目录
[一、 工业仪器仪表检测:挑战与任务定义](#一、 工业仪器仪表检测:挑战与任务定义)
[1.1 检测对象细分](#1.1 检测对象细分)
[1.2 核心技术挑战](#1.2 核心技术挑战)
[1.3 任务分解](#1.3 任务分解)
[二、 YOLOv8核心原理与工业应用优势](#二、 YOLOv8核心原理与工业应用优势)
[2.1 YOLOv8架构精讲(面向实践)](#2.1 YOLOv8架构精讲(面向实践))
[2.2 为何选择YOLOv8用于工业仪表检测?](#2.2 为何选择YOLOv8用于工业仪表检测?)
[三、 实战:构建工业仪表检测系统全流程](#三、 实战:构建工业仪表检测系统全流程)
[3.0 环境配置](#3.0 环境配置)
[3.1 数据准备与标注](#3.1 数据准备与标注)
[3.2 数据增强策略(提升模型鲁棒性关键)](#3.2 数据增强策略(提升模型鲁棒性关键))
[3.3 模型训练与调优](#3.3 模型训练与调优)
[3.4 核心代码片段](#3.4 核心代码片段)
[四、 超越检测:仪表读数与状态识别](#四、 超越检测:仪表读数与状态识别)
[4.1 指针式仪表读数](#4.1 指针式仪表读数)
[4.2 数字式仪表识别](#4.2 数字式仪表识别)
[五、 模型部署与性能优化](#五、 模型部署与性能优化)
[5.1 模型导出](#5.1 模型导出)
[5.2 部署方案](#5.2 部署方案)
[5.3 性能优化技巧](#5.3 性能优化技巧)
[六、 总结与展望](#六、 总结与展望)
[6.1 项目总结](#6.1 项目总结)
[6.2 未来展望](#6.2 未来展望)
摘要/引论:
-
痛点开场: 描述传统工业仪器仪表(如压力表、流量计、数显屏、指针式表盘)人工巡检存在的效率低下、易出错、成本高、无法实时监控等问题。
-
技术引入: 引出计算机视觉,特别是目标检测技术作为解决方案。
