目录
[1 核心功能](#1 核心功能)
[2 IP 协议](#2 IP 协议)
[IPv4 协议](#IPv4 协议)
[IPv4 地址(A/B/C/D/E 类)](#IPv4 地址(A/B/C/D/E 类))
[特殊 IP 地址(私有地址、环回地址、广播地址)](#特殊 IP 地址(私有地址、环回地址、广播地址))
[子网掩码(Subnet Mask)](#子网掩码(Subnet Mask))
[IPv4 数据报文头部格式(TTL, 协议号等)](#IPv4 数据报文头部格式(TTL, 协议号等))
[IP 分片与重组](#IP 分片与重组)
[3 IPv6 协议](#3 IPv6 协议)
[IPv6 地址表示](#IPv6 地址表示)
[IPv6 头部格式](#IPv6 头部格式)
[IPv6 相比 IPv4 的改进](#IPv6 相比 IPv4 的改进)
[IPv4 到 IPv6 的过渡技术(双栈、隧道)](#IPv4 到 IPv6 的过渡技术(双栈、隧道))
[4 路由](#4 路由)
[1. 路由表](#1. 路由表)
[2. 静态路由与动态路由](#2. 静态路由与动态路由)
[3. 路由算法](#3. 路由算法)
[a. 1. 距离向量算法 (Distance Vector) - (以 RIP 为例)](#a. 1. 距离向量算法 (Distance Vector) - (以 RIP 为例))
[b. 2. 链路状态算法 (Link-State) - (以 OSPF 为例)](#b. 2. 链路状态算法 (Link-State) - (以 OSPF 为例))
[c. 3. 路径向量算法 (Path-Vector) - (以 BGP 为例)](#c. 3. 路径向量算法 (Path-Vector) - (以 BGP 为例))
[4. 内部网关协议(IGP)](#4. 内部网关协议(IGP))
[a. 1. 内部网关协议 (IGP - Interior Gateway Protocol)](#a. 1. 内部网关协议 (IGP - Interior Gateway Protocol))
[5. 外部网关协议(EGP)](#5. 外部网关协议(EGP))
[a. 外部网关协议 (EGP - Exterior Gateway Protocol)](#a. 外部网关协议 (EGP - Exterior Gateway Protocol))
[5 网络层协议](#5 网络层协议)
[ICMP(互联网控制报文协议,Ping, Traceroute)](#ICMP(互联网控制报文协议,Ping, Traceroute))
[两个最著名的应用:ping 和 traceroute](#两个最著名的应用:ping 和 traceroute)
[什么是组播 (Multicast)?](#什么是组播 (Multicast)?)
[IGMP 的工作流程](#IGMP 的工作流程)
[6 网络层技术](#6 网络层技术)
[NAT (Network Address Translation) - 网络地址转换](#NAT (Network Address Translation) - 网络地址转换)
[1. 为什么需要 NAT?](#1. 为什么需要 NAT?)
[2. NAT 是如何工作的?](#2. NAT 是如何工作的?)
[3. NAT 的副作用(好处和坏处)](#3. NAT 的副作用(好处和坏处))
[VPN (Virtual Private Network) - 虚拟专用网络](#VPN (Virtual Private Network) - 虚拟专用网络)
[1. 为什么需要 VPN?](#1. 为什么需要 VPN?)
[2. VPN 是如何工作的?(以远程访问为例)](#2. VPN 是如何工作的?(以远程访问为例))
[7 网络层设备](#7 网络层设备)
[一、 核心功能:路由与转发](#一、 核心功能:路由与转发)
[二、 路由器 vs 交换机 (Switch) - L3 vs L2](#二、 路由器 vs 交换机 (Switch) - L3 vs L2)
[三、 核心功能:隔离广播域](#三、 核心功能:隔离广播域)
[四、 工作原理解析(一个数据包的旅程)](#四、 工作原理解析(一个数据包的旅程))
1 核心功能
路由选择
是指整个网络 (所有路由器)如何"计算"并"建立" 那个路由表的过程。
- 做什么: 路由器之间互相通信 (使用 OSPF, BGP 等路由协议),交换彼此的"地图信息"(拓扑结构、链路状态)。通过复杂的算法(如 Dijkstra),它们共同计算 出到达全网所有目的地的"最佳路径",并将这些"最佳路径"的"下一跳"写入各自的路由表。
- 类比:Google 地图(路由协议) 在后台收集全城所有的交通信息,计算出从你家到公司最快的那条完整路线(最佳路径),并把结果("下一个路口请右转")保存在你的手机里(路由表)。
- 特点: 这是一个全局的、相对缓慢的、复杂的计算过程(在控制平面 Control Plane 完成)。
转发
一个路由器内部的具体动作。
- 做什么: 当一个数据包到达路由器的输入端口时,路由器"查看"该数据包的目的 IP 地址,然后"查询"自己的路由表,最后决定应该将这个包从哪个输出端口"扔"出去。
- 类比: 你开车到了一个十字路口(路由器),你看了一眼路牌(路由表),然后打方向盘(转发),从正确的出口(输出端口)开出去。
- 特点: 这是一个本地的、瞬时的、高速的动作(在数据平面 Data Plane 完成)。
异构网络互联
- 是什么? 这是网络层(IP 协议)最神奇的能力:它能将各种不同类型 的物理网络(L2 网络)"粘合 "在一起,让我们感觉它们是一个统一的、无缝的互联网。
- 异构网络有哪些? 比如:
-
- 你办公室的以太网 (Ethernet)
- 你家里的 Wi-Fi
- 你手机的 4G/5G 蜂窝网络
- (早期的)令牌环网
- 如何互联?
- 这些 L2 网络的"帧 (Frame)"格式完全不同(比如 Wi-Fi 帧和以太网帧的头部完全不一样)。
- IP 协议 (L3)充当了"通用语言"。
- 过程:
-
- 你的手机(Wi-Fi)发出一个 IP 包,它被封装在一个 Wi-Fi 帧里,发给你的路由器。
- 路由器(L1/L2)收到 Wi-Fi 信号和帧。
- 路由器(L3)"拆开" Wi-Fi 帧,取出里面的 IP 包。
- 路由器(L3)检查 IP 包的目的地址,发现要从有线网口发出去。
- 路由器(L2)"重新封装" 这个 IP 包,在它外面套上一个以太网帧的头部。
- 路由器(L1)将以太网帧变成电信号,通过网线发出去。
- 结论:IP 包(L3)本身在穿越不同网络时保持不变 ,改变的只是 L2 的"外包装"(帧)。这就是为什么 IP 被称为互联网的"沙漏模型"的腰部,它承载了一切。
拥塞控制(与传输层拥塞控制的区别)
- 什么是拥塞?
- 当到达网络(特别是路由器)的数据包过多,超出了其处理能力或链路带宽时,网络就发生了拥塞。
- 表现: 路由器的缓冲区(队列) 被塞满,导致排队时延剧增,最终开始丢包。
- 网络层 (L3) 的拥塞控制(由路由器主导)
-
- 视角:网络中心。路由器是"交通警察"。
- 机制:
-
-
- 队列管理 (Queueing): 路由器内部有缓存队列。最简单的就是 FIFO(先进先出)。(高级的还有 RED, WRED 等)
- 丢包策略 (Dropping): 当队列满了,路由器必须丢弃新来的数据包(称为 Tail Drop)。
- (可选)显式通知: 某些机制允许路由器主动通知发送者。例如 ICMP 源抑制(已弃用)或 ECN(显式拥塞通知),路由器在 IP 包头上打个"标记",告诉接收方:"我快不行了"。
-
- 总结: L3 的拥塞控制是被动的(丢包)或轻微主动的(ECN标记)。
- 传输层 (L4) 的拥塞控制(由 TCP 主导)
-
- 视角:端到端。发送方是"发货调度中心"。
- 机制:
-
-
- 拥塞检测(推断): TCP 无法看到路由器内部。它通过"症状"来推断网络是否拥塞:
-
-
-
-
- 症状 A (轻微): 收到 3 个重复的 ACK。TCP 推断:"有 1 个包丢了,网络可能有点堵。"
- 症状 B (严重):超时了还没收到 ACK。TCP 推断:"数据包肯定丢了,网络非常堵!"
