操作系统:Debian 12.5_x64 & Windows10_x64
rnnoise版本:0.2
gcc版本:12.2.0
python版本: 3.9.13
RNNoise是一个将传统数字信号处理与深度学习相结合的开源实时音频降噪库,可在消耗极少计算资源的情况下实现毫秒级降噪,今天整理下这方面的笔记,希望对你有帮助。
该库涉及算法的描述详见论文(一种混合 DSP/深度学习方法的实时全频带语音增强技术):
https://arxiv.org/pdf/1709.08243
如果打不开,可从文末提供的渠道获取该论文。
之前整理过如何使用 noisereduce 、 fft 和 Audacity 音频文件降噪,如有需要可参考:
https://www.cnblogs.com/MikeZhang/p/18313792/pynr20240720
一、编译及C使用示例
GitHub地址:
https://github.com/xiph/rnnoise
1、编译及文件说明
编译步骤如下:
./autogen.sh
./configure
make其中,执行 ./autogen.sh 时,会下载models文件(RNNoise 项目预训练的模型数据文件,如果下载过慢,可从文末提供的渠道获取):

rnnoise_data主要包含了项目预训练好的模型权重,使得用户在编译 RNNoise 后,无需自己从头训练模型,就能直接使用其降噪功能。
rnnoise_data文件里面是c代码及pth文件:

这里面有.c文件和.pth文件,其中:
.c 文件由.pth文件生成,存储预训练模型权重,将神经网络权重以C数组形式嵌入,供降噪算法直接调用,降噪时由 rnnoise_process_frame 等函数直接使用。