-
主角登场: 介绍YOLOv8作为YOLO系列的最新里程碑,在速度、精度和易用性上的巨大优势,为何它非常适合工业视觉检测任务。
-
博客价值: 阐明本篇博客将系统性地讲解如何利用YOLOv8,从零开始构建一个鲁棒、高效的工业仪器仪表检测与识别系统。
参考文献:
-
1 Ultralytics YOLOv8 官方文档
-
2 本项目示例代码与数据集(XXX)
-
3 OpenCV、ONNX、TensorRT 等相关官方文档
一、 工业仪器仪表检测:挑战与任务定义
1.1 检测对象细分
* 指针式仪表(压力表、温度表)
* 数字式仪表(数显屏、计数器)
* 指示灯/开关状态
* 类比式仪表(液位计)
1.2 核心技术挑战
* 小目标检测: 仪表在整张图像中占比小,刻度、指针尖端等为极小目标。
* 形状与尺度多变: 圆形、矩形表盘;不同尺寸和安装角度的仪表。
* 复杂背景干扰: 工业现场背景杂乱,存在光线变化、反光、遮挡等问题。
* 高精度要求: 读数识别或状态判断的精度直接关系到生产安全与质量。
1.3 任务分解
* 一级任务:仪表定位 - 检测出图像中所有仪表的位置(边界框)。
* 二级任务:仪表分类 - 识别仪表的类型(压力表、流量计等)。
* 三级任务:信息提取 - 针对不同类型仪表进行关键信息提取(指针角度读数、数字识别、状态判断)。
二、 YOLOv8核心原理与工业应用优势
2.1 YOLOv8架构精讲(面向实践)
* Backbone(主干网络): CSPDarknet 结构,强大的特征提取能力。
* Neck(颈部): PAN-FPN 结构,实现多尺度特征融合,有效应对不同大小的仪表。
* Head(检测头): 无锚框(Anchor-Free)设计,简化训练流程,提升检测速度与精度。
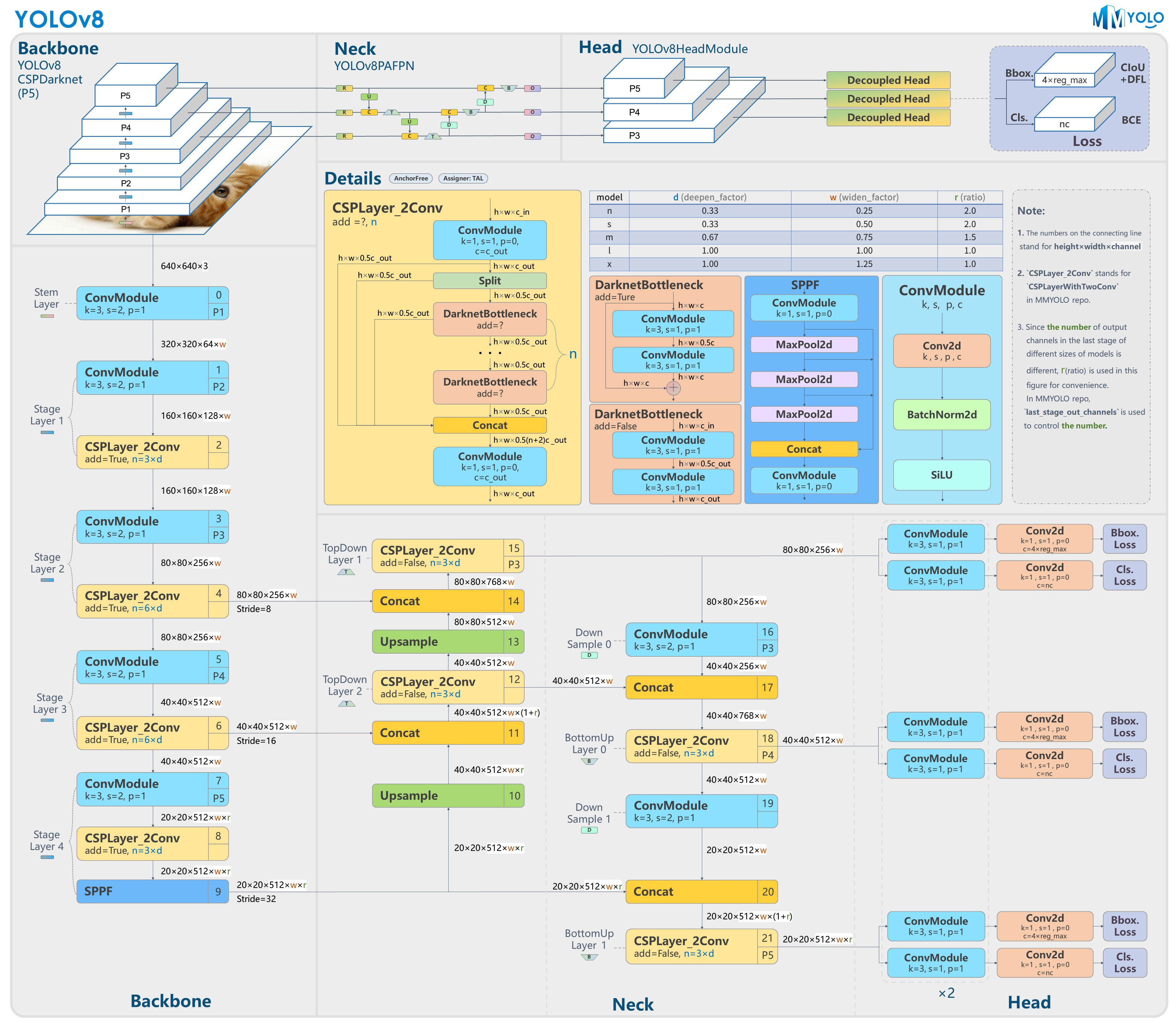
2.2 为何选择YOLOv8用于工业仪表检测?
