目录
模仿玩家习惯的AI系统------GoCap
更拟人的AI
游戏AI通常并不以"变得不可战胜"为目的,而是朝着"更加有趣"的方向努力,就像PVP游戏中玩家匹配到不同的对手那样提供丰富体验。如果游戏AI也能像不同玩家一样就好了,可还是用设计行为树的方式来制定不同的AI的话,一定需要不少的代码吧。目前也有基于神经网络的游戏AI,但其训练往往需要大量的数据和时间,并且难以调试。
不过,基于机器学习的AI的确是个不错想法,它不依赖固定的规则,而是让AI自行从数据中总结出规则。在 Steve Rabin 主编的《AI Game Programming Wisdom》11.3 章节中就提到了一种名为 GoCap(游戏观测捕捉) 的简单机器学习方法,类似人工智能层面的"动捕",可以通过观测玩家的操作来训练AI,使AI能在相似条件下做出该玩家类似的决策。
不必担心,GoCap 的思想并不复杂,代码实现也不长,即便你从来没学过机器学习也一定能够理解。其决策过程也不黑盒(在了解原理后你就明白了),只不过要想将它结合进具体游戏中,需要你对该游戏玩法的代码逻辑有足够了解,也需要你代入玩家视角......话不多说,直接进入正题吧。
GoCap的运行
GoCap的原理很简单,它能模仿玩家的行为,只是事先记录 下了玩家执行行为时频繁身处的环境状况 。在自行决策时,就时时读取当前游戏的环境状况 ,当前状况符合事先频繁记录的状况,就执行那个行为。比如,有个玩家在喝血瓶回血,10次有9次都是自身血量在20%-40%时进行的,那么GoCap所训练出来的AI就也会在自身血量到20%-40%时进行喝血瓶的动作。
这并不难理解,但GoCap是怎么做的呢?
训练
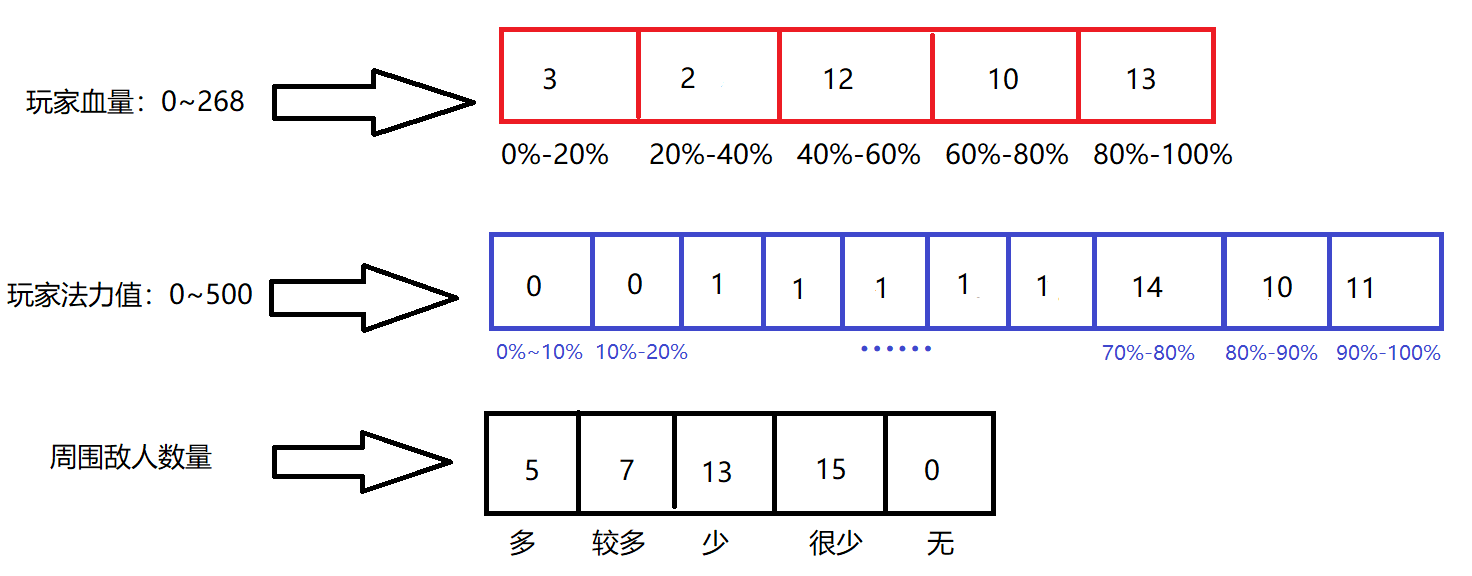
我们要事先将「环境状况」细分与量化 成各种 「规则」,所谓规则就是会单个会影响玩家决策的游戏变量,比如玩家自身的血量、敌人的血量、敌人的数量等等。
将不同的「规则」分别与一个int类型的数组进行对应 ,数组的每一个位置都对应那种变量的一种情况。比如我们可以将玩家血量对应一个长度为5的数组,每个位置代表着20%的血量区间;玩家的蓝量对应一个10长度的数组,每个位置就代表10%的蓝量区间:

我们称这样的数组为 「映射表」 。 但具体要怎么进行映射呢?很简单,给每个数组都配套一个 「映射函数」,比如上图的3中变量,就可以这样:
csharp
//衡量血量,将具体的血量值转化成对应数组的下标
int EvaluateHP(float curHP)
{
float condition = curHP / MaxHP; //获取当前血量百分比
//将血量百分比以20%为一个区间进一步划分
return (int)(condition / 0.2f);
}
//衡量法力值,将具体的法力值转化成对应数组的下标
int EvaluateMP(float curMP)
{
float condition = curHP / MaxHP; //获取当前血量百分比
//以10%为一个区间进一步划分
return (int)(condition / 0.1f);
}
//将具体的敌人数量转化成5种情况
int EvaluateEnemyCount(int enemiesCount)
{
if(enemiesCount == 0)
{
return 0; //0个敌人,对应“无”情况
}
else if(enemiesCount == 1)
{
return 1;//1个敌人对应“很少”
}
else if(enemiesCount > 1 && enemiesCount < 4)
{
return 2;//2~3个敌人对应“少”
}
else if(enemiesCount >= 4 && enemiesCount < 7)
{
return 3;//4~6个敌人对应“多”
}
else
{
return 4;//大于等于7个敌人对应“很多”
}
}可以看到,这些函数都比较朴实,其实它们没有固定的写法,只要能正确地映射到所对应的数组的下标就行。什么,你问能不能让血量也按10%的区间划分,变成长度为10的数组?当然可以!划分长度与对应函数的划分规则,纯粹出于开发者个人意愿。
接下来,我们就要将「规则」与玩家的行为挂钩,玩家的行为本质就是那些最基本玩法相关的函数,比如攻击、跳跃、翻滚等等。
但GoCap怎么知道动作与哪些「规则」有关呢?就比如它怎么知道玩家喝血瓶这一动作与玩家自身血量相关呢?很遗憾,它并不知道,需要我们人为设置,后续实现部分,我们会在「行为」相关的类中,设置一个「规则」集合,开发者自己将相关的「规则」加入到这个集合中。(这就是为什么开头说"需要代入玩家视角",但这也让它的决策更可控不是吗
我们可以在玩家调用这些动作函数时,将当前环境映射进动作相关的「规则」里,并在它们所处的数组位置中进行+1计数。比如,先前表示玩家血量状况的数组,初始这个数组上的值都是0,我们事先在玩家喝血瓶相关的函数里加点"小巧思",这样一来每次玩家喝血瓶就可以进行一次标记了:
csharp
void DrinkBlood()
{
if(actorState == GoCapState.Train)
{
int index = EvaluateHP(curHP);
hpClusterMap[index]++;
}
//正常的喝血瓶逻辑
……
}现在玩家的血量为36%,玩家喝了一次血瓶,那么我们就将代表着20%~40%的元素+1。玩家喝了N次血瓶后,这个数组变成了这样:

这就是GoCap在训练阶段唯一需要做的事情,很简单不是嘛!什么,你说如果一个行为与多个「规则」挂钩怎么办?也简单,分别进行映射并让它们都进行计数+1就可以了。比如玩家的攻击动作与自身的血量、法力值、当前敌人数都相关的话,就可以这样:
csharp
void Attack()
{
if(actorState == GoCapState.Train)
{
int index = EvaluateHP(curHP);
hpClusterMap[index]++;
index = EvaluateMP(curMP);
mpClusterMap[index]++;
index = EvaluateEnemyCount(enemiesCount);
enemyClusterMap[index]++;
}
//正常的攻击逻辑
……
}记录了玩家N次攻击后,这个数组变成了这样:
决策
那标记完这些数组后,要怎么用来决策呢?我们已知每个行为都有一系列「规则」,我们将它们放在一个容器(比如数组)里,而角色也有多种行为,我又将这些行为放在一个容器(比如数组)里。在进行决策时就遍历行为,看看每个行为所需的「规则」用当前的环境变量映射后所在的映射表下标元素计数是否达到了上限,如果每个规则都满足,那这个行为就添加进备选名单。
比如,现在训练完后的GoCap角色进行了自主决策,当前环境状况是这样的:

对于攻击这一行为,很明显每个「规则」映射后的位置上值都大于等于10,所有规则都满足,将攻击动作加入备选名单。如果还有其它行为也满足条件,就也将其也加入备选名单。
该选择那个动作来执行呢?这需要我们根据具体游戏设计一个具体的启发函数来对它们的重要性进行比较,选出最合适的进行执行。这其实是不小的挑战,而且它因游戏而异,没有固定的写法,这里就暂且不提。
总之,GoCap的决策就是先遍历角色所有的行为,哪个行为下所有的规则都满足(即计数达到了指定上限)了,就加入备选名单,最后从备选名单中选出最合适的来执行。
但要注意,并不是 说数组中的某个元素被标记到>=10时就停止训练了,不然我们就只能记录到玩家的一种情况下习惯了,只是说可以给标记次数设个上限值,不需要让数值一直增长。真正用于判断AI是否训练完成的标准只有一个,那就是让它自行运行,看看是否与玩家的操作是否类似,这很主观但也很直接。
GoCap的实现
GoCap的代码实现,可以分为3个部分,由小到大分别是:GoCap_Rule(规则)、GoCap_Behavior(行为)、GoCap_Actor(角色)。
其中,规则,用于描述某项具体的会影响玩家某些操作的因素,比如玩家自身血量情况会影响玩家的很多操作,我们就可以单独设计一个用于衡量血量的规则。
规则主要包含映射表、训练标记上限和用于将具体值转化为映射表下标的函数。转化函数的设计并没有固定形式,我们用返回int值的委托来表示,在初始化时传入,这样就可以定义不同转化函数的规则了。(可以看看示例)
csharp
using System;
using UnityEngine;
[Serializable]
public class GoCap_Rule
{
[SerializeField] protected int[] clusterMap; //映射表
private readonly int trainLimit; //训练极限,当计数大于等于该值时,视为训练完毕
private readonly Func<int> evaluateCondition; //将具体规则相关的值,化成映射表的下标的函数
/// <summary>
/// 初始化行为所需的规则(之一)
/// </summary>
/// <param name="mapLen">映射表的长度(分辨率)</param>
/// <param name="trainLimit">训练完成的所需的次数</param>
/// <param name="evaluateFunc">该规则的评估函数</param>
public GoCap_Rule(int mapLen, int trainLimit, Func<int> evaluateFunc)
{
clusterMap = new int[mapLen];
this.trainLimit = trainLimit;
evaluateCondition = evaluateFunc;
