函数
函数允许用户将程序划分为多个模块,每个模块完成特定任务。使用函数编写模块化、可复用的代码。
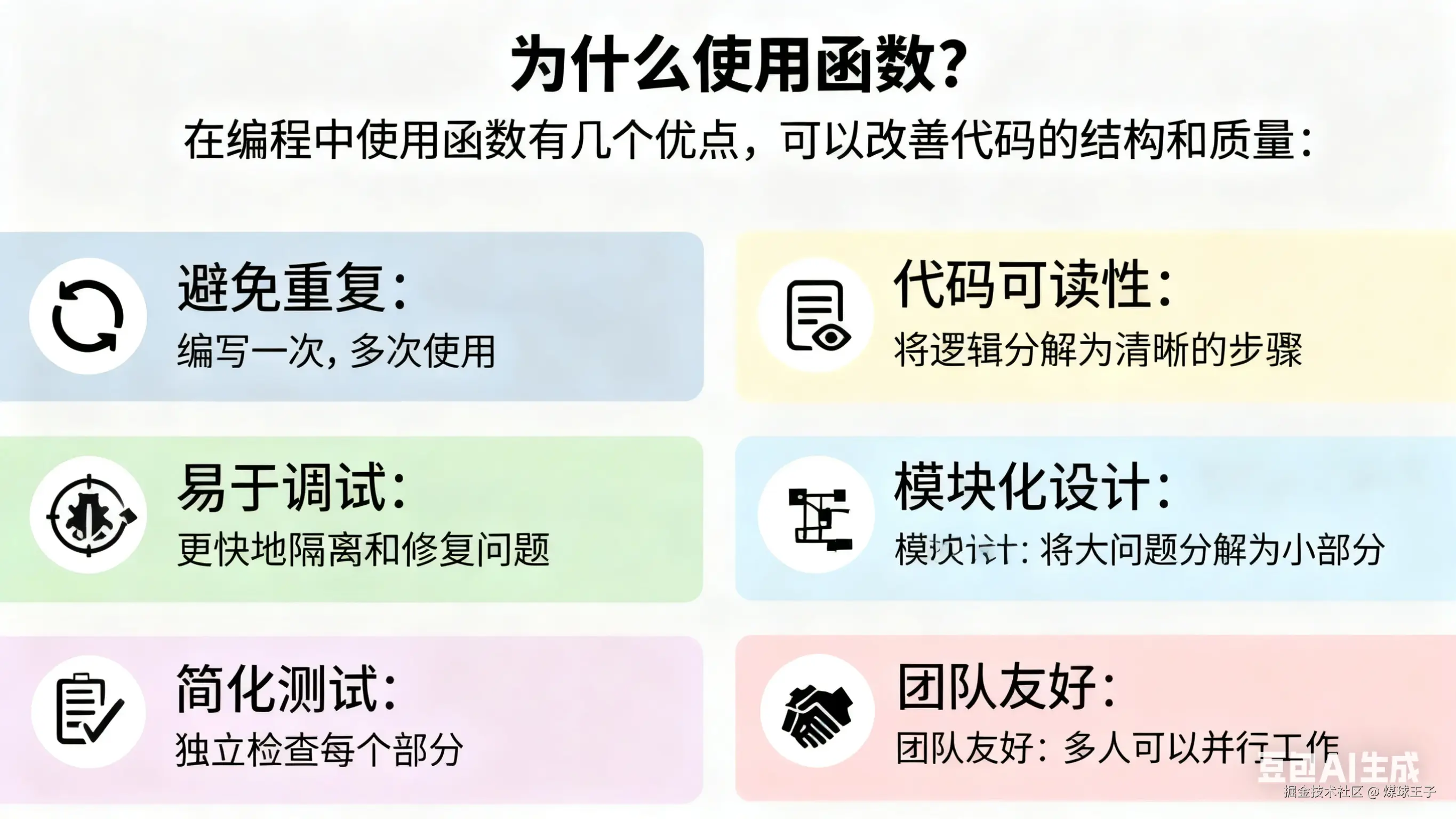
函数是一段可重复使用的代码块,用来完成特定任务。它能把大程序拆成小而清晰的模块,使代码更易读、更易维护。
与 C 相比,C++ 的函数还支持重载 、默认实参 、内联等高级特性,更加灵活。
示例代码:
cpp
#include <iostream>
using namespace std;
// 无返回值函数
void hello() {
cout << "GeeksforGeeks" << endl;
}
// 带返回值函数
int square(int x) {
return x * x;
}
int main() {
hello(); // 调用无返回值函数
int result = square(5); // 调用带返回值函数
cout << "Square of 5 is: " << result << endl;
return 0;
}运行结果:
csharp
GeeksforGeeks
Square of 5 is: 25代码说明:
main():程序入口,从这里开始执行,负责调用其他函数。hello():用户自定义的无参数、无返回值函数,仅打印GeeksforGeeks。square(int x):用户自定义函数,接收一个整数并返回其平方值;在main()中以 5 为实参调用,结果存入变量后输出。
1. C++ 函数语法
一个函数通常按以下格式书写:
cpp
return_type function_name(parameter_list) {
// 函数体
}各部分作用:
- 返回类型 (return_type):说明函数把什么类型的结果带回来;若无结果,写
void。 - 函数名(function_name):以后调用它时用的名字。