* 卓越的精度-速度平衡: 满足工业实时检测需求。
* 出色的多尺度检测能力: 完美应对大小不一的仪表。
* 灵活的模型尺寸: 提供n/s/m/l/x全系列模型,可根据部署硬件(如边缘计算设备)选择。
* 强大的生态与易用性: Ultralytics 库提供了极其友好的API和预训练模型,大幅降低开发门槛。
三、 实战:构建工业仪表检测系统全流程
3.0 环境配置
1. 安装CUDA
- 配置虚拟环境yolov8
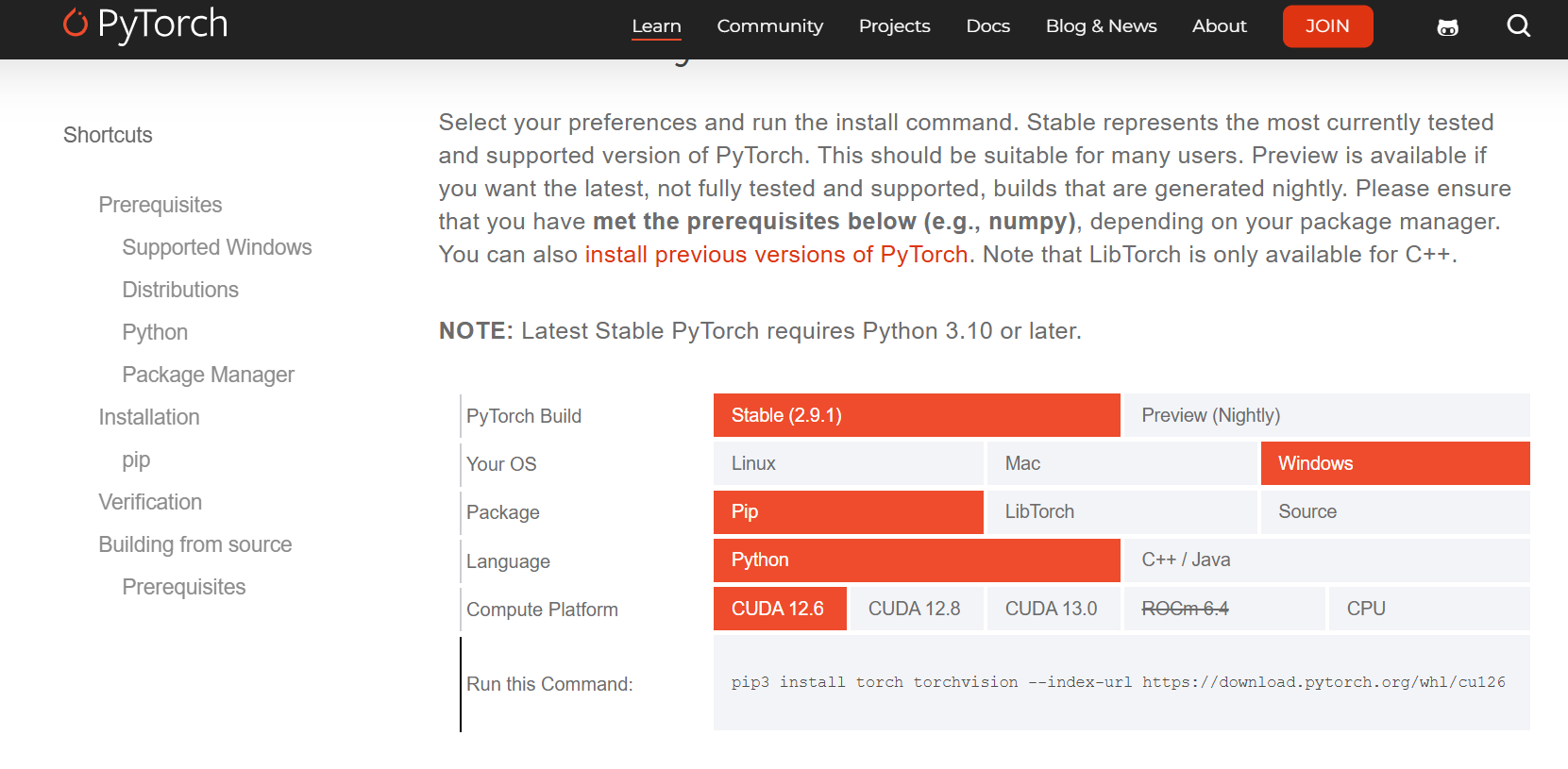
进入pytorch官网安装页面,找到对应的pytorch和torchvision的安装包(cp代表python版本,如果其中一个文件找不到对应版本,则重复上一步骤查询可匹配的其他版本)
bash
# 安装 PyTorch(以 CUDA 11.8 为例)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装 YOLOv8 官方库
pip install ultralytics opencv-python numpy matplotlib tqdm scikit-learn pandas pillow
# 可选:TensorBoard 可视化
pip install tensorboard
# 验证安装
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
# 应输出 True 表示 GPU 可用
- YoloV8环境配置
bash
pip install ultralytics opencv-python numpy matplotlib tqdm scikit-learn pandas pillow
-
验证
python -c "import torch; print(torch.version); print(torch.cuda.is_available())"
输出:2.7.1+cu118 True
3.1 数据准备与标注
* 数据采集: 模拟工业现场环境,涵盖不同光照、角度、距离。
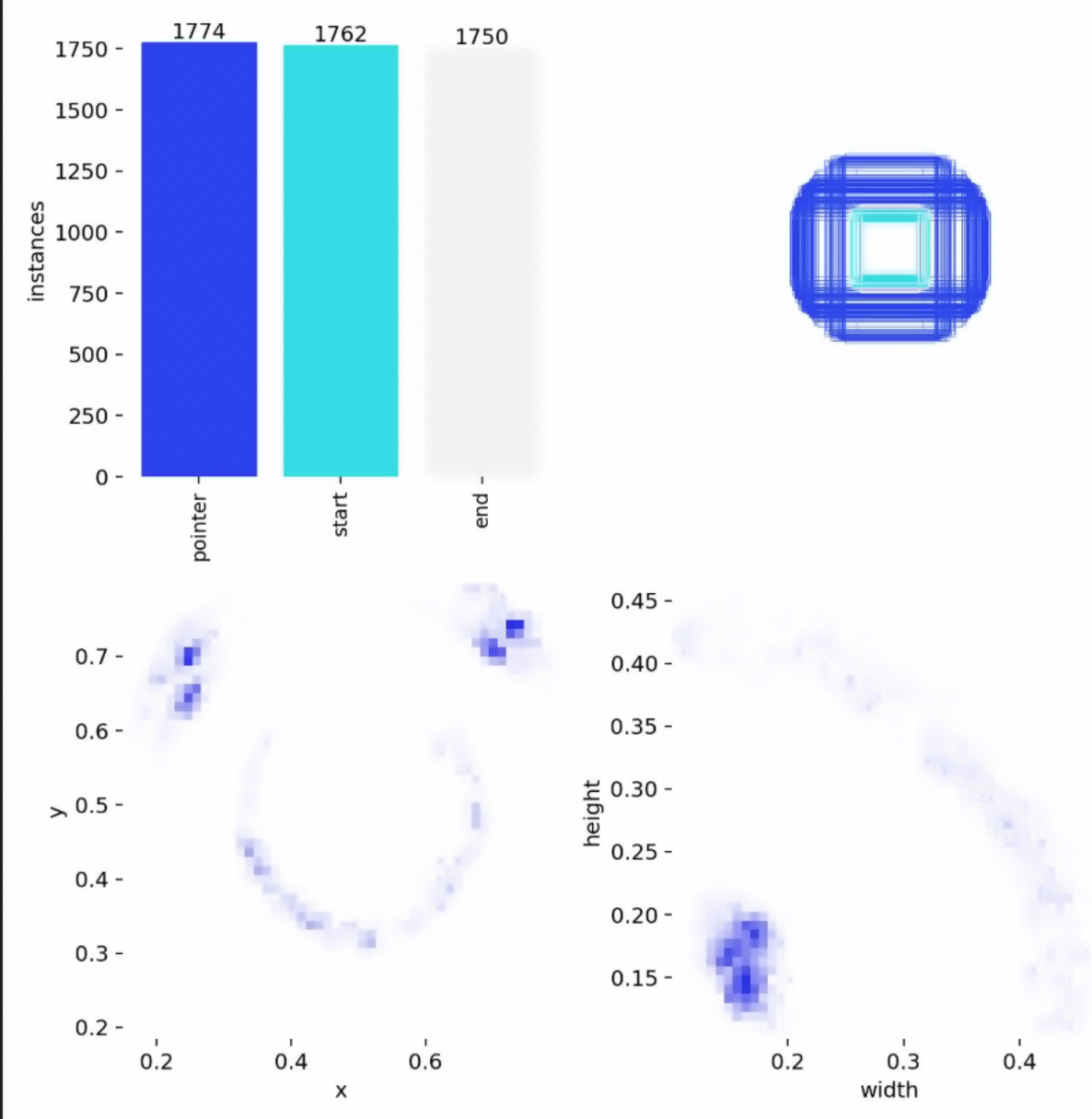
* 标注规范:
* 使用LabelImg或Roboflow等工具。
* 类别定义:pressure_gauge, digital_meter, indicator_light等。
* 边界框要求:紧密贴合仪表边缘。