-
-
-
-
- 拥塞控制(动作): TCP 作为发送方,主动调整自己的发送速率(通过一个叫
cwnd拥塞窗口的变量)。
- 拥塞控制(动作): TCP 作为发送方,主动调整自己的发送速率(通过一个叫
-
-
-
-
- 发现症状 A -> 触发"快速恢复"(速率减半,线性增长)。
- 发现症状 B -> 触发"慢启动"(速率降到最低,指数增长)。
-
-
- 总结: L4 (TCP) 的拥塞控制是端到端的、主动调整发送速率的、基于推断的。
最简单的类比:
- L3 拥塞控制: 十字路口(路由器)的交警发现车太多,开始拦车,不让车进入路口(丢包)。
- L4 拥塞控制: 你家(发送方)的导航 App(TCP) 发现路况(RTT 变长、丢包)很差,主动为你重新规划了一条更慢的路线或建议你"晚点出发"(降低发送速率)。
2 IP 协议
IPv4 协议
IP 协议是 TCP/IP 协议栈的核心,它工作在网络层(OSI 第 3 层)。
你可以把 IP 协议想象成"互联网的邮政系统"。它的唯一任务是:为数据包(Packet)添加一个"地址标签"(IP 头部),并尽最大努力(Best-Effort)将其从源主机投递到目的主机。
- 特点 1:无连接 (Connectionless)
-
- IP 在发送数据包之前,不需要像 TCP 那样先"握手"建立连接。它直接把包扔出去。
- 特点 2:尽力而为 (Best-Effort)
-
- IP 不保证数据包能成功到达。
- 它不保证数据包的顺序(可能后发的先到)。
- 它不保证数据包的完整性(可能在中途损坏)。
- (这些"保证"工作全部交给了上层(如 TCP)去做)
- 地址: 它使用 32 位(bit) 的地址,这 32 位二进制数通常被分为 4 个 8 位的"八位组",并用"点分十进制"表示。
- 格式:
x.x.x.x(例如192.168.1.1) - 地址空间: 2^32 ≈ 42.9 亿个地址。
IPv4 地址(A/B/C/D/E 类)
这是早期的 IP 地址划分方式,现在已被 CIDR 取代,但作为基础概念仍需理解。它根据 IP 地址的第一个八位组来"猜测"这个网络的规模。
|-----|-------------|-------------|--------------------------|-------------|---------------------------|
| 类别 | 第一个八位组(二进制) | 第一个八位组(十进制) | 默认子网掩码 | 网络/主机 位 | 描述 |
| A 类 | 0xxxxxxx | 1 - 126 | 255.0.0.0 (/8 ) | 网络.主机.主机.主机 | 用于超大型网络 (如 10.0.0.0 ) |
| B 类 | 10xxxxxx | 128 - 191 | 255.255.0.0 (/16 ) | 网络.网络.主机.主机 | 用于大型网络 (如 172.16.0.0 ) |
| C 类 | 110xxxxx | 192 - 223 | 255.255.255.0 (/24 ) | 网络.网络.网络.主机 | 用于小型网络 (如 192.168.1.0 ) |
| D 类 | 1110xxxx | 224 - 239 | 不适用 | 不适用 | 组播 (Multicast) 地址 |
| E 类 | 1111xxxx | 240 - 255 | 不适用 | 不适用 | 保留 (Experimental) 地址 |
缺点: 这种分类方式极其浪费。如果你是一个需要 500 个 IP 的中型公司,C 类(254 个可用 IP)太小,B 类(65534 个可用 IP)又太大,会造成巨量浪费。
特殊 IP 地址(私有地址、环回地址、广播地址)
|-----------------------|-----------------------------------------------------|-----------------------------------------------------------------------|
| 类型 | 地址范围 | 描述 |
| 私有地址 (Private) | 10.0.0.0- 10.255.255.255 (10.0.0.0/8) | 用于超大型内部网络 (如企业) |
| 私有地址 (Private) | 172.16.0.0- 172.31.255.255 (172.16.0.0/12) | 用于中型内部网络 (如校园) |
| 私有地址 (Private) | 192.168.0.0- 192.168.255.255 (192.168.0.0/16) | 用于小型内部网络 (如家庭路由 192.168.1.0/24) |
| 环回地址 (Loopback) | 127.0.0.0- 127.255.255.255(127.0.0.0/8) | 127.0.0.1(localhost) 是最常用的。用于本机测试,ping 环回地址永远不会离开你自己的电脑。 |
| 网络地址 (Network ID) | 192.168.1.0 (在一个 /24 网络中) | 子网中的第一个 地址,主机号全为 0。它不分配给任何主机,仅用于代表整个网络。 |
| 定向广播 (Directed) | 192.168.1.255(在一个 /24 网络中) | 子网中的最后一个 地址,主机号全为 1。向此地址发送数据包,该子网内的所有主机会收到。 |
| 受限广播 (Limited) | 255.255.255.255 | 在本地局域网 内广播,不会被路由器转发。DHCP Discover 就是用这个地址。 |
| APIPA | 169.254.0.0/16 | 当你的电脑设置为"自动获取 IP",但 DHCP 服务器 又失败时,Windows 会自动给自己分配一个这个范围的 IP。 |
子网划分(Subnetting)
子网划分是对"有类"寻址的第一个改进。它允许你在"内部"对一个大网络(如一个 C 类)进行再分割,切成更小的"子网"。
方法:"借位"。从"主机号"部分借几位给"网络号"。
示例: 你有一个 C 类网络 192.168.1.0,默认掩码是 ...00000000 (/24)。 你希望把它切成 4 个更小的子网。
- 你需要
2^2 = 4,所以你需要借 2 位主机位。 - 新的子网掩码:
...11000000(十进制192),即255.255.255.192(/26)。 - 现在,每个子网的主机位只剩下 6 位 (
2^6 - 2 = 62个可用 IP)。 - 你得到了 4 个子网:
-
- 子网 1:
192.168.1.0(/26) - 子网 2:
192.168.1.64(/26) - 子网 3:
192.168.1.128(/26) - 子网 4:
192.168.1.192(/26)
- 子网 1:
好处: 隔离了广播域,提高了 IP 地址利用率。
子网掩码(Subnet Mask)
子网掩码是用来"划分"IP 地址的"标尺"。它与 IP 地址一一对应,用来指明一个 IP 地址中:
- 哪些位是网络号 (Network ID)(代表"哪个街道")
- 哪些位是主机号 (Host ID)(代表"哪家门牌号")
规则:
- 子网掩码中,
1对应的 IP 位是"网络号"。 - 子网掩码中,
0对应的 IP 位是"主机号"。
示例:
- IP 地址:
192.168.1.100(11000000.10101000.00000001.01100100) - 子网掩码:
255.255.255.0(11111111.11111111.11111111.00000000) - 含义: 前 24 位(
192.168.1)是网络号,后 8 位(100)是主机号。
判断: 计算机通过 IP 地址 AND 子网掩码 的"与运算",来得到网络地址。 192.168.1.100 AND 255.255.255.0 = 192.168.1.0 这台电脑就知道自己属于 192.168.1.0 这个网络。
CIDR(无类别域间路由)
CIDR 是现代的 IP 寻址方案,它彻底抛弃了 A/B/C 类的概念。
- 核心思想: IP 地址和子网掩码必须成对出现。
- 表示法: 使用"斜杠记法"来表示网络号的位数。
-
255.255.255.0(24 个1) =/24255.255.0.0(16 个1) =/16255.255.255.192(26 个1) =/26
- 示例:
192.168.1.0/24 - 好处: 极其灵活。ISP 可以给你分配任意大小的地址块,比如
120.50.30.0/22,完全不受 A/B/C 类的限制。它还支持"超网"(Supernetting),即把多个 C 类网络合并成一个更大的路由条目(如/22),来减少互联网主干路由器的路由表大小。
IPv4 数据报文头部格式(TTL, 协议号等)
IPv4 头部是 IP 包的"快递面单",它包含了所有投递所需的信息(通常为 20 字节)。
|------------------------|--------|--------------------------------------------------------------------------------|
| 字段 | 长度 | 描述 |
| 版本 (Version) | 4 bit | 4(代表 IPv4) |
| 头部长度 (IHL) | 4 bit | 头部有多少个 32 位字(通常是 5,即 5 x 4 = 20 字节)。如果有"选项"字段,会大于 5。 |
| 服务类型 (ToS) | 8 bit | 用于 QoS (服务质量),指示包的优先级(如"语音包"优先)。 |
| 总长度 (Total Length) | 16 bit | 整个 IP 包(头部 + 数据)的总字节数。最大 65535 字节。 |
| 标识 (ID) | 16 bit | 用于 IP 分片。一个大包被切分后,所有"分片"都拥有相同的 ID。 |
| 标志 (Flags) | 3 bit | 用于 IP 分片。DF(Don't Fragment - 别分片),MF (More Fragments - 后面还有分片)。 |
| 分片偏移 (Offset) | 13 bit | 用于 IP 分片。指示这个分片在原始数据包中的"位置"。 |
| TTL (Time To Live) | 8 bit | "存活时间"。每经过一个路由器,TTL 减 1。当 TTL = 0 时,路由器会丢弃这个包。目的是防止数据包在网络中无限循环。 |
| 协议号 (Protocol) | 8 bit | 极其重要。指示这个 IP 包"肚子"里装的是什么(L4)协议的数据。- 6 = TCP,- 17 = UDP,- 1 = ICMP (Ping) |
| 头部校验和 | 16 bit | 只检查 IP 头部是否在传输中损坏。 |
| 源 IP 地址 | 32 bit | 发送方的 IP。 |
| 目的 IP 地址 | 32 bit | 接收方的 IP。 |
| 选项 (Options) | 可变 | (可选)用于网络测试等,不常用。 |
IP 分片与重组
- 为什么需要?
-
- 数据链路层(L2,如以太网)有MTU(最大传输单元) 的限制(以太网标准是 1500 字节)。
- 如果一个 IP 包(L3)的总长度(如 4000 字节)大于 L2 链路的 MTU(1500 字节),这个包就必须被"分片"(切割)才能通过。
- 谁来分片?
-
- 发送方主机 或 中间的路由器 都可以进行分片。
- 如何分片?(使用头部字段)
-
- 一个 4000 字节的包(20 字节头 + 3980 字节数据)要过 1500 字节的 MTU。
- 分片 1: 头部(20 字节) + 数据(1480 字节)。
-
-
ID = 12345(一个随机数)Flags = 1(MF=1, 后面还有)Offset = 0
-
-
- 分片 2: 头部(20 字节) + 数据(1480 字节)。
-
-
ID = 12345(ID 必须相同)Flags = 1(MF=1, 后面还有)Offset = 1480(偏移量)
-
-
- 分片 3: 头部(20 字节) + 数据(1020 字节)。
-
-
ID = 12345(ID 必须相同)Flags = 0(MF=0, 这是最后一个)Offset = 2960(偏移量)
-
- 谁来重组?
-
- 绝对不是中间的路由器(它们只管转发)。
- 只有最终的目的地主机 才会负责重组。
- 它会根据相同的 IP ID 收集所有分片,并根据偏移量将它们按正确顺序拼装起来,最后才交给 L4 (TCP/UDP)。
- 缺点: 效率低下。如果任何一个分片在传输中丢失,整个 IP 包(所有分片)都必须被重传。(这也是 IPv6 努力避免的机制)。
3 IPv6 协议
为什么需要 IPv6?
最根本的原因:IPv4 地址已经耗尽。
IPv4 只有 32 位地址(约 42.9 亿个),在 2011 年(全球)和 2019 年(中国)就已经分配完毕。随着手机、电脑、物联网(IoT)设备的爆炸式增长,我们迫切需要一个更大的地址空间。
IPv6 是什么?
IPv6 是下一代互联网协议。它最显著的特点是使用了 128 位 (bit) 的地址。
- IPv4:2^32 (约 42.9 亿)
- IPv6:2^128 (这是一个天文数字,大约是 3.4 x 10³⁸ 个)
- 类比: IPv6 的地址数量号称可以为地球上的每一粒沙子都分配一个 IP 地址。
IPv6 地址表示
128 位的地址如果用十进制写出来会是灾难。因此,IPv6 采用了十六进制表示法。
- 完整格式:
-
- 128 位被分为 8 组(段),每组 16 位。
- 每 16 位用 4 个十六进制数表示。
- 组与组之间用冒号(
:) 分隔。 - 示例:
2001:0db8:85a3:0000:0000:8a2e:0370:7334
- 压缩规则(为了简化书写):
-
- 规则 1:省略前导零 (Leading Zeros)
-
-
- 在任意一组中,开头的
0可以被省略。 0db8->db80000->00370->370- 压缩后:
2001:db8:85a3:0:0:8a2e:370:7334
- 在任意一组中,开头的
-
-
- 规则 2:压缩连续的零(双冒号)
-
-
- 如果地址中有一段或多段连续的
0(如上例中的:0:0:),可以用双冒号(::) 来代替。 - 压缩后:
2001:db8:85a3::8a2e:370:7334 - 重要限制: 在一个地址中,双冒号(
::)只能使用一次。
- 如果地址中有一段或多段连续的
-
-
-
-
- 为什么? 如果使用两次(如
2001::abcd::1),计算机会无法判断每段::代表了多少个 0,导致歧义。
- 为什么? 如果使用两次(如
-
-
-
- 更多示例:
-
-
- 环回地址 (Loopback):
0000:0000:0000:0000:0000:0000:0000:0001 - (规则 1) ->
0:0:0:0:0:0:0:1 - (规则 2) ->
::1(这就是 IPv6 的localhost) - 未指定地址:
