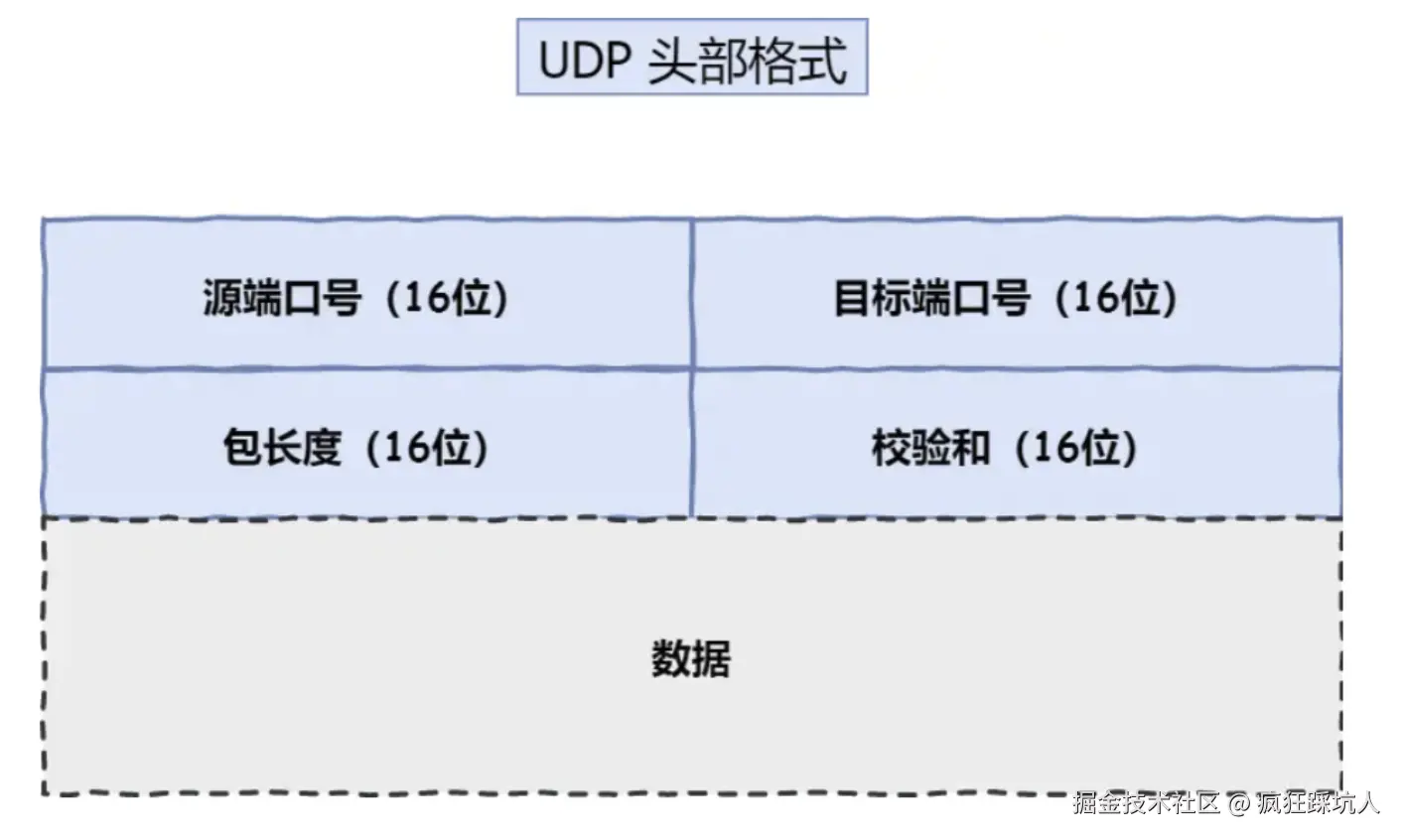
- UDP报文头8个字节,只有端口、包长度和校验和字段。
(图片来自TCP 头格式有哪些?)
3.可靠性
- TCP 拥塞控制、流量控制、重传机制、滑动窗口等机制保证传输质量
- UDP没有
4.双工性
- TCP 是点对点通信 全双工通信
- UDP 支持一对一、一对多、多对一和多对多的交互通信。
TCP 三次握手
流程
(图片来自三次握手过程是怎么样的?)
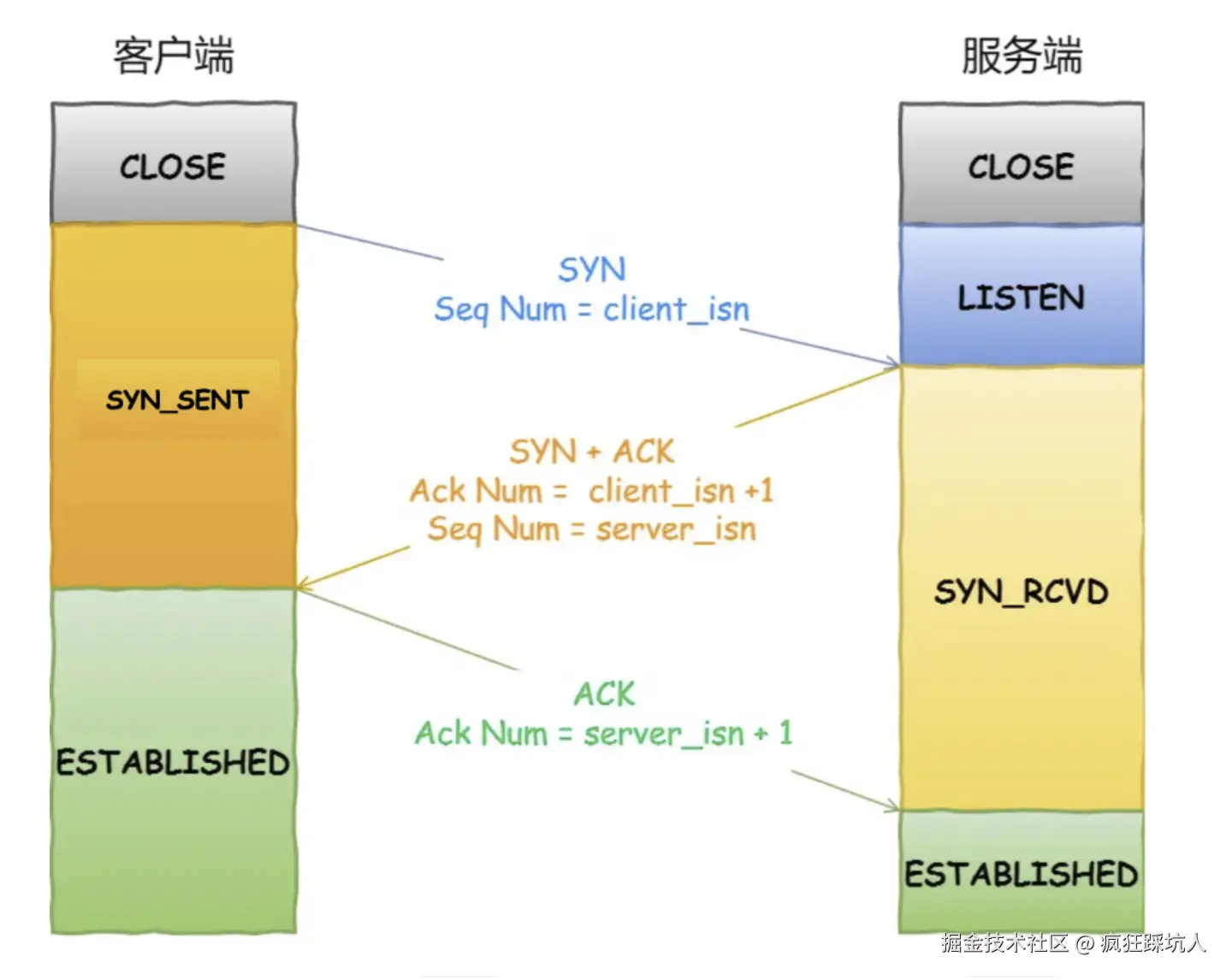
一次握手
客户端会随机初始化序号(client_isn),将此序号置于 TCP 首部的「序列号」字段中,同时把 SYN 标志位置为 1 ,表示 SYN 报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于 SYN-SENT 状态。
二次握手
服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK 标志位置为 1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于 SYN-RCVD 状态。
三次握手
客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部 ACK 标志位置为 1 ,其次「确认应答号」字段填入 server_isn + 1 ,最后把报文发送给服务端,这次报文可以携带客户到服务器的数据,之后客户端处于 ESTABLISHED 状态。
建议自己可以按下面的方式写写记记
1)Client -> Server:
SYN=1, SeqNum=x (client_state='syn_sent')
2)Server -> Client:
SYN=1, ACK=1, SeqNum=y, AckNum=x+1 (server_state='syn_recevied')
3)Client -> Server:
ACK=1, AckNum=y+1 (client_state='established',当Server收到Client的确认应答后server_state='established')
问题1:为什么2次不行?
假设client发送了两次SYN报文(旧SYN报文,新SYN报文)。若旧报文先到,Server收到后发出ACK报文的AckNum和Client预期的不一样(不是新SeqNum+1), Client就会发送一个RST报文取消连接。若新报文先到,Client发送一个ACK报文告诉Server可以建立连接。 由上可以看出3次握手可以阻止历史连接,否则的话Server会先建立连接,客户端没有建立连接,这样造成Server的资源浪费。
b.同步双方初始序列号。
Client发送SYN报文后得到来自Server的ACK报文,说明服务端收到了客户端的序列号;Server发送SYN后得到来自Client的ACK,说明客户端收到了服务端的序列号;这样一来一回,才能保证双方的初始序列号能被可靠的同步
c.3次可以建立可靠连接,就不需要4次
问题2:序列号的作用以及是如何生成的?
序列号能保证数据包不重复、不丢失和按序传输。
生成算法:ISN=M+F。M是时钟,每4ms +1。F是对(源IP,目标IP,源端口,目标端口)的hash值。 如果序列号相同,旧连接的历史报文残留在网络中,接受的一方无法分辨。对于1个TCP连接,序列号的生成大概4个小时就会重复,1个TCP连接一般不会这么久。
问题3:第三次可以携带数据吗?
可以
TCP四次挥手
流程
(图片来自TCP 四次挥手过程是怎样的?)