* 数据格式: 统一转换为YOLO格式(txt文件)。
3.2 数据增强策略(提升模型鲁棒性关键)
* 基础增强: 翻转、旋转、缩放、裁剪、色彩抖动。
* 高级增强(针对工业场景):
* Mosaic增强: 提升小目标检测性能。
* MixUp增强: 提高模型泛化能力。
* 模拟光照变化: 调整亮度、对比度、伽马值。
* 添加高斯噪声与模糊: 模拟传感器噪声和运动模糊。
3.3 模型训练与调优

* 环境配置: PyTorch, Ultralytics YOLO 库安装。
* 模型选择: 根据需求在YOLOv8n / YOLOv8s / YOLOv8m 之间权衡。
* 超参数配置:
* 学习率、优化器(AdamW)、批次大小。
* 关键参数:imgsz(图像尺寸),epochs(训练轮数)。
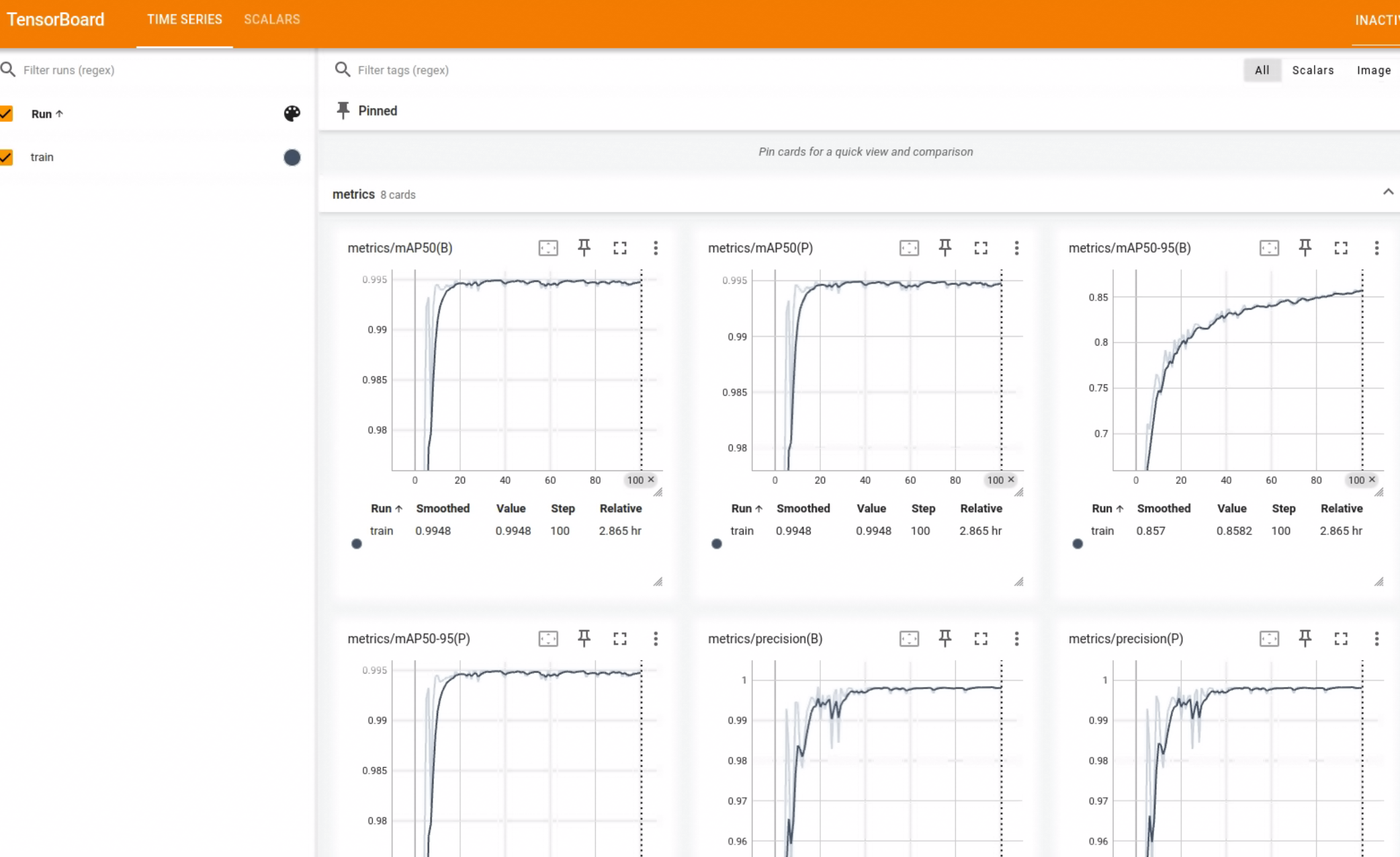
* 训练过程监控:
* 使用TensorBoard或内置日志工具监控损失曲线、mAP50、mAP50-95等指标。
* 模型验证: 在预留的验证集上评估模型性能,分析PR曲线和混淆矩阵。
Downloading https://ultralytics.com/assets/Arial.ttf to '/home/dev/.config/Ultralytics/Arial.ttf': 100% ━━━━━━━━━━━━ 755.1KB 818.5KB/s 0.9s
from n params module arguments
0 -1 1 2320 ultralytics.nn.modules.conv.Conv [3, 80, 3, 2]
1 -1 1 115520 ultralytics.nn.modules.conv.Conv [80, 160, 3, 2]
2 -1 3 436800 ultralytics.nn.modules.block.C2f [160, 160, 3, True]
3 -1 1 461440 ultralytics.nn.modules.conv.Conv [160, 320, 3, 2]
4 -1 6 3281920 ultralytics.nn.modules.block.C2f [320, 320, 6, True]
5 -1 1 1844480 ultralytics.nn.modules.conv.Conv [320, 640, 3, 2]
