目录
前言
在日常生活中,饮食是人们不可或缺的一部分,而食谱与菜单的管理则是一个典型的一对多关系实例。一个食谱餐别(如早餐、午餐、晚餐等)可以对应多个菜单详情(具体的菜品及其制作信息等),这种关系清晰地体现了"一"与"多"之间的关联。以食谱餐别与菜单详情为例来探讨 MybatisPlus 中实现一对多查询的多种方法,不仅具有实际的业务应用场景价值,还能帮助开发者更好地理解和掌握相关技术,提升开发效率与数据处理能力。MybatisPlus 作为一款流行的 Java 持久层框架,在数据操作方面提供了诸多便捷与强大的功能,深受开发者青睐。其中,一对多查询的实现是数据库关联查询中极为常见且重要的场景,它能够帮助我们构建丰富、复杂且逻辑清晰的数据模型,满足各种业务需求。

本文将以食谱餐别与菜单详情这一具体案例为切入点,详细探讨 MybatisPlus 中实现一对多查询的多种方法,包括它们的实现原理、代码示例、优缺点分析以及在实际应用中的注意事项等。希望通过本文的介绍,能够帮助广大开发者在面对类似的一对多查询场景时,能够更加得心应手地运用 MybatisPlus 提供的强大功能,提升开发效率,构建更加优质的软件系统。
一、数据库物理表及模型类
为了让大家对这个一对多的物理表有一个基本的认识,这里我们将给出数据库物理表结构和对应的JavaBean,这两个对象是我们日常开发系统的核心关注点。很多的业务都是围绕这两个点去开展。
1、数据库物理表
在之前的博文中,我们曾经以国家健康食谱为例,详细的介绍了相关的数据存储物理表。下面即选取其中两张比较有代表性的表,食谱餐别信息表和菜单详情信息表。食谱餐别信息表物理表SQL语句如下:
sql
CREATE TABLE "public"."biz_recipe_meal_type" (
"pk_id" int8 NOT NULL,
"recipe_id" int8,
"meal_type_name" varchar(10) COLLATE "pg_catalog"."default",
"order_num" int2,
CONSTRAINT "pk_biz_recipe_meal_type" PRIMARY KEY ("pk_id")
);
COMMENT ON COLUMN "biz_recipe_meal_type"."pk_id" IS '主键';
COMMENT ON COLUMN "biz_recipe_meal_type"."recipe_id" IS '食谱id';
COMMENT ON COLUMN "biz_recipe_meal_type"."meal_type_name" IS '餐别名称,如早餐、加餐等';
COMMENT ON COLUMN "biz_recipe_meal_type"."order_num" IS '排序号';
COMMENT ON TABLE "biz_recipe_meal_type" IS '食谱餐别信息表';食谱餐别信息表存储的数据如下:
sql
pk_id recipe_id meal_type_name order_num
1 1 早餐 1
1979210036504735746 1 加餐 2
1979209310982418434 1 中餐 3
1979338709262258178 1 晚餐 4
1979339628263624705 1 油、盐 5菜单详情信息表物理表SQL如下:
sql
CREATE TABLE "public"."biz_recipe_details" (
"pk_id" int8 NOT NULL,
"meal_type_id" int8,
"name" varchar(100) COLLATE "pg_catalog"."default",
"formula" varchar(100) COLLATE "pg_catalog"."default",
"order_num" int2,
CONSTRAINT "pk_biz_recipe_details" PRIMARY KEY ("pk_id")
);
COMMENT ON COLUMN "biz_recipe_details"."pk_id" IS '主键';
COMMENT ON COLUMN "biz_recipe_details"."meal_type_id" IS '餐别id';
COMMENT ON COLUMN "biz_recipe_details"."name" IS '名称';
COMMENT ON COLUMN "biz_recipe_details"."formula" IS '配方信息';
COMMENT ON COLUMN "biz_recipe_details"."order_num" IS '排序号';
COMMENT ON TABLE "biz_recipe_details" IS '菜单详情信息表';菜单详情信息表存储的信息如下:
sql
pk_id meal_type_id name formula order_num
1979340957220458498 1979340957220458497 二米饭 大米 30g,小米 20g 1
1979340957220458499 1979340957220458497 蒜苔炒肉 猪里脊肉 50g,蒜苔 100g 2
