文章目录
- 摘要
- abstract
- 一、深度学习
-
- [1.1 倾斜数据的误差指标](#1.1 倾斜数据的误差指标)
- [1.2 决策树模型 与神经网络对比](#1.2 决策树模型 与神经网络对比)
- [1.3 决策树](#1.3 决策树)
-
- [1.3.1 特征值取多个离散值](#1.3.1 特征值取多个离散值)
- [1.3.2 特征值取连续值](#1.3.2 特征值取连续值)
- [1.4 回归树](#1.4 回归树)
- 二、CNN学习实践
-
- [2.1 可视化数字训练](#2.1 可视化数字训练)
- [2.2 增加字母数据](#2.2 增加字母数据)
- 总结
摘要
本周继续学习深度学习,并实践。学习了深度学习的倾斜数据误差指标(下面CNN实践用上)、决策树、回归树;在CNN学习实践中,对上周训练加了可视化,并增加了新的数据识别。
abstract
This week I continued studying deep learning and put it into practice. I learned about skewed data error metrics in deep learning (which were used in the CNN practice below), decision trees, and regression trees; in the CNN learning practice, I added visualization to last week's training and included new data recognition.
一、深度学习
1.1 倾斜数据的误差指标
混淆矩阵是分类问题中的一种矩阵,用于展示模型在每一类上的预测情况。对于二分类问题,混淆矩阵是一个2x2的矩阵,包括真正例(TP)、假正例(FP)、真负例(TN)和假负例(FN)。
通过混淆矩阵,我们可以计算出多种指标。
精确率衡量的是模型预测为正例的样本中真正为正例的比例。Precision = TP / (TP + FP)。精确率高意味着模型在预测为正例的样本中,实际正例的比例高,即误报率低。
召回率衡量的是实际为正例的样本中被模型正确预测为正例的比例。Recall = TP / (TP + FN)。召回率高意味着模型能够有效地捕捉到实际的正例,即漏报率低。

F1分数是精确率和召回率的调和平均数,它试图同时考虑精确率和召回率。F1 = 2 * (Precision * Recall) / (Precision + Recall)。F1分数在精确率和召回率之间取得平衡,适用于需要同时考虑两者的情况。
精确率-召回率曲线下面积(AUC-PR)。PR曲线是以召回率为横轴,精确率为纵轴绘制的曲线。AUC-PR是PR曲线下的面积,特别适用于类别不平衡的情况,在这种情况下,精确率和召回率比假正率更重要。
马修斯相关系数(MCC):MCC是一种用于衡量二分类性能的指标,它考虑了真正例、假正例、真负例和假负例,是一个平衡的指标,即使在类别不平衡时也能表现良好。
MCC = (TPTN - FPFN) / sqrt((TP+FP)(TP+FN)(TN+FP)*(TN+FN))。
MCC的取值范围为-1,1,1表示完美预测,0表示随机预测,-1表示完全错误预测。
几何平均数(G-Mean):G-Mean是召回率和特异性的几何平均数,常用于评估不平衡数据的分类性能。
G-Mean = sqrt(Recall * Specificity)
其中,特异性(Specificity) = TN / (TN + FP)
G-Mean同时考虑了正例和负例的识别能力,在不平衡数据中是一个很好的指标。
适用场景
'精确率': '误报代价高时(如垃圾邮件检测)',
'召回率': '漏报代价高时(如疾病诊断)',
'F1分数': '需要平衡精确率和召回率时',
'MCC': '各类别重要性相同时',
'G-Mean': '严重不平衡数据',
'平衡准确率': '各类别平等重要'
对于多分类问题,这些指标可以通过宏平均(Macro-average)、微平均(Micro-average)和加权平均(Weighted-average)来扩展。
注:最近用到的主要是准确率,召回率这些,其他拓展还没用上,没有展开。
1.2 决策树模型 与神经网络对比
决策树:模仿人类的决策过程。通过一系列清晰的、基于特征的if-then-else问题,对数据进行层层划分,最终得到一个预测结果。(白盒模型,规则清晰可解释,基于规则的推理)。像一份精确的问卷调查或流程图。结构化数据划分。
例子:问:"是男的还是女的?" -> "男的" -> 问:"年龄大于30吗?" -> "是" -> 问:"收入高于5万吗?" -> ... 最终得出结论
目标:找到能够最纯净地划分数据集的特征和阈值。
擅长处理表格化数据(结构化数据),对特征工程要求较低。
对比下神经网络:模仿人脑的神经元网络。通过大量简单的"神经元"相互连接,并对连接强度(权重)进行自适应调整,来学习数据中复杂的、非线性的模式。(黑盒模型,内部逻辑难以解释,基于连接的模拟)。
例子:像一個儿童的大脑。给他看成千上万张猫和狗的图片(数据),并告诉他答案(标签)。他一开始会乱猜,但通过不断纠正错误,大脑内部的神经元连接会自我调整,最终形成一个复杂的"网络",能准确识别出猫狗,但他可能无法用语言清晰解释为什么。
目标:通过前向传播和反向传播,最小化预测误差,从而学习到最佳的权重和偏置。
擅长处理原始数据(图像、文本、音频),需要复杂的特征工程或能自动学习特征。
1.3 决策树
决策树是一种基于特征划分的树形结构模型,它通过对特征进行一系列的判断来做出决策。对于传统的决策树,输入特征通常是表格化的数据,即每个样本是一组特征向量。决策树并不直接处理原始图像数据,因为图像通常是由像素组成的高维数据,而且像素之间的空间关系对于图像识别至关重要。
判别图像是否为猫:根据不同的特征进行判别(像一颗向下的树):
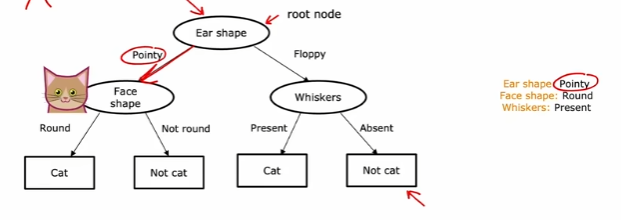
学习过程:通过提出一系列"问题"(基于特征),将数据集划分成越来越纯净的子集。自动地、数据驱动地找出最优的一系列问题。
根节点:代表整个数据集,是树的起点。内部节点:代表一个特征测试,根据测试结果将数据引向不同的分支。叶节点:代表最终的决策结果(类别或数值)。分支:代表一个特征测试的结果。
