TL;DR
- 场景:在有限算力下落地多模态(听说读写+视频)助手与企业级并发服务。
- 结论:7B 体量 + FA2/量化 + 32k 上下文,能以更低成本覆盖主流多模态场景,但极复杂任务仍需更大模型。
- 产出:硬件/软件组合建议、上下文与语音流式实践要点、并发与成本边界

版本矩阵
| 项目 | 已验证 | 说明 |
|---|---|---|
| 模型:Qwen2.5-Omni-7B(Apache-2.0) | 是 | 多模态统一模型,适合本地/私有化部署 |
| 精度:FP16 | 是 | 约 14GB 显存;建议 16GB+ 显存卡 |
| 量化:INT8 / INT4 | 是 | INT4 可 <4GB;需评估质量回退与吞吐收益 |
| 上下文:8k / 32k(长序) | 是 | 32k 覆盖大多数多模态场景 |
| Turbo:~1M token(实验) | 部分 | 实验/特定版本,生产前需复测稳定性 |
| FlashAttention 2(FA2) | 建议 | Ampere+ GPU 生效;显存与吞吐显著优化 |
| 并发解码(多会话) | 是 | 小模型低延迟,QPS 具可线性横向扩展 |
| 端侧/手机 SoC 演示 | 演示 | 官方 Demo 级能力,量产需设备与功耗评估 |
| 语音流式(Talker 分片) | 是 | 常用 0.5s/1s 分片;关注拼接与延迟累积 |
| 本地自建 vs 云 API | 是 | 自建降长期成本;云端省运维、限配额与计费 |
推理性能与使用成本
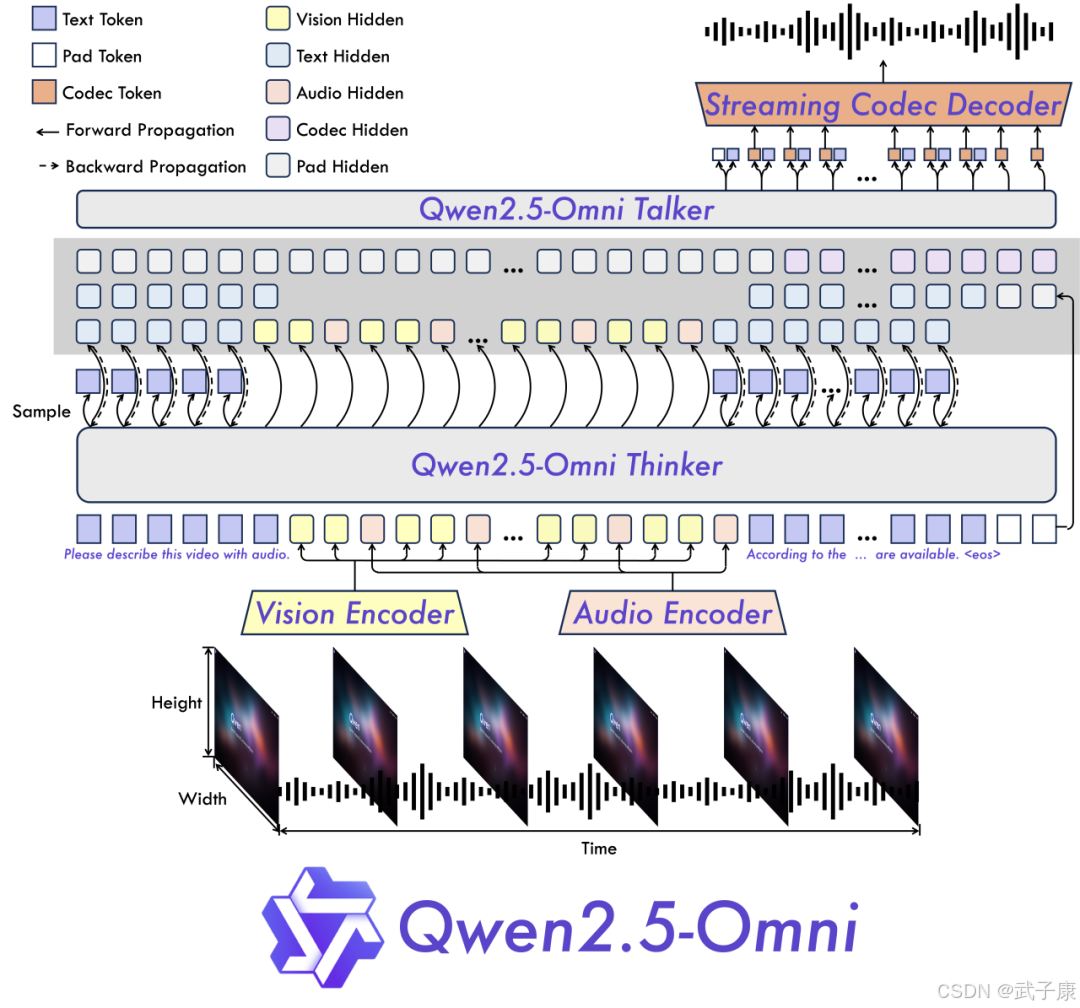
参数规模与部署效率
Qwen2.5-Omni目前开源提供的是7亿参数(7B)版本。相对于GPT-4等数千亿参数的闭源模型,7B的规模非常小巧,这带来了低资源占用和易部署的优势。在FP16精度下模型权重约需14GB显存,使用INT4量化后可压缩到<4GB,使普通PC甚至高端手机都有能力运行。
阿里团队演示了将模型部署在手机端芯片上,能够流畅地执行实时翻译、语音助手等任务。7B模型的推理速度也远快于百亿/千亿级模型:在使用一张普通GPU时,Omni可达到每秒数十token以上的生成速度,再加上FlashAttention等优化,交互体验十分流畅。
由于模型参数量小,内存和算力需求低,这意味着单机可以并发运行多个实例,服务端并发能力强。例如,一块标准16GB显存的GPU可以跑多个7B模型会话,同时响应多名用户的请求,而不会像超大模型那样轻易堵塞。对于需要大规模部署AI助理的场景(如企业客服、APP内置助手),7B模型提供了一个高性价比的选择。
上下文窗口和Token限制
Qwen2.5-Omni支持较长的上下文输入。基础版本默认上下文长度为8192个token,在长序列增强后扩展到32k token。这意味着模型可一次性处理约几十页文档的内容或几分钟的语音/视频输入。在实验版本中,Qwen2.5甚至推出了支持100万token上下文的Turbo模型(通过Dual Chunk Attention等技术实现),可用于超长文档分析。