- 形参列表(parameter_list):函数期望接收的输入,可以为空。
- 函数体:真正执行的代码块,调用函数时就会跑这段逻辑。
2. 函数声明 vs 函数定义
函数声明 (Declaration) 只向编译器"介绍"函数:给出返回类型、函数名和参数列表,不写函数体,末尾带分号。
cpp
// 声明
int add(int, int);函数定义(Definition) 同时给出函数体,即真正的实现代码。
cpp
int add(int a, int b) {
return a + b;
}为什么需要声明?
- 如果函数定义在 main 之后(或别的源文件里),编译器在第一次遇到调用语句时还不知道有这么个函数,会报错。
- 提前写一份声明,编译器就能先知道它的"签名",从而检查调用是否正确。
一句话:
- 声明告诉编译器"有个函数长这样";
- 定义把"具体怎么做"补全。
3. 调用函数
函数一旦定义完成,只需写出函数名并加上括号 (),程序就会跳进去执行其中的代码。
- 如果函数需要参数,把实参按顺序放进括号;
- 如果不需要参数,就留空括号。
示例代码:
cpp
#include <iostream>
using namespace std;
// 无参数、无返回值的函数
void greet() {
cout << "Welcome to C++ Programming!" << endl;
}
// 有参数、有返回值的函数
int multiply(int a, int b) {
return a * b;
}
int main() {
greet(); // 调用 greet()
int result = multiply(4, 5); // 调用 multiply()
cout << "Multiplication result: " << result << endl;
return 0;
}运行结果:
css
Welcome to C++ Programming!
