我自己的原文哦~ https://blog.51cto.com/whaosoft143/14293271
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#xxx
....
#TrajGATFormer
阿尔伯塔大学提出TrajGATFormer:ADE与FDE降低超35%,精准预测施工现场轨迹
在建筑行业,效率和安全永远是核心议题。尤其是在"异地施工"(Off-site Construction)这种新兴模式下,工人和机器、物料在相对集中的空间里频繁互动,如何避免碰撞、保障安全,成了一个亟待解决的难题。最近,来自阿尔伯塔大学的研究者们就带来了一个非常有趣的解决方案,他们提出了一种名为 TrajGATFormer 的新方法,专门用来预测工人和障碍物的运动轨迹。
简单来说,TrajGATFormer 这个名字融合了 GAT (Graph Attention Networks, 图注意力网络) 和 Transformer,点明了它的核心技术:利用图网络来理解空间中多个对象(人、障碍物)的相互影响,再用 Transformer 捕捉它们在时间上的运动趋势。这项研究的目标,就是让机器能"预见"未来几秒内人和物的动向,从而为自动防撞系统提供决策依据。
- 论文标题: TrajGATFormer: A Graph-Based Transformer Approach for Worker and Obstacle Trajectory Prediction in Off-site Construction Environments
- 作者: Mohammed Alduais, Xinming Li, Qipei Mei
- 机构: University of Alberta (阿尔伯塔大学)
- 论文地址: https://arxiv.org/abs/2510.22205
研究背景与挑战
传统的轨迹预测方法在面对动态、复杂的建筑环境时,常常显得力不从心。它们要么依赖过于简化的物理模型,要么需要人工设计复杂的特征,很难实时应对人与移动障碍物之间的复杂互动。
近年来,数据驱动的方法虽然在时序模式学习上有所进步,但在捕捉长时程行为、并融合空间与社交环境信息方面,依然面临挑战。毕竟,工人的移动并非完全随机,它会受到周围人、设备、障碍物以及任务目标的影响。如何将这些复杂的"社会性"和"环境性"因素融入预测模型,是提升准确率的关键。
TrajGATFormer:检测、跟踪与预测一体化框架
为了解决上述难题,作者们设计了一个集成了目标检测、跟踪和轨迹预测的完整框架。
整个流程可以分为三步:
- 精准检测 : 采用 YOLOv10n 作为目标检测的骨干网络,它能准确地从不同场景中识别出工人、机器和障碍物。
- 稳定跟踪 : 使用 DeepSORT 算法对检测到的目标进行跨帧跟踪,为每个目标分配一个独一无二的ID,确保轨迹的连续性。
- 轨迹预测: 这就是 TrajGATFormer 发挥作用的核心环节。它接收过去一段时间的轨迹数据作为输入,输出对未来轨迹的预测。
TrajGATFormer 模型结构
作者提出了两种具体的模型:TrajGATFormer(仅预测工人轨迹)和 TrajGATFormer-Obstacle(同时预测工人与障碍物轨迹)。
TrajGATFormer 的结构如下图所示,它主要由一个编码器和一个解码器组成。
- 输入: 工人过去12个时间步(4.8秒)的轨迹坐标。
- 编码器: 内部包含一个图注意力网络(GAT)层和一个Transformer编码器层。GAT用于捕捉同一时刻不同工人之间的空间交互关系(可以理解为"社交"影响),而Transformer则用来学习单个工人自身在时间维度上的运动模式。
- 解码器: 接收编码后的特征,并自回归地生成未来12个时间步(4.8秒)的预测轨迹。
- 输出: 工人未来的轨迹坐标。
TrajGATFormer-Obstacle 模型则更进一步,它将障碍物的轨迹也纳入了考量,使得预测更贴近真实世界的复杂互动。
为了保证模型的可复现性,作者还给出了详细的模型和优化器参数。xx认为这一点做得非常扎实,方便了其他研究者跟进。
实验与结果分析
为了验证模型的效果,研究者们在一个真实的建筑工地区域收集了数据,并进行了标注。
从训练过程来看,作者发现使用迁移学习能够有效加速模型的收敛,并达到更低的损失。
定量结果:性能显著提升
实验结果非常亮眼。在预测未来4.8秒的轨迹时,TrajGATFormer 模型的平均位移误差(ADE)为1.25米,最终位移误差(FDE)为2.3米。而考虑了障碍物信息的 TrajGATFormer-Obstacle 模型表现更佳,ADE和FDE分别降至1.15米和2.2米。
与传统的 LSTM、Bi-LSTM 和 GRU 等方法相比,新提出的两种模型在工人和面板(障碍物)轨迹预测上都取得了目前最好的结果(SOTA),将ADE和FDE指标分别降低了高达35%和38%。
各模型对工作人员轨迹的预测结果
移动障碍物的轨迹预测性能
实验结果表明:TrajGATFormer在ADE指标上较基线模型提升约27%-31%,在FDE指标上提升约26%-29%,均优于所有基线模型。
而TrajGATFormer-Obstacle相较基线模型提升更为显著------与LSTM相比,ADE提升超40%,FDE提升达38%。
进一步对比TrajGATFormer-Obstacle与TrajGATFormer可见:前者ADE为1.03,后者为1.25,相对提升约17.6%,表明其对整体轨迹的预测更精准;前者FDE为2.06,后者为2.35,相对提升约12.34%,体现其在终点位置预测上具有更高准确度。
定性结果:预测轨迹更贴近真实
除了冰冷的数字,可视化的结果更能直观地展示模型的效果。下方的对比图清晰地显示了预测轨迹(红色)与真实轨迹(蓝色)的贴合程度。可以看到,无论是 TrajGATFormer 还是 TrajGATFormer-Obstacle,其预测都相当精准。
对于一些距离较长的复杂轨迹,模型同样表现出了良好的预测能力。
即使是短距离的移动,预测也同样可靠。
总结
总的来说,这项工作为解决异地施工环境下的安全问题提供了一个非常强大且有效的新工具。通过融合图注意力网络和Transformer,TrajGATFormer能够更深刻地理解人与物之间的时空动态关系,做出更精准的轨迹预测。
xx认为,这类技术不仅能用于建筑安全,未来在自动驾驶、机器人协作、人流疏导等领域也都有着巨大的应用潜力。
....
#MERGE
华科大新作:生成与感知「即插即用」,一个模型双模切换,性能与效率兼得!
MERGE为T2I模型加装"可拔插转换器":训练时12%参数解锁深度/法线估计,推理时跳过模块即恢复原生成能力,零样本NYUv2性能超OneDiffusion,数据仅用其千分之一,代码已开源。
近年来,文生图(T2I)扩散模型以前所未有的速度发展,并衍生出诸多基于全参微调的生成式感知工作,如Marigold等。然而,全参微调会破坏文图模型原本的图像生成能力,一个问题随之而来:我们能否利用这些模型强大的视觉先验知识,去执行深度估计等感知任务,同时又不损害其宝贵的图像生成能力?
近日,一项由华中科技大学团队提出的名为MERGE的全新框架,为这一难题提供了极其优雅的解决方案,该工作已被NeurIPS 2025接收。该方法创新性地提出了一种"即插即用"的范式,仅需为预训练T2I模型增加约12%的可训练参数,即可在完整保留原始生成能力的同时,解锁出顶尖的零样本(zero-shot)几何估计能力,在多个权威基准上超越了需要海量数据从零训练的统一模型,实现了性能与效率的完美统一。
论文标题: More Than Generation: Unifying Generation and Depth Estimation via Text-to-Image Diffusion Models
论文链接: https://arxiv.org/abs/2510.23574
代码链接: https://h-embodvis.github.io/MERGE
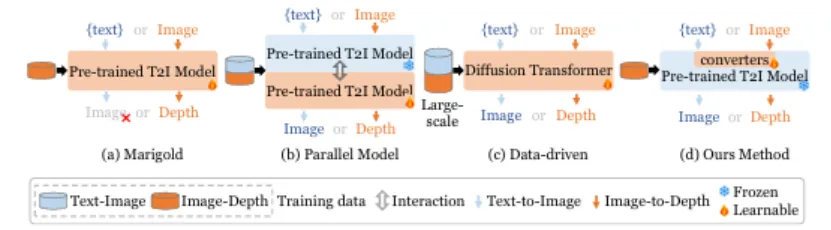
图1.和全参微调方法及其他多任务统一范式的对比
01 挑战:生成与感知的"两难困境"
预训练+微调是当前AI领域的主流范式。然而,当试图让一个强大的T2I模型"学会"深度估计等新技能时,研究者们普遍面临着"灾难性遗忘"(Catastrophic Degradation)的魔咒------模型原有的生成能力会遭到严重破坏。为了解决这个问题,研究人员探讨了多种方案:
- 双模型并行范式:以JointNet为代表,通过并行运行两个独立模型并进行特征交互来保留各自功能。然而,这种方法在应用层面两倍文生图模型的开销,可能被认为是一种次优解。
- 大规模重训练范式:以OneDiffusion为代表,在高达1亿样本量的多任务数据集上从零开始训练一个统一模型。这种超大规模数据驱动的方法尽管有效,但其惊人的数据和算力门槛,让绝大多数研究者望而却步。
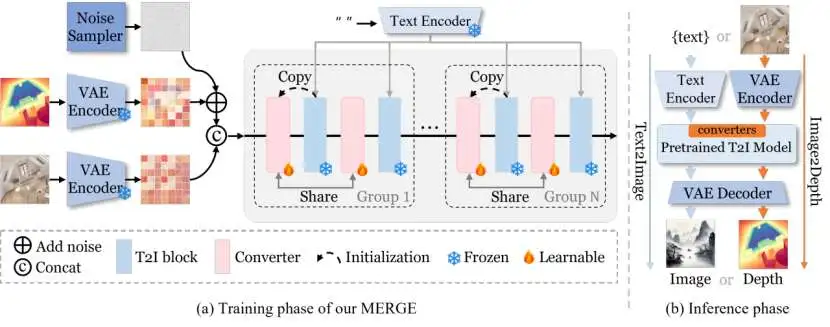
图2. MERGE的训练和推理流程图
02 破局:MERGE的"即插即用"新范式
