Unity实现实时问答数字人
现在数字人挺火的,这两天研究了一阵子,先将所得记录和总结一下,如果这篇文章能够帮到你,那就更好了。
目前数字人大概分为两种,第一种是非实时的,本质上就是视频生成,有文生视频、图生视频还有参考视频生视频,这种比较适合直播,还有做视频的UP主,这种在我看来不太符合我的研究方向,懒得研究它。
另一种,就是实时性的了,本文重点研究这种类型的。
全模态Unity实时数字人
第一部分,经典架构和模块解析
麦克风管理及人声检测(Voice Activity Detection,VAD)
功能:检测用户语音活动
第一步,就是人声检测(VAD)了,你总得知道客户啥时候说了话,然后把它说的话发给语音识别。github上有开源的VAD库,但是我观其代码,写的很不优雅,每一帧都要new 一堆 byte \[\],都不考虑GC和性能,可能人家只是抛砖引玉吧。后来我自己写了一个麦克风管理的组件,其实原理相当简单,就是一直检测麦克风采样的能量值,然后通过均方差来检测能量阈值,达到某个阈值时启动数据发送,低于某个阈值并且持续一段时间时,就停止发送。
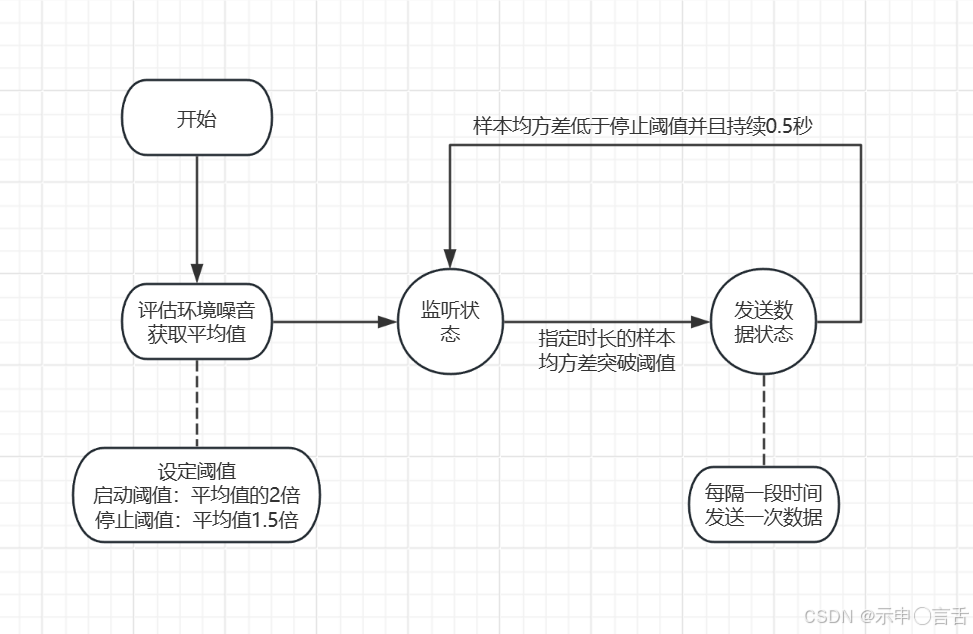
使用均方差而不是简单的平均值,是因为能量样本含有负数,如果简单的求平均,则总体样本平均值趋于0,无法检测有效的能量波动。因此,使用均方差进行检测。
语音识别(ASR)
功能:将用户的语音数据转化为文字。
目前有好多ASR大模型,为了实时性,最好是采用支持流失输入输出的ASR模型。我尝试了很多ASR模型,比如讯飞,阿里,还尝试了本地部署的阿里开源FunASR。如果有本地部署的条件,其实自己搭建一个FunASR服务端效果就很好。阿里的也不错,缺点服务端入口特别杂乱,就单单这个语音识别,有个"智能语音交互"产品,还有"阿里云百炼",各种产品五花八门,你都不知道应该选哪个,应该用哪个,很难从中找出你想要的那个,还有就是"智能语音交互"产品,鉴权流程特别复杂。某飞就更不好用了,产品接入点倒是简单,但是用起来很麻烦,识别结果很不直观。
文本大模型(LLM)
功能:解答用户的问题。
这个可以选择的就太多了,可以自己部署的选择也非常多,甚至可以自己微调,可以搭建知识库,让大模型更精准的回答问题。不过不能自己部署,可以选择各大模型提供商,比如DeepSeek、硅基流动、阿里云百炼...