.pth 文件存储训练模型,用于模型研究、微调或重新训练,并非RNNoise运行时必需。
使用说明:
1)若只需使用RNNoise的降噪功能,关注编译好的库及API即可。
2)若需要优化模型或适配特殊场景,才需研究 .pth 文件及项目的训练脚本。
2、降噪效果验证
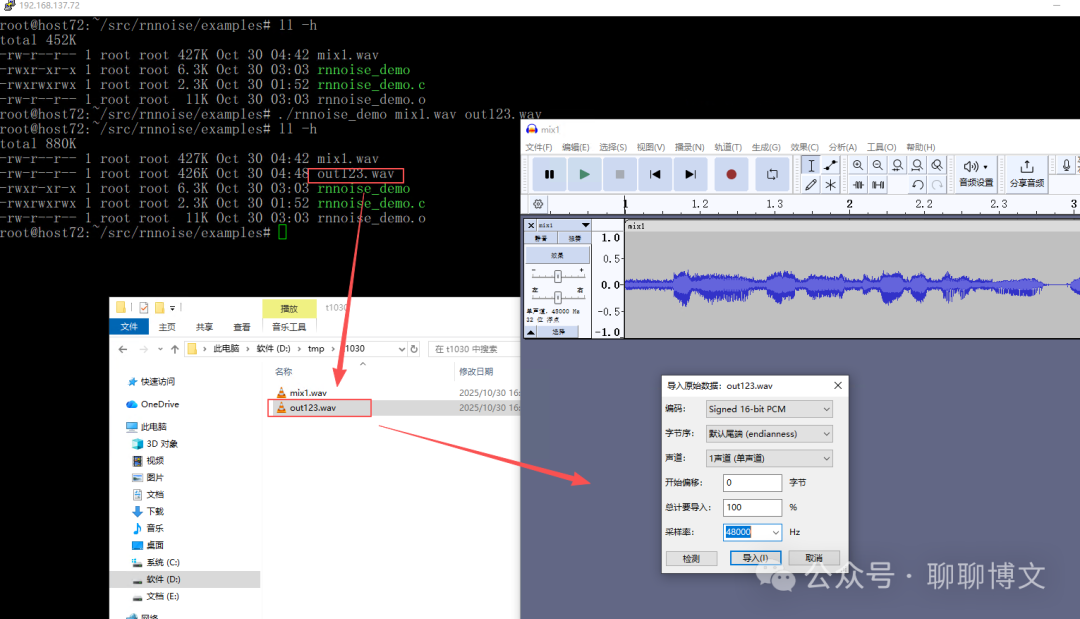
在examples目录里面有可直接运行的demo程序,需要准备s16le 48khz格式的音频文件。
输出为pcm格式的文件。
导入效果如下:
降噪效果如下:
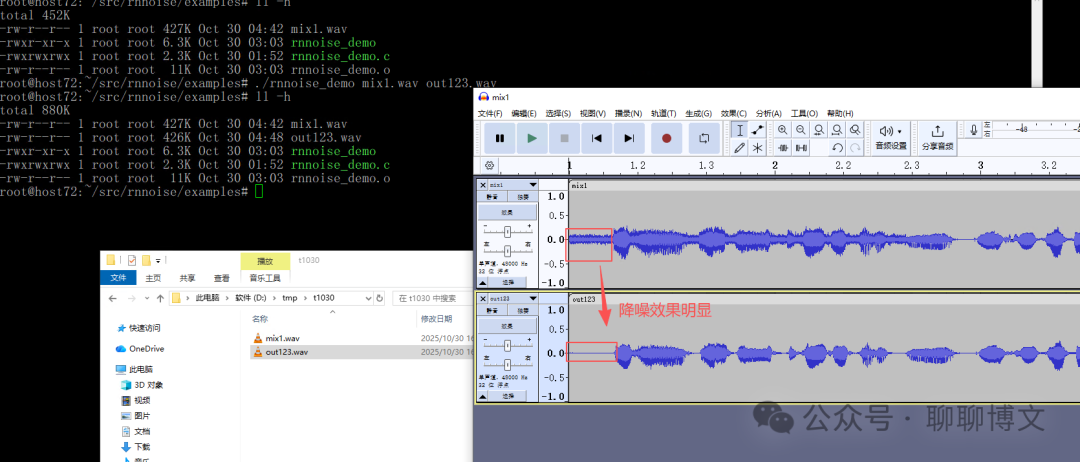
这里用的是Audacity软件查看降噪效果的,关于Audacity软件的使用,可参考这篇文章:
https://www.cnblogs.com/MikeZhang/p/audacity2022022.html
关于pcm音频的播放可参考这篇文章:
https://www.cnblogs.com/MikeZhang/p/pcm20232330.html
配套的音频文件可从如下渠道获取:
关注微信公众号(聊聊博文,文末可扫码)后回复 20251031 获取。
3、使用静态库二次开发
实际使用过程中,会涉及基于rnnoise库进行二次开发的情况,这里提供下简单示例。
基于rnnoise_demo.c修改的示例代码如下(test1.c):
#include <stdio.h>
#include "rnnoise.h"
#define FRAME_SIZE 480
int main(int argc, char **argv) {
int i;
int first = 1;
float x[FRAME_SIZE];
FILE *f1, *fout;