0000:0000:0000:0000:0000:0000:0000:0000->::
- 环回地址 (Loopback):
-
- CIDR (无类别路由) 表示法:
-
- 和 IPv4 一样,IPv6 也使用 CIDR 来表示子网。
- 示例:
2001:db8:abcd:0012::/64表示前 64 位是网络前缀。
IPv6 头部格式
IPv6 不仅仅是扩展了地址,它还彻底重新设计 了 IP 报文头部,使其更简单、更高效。
- IPv4 头部: 20 字节(可变,带选项)
- IPv6 头部: 固定的 40 字节
IPv6 头部(40 字节):
|--------------------------------|---------|-------------------------------------------------------------------------------------------------------------------|
| 字段 | 长度 | 描述 |
| 版本 (Version) | 4 bit | 6(代表 IPv6) |
| 流量类别 (Traffic Class) | 8 bit | 类似于 IPv4 的 ToS,用于 QoS (服务质量)。 |
| 流标签 (Flow Label) | 20 bit | (新增) 一个用于标识特定"流"的标签,路由器可以对同一流的数据包进行统一处理(如 QoS 或负载均衡)。 |
| 有效载荷长度 (Payload Length) | 16 bit | 指示 IP 头部之后的"数据部分"有多长(字节)。 |
| 下一头部 (Next Header) | 8 bit | (关键改进) 指示紧跟在 IPv6 头部后面的是什么。- 6**= TCP** - 17**= UDP,** - 58**= ICMPv6** - 或扩展头部 (如 44=分片头部) |
| 跳数限制 (Hop Limit) | 8 bit | (替换 TTL) 功能与 IPv4 的 TTL 完全相同。每过一个路由器减 1,到 0 则丢弃该包(防环)。 |
| 源地址 (Source Address) | 128 bit | 发送方的 IPv6 地址。 |
| 目的地址 (Destination Address) | 128 bit | 接收方的 IPv6 地址。 |
IPv6 相比 IPv4 的改进
IPv6 不是对 IPv4 的简单升级,而是彻底的革新。
- 巨大的地址空间 (2¹²⁸)
-
- 这是最直观的改进。从根本上解决了 IPv4 地址枯竭的问题。
- 简化的头部格式(路由器处理更快)
-
- IPv6 头部是固定 40 字节。IPv4 头部是 20 字节 + 可变的"选项",路由器每次都要检查头部长度(IHL 字段),增加了处理开销。
- IPv6 将所有"选项"都移入了"扩展头部" (Extension Headers),核心路由器根本不看扩展头部,极大提高了转发效率。
- 移除了头部校验和 (Header Checksum)
-
- (巨大改进) IPv4 中,每个路由器都必须重新计算头部的校验和(因为 TTL 变了)。这是一个巨大的性能瓶颈。
- IPv6 直接取消了头部校验和。
- 理由: 现代网络的数据链路层(L2,如以太网 CRC)和传输层(L4,如 TCP/UDP Checksum)都有非常可靠的校验。L3 的校验是多余的。这极大地释放了路由器的 CPU 算力。
- 路由器不再分片 (No Router Fragmentation)
-
- (巨大改进) IPv4 中,如果路由器发现一个包(如 4000 字节)太大,无法通过下一跳(MTU 1500),路由器会负责将其"分片"。这个过程很慢。
- IPv6 中,路由器绝对不会分片。
- 机制: IPv6 依赖"路径 MTU 发现 (PMTUD)"。发送方(源主机) 会在发送前,先确定好整条路径上的最小 MTU。如果数据太大,发送方自己会提前分片(使用"分片扩展头部"),中间路由器只管转发。
- 好处: 再次简化了路由器的T作,把复杂工作甩回给端点。
- 恢复了端到端连接 (NAT 被废除)
-
- 由于 IPv4 地址不够用,才发明了 NAT(网络地址转换),导致你家里的
192.168.x.x无法被公网直接访问,破坏了互联网的"端到端"原则(P2P 应用很难)。 - IPv6 地址"多到用不完",每个设备都可以拥有一个全球唯一的公网 IP 地址。NAT 不再是必需品,P2P 和其他应用将变得极其简单。
- 由于 IPv4 地址不够用,才发明了 NAT(网络地址转换),导致你家里的
- 强制的 IPsec 支持 (更安全)
-
- IPsec (网络层加密/认证) 在 IPv4 中是"可选"的。
- 在 IPv6 中,IPsec 是协议规范的组成部分(虽然作为扩展头部实现),使其更容易部署,网络天生更安全。
- SLAAC (无状态地址自动配置)
-
- IPv4 严重依赖 DHCP 服务器来"分配"IP。
- IPv6 支持 SLAAC,设备可以不需要 DHCP 服务器,仅通过"侦听"路由器的广播,并结合自己的 MAC 地址,自动"计算"出一个全球唯一的 IP 地址来使用。
IPv4 到 IPv6 的过渡技术(双栈、隧道)
世界不可能在一夜之间从 v4 切换到 v6。在未来几十年,两者将共存。以下是三种主要的过渡技术:
- 双栈 (Dual Stack)
-
- 是什么?最常用、最直接的方案。
- 原理: 你的设备(电脑、手机、路由器)同时运行 IPv4 和 IPv6 两套独立的协议栈。它既有 IPv4 地址,也有 IPv6 地址。
- 类比: 你是一个双语者。
- 工作: 当你访问谷歌(支持 v6),系统优先使用 IPv6 栈。当你访问一个只支持 v4 的老网站,系统自动切换到 IPv4 栈。
- 隧道技术 (Tunneling)
-
- 是什么? 当两个"IPv6 孤岛"需要跨越"IPv4 海洋"(如现在的互联网)进行通信时使用。
- 原理: 你的路由器(隧道入口)将整个 IPv6 数据包(乘客)"打包"(封装)进一个IPv4 数据包(汽车)的"数据"部分。
- 这个 IPv4"汽车"载着 IPv6"乘客"穿过 IPv4 互联网。
- 到达对面的路由器(隧道出口)时,"汽车"被拆开,IPv6"乘客"被放出来,继续它的旅程。
- (例如 6to4, Teredo, ISATAP)
- 地址/协议转换 (NAT64 / DNS64)
-
- 是什么? 用于只有 IPv6 的设备(如某些 5G 手机网络)去访问只有 IPv4 的老服务器。
- 原理:
-
-
- DNS64: 你的 v6 手机查询
old-website.com(只有 v4 地址)。DNS 服务器(DNS64)会"合成"一个假的 IPv6 地址(比如64:ff9b::[v4 地址])返回给你。 - NAT64: 你的手机向这个"假 v6 地址"发送数据。网络边缘的 NAT64 网关会捕获这个包,将 IPv6 头部翻译成 IPv4 头部,然后替你访问那个 v4 服务器。收到回复时再反向翻译回来。
- DNS64: 你的 v6 手机查询
-
-
- 类比: 一个实时翻译官。
4 路由
1. 路由表
路由表是路由这个"过程"所产出的"结果"。
- 定义: 它是路由器内部的一张"导航指令表"或"路牌"。这张表极其简单,它不包含完整的地图,只包含"下一步该怎么走"。
- 类B: 你(路由器)在环岛上,要去"谷歌(