6 -1 6 13117440 ultralytics.nn.modules.block.C2f [640, 640, 6, True]
7 -1 1 3687680 ultralytics.nn.modules.conv.Conv [640, 640, 3, 2]
8 -1 3 6969600 ultralytics.nn.modules.block.C2f [640, 640, 3, True]
9 -1 1 1025920 ultralytics.nn.modules.block.SPPF [640, 640, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 3 7379200 ultralytics.nn.modules.block.C2f [1280, 640, 3]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 3 1948800 ultralytics.nn.modules.block.C2f [960, 320, 3]
16 -1 1 922240 ultralytics.nn.modules.conv.Conv [320, 320, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 3 7174400 ultralytics.nn.modules.block.C2f [960, 640, 3]
19 -1 1 3687680 ultralytics.nn.modules.conv.Conv [640, 640, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 3 7379200 ultralytics.nn.modules.block.C2f [1280, 640, 3]
22 [15, 18, 21] 1 10048075 ultralytics.nn.modules.head.Pose [3, [2, 3], [320, 640, 640]]
my_YOLOv8x-pose summary: 224 layers, 69,482,715 parameters, 69,482,699 gradients, 263.9 GFLOPs
训练时开启TensorBoard
https://www.cnblogs.com/SunshineWeather/p/18195908
什么是TensorBoard?