DenoiseState *st;
st = rnnoise_create(NULL);
if (argc!=3) {
fprintf(stderr, "usage: %s <noisy speech> <output denoised>\n", argv[0]);
return 1;
}
f1 = fopen(argv[1], "rb");
fout = fopen(argv[2], "wb");
while (1) {
short tmp[FRAME_SIZE];
fread(tmp, sizeof(short), FRAME_SIZE, f1);
if (feof(f1)) break;
for (i=0;i<FRAME_SIZE;i++) x[i] = tmp[i];
rnnoise_process_frame(st, x, x);
for (i=0;i<FRAME_SIZE;i++) tmp[i] = x[i];
if (!first) fwrite(tmp, sizeof(short), FRAME_SIZE, fout);
first = 0;
}
rnnoise_destroy(st);
fclose(f1);
fclose(fout);
return 0;
}编译命令如下:
g++ test1.c -o test1 -Iinclude -static libs/librnnoise.a也可写使用Makefile文件:
CC = g++
CFLAGS = -g -O2 -Wall
HDRS= -Iinclude
LIBS = -static libs/librnnoise.a
# g++ test1.c -o test1 -Iinclude -static libs/librnnoise.a
all:
make test1
test1:test1.o
$(CC) -o test1 test1.o $(LIBS)
clean:
rm -f test1
rm -f *.o
.c.o:
$(CC) $(CFLAGS) $(HDRS) -c -o $*.o $<编译及运行效果如下:
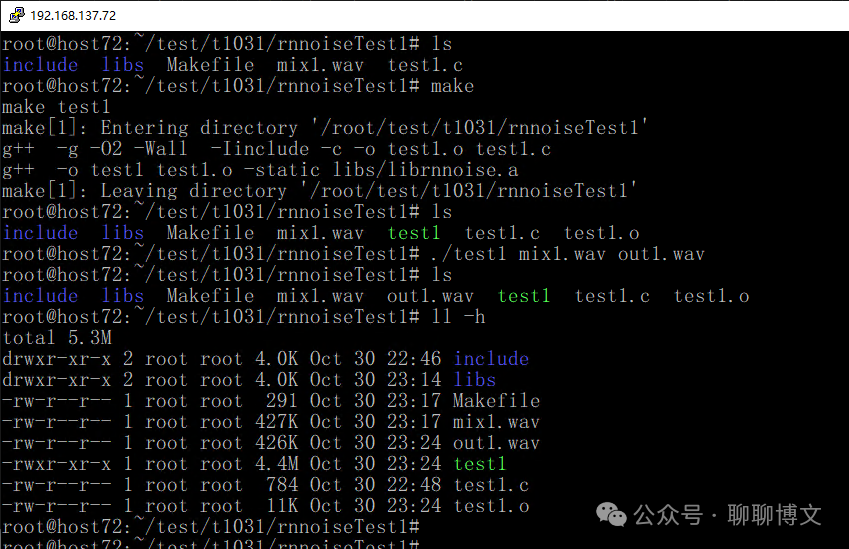
降噪效果如下:
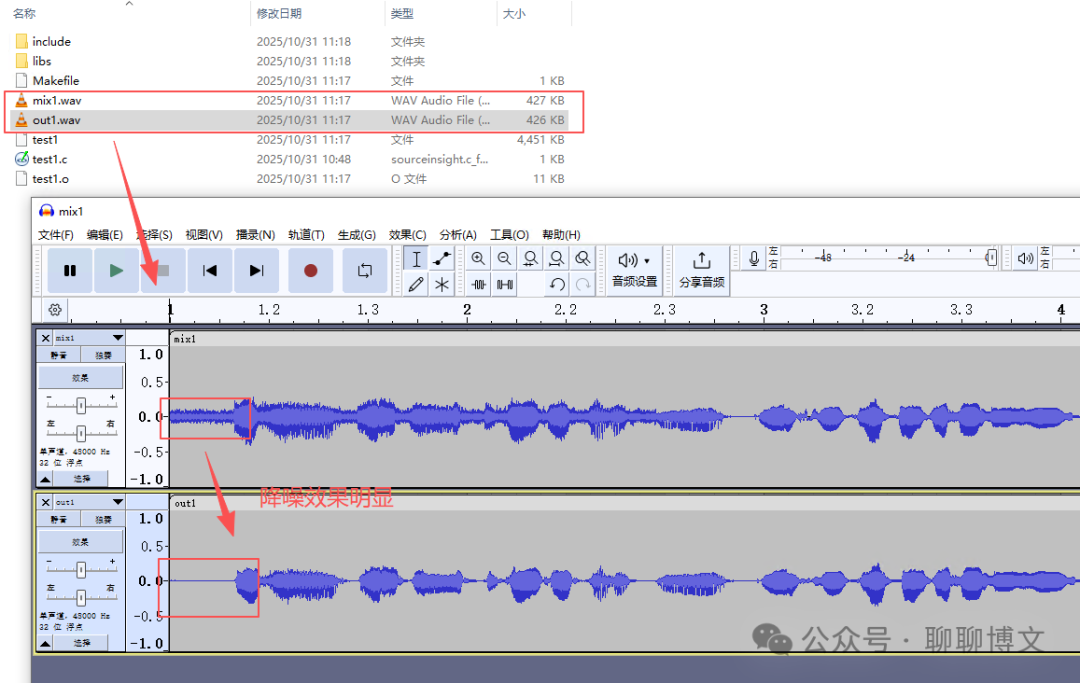
配套代码及文件可从如下渠道获取:
关注微信公众号(聊聊博文,文末可扫码)后回复 20251031 获取。
二、在python中使用rnnoise库
rnnoise的python库内置的有降噪模型,不用额外下载模型。
pypi地址:
https://pypi.org/project/pyrnnoise/
安装rnnoise库:
pip install pyrnnoise主流平台都支持的:
安装时会下载很多依赖库:
安装后dll路径:
示例代码(rnnoiseTest1.py):
from pyrnnoise import RNNoise
# Create denoiser instance
denoiser = RNNoise(sample_rate=16000)
# Process audio file
for speech_prob in denoiser.denoise_wav("mix1.wav", "output.wav"):
print(f"Processing frame with speech probability: {speech_prob}")运行效果如下:
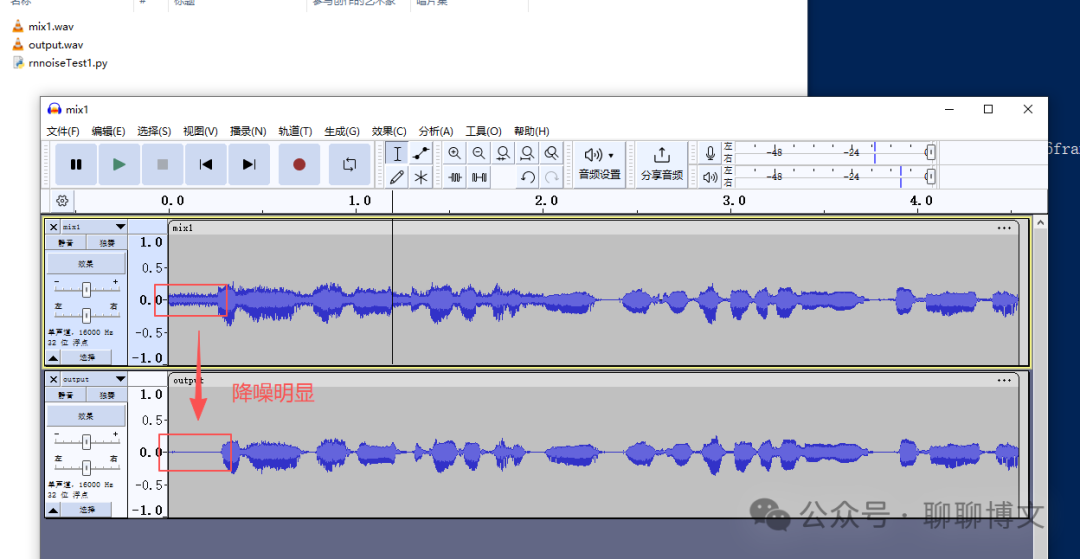