8.8.8.8)"。路由表不会告诉你全程路线,它只会告诉你:"去8.8.8.8?从 3 号口(WAN 口)出去就行了。" - 路由表的核心列:
|-----------------|-----------------|---------------------|----------------|-------------|
| 目的网络 | 子网掩码 (Mask) | 下一跳 (Next Hop) | 接口 (Interface) | 度量 (Metric) |
| 192.168.1.0 | 255.255.255.0 | 0.0.0.0(直连) | LAN 1 | 0 |
| 192.168.2.0 | 255.255.255.0 | 0.0.0.0 (直连) | LAN 2 | 0 |
| 0.0.0.0(默认路由) | 0.0.0.0 | 123.45.67.1 (ISP) | WAN | 10 |
0.0.0.0/0 (默认路由): 这是路由表的"else"选项。当一个目的 IP(如 8.8.8.8)无法匹配表中的任何"已知"网络时,路由器就会使用这条"默认"路由,把它扔给"下一跳"(通常是你的 ISP 运营商)。
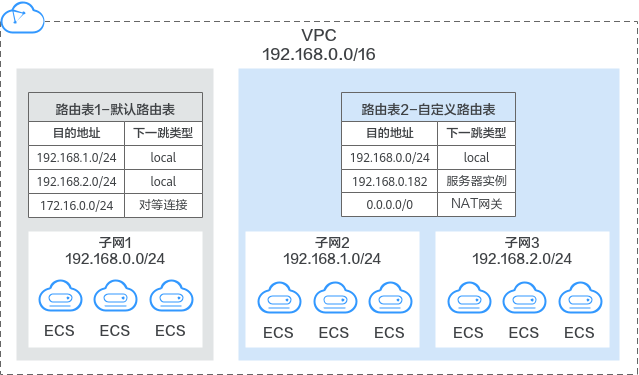
2. 静态路由与动态路由
这是"路由表"是如何被"填写"的两种方式。
- 静态路由
-
- 方式: 由网络管理员(人)"手动"配置。
- 命令: 比如管理员在路由器 A 上敲命令:
ip route 10.1.1.0 255.255.255.0 172.16.1.1 - 翻译: "(路由器A)如果你想去
10.1.1.0这个网,就把包发给172.16.1.1。" - 优点:
-
-
- 安全: 路由器不会"广播"自己的网络信息。
- 简单: 在小型、固定的网络中易于配置。
- 低开销: 不消耗 CPU 或带宽去"计算"路由。
-
-
- 缺点:
-
-
- 维护量大: 网络发生变化(比如增加一个新路由),管理员必须手动更新所有相关路由器。
- 无容错: 如果
172.16.1.1这条路断了,静态路由不会自动寻找"备胎"路线。
-
- 动态路由
-
- 方式: 由路由器"自动"学习和维护。
- 原理: 路由器们运行"路由协议"(如 OSPF, BGP),像开会一样互相"聊天"(交换路由信息),共同计算出全网的拓扑,并自动更新自己的路由表。
- 优点:
-
-
- 自动: 无需手动干预,扩展性极强。
- 自动容错: 如果一条"最佳路径"断了,协议会自动(在几秒或几分钟内)收敛,计算出"次佳路径"并启用。
-
-
- 缺点:
-
-
- 复杂: 配置相对复杂。
- 有开销: 消耗 CPU 算力和网络带宽(用于"聊天")。
-
3. 路由算法
路由算法是"动态路由"的"大脑",它规定了路由器该如何"思考"和"计算"最佳路径。主要分为三大类:
a. 1. 距离向量算法 (Distance Vector) - (以 RIP 为例)
- 算法思想: "道听途说"或"邻居八卦"。
- 工作方式: 路由器不关心全网的拓扑,它只关心:
-
- 距离: 我的"邻居"告诉我,它去某个目的地有多"远"?(例如,"跳数")
- 向量: 我应该从"哪个方向"(哪个邻居)走?
- 示例(RIP - Routing Information Protocol):
-
- 度量:跳数,即经过多少个路由器。
- 流程: 路由器 A 把自己的路由表("我 1 跳能到 X,2 跳能到 Y...")发给邻居 B。B 收到后,把所有距离加 1,然后和自己的表比较,"择优录取"(选择跳数最少的)。
- 缺点:
-
-
- 收敛慢: 好消息传得快,坏消息(如链路断开)传得极慢。
- "计数到无穷":容易在环路中"道听途说",导致路由表"中毒"。
-
b. 2. 链路状态算法 (Link-State) - (以 OSPF 为例)
- 算法思想: "全图在手,自己计算"。
- 工作方式: 每个路由器都"泛洪"自己直连接口的状态("我的 1 号口连着 R2,带宽 100M,状态 Up..."),这种信息叫 LSA (链路状态通告)。
- 流程:
-
- 所有路由器收集全网所有的 LSA,在本地"拼凑"出一张完整、一致的全网拓扑地图(LSDB)。
- 每台路由器独立地在自己的本地地图上,以自己为根,运行 Dijkstra(SPF - 最短路径优先)算法。
- 计算出自己到全网所有目的地的"最短路径树"。
- 示例(OSPF - Open Shortest Path First):
-
- 度量:Cost (开销)。Cost 通常与带宽成反比(带宽越高,Cost 越低)。OSPF 总是选择总 Cost 最小的路径。
- 优点:收敛极快、无环路、可扩展性强(通过"区域"划分)。
c. 3. 路径向量算法 (Path-Vector) - (以 BGP 为例)
- 算法思想: "策略为王,不问细节"。
- 工作方式: 这是距离向量的一种高级演变。它不只关心"多远",它更关心"经过了谁"。
- 流程:
-
- 当一个路由被通告时,它必须携带一个"路径属性"(
AS_PATH),这个属性记录了它"途经的所有自治系统(AS)列表"。 - (例如:
AS_PATH: [AS 2, AS 1])
- 当一个路由被通告时,它必须携带一个"路径属性"(
- 示例(BGP - Border Gateway Protocol):
-
- 核心: BGP 不是用来选"最快"路径的,它是用来在不同组织(AS) 之间执行"策略"的。
- 防环: 路由器收到 BGP 路由,如果发现
AS_PATH里已经有自己的 AS 号了,就知道这是个环路,立即丢弃。
4. 内部网关协议(IGP)
这是对所有"动态路由协议"的最高级别分类,它定义了这些协议在"哪里"使用。
要理解这个,必须先知道"自治系统":
- AS (自治系统): 一个单一组织(如中国电信、中国联通、谷歌、一所大学)所管理的整个网络。
a. 1. 内部网关协议 (IGP - Interior Gateway Protocol)
- 定义: 在"一个"AS 内部使用的路由协议。
- 目标:效率和速度。在组织内部尽快找到"最短/最快"的路径。
- 例子:
-
- RIP (距离向量)
- OSPF (链路状态)
- EIGRP (Cisco 私有)
5. 外部网关协议(EGP)
a. 外部网关协议 (EGP - Exterior Gateway Protocol)
- 定义: 在"不同"AS 之间(在互联网的"边界"上)使用的路由协议。
- 目标:策略和控制。它不关心你公司内部的细节,它只关心"中国电信"的网络如何与"中国联通"的网络交换路由信息。
- 例子:
-
- BGP (边界网关协议) 是目前互联网上唯一在使用的 EGP 协议。
总结: 在你公司(AS 65001)内部,所有路由器跑 OSPF (IGP) 来高效通信。你公司的边界路由器,会使用 BGP (EGP) 来和中国电信(AS 4134)的路由器"对话",告诉它:"嘿,我这里有这些网络,你可以通过我访问它们。"
5 网络层协议
ICMP(互联网控制报文协议,Ping, Traceroute)
ICMP 是网络层的诊断和错误报告协议。
- 核心功能: 它的唯一工作是报告网络问题和发送控制消息。它不传输数据,而是传输"关于网络状态"的消息。
- 类比: 你是 IP 协议(一个只管送货的快递员)。ICMP 就像是你的对讲机或"投递失败通知单"。
-
- 当你(IP)投递一个包失败时,ICMP 负责报告:"嘿,总部,那个地址(目的IP)根本不存在!"
- 或者你用 ICMP 呼叫目的地:"嘿,你(目的IP)在吗?"
- 封装: ICMP 报文是封装在 IP 数据包内部的。当一个路由器或主机要发送 ICMP 消息时,它会创建一个 ICMP 报文,然后在外面包上一个 IP 头部(IP 头部中的"协议号"字段会被标记为
1),然后发送出去。
两个最著名的应用:ping 和 traceroute
ping(Packet Internet Groper) - "你在吗?"
ping 是用来测试网络连通性和往返时间 (RTT) 的命令。它利用了两种 ICMP 消息:
- ICMP 类型 8 (Echo Request - 回显请求)
- ICMP 类型 0 (Echo Reply - 回显应答)
工作流程:
-
你在电脑 A 上执行
ping 8.8.8.8(谷歌的 DNS 服务器)。 -
你的电脑 A 会构建一个 ICMP Echo Request 报文,封装在一个 IP 包里(目标 IP:
8.8.8.8),然后发送出去。 -
当
8.8.8.8这台服务器的网络层(IP 层)收到这个包,它会查看 IP 头部的"协议号",发现是1(ICMP)。 -
它解开包,看到 ICMP 头部,发现是"类型 8"(回显请求)。
-
服务器的操作系统立即构建一个 ICMP Echo Reply 报文,封装在一个新的 IP 包里(目标 IP: 你的电脑 A),然后发回给你。
-
你的电脑 A 收到回复,计算从发送到接收的总时间(比如
10ms),这就是 RTT。 -
traceroute(或tracerton Windows) - "我该怎么去你那里?"
traceroute 是一个更高级的诊断工具,用来探测一个数据包从你的电脑到目标主机所经过的"每一跳"路由器。
它巧妙地利用了 IP 头部的 TTL (Time To Live) 字段和 ICMP 的"超时"**消息:
- ICMP 类型 11 (Time Exceeded - 超时)
工作流程(以 traceroute 8.8.8.8 为例):
- 第一次探测 (TTL=1):
-
- 你的电脑 A 发送一个 UDP 包(或 ICMP 请求包)给
8.8.8.8,但故意将 IP 头部的TTL设置为 1。 - 包到达第一个路由器 R1。R1 按规定将
TTL减 1,TTL变为 0。 - 路由器 R1 丢弃这个包(因为 TTL=0),并发回一个 ICMP Time Exceeded 错误消息给你的电脑 A。
- 你的电脑 A 收到这个 ICMP 包,记录下 R1 的 IP 地址和 RTT。
- 你的电脑 A 发送一个 UDP 包(或 ICMP 请求包)给
- 第二次探测 (TTL=2):
-
- A 再发送一个包,这次将
TTL设置为 2。 - 包到达 R1,TTL 减为 1,通过。
- 包到达第二个路由器 R2。R2 将
TTL减为 0,丢弃该包。 - R2 发回一个 ICMP Time Exceeded。
- A 记录下 R2 的 IP 地址和 RTT。
- A 再发送一个包,这次将
- 依此类推 (TTL=3, 4, 5...):
-
- 这个过程不断重复,每次
TTL加 1,直到...
- 这个过程不断重复,每次
- 到达终点:
-
- ...
TTL足够大(比如TTL=8),包终于到达了最终目的地8.8.8.8。 8.8.8.8收到这个(UDP)包,发现端口不可用(traceroute故意用一个奇怪的端口),它会发回一个 ICMP Destination Unreachable (Port Unreachable) 错误消息。- 当你的电脑 A 收到这个"端口不可达"的消息时,它就知道:"探测结束,我到站了。"
- ...
IGMP(互联网组管理协议,组播)
IGMP 是网络层用来管理"组播 (Multicast)" 成员关系的协议。
- 核心功能: 它的唯一工作是让一台主机(你的电脑)告诉它"本地的路由器":"嘿,我想加入/离开某个组播组(比如一个电视频道)。"
- 类比: 如果"组播"是一个付费杂志的订阅服务,IGMP 就是你用来"订阅"和"退订"这本杂志的回执单。
什么是组播 (Multicast)?
要理解 IGMP,必须先理解组播。组播是介于"单播"和"广播"之间的一种高效传输方式:
- 单播 (Unicast) (1-to-1): 你给朋友单独发一封邮件。
- 广播 (Broadcast) (1-to-All): 你在小区里用大喇叭喊话,所有人(无论想不想听)都听到了。非常浪费资源。
- 组播 (Multicast) (1-to-Many):
-
- 你(服务器)向一个特殊的"组地址"(一个 D 类 IP,如
239.1.1.1)发送数据流。 - 互联网上只有那些"订阅"(加入)了
239.1.1.1这个组的用户才能收到这份数据流。 - 最经典应用:IPTV(网络电视)。
- 你(服务器)向一个特殊的"组地址"(一个 D 类 IP,如
-
-
- 电视台(服务器)只需要发送一路高清视频流到
239.1.1.1(CCTV5 频道)。 - 全市有 5000 个人在看 CCTV5,他们 5000 台电脑都通过 IGMP 告诉路由器"我要加入
239.1.1.1"。 - 路由器(支持组播的)就会把这一路视频流复制并转发给这 5000 个人。
- (这远比用"单播"向 5000 人单独发送 5000 路视频流要高效得多)。
- 电视台(服务器)只需要发送一路高清视频流到
-
IGMP 的工作流程
IGMP 就是你(主机)和你家门口的路由器之间那个"订阅"和"退订"的对话:
- IGMP Membership Report (成员报告 / "Join")
-
- 你打开 IPTV 客户端,点了 CCTV5。
- 你的电脑会向本地路由器发送一个 IGMP 报告:"嘿,路由器,我想加入
239.1.1.1这个组。" - 路由器收到后,记下:"OK,我这个网段(LAN)有人要看 CCTV5 了。" 路由器就会开始向上游请求这个视频流。
- IGMP Query (成员查询)
-
- 路由器会定期(比如每 60 秒)向本地局域网发送一个 IGMP 查询:"嘿,我网段下的各位,有谁还在看
239.1.1.1吗?" - 所有还在看的电脑都会回复一个 IGMP 报告。
- 如果一段时间内(比如 3 分钟),路由器没有收到任何关于
239.1.1.1的回复,它就认为"这个频道没人看了",于是它就停止向上游请求这个视频流,以节省带宽。
- 路由器会定期(比如每 60 秒)向本地局域网发送一个 IGMP 查询:"嘿,我网段下的各位,有谁还在看
- IGMP Leave Report (离开报告)
-
- 你换台了(或关了电视)。
- 你的电脑会(主动)发送一个 IGMP 离开报告:"嘿,路由器,我要离开
239.1.1.1这个组了。"
总结对比
|-------|-----------------------------------------------------------------|-------------------------------------------------------------|
| 协议 | ICMP (互联网控制报文协议) | IGMP (互联网组管理协议) |
| 用途 | 诊断与错误报告 | 组播 (Multicast) 成员管理 |
| 解决了什么 | "网络通不通?" (Ping) "中间经过了谁?" (Traceroute) "为什么发不过去?" (Unreachable) | "谁想接收这个组播流?" (Join) "谁退订了这个流?" (Leave) (用于高效的 1-to-Many 传输) |
| 封装 | 封装在 IP 包中 (协议号 1) | 封装在 IP 包中 (协议号 2) |
| 类比 | 快递的"对讲机"或"投递失败通知单" | IPTV 的"电视频道订阅/退订单" |
6 网络层技术
6NAT 和 VPN 是网络层(L3)上两个极其重要且应用广泛的技术,它们分别解决了"IP 地址枯竭"和"网络通信安全"两大难题。
NAT (Network Address Translation) - 网络地址转换
NAT 是一种"地址欺骗"技术。它的核心功能是:允许多个设备(使用内网 IP)共享一个"公网 IP"去访问互联网。
- 类比:
-
- 你的公司(内网)是一个大办公室,里面有 100 名员工(100 台电脑,IP 都是
192.168.1.xxx)。 - 公司的前台(路由器) 只有一个公共的街道地址(公网 IP,比如
123.45.67.89)。 - NAT 就是这个前台的"总机小姐"。
- 你的公司(内网)是一个大办公室,里面有 100 名员工(100 台电脑,IP 都是
1. 为什么需要 NAT?