TensorBoard是一个用于可视化机器学习模型训练过程中的各种指标的工具,它可以帮助用户更好地理解和调试模型。TensorBoard可以显示各种类型的数据,如损失函数值、准确率、权重矩阵等,并且支持多种图表类型,如折线图、柱状图、散点图等。通过使用TensorBoard,用户可以在训练过程中实时监控模型的性能,并根据需要调整超参数和优化模型结构。
https://www.tensorflow.org/tensorboard?hl=zh-cn
安装TensorBoardconda创建并激活虚拟环境:
通过"pip install tensorboard"安装
启动并查看YOLO训练结果
tensorboard --logdir=训练结果保存路径指定到YOLOv8训练的根目录,里面有包含每一次训练的结果
tensorboard --logdir=D:\my_project\wepy\src\wepy\aitool\train\runs\detect\指定到YOLOv8训练的根目录下面的某一次训练的结果train2
tensorboard --logdir=D:\my_project\wepy\src\wepy\aitool\train\runs\detect\train2
3.4 核心代码片段
python
import torch # 导入PyTorch框架,用于深度学习计算
from ultralytics import YOLO # 导入Ultralytics的YOLO类,用于构建和训练YOLO模型
if __name__ == '__main__': # 确保以下代码仅在作为主程序运行时执行
# 初始化YOLO模型,使用my_yolov8x-pose.yaml定义网络结构
# 可选:使用.load('yolov8n-pose.pt')加载预训练权重(当前被注释)
model = YOLO('my_yolov8x-pose.yaml') # .load('yolov8n-pose.pt')
# 开始训练模型
# data: 数据集配置文件路径
# epochs: 训练轮数
# imgsz: 输入图像尺寸
# device: 指定训练设备(CPU/GPU),默认自动选择
# batch: 每个批次大小
results = model.train(data="my_data.yaml", epochs=100, imgsz=640,
# device=torch.device("cpu"),
batch=3)
# 在验证集上评估模型性能
model.val()data.yaml
python
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
# path: ../datas/dataset_meter/yolov8/DATASETS # dataset root dir
train: ../datas/dataset_meter/yolov8/DATASETS/images/train # train images (relative to 'path') 4 images
val: ../datas/dataset_meter/yolov8/DATASETS/images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Keypoints
kpt_shape: [2, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
flip_idx: [0, 1]
# Classes
names:
0: pointer
1: start
2: end
python
import cv2
import numpy as np
import matplotlib.pyplot as plt
from ultralytics import YOLO
# 加载模型
model = YOLO('best.pt')
objs_labels = model.names
# 在图片列表上运行批量推理
results = model(['../datas/test_data/roi_image_0_20240712105258.jpg'], save=False, imgsz=640)
frame = cv2.imread("../datas/test_data/roi_image_0_20240712105258.jpg")
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 定义颜色常量
RED = (255, 0, 0) # 红色
GREEN = (0, 255, 0) # 绿色
BLUE = (0, 0, 255) # 蓝色
PURPLE = (255, 0, 255) # 紫色
YELLOW = (255, 255, 0) # 黄色
# 存储各类别的关键点
pointer_keypoints = None
start_keypoints = None
end_keypoints = None
# 设置实际量程
actual_range = 0.1 # 修改为您的实际量程(例如:0-100)
min_value = 0 # 设置量程下限(例如:0)
# 存储读数结果
final_reading = None
# 调整显示参数
DETECTION_BOX_THICKNESS = 1 # 检测框宽度
POINT_RADIUS = 5 # 关键点半径
LINE_THICKNESS = 2 # 指针线宽度
TEXT_THICKNESS = 2 # 文本字体粗细
TEXT_SCALE = 1 # 文本字体大小
# 定义读数颜色
READING_COLOR = RED # 红色读数
READING_BG_COLOR = (255, 255, 255) # 白色背景(用于提高对比度)
for result in results:
boxes = result.boxes
boxes = boxes.cpu().numpy()
