目录
-
- 前言
- 一、源码分析
- 二、封装实现 unordered_map 和 unordered_set
-
- 2.1 实现出复用哈希表的框架,并支持 insert
-
- insert 的测试
- 2.2 iterator 的实现
-
- 2.2.1 operator* 、 operator-> 、operator== 、operator!=
- 2.2.2 支持迭代器的 前置、后置 ++
- 2.2.3 支持哈希表类、unordered系列的Begin、End
-
- 迭代器测试代码
- 关于 key 不能修改的问题
- 2.3 支持 const_iterator
-
-
- 测试代码
-
- 2.4 支持 unordered_map 的 operator
-
-
- operator 的测试
-
- 2.5 增加find 和 erase函数
-
- 测试代码
前言
上两期博客,我们实现了哈希表,本期博客我们将对哈希表代码做修改,来封装unordered_map和unordered_set,没有了解上几期内容的读者,请移步至哈希表实现 - 开放定址法 和 哈希表实现 - 链地址法/哈希桶。
一、源码分析
和红黑树封装map和set的那期博客一样,我们依旧看一下源码是怎样封装实现的。
SGI-STL30实现了哈希表,只是容器的名字是hash_map和hash_set,他是作为非标准的容器出现的,非标准是指非C++标准规定必须实现的,源代码在hash_map/hash_set/stl_hash_map/stl_hash_set/stl_hashtable.h中hash_map和hash_set的实现结构框架核心部分截取出来如下:
cpp
// stl_hash_set
template <class Value, class HashFcn = hash<Value>,
class EqualKey = equal_to<Value>,
class Alloc = alloc>
class hash_set
{
private:
typedef hashtable<Value, Value, HashFcn, identity<Value>,
EqualKey, Alloc> ht;
ht rep;
public:
typedef typename ht::key_type key_type;
typedef typename ht::value_type value_type;
typedef typename ht::hasher hasher;
typedef typename ht::key_equal key_equal;
typedef typename ht::const_iterator iterator;
typedef typename ht::const_iterator const_iterator;
hasher hash_funct() const { return rep.hash_funct(); }
key_equal key_eq() const { return rep.key_eq(); }
};
// stl_hash_map
template <class Key, class T, class HashFcn = hash<Key>,
class EqualKey = equal_to<Key>,
class Alloc = alloc>
class hash_map
{
private:
typedef hashtable<pair<const Key, T>, Key, HashFcn,
select1st<pair<const Key, T> >, EqualKey, Alloc> ht;
ht rep;
public:
typedef typename ht::key_type key_type;
typedef T data_type;
typedef T mapped_type;
typedef typename ht::value_type value_type;
typedef typename ht::hasher hasher;
typedef typename ht::key_equal key_equal;
typedef typename ht::iterator iterator;
typedef typename ht::const_iterator const_iterator;
};
// stl_hashtable.h
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey,
class Alloc>
class hashtable {
public:
typedef Key key_type;
typedef Value value_type;
typedef HashFcn hasher;
typedef EqualKey key_equal;
private:
hasher hash;
key_equal equals;
ExtractKey get_key;