最根本的原因:IPv4 地址不够用了。 全球只有约 42.9 亿个 IPv4 地址,但有几百亿台设备。NAT 允许你家里(或公司)的几十台设备(手机、电脑、电视)共用一个由运营商(ISP)分配的公网 IP,极大地缓解了 IP 地址的消耗。
2. NAT 是如何工作的?
当你的电脑(内网 IP 192.168.1.100)要访问谷歌(公网 IP 8.8.8.8)时:
- 打包(离开内网):
-
- 你的电脑发出一个 IP 包。
- 源 IP:
192.168.1.100(你的内网 IP) - 源端口:
50000(一个随机的高端口) - 目的 IP:
8.8.8.8 - 目的端口:
443(HTTPS)
- NAT 转换(在路由器):
-
- 路由器(前台总机)收到这个包。它不能把带有"内网 IP"的包发到公网上(公网不认识
192.168.1.100)。 - 路由器"欺骗性"地修改了这个包的源地址:
- 源 IP:
123.45.67.89(路由器的公网 IP) - 源端口:
9001(路由器新分配的端口) - 同时, 路由器在自己的"NAT 转换表"(小本本)上记下一笔:
{ 内部 192.168.1.100:50000 } <--> { 外部 123.45.67.89:9001 }
- 路由器(前台总机)收到这个包。它不能把带有"内网 IP"的包发到公网上(公网不认识
- 访问公网:
-
- 谷歌服务器(
8.8.8.8)收到了这个包。在它看来,这个包是123.45.67.89:9001(路由器)发来的。 - 谷歌服务器把回包发往
123.45.67.89:9001。
- 谷歌服务器(
- NAT 逆转换(返回内网):
-
- 路由器(前台总机)收到了谷歌的回包(目标是
...:9001)。 - 路由器查询"NAT 转换表"(小本本),发现
9001对应的是192.168.1.100:50000。 - 路由器再次修改这个包的目的地址:
- 目的 IP:
192.168.1.100 - 目的端口:
50000 - 路由器把包发给你内网的电脑。
- 路由器(前台总机)收到了谷歌的回包(目标是
- 完成: 你的电脑收到了回包。在整个过程中,你的电脑完全不知道自己的 IP 地址被"掉包"了。
3. NAT 的副作用(好处和坏处)
- 好处(主要目的): 解决了 IP 地址枯竭问题。
- 附带的好处(安全性): NAT 充当了一个天然的防火墙。
-
- 互联网上的黑客(在公网)无法主动发起连接来访问你的
192.168.1.100,因为路由器(防火墙)收不到"未经请求"的外部数据时,根本不知道该把包转给内网的谁,会直接丢弃。
- 互联网上的黑客(在公网)无法主动发起连接来访问你的
- 坏处:破坏了"端到端"连接。
-
- 因为内网设备被隐藏了,P2P 应用(如某些联机游戏、BT 下载)变得非常困难。你需要手动设置"端口转发"才能让外部访问你的内网服务。
VPN (Virtual Private Network) - 虚拟专用网络
VPN 是一种"加密隧道"技术。它的核心功能是:允许你通过一个不安全的网络(如公共互联网),安全地访问一个私有的网络(如你的公司内网)。
- 类比:
-
- 你在星巴克(不安全的公共网络)办公。
- 你想访问你公司的内部服务器(
10.1.1.5,这是一个内网 IP,在星巴克根本访问不到)。 - VPN 就像是: 你从星巴克的电脑上,建立了一条"加密的、私密的、虚拟的"地下通道,这条通道穿过整个互联网,直达你公司的大门口(VPN 网关)。
1. 为什么需要 VPN?
- 远程访问 (Remote Access):
-
- 这是最常见的用途。允许出差的员工或居家办公的员工,能像在公司内部一样,安全地访问公司的内部资源(如文件服务器、OA 系统)。
- 站点到站点 (Site-to-Site):
-
- 连接两个不同地理位置的公司办公室(比如北京分部和上海总部)。
- VPN 可以在这两个办公室的路由器之间建立一条永久的加密隧道,使得两个办公室的内网(如
192.168.1.0/24和192.168.2.0/24)看起来就像在同一个局域网内。
- 绕过限制("科学上网"):
-
- (这是 VPN 的一个衍生用途)VPN 会把你所有的网络流量都从这条"隧道"发出去。
- 如果隧道的"出口"(VPN 服务器)在美国,那么在互联网上的所有人(如谷歌、YouTube)看来,你仿佛就是在美国上网。
2. VPN 是如何工作的?(以远程访问为例)
- 启动连接:
-
- 你在星巴克的电脑(公网 IP
200.1.1.1)上启动 VPN 客户端(如Cisco AnyConnect)。 - 你输入你公司 VPN 网关的公网地址(如
150.1.1.1)以及你的用户名和密码。
- 你在星巴克的电脑(公网 IP
- 建立隧道(加密):
-
- 你的电脑和公司 VPN 网关之间通过互联网进行"握手"。
- 它们协商出一个加密密钥,建立起一条IPsec或SSL/TLS加密隧道。
- 分配内网 IP:
-
- 隧道建立后,公司 VPN 网关会额外分配给你一个"公司内网的临时 IP"(比如
10.1.1.200)。 - 现在,你的电脑拥有了两个 IP:一个是星巴克的公网 IP(用于物理通信),一个是公司分配的内网 IP(用于隧道内通信)。
- 隧道建立后,公司 VPN 网关会额外分配给你一个"公司内网的临时 IP"(比如
- 访问内网:
-
- 你试图访问公司服务器
10.1.1.5。 - 你的电脑(操作系统)发现目标是
10.x.x.x网段,它知道"这个流量要走 VPN 隧道"。 - 打包(封装与加密):
- 你试图访问公司服务器
-
-
- (A) 原始包(内网包):
-
-
-
-
- 源 IP:
10.1.1.200(VPN 分配给你的) - 目的 IP:
10.1.1.5(公司服务器)
- 源 IP:
-
-
-
-
- (B) 加密: 你的电脑将整个 (A) 包进行加密。
- (C) 封装(隧道包): 你的电脑将这个"加密数据块"作为数据,封装到一个新的公网 IP 包里:
-
-
-
-
- 源 IP:
200.1.1.1(星巴克的 IP) - 目的 IP:
150.1.1.1(公司 VPN 网关的 IP)
- 源 IP:
-
-
- 解密与转发:
-
- 这个公网包 (C) 穿过互联网,到达公司 VPN 网关。
- 网关收到后,拆开 (C) 包,发现是加密数据。
- 网关用密钥解密 (B),取出了原始的内网包 (A)。
- 网关一看:"哦,是发给
10.1.1.5的。" 于是它把这个原始包 (A) 转发到了公司内网。
- 完成: 公司服务器
10.1.1.5收到了包,它看来,这个包就是从10.1.1.200(你)那里发来的。它把回包发给10.1.1.200,网关再加密、封装、发回给你。
总结: VPN 就是通过"封装 + 加密",在公网(L3)上虚拟出了一条私密(L2) 的"隧道"。
7 网络层设备
路由器(Router)