核心是解决两个问题:选择哪个特征进行分裂?在这个特征的哪个值上进行分裂?
需要一个衡量标准来判断"分裂的好坏"。标准:不纯度。我们的目标是让子节点的不纯度尽可能低(即尽可能纯净)。
熵:度量样本集合纯度的指标。熵越大,越混乱。
熵值的定义H(p1):越靠近边缘两端,越纯,靠近中间越不纯。

决策树的构建通常是一个递归和贪心的过程。递归:对每个分裂后的子数据集,重复调用相同的建树过程。贪心:在每一步,只选择当前最优的分裂,而不考虑全局最优。
j
函数:构建决策树(当前数据集 D, 特征集 A)
1. 创建节点 N
2. IF D 中所有样本都属于同一类别 C:
3. 将节点 N 标记为 C 类叶节点;返回 N
4. IF 特征集 A 为空 OR D 中样本在所有特征上取值相同:
5. 将节点 N 标记为 D 中样本数最多的类别的叶节点;返回 N // 多数表决
6. 从特征集 A 中选择最优分裂特征 a_star // 根据信息增益或基尼指数
7. FOR 特征 a_star 的每一个取值 v:
8. 从节点 N 引出一个分支,对应测试条件 a_star = v
9. 令 D_v 为 D 中满足 a_star = v 的样本子集
10. IF D_v 为空:
11. 将分支末端标记为 D 中样本数最多的类别的叶节点
12. ELSE:
13. 以 构建决策树(D_v, A \ {a_star}) 为分支节点 // 递归调用,并移除已用特征
14. 返回 节点 N例子:决策识别猫:
加权后的熵:
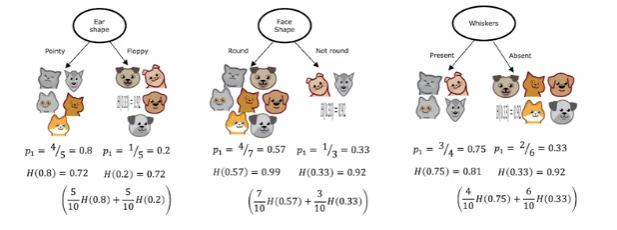
信息增益(相对于上节点):


增益太少:可以选择不分裂。熵为0,不用划分。是否停止,需要判别条件:
避免树无限生长(导致过拟合),必须设定停止递归的条件:
1)节点中的样本全部属于同一类别。2)没有剩余特征可供分裂。3)没有样本满足当前分裂条件(分支为空)。4)达到预设的树最大深度 (max_depth)。5)节点的样本数少于预设的阈值 (min_samples_split)。6)分裂带来的不纯度下降小于预设的阈值 (min_impurity_decrease)。
过拟合:如果不加控制,树会生长得非常复杂,完美拟合训练数据(包括噪声),泛化能力差。
解决方法:剪枝。预剪枝:在树构建过程中,提前停止生长。后剪枝:先构建一棵完整的树,然后自底向上,尝试剪掉一些节点,若验证集精度提升则剪枝。
1.3.1 特征值取多个离散值
多路分散:为特征的每个取值创建一个分支。(不用)
二值分裂:将多个取值组合成两个子集,进行二值分裂。转换成二值分裂问题。(通常做法)
二值分裂:对于有 k个取值的特征,考虑的分裂方式: 2 k − 1 − 1 2^{k-1}-1 2k−1−1种。
解决:
1)增益比代替信息增益,通过引入分裂信息来惩罚取值多的特征。
2)独热编码:
j
import pandas as pd
import numpy as np
# 基础示例
data = pd.DataFrame({'颜色': ['红', '绿', '蓝', '绿', '红']})
print("原始数据:")
print(data)
# 独热编码转换
one_hot_encoded = pd.get_dummies(data, columns=['颜色'])
print("\n独热编码后:")
print(one_hot_encoded)通过以下方式有效解决多值离散特征问题:
消除虚假顺序:避免算法误认为类别之间有数学顺序;
保持特征独立性:每个类别都作为独立的二元特征;
兼容线性模型:让线性算法能够正确处理分类特征;
提高模型性能:在多数情况下比标签编码获得更好效果。
1.3.2 特征值取连续值
考虑临界值,阈值。
对于连续特征,决策树不再是判断"特征=?",而是判断"特征≤阈值?",通过寻找最佳阈值将连续特征二值化。
例子:
j
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 示例:连续特征的最佳分裂
def find_best_split_demo():
"""演示如何在连续特征中寻找最佳分裂点"""
# 创建示例数据
np.random.seed(42)
data = pd.DataFrame({
'年龄': np.concatenate([
np.random.normal(25, 3, 50), # 年轻群体
np.random.normal(45, 5, 50) # 年长群体
]),
'类别': [0]*50 + [1]*50 # 0: 不购买, 1: 购买
})
print("连续特征数据示例:")
print(data.head(10))
# 可视化数据分布
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.hist(data[data['类别'] == 0]['年龄'], alpha=0.7, label='类别 0', bins=15)
plt.hist(data[data['类别'] == 1]['年龄'], alpha=0.7, label='类别 1', bins=15)
plt.xlabel('年龄')
plt.ylabel('频数')
plt.title('连续特征分布')
plt.legend()
return data
demo_data = find_best_split_demo()如何从上往下选择特征:
根据信息增益计算:
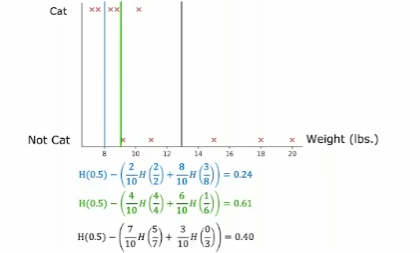
算法:
j
def find_best_split_basic(X, y, criterion='gini'):
"""
在连续特征中寻找最佳分裂点的基本算法
参数:
X: 连续特征值 (一维数组)
y: 目标变量
criterion: 分裂标准 ('gini' 或 'entropy')
返回:
best_threshold: 最佳分裂阈值
best_gain: 最佳信息增益
"""
# 按特征值排序
sorted_indices = np.argsort(X)
X_sorted = X[sorted_indices]
y_sorted = y[sorted_indices]
best_gain = -np.inf
best_threshold = None
# 计算父节点的不纯度
if criterion == 'gini':