typedef __hashtable_node<Value> node;
vector<node*, Alloc> buckets;
size_type num_elements;
public:
typedef __hashtable_iterator<Value, Key, HashFcn, ExtractKey, EqualKey,
Alloc> iterator;
pair<iterator, bool> insert_unique(const value_type& obj);
const_iterator find(const key_type& key) const;
};
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;
Value val;
};通过源码可以看到,结构上hash_map和hash_set跟红黑树封装map和set的完全类似:封装红黑树实现 set 和 map,复用同一个哈希表代码hash_table实现key和key/value结构,hash_set传给hash_table的是两个key,hash_map传给hash_table的是pair<const key, value>。
和红黑树封装map和set一样,哈希表并不知道它的第二个模板参数的类型是什么,而哈希表需要使用key类型的数据,所以这里和红黑树的封装一样都是让unordered_map和unordered_set,自己实现一个仿函数返回哈希表所需要的key类型数据,之后在哈希表的参数列表中增加一个模板参数,来接收仿函数类型。
二、封装实现 unordered_map 和 unordered_set
2.1 实现出复用哈希表的框架,并支持 insert
哈希表需要的主要修改点:1、修改哈希类的模板参数,增加一个仿函数类型的模板参数;2、将哈希节点类的两个模板参数修改为一个模板参数控制;3、将哈希类中所有涉及到使用key类型数据的地方,全部套上仿函数,获取真实key类型数据。
实现复用的哈希表(考虑到有人没有看过上几期博客,或者忘记了,这里呈现的是未删减的,有点长):
cpp
template<class T> // T 可能是 K, 或者 pair<K, V>
struct HashNode
{
// 单链表足以满足需求
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{ }
};
template<class K>
struct HashOfKey
{
size_t operator()(const K& k)
{
return (size_t)k;
}
};
template<>
struct HashOfKey<string>
{
size_t operator()(const string& k)
{
size_t hs = 0;
for (auto& e : k)
{
hs += e;
hs *= 131; // 能够有效防止 "abcd" "bcda"的整型值一样的情况
}
return hs;
}
};
// 这里传的 K 是给find和erase用的,T 可能是 K, 或者 pair<K, V>
// KeyOfT 是unordered_map和unordered_set传递的仿函数类型,用于获取Key类型的数据
template<class K, class T, class KeyOfT, class Hash = HashOfKey<K>>
class HashTable
{
public:
typedef HashNode<T> Node;
HashTable()
:_tables(__stl_next_prime(1)) // 开初始空间, 函数返回的是比 1 大且最接近 1 的值
, _n(0)
{ }
~HashTable()
{
for (int i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
// 近乎二倍增长的质数表
inline unsigned long __stl_next_prime(unsigned long n)
{
// Note: assumes long is at least 32 bits.
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
bool insert(const T& data)
{
Hash hs;
KeyOfT kot; // 获取key类型数据
if (find(kot(data)))
{
return false;
}
// 负载因子 == 1,就扩容
if (_n == _tables.size())
{
vector<Node*> newtables(__stl_next_prime(_tables.size() + 1));
for (int i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
// 存储 cur 的下一个节点