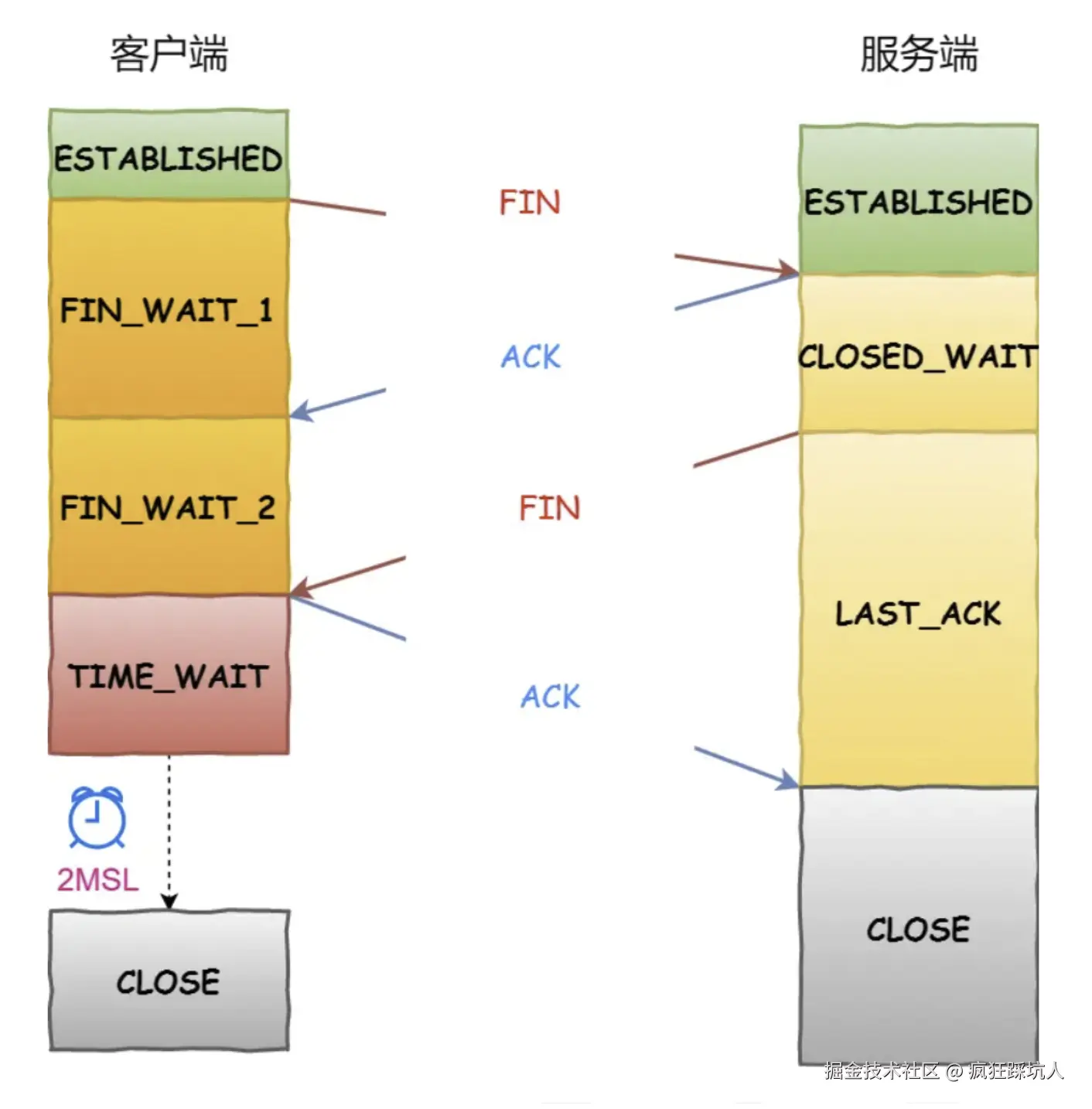
一次挥手
客户端打算关闭连接,此时会发送一个 TCP 首部 FIN 标志位被置为 1 的报文,也即 FIN 报文,之后客户端进入 FIN_WAIT_1 状态。
二次挥手
服务端收到该报文后,就向客户端发送 ACK 应答报文,接着服务端进入 CLOSED_WAIT 状态。
三次挥手
客户端收到服务端的 ACK 应答报文后,之后进入 FIN_WAIT_2 状态。等待服务端处理完数据后,也向客户端发送 FIN 报文,之后服务端进入 LAST_ACK 状态。
四次挥手
- 客户端收到服务端的
FIN报文后,回一个ACK应答报文,之后进入TIME_WAIT状态 - 服务器收到了
ACK应答报文后,就进入了CLOSED状态,至此服务端已经完成连接的关闭。 - 客户端在经过
2MSL一段时间后,自动进入CLOSED状态,至此客户端也完成连接的关闭。
建议自己可以按下面的方式写写记记
1)client -> server: FIN
2)server -> client: ACK
3)server -> client:FIN (此时数据不能再传输)
4)client -> server:ACK (server 关闭)
5)client: 等2MSL (Maximum Segment LifeTime 最大报文存活时间) 后关闭
也可以动手自己画画这个流程图,像下面这样
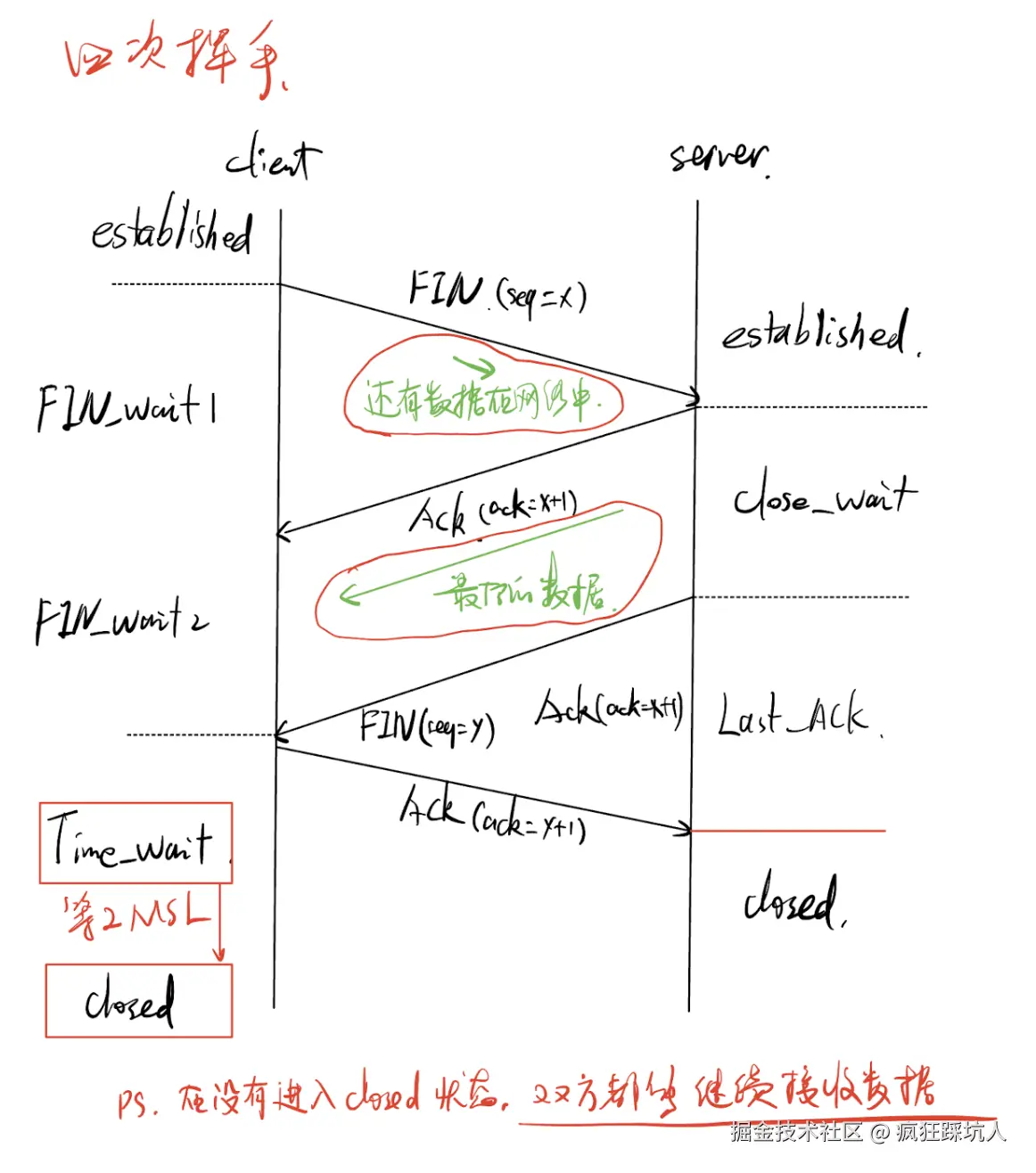
为什么两次不行?
如果server 收到FIN报文就中断,那么server还有数据要传输怎么办? 所以为了能把剩下的数据传完,2次不行。 另外,client发出FIN报文期间,可能还有数据在网络中传输,未到server。如果FIN先到了,server关闭,则数据丢失。
为什么三次不行?
情况一: 第二次握手和第三次握手合并 在server没有数据传输的情况下,是可能合并的,即第二次握手即是FIN报文又是ACK报文。
情况二: 不需要第四次握手 不行。这种情况下server一发出FIN报文就close,无法判断是否丢包-> 无法判断client是否关闭。
为什么要等2MSL?
Client收到FIN发送ACK后进入一个TIME_WAIT ,在TIME_WAIT的期间内如果没有继续收到Server发的FIN说明服务端已经关闭连接(否则服务端会重发FIN)。 从而判断出server已经关闭 -> client可以关闭连接了。
非正常关闭
TCP Keepalive机制是TCP提供的一种检测连接是否存活的可选机制,主要用于:
- 检测对端是否仍然可达
- 防止中间设备因超时断开连接
- 释放已失效连接占用的资源
Keepalive工作原理
- 空闲检测 :当连接空闲时间超过
tcp_keepalive_time(默认2小时)后,开始发送探测包 - 探测间隔 :每隔
tcp_keepalive_intvl(默认75秒)发送一次探测包 - 重试次数 :最多尝试
tcp_keepalive_probes(默认9次)次 - 判定失效:如果所有探测都无响应,则认为连接已断开
基于Keepalive机制,如果TCP连接的一方非正常关闭后,另一方会在一定时机发送探测报文来确定对方是否还"活着"。如果对方已关闭,则关闭己方的TCP连接,释放资源。
TCP 可靠性传输
总的来说,TCP通过序列号机制、校验和、重传机制、流量控制和拥塞控制保证了TCP。
序列号机制
通过Sequence Number和ACK Number给发送数据编号,通信过程中接收方就能知道那个包丢了,那个包接受了。
校验和
TCP包的伪首部有一个校验和字段,能对TCP的首部和数据进行校验,判断数据是否在传输时出错了。
重传机制
超时重传
超过一定时间,说明包丢失了,重传(这个"一定时间"是采样得到的,大于一个往返时延)。
快速重传
连续收到三个重复的ACK报文、就立即重传。根据ACK Number立即重传包,不等待超时机制触发了。
SACK机制
前面有个一个报文丢失了,收到重复的ACK number,快速重新哪些报文呢? 所以ACK报文还要告诉对方ACK number之后哪些报文已接受了,这样发送方对于已经接受到的报文就不发了(不是一股脑从ACK number序号后全发)。
流量控制
定义:针对接收方的接受速度,调整发送速度,减少包丢失。 TCP的头部有一个Window字段。接收方在响应报文中设置Window字段可以调整发送方的 send window大小。
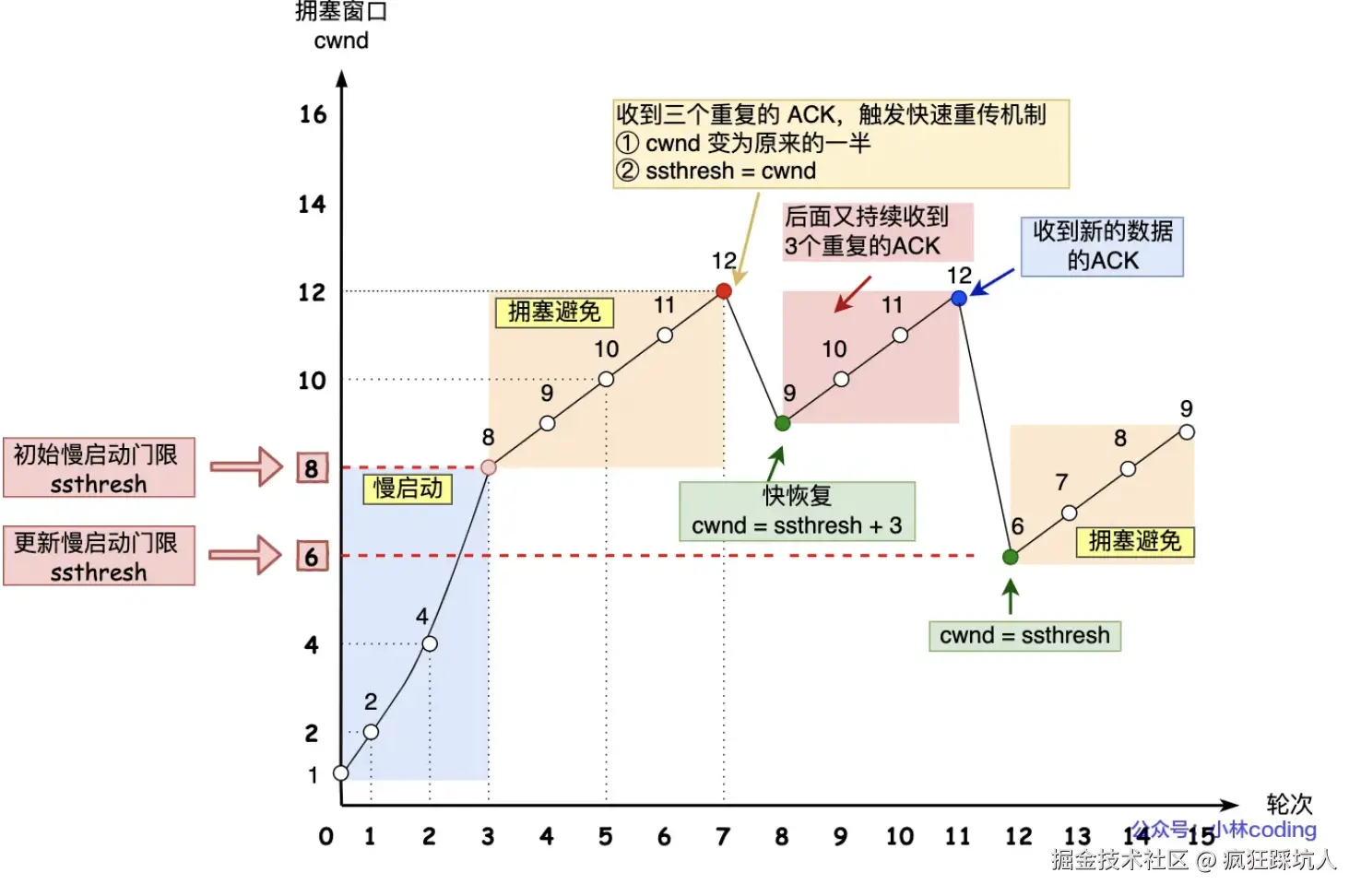
拥塞控制
定义:为了避免网络拥塞,导致丢包甚至网络瘫痪问题,从而设计一些算法来控制发送端的速度。
有四个算法:慢启动算法、避免拥塞算法、快速恢复、拥塞算法 1)刚建立连接:「慢启动算法」(拥塞窗口大小cwnd) 指数增长 2)增长到阈值时:「避免拥塞算法」开始线性增长 3)出现快速重传:「快速恢复算法」cwnd为原来的一半+3,阈值为原来cwnd的一半。 4)出现超时重传:「拥塞算法」cwnd减半,阈值为原来的cwnd的一半。
P.S. swnd = min(cwnd, rwnd)
swnd: send window;cwnd: crowd window;rwnd: receive window;
(图片来自「小林coding」)
【参考】
TCP 三次握手与四次挥手面试题------小林coding
TCP 重传、滑动窗口、流量控制、拥塞控制------小林coding
三、HTTP
HTTP 1.1与1.0的区别
区别:
- 长连接 :HTTP 1.1 默认使用持久连接(
Connection: keep-alive),同一 TCP 连接可复用多个请求/响应;HTTP/1.0 默认每次请求都新建连接(最重要的!)。 - 更完善的缓存机制:
Cache-Control、ETag/If-None-Match等,更准确和精细化控制缓存与节省带宽。 - 升级与代理:
Connection:Upgrade、Via等,明确协议升级和代理行为。 - 更多方法
OPTIONS、PUT、DELETE、TRACE、CONNECT(PATCH为后续 RFC 引入,并非 1.1 核心)。
(下面的区别了解即可)
- 虚拟主机支持:
Host头在 1.1 中是必需字段,让同一 IP 上托管多个域名成为主流。 - 传输能力增强:支持分块传输(
Transfer-Encoding: chunked),可在未知内容长度时流式发送;支持100-continue协商。 - 断点续传与部分内容:
Range/Accept-Ranges及206 Partial Content,有效减少重传。
HTTP 1.1 缺点
- 队头阻塞:1个TCP就是1个管道,同一个TCP内必须等前面一个请求完成,才能发送后一个请求(
请求响应等待模型)。 - HTTP头大且重复发送:头部没有压缩,头部冗余信息(重复的头部信息)
- 浏览器对TCP连接数量限制:Chrome 最多允许对同一个 Host(域名) 建立六个 TCP 连接,不同的浏览器有一些区别,这就意味着并发量受限。
假设我们还处在 HTTP/1.1 时代,那个时候没有多路传输,当浏览器拿到一个有几十张图片的网页该怎么办呢?肯定不能只开一个 TCP 连接顺序下载,那样用户肯定等的很难受,但是如果每个图片都开一个 TCP 连接发 HTTP 请求,那电脑或者服务器都可能受不了,要是有 1000 张图片的话总不能开 1000 个TCP 连接吧,你的电脑同意 NAT 也不一定会同意。 所以,浏览器对同一个host的TCP连接数量有限制!
HTTP 2 与1.1的区别
- 头部压缩
- 多路复用
- 服务端推送
头部压缩
Http1.x仅针对HTTP的body部分进行压缩,通过Content-Encoding来规定如何编码压缩。但并未对请求头进行压缩。而Http2开始对头部字段(包括状态行)进行压缩------使用了HPACK算法。
用通俗的语言解释下就是,头部压缩需要在支持 HTTP/2 的浏览器和服务端之间:
- 维护一份相同的
静态字典(Static Table),包含常见的头部名称,以及特别常见的头部名称与值的组合; - 维护一份相同的
动态字典(Dynamic Table),可以动态地添加内容; - 支持基于静态哈夫曼码表的哈夫曼编码(Huffman Coding);
P.S. Huffman编码是基于Huffman 树------一种 「最优二叉树」(其带权路径长度WPL最小)构建的编码,作用是将字符/数字用一种变长编码表示,频率高的字符串所用的编码越短,反之所用编码越长,从而起到压缩最终的字符串的效果。
静态字典 保存了HTTP中常见的请求头name-value(有的只有name), HTTP/2 中的静态字典如下(以下只截取了部分,完整表格在这里):
| Index | Header Name | Header Value |
|---|---|---|
| 1 | :authority | |
| 2 | :method | GET |
| 3 | :method | POST |
| 4 | :path | / |
| 5 | :path | /index.html |
| 6 | :scheme | http |
| 7 | :scheme | https |
| 8 | :status | 200 |
| ... | ... | ... |
| 32 | cookie | |
| ... | ... | ... |
| 60 | via | |
| 61 | www-authenticate | |
注意 :新条目总是插入到索引62的位置,旧条目会被向下推。所以动态表的索引是从62开始向上增长的
动态字典 是在一个HTTP2连接(1个TCP连接)生命周期内的,当一个HTTP2连接结束就会重置动态字典(情况),动态字典初始情况是空的。
| 索引 (Index) | 头部名 (Header Name) | 头部值 (Header Value) | 说明 |
|---|---|---|---|
| 1-61 | ... | ... | 静态表(固定不变) |
| 62 | (空) | (空) | 动态表起始边界(空) |
具体的交互过程
(图片来自 Google 的性能专家 Ilya Grigorik 在 Velocity 2015 • SC 会议中分享的「HTTP/2 is here, let's optimize!」)
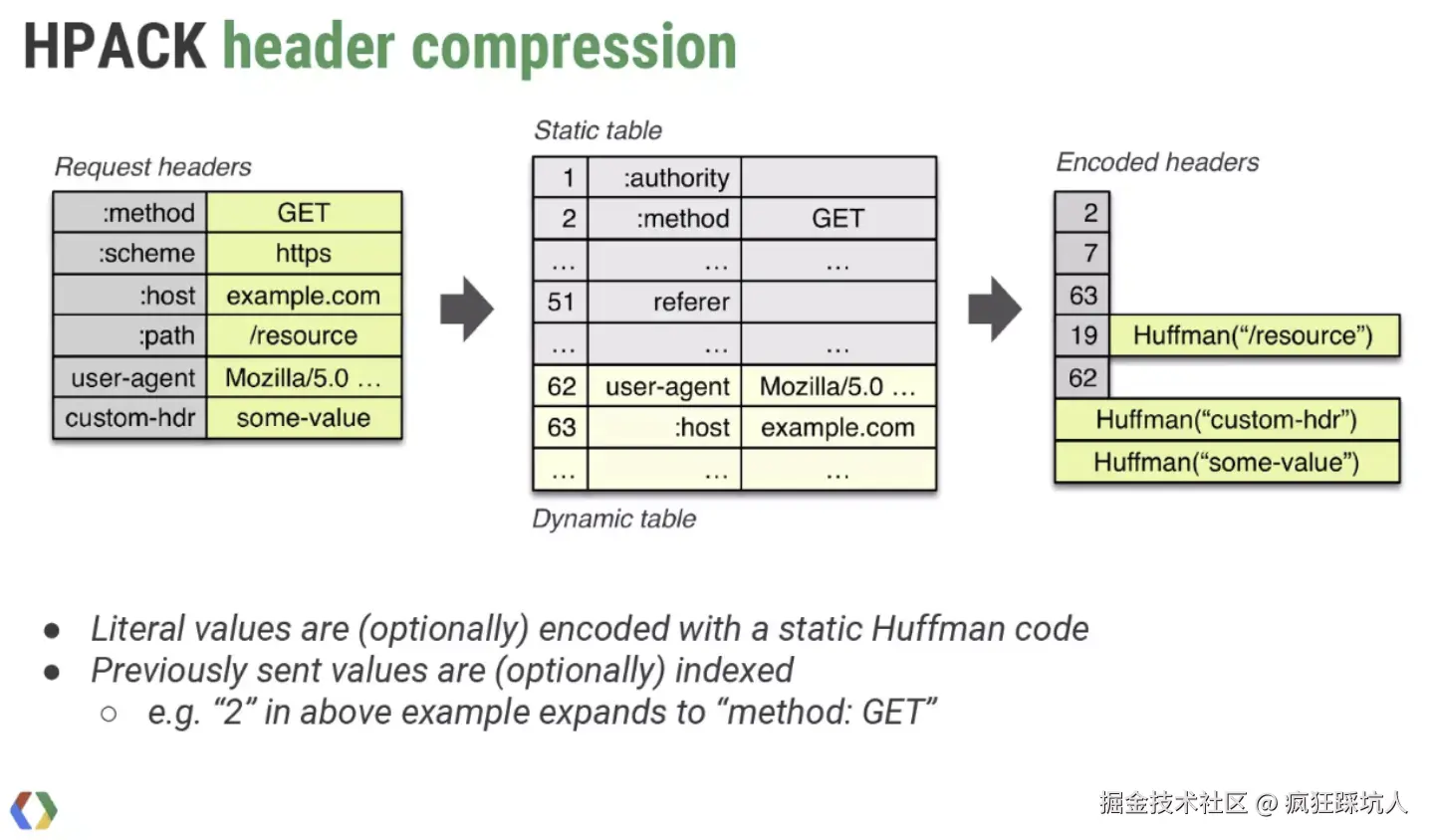
1.客户端第一次请求的头
1.1. header name-value出现在(静态)字典中的,可以使用(静态)字典中的Index进行编码。
1.2. 对于只有header name出现在静态字典则更新客户端的动态字典 ,但此时编码的name使用Index,而value继续使用Huffman编码的字符串(如上图的19 Huffman("/resource"))。
1.3. 如果连header name都没有出现在静态字典,则对name和value都采用Huffman编码。(如上图的 Huffman("custom-hdr"))
2.当服务端收到这个请求头,对于静态字典/动态字典中没有的头部字段分两种情况处理
2.1.对于只有header name出现在字典中的,更新动态字典
2.2对于header name-value都没出现在字典中的,更新动态字典 (此时服务端已经同步了客户端的动态字典,服务端响应时,动态字典内name-value会用Index进行编码)
3.当客户端收到响应头,也会和第2步一样处理,更新动态字典(至此,客户端和服务端的动态字典同步了)
注意:
- 客户端/服务端动态字典的同步是在不断请求-响应中逐步同步的,而不是一次性同步的。HTTP/2头部压缩高效的关键------通过在多次请求间复用和累积动态字典,可以大幅减少后续请求的头部大小。
动态字典的生命周期和一个 HTTP/2 连接 (通常对应一个 TCP 连接)一致。 当 TCP/HTTP2 连接断开时,动态字典也随之失效(清空)。(所以这也是为什么上述第3步客户端收到响应头还要继续更新动态字典)
最终效果:能把Http1.x头部传输的长度压缩大概一半以上,效果非常好。
多路复用
三个概念
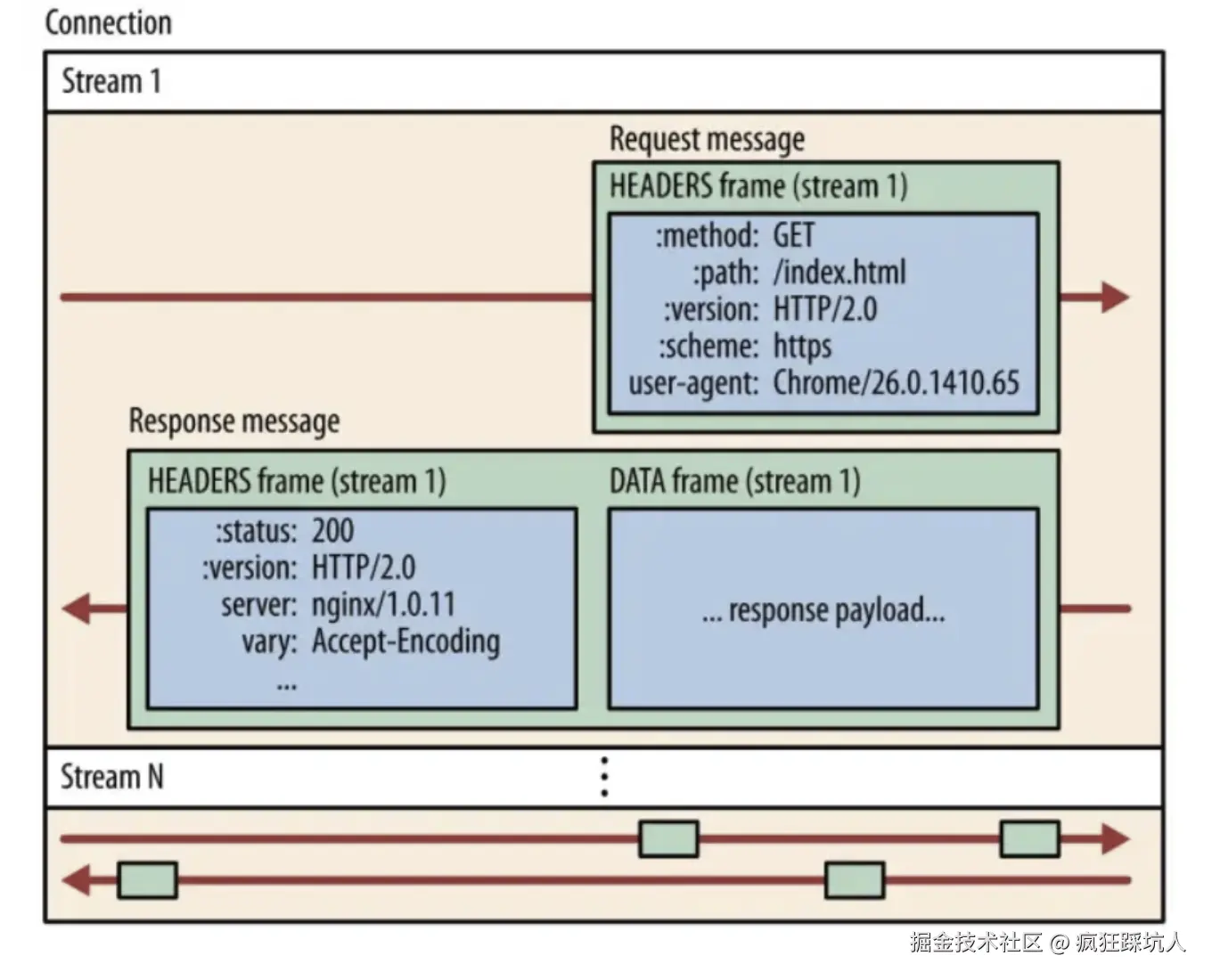
Stream:
- HTTP2可以在1个TCP的基础上划分多个stream(应用层的一个虚拟通道)。
- 每个stream都有一个编号streamID,客户端建立的streamID是奇数,服务端建立的streamID是偶数(发请求的时候建立,服务端建立streamID是为了实现server push)。
Message:对应1个请求或1个响应。Frame:HTTP2中最小通信数据单元,1个Message被拆分成多个Frame传输。
多路复用原理:
- 1个Stream只用来传输1次请求+1次响应,使用一个Stream(标记StreamID)发送完请求Frame完后,会使用同样的StreamID的Stream将响应Frame返回。streamID不能复用(请求响应结束后,下一个请求需要使用新的Stream)。可配置Stream编号的上限,比如128个,当编号用完,则关闭TCP连接。
- 不同的请求用了不同的Stream, Stream之间Message的传输是并发的,所以http请求时并发的(就是说stream之间的帧是可以乱序发的,而同一个stream里面的帧是串行的)。
- 匹配帧:帧头有streamID, 从而判断Frame属于哪一个stream
下图形象描述了Stream、Message和Frame的关系以及并发的原理:
下图描述了多路复用后的效果:

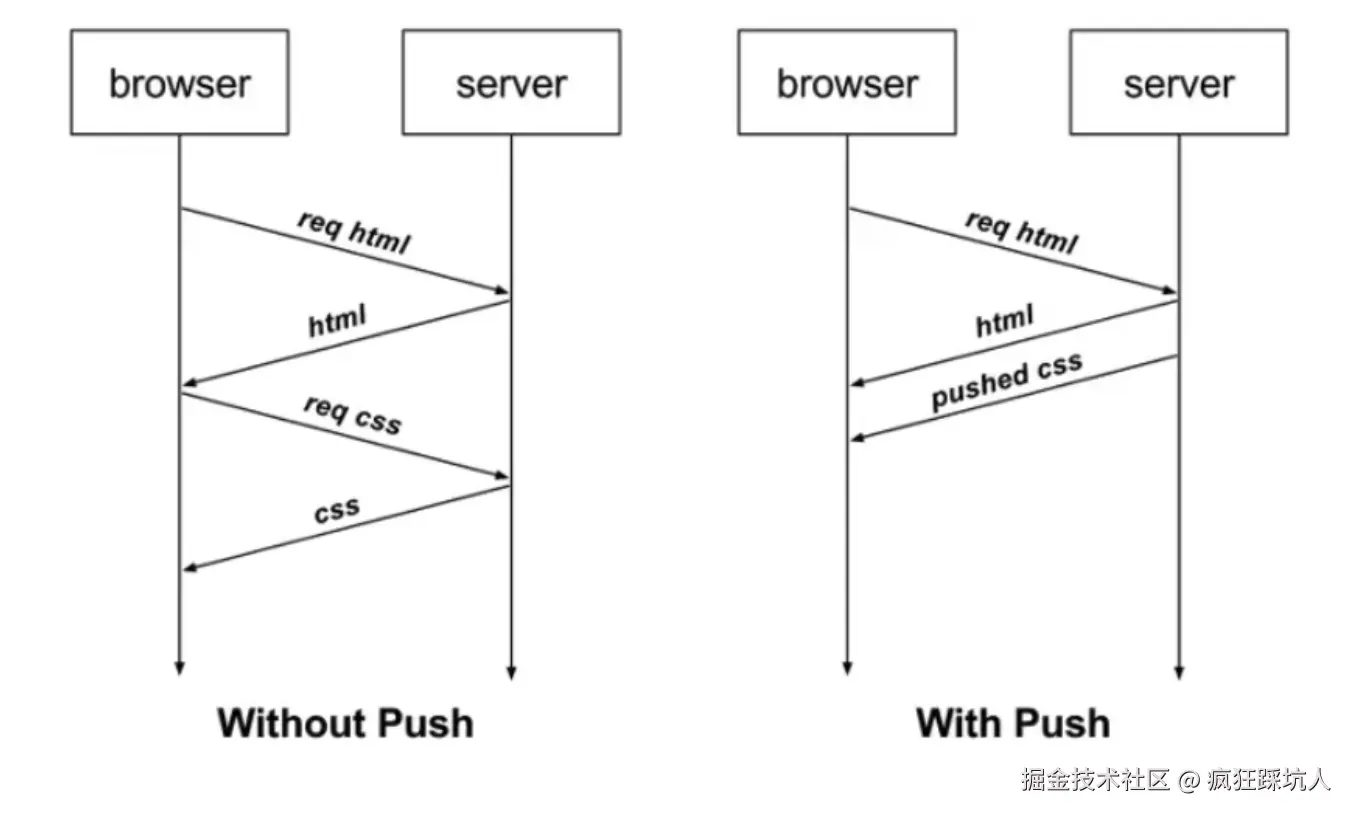
服务端推送
服务端推送主要使用于Get请求(用于优化静态资源的访问):
场景 :访问html时,先请求html再请求css,发生了两次请求,有传播延迟,实际可以合并为一次请求。
实现:当客户端访问服务端的某个资源时,服务端除了响应第一个资源,还主动推送其他资源。
协商缓存和强缓存
- Http缓存包括协商缓存和强缓存,通过请求头和响应头完成对缓存策略的执行。
- 强缓存: 将资源存在浏览器/客户端本地,下次访问url时能直接使用本地的缓存资源。
- 协商缓存:将资源存在浏览器/客户端本地,下次访问url需要发请求给服务端判断本地的资源是否有效,如果服务端响应说有效,就继续使用本地资源。
http1.0时代
1.基于Expires头字段实现强缓存,基于Last-Modified/If-Modified-Since头字段实现协商缓存。
2.Last-Modified是资源上次(在服务器上)被修改的时间,通过修改时间是否变化来判断资源是否过期。
http1.1时代
1、1.0时代的Expires,Last-Modified/If-Modified-Since这些头字段可以继续使用,但增加了新字段(Cache-Control, Etag/If-None-Match)来控制:
- 基于
Cache-Control头字段的max-age属性实现强缓存。(max-age的优先级高于Expires) - 基于
Etag/If-None-Match头实现协商缓存。 (If-None-Match优先级高于If-Modified-Since,即如果请求头有If-None-Match并和服务器请求,则会忽略If-Modified-Since)
2、Etag是资源内容的一个hash标志,一般是基于资源位文件的名称/大小等元数据计算出来的一个hash值。不依据文件内容计算hash值是因为这个计算量太大,并且可以服务端可以缓存这个hash值,并不是每次响应请求都要计算一次.
缓存流程
强缓存:
1.第一次请求url得到响应如下,下载并缓存该资源。可以看到Cache-Control的max-age设置了一个时间(单位秒),即资源的保鲜期。
http
HTTP/1.1 200 OK
Content-Type: application/javascript
Content-Length: 1024
Cache-Control: max-age=604800
ETag: W/"5c2d1a37a1e6ceecbad3deeff0fd68a5"
last-modified: Thu, 10 Jul 2025 02:53:06 GMT2.第二次访问该url时:当超过max-age保鲜期,则会重新发送请求,否则从内存/磁盘中读取响应内容。
协商缓存: 1.第一次请求url的响应中有Etag头字段的。 2.当强缓存失效(超过max-age保鲜期),则访问该资源时会将向该资源发起请求:把资源之前响应中的Etag值放入请求头的If-None-Match字段
http
GET /resources/xx.js HTTP/1.1
Host: example.com
Accept: application/javascript
Connection: keep-alive
If-None-Match: "5c2d1a37a1e6ceecbad3deeff0fd68a5"3.服务器会判断If-None-Match和资源的hash值是否相同,相同则返回304,否则返回200。 4.请求如果返回304(not modified,响应头如下)说明资源未修改,可以继续使用本地缓存,并且刷新保鲜期(根据响应的max-age重新计算)和ETag;否则在响应的body中加入资源的内容返回给客户端。
http
HTTP/1.1 304 OK
Content-Type: application/javascript
Content-Length: 1024
Cache-Control: max-age=604800
ETag: W/"5c2d1a37a1e6ceecbad3deeff0fd68a5"
last-modified: Thu, 10 Jul 2025 02:53:06 GMTP.S 如果是基于Last-Modified的协商缓存,原理也差不多,只是把字段换一下,请求会携带上次响应的Last-Modified放在请求头字段If-Modified-Since中,然后判断响应是否为304。
相关问题
1、Cache-Control头字段有哪些属性?
- public: 允许响应被任何缓存存储,包括浏览器和中间代理服务器。
- private: 只允许响应被单个用户的浏览器缓存,不能被中间代理服务器(比如cdn服务器)存储。
- no-cache: 禁止强缓存。这并不意味着不缓存,而是意味着在使用缓存之前必须进行验证(要协商缓存)。
- no-store: 禁止任何缓存存储请求或响应数据。
- max-age=seconds: 指定从请求时间开始,缓存可被视为新鲜的秒数。
2、Etag解决了Last-Modified的哪些问题?
Last-Modified/If-Modified-Since的缺陷:
- 只能精确到秒,如果文件是毫秒级别的更新则
Last-Modified不变; - 文件内容不一定变化,但修改时间变了;
- 负载均衡、分布式的情况下,资源的
Last-Modified不一致。
但 建议应该保留Last-Modified字段: 有些代理服务器或CDN会去掉/修改Etag或者不支持If-None-Match,所以需要Last-Modified来兜底。或一些要考虑速度的场景Last-Modified的生成比Etag快。
HTTP状态码
RFC 规定 HTTP 的状态码为三位数,被分为五类:
- 1xx: 表示目前是协议处理的中间状态,还需要后续操作。 比如 100 continue;101切换协议(http切换到websocket);
- 2xx: 表示成功状态。
- 3xx: 重定向状态,资源位置发生变动,需要重新请求。 比如 301表示永久重定向;302表示临时重定向;304 Not Modified 表示资源未修改;
- 4xx: 请求报文有误。400表示错误请求;401表示认证; 比如 403表示未授权;404 not Found;405表示方法不允许;
- 5xx: 服务器端发生错误。
GET和POST的区别
| 对比项 | GET | POST |
|---|---|---|
| 参数位置 | 通过 URL 传参(?key=value) |
放在请求体(Request Body)中 |
| 是否有请求体 | 无请求体(理论上是可以有,但实现上不带请求体) | 有请求体 |
| 安全性 | 参数暴露在 URL 中,不安全 | 参数在请求体中,相对安全(但仍需 HTTPS) |
| 幂等性 | 幂等(同样请求多次结果相同) | 非幂等(多次提交可能造成重复数据) |
| 缓存 | 默认可被缓存(浏览器会缓存 GET 请求) | 默认不会被缓存 |
| 长度限制 | URL 有长度限制(约 2KB~8KB,依浏览器/服务器不同) | 理论上无限制 |
| 编码 | 会被URL 编码,中文空格'/'等非ASCII会被转义。 | 支持多种编码,比如: multipart/form-data:二进制application/x-www-form-urlencoded:键值对文本 |
【参考】
(建议精读)HTTP灵魂之问,巩固你的 HTTP 知识体系
HTTP/2 头部压缩技术介绍
HTTP/2 牛逼在哪?
四、HTTPs
基础概念
TLS(Transport Layer Security)即传输层安全协议,以前也叫SSL。它是介于应用层和传输层之间的一层协议,起到加密作用。
对称秘钥加密: 双方用同一个秘钥来加密和解密数据。比如AES(Advance Encrypt Standard), SHA-256。
非对称加密算法(公钥私钥):私钥保存在服务器,公钥明文的形式发给客户端。私钥加密的只有公钥能解,公钥加密的只有私钥能解。比如 RSA加密算法 。
对比:对称加密更快,非对称加密更安全(对称加密,秘钥泄漏的风险较大)。
数字证书 包含了如下信息:
- 持有者信息 (域名、国家)
- CA信息 (颁发机构、非对称加密算法)
- 证书有效期
- 公钥 (自己服务器生成的公钥私钥中的公钥)
- 数字签名 (这个是对上述内容加密了的密文,叫签名)
证书是明文传输的,通过签名可以校验证书是否被篡改。
CA: 数字证书权威机构,作用:颁发数字证书。(数字证书签名使用了CA的私钥,浏览器保存了CA的公钥,因此浏览器可以验证数字签名的正确性)
TLS 四次握手
(图片来自「技术蛋老师」的这期视频)
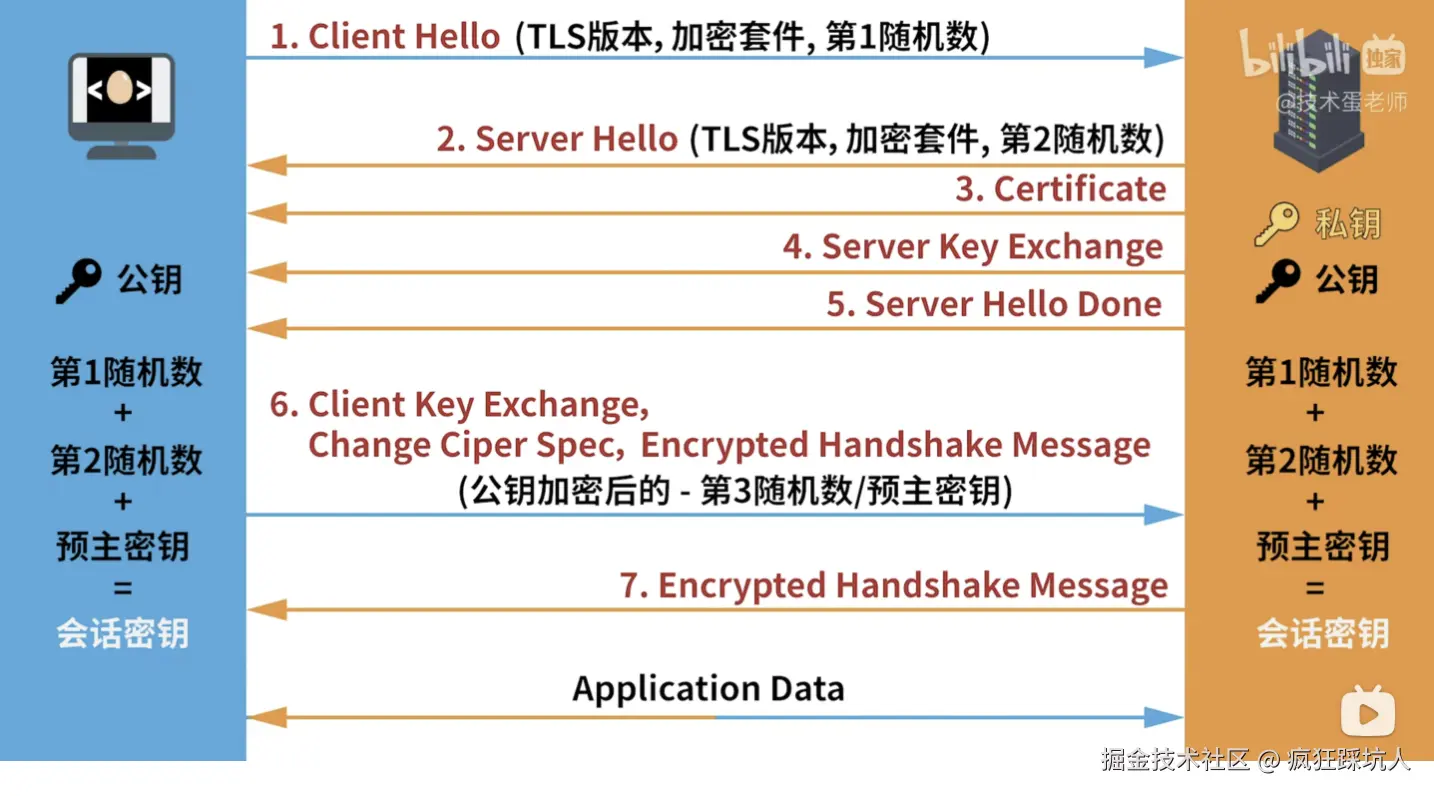
流程:
1、Client -> Server :
- 告知客户端的TLS版本,加密套件,第1随机数。
2、Server -> Client:
- Server Hello: 确定TSL版本,选择的加密算法,第2随机数。
- 发送数字证书(包含服务端生成的公钥)
3、Client -> Server:
- 客户端通过内置的CA机构的公钥 验证数字证书是否有效,则认为公钥是安全的。使用公钥加密
预主密钥(即第3个随机数),发送给服务端。 - 此时客户端和服务端都是通过同样的方式来生成
会话密钥:第1随机数+第2随机数+预主密钥。
4、Server -> Client:
- 服务端使用私钥(之前生成的公钥私钥对)解密,拿到
预主密钥,生成会话密钥。 - 回复确认。
之后,采用会话密钥进行加密通信。
为什么要CA 签名?
保证证书不被篡改/伪造,即公钥是安全可用的。 数字证书包含了公钥,并且被CA机构的私钥做了签名,而浏览器内置了各CA机构的公钥,可以用来验签(也就是能解密)这个签名。如果验签成功,说明这个证书是可信任的,确实是CA签发的,不是被第三方伪造的。
非对称加密 在该过程的作用?
用来安全的传输「预主密钥」,换句话说就是用来保证安全下发「会话密钥」。
为什么会话过程中 使用对称加密?
对称加密速度快,用于会话通信的加密效率高。
随机数的作用?
使用随机数来生成秘钥,保证了会话密钥的唯一性和不确定性,更安全。
HTTPS和HTTP的区别
| 对比维度 | HTTP | HTTPS |
|---|---|---|
| 协议安全性 | 明文传输,数据容易被窃听、篡改或中间人攻击 | 通过SSL/TLS协议对数据进行加密,确保数据的保密性和完整性 |
| 默认端口 | 80 | 443 |
| 证书要求 | 不需要证书 | 需要向可信的证书颁发机构(CA)申请SSL/TLS证书,以验证服务器身份 |
| 性能与速度 | 无加密开销,连接建立快 | 加密/解密会消耗额外计算资源,连接建立需更多步骤,但现代技术(如TLS 1.3)已大幅缩小差距 |
相关问题
1、HTTPS一定绝对安全吗?
不一定。虽然 HTTPS 提供了加密和身份验证来保护传输中的数据安全,但它并非绝对安全,存在被抓包和中间人攻击的风险:
- 比如你主动信任某个抓包工具,就构造出一个"中间人"进行解密传输,抓包工具可以恶意获取你的敏感信息。
- 如果你电脑中病毒,被植入恶意的中间人根证书,此时是你客户端不安全导致的中间人攻击;
- 比如
恶意wifi这种作为"中间人服务器"可以给你下发假「公钥证书」,导致后续通信可以被解密、泄漏。但是要发生这种场景是有前提的,前提是用户点击接受了中间人服务器的证书。
2、HTTPS如何抓包?
- 可以使用
wireshake和whistle这类代理工具进行抓包(让本地HTTP请求发到本地的代理服务器,然后由代理服务器发出去)。 - 对于HTTPS而言就需要安装代理工具提供的根证书(放到电脑/手机的指定位置,让操作系统内能访问)
- 比如:whistle------抓包https请求的解决办法
【参考】
视频:HTTPS是什么?加密原理和证书。SSL/TLS握手过程
HTTPS 一定是安全的吗?
五、DNS
DNS是什么?
DNS( D omain N ame System)即域名系统,是一种应用层的协议和分布式数据库服务的结合。DNS协议告诉网络如何通过域名查询出IP,而DNS服务器则是一个分布式数据库,存放了域名到IP的映射。
域名 www.example.com实际可以看着www.example.com.(后面还有个.)