路由器(Router)是网络层(OSI 第 3 层) 的绝对核心设备。如果你家里的 Wi-Fi 路由器是"内务总管",那么互联网上的路由器就是"全球邮政总局"和"交通枢纽"。
它最核心的工作,就是连接两个或多个不同的网络(比如你家内网和外面的互联网),并根据 IP 地址决定数据包的最佳路径,然后将其转发出去。
一、 核心功能:路由与转发
这是路由器的立身之本,是它存在的唯一目的。这两个词经常被混用,但它们是两个不同的动作:
-
- 转发 - "查地图"
-
- 这是路由器的瞬时动作(在"数据平面"完成)。
- 当一个数据包(比如你发给谷歌的包)到达路由器时,路由器会立即:
-
-
- "拆开" 数据链路层(L2)的帧。
- "查看" 网络层(L3)IP 包头部的"目的 IP 地址"(比如
8.8.8.8)。 - "查询" 自己内部的一张"路由表"。
- 根据路由表中的指示("最佳路径"),决定应该从哪个"出口"(物理端口) 把这个包扔出去。
-
-
- 类比: 你开车到了一个复杂的环岛(路由器),你只看了一眼路牌(路由表),就立即打方向盘(转发) 从正确的出口(如"往北/往高速")开出去。
-
- 路由选择 - "画地图"
-
- 这是路由器后台的、持续的计算过程(在"控制平面"完成)。
- 路由器的"路由表"不是天生就有的,它必须被建立起来。
- 路由选择就是路由器建立并维护这张"路由表"的过程。
- 建立方式:
-
-
- a. 直连路由: 路由器开机,它会立即知道自己插上了几根网线,这几个直连的网络(比如
192.168.1.0/24)是它的第一批路由。 - b. 静态路由: 网络管理员手动告诉路由器:"嘿,要去
10.1.1.0/24这个网,你必须从 3 号口发给172.16.1.1。" - c. 动态路由:(最核心) 路由器们自己运行 OSPF 或 BGP 这样的路由协议,像开会一样互相交换"地图信息",并自动计算出到达全网的"最佳路径"。
- a. 直连路由: 路由器开机,它会立即知道自己插上了几根网线,这几个直连的网络(比如
-
总结: 路由负责"画地图"(建立路由表),转发负责"查地图"(使用路由表发送数据)。
二、 路由器 vs 交换机 (Switch) - L3 vs L2
这是网络中最重要的区别:
- 交换机 - L2 - 局域网总机
-
- 工作在: 数据链路层(L2)。
- 理解什么:MAC 地址(物理地址)。
- 作用: 在同一个局域网(LAN) 内部(如你家或你办公室),根据 MAC 地址精确地转发数据帧。
- 类比: 你公司的内部电话总机。它只负责把
A 工位的电话转接给B 工位,它不负责帮你打电话到另一家公司。
- 路由器 - L3 - 网络边境口岸
-
- 工作在: 网络层(L3)。
- 理解什么:IP 地址(逻辑地址)。
- 作用: 连接不同的网络(LAN 和 WAN,内网和公网),在网络之间转发数据包。
- 类比:电信局或国家海关。它不管你公司内部的电话,它只负责把你的"国际长途"从你公司(一个网络)转接到另一家公司(另一个网络)。
三、 核心功能:隔离广播域
这是路由器的另一个极其重要的特性。
- 什么是广播域?
-
- 在一个局域网中,如果一台电脑 A 发送一个广播(比如 ARP 请求:"谁是 192.168.1.1?"),交换机 会"无脑"地把这个广播转发给所有连接在它上面的其他电脑。这个广播能触及的范围,就是一个"广播域"。
- 问题: 如果一个网络有上万台电脑(比如一个大学校园),全都连在交换机上,那么任何一个广播都会"淹没"整个网络,造成"广播风暴",网络会瞬间瘫痪。
- 路由器的解决方案:
-
- 路由器是"广播"的终结者。
- 默认情况下,路由器绝对不会将一个局域网(如
192.168.1.0/24)的广播(L2 Broadcast)转发到另一个局域网(如192.168.2.0/24)。 - 结论: 路由器的每一个端口(接口)都连接着一个独立的广播域。它把一个巨大的广播域,切分成了多个小型的、可管理的广播域。
- (这也是为什么你家里的
VLAN 10和VLAN 20之间必须要有一个路由器(或三层交换机)才能通信)。
四、 工作原理解析(一个数据包的旅程)
场景: 你的电脑 (192.168.1.100) 想要访问谷歌服务器 (8.8.8.8)。
- 在你电脑上(L3):
-
- 你的电脑(操作系统)查看
8.8.8.8。它用自己的子网掩码(255.255.255.0)一算,发现8.8.8.8不在本地网络(192.168.1.0)内。 - 电脑决定:"我必须把这个包发给我的默认网关。"
- (默认网关就是你家路由器的内网 IP,比如
192.168.1.1)
- 你的电脑(操作系统)查看
- 在你电脑上(L2):
-
- 你的电脑使用 ARP 协议,获取了路由器
192.168.1.1的 MAC 地址(比如Router-MAC)。 - 你的电脑封装一个 L2 帧:
- 你的电脑使用 ARP 协议,获取了路由器
-
-
- 源 MAC:
PC-MAC - 目的 MAC:
Router-MAC
- 源 MAC:
-
-
- 在这个 L2 帧里面,封装了 L3 的 IP 包:
-
-
- 源 IP:
192.168.1.100 - 目的 IP:
8.8.8.8
- 源 IP:
-
-
- 电脑将这个帧发给交换机,交换机将其转发给路由器。
- 在路由器上(核心处理):
-
-
Step 1 (L2 接收): 路由器从内网端口(LAN Port) 收到这个帧。
-
Step 2 (L2 解封装): 路由器检查目的 MAC(
Router-MAC),"是发给我的!"。于是它"拆开"这个 L2 帧,扔掉 L2 头部,取出里面的 L3 IP 包。 -
Step 3 (L3 检查): 路由器查看 IP 包,看到目的 IP 是
8.8.8.8。 -
Step 4 (L3 查表): 路由器查询自己的路由表:
- 192.168.1.0/24 -> 走 LAN 口
- 0.0.0.0/0 (默认路由) -> 走 WAN 口,下一跳 123.45.67.1 (ISP的路由器)
-
-
- 路由器匹配到默认路由:"OK,这个包必须从外网端口(WAN Port) 扔出去。"
- Step 5 (TTL 减 1): 路由器将 IP 包头部的 TTL 字段减 1(比如从 64 变成 63),以防止无限循环。
- Step 6 (L2 重封装): 路由器"重新"打包这个 IP 包(注意: IP 包的源/目 IP 始终不变),在它外面套上一个全新的 L2 帧(比如发往 ISP 的帧)。
-
-
- 源 MAC:
Router-WAN-MAC(路由器外网口的 MAC) - 目的 MAC:
ISP-Router-MAC(它通过 ARP 获得的下一跳 MAC)
- 源 MAC:
-
-
- Step 7 (L1 发送): 路由器将这个新帧从 WAN 口发送到互联网。
这个"拆 L2 -> 查 L3 -> 重组 L2"的过程,就是路由器的核心工作原理。