1979340957220458500 1979340957220458497 尖椒土豆片 尖椒 50g,土豆 50g 3
1979340957220458501 1979340957220458497 决明子海带豆腐汤 决明子*10g,海带【水发】50g,南豆腐 50g 42、Java对象类
与数据库表一一对应的是,与每一个数据库表都有一个对应的实体类,闲言少叙,这里直接给出对应的JavaBean实现。
java
package com.yelang.project.extend.earthquake.domain;
import java.io.Serializable;
import java.util.List;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
/**
* - 食谱餐别信息表
* @author 夜郎king
*/
@TableName(value = "biz_recipe_meal_type")
@NoArgsConstructor
@AllArgsConstructor
@Setter
@Getter
@ToString
public class RecipeMealType implements Serializable {
private static final long serialVersionUID = 4399855059597304978L;
@TableId(value = "pk_id")
private Long pkId;// 主键
@TableField(value = "recipe_id")
private Long recipeId;// 食谱id
@TableField(value = "meal_type_name")
private String mealTypeName;// 餐别名称,如早餐、加餐等
@TableField(value = "order_num")
private Integer orderNum;// 排序号
@TableField(exist = false)
private List<RecipeDetails> recipeDetailsList;//菜单详情
public RecipeMealType(Long recipeId, String mealTypeName, Integer orderNum) {
super();
this.recipeId = recipeId;
this.mealTypeName = mealTypeName;
this.orderNum = orderNum;
}
}菜单详情信息表对应的实体类如下:
java
package com.yelang.project.extend.earthquake.domain;
import java.io.Serializable;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
/**
* - 菜单详情信息表
* @author 夜郎king
*/
@TableName(value = "biz_recipe_details")
@NoArgsConstructor
@AllArgsConstructor
@Setter
@Getter
@ToString
public class RecipeDetails implements Serializable {
private static final long serialVersionUID = -4003180539390925788L;
@TableId(value = "pk_id")
private Long pkId;// 主键
@TableField(value = "meal_type_id")
private Long mealTypeId;// 餐别id
private String name;// 名称
private String formula;// 配方信息
@TableField(value = "order_num")
private Integer orderNum;// 排序号
public RecipeDetails(Long mealTypeId, String name, String formula, Integer orderNum){
super();
this.mealTypeId = mealTypeId;
this.name = name;
this.formula = formula;
this.orderNum = orderNum;
}
}从以上两个对象的实现上可以看到,在RecipeMealType.java中有一个private List<RecipeDetails> recipeDetailsList;//菜单详情集合。完美符合一对多的查询实现场景。后面我们将基于这两个基础类来详细说明如何进行一对多的查询实现。
二、MybatisPlus中一对多的两种实现
在传统的数据库查询中,实现一对多查询可能会涉及到复杂的 SQL 语句编写,以及在代码层面进行繁琐的数据组装和处理。MybatisPlus 的出现极大地简化了这一过程,它在继承了 Mybatis 优秀特性的同时,还提供了诸如代码生成器、CRUD 操作简化等众多新特性。在一对多查询的实现上,MybatisPlus 提供了多种方法,每种方法都有其独特的优势和适用场景。