文字转语音(TTS)
功能:将大模型回答的文字,转化为语音进行播放。
这个选择性也很多,也可以自己部署。开源的有:阿里的CosyVoice、bilibili的IndexTTS等,我自己尝试的结论是:Cosyvoice实时性最好,首包延时较低,流失输出,但是有声音有时候会有BUG,比如语速突然不一样,漏子等。IndexTTS实时性差一些,但是很长的文字语气什么的都比较自然,比较适合非实时的场合。目前我使用的硅基流动的CosyVoice,阿里云百炼未尝试。
口型同步(LipSync)
功能:实现数字人口型驱动
Unity有插件,基于BlendShape表情混合,效果还行。
回音消除(AEC)
功能:让数字人忽略自己说的话
这是个可选的功能,由于数字人会播报语音来解答用户的问题,这就造成一个问题,就是麦克风会听到它自己的播报,这样就会形成一个环路,导致数字人不停的自我问答。最简单粗暴的解决方案就是,在数字人播报语音时,关闭麦克风。 但是这样的话,在数字人说话期间,你就不能提出新的问题,即数字人播报不能被打断。另一种解决方案就是,引入回音消除系统。 然而我尝试了很久,没有完美的方案。以下是我尝试过的方案:
- 网上有所谓的"数字人专用麦克风",号称可以消除回音,但缺点是,它需要一根信号采集线,采集电脑喇叭输出的声音,然后用算法去消除,然而,经过测试,消除后的声音,要么没有卵用,要么麦克风原音被严重干扰,总之效果很差。失败。
- github上有一套开源库,名字叫做WebRTC,然而它没有C#版,有一个for Unity的版本,里面没有AEC模块,研究了很久,失败。