# 遍历每个框
for box in boxes.data:
l, t, r, b = box[:4].astype(np.int32)
conf, id = box[4:]
id = int(id)
# 绘制框
cv2.rectangle(frame, (l, t), (r, b), (0, 0, 255), DETECTION_BOX_THICKNESS)
# 绘制类别+置信度
cv2.putText(frame, f"{objs_labels[id]} {conf * 100:.1f}%", (l, t - 10),
cv2.FONT_HERSHEY_SIMPLEX, TEXT_SCALE, (0, 0, 255), TEXT_THICKNESS)
# 遍历 keypoints
keypoints = result.keypoints
keypoints = keypoints.cpu().numpy()
print(keypoints.data)
# 存储各类别的关键点
for i, keypoint_group in enumerate(keypoints.data):
cls_id = int(boxes.data[i][5]) # 获取当前关键点组对应的类别ID
if cls_id == 0: # pointer类别
pointer_keypoints = keypoint_group
elif cls_id == 1: # start类别
start_keypoints = keypoint_group
elif cls_id == 2: # end类别
end_keypoints = keypoint_group
# 绘制关键点
if pointer_keypoints is not None:
# 指针根部(圆心)- 红色
x0, y0, _ = pointer_keypoints[0]
cv2.circle(frame, (int(x0), int(y0)), POINT_RADIUS, RED, -1)
cv2.putText(frame, "Center", (int(x0), int(y0) - 15),
cv2.FONT_HERSHEY_SIMPLEX, TEXT_SCALE * 0.7, RED, TEXT_THICKNESS)
# 指针端部 - 绿色
x1, y1, _ = pointer_keypoints[1]
cv2.circle(frame, (int(x1), int(y1)), POINT_RADIUS, GREEN, -1)
cv2.putText(frame, "Pointer", (int(x1), int(y1) - 15),
cv2.FONT_HERSHEY_SIMPLEX, TEXT_SCALE * 0.7, GREEN, TEXT_THICKNESS)
# 绘制指针线
cv2.line(frame, (int(x0), int(y0)), (int(x1), int(y1)), PURPLE, LINE_THICKNESS)
if start_keypoints is not None:
# 起始点 - 蓝色
x_start, y_start, _ = start_keypoints[0]
cv2.circle(frame, (int(x_start), int(y_start)), POINT_RADIUS, BLUE, -1)
cv2.putText(frame, "Start", (int(x_start), int(y_start) - 15),
cv2.FONT_HERSHEY_SIMPLEX, TEXT_SCALE * 0.7, BLUE, TEXT_THICKNESS)
if end_keypoints is not None:
# 终止点 - 黄色
x_end, y_end, _ = end_keypoints[0]
cv2.circle(frame, (int(x_end), int(y_end)), POINT_RADIUS, YELLOW, -1)
cv2.putText(frame, "End", (int(x_end), int(y_end) - 15),
cv2.FONT_HERSHEY_SIMPLEX, TEXT_SCALE * 0.7, YELLOW, TEXT_THICKNESS)
# 计算指针读数
if (pointer_keypoints is not None and
start_keypoints is not None and
end_keypoints is not None):
# 获取中心点坐标
center_x, center_y, _ = pointer_keypoints[0]
# 获取指针端点坐标
pointer_x, pointer_y, _ = pointer_keypoints[1]
# 获取起始点坐标
start_x, start_y, _ = start_keypoints[0]
# 获取终止点坐标
end_x, end_y, _ = end_keypoints[0]
# 改进的角度计算函数
def calculate_angle(x1, y1, x2, y2, center_x, center_y):
# 计算向量(调整y轴方向,使向上为正)
v1 = np.array([x1 - center_x, center_y - y1])
v2 = np.array([x2 - center_x, center_y - y2])
# 计算向量模长
v1_length = np.linalg.norm(v1)
v2_length = np.linalg.norm(v2)
# 避免除以零
if v1_length < 1e-6 or v2_length < 1e-6:
return 0
# 计算单位向量
v1_unit = v1 / v1_length
v2_unit = v2 / v2_length
# 计算点积(余弦值)
dot_product = np.dot(v1_unit, v2_unit)
