大语言模型的英文全称是"Large Language Models",通常简称为LLM。这里的"大"并不是指它的物理尺寸,而是指它的参数量极其庞大。比如,Deepseek模型有6710亿个参数,这个数字是什么概念呢?相当于地球上每个人分到80多个参数。
这些模型基于一种革命性的深度学习架构------Transformer架构。这个架构我们在后面会详细讲解,它让模型能够同时处理大量的文本信息,而不是像以前那样只能逐词处理。
大语言模型通过学习海量的文本数据,阅读了互联网上几乎所有的公开文本------包括维基百科、新闻文章、科学论文、小说诗歌等等。不仅记住了事实性知识,更重要的是学会了语言的模式、语法结构、语义关系,甚至不同领域的专业表达方式。

2022年11月30日发生了一件事。
这一天,OpenAI发布了ChatGPT。当时可能没有人能预料到,这个产品会在如此短的时间内引发全球性的关注浪潮。
ChatGPT仅用两个月时间,日活跃用户就突破了1亿大关。这个增长速度是什么概念呢? 之前的一些具有全球影响力的应用都用了几十个月才到1亿用户,连火的一塌糊涂的tiktok都用了9个月,而ChatGPT只用了两个月就席卷全球。
它之所以能如此迅速的获得用户青睐,跟它的对话体验流畅性是分不开的,可以毫不夸张的说,对于绝大多数人来说,它凭一己之力把人工智能从科幻拽进了生活。

ChatGPT的成功就像在平静的湖面投下了一块石头,短短两年多的时间里,我们看到了一场全球意义上的"百模大战"。
国内外各大科技企业纷纷涌入这个大模型赛道,比较有代表性的,国内有深度求索的"Deepseek",百度的"文心一言",字节跳动的"豆包",月之暗面的"Kimi",清华智谱AI等等,国际上谷歌推出了"Gemini"系列,马斯克的"Grok"模型,这些模型可以说各有所长,给整个大语言模型生态注入了活力。
 2017年,当时,谷歌研究团队发表了一篇名为《Attention Is All You Need》的论文。这篇论文提出了一种全新的框架------Transformer,其核心是一种叫做"自注意力机制"的创新技术。
2017年,当时,谷歌研究团队发表了一篇名为《Attention Is All You Need》的论文。这篇论文提出了一种全新的框架------Transformer,其核心是一种叫做"自注意力机制"的创新技术。
我们可以用一个简单的比喻来理解自注意力机制,当你在阅读一篇文章时,你的大脑会自然地将注意力集中在与当前句子最相关的上下文上。比如,当你看到"苹果"这个词时,如果前文在讨论水果,你会想到可以吃的水果;如果前文在讨论科技产品,你会想到iPhone。