1、业务层编码实现
MybatisPlus 支持使用分步查询的方式实现一对多查询。首先查询主表数据,然后根据主表中的关联字段,再查询从表数据。这种方法在一定程度上可以缓解数据库的压力,尤其是在面对大量数据时,通过合理的分步查询策略,能够提高查询效率。但它的缺点是需要在代码层面进行更多的逻辑处理,以确保数据的完整性和一致性。这种实现方式比较简单,我们只需要在业务代码中来进行编码实现。以下代码即是一种实现场景,这种场景原理比较简单,这里给出具体的实现代码:
java
List<RecipeDetails> list = recipeDetailsService.selectListByMealTypeId(pkId);
RecipeMealType recipeMealType = recipeMealTypeService.getById(pkId);
recipeMealType.setRecipeDetailsList(list);在上述的方法中,有一个根据主表id查询子表列表的方法,具体实现如下:
java
@Override
public List<RecipeDetails> selectListByMealTypeId(Long mealTypeId) {
QueryWrapper<RecipeDetails> queryWrapper = new QueryWrapper<RecipeDetails>();
queryWrapper.eq("meal_type_id", mealTypeId);
return this.baseMapper.selectList(queryWrapper);
}以上就是一种比较简单的使用自主编码的形式进行对象获取的方法。通过这种方法也是可以获取相关对象。
2、Mapper中注解实现
除了通过手动编码的方式进行关联查询,也通过使用 MybatisPlus 提供的关联查询注解,如 @Many,可以方便地在实体类中定义关联关系,实现自动的关联查询。这种方法在代码的可读性和维护性方面表现出色,能够让开发者以更加直观的方式理解和操作数据关联。然而,它也可能在某些复杂场景下受到性能或灵活性的限制。这里我们介绍注解的实现方式,首先我们需要在多的这一端的数据库操作类实现一个查询列表的方法,比如需要根据餐别id查询菜单列表,实现代码如下:
java
package com.yelang.project.extend.earthquake.mapper;
import java.util.List;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.yelang.project.extend.earthquake.domain.RecipeDetails;
public interface RecipeDetailsMapper extends BaseMapper<RecipeDetails>{
@Select("SELECT * FROM biz_recipe_details WHERE meal_type_id = #{mealTypeId} order by order_num ")
List<RecipeDetails> queryListByMealTypeId(@Param("mealTypeId")Long mealTypeId);
}然后在一的数据库操作类中实现自定义注解,将多端的对象查询配置进来(需要注意的是,在配置的Many属性中,select的配置要配完整,否则极易出错),核心实现如下:
java
package com.yelang.project.extend.earthquake.mapper;
import org.apache.ibatis.annotations.Many;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Result;
import org.apache.ibatis.annotations.Results;
import org.apache.ibatis.annotations.Select;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.yelang.project.extend.earthquake.domain.RecipeMealType;
public interface RecipeMealTypeMapper extends BaseMapper<RecipeMealType>{
@Select("SELECT * FROM biz_recipe_meal_type WHERE pk_id = #{pkId}")
@Results({
@Result(property = "recipeDetailsList", column = "pk_id",
many = @Many(select = "com.yelang.project.extend.earthquake.mapper.RecipeDetailsMapper.queryListByMealTypeId"))
})
RecipeMealType queryMealTypeById(@Param("pkId")Long pkId);
