缓存可以说是计算机领域最伟大的发明之一,
经常会有人问,缓存是越多越好么?
一般人们都会斩钉截铁的回答不是。
至于为什么?
往往无法直觉回答了,可能会从缓存一致性,空间占用等几个角度逐一分析。
今天就来看看由于一致性导致的缓存问题。
在之前的文章中,我们聊过JMM java的内存模型(一定要有所了解,不太清楚的同学可以看下前文链接https://www.cnblogs.com/jilodream/p/9452391.html),可以知道线程并不是直接读写内存,而是调用线程自己的工作空间。
但这只是一个逻辑模型,线程我们可以理解为cpu的核心,工作空间所对应的位置一般是指cpu的缓存。就像下图这样:
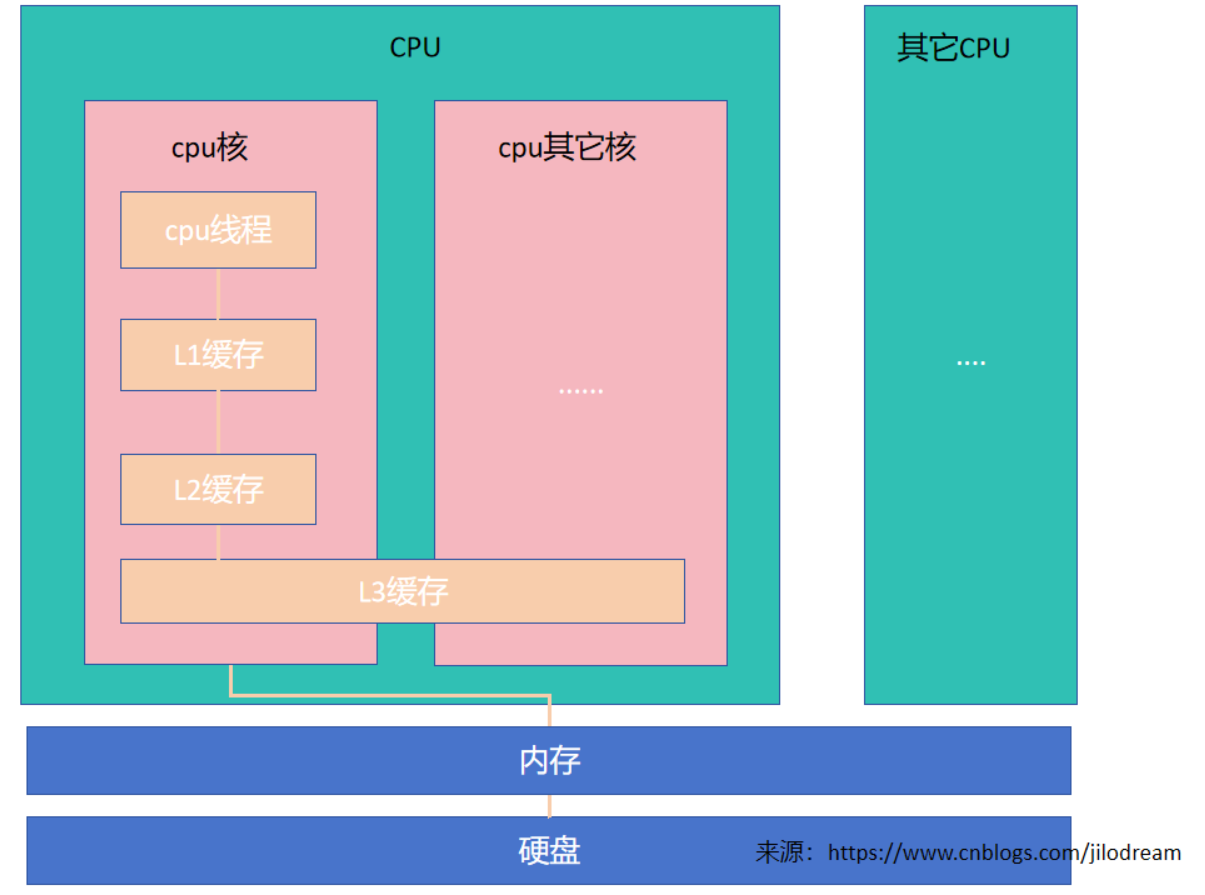
目前主流的cpu就是每个核心有自己的多级缓存,一般还会加一个共享缓存,
越靠近核,缓存越小,但越快,成本也越大。
java线程实际对应的就是这个核,工作空间对应的就是这个缓存。
如果你详细思考,就会考虑到缓存中的数据时如何加载变量的。毕竟变量又长有短,如何加载定位的?