Node* next = cur->_next;
int hashi = hs(kot(cur->_data)) % newtables.size();
cur->_next = newtables[hashi];
newtables[hashi] = cur;
cur = next; // 走到原链表的下一个节点
}
// 清空原链表节点数据
_tables[i] = nullptr;
}
// 交换新旧表
_tables.swap(newtables);
}
int hashi = hs(kot(data)) % _tables.size();
Node* newNode = new Node(data);
// 头插,尾插还要找尾
// 第一个节点的地址在表里面
newNode->_next = _tables[hashi];
_tables[hashi] = newNode;
++_n;
return true;
}
Node* find(const K& key)
{
Hash hs;
size_t hashi = hs(key) % _tables.size();
Node* cur = _tables[hashi];
KeyOfT kot; // 获取key类型数据
while (cur)
{
// 找到返回节点地址
if (kot(cur->_data) == key)
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}
bool erase(const K& key)
{
Hash hs;
size_t hashi = hs(key) % _tables.size();
Node* cur = _tables[hashi];
Node* pre = nullptr; // 保存 cur 的前一个节点
KeyOfT kot; // 获取key类型数据
while (cur)
{
// 找到返回节点地址
if (kot(cur->_data) == key)
{
// 要找的节点是表头
if (pre == nullptr)
{
_tables[hashi] = cur->_next;
}
else
{
pre->_next = cur->_next;
}
delete cur;
return true;
}
pre = cur;
cur = cur->_next;
}
return false;
}
private:
vector<Node*> _tables;
size_t _n; // 实际存储的数据个数
};unordered_set 和 unordered_map 封装的简单代码
cpp
namespace U_SET
{
template<class K>
class unordered_set
{
// 添加仿函数返回红黑树想要的 Key 值
struct SetKeyOfT
{
const K& operator()(const K& k)
{
return k;
}
};
public:
bool insert(const K& k)
{
return _s.insert(k);
}
private:
HashTable<K, K, SetKeyOfT> _s;
};
}
namespace U_MAP
{
template<class K, class V>
class unordered_map
{
// 添加仿函数返回红黑树想要的 Key 值
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
bool insert(const pair<K, V>& kv)
{
return _s.insert(kv);
}
private:
HashTable<K, pair<K, V>, MapKeyOfT> _s;
};
}insert 的测试
测试代码:
cpp
void test_uset1()
{
U_SET::unordered_set<int> s;
s.insert(45);
s.insert(5);
s.insert(13);
s.insert(45);
}
void test_umap1()
{
U_MAP::unordered_map<string, string> dict;
dict.insert({ "insert", "插入" });
dict.insert({ "sort", "排序" });
dict.insert({ "test", "测试" });
}测试结果 :
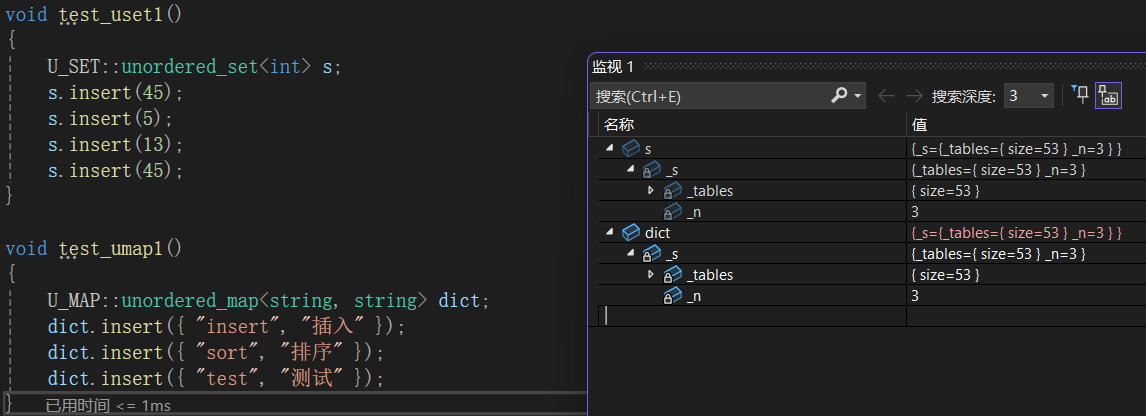
insert函数目前可以运行了。
2.2 iterator 的实现
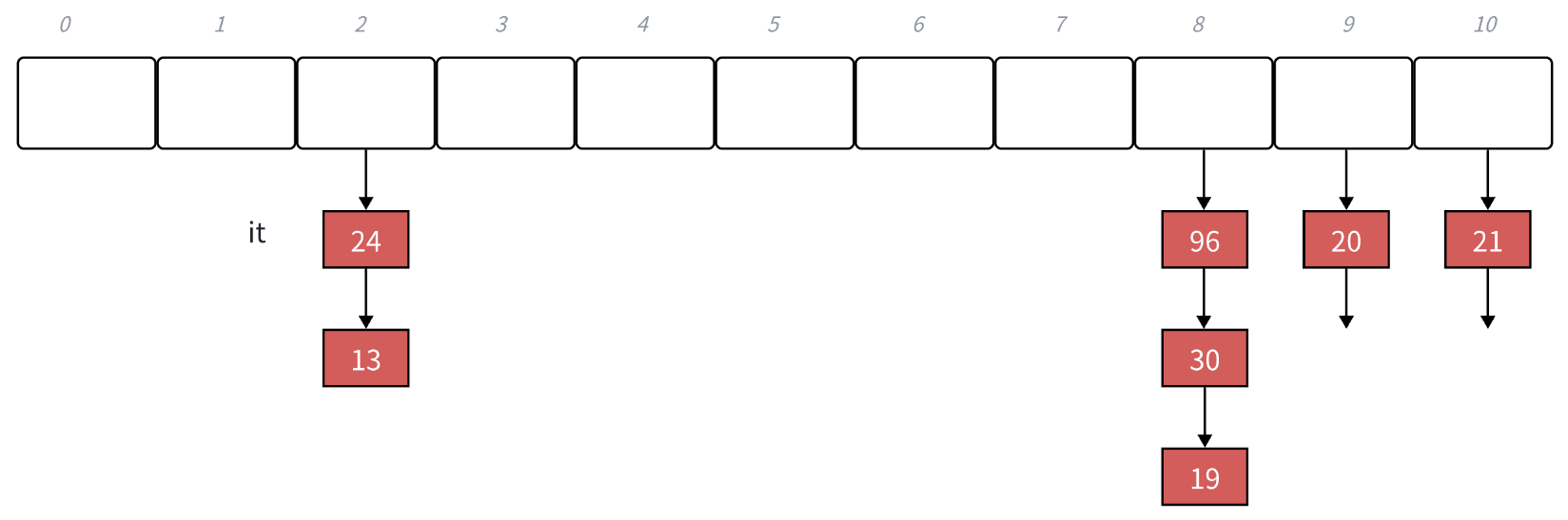
如上图,我们的链地址法实现的哈希表是这样的结构,那么我们想要设计迭代器,这个迭代器类中肯定要有节点类型的指针 ,但是单有指针还不够。仔细想一下,我们迭代器的++操作,是在每一条链表中执行的,当这个链表遍历完成后,再次++就要到达下一个不为空的位置,这个时候怎么办?