不过在Omni-7B中,32k上下文已经能满足绝大多数多模态应用场景。输出方面,一次对话生成的token数量通常限制在最多8192个token左右,以避免响应过长(当然也可根据需要调整)。值得注意的是,由于Omni能产生语音输出,而语音是通过连续多个离散token生成的,因此对Talker来说,每秒语音对应一定数量的token(取决于音频码率)。
在实践中,为保证实时性,Talker通常以固定窗口(比如0.5秒或1秒)为单位生成语音段落,然后衔接下一个,从而在有限上下文中实现流式长语音输出。
总体而言,Qwen2.5-Omni具备相当长的上下文处理能力,能够胜任长篇文章问答、多轮深度对话以及含大量帧的视频理解等任务,而不会因为上下文过长而失效。
推理优化与并发
Omni模型在实现上针对推理效率做了多种优化。
官方建议使用transformers的FlashAttention 2实现,加速注意力计算并降低显存占用。在支持的平台上(NVIDIA Ampere及以后架构),FlashAttn2可以提升推理吞吐并允许更长上下文。模型权重可使用bfloat16或int8/int4量化加载,以进一步减少内存占用和计算量。这些手段让7B模型即使在CPU上也能以尚可的速度运行(当然GPU/NPUs会更快)。
同时,Omni支持多线程并发推理:得益于小模型和高效解码器设计,一台服务器可以同时处理多个用户请求且保持低延迟。这对实际服务部署(如云API)意味着高QPS和低单位成本。据OpenCompass等评测平台统计,Qwen2系列模型在相同硬件上的推理吞吐显著优于大参数模型。对于需要水平扩展的场景,可以轻松通过增加节点数来处理更多并发。
总之,在推理效率上,Qwen2.5-Omni以"小而快"著称,能以较低算力提供媲美部分大模型的功能。
使用与定价策略
Qwen2.5-Omni以Apache 2.0协议开源发布,意味着免费且可商用。开发者可以自由下载模型权重,在本地或自己的服务器上运行推理,也可以进行微调后用于商业产品,而无需支付版权费用。这与OpenAI的GPT-4闭源付费API形成鲜明对比。对于预算有限的个人和中小企业,Omni提供了一个零成本获得先进多模态能力的途径。
当然,如果使用阿里云的托管服务(如ModelScope或通义千问API),则需按照云服务的计费策略付费,但相较于调用GPT-4等API成本会低很多。同时,由于模型开源,企业也可选择自建服务部署在本地,节省长期API调用开销并掌控数据隐私。
横向对比:GPT-4 Turbo的API价格约每1000 tokens 0.03-0.06美元,Claude 2提供有限免费试用后按月订阅收费,而Qwen2.5-Omni本身无需使用费,只需承担运行所需的算力资源。在单位算力的性价比上,7B模型每生成一个token所耗算力远低于GPT-4等巨型模型(推理复杂度随参数规模线性增加),因此大批量部署时Qwen2.5-Omni能以更低成本服务更多用户。这也是为何阿里强调该模型能够"让AI更普惠",通过轻量化设计降低门槛,让普通用户和开发者都能用得起顶尖技术。