面对上述瓶颈,MERGE的作者团队另辟蹊径,其核心思想并非"替换"或"重建",而是"释放"------他们认为,感知能力作为一种视觉先验,已经潜藏在预训练T2I模型中,只需找到正确的钥匙去解锁。
MERGE的设计极具巧思,其工作流程可以概括为:
- 设计可插拔转换器 (Pluggable Converter):研究者设计了一种轻量级的、可学习的"转换器"模块。在执行深度估计任务时,将这些转换器接入到预训练模型的特征流中,引导模型输出深度图。
- 实现无损模式切换:在执行图像生成任务时,只需将这些转换器跳过,特征流便会绕过它们,模型恢复到其原始的、未受任何影响的状态,继续高效地生成图像。这种设计彻底解决了"灾难性遗忘"问题。
- 引入组重用机制 (Group Reuse Mechanism, GRE):通过观察到T2I模型中相邻层特征的高度相似性,MERGE让一个组内的多个层共享同一个转换器,极大地减少了需要额外学习的参数数量,实现了极致的参数效率。 通过这一系列操作,MERGE巧妙地将一个固定的T2I模型,转变为一个高性能的生成-感知双模模型,实现了知识的高效、无损迁移。
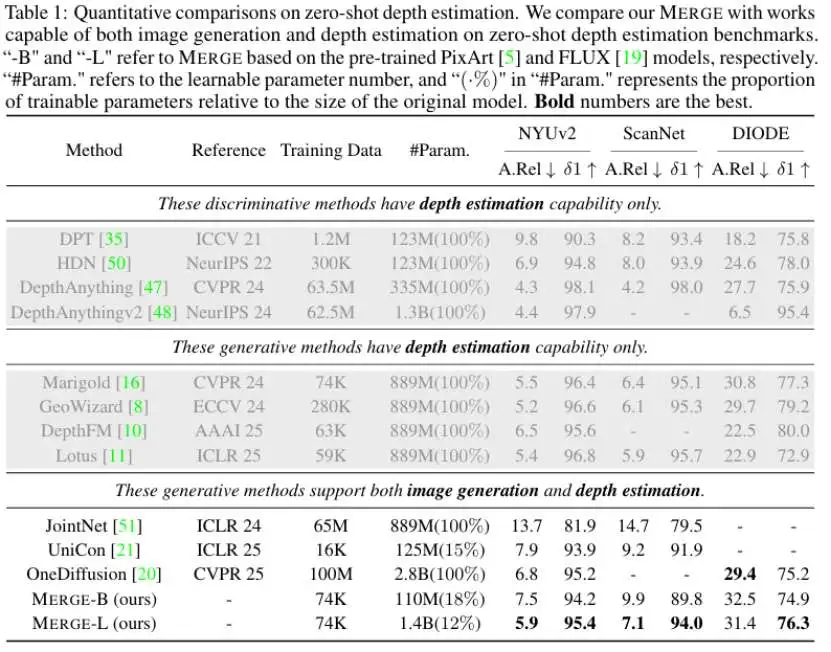
表1. 零样本深度估计的定量评估结果
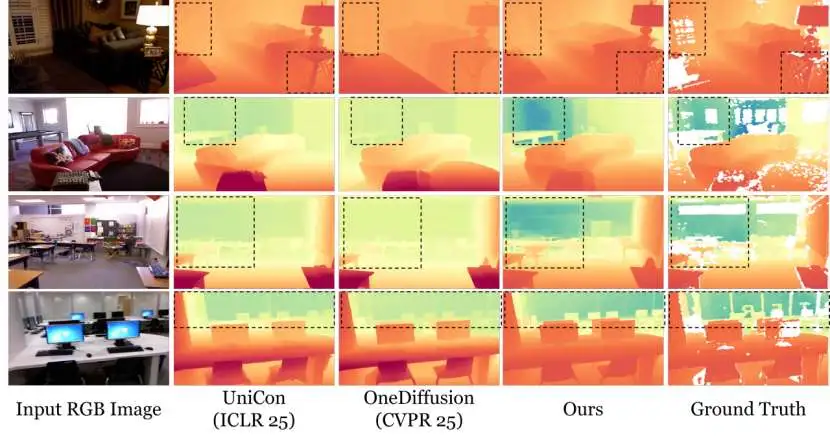
图3.零样本深度估计的定性评估结果
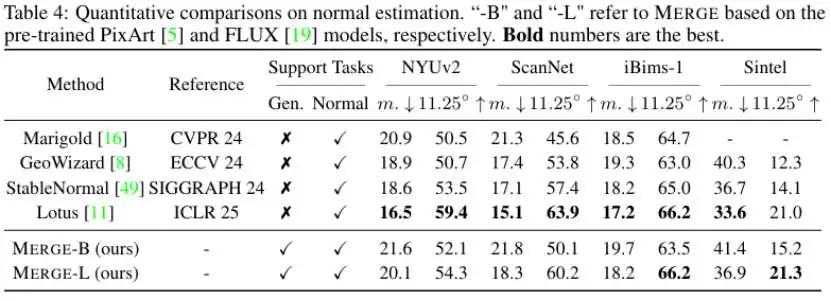
表2.零样本法线估计的定量评估结果
03 实验结果:性能与效率的双重胜利
MERGE的性能到底如何?实验数据给出了答案。
- 性能表现优异:在具挑战性的NYUv2深度估计基准上,MERGE-L(基于FLUX.1模型)的性能超越了OneDiffusion,而其训练数据量不足后者的千分之一(7.4万 vs 1亿),可训练参数仅为后者的一半。
- 极致的参数效率:在同一预训练文生图模型PixArt的设置下,与完全微调的Marigold相比,MERGE-B仅用其约18%的可训练参数,就取得了高度可比的深度估计性能,最关键的是,MERGE完整保留了模型的生成能力。
- 卓越的泛化能力:MERGE的框架被成功应用于表面法线估计任务,再次证明了其并非针对特定任务的"特解",而是一个具有普适性的方法论。这为构建模块化、可扩展的统一感知系统提供了新的见解。
- 定性表现惊艳:在视觉效果上,MERGE生成的深度图在细节上更加清晰准确,尤其在处理中空区域、反光表面等传统难题上,表现出强大的鲁棒性。
04 总结与展望
本文提出的MERGE框架,通过创新的"即插即用"范式,为如何在不牺牲原有能力的前提下扩展模型功能,提供了一个简单、优雅且高效的答案。它标志着一种范式转变的潜力:从过去那种破坏性的微调或资源密集型的重训练,转向一种更可持续、更模块化、更具成本效益的模型扩展方式。
总体而言,这项工作为如何利用和释放现有大型基础模型的潜能,提供了一份新的见解,为解决大模型落地应用中的效率与性能平衡问题,探索出一条全新的路径。
....