一、内容准备
1.1、Hadoop集群规划
|------------------|----------|--------------|--------------------------|
| 采用一共3台物理机或虚拟机,都使用(RHEL9/Almalinux9.1)及其更高版本的Linux系统 ||||
| 节点类型 | 主机名 | IP地址 | 角色类型 |
| 主节点 (namenode) | hadoop01 | 192.168.1.9 | NameNode、ResourceManager |
| 从节点1 (datanode1) | hadoop02 | 192.168.1.37 | DataNode、NodeManager |
| 从节点2 (datanode2) | hadoop03 | 192.168.1.39 | DataNode、NodeManager |
[hadoop集群的规划配置]
1.2、修改系统的主机名称
bash
#按照规划修改主机名称
#一、修改主节点的主机名称
#1.1-将192.168.1.9主机的名称修改为hadoop01
hostnamectl set-hostname hadoop01
#1.2-修改hosts配置
cp -p /etc/hosts /etc/hosts.bak
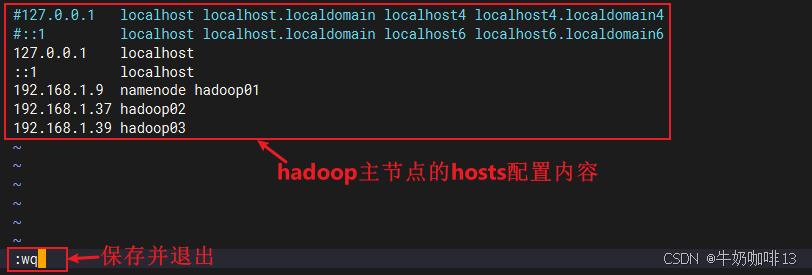
vi /etc/hosts
#etc/hosts文件的完整内容如下:
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost
::1 localhost
192.168.1.9 namenode hadoop01
192.168.1.37 hadoop02
192.168.1.39 hadoop03
#1.3-让修改的主机名称生效
systemctl restart systemd-hostnamed
exec bash
#二、修改从节点1的主机名称
#2.1-将192.168.1.37主机的名称修改为hadoop02
hostnamectl set-hostname hadoop02
#2.2-修改hosts配置
cp -p /etc/hosts /etc/hosts.bak
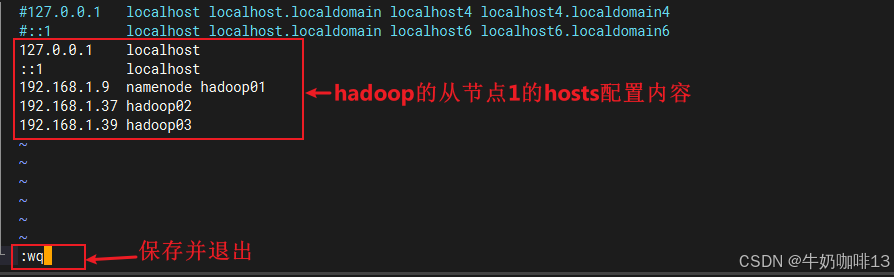
vi /etc/hosts
#etc/hosts文件的完整内容如下:
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost
::1 localhost
192.168.1.9 namenode hadoop01
192.168.1.37 hadoop02
192.168.1.39 hadoop03
#2.3-让修改的主机名称生效
systemctl restart systemd-hostnamed
exec bash
#三、修改从节点2的主机名称
#3.1-将192.168.1.39主机的名称修改为hadoop03
hostnamectl set-hostname hadoop03
#3.2-修改hosts配置
cp -p /etc/hosts /etc/hosts.bak
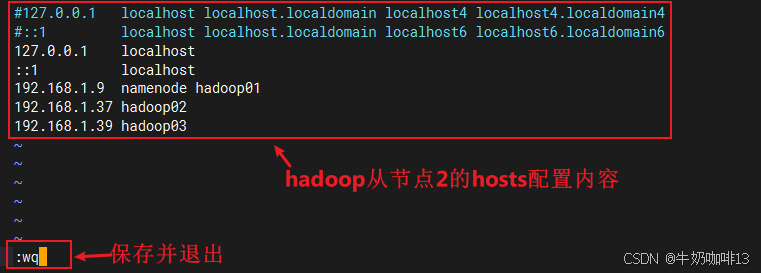
vi /etc/hosts
#etc/hosts文件的完整内容如下:
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 localhost
::1 localhost
192.168.1.9 namenode hadoop01
192.168.1.37 hadoop02
192.168.1.39 hadoop03
#3.3-让修改的主机名称生效
systemctl restart systemd-hostnamed
exec bash

1.3、配置免密登录
bash
#配置免密登录实操流程
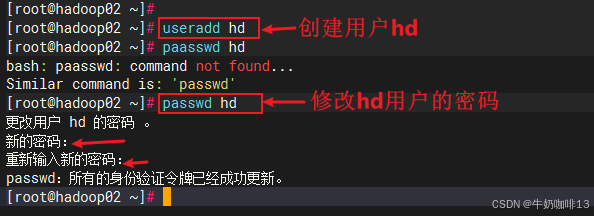
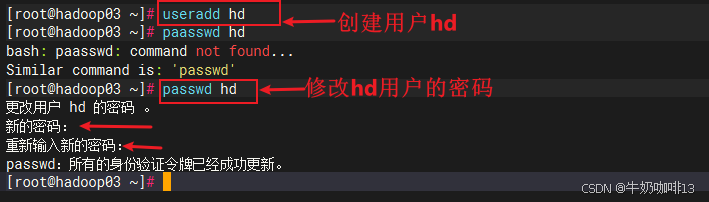
#0-先在3台服务器系统中创建hd用户并设置密码(注意:若有除了root的用户外的其他用户就不用创建)
useradd hd
passwd hd
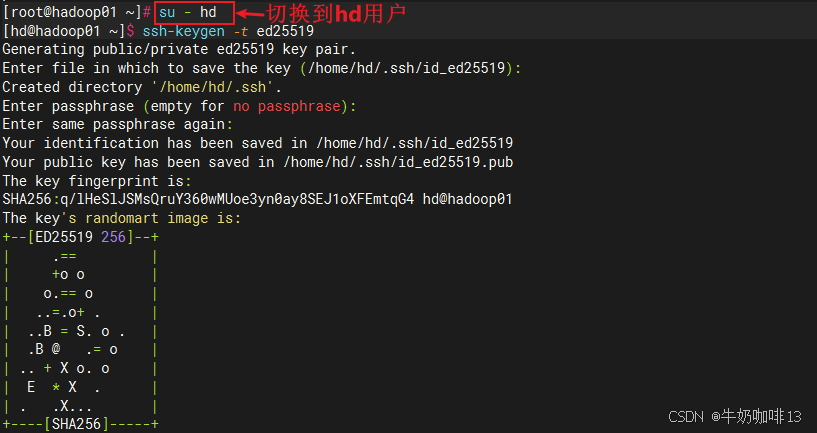
#1-在主节点(192.168.1.9)上切换到指定用户(如:hd)生成SSH密钥
su - hd
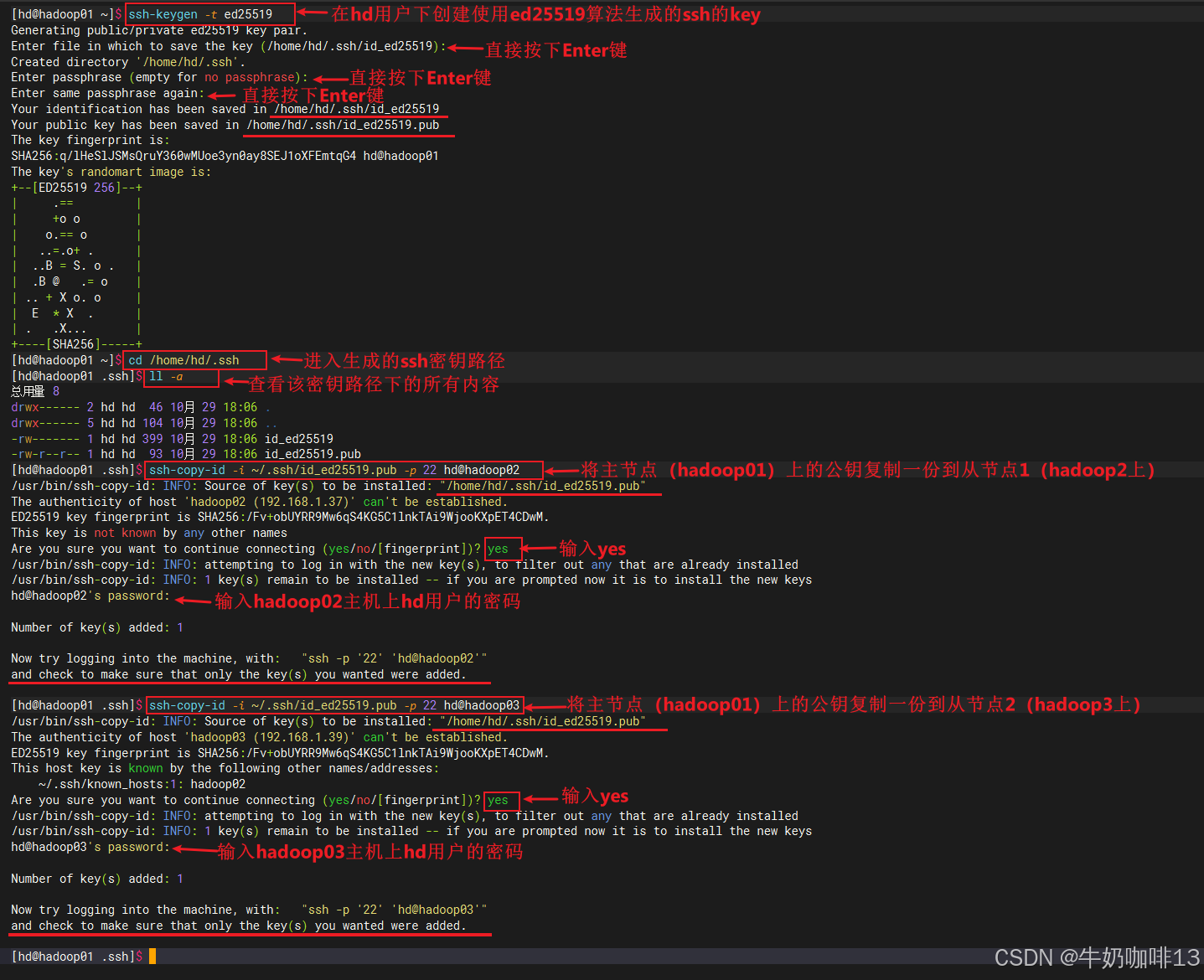
ssh-keygen -t ed25519
##2-进入密钥对生成的路径【/root/.ssh】并查看该路径下的所有文件,其中【id_ed25519】是私钥文件;【id_ed25519.pub】是公钥文件
cd ~/.ssh
ll -a
#2-将主节点(192.168.1.9)上的公钥添加到需ssh免密登录的远程服务器上(hadoop02【192.168.1.37】、hadoop03【192.168.1.39】)
ssh-copy-id -i ~/.ssh/id_ed25519.pub -p 22 hd@hadoop02
ssh-copy-id -i ~/.ssh/id_ed25519.pub -p 22 hd@hadoop03
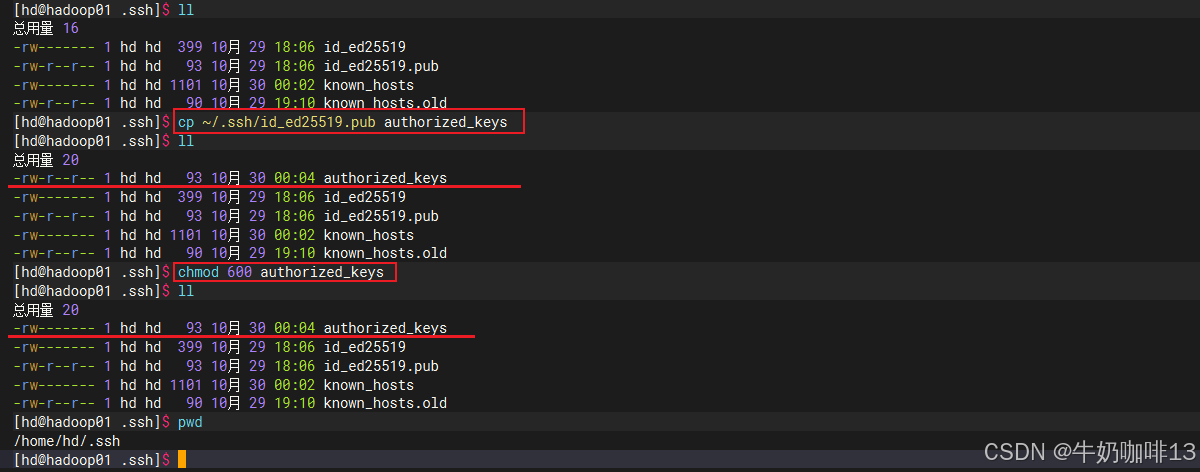
#注意:本机也需要使用该公钥免密登录(操作如下)
cp -p ~/.ssh/id_ed25519.pub authorized_keys
chmod 600 authorized_keys
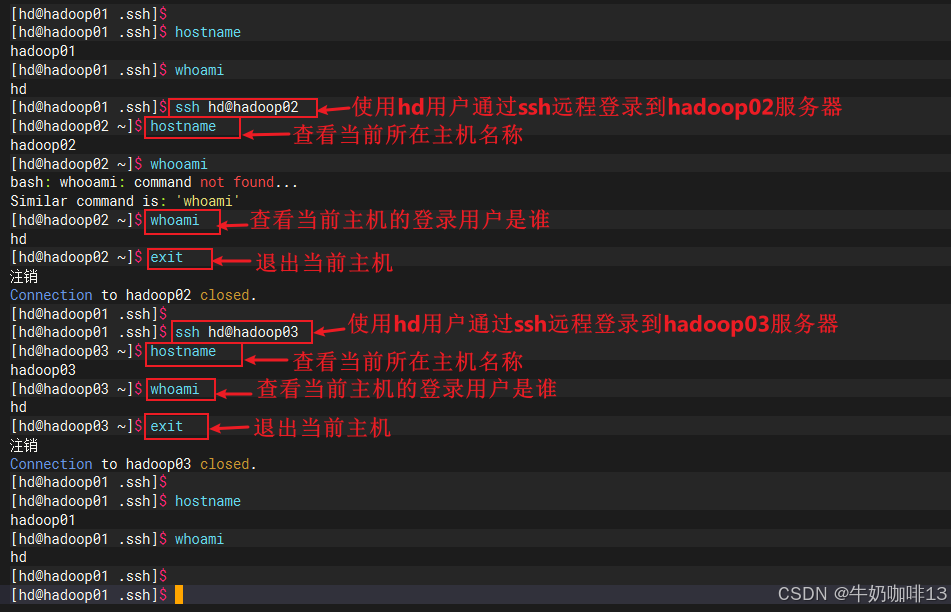
#3-测试在当前服务器使用ssh免密登录到远程服务器是否成功(不用输入密码就能直接登录上就表示成功)
ssh hd@hadoop01
hostname
whoami
exit
ssh hd@hadoop02
hostname
whoami
exit
##若远程服务器的端口不是默认的22端口则需要指定端口【ssh -p 免密登录服务器的端口号 用户名称@免密登录服务器的IP】(如:可以使用ck用户免密登录远程服务器192.168.1.41且该服务器的ssh端口是22222)
ssh -p 22222 ck@192.168.1.41
实现Linux的ssh免密登录实操保姆级教程_linux免密登录![]() https://coffeemilk.blog.csdn.net/article/details/152375722
https://coffeemilk.blog.csdn.net/article/details/152375722
1.4、防火墙配置