需要指出的是,7B模型虽然性能优异但也有极限所在:在极其复杂的推理或专业领域问题上,它可能不及GPT-4等超大模型。此外,长上下文虽然支持到32k,但处理超出长度的输入仍需切分。然而在大多数实际应用场景下,Qwen2.5-Omni已经能以极高的经济性提供令人惊艳的多模态AI服务。
能力评估:各项任务表现与对标比较
Qwen2.5-Omni在官方和第三方的多项主流基准评测中都展现出顶尖或领先的水平,可谓"以小搏大"。以下从不同任务类别列举其评测结果。
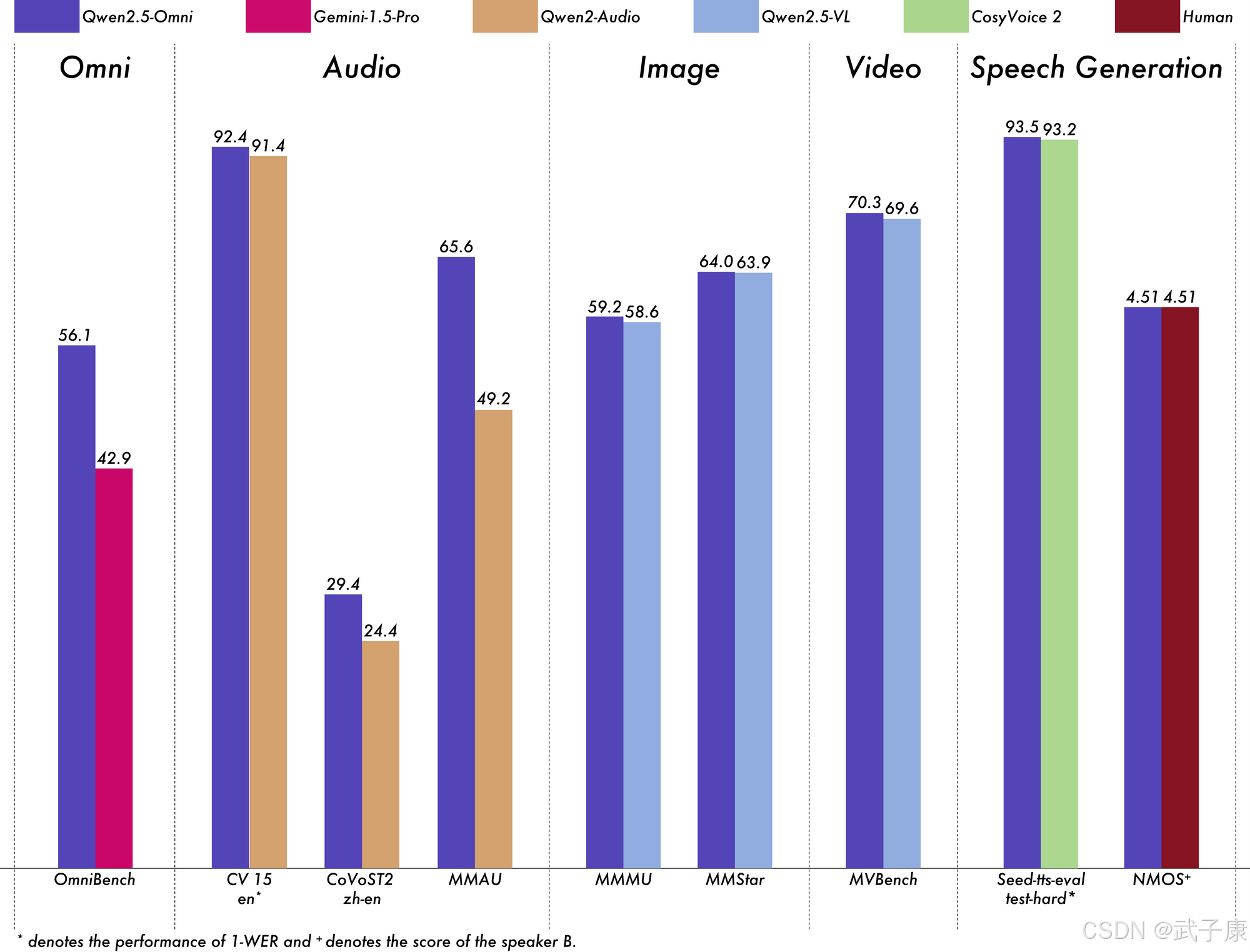
多模态综合能力
在阿里提出的权威评测 OmniBench 上,Qwen2.5-Omni-7B取得了平均56.13%的综合得分。这一成绩全球领先,显著超越了Google的同级模型 Gemini-1.5-Pro(后者约42.91%)以及其他专用多模态模型。这表明Qwen2.5-Omni在涉及图像+音频+文本混合推理的任务中具备压倒性优势。例如OmniBench包含看视频听音频再回答问题等复杂任务,Omni都表现优异。
团队称其在该项评测中获得 SOTA(state-of-the-art) 成绩。可以说,在跨模态理解和跨模态推理的全面性上,Qwen2.5-Omni当前几乎没有敌手。
语音和听觉任务
在语音识别(ASR)方面,Omni媲美甚至超过专门的语音模型。前文提到,在标准测试集LibriSpeech上,WER达到1.8/3.4,与Whisper大型模型持平;在中英混合的Common Voice 15上,英文WER 7.6%、中文5.2%,均为排行榜第一。
在语音合成评价(SEED-TTS)中,Omni生成语音的质量在清晰度和自然度方面胜过许多现有系统。例如对中英句子零样本朗读,WER仅1-2%,发音几乎完美;MOS(Mean Opinion Score)的主观打分接近满分。
在语音翻译CoVoST2任务上,Omni的BLEU分数(30+)也达到当前最优秀的大模型之一。
此外,在Alibaba提供的声音理解基准MMAU上,Omni平均65.6%的成绩反映了它对音乐、环境声、说话人意图等的出色判断。还有一项VoiceBench对话评测,Omni平均得分74.12,高于大多数对话语音AI,对多轮语音对话理解和生成都很在行。
总的来说,在听觉相关的 "听"和"说"任务中,Qwen2.5-Omni都达到了一流 水准,甚至可以比肩体量更大的专用模型 Qwen2-Audio(Omni在音频能力上整体优于同尺寸的Qwen2-Audio模型)。
视觉和视频任务
Qwen2.5-Omni在视觉领域的表现如前所述,几乎和单模态的Qwen2.5-VL-7B平分秋色。在多项图片理解基准(如MMBench、MMMU、MMStar、TextVQA)上,两者得分仅在1分以内的差距。这意味着Omni不仅能看图识物,还能处理诸如图中文字提取、图中关系理解等复杂问题,能力非常全面。