}通过以上基本就实现了在MybatisPlus中进行一对多的查询。下面我们使用Junit来测试一下相关的运行逻辑,核心代码如下:
java
package com.yelang.project.mybatisplus;
import java.util.List;
import org.junit.Assert;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import com.yelang.project.extend.earthquake.domain.RecipeDetails;
import com.yelang.project.extend.earthquake.domain.RecipeMealType;
import com.yelang.project.extend.earthquake.service.IRecipeMealTypeService;
@SpringBootTest
@RunWith(SpringRunner.class)
public class RecipeMealTypeOne2ManyCase {
@Autowired
private IRecipeMealTypeService recipeMealTypeService;
/**
* - 多次查询实例
*/
@Test
public void testOne2Many() {
Long pkId = 1979340472086286337L;
RecipeMealType recipeMealType = recipeMealTypeService.queryMealTypeById(pkId);
Assert.assertNotNull(recipeMealType);
System.out.println(recipeMealType);
List<RecipeDetails> recipeDetailsList = recipeMealType.getRecipeDetailsList();
Assert.assertNotNull(recipeDetailsList);
System.out.println(recipeDetailsList.size());
for (RecipeDetails details : recipeDetailsList) {
System.out.println(details);
}
}
}程序运行之后,在控制台可以看到一下输出,表名我们已经实现了查询转换。
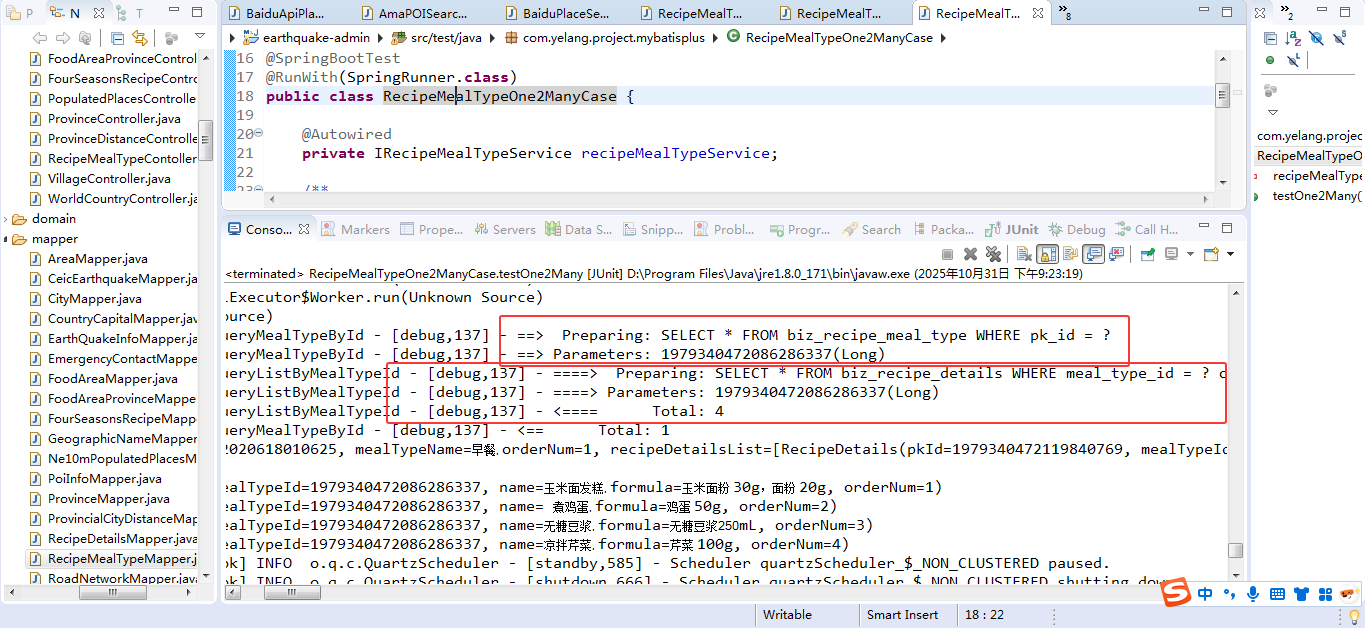
可以很明显的看到,在后台的执行过程中,SQL语句发了两次。
3、Mapper中Xml实现
另一种方法是手动编写 SQL 语句,通过 MybatisPlus 的 XML 配置或注解方式进行查询。这种方式虽然在灵活性上极高,能够满足各种复杂的查询需求,但同时也增加了代码的复杂度和开发成本。关于在Mapper中使用Xml的具体实现,这里不深入讲解,大家可以参考以下内容,其实原理与注解的实现形式差不多的。
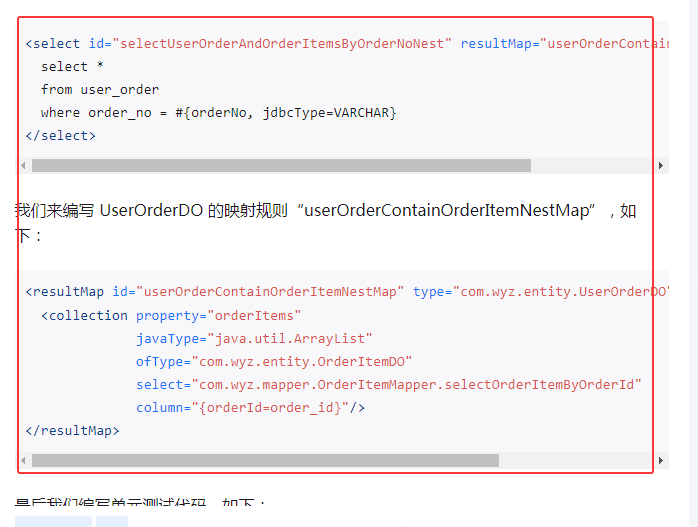
三、使用场景及综合推荐
下面从使用场景及其具体的推荐来说明一下不同的实现方式的区别。
1、使用场景及优缺点对比
简单查询场景
-
使用场景:查询逻辑简单,只需要查询主表和从表的直接关联关系。
-
推荐方法 :使用
@OneToMany注解实现。 -
理由:注解方式可以快速实现查询功能,代码简洁且易于维护,适合简单查询场景。
复杂查询场景
-
使用场景:查询逻辑复杂,需要在查询过程中进行额外的业务处理,或者需要对查询结果进行复杂组装和处理。
-
推荐方法:使用业务代码实现。
-
理由:业务代码提供了更高的灵活性,可以更好地处理复杂的查询逻辑和业务需求,适合复杂查询场景。
性能敏感场景
-
使用场景:数据量大,对查询性能有较高要求。
-
推荐方法:使用业务代码实现。
-
理由:通过分步查询和手动处理,可以更好地控制查询性能,减少单次查询的压力,适合性能敏感场景。
快速开发场景
-
使用场景:开发初期,需要快速搭建基本的数据查询功能。
-
推荐方法 :使用
@OneToMany注解实现。 -
理由:注解方式可以快速实现查询功能,减少代码编写量,提高开发效率,适合快速开发场景。
2、综合推荐
在选择使用业务代码实现还是 @OneToMany 注解实现时,需要根据具体的使用场景和项目需求进行综合考虑。对于简单查询场景和快速开发场景,推荐使用 @OneToMany 注解实现,以提高开发效率和代码简洁性;对于复杂查询场景和性能敏感场景,推荐使用业务代码实现,以提供更高的灵活性和更好的性能控制。在实际开发中,也可以根据不同的场景混合使用这两种方法,以达到最佳的开发效果和性能表现。
四、总结
以上就是本文的主要内容,本文通过对 MybatisPlus 中实现一对多查询的多种方法进行深入解析和对比分析,我们不仅能够更好地理解每种方法的原理和适用场景,还能够在实际项目中根据具体情况灵活选择最合适的方法,从而实现高效、稳定且可维护的数据查询功能。在实际开发中,选择哪种方法实现一对多查询,需要根据具体的业务需求、数据量大小、系统的性能要求以及开发团队的技术水平等多方面因素进行综合考量。行文仓促,定有许多的不足之处,欢迎各位朋友在评论区批评指正,不胜感激。