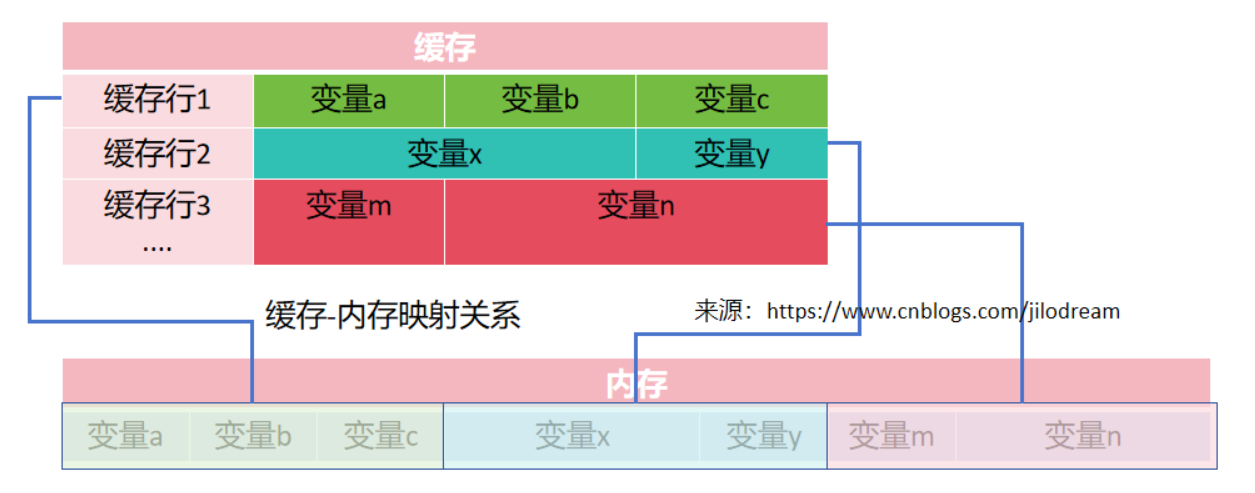
一般来说,我们将内存划分成若干的块,(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )每一块是64个字节(主流是这个大小)
同时我们将缓存划分成若干的缓存行,也是64个字节。
cpu每次加载时,不是按照某个变量加载,而是将已经划分好的整块内容直接加载到缓存行中。因为从数据的使用经验来看,一般我们在使用某个变量时,很大可能会使用邻近变量,这种缓存的预判加载,提高了缓存的命中率。
有小伙伴会有疑问,会不会不同核的缓存行加载的数据跨了内存块了,也就是A核的缓存行是 xyz变量,B核的缓存行是yza变量。这是不会的,缓存块是根据内存的地址和偏移量划分好的,不会根据不同核来划分不同的边界的。
做过缓存设计的同学肯定知道,在设计时一定要考虑数据一致性的问题。如果多份缓存以及主存之间的数据不一致,就无法并发处理,无法得到准确的结果。
(ps,cpu一般是通过MESI缓存一致性协议并且配合失效缓存队列等等来实现的,感兴趣的读者可以查下相关内容)
从前文中的java内存模型中可以知道,当volatile变量发生变化时,java通过内存屏障,来强制失效其它cpu核心中缓存。
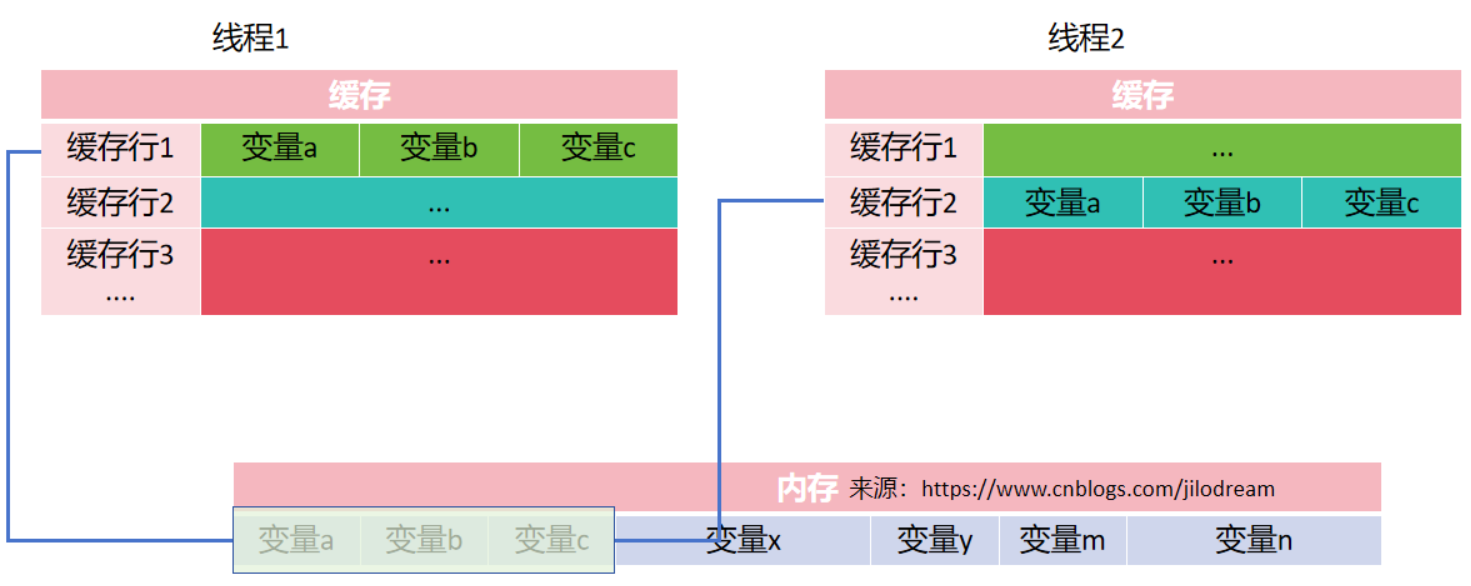
但是在真实情况下,cpu是按照行来缓存变量的,而不是单个变量,此时标记失效的就是整个缓存行。那么就会出现类似一个情况:
线程1操作变量a,线程2操作变量b,根据缓存的加载机制
(1)两者的均加载同一段缓存行。
(2)当线程1 修改完变量a时,通知其它线程失效该缓存行
(3)线程2修改变量b,发现缓存行失效,重新加载缓存行,修改完变量b后,重新知会其它线程该行已经失效
这样当线程1每次修改变量a,线程2每次修改变量b时,当前缓存都不断的需要重新加载,本质上已经失去了缓存的意义,还增加了缓存状态控制,缓存重新加载的开销。
这种在相同的缓存行的多个变量,但是由于并发原因,导致缓存不断失效,无法利用缓存读取变量的场景,我们就称之为伪共享。(False Sharing)
这种情况其实不仅仅是java,其它语言,甚至是多缓存的业务,都会有类似的问题。
即由于并发引起的缓存联动失效,即使对我当前业务没有实际影响,但是由于缓存一致性的协议设计,我们判断当前缓存已经脏了。我们就需要重新加载。缓存的优势丧失,成本却被无限放大。
就像下边这个例子:
缓存类:
1 public class CacheA {
2 volatile int a;
3
4 volatile int b;
5 }线程类:
1 public class Main {
2 private static CacheA cache = new CacheA();
3 private static final int TOTAL = 1000000;
4
5 public static void main(String[] args) {
6 Runnable r1 = new Runnable() {
7 @Override
8 public void run() {
9 long startTime = System.currentTimeMillis();
10 for (int i = 0; i < TOTAL; i++) {
11 cache.a = (i-99999)*(i+99999);
12 }
13 long endTime = System.currentTimeMillis(); // 结束时间(毫秒)
14 long cost = endTime - startTime; // 耗时(毫秒)
15
16 System.out.println("方法耗时1: " + cost + " 毫秒");
17 }
18 };
19
20 Runnable r2 = new Runnable() {
21 @Override
22 public void run() {
23 long startTime = System.currentTimeMillis();
24 for (int i = 0; i < TOTAL; i++) {
25 cache.b =(i-99999)*(i+99999);
26 }
27 long endTime = System.currentTimeMillis(); // 结束时间(毫秒)
28 long cost = endTime - startTime; // 耗时(毫秒)
29
