算法StandardScaler是用于处理向量数据集合的数据元素的标准缩放,减少数据元素之间的差异,更加容易地执行数据分析,是统计学的数据分析领域常用的标准化方法。
向量数据集合的数据元素的标准缩放的计算公式,对数据中心化(参数:withMean,默认值为True),则均值为0,对数据缩放(参数:withStd,默认值为False),则标准差为1:
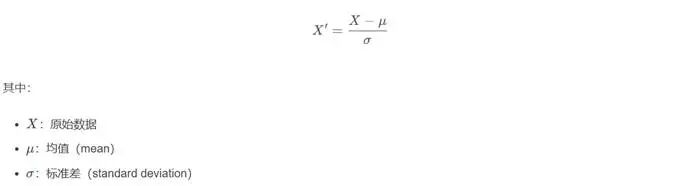

Java代码示例
创建算法StandardScaler测试类,初始化spark实例:

加载数据分类libsvm的标准测试数据集合:

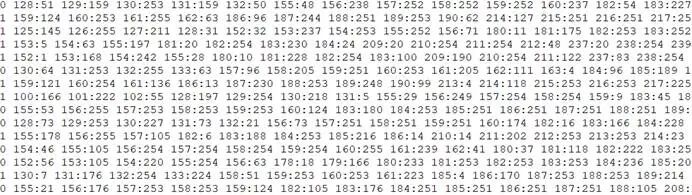
数据分类libsvm的标准测试数据集合的部分数据样本,其中,第一列是标签,用于标识数据的分类,其他列是特征数据(特征值对应的索引号:特征值):
创建算法StandardScaler实例,设置输入输出数据列的名称,设置标准差以及均值的参数:
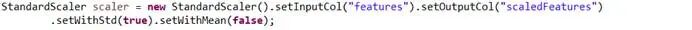
创建算法StandardScaler模型实例,用于对向量数据集合执行特征转换:
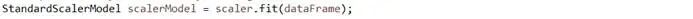
使用算法StandardScaler模型实例执行特征转换,输出标准化的向量数据集合:

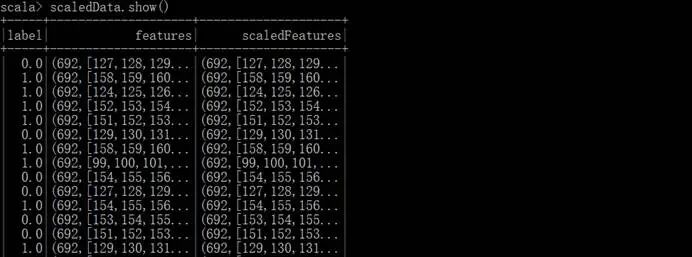
特征转换输出的部分数据样本,其中,第一列是标签,692是特征值的总数,特征值对应的索引号集合,特征转换的标准缩放的数据集合:
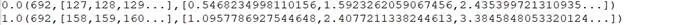
Scala代码示例
与Java代码示例的功能逻辑相同:

启动spark-shell的Scala本地运行环境:
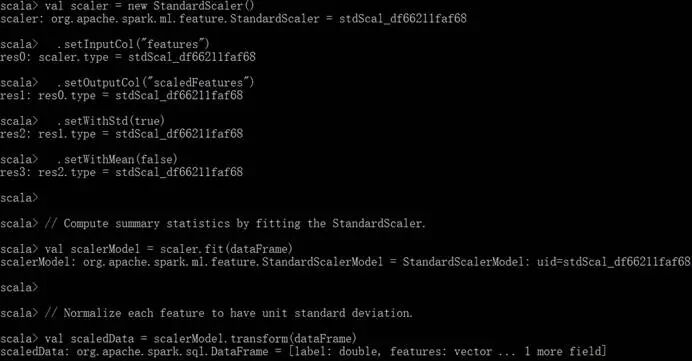
运行StandardScaler算法代码:
特征转换输出的数据集合: