本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:吕海波,PG ACED ,北京大学数据库课程企业导师。
本文主要包括以下三部分内容:
- CPU 流水线的秘密:神秘的 PMC 与 PMU
- 示例数据库 1 的改进与不足:从 CPU 看程序
- 示例数据库 2 的秘密花园使用 PMC 推导软件架构
CPU 流水线的秘密:神秘的 PMC 与 PMU
- PMC:Performance Monitoring Counter
- PMU:Performance Monitoring Unit
PMC 是性能监控计数器,PMU 是性能监控单元,两者其实是一回事。
CPU 在其流水线的内部内置了上千个计数器,用来观察程序指令在 CPU 内部运行的状态。单个计数器就是 PMC,所有的计数器合起来就是 PMU。
PMC 的作用
众所周知,CPU 体积很小,却内置了上千个计数器,其重要性不言而喻。
PMC 的作用是对程序进行 profiling(或画像/侧写/......)。通过画像,让开发者了解程序在 CPU 中的运行状况,有针对性的调整、优化程序,以提高程序性能、能效。
perf 与 PMC
perf stat -ePMC1,PMC2,......PMCn -p/t 进/线程
使用一条 perf 的命令,就能够把某个或某些计数器打开,然后把机器去的结果展现出来。
CPU 中有什么 PMCs ?
使用 perf list 这一条命令,就能把所有的 PMC 列出来。
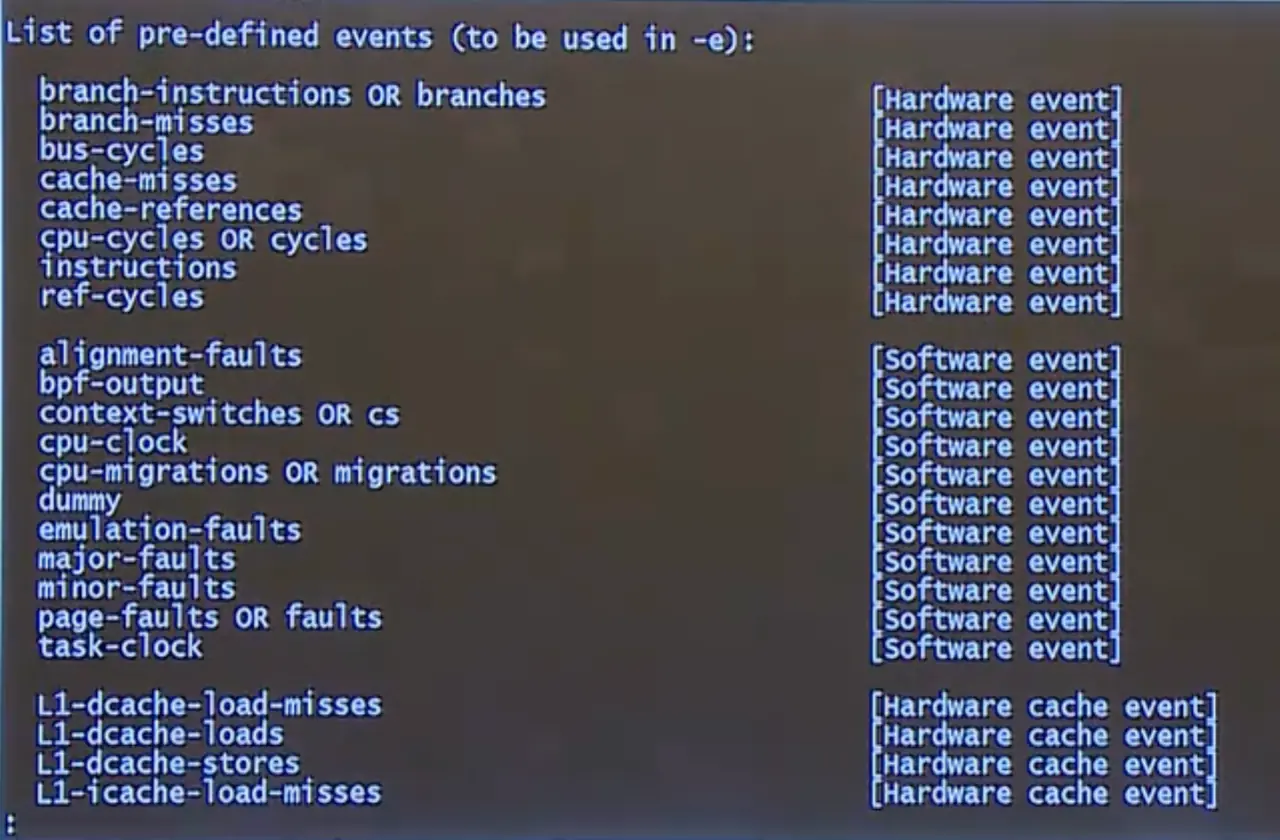
上图中标记 hardware event 的即为 CPU 内流水线的计数器,一共有 1000 多个。标记为 software event 的则是操作系统中软件的计数器,但不是 CPU 中的。
虽然这些计数器很多,但最重要的是开头这些。
示例数据库 1 的改进与不足:从 CPU 看程序
PMC 的作用
下面用一个非常简单的例子,来看一下 PMC 的作用。
如果想知道"执行某条命令时,CPU 到底为它运行了多少条指令",用 perf stat -e instructions:u -t 26896 这条命令就能精准统计。
这条命令的每个部分都有明确作用:
-e instructions:u:指定要监控的"事件计数器"。instructions表示计数器类型,即统计"指令总数"。- 冒号后的
u是筛选条件,只统计用户态指令,会自动屏蔽操作系统内核态的指令。
-t 26896:指定监控对象。t是thread(线程)的缩写,这里直接跟线程 ID26896,表示只监控该线程的指令。- 若想监控整个进程,需将
-t换成-p,再跟上进程 ID。
CPU 会根据"特权等级"区分指令来源,主要分两类:
- 用户态指令:普通应用程序(比如你执行的命令)发出的指令,是统计的核心目标。
- 内核态指令:操作系统自身(比如处理文件、网络)发出的指令,属于"干扰项"。
加 :u 能屏蔽内核态指令,让最终的统计结果更干净,只反映你关注的命令实际消耗的 CPU 指令数。
画像,对比着看才更有意义。我们下面对比下"示例 1 数据库"和 PG。看看怎么从 CPU 角度对数据库进行画像。
接下来我们进行观察时,需先明确两点核心逻辑:
- 若有多个 PMC(性能监控计数器),可针对单个程序做深度分析;
- 当前仅用"指令数"这一个 PMC,因此更适合通过多个程序对比来得出结论。
我们选取两个数据库对象作为对比样本,关键信息如下:
- 第一个对象:PG 数据库
- 内置一张表,表名为"vage2";
- 该表数据量为 195M,包含 4 列,其中两列为主键;
- 表内共插入 300 万行数据。
- 第二个对象:示例数据库
- 暂不提及具体名称,统一称其为"示例数据库 1";
- 该表数据量为 196M,包含 4 列,其中两列为主键;
- 表内共插入 300 万行数据。
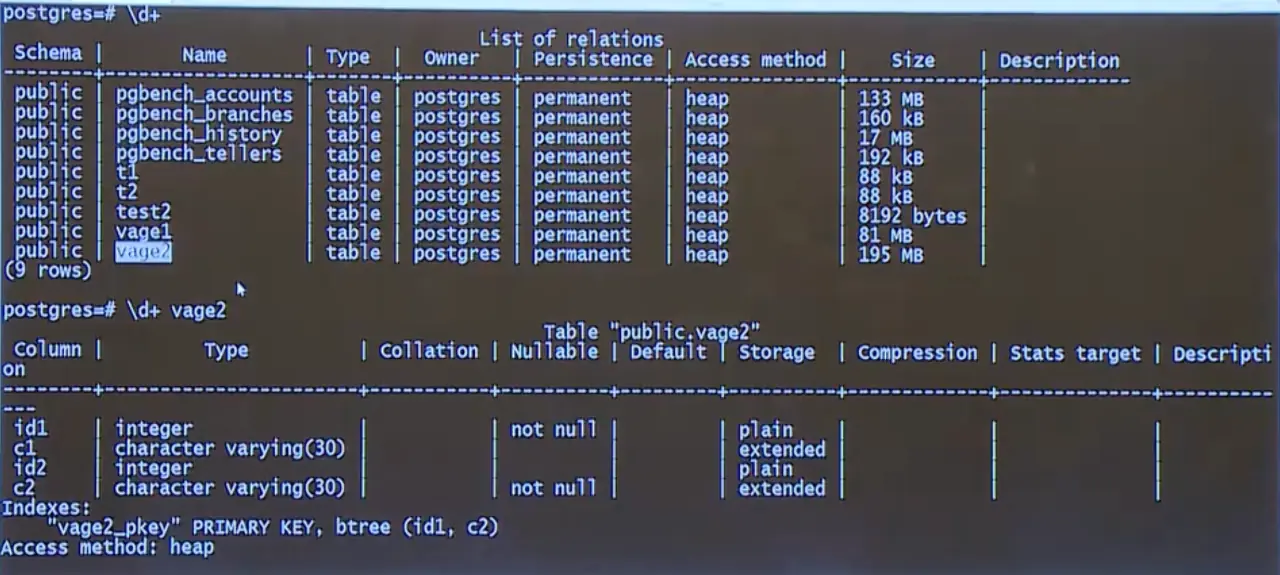
PG
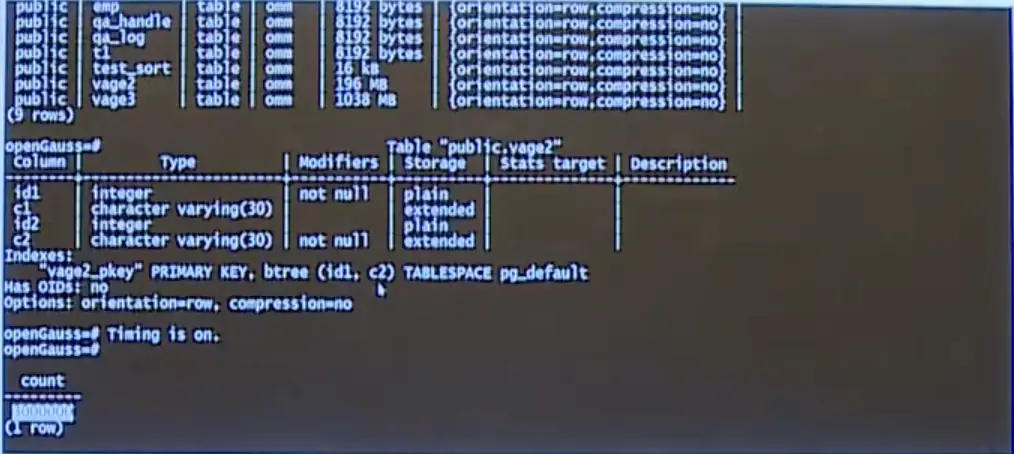
示例数据库 1
对比分析先从简单 SQL 开始------复杂压测的指令数太多,暂不考虑。以主键 ID 为例,300 万行数据对应的索引层高约 3-4 层,若按 3 层计算,一次查询会涉及 4 次逻辑操作。
另外,示例数据库 1 将 PG 的进程模式改成了线程模式。之前展示的统计命令其实需要进程号和线程号,但从示例数据库 1 查询到的并非线程号或进程号,而是线程标识。这里我也做了演示:先用 GDB 调试示例数据库 1 的进程,再通过一条命令 (gdb) i threads,即可从线程标识获取线程号。这里的"I"就是 Info 命令。用 Info 命令显示数据库一的所有线程,就能列出所有线程信息。接着,查出之前的线程号,将其转换成十六进制,再在显示的线程列表中搜索这个十六进制值,就能找到对应的是 2 号线程------也就是刚才第二个窗口里对应的线程,其线程号为 6918。
接下来的操作很简单:我们执行命令 perf stat -e instructions:u -t 26896,其中 -t 后面跟的就是目标线程号(这里以 26896 为例)。这条命令会针对 26896 线程开启 CPU 指令计数器------只要该线程有任何操作,都会触发 CPU 前端指令计数器的计数增长。
开启计数器后,切换到旁边的窗口执行目标 SQL(比如我们之前提到的简单语句,也可以是其他语句);执行完成后切回原窗口,按 ctrl+c 即可查看统计结果。
多次执行后会发现,前两次结果可能有波动,后续则趋于稳定。在示例数据库一中,执行这条简单 SQL 大约需要 100 多万条指令(略多于 100 万)。 再看 PG 的测试,操作模式几乎一致:先多次执行目标 SQL,查出其进程号(比如 7096),然后在旁边窗口使用 perf 命令时,因 PG 是进程模式,只需将参数从-t(线程号)换成-p(进程号),即 -p 7096,其他命令保持不变。
统计结果显示,PG 执行相同操作的指令数约为 21 万(略多于 20 万)。对比来看,示例数据库一的指令数是 PG 的 4 到 6 倍,多次测试取平均值后,差距约为 5 倍。
从功能上看,PG 并不比示例数据库一弱,甚至在不同场景下各有优势。但从指令数差异能看出,示例数据库一的操作逻辑略显冗余------就像两人聊天时,本可以用 10 句话讲清的问题,它却用了 50 句,存在一定的资源浪费。不过,这种冗余在当前场景下的影响并不算大,我们通过这种简单方式,能从 CPU 指令角度直观观察到这一特点。
衡量 Coding 水平
除了统计指令数,使用 PMC 中的指标,还可以简单的观察程序开发者的 coding 水平。以分枝指令数和 not_taken 分枝指令数为例进行对比。
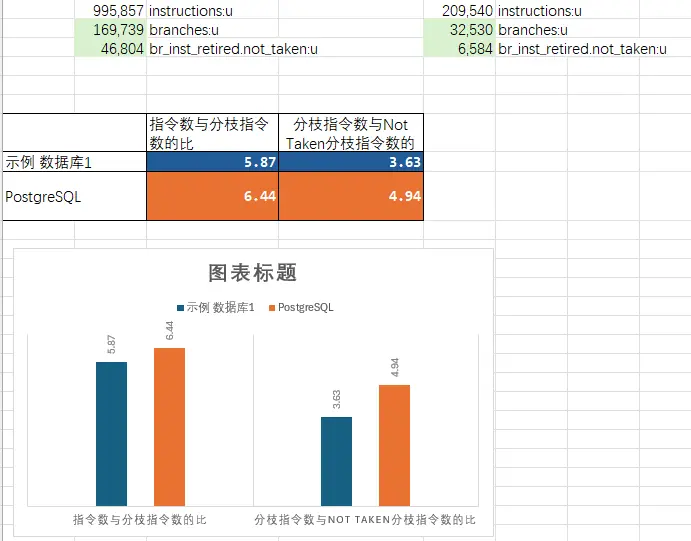
可以看到,示例数据库 1 和 PG 相比,coding 水平是有差异的。不过示例数据库 1 也有优点,它把进程改成了线程。线程的最大优势是 TLB 的 miss 率更低。
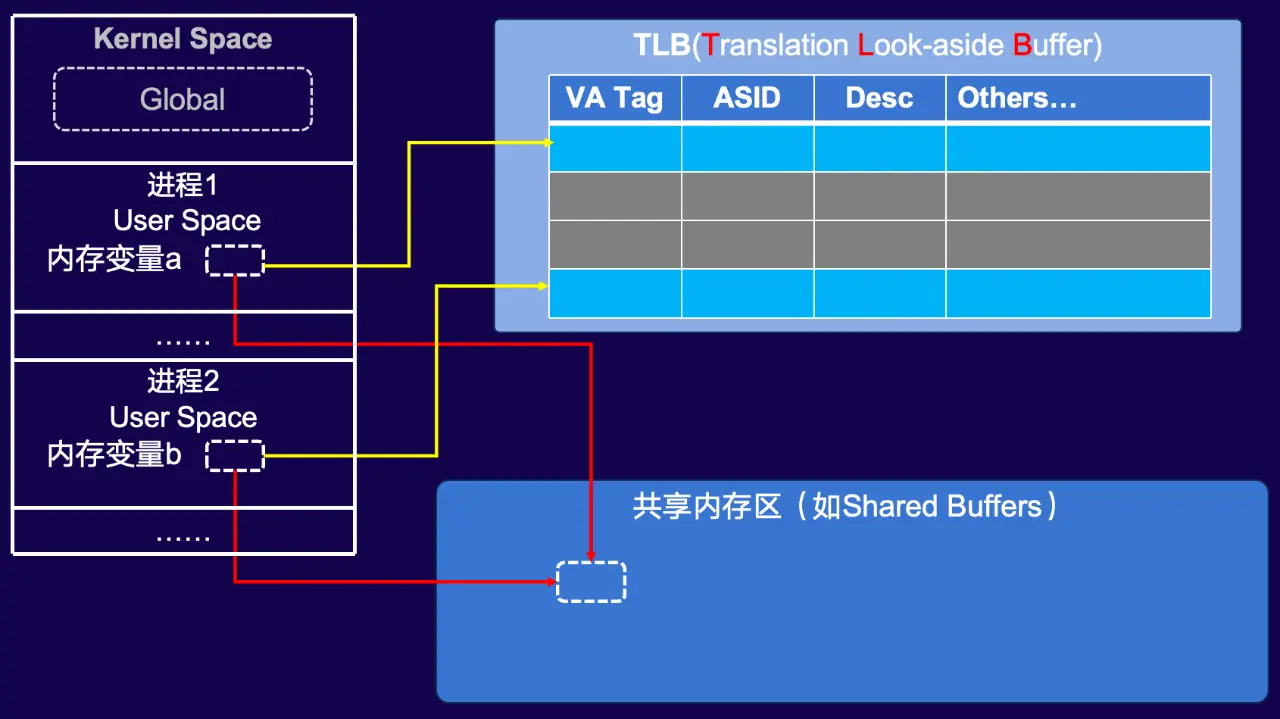
进程与线程
- 进程模式下的 TLB 行为 如图所示,进程 1 和进程 2 的用户空间中,变量 a 和变量 b 虽映射到同一块共享内存,但由于进程拥有独立的地址空间,TLB(地址转换旁视缓冲器)会为它们分别维护包含 VA Tag(虚拟地址标签)、ASID(地址空间标识符)等字段的条目。即使物理内存是同一块,TLB 中也会存在两个独立的条目。
- 线程模式下的 TLB 优势 线程属于同一进程,共享同一个地址空间。若两个线程访问类似变量 a、b(映射到同一块共享内存),它们在 TLB 中会复用同一个条目。
- 当线程 1 访问变量 a 时,TLB 会缓存对应的地址转换条目;
- 线程 2 访问变量 b 时,可直接命中该 TLB 条目,无需重新执行地址转换,从而大幅降低 TLB miss 率。
- 性能影响的本质 TLB miss 率的降低能直接提升内存访问效率(如数据库场景中,线程模式的地址转换开销会显著小于进程模式)。但性能提升的上限还受其他因素制约------若代码本身存在逻辑冗余(如不必要的繁琐流程),仅靠线程的 TLB 优势可能无法完全抵消整体性能损耗。
示例数据库 2 的秘密花园:使用 PMC 推导软件架构
用 PMC 推导软件架构:准备测试数据
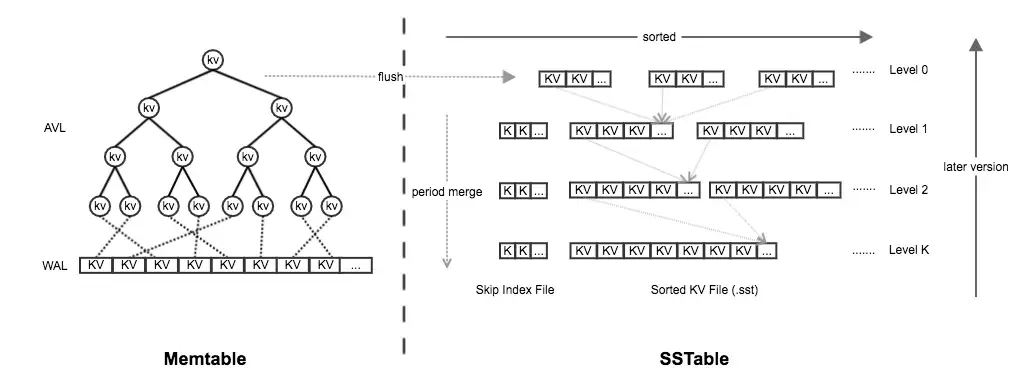
接下来我们用示例数据库 2 做对比,该数据库是基于 SSTable 处理架构的。
启动测试,测试的表有 100 万行,八九十兆,沿着主键做 10 万次查询。查询完成的时间为 1.6 秒左右,是 PG 的六七倍。
以不同的步幅访问内存,产生不同比例的 L1 Cache Miss,观察影响。 示例数据库 2 比 PG 慢,主要原因是 miss 率太差,导致性能下降很多。示例数据库 2 的 miss 率差,主要原因是,像传统的数据库,一个进/线程从头到尾完成 SQL 所有工作。 
示例数据库 2 采用分阶段执行 SQL 的架构设计,将单条 SQL 的执行流程拆分为多个独立阶段。针对每个阶段,系统会维护一个线程资源池;当请求流转至该阶段时,会从对应的资源池中获取一个线程,专门为该请求在当前阶段的处理提供服务。 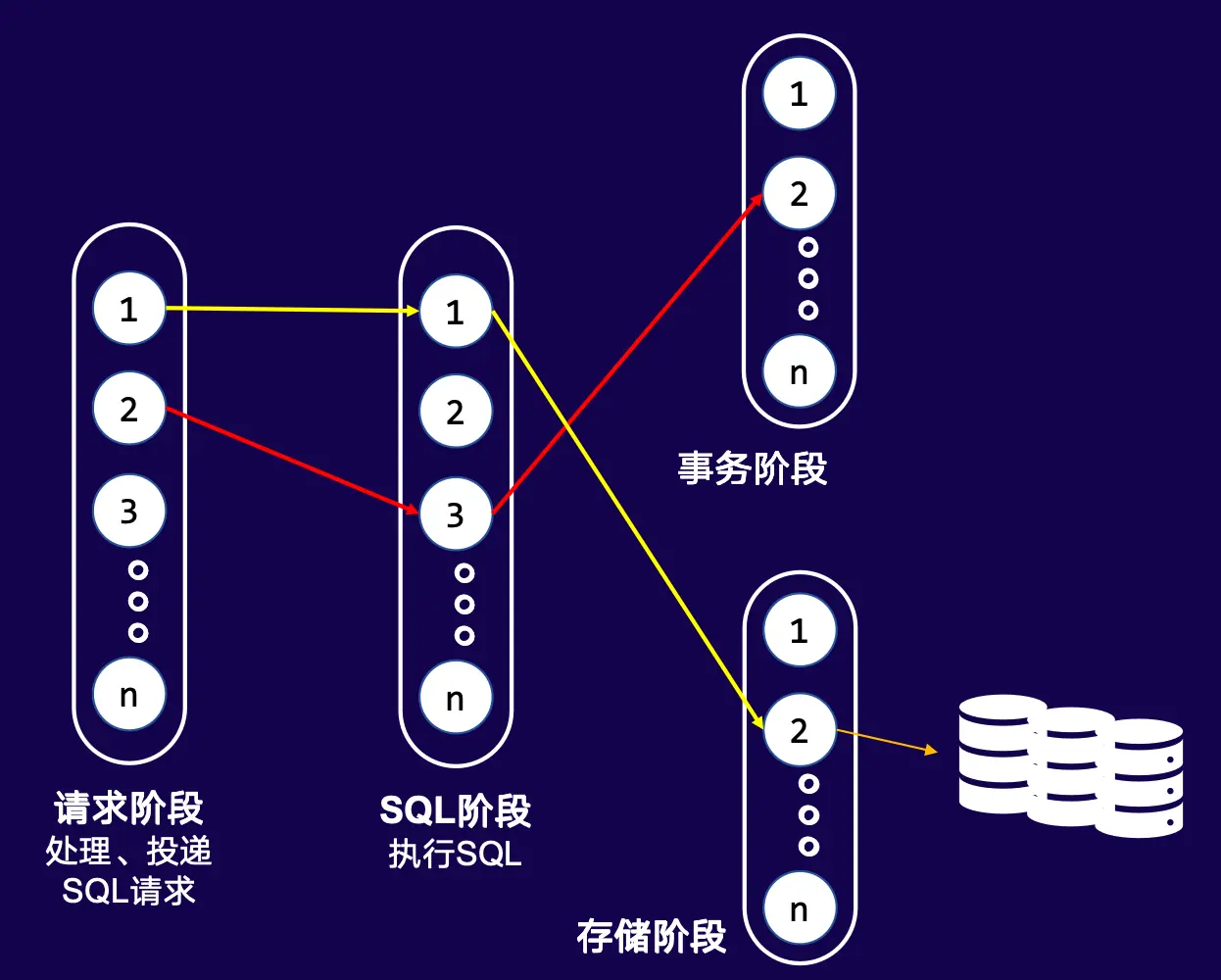
该模式存在重大性能缺陷:跨 CPU 核心的阶段调度会引发高频缓存失效。 如图所示,SQL 请求的处理被拆分为请求阶段、SQL 执行阶段、事务阶段、存储阶段,分别由不同 CPU 核心(Core 1 至 Core 4)负责。当请求从一个阶段流转到下一个阶段时,执行线程会切换到不同的 CPU 核心。
由于每个 CPU 核心的 L1、L2 缓存是私有的,前一阶段在 Core 1 缓存的 L1、L2 数据,无法被后续阶段所在的 Core 2/Core 3/Core 4 直接复用。这必然导致大量 L1、L2 缓存失效(miss)------数据需在 CPU 核心间传递,甚至回退到 L3 缓存或内存中重新读取,大幅增加了缓存访问开销。
这也是示例数据库性能不佳的核心原因:跨 CPU 核心的阶段拆分导致 L1/L2 缓存 miss 率显著升高,直接拖累了整体执行效率。 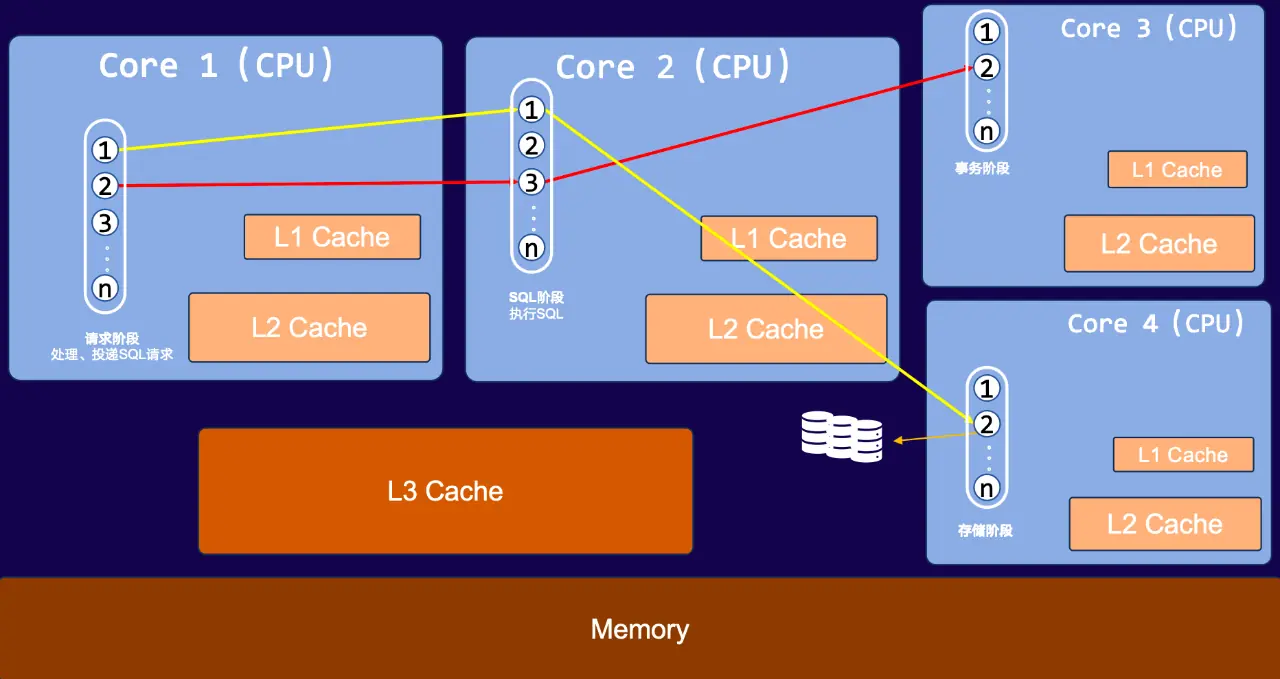
分支预测与编码对底层硬件的适配性
- BTB 的硬件作用 BTB(Branch Target Buffer,分支目标缓冲器)是 CPU 用于分支预测的关键硬件结构,存储"跳转语句"(如代码中的 if (条件 1))和"预测的目标地址",通过提前预判分支走向,减少分支指令的执行开销,提升 CPU 执行效率。
- 示例数据库 2 的分支预测缺陷 该数据库分支预测命中率低,核心原因是编码阶段未充分适配底层硬件机制(如 BTB 的工作逻辑)。开发者对 CPU 分支预测这类底层特性缺乏考量,导致分支指令频繁触发预测失败,直接拖累执行性能。
- 与 PG 的对比及本质结论 PostgreSQL(PG)在设计时更注重对底层硬件(包括分支预测、缓存架构等)的适配,因此分支预测命中率更高,执行效率更优。
这种差异本质上是编码对底层系统(硬件机制+软件架构)理解深度的差异------若要从底层优化性能,需深入理解 BTB、缓存、CPU 调度等原理,才能针对性地提升编码对硬件特性的适配性。 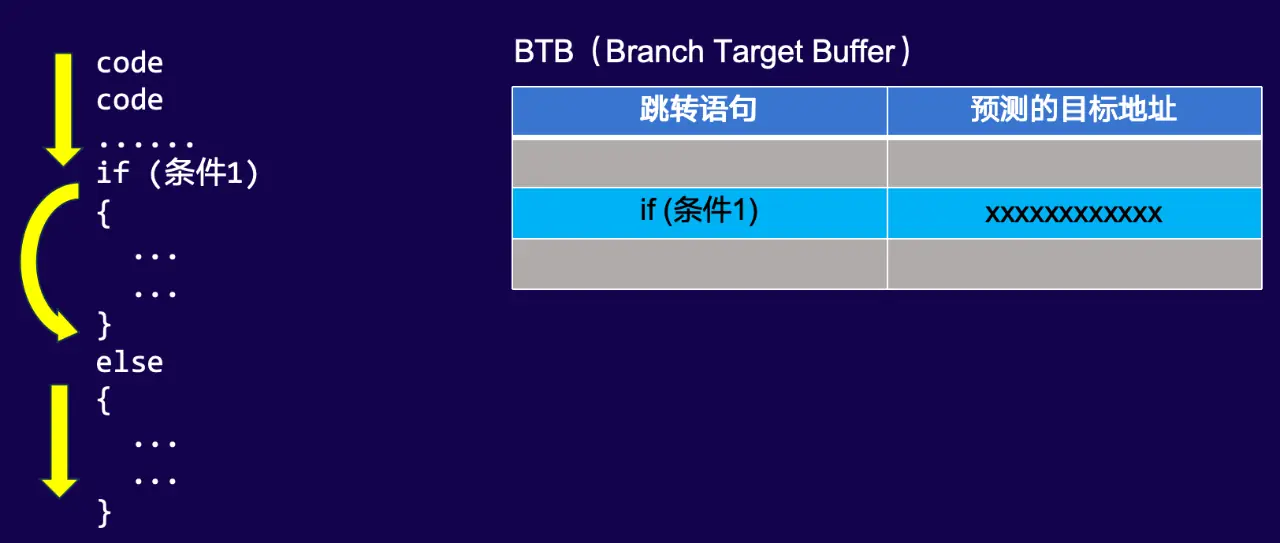
以上就是分享的全部内容,欢迎大家关注吕海波老师的公众号《IT 知识刺客》。