30 System.out.println("方法耗时2: " + cost + " 毫秒");
31 }
32 };
33
34 Thread t1=new Thread(r1);
35 t1.start();
36
37 Thread t2=new Thread(r2);
38 t2.start();
39 }
40 }代码逻辑是两个线程并发修改两个变量,这两个变量在同一个实例里边。
输出结果是这样的:
Connected to the target VM, address: '127.0.0.1:58237', transport: 'socket'
方法耗时2: 19 毫秒
方法耗时1: 22 毫秒
Disconnected from the target VM, address: '127.0.0.1:58237', transport: 'socket'
Process finished with exit code 0我们来修改代码,加上很多无效的变量,重新执行,
缓存类:
1 public class CacheB {
2 volatile int a;
3 long temp1=0;
4 long temp2=0;
5 long temp3=0;
6 long temp4=0;
7 long temp5=0;
8 long temp6=0;
9 long temp7=0;
10
11 volatile int b;
12 }线程类:
1 public class Main {
2 private static CacheB cache = new CacheB();
3 private static final int TOTAL = 1000000;
4
5 public static void main(String[] args) {
6 Runnable r1 = new Runnable() {
7 @Override
8 public void run() {
9 long startTime = System.currentTimeMillis();
10 for (int i = 0; i < TOTAL; i++) {
11 cache.a = (i-99999)*(i+99999);
12 }
13 long endTime = System.currentTimeMillis(); // 结束时间(毫秒)
14 long cost = endTime - startTime; // 耗时(毫秒)
15
16 System.out.println("方法耗时1: " + cost + " 毫秒");
17 }
18 };
19
20 Runnable r2 = new Runnable() {
21 @Override
22 public void run() {
23 long startTime = System.currentTimeMillis();
24 for (int i = 0; i < TOTAL; i++) {
25 cache.b =(i-99999)*(i+99999);
26 }
27 long endTime = System.currentTimeMillis(); // 结束时间(毫秒)
28 long cost = endTime - startTime; // 耗时(毫秒)
29
30 System.out.println("方法耗时2: " + cost + " 毫秒");
31 }
32 };
33
34 Thread t1=new Thread(r1);
35 t1.start();
36
37 Thread t2=new Thread(r2);
38 t2.start();
39 }
40 }执行结果如下:
Connected to the target VM, address: '127.0.0.1:58389', transport: 'socket'
方法耗时1: 10 毫秒
方法耗时2: 10 毫秒
Disconnected from the target VM, address: '127.0.0.1:58389', transport: 'socket'
Process finished with exit code 0是不是很神奇,我们给一个对象加了很多无用的变量,它居然变快了。而且性能还提升了不少。
这个优化的核心思路就是通过强制指定内存相对位置,将不相关的变量强制分配到不同的缓存行上,让缓存行不会因为当前不使用的缓存而被强制失效。
很多人也喜欢这样子写:
private volatile long value;