}
/// <summary>
/// 复制一个与copyRule一样的新的规则出来(映射表不共享,以便独立标记)
/// </summary>
/// <param name="copyRule">被复制的规则</param>
public GoCap_Rule(GoCap_Rule copyRule)
{
clusterMap = new int[copyRule.clusterMap.Length];
Array.Copy(copyRule.clusterMap, clusterMap, clusterMap.Length);
trainLimit = copyRule.trainLimit;
evaluateCondition = copyRule.evaluateCondition;
}
/// <summary>
/// 根据当前目标增加训练标记
/// </summary>
public void Reinforce()
{
int index = evaluateCondition();
if(clusterMap[index] < trainLimit)
{
++clusterMap[index];
}
}
/// <summary>
/// 当前目标是否满足条件
/// </summary>
public bool IsFired()
{
int index = evaluateCondition();
return clusterMap[index] == trainLimit;
}
}行为,包含一个规则的集合和一个行动对应的函数,代表着如果规则集合中的规则全都满足 的情况下,就执行这个行动函数。但在这里有个小技巧,使用一个int类型的id来代替具体的函数,在外部用id来匹配到对应的函数。
为什么要多此一举呢?因为这可以增加复用性,比如我们想让两个有着不同攻击方式的怪,共同使用一种GoCap的AI,我们就可以指定攻击行为的id为0,而这两个怪再收到行为返回0后,就各自掉用自己的攻击函数,省去了构建两个大同小异的攻击行为。
具体实现如下:
csharp
using System;
using System.Collections.Generic;
using UnityEngine;
[Serializable]
public class GoCap_Behavior
{
[SerializeField] private List<GoCap_Rule> ruleSet;//规则集合
[SerializeField] private int behaviorId;//行为id
public GoCap_Behavior(int behaviorId)
{
ruleSet = new List<GoCap_Rule>();
this.behaviorId = behaviorId;
}
public GoCap_Behavior(int behaviorId, List<GoCap_Rule> ruleSet)
{
this.ruleSet = ruleSet;
this.behaviorId = behaviorId;
}
/// <summary>
/// 添加规则
/// </summary>
public void AddRules(params GoCap_Rule[] rules)
{
for(int i = 0; i < rules.Length; ++i)
{
ruleSet.Add(rules[i]);
}
}
/// <summary>
/// 标记当前规则集合(用于训练阶段)
/// </summary>
public void Reinforce()
{
for(int i = 0; i < ruleSet.Count; ++i)
{
ruleSet[i].Reinforce();
}
}
/// <summary>
/// 判断规则是否全符合,返回行为ID
/// </summary>
/// <returns>id为-1,则表明规则未能通过</returns>
public int Fire()
{
return IsAllRulesFired() ? behaviorId : -1;
}
private bool IsAllRulesFired()
{
for(int i = 0; i < ruleSet.Count; ++i)
{
if(!ruleSet[i].IsFired())
{
return false;
}
}
return ruleSet.Count != 0;
}
}最后就是角色了,角色其实只需要一个行为集合就行了,它包含所有这个角色会用到的行为。但有时,同一时刻下,会有多个行为都满足了条件,我们就需要将它们都记录下来,再根据具体游戏类型定制一个启发式函数来从它们中选出最优先的来执行。
csharp
using System;
using System.Collections.Generic;