有人想到遍历一下vector数组,是的,的确和vector数组有关,但我们不知道当前在数组的那个位置呀?
我们目前拥有的是节点的指针,指针中存放着节点的数据T _data,而我们可以首先获得这个数据的key类型数据 ,在利用仿函数取出key类型数据的整型值 ,让这个整型值取模数组的大小size(),这样就能达到当前所在的位置了。紧接着从当前位置遍历数组,就可以拿到下一个位置。
所以迭代器类中的成员就确定了,一个是节点的指针 ,一个是哈希表数组的指针。
迭代器类:
cpp
template<class K, class T, class KeyOfT, class Hash = HashOfKey<K>>
struct HTIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT> HT;
Node* _node;
HT* _ht;
HTIterator(Node* node, HT* ht)
:_node(node)
,_ht(ht)
{ }
};注意 :这里直接运行会编译报错的,因为我们的迭代器类内部用到了HashTable<K, T, KeyOfT>,而这个是在后面定义的,编译器向上查找时找不到,我们也不可以将HashTable类的定义放在前面,因为HashTable中也使用了HTIterator<K, T, KeyOfT>,这两个类之间相互引用。解决办法也很简单,就是在迭代器类前面放置哈希表类的前置声明。
cpp
// 前置声明
template<class K, class T, class KeyOfT, class Hash = HashOfKey<K>>
class HashTable;
template<class K, class T, class KeyOfT, class Hash = HashOfKey<K>>
struct HTIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT> HT;
Node* _node;
HT* _ht;
HTIterator(Node* node, HT* ht)
:_node(node)
,_ht(ht)
{ }
};
// 上面的前置声明给了第四个模板参数默认参数,再次给就重定义了
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
public:
typedef HashNode<T> Node;
typedef HTIterator<K, T, KeyOfT> Iterator;
// ...
}2.2.1 operator* 、 operator-> 、operator== 、operator!=
cpp
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
typedef HTIterator<K, T, KeyOfT> Self;
bool operator==(const Self& s) const
{
return _node == s._node;
}
bool operator!=(const Self& s) const
{
return _node != s._node;
}2.2.2 支持迭代器的 前置、后置 ++
stl库中的unordered系列就不支持前置、后置--,所以也就不用支持了,如果使用的是双向链表设计的哈希表的话,可以支持。
前置++:
cpp
Self& operator++()
{
if (_node->_next) // 当前链表还有节点
{
_node = _node->_next;
}
else
{
Hash hs; // 取出 key 类型数据对应的整型值
KeyOfT kot; // 取出 T 中的key
// 访问 _tables 等私有成员 HTIterator 需要成为 HashTable 的友元
size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();
hashi++;
while (hashi != _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
hashi++;
}
// 哈希数组访问完了,给 End(), nullptr
if (hashi == _ht->_tables.size())
_node = nullptr;
}
return *this;
}
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
// 友元声明
template<class K, class T, class KeyOfT, class Hash>
friend struct HTIterator;
// ...