parent_impurity = gini_impurity(y)
else: # entropy
parent_impurity = entropy(y)
# 遍历所有可能的分裂点(相邻值的中点)
for i in range(1, len(X_sorted)):
# 避免在相同值之间分裂
if X_sorted[i] == X_sorted[i-1]:
continue
# 计算候选阈值(中点)
threshold = (X_sorted[i] + X_sorted[i-1]) / 2
# 分裂数据集
left_mask = X_sorted <= threshold
right_mask = ~left_mask
y_left = y_sorted[left_mask]
y_right = y_sorted[right_mask]
# 计算加权不纯度
if criterion == 'gini':
left_impurity = gini_impurity(y_left)
right_impurity = gini_impurity(y_right)
else: # entropy
left_impurity = entropy(y_left)
right_impurity = entropy(y_right)
n_left = len(y_left)
n_right = len(y_right)
n_total = len(y_sorted)
weighted_impurity = (n_left / n_total) * left_impurity + (n_right / n_total) * right_impurity
# 计算信息增益
gain = parent_impurity - weighted_impurity
# 更新最佳分裂点
if gain > best_gain:
best_gain = gain
best_threshold = threshold
return best_threshold, best_gain
# 辅助函数:不纯度计算
def gini_impurity(y):
"""计算基尼不纯度"""
if len(y) == 0:
return 0
p1 = np.sum(y) / len(y)
p0 = 1 - p1
return 1 - (p0**2 + p1**2)
def entropy(y):
"""计算信息熵"""
if len(y) == 0:
return 0
p1 = np.sum(y) / len(y)
p0 = 1 - p1
if p0 == 0 or p1 == 0:
return 0
return -p0 * np.log2(p0) - p1 * np.log2(p1)1.4 回归树
回归树是决策树在回归问题上的扩展,用于预测连续值目标变量。与分类树不同,回归树的叶节点输出的是连续数值而不是类别标签。
目的:回归树的核心分裂准则是最小化子节点的加权方差。回归树通常最小化均方误差,等价于方差减少。
计算方差 约等于 计算熵大小

按照决策树的最大信息熵减小原则,减小方差进行回归树的生成。
二、CNN学习实践
2.1 可视化数字训练
本周在前面的训练上,加了可视化分析:
j
import os
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, classification_report, precision_recall_curve, roc_curve, auc
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
import pandas as pd
import json
from torchvision import transforms, datasets
from PIL import Image
import warnings
warnings.filterwarnings('ignore')
# 配置参数
MODEL_PATH = './Models'
SPLIT_DATA_PATH = './split_dataset'
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {DEVICE}")
def load_model_and_data():
"""加载训练好的模型和数据"""
# 加载最佳模型
model_path = os.path.join(MODEL_PATH, 'ImprovedCNN_MNIST_best.pkl')
if not os.path.exists(model_path):
print(f"错误:找不到模型文件 {model_path}")
return None, None, None, None
checkpoint = torch.load(model_path, map_location=DEVICE)
# 加载标签映射
label_mapping = checkpoint['label_mapping']
num_classes = len(label_mapping)
# 创建模型实例
from train import ImprovedCNN # 从训练文件导入模型类
model = ImprovedCNN(num_classes=num_classes).to(DEVICE)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval()
print(f"模型加载成功!验证集准确率: {checkpoint['val_accuracy']:.2f}%")
print(f"类别数量: {num_classes}")
print("标签映射:", label_mapping)
# 加载数据
test_loader = create_test_loader()
return model, test_loader, label_mapping, checkpoint
def create_test_loader(batch_size=512, target_size=(28, 28)):
"""创建测试集数据加载器"""
transform = transforms.Compose([