为了方便我们对hadoop集群的正常配置通信,我们这里可以先临时关闭防火墙。
bash
#禁用防火墙,方便hadoop集群能够正常通信
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld1.5、ssh配置
二、安装Hadoop
由于hadoop是需要在java环境中运行,因此我们需要先安装java环境后再安装hadoop.
2.1、安装java环境_openjdk、openjre
由于在 HADOOP-18197 中,Hadoop将 hadoop-thirdparty 中的 Protobuf 升级到版本 3.21.12。此版本可能与某些版本的 JDK8 存在兼容性问题,可能会遇到一些错误;且Hadoop将在 3.4.x 的未来版本中停止对 JDK8 的支持,因此建议将生产环境中的Java Jdk 版本升级到更高版本(> JDK8)。因此我们这里直接安装openjdk21和openjre21。
bash
#安装java的Jdk、jre环境有两种方法
#方法一:直接在线安装java的JDK包(如:我这里安装java-11-openjdk-devel)
#注意:可以先检查当前Linux是否支持指定版本的jdk环境(如没有jdk17则无法使用yum安装,需手动安装)
yum list | grep jdk
yum install java-17-openjdk-devel -y
#方法二:直接手动安装配置指定版本java的jdk和jre
#手动安装openjdk21实操流程(其余版本的Jdk安装方法也一样)
#1-检查Linux支持的jdk环境(若没有jdk21则无法使用yum安装,需手动安装)
yum list | grep jdk
#2-下载openjdk21的压缩包【注意:这个openjdk的下载链接需要自己到红帽官网获取,我这里提供的会失效】
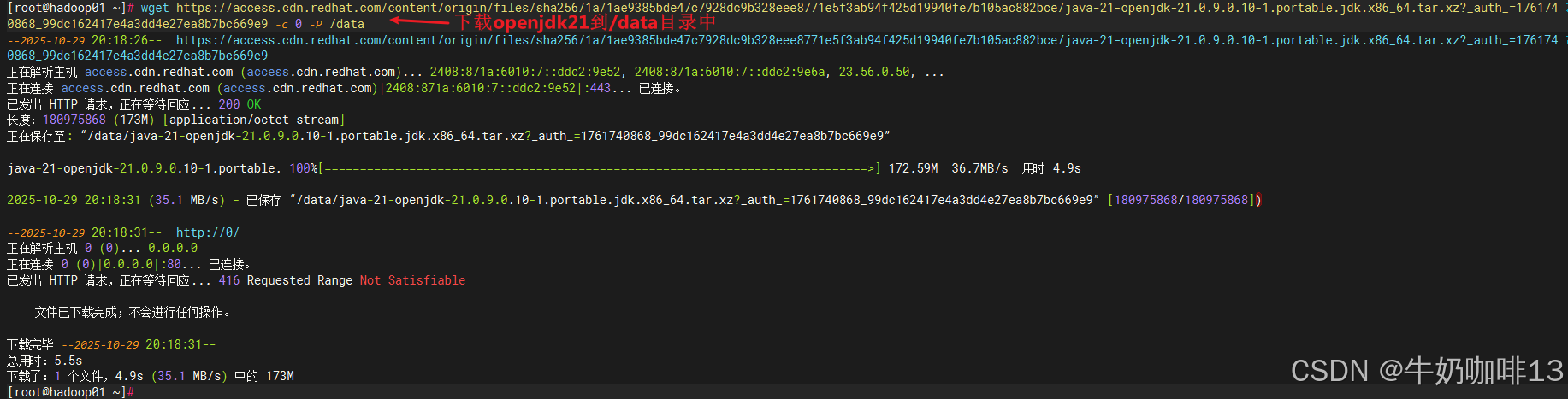
wget https://access.cdn.redhat.com/content/origin/files/sha256/1a/1ae9385bde47c7928dc9b328eee8771e5f3ab94f425d19940fe7b105ac882bce/java-21-openjdk-21.0.9.0.10-1.portable.jdk.x86_64.tar.xz?_auth_=1761740868_99dc162417e4a3dd4e27ea8b7bc669e9 -c 0 -P /data
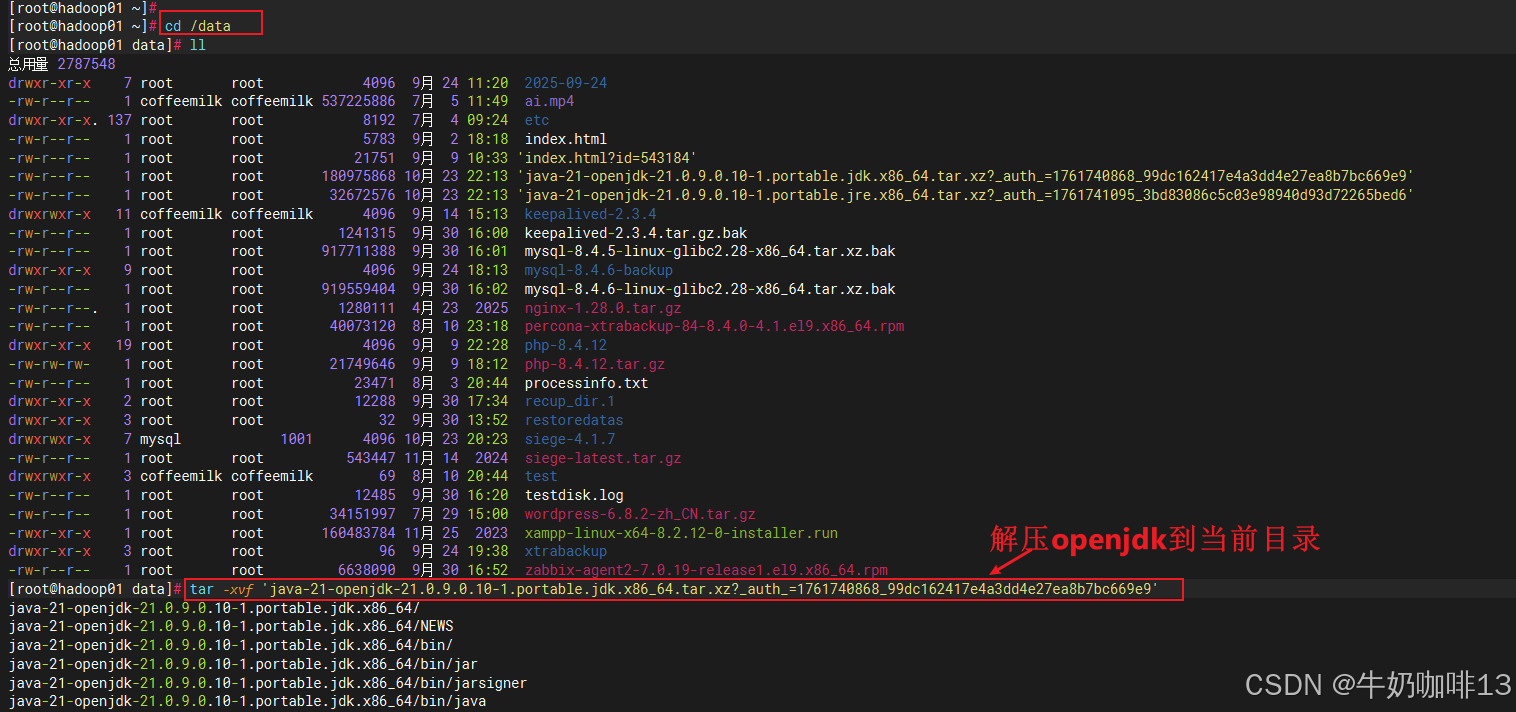
#3-解压openjdk21并修改名称
cd /data/
tar -xvf 'java-21-openjdk-21.0.9.0.10-1.portable.jdk.x86_64.tar.xz?_auth_=1761740868_99dc162417e4a3dd4e27ea8b7bc669e9'
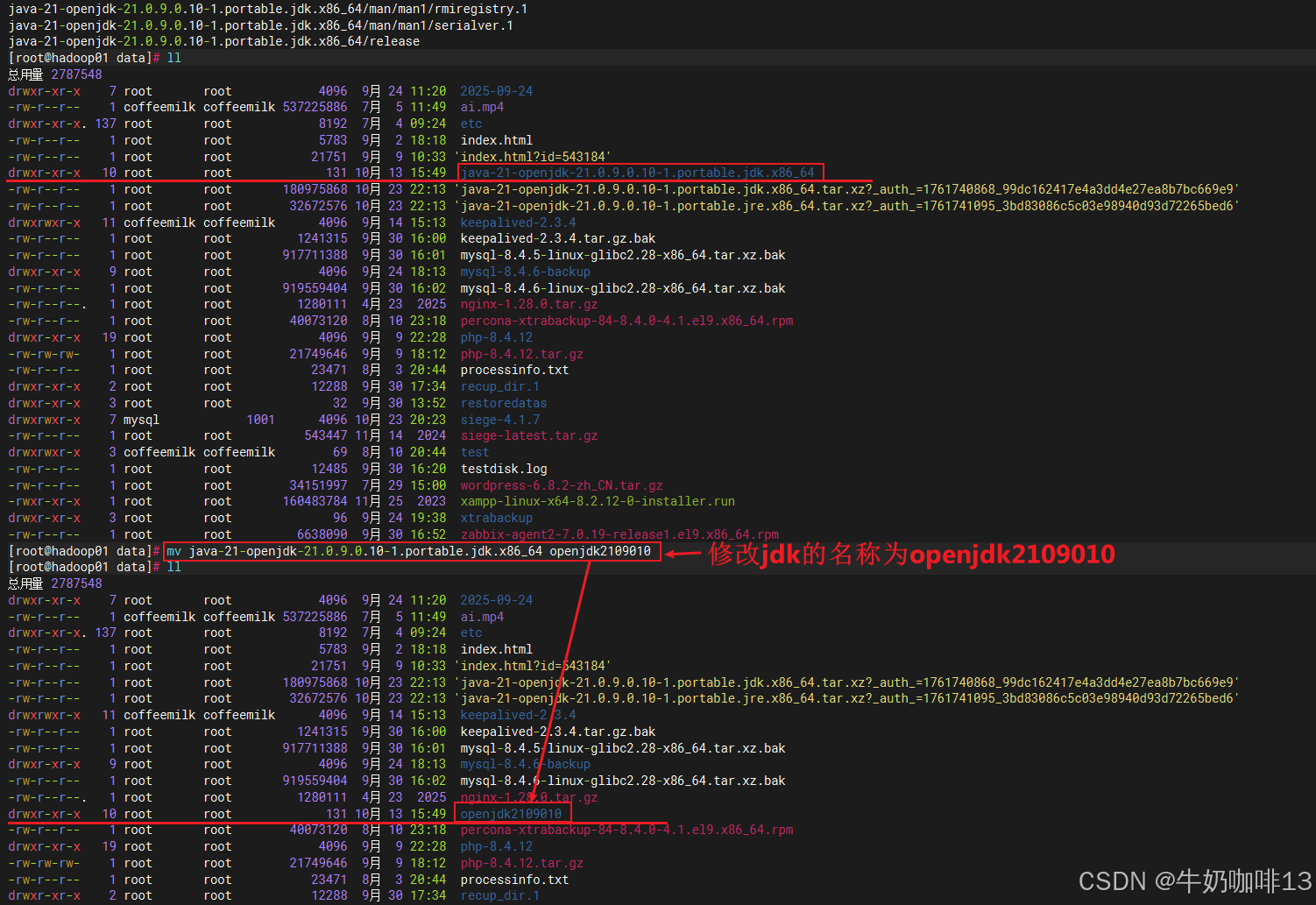
mv java-21-openjdk-21.0.9.0.10-1.portable.jdk.x86_64 openjdk2109010
#4-编辑环境配置文件并添加openjdk21的环境变量
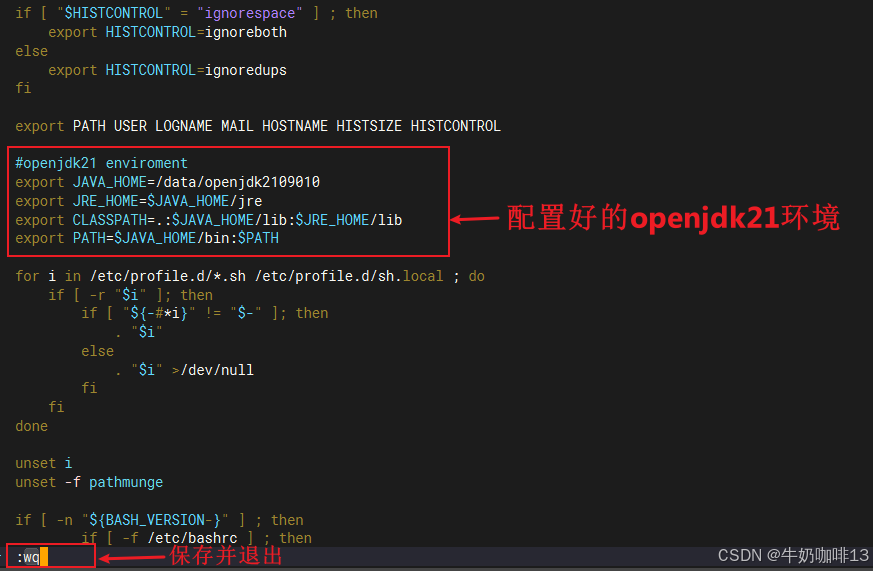