}注意:这里要访问哈希表类中的_tables私有成员,迭代器类是访问不了的,为了能够访问,可以进行友元声明。
后置++:
cpp
Self operator++(int)
{
Node* node = _node;
if (_node->_next) // 当前链表还有节点
{
_node = _node->_next;
}
else
{
Hash hs; // 取出 key 类型数据对应的整型值
KeyOfT kot; // 取出 T 中的key
// 访问 _tables 等私有成员 HTIterator 需要成为 HashTable 的友元
size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();
hashi++;
while (hashi != _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
hashi++;
}
// 哈希数组访问完了,给 End(), nullptr
if (hashi == _ht->_tables.size())
_node = nullptr;
}
return HTIterator(node, _ht);
}
};2.2.3 支持哈希表类、unordered系列的Begin、End
HashTable.h:
cpp
Iterator End()
{
// 迭代器类需要哈希表类类型的指针,传递 this 即可
return Iterator(nullptr, this);
}
Iterator Begin()
{
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i])
{
return Iterator(_tables[i], this);
}
}
// 哈希表为空
return End();
}unordered_set:
cpp
typedef typename HashTable<K, K, SetKeyOfT>::Iterator iterator;
// 编译器在解析阶段无法确定这个名称是类型还是静态成员变量还是枚举值,
// 凡是取没有实例化的类模板中的内嵌类型都要加 typename, 告诉编译器这是一个类型,从而编译通过
iterator begin()
{
return _s.Begin();
}
iterator end()
{
return _s.End();
}
bool insert(const K& k)
{
return _s.insert(k);
}
private:
HashTable<K, K, SetKeyOfT> _s;unordered_map:
cpp
typedef typename HashTable<K, pair<K, V>, MapKeyOfT>::Iterator iterator;
// 编译器在解析阶段无法确定这个名称是类型还是静态成员变量还是枚举值,
// 凡是取没有实例化的类模板中的内嵌类型都要加 typename, 告诉编译器这是一个类型,从而编译通过
iterator begin()
{
return _m.Begin();
}
iterator end()
{
return _m.End();
}
bool insert(const pair<K, V>& kv)
{
return _m.insert(kv);
}
private:
HashTable<K, pair<K, V>, MapKeyOfT> _m;迭代器测试代码
测试代码:
cpp
void test_uset2()
{
U_SET::unordered_set<int> s;
s.insert(45);
s.insert(31);
s.insert(13);
s.insert(45);
s.insert(625);
U_SET::unordered_set<int>::iterator it = s.begin();
while(it != s.end())
{
cout << *it << " ";
it++;// 后置++ 测试
}
cout << endl;
}
void test_umap2()
{
U_MAP::unordered_map<string, string> dict;
dict.insert({ "insert", "插入" });
dict.insert({ "sort", "排序" });
dict.insert({ "test", "测试" });
U_MAP::unordered_map<string, string>::iterator it = dict.begin();
while (it != dict.end())
{
cout << it->first << " " << it->second << endl;
++it; // 前置++ 测试
}
}测试结果 :
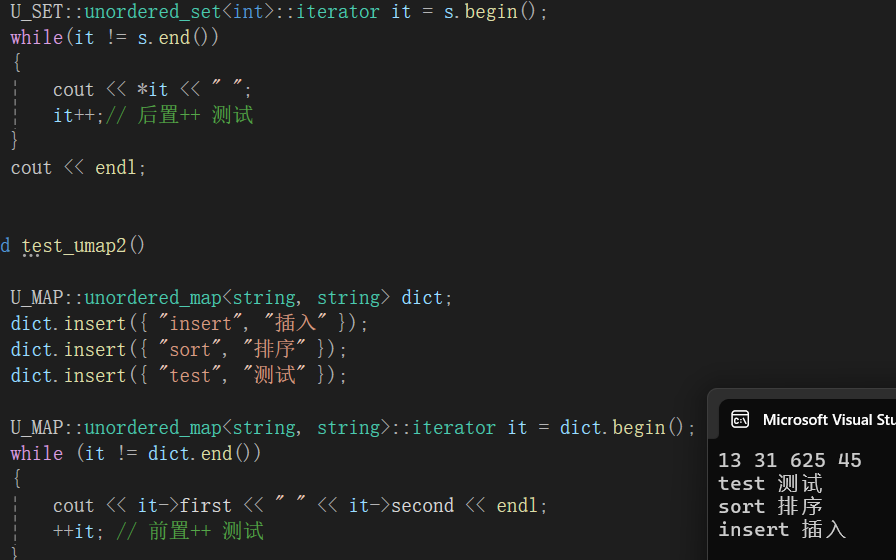
关于 key 不能修改的问题
unordered_set 和 unordered_map都不支持修改key,我们目前的代码是支持修改key的。这里最简单的方式就是在unordered系列封装那层传递的第二个模板参数都修改成const K,这样节点的模板参数T中的key就都被const修饰了。也就不能被修改了。
cpp
template<class K>
class unordered_set
{
// ...