private long p1, p2, p3, p4, p5, p6, p7;通过手动补齐剩余字节,确保当前变量尽可能在一个缓存行上。
但是这样子写代码就很不方便了,(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )我们要增加很多无意义的字段,或者通过其它变量穿插起来。很容易被别人误改,误删,也影响代码最重要的阅读性。
因此java在8及以上的版本,增加了一个注解@Contended
Contended
美kənˈtend 英kən'tend
v.竞争;认为;争夺
这个注解既可以用在类上,也可以用在变量上代码如下:
缓存类:
1 import jdk.internal.vm.annotation.Contended;
2
3 /**
4 * @discription
5 */
6 public class CacheC {
7 @Contended
8 volatile int a;
9
10 @Contended
11 volatile int b;
12 }线程执行类:
1 public class Main {
2 private static CacheC cache = new CacheC();
3 private static final int TOTAL = 1000000;
4
5 public static void main(String[] args) {
6 Runnable r1 = new Runnable() {
7 @Override
8 public void run() {
9 long startTime = System.currentTimeMillis();
10 for (int i = 0; i < TOTAL; i++) {
11 cache.a = (i-99999)*(i+99999);
12 }
13 long endTime = System.currentTimeMillis(); // 结束时间(毫秒)
14 long cost = endTime - startTime; // 耗时(毫秒)
15
16 System.out.println("方法耗时1: " + cost + " 毫秒");
17 }
18 };
19
20 Runnable r2 = new Runnable() {
21 @Override
22 public void run() {
23 long startTime = System.currentTimeMillis();
24 for (int i = 0; i < TOTAL; i++) {
25 cache.b =(i-99999)*(i+99999);
26 }
27 long endTime = System.currentTimeMillis(); // 结束时间(毫秒)
28 long cost = endTime - startTime; // 耗时(毫秒)
29
30 System.out.println("方法耗时2: " + cost + " 毫秒");
31 }
32 };
33
34 Thread t1=new Thread(r1);
35 t1.start();
36
37 Thread t2=new Thread(r2);
38 t2.start();
39 }
40 }同时我们要在jdk 启动时配上虚拟机参数:
-XX:-RestrictContended
这个配置参数表示启用Contended注解
同时IDEA等(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )工具还会提示我们在配置中开启编译选项开关,允许代码访问jdk内部/隐藏的api
--add-exports java.base/jdk.internal.vm.annotation=ALL-UNNAMED使用注解后,执行结果如下
Connected to the target VM, address: '127.0.0.1:56688', transport: 'socket'
方法耗时2: 11 毫秒
方法耗时1: 12 毫秒
Disconnected from the target VM, address: '127.0.0.1:56688', transport: 'socket'和手动补齐的速度差不多。
手动补齐易于控制,但是影响代码阅读,交给虚拟机自动补齐。
通过注解交给jvm来强制填充隔离,又因为是内部API,不保证稳定性,因此大家根据自己情况来选用。