降噪效果如下:
配套代码及文件可从如下渠道获取:
关注微信公众号(聊聊博文,文末可扫码)后回复 20251031 获取。
三、模型训练
这里做下简单说明,具体可参考GitHub上的README文档:
https://github.com/xiph/rnnoise
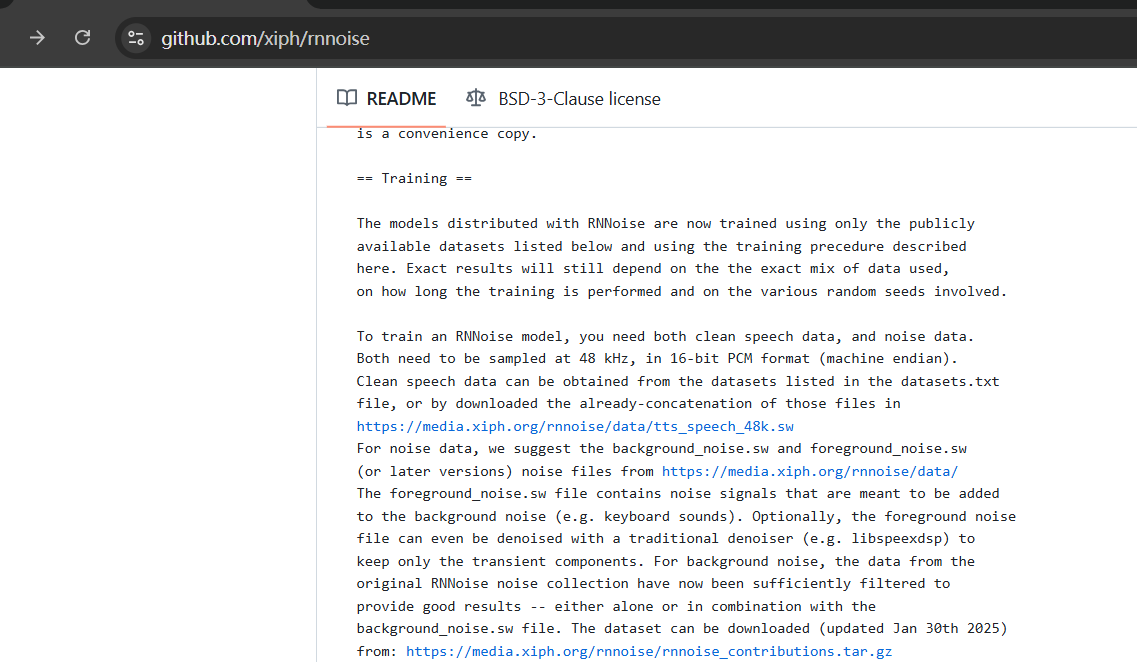
1、数据集获取
数据及模型下载地址:
https://media.xiph.org/rnnoise/
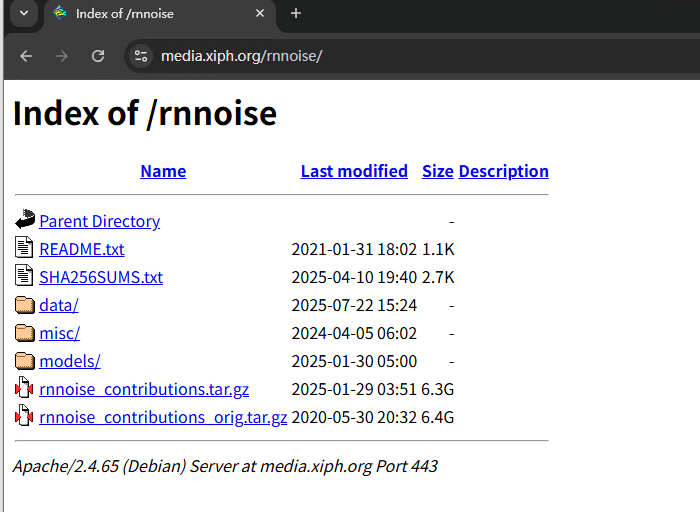
1)rnnoise_contributions.tar.gz 是 RNNoise 项目提供的一个数据集压缩包,主要用于训练 RNNoise 模型;
2)data目录里面包含语音数据、噪音数据及其它辅助数据,展开如下;

3)misc目录只有一个wav音频文件;
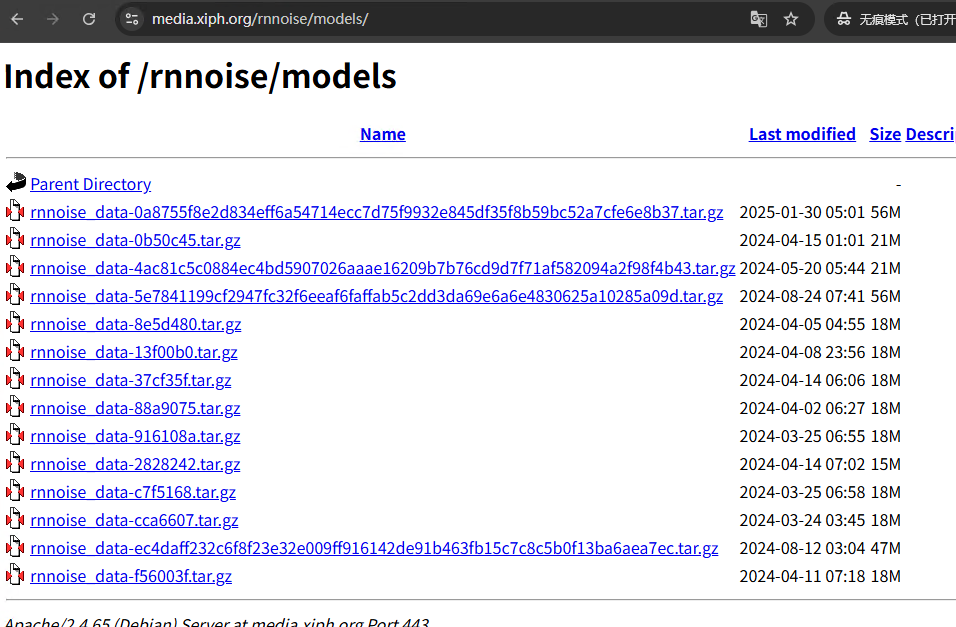
4)models文件夹存储的训练好的模型,可直接使用;
2、训练过程
大致过程如下:
1)使用dump_features提取特征文件。
示例如下:
./dump_features -rir_list rir_list.txt speech.pcm background_noise.pcm foreground_noise.pcm features.f32 <count>其中 为处理的序列数量,建议至少 10000 次(越多越好,推荐 200000 次以上)。
dump_features在rnnoise的根目录(编译后):
2)可使用脚本 script/dump_features_parallel.sh 加速特征生成。