public:
typedef typename HashTable<K, const K, SetKeyOfT>::Iterator iterator;
// 编译器在解析阶段无法确定这个名称是类型还是静态成员变量还是枚举值,
// 凡是取没有实例化的类模板中的内嵌类型都要加 typename, 告诉编译器这是一个类型,从而编译通过
// ...
private:
// const K 保证 key 不能被修改
HashTable<K, const K, SetKeyOfT> _s;
};
template<class K, class V>
class unordered_map
{
// ...
public:
typedef typename HashTable<K, pair<const K, V>, MapKeyOfT>::Iterator iterator;
// 编译器在解析阶段无法确定这个名称是类型还是静态成员变量还是枚举值,
// 凡是取没有实例化的类模板中的内嵌类型都要加 typename, 告诉编译器这是一个类型,从而编译通过
// ...
private:
// const K 保证 key 不能被修改
HashTable<K, pair<const K, V>, MapKeyOfT> _m;
};结果 :
2.3 支持 const_iterator
const_iterator的要求是所指向的数据不能够被修改,而迭代器类中涉及到数据修改的函数,就是operator*和operator->,和list的迭代器设计一样,普通迭代器 分别返回T&、T*类型,那么const迭代器 分别返回const T&、const T*,这样指向的数据就不能够被修改了。
所以我们的迭代器类中需要添加两个类模板参数,分别接受引用的两种类型和指针的两种类型。关于引用的模板参数名称为Ref,关于指针的模板参数名称为Ptr。
哈希表类中的修改:
cpp
template<class K, class T, class KeyOfT, class Hash>
class HashTable
{
// 友元声明
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
friend struct HTIterator;
public:
typedef HashNode<T> Node;
typedef HTIterator<K, T, T&, T*, KeyOfT> Iterator;
typedef HTIterator<K, T, const T&, const T*,KeyOfT> Const_Iterator;
// ...
Const_Iterator End() const
{
// 迭代器类需要哈希表类类型的指针,传递 this 即可
return Const_Iterator(nullptr, this);
}
Const_Iterator Begin() const
{
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i])
{
return Const_Iterator(_tables[i], this);
}
}
// 哈希表为空
return End();
}
// ...
}迭代器类中的更改:
cpp
// Ref 是 T& 或者 const T&, Ptr 是 T* 或者 const T*
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash = HashOfKey<K>>
struct HTIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT> HT;
typedef HTIterator<K, T, Ref, Ptr, KeyOfT> Self;
Node* _node;
HT* _ht;
HTIterator(Node* node, HT* ht)
:_node(node)
,_ht(ht)
{ }
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
}unordered_set中的修改:
cpp
template<class K>
class unordered_set
{
// ...
public:
typedef typename HashTable<K, const K, SetKeyOfT>::Iterator iterator;
// 编译器在解析阶段无法确定这个名称是类型还是静态成员变量还是枚举值,
// 凡是取没有实例化的类模板中的内嵌类型都要加 typename, 告诉编译器这是一个类型,从而编译通过
typedef typename HashTable<K, const K, SetKeyOfT>::Const_Iterator const_iterator;
// ...
const_iterator begin() const
{
return _s.Begin();
}
const_iterator end() const
{
return _s.End();
}
}unordered_map中的修改:
cpp
template<class K, class V>
class unordered_map
{
// ...
public:
typedef typename HashTable<K, pair<const K, V>, MapKeyOfT>::Iterator iterator;
// 编译器在解析阶段无法确定这个名称是类型还是静态成员变量还是枚举值,
// 凡是取没有实例化的类模板中的内嵌类型都要加 typename, 告诉编译器这是一个类型,从而编译通过
typedef typename HashTable<K, pair<const K, V>, MapKeyOfT>::Const_Iterator const_iterator;
// ...