.就是根域名。.com就是顶级域名(TLD)。还有诸如.net,.org等等。example.com就是一级域名。基于这个一级域名可以划分二级、三级域名。比如www就是www.example.com的二级域名、map就是map.baidu.com的二级域名。
IP 连入网络的计算机都具有一个IP地址,作为通信的地址,它由4个数组成(总共32位),每个数是0~255。比如下面的IP地址:
220.181.7.203由于IP不便于记忆,所以出现了域名来指代IP,当然实际DNS中域名:IP并不一定是1:1.
| 对应关系 | 描述 | 主要目的 |
|---|---|---|
| 一个域名 → 多个IP | 在DNS中为同一域名配置多条A记录(IPv4),每条记录指向一个不同的服务器IP地址。 | 实现负载均衡与高可用性 |
| 多个域名 → 一个IP | 在DNS中将不同的域名解析到同一个IP地址,服务器根据HTTP请求头中的域名信息来提供不同的网站内容。 | 节约IP资源,降低托管成本(虚拟主机) |
| 一个域名 → 一个IP | 传统的简单映射关系,通常用于对独立性或安全性有特殊要求的服务。 | 简化管理,满足特定需求 |
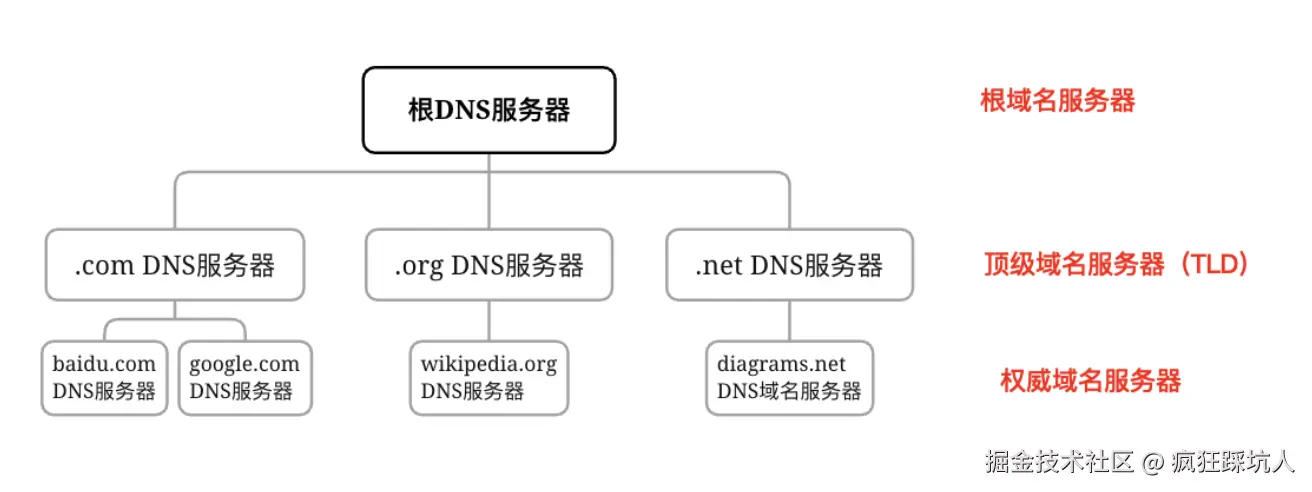
DNS服务器的类型和层次结构
DNS服务器是具有层次结构的,分为根域名服务、顶级域名服务器、权威域名服务器,分层结构如下图:
DNS 解析的过程
DNS两种查询方案
- 递归式查询
- 迭代式查询
递归式查询
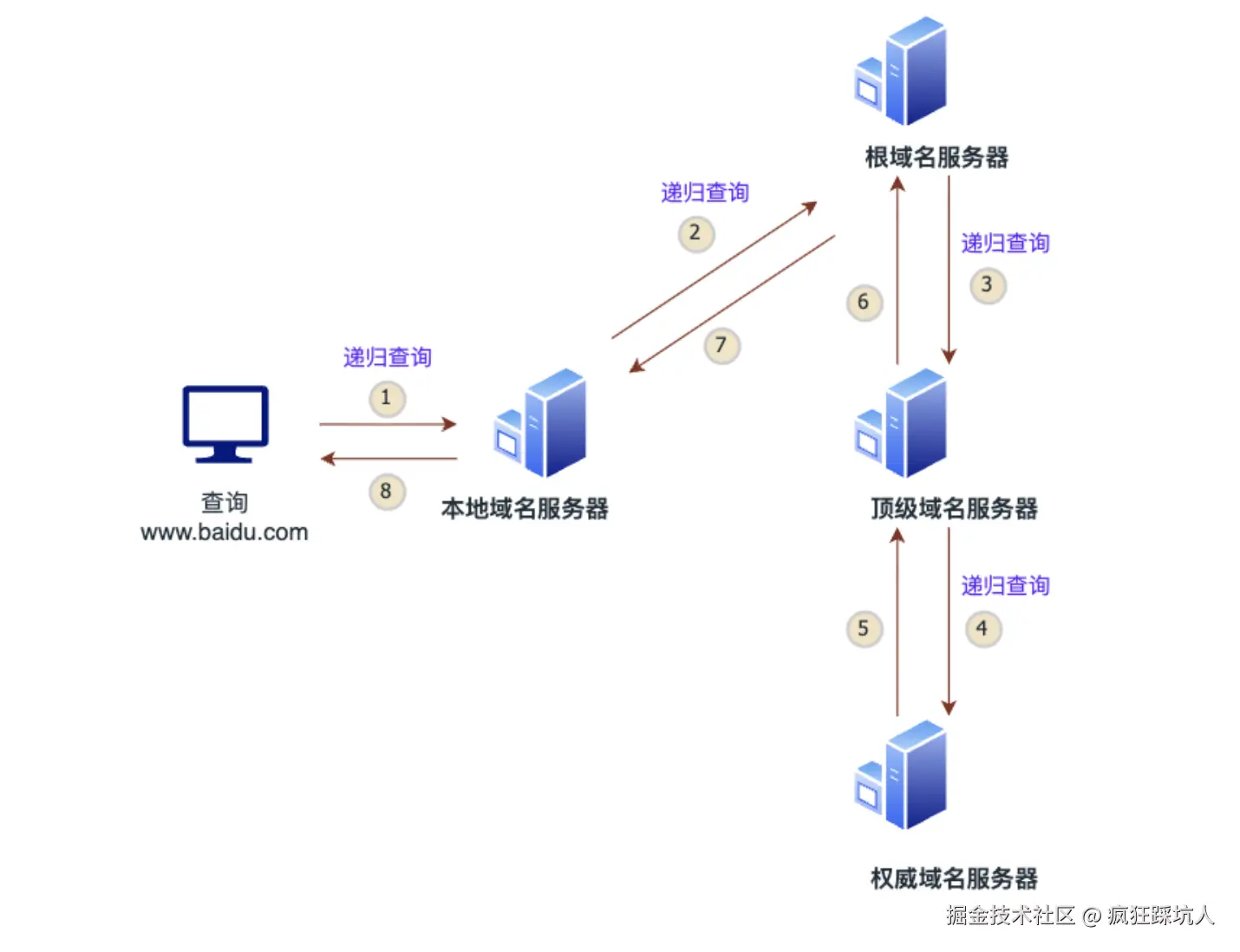
- 用户请求 :用户在自己的电脑上输入网址
www.baidu.com,电脑首先向本地域名服务器 (通常由ISP提供)发起一个递归查询请求。 - 查询根服务器 :本地域名服务器收到请求后,向DNS体系中的根域名服务器发起查询。
- 返回顶级域地址 :根域名服务器不直接提供具体IP,但它知道顶级域(如
.com)的信息。它告诉本地域名服务器:"我不知道www.baidu.com的IP,但我告诉你负责.com域的顶级域名服务器的地址,你去问它。" - 查询顶级域服务器 :本地域名服务器根据收到的地址,向 .com 顶级域名服务器发起查询。
- 返回权威服务器地址 :.com 顶级域名服务器回复本地域名服务器:"我不知道
www.baidu.com的具体IP,但我告诉你负责baidu.com这个域的权威域名服务器的地址,你去问它。" - 查询权威服务器 :本地域名服务器再向管理
baidu.com域的权威域名服务器发起查询。 - 返回最终IP地址 :权威域名服务器查询自己的记录,确认了
www.baidu.com对应的IP地址,并将这个最终的IP地址返回给本地域名服务器。 - 响应用户 :本地域名服务器终于拿到了目标IP地址,它将这个IP地址返回给用户的电脑。至此,电脑获得了IP,就可以开始与百度服务器建立连接了。
简单总结:整个过程就像问路,本地DNS服务器替你一层一层地去问(根服务器->顶级域服务器->权威服务器),直到拿到最终地址(IP)后回来告诉你。
迭代式查询
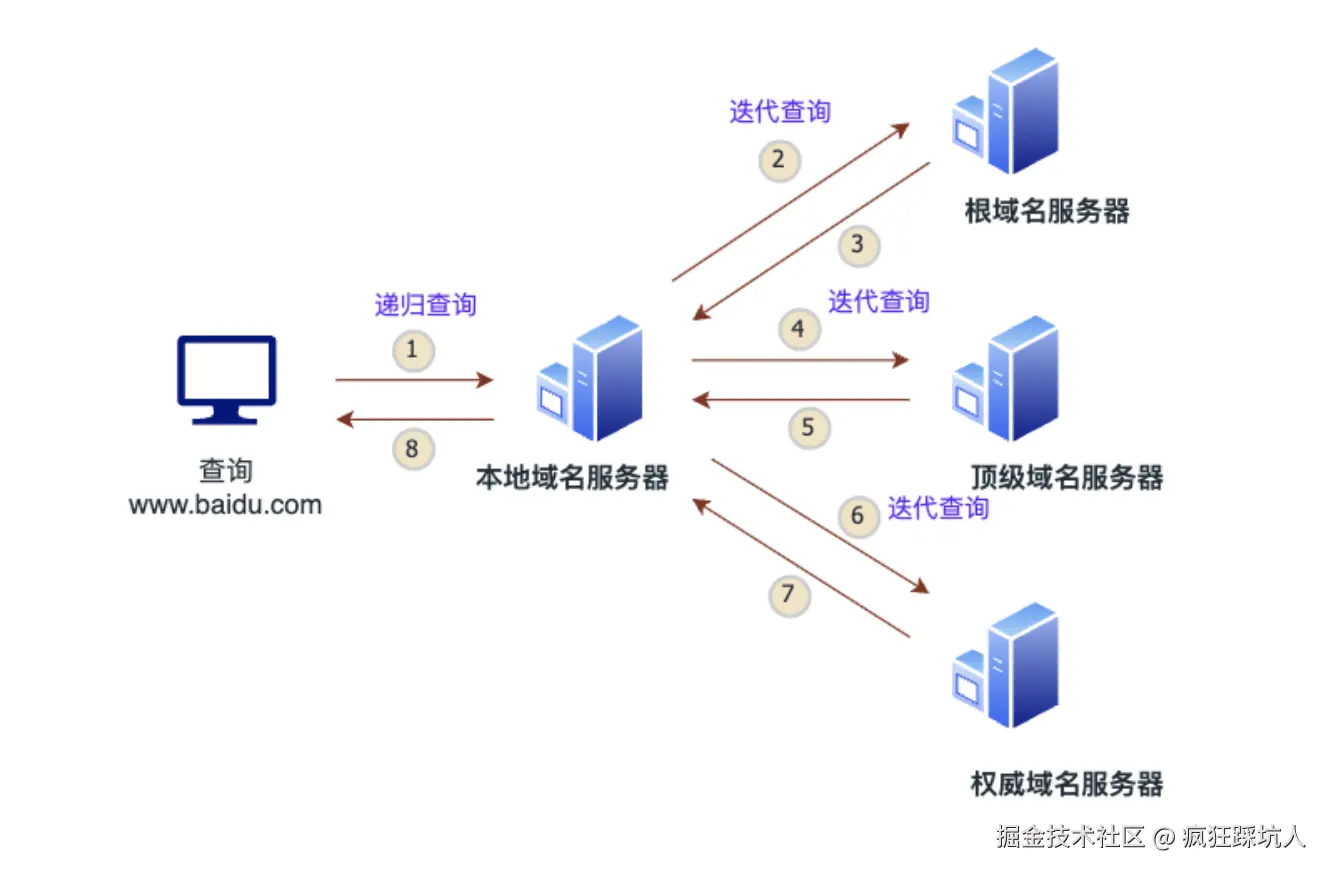
- 用户在电脑浏览器中输入
www.baidu.com后,用户的电脑(DNS客户端)向本地域名服务器 (通常由网络服务商ISP提供)发起一个递归查询请求。 - 本地域名服务器收到请求后,首先向根(
.)域名服务器发起第一次迭代查询。 - 根域名服务器返回一个顶级域名服务器的地址,让本地域名服务器继续查这个地址。
- 本地域名服务器向顶级(
.com)域名服务器第二次迭代查询。 - 顶级域名服务器返回一个权威域名服务器的地址,让本地域名服务器继续查这个地址。
- 本地域名服务器向权威(
baidu.com)域名服务器发起第三次迭代查询。 - 权威域名服务器查询自己的记录,确认了主机
www.baidu.com对应的确切IP地址,并将这个最终的IP地址返回给本地域名服务器。 - 本地域名服务器终于拿到了最终的IP地址,它将这个IP地址返回给用户的电脑。
"递归查询"意味着用户要求本地域名服务器必须给出最终的IP地址,而不能只是返回一个线索。
「迭代式查询」方案中,其实是既有递归查询,又有迭代查询的,(见「迭代式查询」图)主机查询本地域名服务器是采用递归查询,本地域名服务器去查其他服务器是迭代查询的。
根服务器和顶级域名服务器的作用是"导航"和"指路",而最终的目的地(IP地址)只有域名的拥有者所管理的"权威域名服务器"才知道。根域名服务器和顶级域名服务器是不会存目标域名的IP,因为像.com这种有上亿个网站,都存入顶级域名服务器存储和查询压力都是非常大的。所以采用这种委托机制。
由于「递归式查询」对根域名服务器的压力大,所以实际互联网采用了「迭代式查询」方案(递归查询和迭代查询混用的形式)。DNS的传输层协议默认情况下使用的UDP协议(端口是53),一些情况下也会用TCP协议辅助。
DNS缓存
一方面是本地域名服务器上有缓存(一般有一个较短的存活时间,DNS记录的TTL表示),另一方面是用户的主机(电脑手机设备)有缓存。
域名解析缓存路径:浏览器缓存(几十秒)------>系统hosts文件------>本地域名服务器缓存(几天)------>向外部查询
【参考】
字节面试被虐后,是时候搞懂 DNS 了
8 张图带你彻底搞懂 DNS 域名解析过程
36 张图详解 DNS :网络世界的导航
六、CDN
CDN作用和原理
CDN (全称 Content Delivery Network),即内容分发网络。基于现有网络,构建的一个虚拟网络,这个虚拟网络由分布在各地的边缘服务器组成。 通过cdn可以将静态
简单总结CDN原理:本地域名服务器向DNS发送查询请求,对于使用了CDN的域名,那么DNS会返回一个CNAME记录(而不是一个ip地址,CNAME是指向CDN网络的域名)。本地域名服务器,会请求查询这个 CNAME 对应的IP。从而进入CDN的智能调度网络中,综合下面因素,找到合适的CDN节点: 1)IP 物理地址,查表找最近的 2)找同一个运营商网络中的 3)考虑节点的服务能力,响应速度
DNS与CNAME记录的作用
- CDN智能调度的起点是 CNAME记录 。当你的网站接入了CDN服务后,在域名的DNS设置中,不再是直接将域名指向源站服务器的IP地址(A记录),而是指向一个由CDN服务商提供的域名,也就是CNAME记录(例如