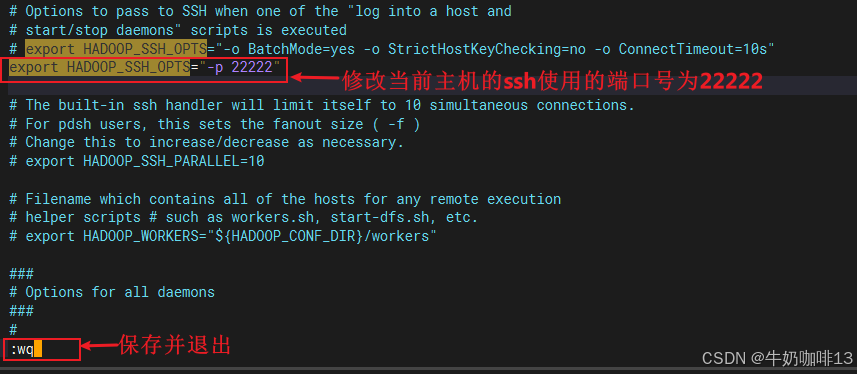
vi /etc/profile
#openjdk21 enviroment
export JAVA_HOME=/data/openjdk2109010
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
#5-让修改的环境变量生效
source /etc/profile
#6-查看java版本信息
echo $JAVA_HOME
echo $PATH
java -version
#7-安装openjdk21对应的jre
#7.1-下载openjdk21对应的jre二进制压缩包
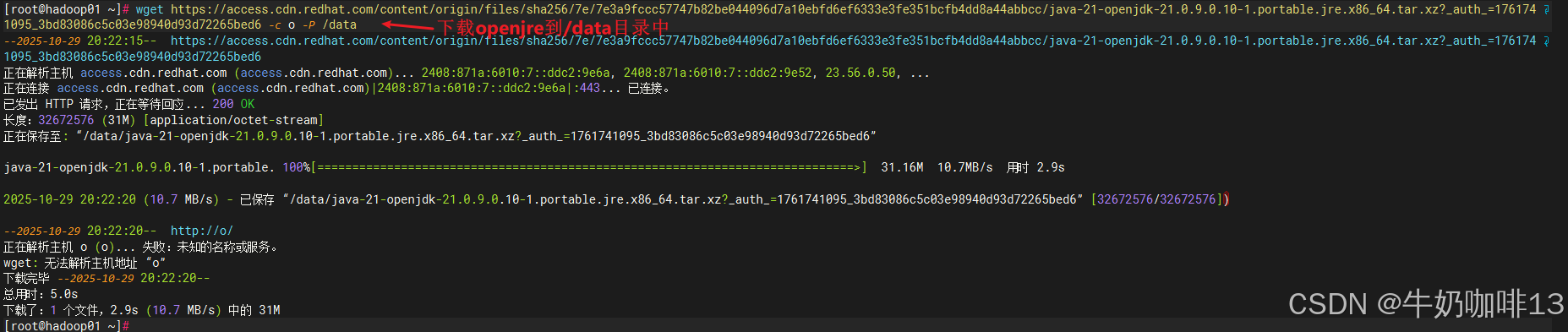
wget https://access.cdn.redhat.com/content/origin/files/sha256/7e/7e3a9fccc57747b82be044096d7a10ebfd6ef6333e3fe351bcfb4dd8a44abbcc/java-21-openjdk-21.0.9.0.10-1.portable.jre.x86_64.tar.xz?_auth_=1761741095_3bd83086c5c03e98940d93d72265bed6 -c o -P /data
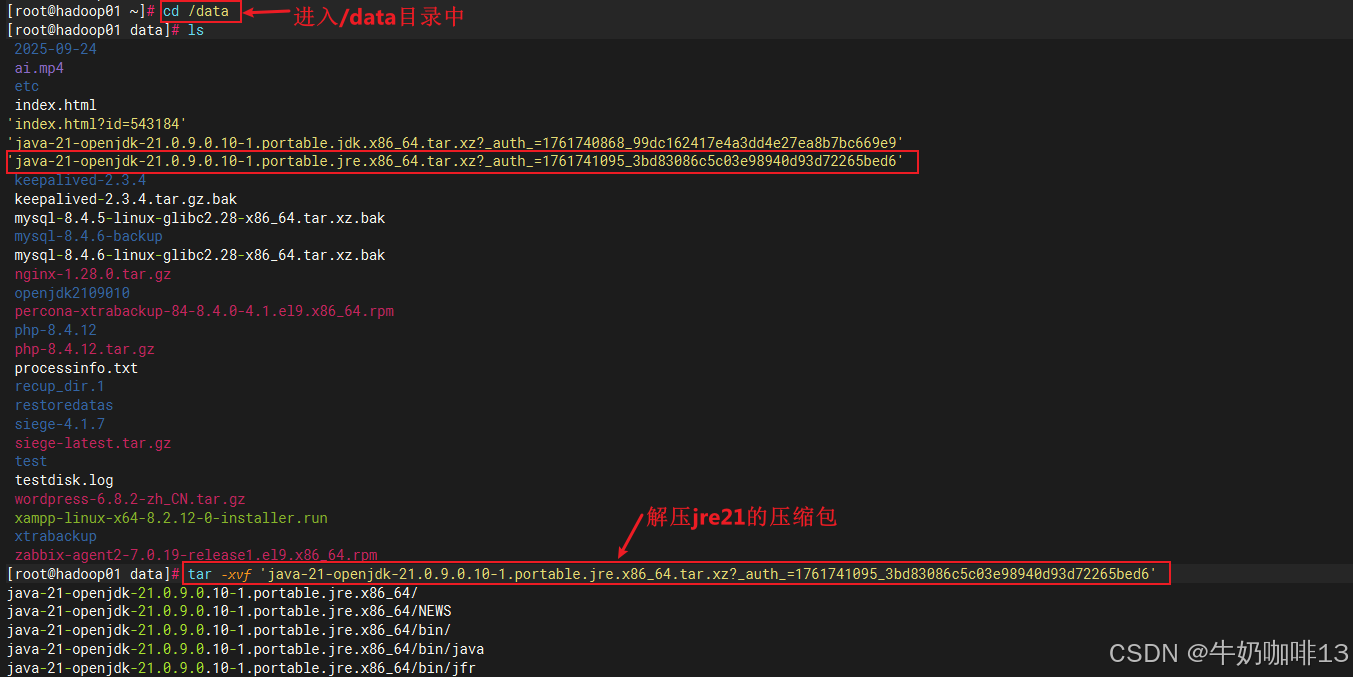
#7.2-进入/data目录并解压下载好的jre21包
cd /data
tar -xvf 'java-21-openjdk-21.0.9.0.10-1.portable.jre.x86_64.tar.xz?_auth_=1761741095_3bd83086c5c03e98940d93d72265bed6'
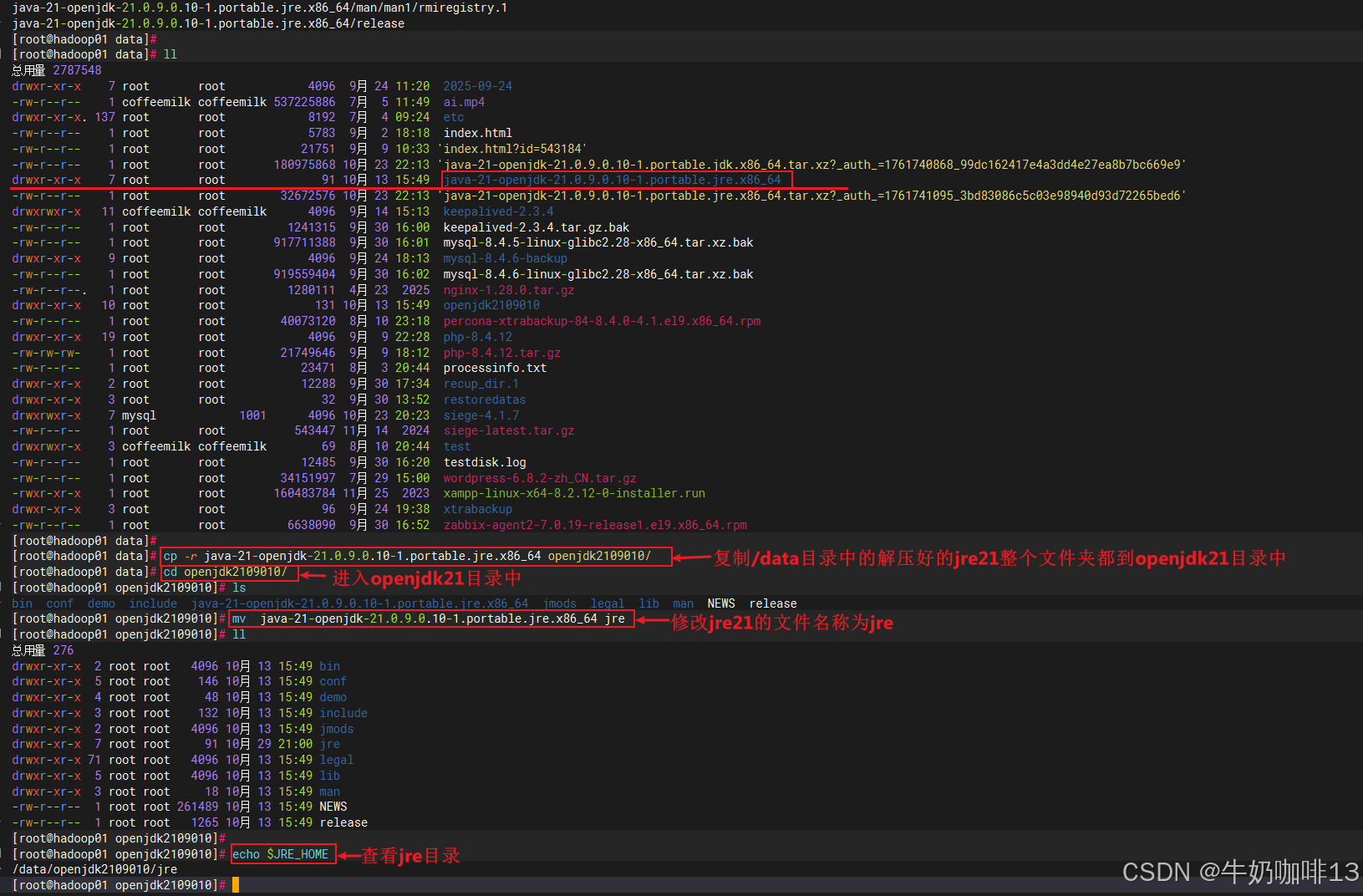
#7.3-将解压好的jre17复制一份到openjdk21目录中并修改名字为jre
cp -r java-21-openjdk-21.0.9.0.10-1.portable.jre.x86_64 openjdk2109010/
cd openjdk2109010/
mv java-21-openjdk-21.0.9.0.10-1.portable.jre.x86_64 jre
#7.4-查看jre的路径信息
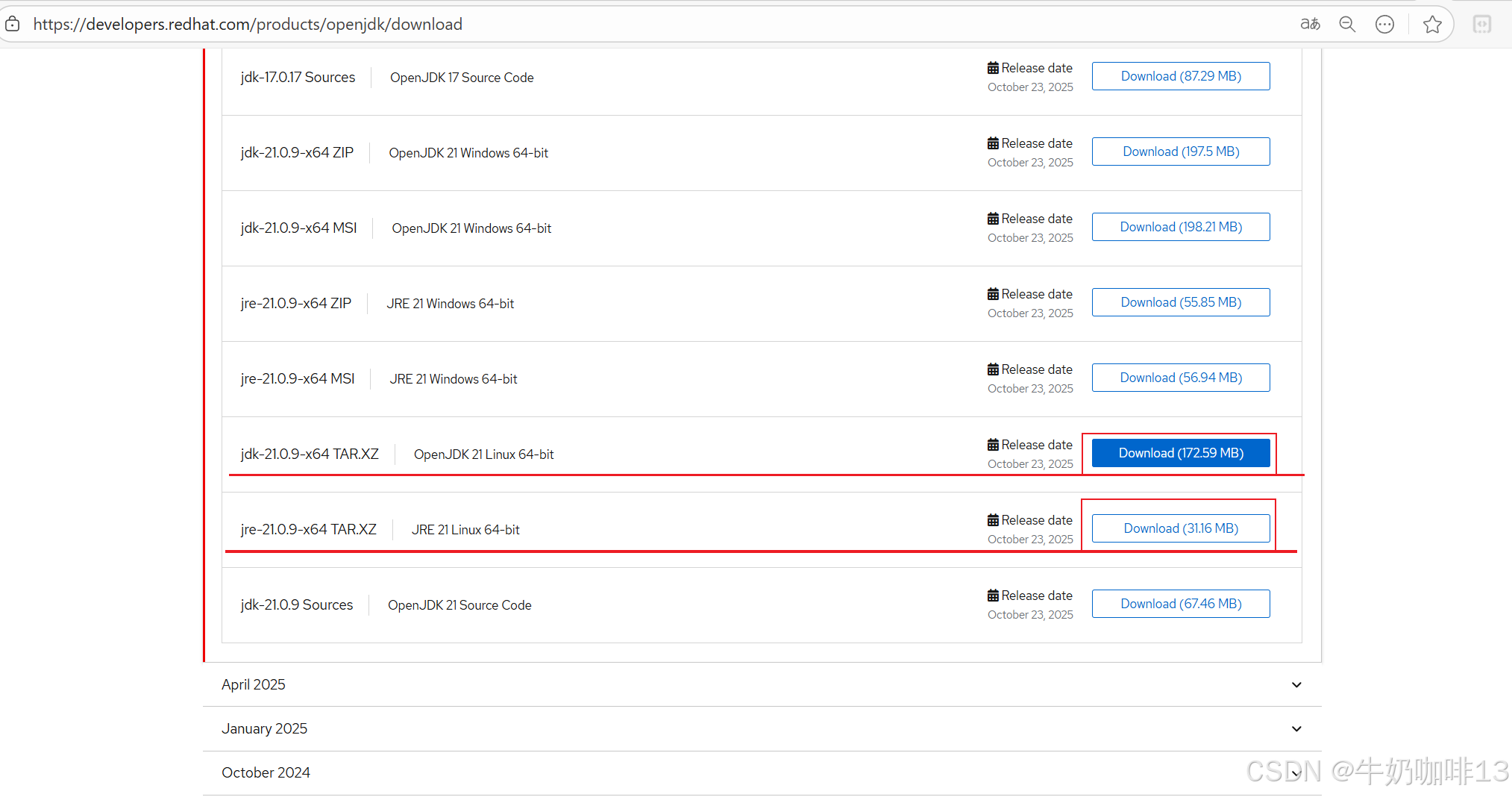
echo $JRE_HOME这是红帽官网提供的OpenJDK下载网址,在这里可以查找到对应的java jdk包下载(注意:这些OpenJDK包的下载需要用账号登录红帽官网后才能下载):如下图所示:


2.2、安装Hadoop3.4.2
bash
#下载安装部署Hadoop3.4.2实操流程
#1-下载最新的稳定版本Hadoop3.4.2
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.2/hadoop-3.4.2.tar.gz -c o -P /data
#2-进入/data目录并解压下载好的Hadoop
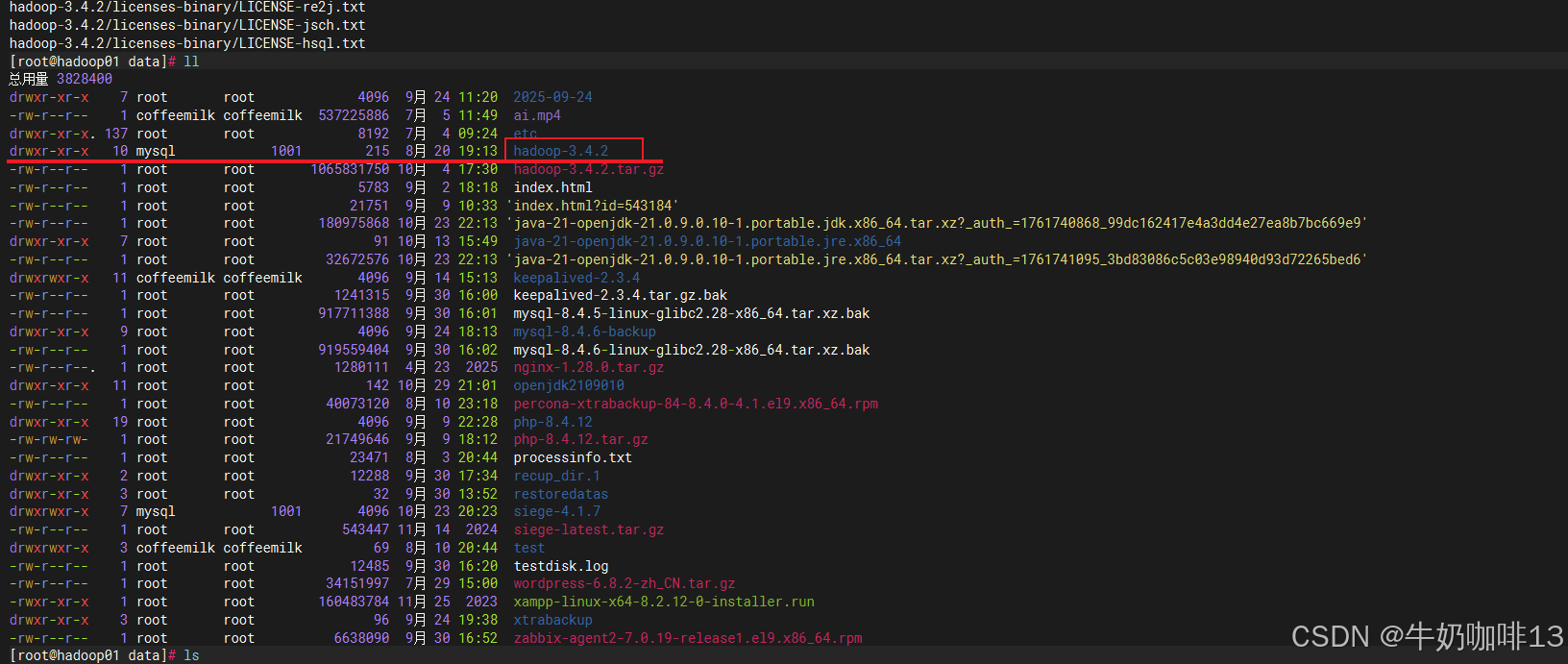
cd /data
tar -zxvf hadoop-3.4.2.tar.gz
#3-配置全局变量实现在任意位置都可以执行hadoop
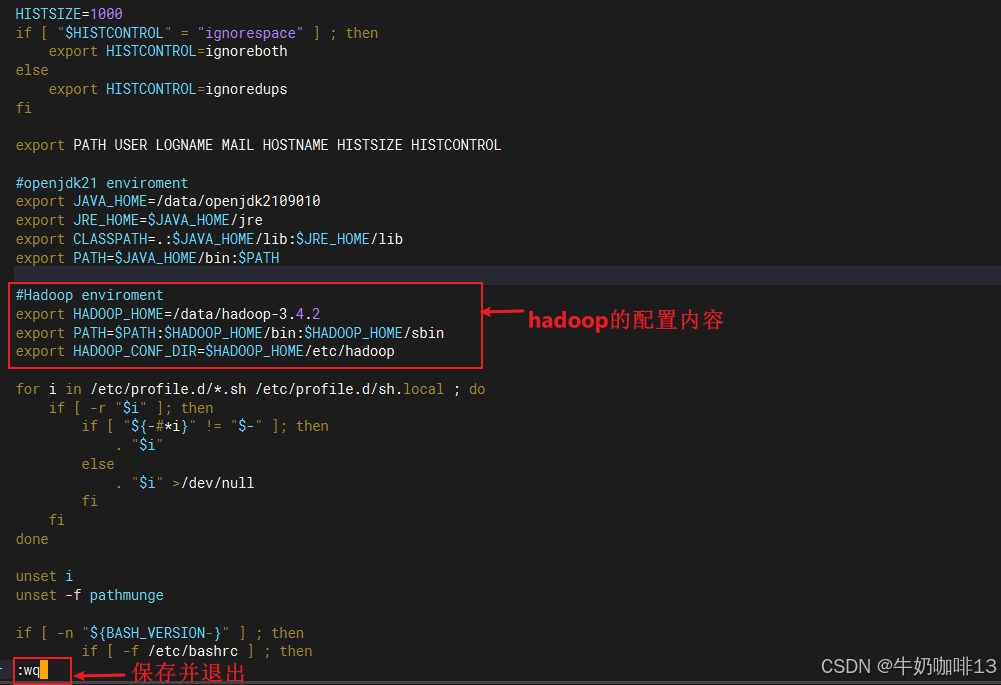
vi /etc/profile
#Hadoop enviroment
export HADOOP_HOME=/data/hadoop-3.4.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#4-让修改的环境变量生效
source /etc/profile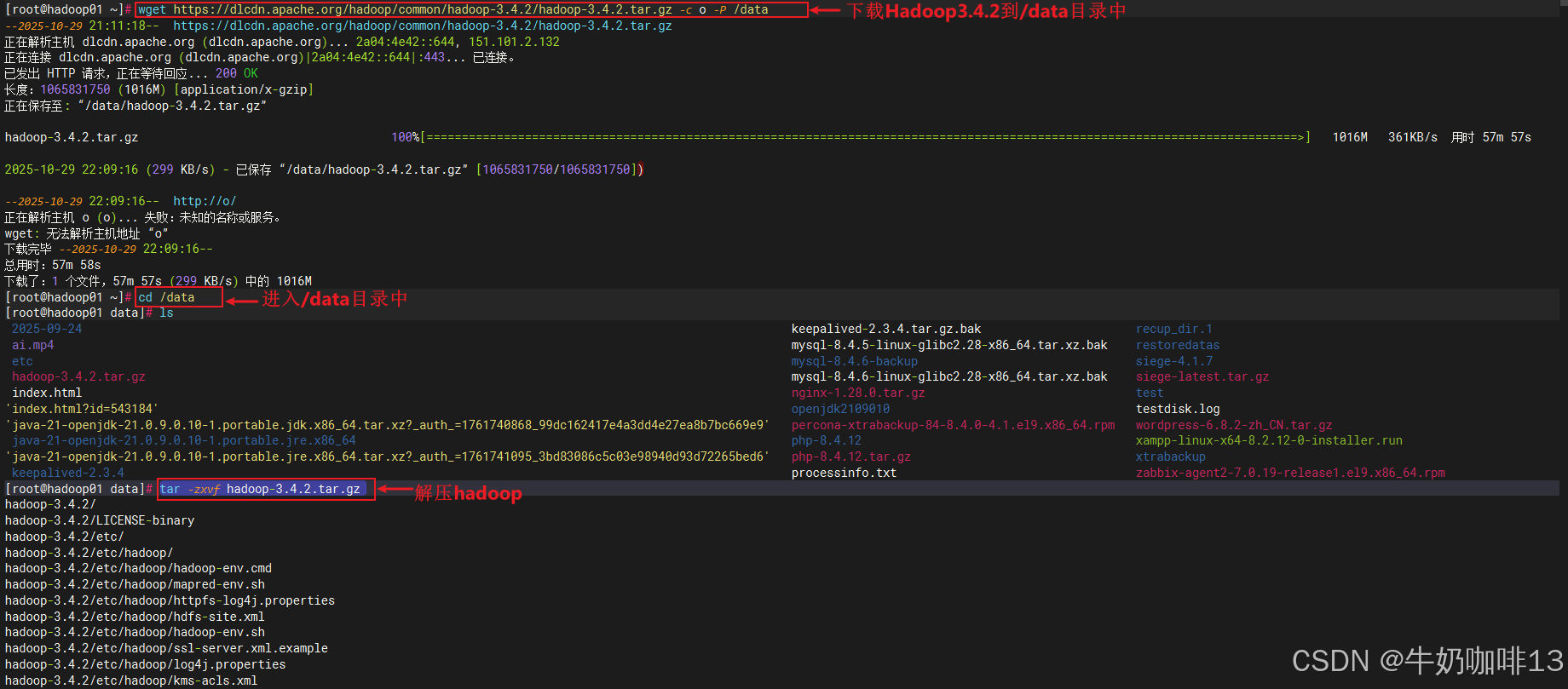

2.3、Hadoop集群配置
2.3.1、配置【hadoop-env.sh】
bash
#配置Hadoop的配置文件【hadoop-env.sh】的【JAVA_HOME】实操流程
#1-进入Hadoop的配置文件路径【如:/data/hadoop-3.4.2/etc/hadoop】
cd /data/hadoop-3.4.2/etc/hadoop
#2-给【hadoop-env.sh】配置JAVA_HOME
vi hadoop-env.sh
export JAVA_HOME=/data/openjdk2109010
#注意:如果当前系统的ssh端口号不是默认的22端口,则需要添加对应的ssh端口号配置(如:我在Hadoop主机上配置了ssh的端口是22222)
export HADOOP_SSH_OPTS="-p 22222"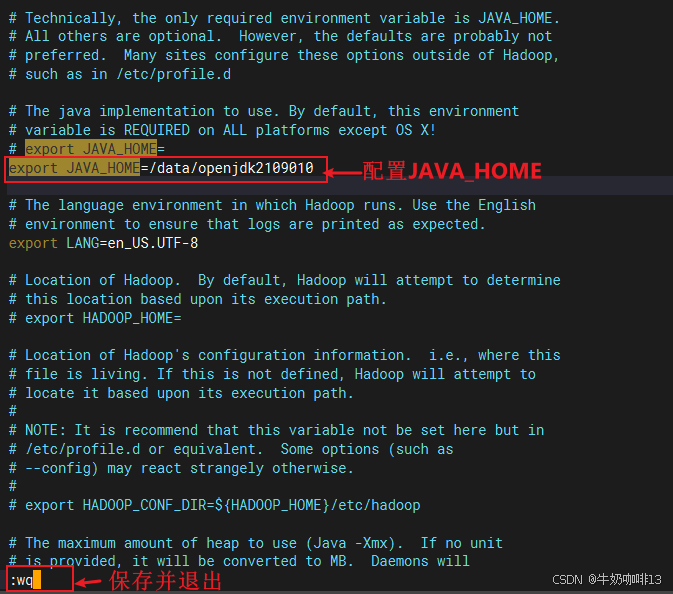
2.3.2、配置【core-site.xml】
bash
#配置Hadoop的配置文件【core-site.xml】的实操流程
#1-进入Hadoop的配置文件路径【如:/data/hadoop-3.4.2/etc/hadoop】
cd /data/hadoop-3.4.2/etc/hadoop
#2-给【core-site.xml】编辑内容
vi core-site.xml
#core-site.xml文件里面添加的内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop-3.4.2/data/hadoop/tmp</value>
</property>
</configuration>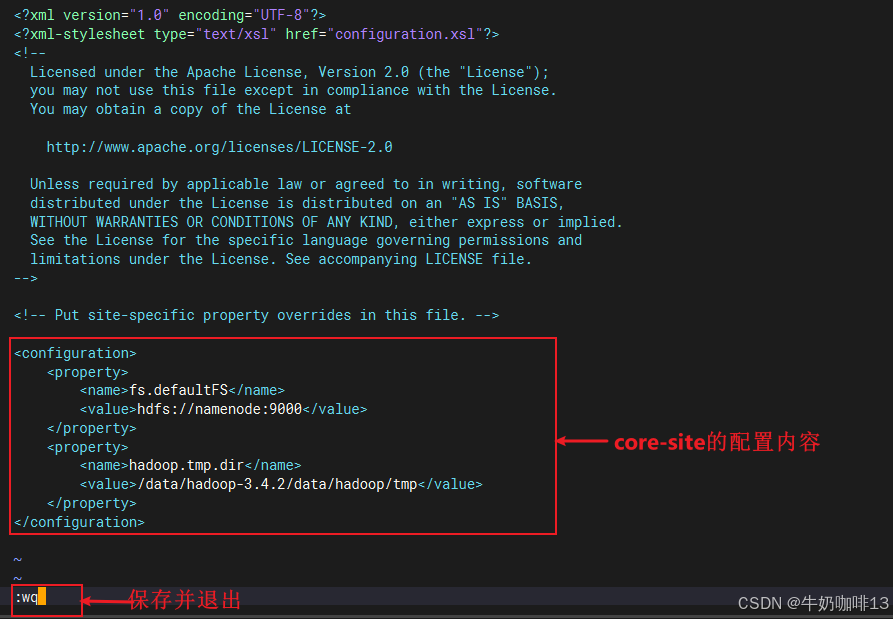
2.3.3、配置【hdfs-site.xml】
bash
#配置Hadoop的配置文件【hdfs-site.xml】的实操流程
#1-进入Hadoop的配置文件路径【如:/data/hadoop-3.4.2/etc/hadoop】
cd /data/hadoop-3.4.2/etc/hadoop
#2-给【hdfs-site.xml】编辑内容
vi hdfs-site.xml
#hdfs-site.xml文件里面添加的内容
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop-3.4.2/data/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop-3.4.2/data/hadoop/hdfs/datanode</value>
</property>
</configuration>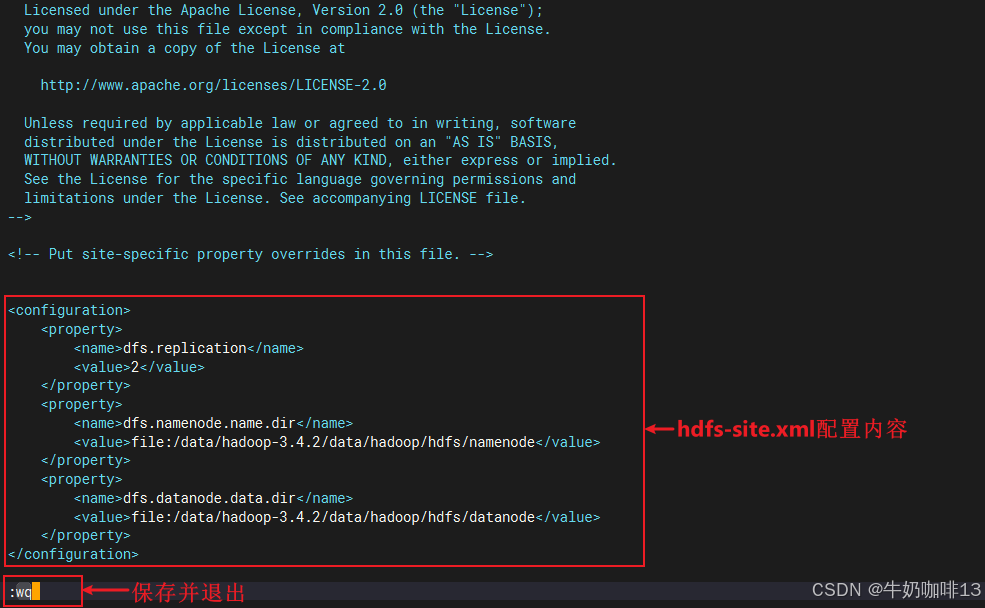
2.3.4、配置【yarn-site.xml】
bash
#配置Hadoop的配置文件【yarn-site.xml】的实操流程
#1-进入Hadoop的配置文件路径【如:/data/hadoop-3.4.2/etc/hadoop】
cd /data/hadoop-3.4.2/etc/hadoop
#2-给【yarn-site.xml】编辑内容
vi yarn-site.xml
#yarn-site.xml文件里面添加的内容
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>namenode</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>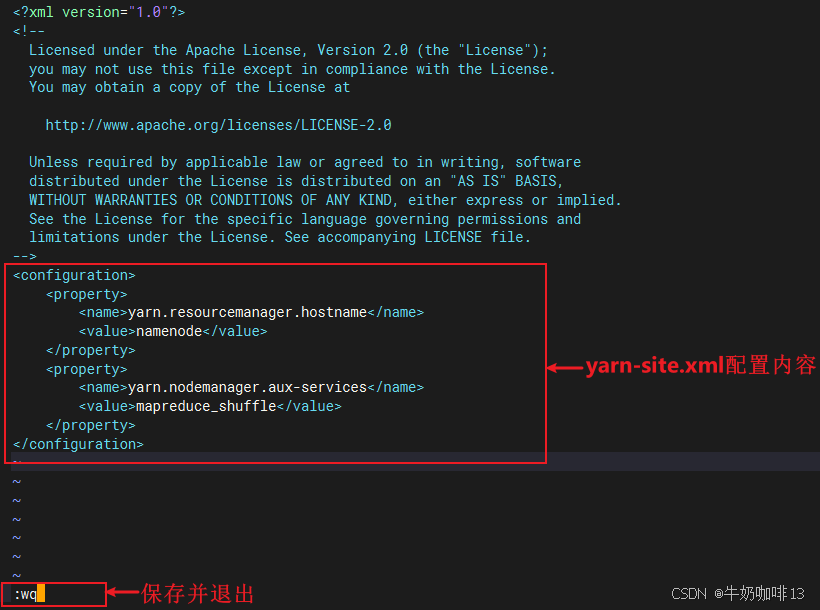
2.3.5、配置【workers】
bash
#配置Hadoop的配置文件【workers】的实操流程
#1-进入Hadoop的配置文件路径【如:/data/hadoop-3.4.2/etc/hadoop】
cd /data/hadoop-3.4.2/etc/hadoop
#2-给【workers】配置从节点名称
vi workers
#workers添加的内容
hadoop02
hadoop03
2.4、其他从节点Hadoop配置
将当前主节点配置好的Hadoop文件夹分发到所有从节点:
bash
#1-将/data/hadoop-3.4.2文件夹的属主、属组权限都修改为hd用户;且压缩一份配置好的hadoop
chown -R hd:hd /data/hadoop-3.4.2
tar -Jcvf hadoop-3.4.2.tar.xz hadoop-3.4.2
#2-将当前主节点配置好的Hadoop文件夹分发到所有从节点:
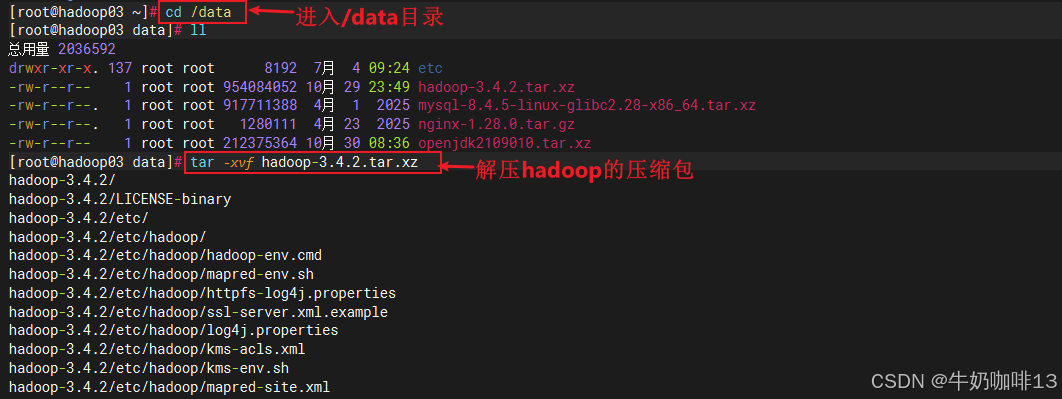
cd /data
scp -P 22 hadoop-3.4.2.tar.xz root@hadoop02:/data
scp -P 22 hadoop-3.4.2.tar.xz root@hadoop03:/data
#3-分别进入到各个从节点配置Hadoop全局可用(所有从节点都需要执行)
#3.1-进入/data目录并解压下载好的Hadoop
cd /data
tar -xvf hadoop-3.4.2.tar.xz
#3.2-配置全局变量实现在任意位置都可以执行hadoop
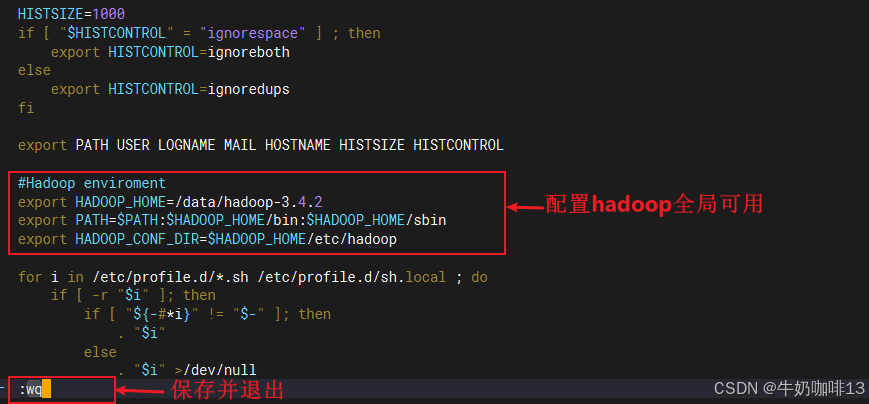
vi /etc/profile
#Hadoop enviroment
export HADOOP_HOME=/data/hadoop-3.4.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#3.3-让修改的环境变量生效
source /etc/profile
chown -R hd:hd /data/hadoop-3.4.2



2.5、其他从节点系统环境配置
bash
#Hadoop其他从节点的环境配置
#1-现在Hadoop主节点将安装好的jdk21、jre21打包,并分别发送到其他从节点
tar -Jcvf openjdk2109010.tar.xz openjdk2109010
scp -P 22 openjdk2109010.tar.xz root@hadoop02:/data
scp -P 22 openjdk2109010.tar.xz root@hadoop03:/data
#2-在从节点解压jdk21、jre21压缩包及其配置系统环境全局可用(每个从节点都需要执行)
cd /data
tar -xvf openjdk2109010.tar.xz
#2.1-配置从节点的jdk21、jre21系统环境全局可用
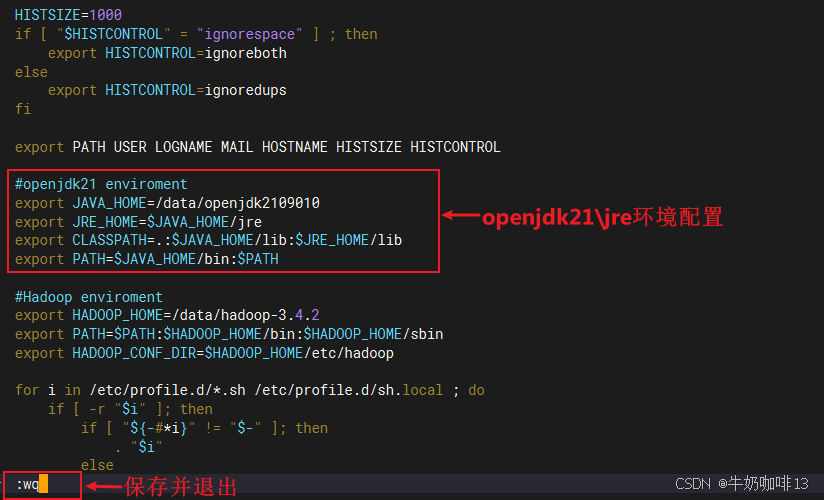
vi /etc/profile
#openjdk21 enviroment
export JAVA_HOME=/data/openjdk2109010
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
#2.2-让修改的环境变量生效
source /etc/profile
#2.3-查看java版本信息
echo $JAVA_HOME
echo $PATH
java -version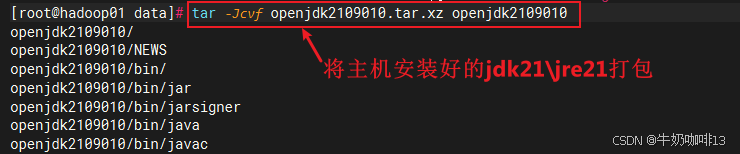


2.6、启动Hadoop集群
在正式启动Hadoop集群前,需要检查一下所有Hadoop服务器的ssh端口都修改为22222。
bash
#检查ssh的端口是否为【22222】(若不是则需要设置)
#1-先备份ssh的配置文件
cd /etc/ssh/
cp -p sshd_config sshd_config.bak
#2-修改ssh的配置文件【/etc/ssh/sshd_config】里面的【Port】值为【22222】且取消注释并保存退出
vi /etc/ssh/sshd_config
Port 22222
#3-(若防火墙是开启中)则需要先将防火墙的22222端口放开
firewall-cmd --list-port
firewall-cmd --zone=public --add-port=22222/tcp --permanent
firewall-cmd --reload
firewall-cmd --list-port
#3-重启sshd服务(若此时重启sshd服务失败,则可以先临时禁用selinux【setenforce 0】)
systemctl restart sshd.service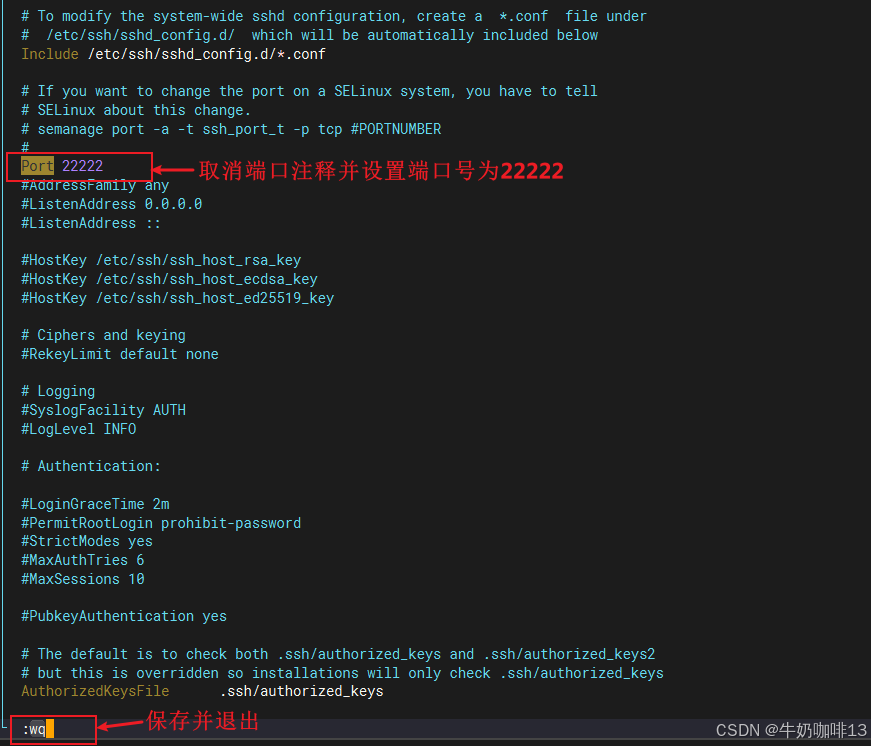
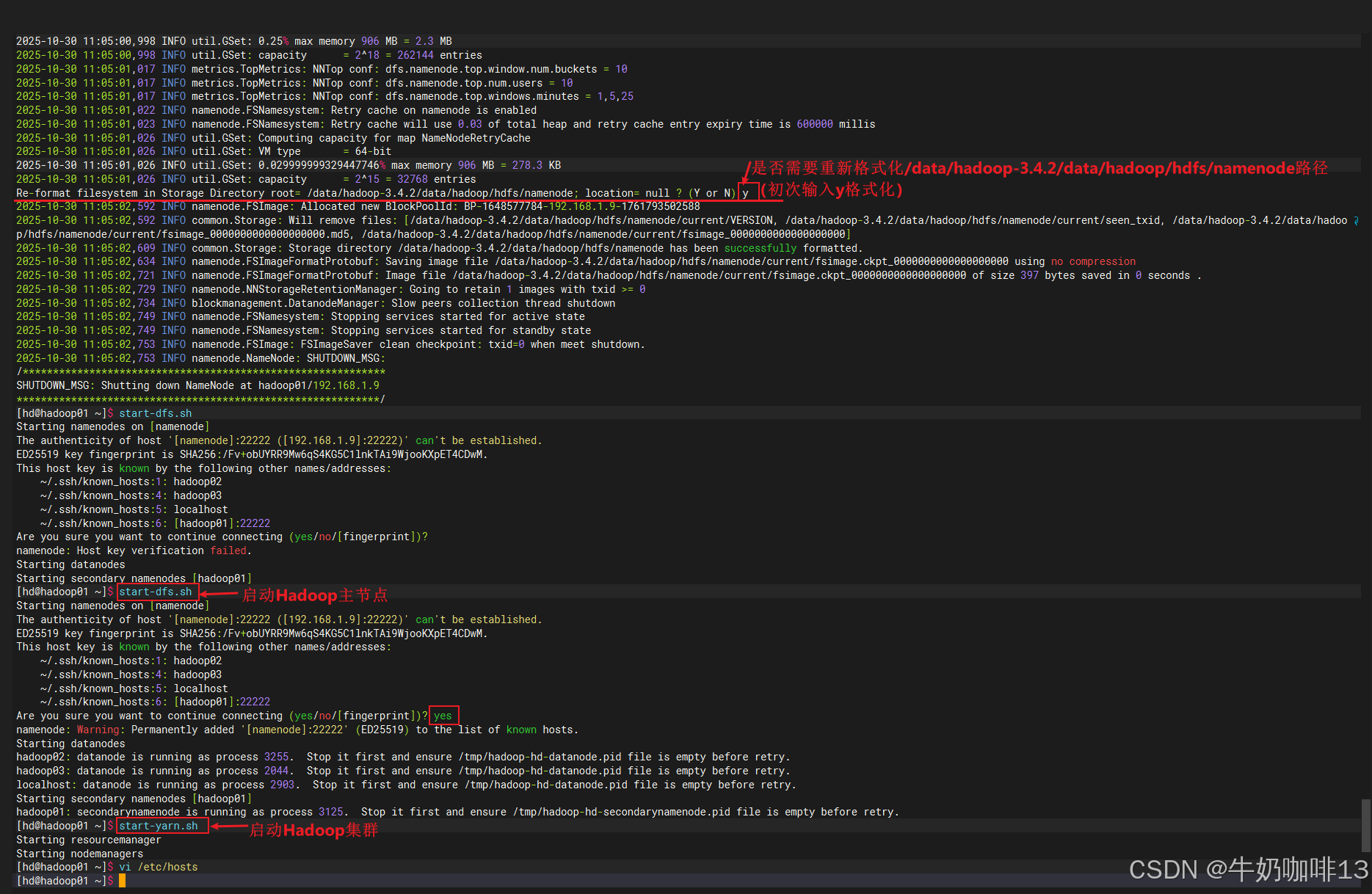
bash
#启动HDFS集群实操流程(注意:在启动Hadoop集群前需要确保其他节点的Hadoop也都安装配置好了)
#0-先切换到hd用户
su - hd
#1-在主节点(hadoop01【192.168.1.9】)上格式HDFS
hdfs namenode -format
#2-启动 HDFS 和 YARN
start-dfs.sh
start-yarn.sh
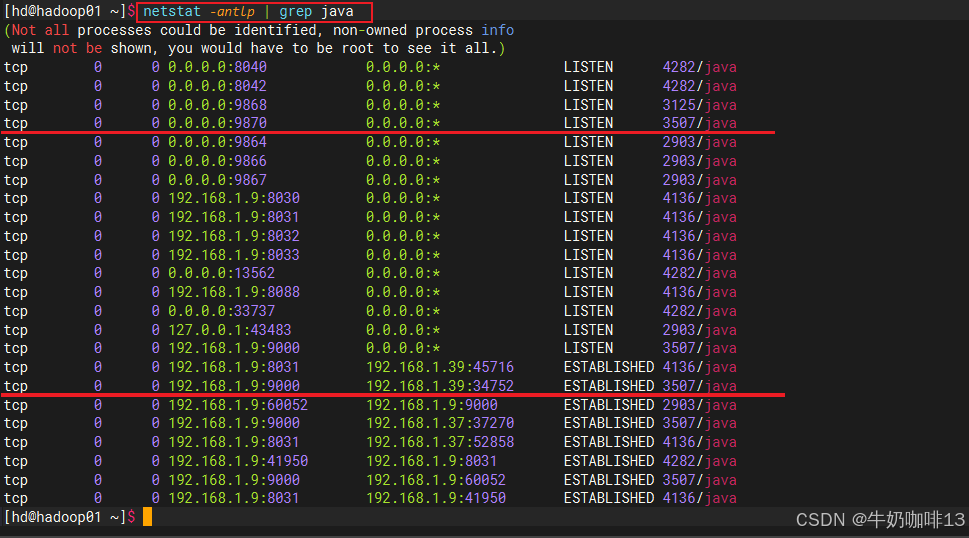
#3-查看所有网络情况
netstat -antlp | grep java
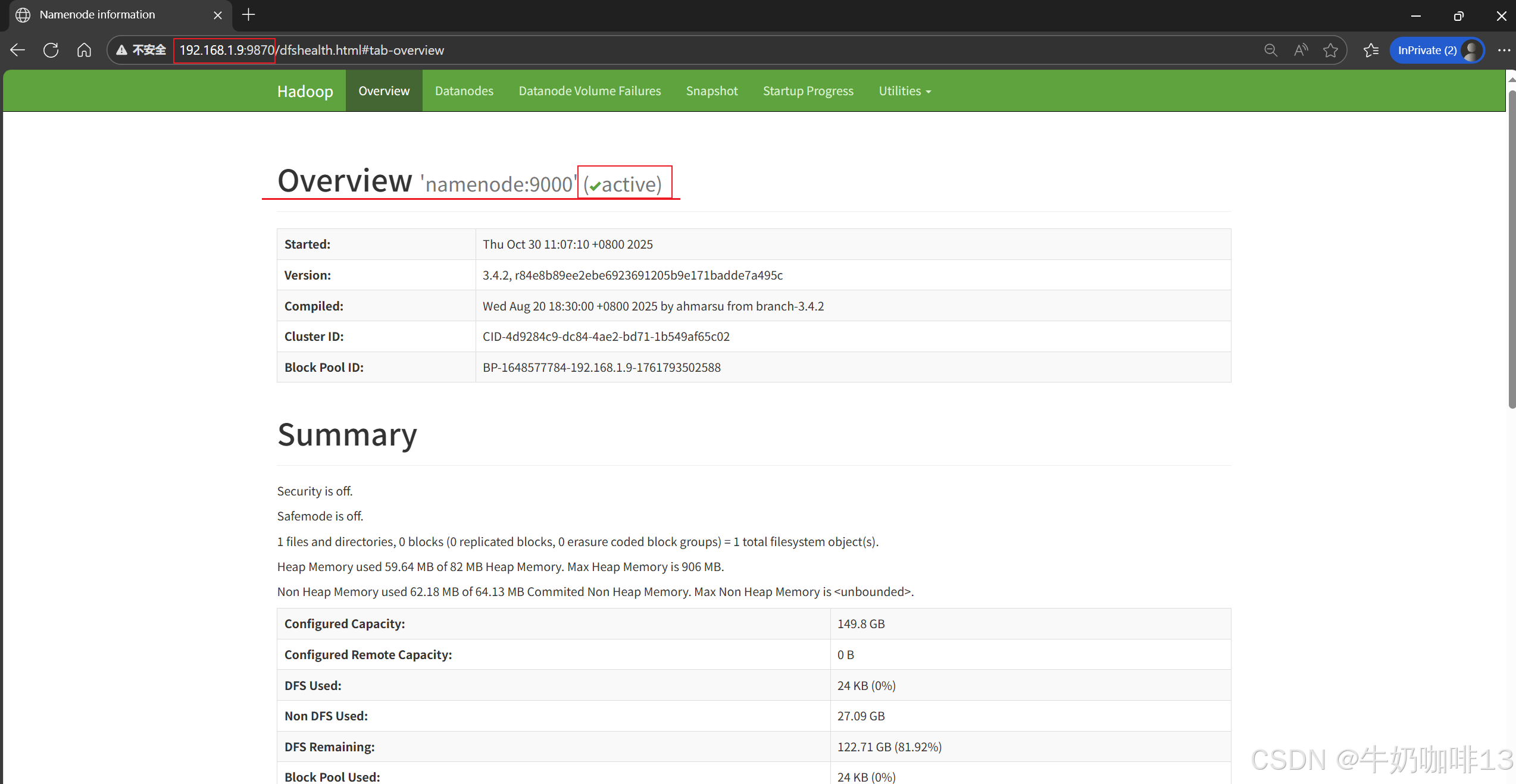
#3-在浏览器访问(主节点namenode的IP地址查看命令是【ip a】):