- Unity商城,有一个Vivox插件,用于语音对讲,文档介绍,它可以消除来自远端的声音,即避免麦克风接收远端发过来用于播放的声音。然而,它并不支持将本地播放的语音加入到远端通道,从而实现本地的回音消除。失败。
- Unity商城,有另一个语音库插件,忘记名字了,但它可以将本地AudioSource加入到参考信号,从而实现消除,然而实际测试,它需要麦克风监听本地播放的声音很久之后,才能进行收敛,并且最后的效果也是很一般,而且,这插件并不免费,未深入测试。失败。
- 我使用Grok,帮我写了一套AEC算法,用到了NLMS自适应算法,经过一系列折腾,最后测试,效果也是很一般。失败 。
所以,其实到现在,我还没有完美有效的AEC方案。
如果各位大神看到这篇文章,并且有好的AEC方案,烦请务必联系我。感谢。。
第二部分,全模态架构
自动阿里推出了Qwen-Omni,就方便太多了,它支持直接语音输入,并且支持直接语音输出!而且,它还支持动态的VAD,那就意味着,之前的各种模块,什么VAD、ASR、LLM、TTS...都不需要了。就一个Qwen-Omni完事了。
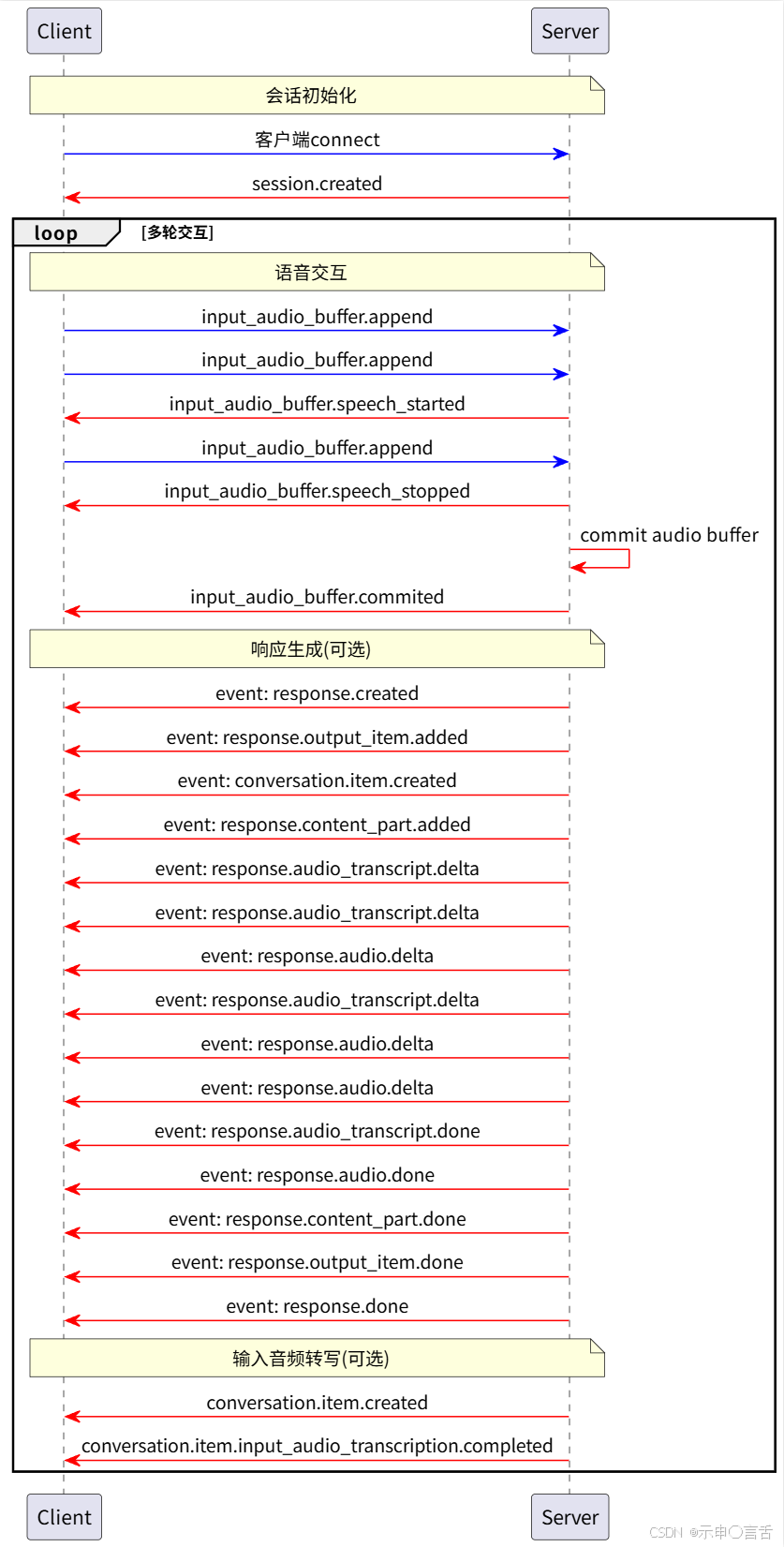
但是Omni也有缺点:
- 遇到多音字,会读错字,比如它作为银行的AI助手,读我hang时,会读我xing,在提示词里纠正了也白搭。
- 不支持知识库接入。目前没有针对全模态的知识库系统,要想接入可能得自己构建。很麻烦,还不如用传统的架构。
- 仍然存在回音消除问题。