# 处理浮点误差
dot_product = np.clip(dot_product, -1.0, 1.0)
# 计算角度(弧度)
angle_rad = np.arccos(dot_product)
# 计算叉积以确定旋转方向
cross_product = v1[0] * v2[1] - v1[1] * v2[0]
# 如果叉积为负,则角度为负(顺时针方向)
if cross_product < 0:
angle_rad = -angle_rad
return angle_rad
# 计算指针相对于起始点的角度
pointer_angle = calculate_angle(pointer_x, pointer_y, start_x, start_y, center_x, center_y)
# 计算量程范围的总角度
full_range_angle = calculate_angle(end_x, end_y, start_x, start_y, center_x, center_y)
# 确保量程角度为正
if full_range_angle < 0:
full_range_angle += 2 * np.pi
# 计算指针读数(改进方法)
# 1. 处理指针角度超出量程范围的情况
normalized_angle = (pointer_angle % (2 * np.pi))
if normalized_angle > full_range_angle:
normalized_angle -= 2 * np.pi
# 2. 应用量程转换
reading = (normalized_angle / full_range_angle) * actual_range + min_value
# 3. 增加角度滤波(平滑处理)
# 假设我们有历史读数,可以用指数加权平均
# 这里简化为当前读数的平滑
filtered_reading = reading
# 4. 确保读数在有效范围内
final_reading = np.clip(filtered_reading, min_value, actual_range)
# 在图片左上角显示红色的读数结果
text = f"Reading: {final_reading:.3f}"
x, y = 20, 40 # 左上角坐标
# 添加白色背景提高对比度
text_size = cv2.getTextSize(text, cv2.FONT_HERSHEY_SIMPLEX, TEXT_SCALE, TEXT_THICKNESS + 1)[0]
cv2.rectangle(frame, (x - 5, y - text_size[1] - 10), (x + text_size[0] + 5, y + 5), READING_BG_COLOR, -1)
# 黑色描边(加粗效果)
cv2.putText(frame, text, (x, y), cv2.FONT_HERSHEY_SIMPLEX, TEXT_SCALE,
(0, 0, 0), TEXT_THICKNESS + 1, cv2.LINE_AA)
# 红色字体
cv2.putText(frame, text, (x, y), cv2.FONT_HERSHEY_SIMPLEX, TEXT_SCALE,
READING_COLOR, TEXT_THICKNESS, cv2.LINE_AA)
# 打印读数结果(控制台输出也设置为红色)
if final_reading is not None:
print(f"\n\033[91m===== 指针仪表读数结果 =====\033[0m") # 红色标题
print(f"\033[91m实际量程:\033[0m {min_value} - {min_value + actual_range}")
print(f"\033[91m计算得到的读数:\033[0m {final_reading:.3f}")
print(f"\033[91m================================\033[0m\n")
else:
print("警告: 未能计算读数,可能缺少关键点数据")
plt.imshow(frame)
plt.title("Pointer Meter Reading")
plt.axis('off')
plt.show()
四、 超越检测:仪表读数与状态识别
4.1 指针式仪表读数
* 步骤一: 利用YOLOv8定位仪表区域。
* 步骤二: 霍夫圆变换或实例分割(YOLOv8-Seg)精准提取表盘。
* 步骤三: 霍夫线变换或最小二乘法拟合指针直线。
* 步骤四: 计算指针角度,根据量程换算为实际物理值。
4.2 数字式仪表识别
* 步骤一: YOLOv8定位数字区域。
* 步骤二: 图像预处理(二值化、形态学操作)。
* 步骤三: 字符分割(轮廓检测/投影法)。
* 步骤四: 构建一个轻量级的CNN或使用OCR引擎(如PaddleOCR)进行字符识别。
五、 模型部署与性能优化
5.1 模型导出
* 导出为ONNX格式,以实现跨平台部署。
* 导出为TensorRT、OpenVINO等格式,针对特定硬件加速。
5.2 部署方案
* 方案A:服务器端部署 - 使用FastAPI或Flask构建RESTful API。
* 方案B:边缘设备部署 - 在Jetson Nano、NVIDIA TAO等设备上部署,实现端侧智能。
5.3 性能优化技巧
* 模型剪枝与量化: 减小模型体积,提升推理速度。
* TensorRT优化: 利用FP16/INT8精度极大提升NVIDIA GPU上的推理速度。
六、 总结与展望
6.1 项目总结
* 回顾从数据准备到模型部署的完整Pipeline。
* 总结YOLOv8在本项目中的优异表现和关键成功因素。
6.2 未来展望
* 视频流分析: 从静态图片检测升级为实时视频流监控。
* 异常检测: 结合时序数据,预测仪表故障或异常趋势。
* 集成化系统: 将检测系统与MES(制造执行系统)、SCADA(数据采集与监视控制系统)集成,形成闭环控制。