HDFS Web UI:http://<namenode IP>:9870
YARN Web UI:http://<namenode IP>:8088
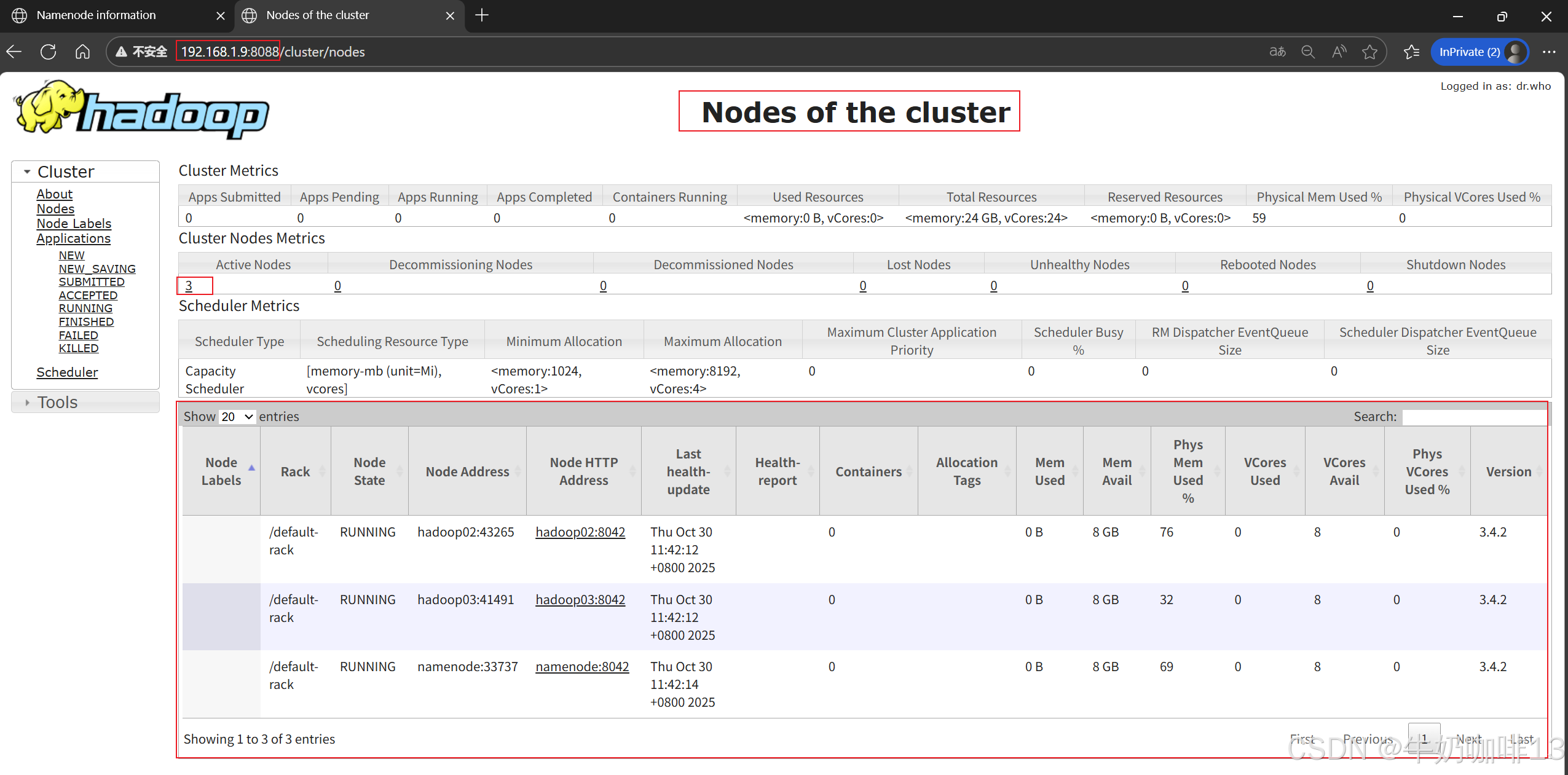
2.7、Hadoop集群管理
|--------|-------------------|-------------------------------------------------------------------------------------|
| 序号 | Hadoop集群管理操作 | 说明 |
| 1 | #### 添加新的数据节点 | 只需将主节点上的 Hadoop 安装包分发到新节点,并在主节点Hadoop配置文件【workers 】中添加新节点的主机名,然后重启 HDFS 即可。 |
| 2 | #### 高可用配置 | 通过设置多个 NameNode 和 JournalNode,可以在一个 NameNode 失败时自动切换到另一个 NameNode。 |
| 3 | #### 监控和管理 | 《1》使用 Hadoop 自带的 Web UI 监控集群状态。 《2》查看日志文件以排查问题,日志文件位于【/data/hadoop-3.3.4/logs 】目录下。 |
[Hadoop集群管理]
三、Hadoop的常见问题和解决方法
3.1、Hadoop的常见问题和解决方法
|--------|--------------------|-----------------------------------------------------------------------------------------------------------|
| 序号 | Hadoop的常见问题 | Hadoop的常见问题解决方法 |
| 1 | #### namenode未成功启动 | 需要确保Hadoop的主节点的主机名称与hosts文件里面都配置为【namenode】 |
| 2 | #### DataNode未成功启动 | 《1》需要确保Hadoop的配置文件【hdfs-site.xml】里配置的【 dfs.datanode.data.dir 】参数指定的目录存在且有权限; 《2》需要确保从节点可以访问到主节点的【9000】端口。 |
| 3 | #### 网络问题 | 需要确保所有节点的网络配置正确,且都可以通过ping相互测试畅通。 |
| 4 | #### 权限问题 | 需要确保 Hadoop 安装目录和数据目录的权限配置正确 (可以使用如【chown -R hd:hd /data/hadoop-3.4.2】命令调整) |
[Hadoop的常见问题和解决方法]
3.2、Hadoop官网资料
Hadoop -- Apache Hadoop 3.4.2![]() https://hadoop.apache.org/docs/stable/Apache Hadoop 3.4.2 -- Hadoop:设置单节点集群。
https://hadoop.apache.org/docs/stable/Apache Hadoop 3.4.2 -- Hadoop:设置单节点集群。![]() https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html