using UnityEngine;
public enum GoCapState
{
//GoCap角色的状态:玩家控制、自动控制、训练
Player, Auto, Train
}
[Serializable]
public class GoCap_Actor
{
public List<int> firedBehaviors;
[SerializeField] private List<GoCap_Behavior> behaviorList;
public GoCap_Actor()
{
behaviorList = new List<GoCap_Behavior>();
firedBehaviors = new List<int>();
}
public void AddBehavior(params GoCap_Behavior[] newBehaviors)
{
for(int i = 0; i < newBehaviors.Length; ++i)
{
behaviorList.Add(newBehaviors[i]);
}
}
/// <summary>
/// 进行自动决策,遍历行为列表,将符合条件的加入到firedBehaviors
/// </summary>
public void Decide()
{
firedBehaviors.Clear();
for(int i = 0, res; i < behaviorList.Count; ++i)
{
res = behaviorList[i].Fire();
if(res != -1)
{
firedBehaviors.Add(res);
}
}
}
/// <summary>
/// 通过id,对指定行为进行训练
/// </summary>
/// <param name="behaviorId">行为id</param>
public void Train(int behaviorId)
{
behaviorList[behaviorId].Reinforce();
}
}示例:石头剪刀布游戏
石头剪刀布本质上是一个零和博弈,从规则来看,胜负和概率完全均等。但在实际游戏中,玩家在出拳时往往有各种非随机的习惯与偏差。
就用这个众所周知的游戏,来制作一个使用GoCap来预测玩家出拳习惯的AI对手吧。
我所考虑的规则有如下所示7种,行为毫无疑问总共3种:出石头、出布、出剪刀,每个行为我都让它与这7个规则挂钩。注意!不同的规则可以有不同的训练标记上限值,这里只是对猜拳来说没太大影响,才都用trainEndTime的。
csharp
//与规则相关的变量
private int lastPlayerRes; //上次玩家出的种类
private int lastEnemyRes; //上次敌方出的种类
private int drawCount; //连续平均数量
private int winCount; //连续获胜的数量
private int loseCount; //连续输的数量
private int[] selfTpyeCount = new int[3]; //连续出指定类型种类的次数
private int[] enemyTpyeCount = new int[3]; //连续出指定类型种类的次数
private void Awake()
{
winType = new int[]{1, 2, 0};//对应出拳类型的克制类型,用于输出克制的结果
actor = new GoCap_Actor();
//规则
var lastPlayerOut = new GoCap_Rule(3, trainEndTime, () => {return lastPlayerRes;});
var selfcontRock = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, selfTpyeCount[0]);});
var selfcontPaper = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, selfTpyeCount[1]);});
var selfcontScissors = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, selfTpyeCount[2]);});
var lastEnemyOut = new GoCap_Rule(3, trainEndTime, () => {return lastEnemyRes;});
var enemycontRock = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, enemyTpyeCount[0]);});