Multiplication result: 20说明:
greet()只是打印欢迎信息,调用时写greet();即可。multiply(4, 5)把 4 和 5 传进去,返回 20 并存入result。
通过多次调用同一函数、传入不同实参,就能以结构化、简洁的方式重复完成任务。
4. C++ 函数的类型
在 C++ 中,函数分两类:
-
库函数
由 C++ 标准库直接提供,例如
std::cout、std::sqrt()、std::abs()、std::getline()等。只要包含对应头文件(<iostream>、<cmath>、<string>等)即可调用。 -
用户自定义函数
程序员自己写的函数,用来完成特定任务。
参数传递方式
C++ 中的参数传递技术。在 C++ 中,可以在调用函数时将数据发送给函数以执行操作。这些数据称为参数(parameters)或实参(arguments),并且 C++ 提供了多种参数传递方式。本文将讨论 C++ 中的各种参数传递技术。
在了解具体技术之前,先弄清以下术语的区别:
- 形式参数(Formal Parameters):函数参数列表中用作占位符的变量,也简称"参数"。
- 实际参数(Actual Parameters):函数调用时传入的表达式或值,也叫"实参"。
C++ 中有 3 种不同的参数传递方法:
1. 值传递(Pass by Value)
在值传递方式中,变量的值被复制一份再传给函数。因此,函数内部对参数的任何修改都不会影响调用者中该变量的原始值。该方法简单、易懂、易实现,但对于大型数据结构不推荐,因为涉及拷贝开销。
cpp
#include <iostream>
using namespace std;
// 参数按值传递
void change(int a) {
a = 22; // 仅修改局部副本
}
int main() {
int x = 5;
change(x); // 将 x 按值传入
cout << x; // 输出仍为 5
return 0;
}输出
52. 引用传递(Pass by Reference)
在引用传递方式中,不再传递实参的值,而是传递实参的引用。这样函数内部对参数的修改会直接影响原始变量。适用于需要修改调用者数据或传递大型对象时。
cpp
#include <iostream>
using namespace std;
// 参数按引用传递
void change(int& a) {
a = 22; // 直接修改原变量
}
int main() {
int x = 5;
change(x); // 将 x 以引用方式传入
cout << x; // 输出 22
return 0;
}输出
22只需把形参 a 声明为引用类型,就从"值传递"变成了"引用传递"。
3. 指针传递(Pass by Pointer)
指针传递与引用传递非常相似,唯一区别是我们把实参的原始地址(指针)作为参数传给函数,而不是引用。
cpp
#include <iostream>
using namespace std;
// 参数按指针传递
void change(int* a) {
*a = 22; // 通过地址修改原变量
}
int main() {
int x = 5;
change(&x); // 传入 x 的地址
cout << x; // 输出 22
return 0;
}输出
22虽然也能修改原始值,但程序复杂度增加:需要小心解引用、取地址等操作。因此,通常优先使用引用传递而非指针传递。
默认参数
C++ 中的默认参数。默认参数是在函数声明时为形参给出的值。如果调用函数时没有为这些形参提供实参,编译器会自动使用该默认值。
规则:
- 默认参数必须出现在参数列表的最右侧。
- 一旦某个参数被指定为默认参数,其右侧的所有参数都必须也带有默认值。
- 建议把默认参数写在函数声明中(通常在头文件里)。
示例代码:
cpp
#include <iostream>
using namespace std;
// 带默认参数的函数
void f(int a = 10)
{
cout << a << endl;
}
int main()
{
f(); // 使用默认值,输出 10
f(221); // 使用传入值,输出 221
return 0;
}运行结果:
10
221
解释:
函数 f 的形参 a 设有默认值 10。
第一次调用 f() 没有传实参,a 取默认值 10 并打印;
第二次调用 f(221) 把 221 传给 a,因此打印 221。
1. 语法
在函数声明中,通过给形参赋值来指定默认参数:
ini
return_type 函数名(p1 = v1, p2 = v2, ...);
其中 v1、v2...... 分别是形参 p1、p2...... 的默认值2. 应遵循的规则
使用默认参数时,请记住以下重要规则与最佳实践:
**(1)默认参数必须写在函数声明中 **
默认参数只能出现在函数声明(原型)里。如果函数的声明与定义分开,则默认值应放在声明处,而不是定义处。
示例:
cpp
// 声明:带默认参数
void func(int x = 10);
// 定义:不再写默认参数
void func(int x)
{
cout << "Value: " << x << endl;