使用方法如下:
script/dump_features_parallel.sh ./dump_features speech.pcm background_noise.pcm foreground_noise.pcm features.f32 <count> rir_list.txt该脚本会启动多个进程,每个进程处理一定数量的序列,并将结果合并为一个文件。
3)执行训练,生成模型文件。
训练脚本目录:torch/rnnoise
训练命令如下:
python3 train_rnnoise.py features.f32 output_directory可选择适当的训练轮数(通过 --epochs 参数指定,比如 75000 次),当使权重更新次数达到约 75000 次时,会生成 .pth 文件(比如 rnnoise_50.pth )。
4)将模型文件转换为 C 代码。
脚本名称: dump_rnnoise_weights.py
转换示例:
python3 dump_rnnoise_weights.py --quantize rnnoise_50.pth rnnoise_c会自动创建 rnnoise_c 文件夹,然后在该文件夹里面生成 rnnoise_data.c 和 rnnoise_data.h 文件。
5)在C代码中使用模型。
复制 rnnoise_data.c 和 rnnoise_data.h 文件到 src/ 目录,然后按照之前描述的方法编译 RNNoise 工程,会在examples目录里面找到可直接运行的demo程序(rnnoise_demo)。
四、资源获取
本文相关资源及运行环境,可从如下渠道获取:
关注微信公众号(聊聊博文,文末可扫码)后回复 20251031 获取。