自注意力机制让模型能够实现类似的能力。它可以动态地计算输入序列中每个词与其他所有词的相关性,从而确定在理解当前词时,应该更加"关注"哪些上下文信息。
这种机制的强大之处在于,它能够有效捕捉文本序列中的长距离依赖关系。在传统的模型中,距离较远的词语之间很难建立联系,而自注意力机制打破了这一限制,使得模型能够真正实现上下文的理解。
就是这一突破,为大语言模型的崛起奠定了技术可能性。我们可以记住照片上这些人,用中国话来说,这些人配享太庙。
大家在使用大语言模型时,可能都注意到一个有趣的现象:模型的回答是一个词一个词往外"蹦"的,而不是一次性给出完整的答案。
这种输出方式并不是为了营造科技感或者高级感,而是由大语言模型的基本原理决定的。
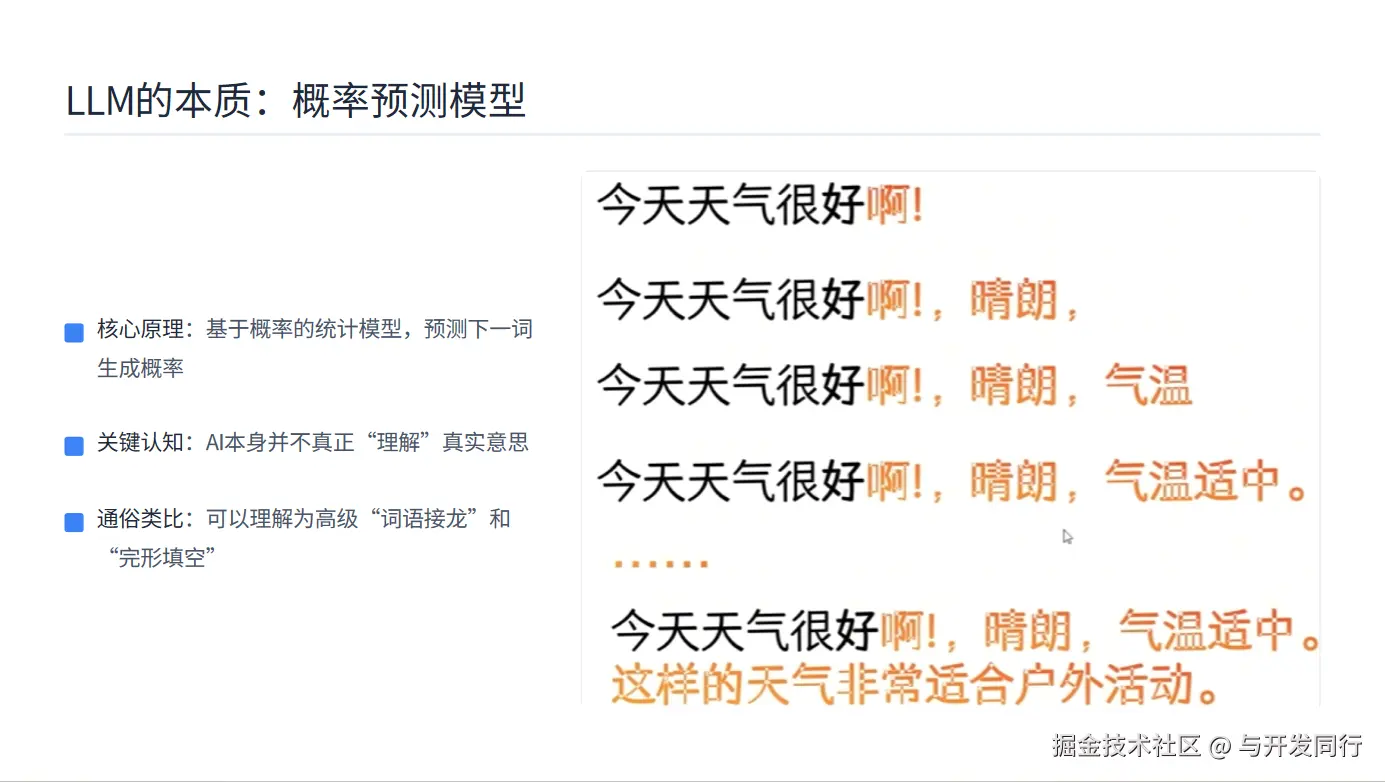
大语言模型本质上是一个基于概率的统计模型。它的核心任务很简单------预测下一个最可能出现的词。
让我们用一个具体的例子来说明。假设模型看到的输入是"今天天气很好啊!",那么模型的任务就是计算在众多可能的后续词汇中,哪个词出现的概率最高。可能就是"清朗""气温适合""户外活动"这些词。
这种工作模式可以理解为两种我们熟悉的语言游戏:词语接龙和完形填空。
在词语接龙中,我们需要根据前一个词来想出下一个词;在完形填空中,我们需要根据上下文来补全缺失的词语。大语言模型做的就是类似的事情,只不过它的"词汇量"和"背景知识"要丰富得多。
人工智能并不真正"理解"语言的意义。它不知道"阳光"的温暖,不理解"爱情"的甜蜜,也不体会"悲伤"的痛苦。它只是在大量文本数据中学习到了词语之间的统计规律。
尽管豆包可以给足我们情绪价值,但很遗憾,我们的感受,它并一点都不能体会和理解。
当模型接收到一个句子时,它并不是直接处理我们看到的文字,而是使用一个叫做"分词器"的工具将句子分解成更小的单元,这些单元就是我们常说的"Token"。
什么是Token呢?它可能是单个汉字,比如"天";也可能是常见的词语组合,比如"天气";甚至可能是英文单词的一部分。分词器的任务就是找到最优的切分方式。
每个Token都会被赋予一个唯一的数字标识,称为Token ID。这个过程就像给每个词分配一个身份证号码。
但数字本身并不能表达语义信息,所以模型还需要将这些数字转换成高维向量。什么是向量呢?简单来说,它是一组数字,代表了该Token在多维空间中的位置。语义相近的词在向量空间中的位置也相近。
例如,"国王"和"君主"的向量会比较接近,而"国王"和"苹果"的向量则相距较远。
这种向量表示的好处是,它能够捕捉词语之间的复杂关系。经典的例子是:向量("国王") - 向量("男人") + 向量("女人") ≈ 向量("女王")。