transforms.Resize(target_size),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
test_dataset = datasets.ImageFolder(
root=os.path.join(SPLIT_DATA_PATH, 'test'),
transform=transform
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False, num_workers=4
)
return test_loader
def plot_training_history():
"""绘制训练历史"""
# 加载训练历史数据
history_path = os.path.join(MODEL_PATH, 'training_history.csv')
if not os.path.exists(history_path):
print("找不到训练历史文件")
return
history = pd.read_csv(history_path)
plt.figure(figsize=(15, 10))
# 1. 损失曲线
plt.subplot(2, 3, 1)
plt.plot(history['epoch'], history['train_loss'], 'b-', label='Training Loss', linewidth=2)
plt.plot(history['epoch'], history['val_loss'], 'r-', label='Validation Loss', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training & Validation Loss')
plt.legend()
plt.grid(True, alpha=0.3)
# 2. 准确率曲线
plt.subplot(2, 3, 2)
plt.plot(history['epoch'], history['train_accuracy'], 'b-', label='Training Accuracy', linewidth=2)
plt.plot(history['epoch'], history['val_accuracy'], 'r-', label='Validation Accuracy', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Training & Validation Accuracy')
plt.legend()
plt.grid(True, alpha=0.3)
# 3. 学习曲线(损失)
plt.subplot(2, 3, 3)
plt.semilogy(history['epoch'], history['train_loss'], 'b-', label='Training Loss', linewidth=2)
plt.semilogy(history['epoch'], history['val_loss'], 'r-', label='Validation Loss', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Loss (log scale)')
plt.title('Learning Curves (Log Scale)')
plt.legend()
plt.grid(True, alpha=0.3)
# 4. 准确率差异
plt.subplot(2, 3, 4)
accuracy_gap = history['train_accuracy'] - history['val_accuracy']
plt.plot(history['epoch'], accuracy_gap, 'g-', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Accuracy Gap (Train - Val)')
plt.title('Generalization Gap')
plt.grid(True, alpha=0.3)
# 5. 损失比率
plt.subplot(2, 3, 5)
loss_ratio = history['val_loss'] / history['train_loss']
plt.plot(history['epoch'], loss_ratio, 'purple', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Loss Ratio (Val / Train)')
plt.title('Overfitting Indicator')
plt.grid(True, alpha=0.3)
# 6. 移动平均准确率
plt.subplot(2, 3, 6)
window = 3
train_smooth = history['train_accuracy'].rolling(window=window, center=True).mean()
val_smooth = history['val_accuracy'].rolling(window=window, center=True).mean()
plt.plot(history['epoch'], train_smooth, 'b-', label='Train (Smooth)', linewidth=2)
plt.plot(history['epoch'], val_smooth, 'r-', label='Val (Smooth)', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Smoothed Accuracy')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(os.path.join(MODEL_PATH, 'training_analysis.png'), dpi=300, bbox_inches='tight')
plt.show()
def evaluate_model_performance(model, test_loader, label_mapping):
"""评估模型性能并生成详细报告"""