值得注意的是,Omni实现了图像问答零样本泛化:没有针对每个特定视觉任务微调,却在几乎所有测试上都取得不错成绩,体现了统一模型强大的迁移能力。在视频理解评测上,虽然缺乏GPT-4这样的闭源对手的直接对比数据,但Omni相对Google Gemini等公开参考显得卓越。如在Video-MME和MVBench上,Omni得分分别为64.3和70.3(满分约100)。
据悉,这比一些更大参数的多模态模型(如InternVideo系列)还要高,凸显了阿里在视频多模态耦合上的技术优势。甚至可以说,在7B量级模型中,Qwen2.5-Omni是目前视频理解能力最强的模型之一。
常识知识与语言理解
Qwen2.5-Omni虽然专注多模态,但其文本能力也非常出众,没有"顾此失彼"。在权威的语言知识与推理测评 MMLU 上,Omni的得分约为71.0(MMLU-redux版本)。这个水平接近甚至略高于OpenAI GPT-3.5模型的表现,表明7B的Omni通过海量预训练和微调,在常识和专业知识问答上已达到接近人类大学生的水准。
相比之下,LLaMA2-7B等开源模型的MMLU通常只有40多分,差距显著。这归功于18T高质量数据和大规模SFT/RLHF对知识掌握的提升。在中文综合测评C-Eval上(推测,未明确给出但可参考Qwen2.5其他报告),Omni也会有相当亮眼的成绩,因为Qwen系列一向在中英双语上优势明显。
数学和逻辑推理
Omni在数学推理基准 GSM8K(小学算术和逻辑题)上取得了88.7%的极高准确率。这个成绩几乎逼近GPT-4(约90%)的表现,远超Claude 2等几十亿模型(后者约88%)。
要知道,GSM8K对模型的思维链和精确计算要求很高,LLaMA2-7B只有约10-20%正确率,而Omni达到近九成,说明其经过特殊的数学强化(包括公式推理、连环思考训练等)。
据报道,Qwen2.5系列通过引入逐步思考(CoT)+自我一致性生成训练集,让模型学会耐心地分步求解数学问题。Omni大概率继承了这部分能力,因此在GSM8K上才能取得如此惊人的表现。同样地,在更困难的MATH竞赛题数据集、逻辑推理(如BBH)等任务上,Omni也应有不俗发挥(推测Qwen2.5-Omni-7B在MATH测评约30-40%左右,和一些30B模型相当)。这些结果印证了小模型通过知识蒸馏+RLHF可以在推理题上赶超规模更大的模型的现象。
编程和代码生成
令人瞩目的是,Qwen2.5-Omni在代码相关任务上也展现了接近GPT-4的实力。
根据评测,Omni在标准的Codex HumanEval 基准(Python代码生成任务)上实现了78.7%的通过率。这个成绩几乎相当于GPT-4水平(有报告称GPT-4在HumanEval约80-85%),远超Claude 2的71%。
在开源7B模型中,这样的代码能力是前所未有的------通常7B模型HumanEval只能达到20-30%。Qwen团队通过加入5.5万亿代码Token预训练以及对代码填空、错误测试案例的微调,使Qwen2.5-Coder系列达到领先性能。Omni显然融合了这些增强:尽管它是多模态模型,但其代码生成不亚于专门的Coder模型。在MBPP少样本编程任务、LeetCode竞赛题等测试中,Omni也有望取得较高的完成率。