前面的介绍中,我们提到了大语言模型基于概率预测下一个词。现在,让我们更深入地了解这个概率机制,以及它如何解释模型行为的随机性。
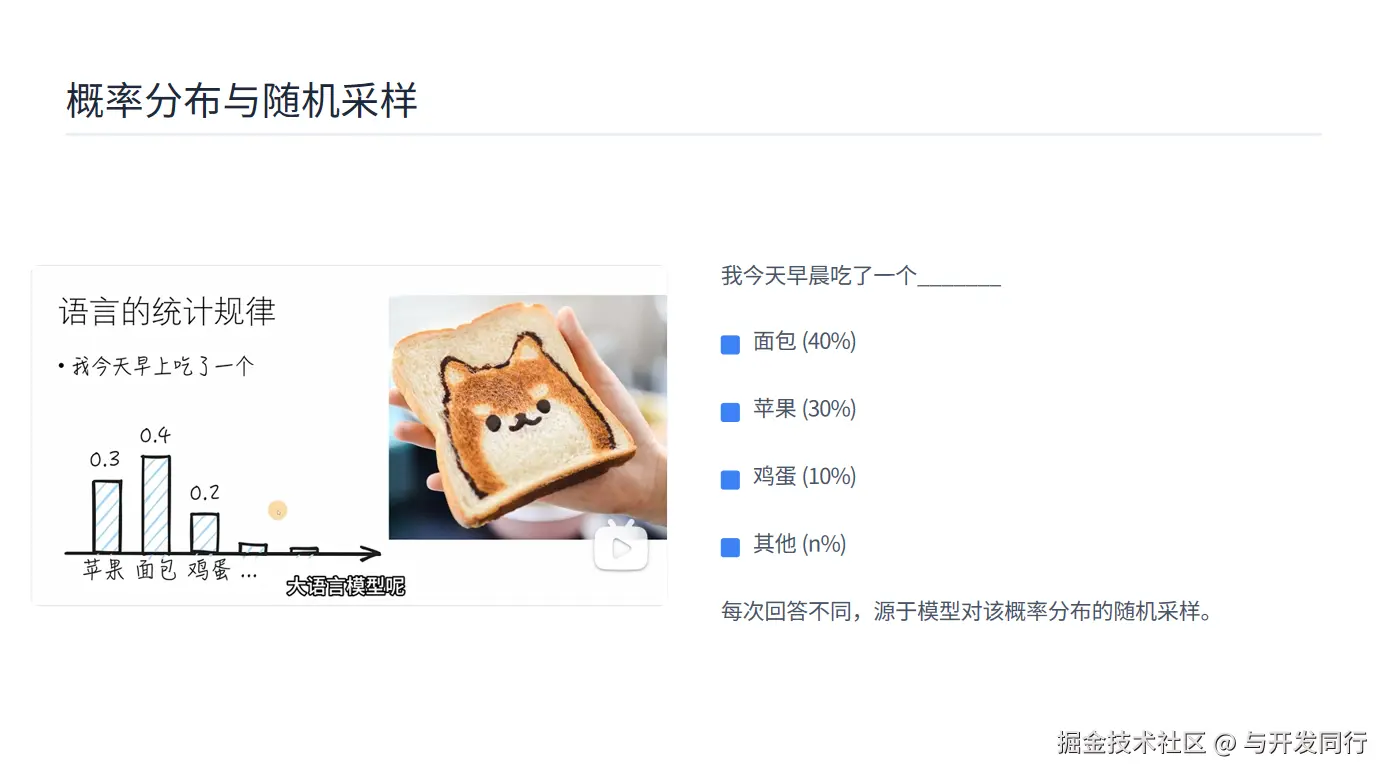
考虑这样一个不完整的句子:"我今天早晨吃了一个_______"。
面对这个填空,大语言模型不会只给出一个确定的答案,而是会计算各种可能性的概率分布。例如:
"面包"可能有40%的概率
"苹果"可能有30%的概率
"鸡蛋"可能有10%的概率
其他食物选项合计20%的概率
那么,模型如何根据这个概率分布选择最终的输出呢?这里有一个重要的概念------随机采样。
随机采样不是简单地选择概率最高的选项,而是按照概率分布进行随机选择。
这就解释了为什么我们向同一个大语言模型提出相同的问题时,可能会得到略有不同的回答。
在实际应用中,开发者可以通过调整"温度"参数来控制这种随机性。温度越高,输出越随机、越有创造性;温度越低,输出越确定、越保守。
这里面还需要澄清一个更加抽象但至关重要的概念------高维向量空间,这是大语言模型能够理解词语多义性的关键。
考虑一个有趣的例子:大语言模型如何区分吃的"苹果"和用的"苹果"?
当模型遇到"苹果"这个词时,它不会只有一个固定的理解,而是会根据上下文在向量空间中找到最合适的位置。
在模型的向量空间中,每个词都被表示为一个高维向量。语义相近的词在空间中的位置也相近。因此:
吃的"苹果"会靠近"水果"、"甜"、"红色"、"吃"等词的向量
用的"苹果"会靠近"手机"、"电脑"、"品牌"、"科技"等词的向量
当模型处理"我吃了一个苹果"时,"苹果"的向量会在空间中被拉向食物相关的区域;而在处理"我买了一部苹果手机"时,同样的"苹果"会被拉向科技产品区域。
我们人类很难直观理解高维空间,因为我们生活在三维世界中。在PPT中,我们只能展示二维或三维的示意图,但真实的大语言模型运作在极高的维度中------GPT系列的模型可能有超过1万个维度!

在欣赏大语言模型强大能力的同时,我们也必须清醒地认识到它目前面临的最大挑战------AI幻觉问题。
什么是AI幻觉?简单来说,就是大语言模型会"一本正经地胡说八道"。它会生成看似合理但实际上是错误的信息,甚至会引用不存在的文献、编造虚假的数据、描述从未发生的事件。
我们要理解AI幻觉并非程序的Bug,而是大语言模型核心工作原理带来的必然产物。
大语言模型本质上是基于统计规律预测下一个词,它并不真正"理解"事实真相。
彻底解决AI幻觉问题,可能需要在现有框架上进行根本性的创新,甚至是完全推翻现有的框架。