www.example.com指向www.example.com.c.cdnhwc1.com)。这个过程可以理解为一种"域名解析权的移交"。 - 当本地DNS服务器查询到CNAME记录后,它需要对这个新的域名(即CDN服务商提供的域名)进行新一轮的DNS解析,在这轮解析中当到达了权威域名服务器 时,会进入CDN的全局负载均衡系统(GSLB)。
- GSLB会根据多种复杂的实时因素来决定将哪个边缘节点的IP地址返回给用户,而不仅仅是简单的地理位置最近。
CDN访问过程
(图来自 为了搞清楚CDN的原理,我头都秃了.. )
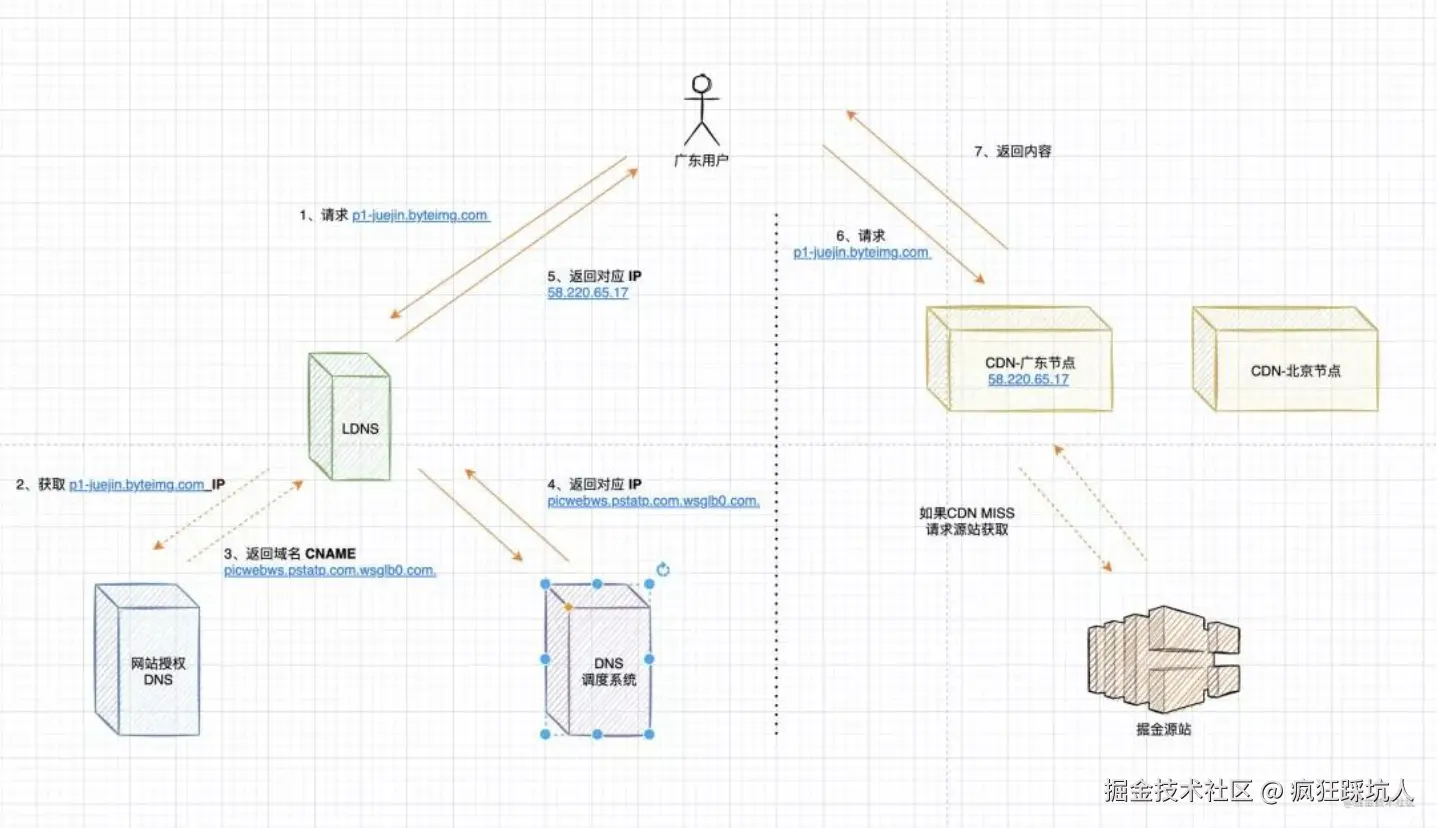
- 先经过 本地DNS服务器(LDNS) 解析,如果 LDNS 命中缓存,直接返回给用户。
- LDNS 未命中缓存,继续DNS查询。
- DNS查询(经过根/顶级/权威域名服务器查询),返回了一个CNAME
- LDNS发现是一个CNAME(还是 一个域名),继续请求DNS解析。此时CNAME解析会返回一个最优的边缘节点IP
- LDNS响应IP给用户
- 用户使用这个IP请求边缘节点的资源
- 返回资源
CDN缓存
我们知道当浏览器的强缓存失效,就会走协商缓存,但如果我的网站使用了cdn呢,协商缓存的验证请求发给谁呢?
cdn缓存本身是HTTP缓存的内容,遵循HTTP协议。还记得Cache-Control的public属性吗,就是用来允许响应可被CDN、代理服务器缓存的。
当用户请求到cdn的资源时,cdn的资源也会有一个缓存期限(依据Cache-Control:max-age=<seconds>设置的保鲜期限),如果在保鲜期限内则直接返回,否则会重新向服务器请求(协商缓存)。
CDN缓存是中间层缓存,与浏览器缓存是不同的缓存层次。
【参考】
八、websocket和SSE
websocket
什么是websocket
HTTP这种单向请求的特点,注定了如果服务器有连续的状态变化,客户端要获知就非常麻烦。我们只能使用"轮询":每隔一段时候,就发出一个询问,了解服务器有没有新的信息。最典型的场景就是聊天室。
(图片来自WebSocket 教程 )
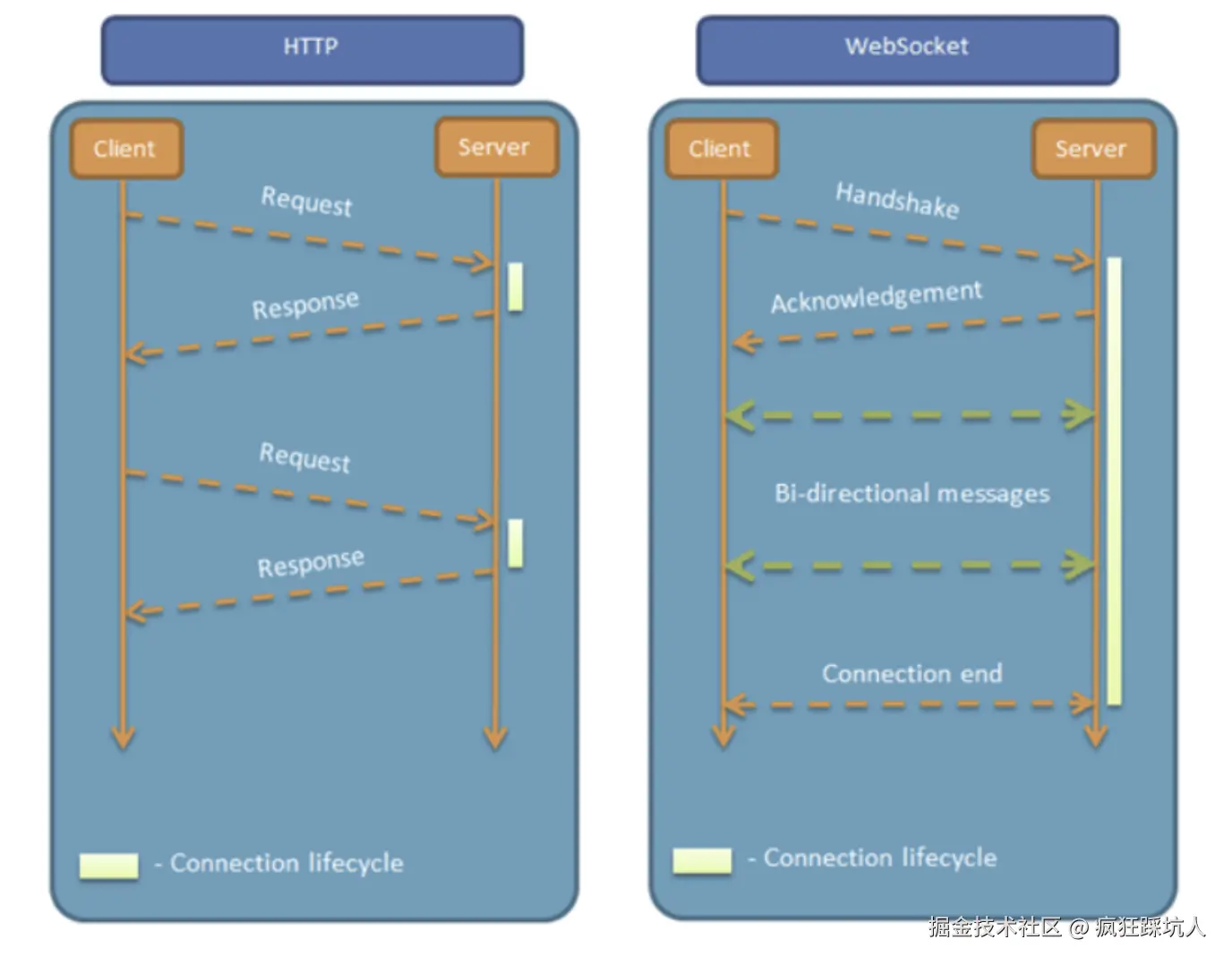
一句话解释:Client给Server发信息的同时,Server可以给Client发送信息,是一种平等的对话,是一种全双工通信协议。
工作原理:
- 握手阶段 : (1次http握手)
- 客户端使用 HTTP(S) 发起一个特殊的请求(包含
Upgrade: websocket头)。 - 服务器返回
101 Switching Protocols响应,确认升级协议。
- 客户端使用 HTTP(S) 发起一个特殊的请求(包含
- 建立连接后 :
- 双方可在同一个 TCP 通道上互相推送数据,不再需要 HTTP 请求头。
- 数据以轻量的二进制帧(Frame)格式传输,延迟低
特点如下:
| 特点 | 说明 |
|---|---|
| 全双工通信 | 客户端和服务端都可以主动发送消息 |
| 基于 TCP | 保证可靠传输,建立后保持 TCP 通道,减少连接开销 |
| 轻量级帧结构 | 比 HTTP 请求头小得多,传输效率高 |
| 跨域支持好 | 通过同源策略限制较少 |
客户端API
创建WebSocket实例时传入一个url实现连接,url的协议必须是ws://或者wss://。
javascript
var ws = new WebSocket("wss://echo.websocket.org");
ws.onopen = function(evt) {
console.log("Connection open ...");
ws.send("Hello WebSockets!");
};
ws.onmessage = function(evt) {
console.log( "Received Message: " + evt.data);
ws.close();
};
ws.onclose = function(evt) {
console.log("Connection closed.");
};ws上的方法有
| 方法 | 作用 |
|---|---|
new WebSocket(url) |
创建连接(ws:// 或 wss://) |
ws.send(data) |
发送字符串或二进制数据 |
ws.close() |
主动关闭连接 |
ws.on() |
监听事件:open,message,error,close |
P.S. ws.on('message', fn)和 ws.onmessage = fn 是一样的,都可以使用。
ws上的属性readyState有四种值:
CONNECTING:值为0,表示正在连接。OPEN:值为1,表示连接成功,可以通信了。CLOSING:值为2,表示连接正在关闭。CLOSED:值为3,表示连接已经关闭,或者打开连接失败。
P.S.由于websocket是一个client/server对等的协议,server端的API起始和客户端是一致的,就不介绍了。
心条机制-断线重连
1.onerror和onclose的区别(弱网环境中的连接断开) 在弱网环境中,如果网络连接不稳定或中断,WebSocket连接可能会被关闭。这种情况下,浏览器通常会触发close事件而不是error事件。close事件会包含一些关于关闭原因的信息,开发者可以根据这些信息判断连接是如何关闭的。
onerror的触发条件 :error事件一般用于捕捉低级别的网络错误或协议错误,例如无法解析服务器地址、send数据时服务器不可达、协议握手失败等。这些错误通常在连接建立阶段或数据传输过程中发生。onclose的触发条件 :close事件会在WebSocket连接关闭时触发,无论关闭的原因是什么,包括正常的关闭和由不正常导致的关闭(对于不正常关闭有一定延迟触发,是底层TCP的keep-alive机制)。借助close事件,开发者可以获取更详细的关闭信息,例如关闭状态码和关闭原因。
2.心跳机制和重连
- 弱网环境中TCP容易断开,然后触发
close事件,通常我们在onclose中发起重连,但可能会有一定延迟。 - 为了避免这个延迟(发真正数据时才发现断开了),所以协议里规定了ping-pong机制(即心跳机制)------服务端发一个ping帧,客户端就会响应一个pong帧,反之亦然。
- 针对ping帧,如果一方没有按时收到pong帧,说明断开了就会自动触发
close事件,然后重连。
SSE
什么是SSE?
(图片来自Server-Sent Events 教程)
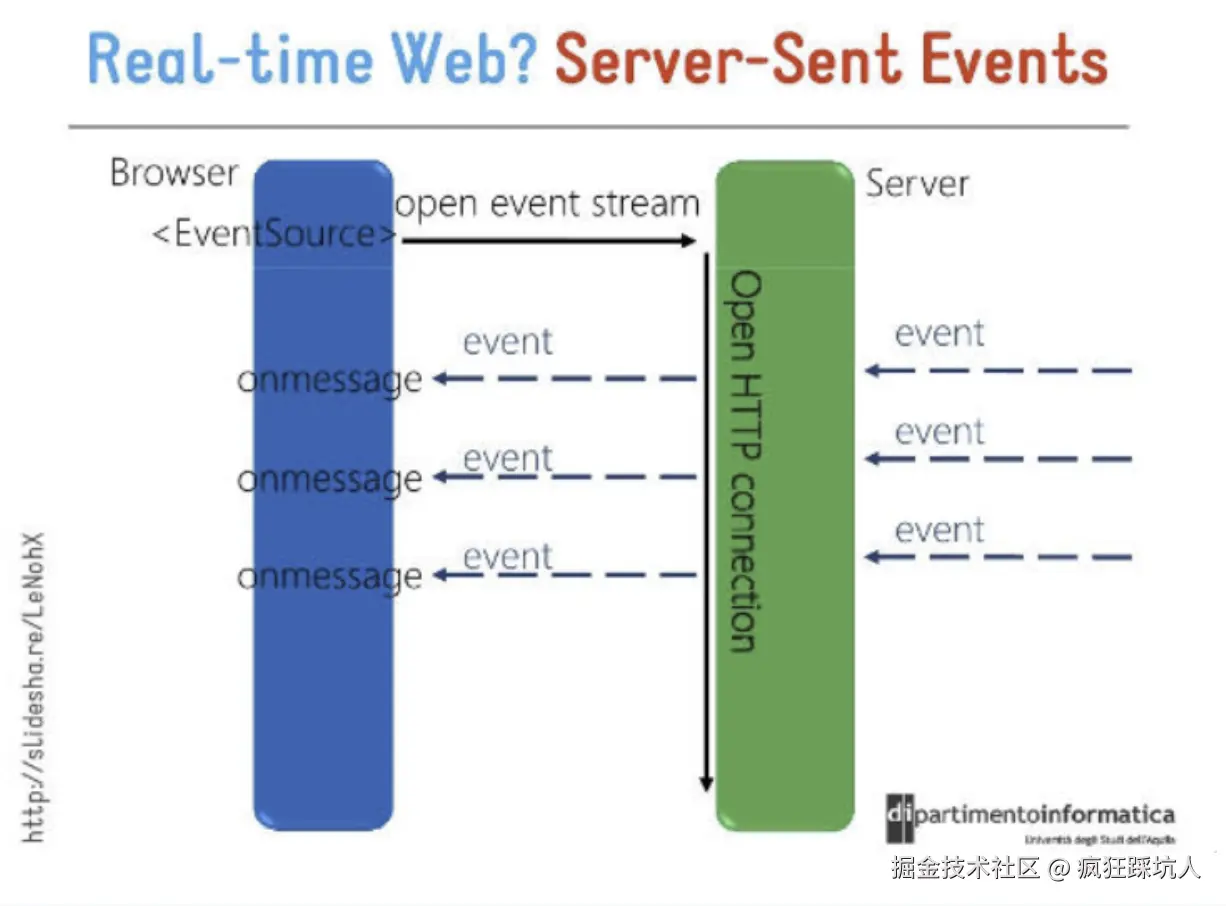
一句话解释:Client(Browse)请求Server后,Server可以持续向Client推送消息,Client通过事件监听不断接受消息直到结束连接。
原理 :Server告诉Client发送的是一种事件流(即text/event-stream,协议层的约定),收到响应后并不立即结束,后面还能继续收到消息,这些消息都是对这次请求的响应。实现关键是通过Server设置响应头Content-Type:text/event-stream,而Client在处理响应时会一直监听消息(onmessage)。
客户端API
EventSource方法和事件:
- EventSource的事件:
- open事件:连接建立时触发。
- message事件:接收到来自服务器端的消息时触发。
- error事件:连接出错时触发。
- EventSource实例方法:
close():手动关闭SSE连接(关闭SSE连接就是关闭TCP连接的)。
- EventSource实例
readyState属性:CONNECTING表示连接正在建立。OPEN表示连接已经建立。CLOSED表示连接已经关闭。
建立连接:
js
const sse = new EventSource("/api/v1/sse"); //创建实例就会自动连接
//sse.readyState可以判断连接状态监听信息:你可以使用EventSource的addEventListener方法监听事件(包括自定义事件)
javascript
source.addEventListener('open', ()=>{})
source.addEventListener('message', (data)=>{})
source.addEventListener('error', ()=>{})
source.addEventListener('close', ()=>{})message事件会被触发多次,即可以分多次接受数据,你可以不断拼接数据块data实现文本展示「打字」效果。
服务端
1.设置响应头
http
Content-Type: text/event-stream
Cache-Control: no-cache
Connection: keep-alive因为SSE推送的是实时信息,所以不需要缓存,设置no-cache;SSE连接是一个长连接,需要持续接受消息,不能接受一次消息就断开TCP连接,设置keep-alive;
2.发送数据 下面是双方约定的响应数据的格式:
http
event: [messageEvent]
id: [num]
data: [textContent]
retry: [num]
: [comment]event字段,表示(下面data数据对应的)自定义的事件类型,默认是message事件。浏览器可以addEventListener()监听该事件。id字段,表示data的编号,浏览器用lastEventId属性读取这个值,对于SSE断开重连同步数据有用。data字段,就是实际传输的文本。retry字段,表示连接出错后重试的次数,重试retry次后就关闭连接。一般只发一次,并且第一个发。- 你没看错,还有最后一种,
:表示注释,这个没有业务作用,主要是防止时间过长TCP断开连接。
一般可以省略 event、id、 retry,数据会长下面这样,\n\n表示一个消息的结束标记(仅一个\n表示换行)。
http
data: some text\n\n
data: another message\n
data: with two lines\n\nonmessage可以接受到两个信息: some text 和 another message\nwith two lines
4.如何结束?
方式一(推荐)自定义结束event: 自定义end事件,比如event: end 表示结束事件,Client监听到end信息后主动close,关闭连接。
P.S. 在Nodejs中,调用res.end("event: end"); 浏览器收到事件后eventSource.close()(底层就是发送一个FIN报文,结束TCP连接)
方式二 server主动关闭: 通过响应头的方式, 响应头Connection: close表示本次 HTTP 响应结束后不再保持连接,服务器会在发送完数据后主动断开。
js
response.setHeader('Connection', 'close');P.S. 此时会触发
error事件,同时event.readyState=EventSource.CLOSED。判断错误对象可以判断是不是正常关闭,还是网络错误导致的关闭。
和websocket的区别
1.协议
- SSE是基于HTTP协议的(本身就是HTTP协议)
- websocket是一种新协议(相对HTTP协议更加复杂),但需从HTTP升级(Upgrade) 2.双工性
- SSE半双工通信,只是服务端推送数据(不能边发边收)。
- websocket是全双工通信,可以一边发送数据一边接受数据。 3.自动断线重连
- SSE 具有自动重连机制:当连接中断时,浏览器会尝试重新建立连接,确保持续地接收服务器的事件流。
- websocket需要手动实现
ping-pong机制来重连。
【参考】
WebSocket 教程 Server-Sent Events 教程
九、URL输入到显示发生了什么
1. 缓存机制
- 缓存检查 :根据URL判断是否有内存或磁盘缓存。
- 强缓存:如果缓存有效,直接使用本地资源,无需请求服务器。
2. DNS解析
- 解析过程 :将域名解析为IP地址。
- 缓存层级 :
- 浏览器缓存
- 本地hosts文件
- 本地域名服务器
- 查询方式 :
- 递归查询
- 迭代查询
- 域名服务器类型 :
- 根域名服务器(
.) - 顶级域名服务器(如
.com) - 权威域名服务器(如
baidu.com) - 本地域名服务器
- 根域名服务器(
- CDN:可能在此阶段介入,加速资源访问。
- 缓存层级 :
3. TCP三次握手
- 建立连接 :
- 客户端发送
SYN报文。 - 服务器响应
SYN-ACK报文。 - 客户端发送
ACK报文,完成连接建立。
- 客户端发送
4. HTTPS连接(TLS握手)
- 四次握手 :
- 协商加密算法和密钥。
- 验证服务器身份。
- 建立安全通道。
5. HTTP请求与响应
- 请求构建:浏览器构建HTTP请求,通过TCP连接发送。
- 协议版本 :
- HTTP/1.1:复用TCP连接,但存在队头阻塞问题。
- HTTP/2:多路复用,避免队头阻塞。
- 响应处理 :
- 状态码 :
304:资源未修改,使用缓存。301:永久重定向。302:临时重定向。200:成功,继续解析和渲染。
- 状态码 :
6. 浏览器渲染
- 解析 :
- HTML解析为DOM树。
- CSS解析为CSSOM树。
- 样式计算:结合DOM和CSSOM生成渲染树(Render Tree)。
- 布局:计算元素位置和尺寸(Layout Tree)。
- 绘制:生成绘制指令。
- 栅格化与合成:将绘制结果转换为像素并显示。
7. 回流与重绘
- 回流(Reflow):布局变化(如尺寸、位置改变)。
- 重绘(Repaint):样式变化(如颜色、可见性改变)。