var enemycontPaper = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, enemyTpyeCount[1]);});
var enemycontScissors = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, enemyTpyeCount[2]);});
var continueDraw = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, drawCount);});
var continueWin = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, winCount);});
var continueLose = new GoCap_Rule(6, trainEndTime, () => {return Mathf.Min(5, loseCount);});
//行为
var rock = new GoCap_Behavior(0);
rock.AddRules(new GoCap_Rule(lastPlayerOut), new GoCap_Rule(lastEnemyOut),
new GoCap_Rule(continueDraw), new GoCap_Rule(continueLose), new GoCap_Rule(continueWin),
new GoCap_Rule(selfcontRock), new GoCap_Rule(selfcontPaper), new GoCap_Rule(selfcontScissors));
var paper = new GoCap_Behavior(1);
paper.AddRules(new GoCap_Rule(lastPlayerOut), new GoCap_Rule(lastEnemyOut),
new GoCap_Rule(continueDraw), new GoCap_Rule(continueLose), new GoCap_Rule(continueWin),
new GoCap_Rule(selfcontRock), new GoCap_Rule(selfcontPaper), new GoCap_Rule(selfcontScissors));
var scissors = new GoCap_Behavior(2);
scissors.AddRules(new GoCap_Rule(lastPlayerOut), new GoCap_Rule(lastEnemyOut),
new GoCap_Rule(continueDraw), new GoCap_Rule(continueLose), new GoCap_Rule(continueWin),
new GoCap_Rule(selfcontRock), new GoCap_Rule(selfcontPaper), new GoCap_Rule(selfcontScissors));
//将行为添加到角色
actor.AddBehavior(rock, paper, scissors);
}在这个示例游戏中,我没有区分训练与自动运行,我让对手AI在还未训练完成时使用随机出拳,有符合条件时才使用GoCap,在游戏右侧会显示对手出拳的依据是Rand(随机)还是 GoCap:
游戏过程很简单,点左边选择出拳方式,点PK进行猜拳,如此往复(代码可以作证无作弊行为,对手决策和玩家决策是相互独立的,只是调用时机一样而已)。对手会在游玩过程中,慢慢摸透你的出拳习惯。
csharp
public void PlayerSelect(int res)
{
if(enemyImg.gameObject.activeSelf)
{
EnmeySelect();
enemyImg.gameObject.SetActive(false);
resFrom.gameObject.SetActive(false);
}
Player_Res = res;
}
private void EnmeySelect()
{
lastEnemyRes = Enemy_Res;
actor.Decide();
if(actor.firedBehaviors.Count == 0)
{
Enemy_Res = Random.Range(0, 3);
resFrom.text = "Rand";
}
else
{
Enemy_Res = winType[actor.firedBehaviors[Random.Range(0, actor.firedBehaviors.Count)]];
resFrom.text = "GoCap";
}
enemyImg.sprite = rpsType[Enemy_Res];
}