}(2)默认参数不能被修改
一旦在声明中指定了默认参数,就不能在函数定义里再次修改。如果在定义处尝试给出不同的默认值,编译器会报错。
cpp
// 声明
void f(int a = 10);
// 错误:定义处试图修改默认值
void f(int a = 222)
{
// 语句
}(3)默认参数必须从右向左依次给出
对于有多个参数的函数,带默认值的形参必须位于形参列表的最右侧。也就是说,如果某个参数有了默认值,那么它右边的所有参数都必须也有默认值。
cpp
// 合法
void func(int x, int y = 20);
// 非法:y 没有默认值,却出现在带默认值参数的左边
void func(int x = 10, int y);(4)函数重载时可能产生歧义
如果利用默认参数对函数进行重载,必须确保调用时编译器能够唯一地匹配,否则会产生二义性错误。
cpp
// 合法
void f(int a = 10, int b = 20);
// 错误:与上一个函数签名相同(仅靠修改默认值无法区分)
void f(int a = 22, int b = 2);
// 错误:与第一个函数在只传一个参数时无法区分
void f(int a);
// 错误:语法本身就非法(参数 b 缺少类型)
void f(int a, b)内联函数
C++ 中的内联函数,内联函数是 C++ 中的一种函数,其代码在编译时会在调用点展开,从而减少函数调用的开销。
inline 关键字建议将函数调用替换为函数体代码以降低开销。
但内联只是"请求",编译器可以拒绝。
如果函数体内出现循环、递归、static 变量、switch/goto、non-void 函数缺少 return 语句,编译器通常会放弃内联。
c
#include <stdio.h>
// 内联函数:计算两数之和
inline int getSum(int a, int b)
{
return a + b;
}
int main()
{
int num1 = 5, num2 = 10;
// 调用内联函数
int result = getSum(num1, num2);
// 输出结果
printf("Sum: %d\n", result);
return 0;
}
运行结果
Sum: 151. 内联函数的必要性
函数调用需要保存返回地址、传递参数、恢复现场等操作,这些开销对于体积小且被频繁调用的函数来说可能非常显著。
内联函数通过把函数体直接"展开"到调用处,省去了上述步骤,从而提升效率。
只有当"函数调用本身的开销"大于"函数体内代码的执行时间"时,使用内联才有实际意义。
2. 内联函数的行为特征
(1). 内联函数在编译阶段将其函数体"展开"到调用处,不会生成独立的符号。
(2). 是否真正内联由编译器决定,它可以拒绝内联请求。
(3). 若函数未被内联,就会生成一份实体定义;当该定义出现在头文件并被多个源文件包含时,可能引发"多重定义"链接错误。
(4). C++ 规定:完全相同的 inline 函数可以出现在多个翻译单元中,因此把它们写在头文件里、用于模板或类定义时都是安全的。
3.类中的内联函数
(1) 在类体内给出完整定义的函数自动成为隐式内联函数,因此所有内联限制对它们同样适用。
(2) 如果想"显式"地把某个成员函数声明为内联,可先在类内只给出声明,然后在类外定义时加上 inline 关键字。
示例
cpp
#include <iostream>
using namespace std;
class A {
public:
// 仅声明
inline int square(int x);
};
// 类外定义并显式指定为内联
inline int A::square(int x) {
return x * x;
}
int main() {
A obj;
cout << obj.square(3); // 输出 9
return 0;
}4.虚函数能否内联?
虚函数在运行期根据对象的实际类型动态解析,而内联是在编译期把函数体直接展开。
由于编译期无法确定最终调用的是哪个虚函数版本,因此无法实现内联。
简言之:运行期解析与编译期展开冲突,导致虚函数无法被内联。
5. 内联函数与宏的对比
在 C++ 中,内联函数和宏都能减少函数调用开销、提升执行速度,但两者在行为上有本质区别。内联函数具备更好的安全性与作用域控制,而宏只是简单的预处理替换。主要差异如下:
| 方面 | 内联函数 | 宏 |
|---|---|---|
| 定义方式 | 使用 inline 关键字定义的函数 |
使用 #define 定义的预处理指令 |
| 作用域与类型检查 | 遵循函数的作用域规则,由编译器做类型检查 | 无作用域概念,也不做类型检查,仅做纯文本替换 |
| 实参求值 | 实参仅被求值一次 | 实参在替换后的表达式里可能被多次求值 |
| 处理阶段 | 由编译器处理 | 由预处理器处理 |
| 访问类私有成员 | 可以访问类的私有成员 | 无法访问类的私有成员 |
| 执行开销 | 编译器可视情况拒绝内联(如函数体过大) | 总是被无条件地展开替换 |
| 递归 | 支持递归调用 | 不支持递归 |
Lambda 表达式