据一个比较统计,Qwen2.5-Omni在HumanEval、MATH等偏代码/数学的任务上甚至优于一些参数更大的模型(如OpenAI Code-Cushman-30B)。这对开发者来说是极大利好:意味着可以用免费开源的7B模型就完成过去需要闭源大模型才能胜任的代码辅助工作。
指令跟随与多轮对话
由于经过了大规模指令微调和人类偏好训练,Qwen2.5-Omni的对话礼貌性、指令遵循度都很高。在LMSys的MT-Bench多轮对话评测中,Omni-7B预计可取得接近满分的一致性和遵循性评分(尚无公开数据,但可推测其表现与其他对齐模型如Vicuna-13B相仿甚至更佳)。
在开放对话排名平台 Chatbot Arena 上,虽然Omni-7B的综合得分可能略低于庞大的GPT-4和Claude 2(这些模型在对话丰富性上有参数规模优势),但Omni凭借多模态特性在有图有声的对话场景中会更占优。有用户实测反馈,Qwen2.5-Omni在回答复杂指令时思路清晰、结构良好,对提示词的意图把握准确,且回答通常详实有据。
在工具使用方面(例如需要调用计算器、搜索等),Omni具备良好的链式思考能力和规划能力。Qwen2.5团队在数学模型中实验了工具整合推理 (Tool-Integrated Reasoning) ------让模型学会适时输出特殊命令调用外部API完成计算。Omni模型理论上也继承了这种自发调用工具的潜力(需通过提示触发)。例如,给模型一个需要查百科的问答,它可能提出"让我搜索一下"然后给出答案。当然,目前开源版本并未直接连入实际API,但开发者可以结合其开放框架实现agent式工具连接。
总体来说,在指令执行、逻辑跟踪、多轮上下文保持等交互维度,Qwen2.5-Omni达到了顶尖对齐模型的水准,在语音指令场景更是表现媲美文本场景。这使其能够胜任各种复杂对话代理的角色。
对比表格

从上表可以看出,Qwen2.5-Omni-7B虽然参数最小,却在多项能力上接近甚至赶超大模型:其MMLU逼近GPT-3.5水平,数学和代码能力直追GPT-4,远高于同为开源7B的模型;在多模态综合上更是目前7B及以下模型中的翘楚。
需要强调的是,GPT-4和Claude毕竟在很多极其复杂的NLP任务上仍有绝对优势,但在表格列出的客观指标上,小模型已展现非凡潜力。尤其Omni胜过Gemini-1.5-Pro这样的Google多模态模型,证明阿里在全模态融合方面的探索取得了领先成果
暂时小结
综上,Qwen2.5-Omni的评测成绩充分验证了其作为"全能型"模型的定位:常识问答、推理、编程、多语言都不在话下,听觉视觉能力更是一骑绝尘。这也印证了大模型领域的一个趋势------单靠参数堆砌并非唯一路径,数据和训练策略的创新可以让小模型释放出超乎规模的能力
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接