const_iterator begin() const
{
return _m.Begin();
}
const_iterator end() const
{
return _m.End();
}
}测试代码
cpp
void func(const U_SET::unordered_set<int>& s)
{
U_SET::unordered_set<int>::const_iterator it = s.begin();
while (it != s.end())
{
// *it = 1;
cout << *it << " ";
it++;// 后置++ 测试
}
cout << endl;
}
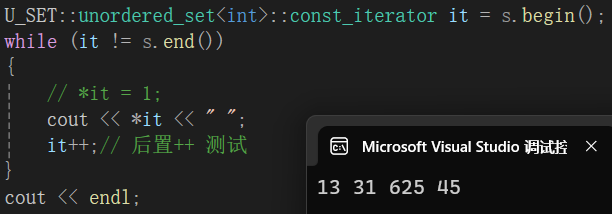
void test_uset3()
{
U_SET::unordered_set<int> s;
s.insert(45);
s.insert(31);
s.insert(13);
s.insert(45);
s.insert(625);
func(s);
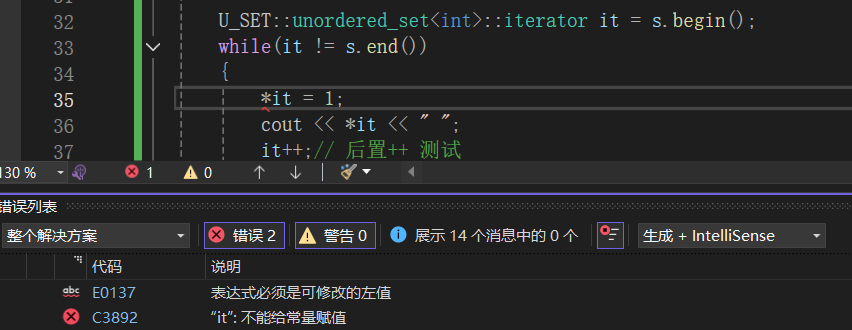
}当我们执行这段代码时,会有以下报错。

原因有些含糊,其实是我们哈希表类中Const_Iterator构造的时候发生的错误,此时的this是const HashTable*类型的,而我们迭代器类中的_ht是HashTable*类型的,导致了权限的缩小,引发了错误。
const的传递链:
cpp
void func(const U_SET::unordered_set<int> s) // s 是 const
→ s.begin() // 调用 const begin()
→ _s.Begin() // 调用 HashTable 的 const Begin()
→ Const_Iterator(_tables[i], this) // this 是 const HashTable*
// 调用链:
func(const unordered_set s)
↓
unordered_set::begin() const
↓
HashTable::Begin() const // this 是 const HashTable*
↓
Const_Iterator(_tables[i], this) // _ht 是 const HT*所以需要在迭代器类成员_ht的类型前加const。
cpp
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash = HashOfKey<K>>
struct HTIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, KeyOfT> HT;
typedef HTIterator<K, T, Ref, Ptr, KeyOfT> Self;
Node* _node;
const HT* _ht;// 加 const
HTIterator(Node* node, const HT* ht) // 加 const
:_node(node)
,_ht(ht)
{ }
}运行结果 :
2.4 支持 unordered_map 的 operator
和红黑树代码封装map一样,unordered_map要支持[]主要需要修改insert返回值支持,修改HashTable中的insert返回值类型为pair<Iterator, bool>。
对insert 和 find返回值的修改:
cpp
pair<Iterator, bool> insert(const T& data)
{
Hash hs;
KeyOfT kot; // 获取key类型数据
auto it = find(kot(data));
if (it != End())
{
return { it, false };
}
// ...