C++ 中的 Lambda 表达式。C++11 引入了 lambda 表达式,用来定义"即用即弃"的小段内联函数,通常不需要名字。它们最常作为回调函数出现在 STL 算法里。
示例:
cpp
#include <iostream>
using namespace std;
int main() {
// 定义一个 lambda:把输入的整数翻倍
auto res = [](int x) {
return x + x;
};
// 调用 lambda
cout << res(5); // 输出 10
return 0;
}上面的 lambda 接受一个整数 x,返回 x + x。res(5) 的结果为 10,即把 5 翻倍。
1.语法
rust
[capture-clause] (parameters) -> return-type {
// 函数体
}(1).返回类型(Return Type )
编译器通常能自行推导出返回类型,一般不必显式写出;但在复杂情况(如条件分支返回不同类型)下需手动指定。
(2).参数列表(Parameters )
与普通函数参数完全一致。
(3).捕获列表(Capture Clause )
lambda 比普通函数更强大:可通过捕获列表访问外层作用域的变量。三种常见方式:
[&]:全部外部变量按引用捕获[=]:全部外部变量按值捕获[a, &b]:a按值捕获,b按引用捕获
若捕获列表为空 [],则只能使用 lambda 内部自建的局部变量。
示例程序
cpp
#include <iostream>
#include <vector>
using namespace std;
void print(vector<int> v) {
for (auto x : v) cout << x << " ";
cout << endl;
}
int main() {
vector<int> v1, v2;
// 全部按引用捕获
auto byRef = [&](int m) {
v1.push_back(m);
v2.push_back(m);
};
// 全部按值捕获(此处代码仍用 [&] 实为引用,注释应为笔误)
auto byVal = [&](int m) {
v1.push_back(m);
v2.push_back(m);
};
// 分别指定捕获方式
auto mixed = [&v1, &v2](int m) {
v1.push_back(m);
v2.push_back(m);
};
byRef(20); // 往原 v1、v2 各推 20
byVal(234); // 同上(因仍是引用)
mixed(10); // 再往原 v1、v2 各推 10
print(v1); // 20 234 10
print(v2); // 20 234 10
return 0;
}运行结果
20 234 10
20 234 10 补充说明
若真的按值捕获 [=],默认情况下捕获的变量在 lambda 体内是 const,需要修改时应加上 mutable 关键字,例如:
cpp
[=](int m) mutable { /* 可修改按值捕获的副本 */ }2.示例
Lambda 表达式在 STL 中被广泛用作"回调"------也就是当作参数传递的小函数。下面通过两个例子说明:
示例 1:将 vector 降序排序
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> v = {5, 1, 8, 3, 9, 2};
// 用 lambda 按降序排序
sort(v.begin(), v.end(), [](const int& a, const int& b) {
return a > b;
});
for (int x : v)
cout << x << " "; // 9 8 5 3 2 1
return 0;
}示例 2:查找第一个能被 3 整除的元素
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> v = {5, 1, 8, 3, 9, 2};
// 用 lambda 查找第一个 %3==0 的元素
auto it = find_if(v.begin(), v.end(), [](const int& a) {
return a % 3 == 0;
});
if (it != v.end()) cout << *it; // 输出 3
else cout << "No such element";
return 0;
}3.应用场景
Lambda 表达式诞生的初衷,就是"用内联、匿名的定义"取代各种回调函数。以下是 C++ 中 lambda 最常见的用武之地:
-
内联匿名函数
在需要的地方当场写一小段逻辑,无需费心起名字。
-
STL 算法
把自定义的比较、变换逻辑直接塞进
sort、for_each、find_if等算法。 -
回调与事件处理
异步操作或 GUI 事件需要回调时,直接写 lambda,不用再单独声明函数。
-
多线程与并发
创建线程时顺手扔一个 lambda 进去,快速完成一次性小任务。
-
容器的自定义比较器
为
priority_queue、set、map等容器提供"即席"排序规则,无需另写类或函数对象。