return { Iterator(newNode, this), true };
}
Iterator find(const K& key)
{
Hash hs;
size_t hashi = hs(key) % _tables.size();
Node* cur = _tables[hashi];
KeyOfT kot; // 获取key类型数据
while (cur)
{
// 找到返回节点地址
if (kot(cur->_data) == key)
{
return Iterator(cur, this);
}
cur = cur->_next;
}
return Iterator(nullptr, this);
}unordered_map:operator[]:
cpp
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _m.insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert({ key, V() });
return ret.first->second;
}
//unordered_set中insert返回值的修改:
pair<iterator, bool> insert(const K& k)
{
return _s.insert(k);
}unordered_map::operator[] 获取值的完整过程链:
cpp
ret.first // iterator 对象
ret.first-> // 调用 iterator::operator->
ret.first->second // 访问 pair 的 second 成员(V类型)
iterator it = ret.first; // 获取迭代器
pair<K, V>* ptr = it.operator->(); // 调用 operator->
return ptr->second; // 返回 V 的引用operator 的测试
测试代码:
cpp
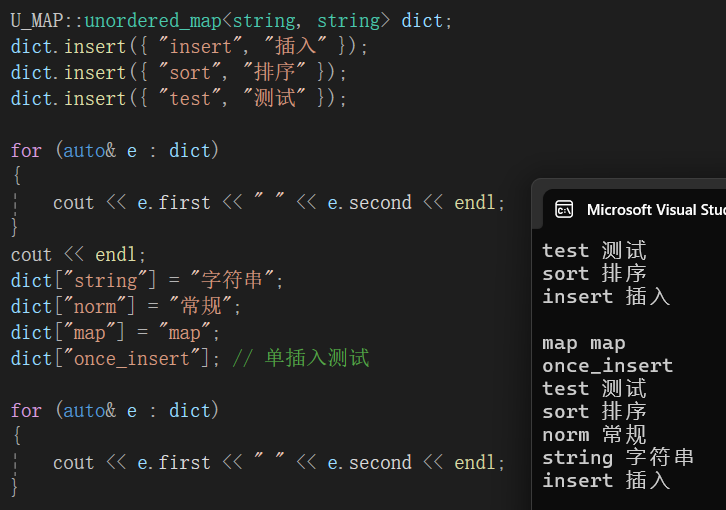
void test_umap3()
{
U_MAP::unordered_map<string, string> dict;
dict.insert({ "insert", "插入" });
dict.insert({ "sort", "排序" });
dict.insert({ "test", "测试" });
for (auto& e : dict)
{
cout << e.first << " " << e.second << endl;
}
cout << endl;
dict["string"] = "字符串";
dict["norm"] = "常规";
dict["map"] = "map";
dict["once_insert"]; // 单插入测试
for (auto& e : dict)
{
cout << e.first << " " << e.second << endl;
}
}测试结果 :
2.5 增加find 和 erase函数
unordered_set和unordered_map中的是一样的。
cpp
iterator find(const K& key)
{
return _s.find(key);
}
bool erase(const K& key)
{
return _s.erase(key);
}测试代码
cpp
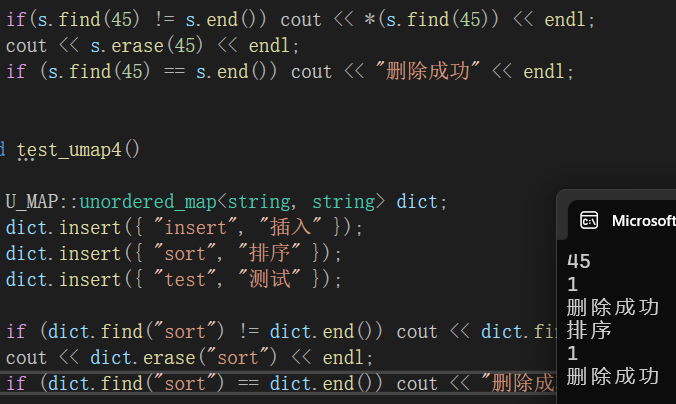
void test_uset4()
{
U_SET::unordered_set<int> s;
s.insert(45);
s.insert(31);
s.insert(13);
s.insert(45);
s.insert(625);
if(s.find(45) != s.end()) cout << *(s.find(45)) << endl;
cout << s.erase(45) << endl;
if (s.find(45) == s.end()) cout << "删除成功" << endl;
}
void test_umap4()
{
U_MAP::unordered_map<string, string> dict;
dict.insert({ "insert", "插入" });
dict.insert({ "sort", "排序" });
dict.insert({ "test", "测试" });
if (dict.find("sort") != dict.end()) cout << dict.find("sort")->second << endl;
cout << dict.erase("sort") << endl;
if (dict.find("sort") == dict.end()) cout << "删除成功" << endl;
}测试结果 :
总结:
以上就是本期博客分享的全部内容啦!如果觉得文章还不错的话可以三连支持一下,你的支持就是我前进最大的动力!
技术的探索永无止境! 道阻且长,行则将至!后续我会给大家带来更多优质博客内容,欢迎关注我的CSDN账号,我们一同成长!
(~ ̄▽ ̄)~