model.eval()
all_predictions = []
all_labels = []
all_probabilities = []
with torch.no_grad():
for images, labels in test_loader:
images = images.to(DEVICE)
labels = labels.to(DEVICE)
outputs = model(images)
probabilities = torch.softmax(outputs, dim=1)
_, predicted = torch.max(outputs, 1)
all_predictions.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
all_probabilities.extend(probabilities.cpu().numpy())
# 转换为numpy数组
all_predictions = np.array(all_predictions)
all_labels = np.array(all_labels)
all_probabilities = np.array(all_probabilities)
# 计算准确率
accuracy = np.mean(all_predictions == all_labels) * 100
print(f"测试集准确率: {accuracy:.2f}%")
print(f"测试集样本数: {len(all_labels)}")
return all_predictions, all_labels, all_probabilities, accuracy
def plot_confusion_matrix(all_predictions, all_labels, label_mapping):
"""绘制混淆矩阵"""
# 计算混淆矩阵
cm = confusion_matrix(all_labels, all_predictions)
plt.figure(figsize=(10, 8))
# 使用seaborn绘制热力图
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=label_mapping.values(),
yticklabels=label_mapping.values())
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.xticks(rotation=45)
plt.yticks(rotation=0)
plt.tight_layout()
plt.savefig(os.path.join(MODEL_PATH, 'confusion_matrix.png'), dpi=300, bbox_inches='tight')
plt.show()
return cm
def plot_classification_metrics(all_predictions, all_labels, label_mapping):
"""绘制分类指标"""
# 计算每个类别的准确率
class_accuracy = {}
valid_classes = [] # 只包含有样本的类别
for class_id, class_name in label_mapping.items():
class_mask = all_labels == class_id
if np.sum(class_mask) > 0: # 只处理有样本的类别
class_acc = np.mean(all_predictions[class_mask] == all_labels[class_mask]) * 100
class_accuracy[class_name] = class_acc
valid_classes.append(class_name)
# 如果没有有效的类别,直接返回
if len(valid_classes) == 0:
print("警告:没有找到有效的类别样本")
return {}, {}
# 创建图表
plt.figure(figsize=(12, 8))
# 1. 各类别准确率
plt.subplot(2, 2, 1)
classes = valid_classes
accuracies = [class_accuracy[cls] for cls in classes]
colors = plt.cm.Set3(np.linspace(0, 1, len(classes)))
bars = plt.bar(classes, accuracies, color=colors)
plt.xlabel('Class')
plt.ylabel('Accuracy (%)')
plt.title('Accuracy per Class')
plt.xticks(rotation=45)
# 在柱状图上添加数值
for bar, acc in zip(bars, accuracies):
plt.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 0.5,
f'{acc:.1f}%', ha='center', va='bottom', fontsize=8)
# 2. 准确率分布
plt.subplot(2, 2, 2)
plt.hist(accuracies, bins=10, alpha=0.7, color='skyblue', edgecolor='black')
plt.xlabel('Accuracy (%)')
plt.ylabel('Number of Classes')
plt.title('Accuracy Distribution Across Classes')
if len(accuracies) > 0:
plt.axvline(np.mean(accuracies), color='red', linestyle='--', label=f'Mean: {np.mean(accuracies):.1f}%')
plt.legend()
# 3. 各类别样本数量
plt.subplot(2, 2, 3)
class_counts = {}
for class_id, class_name in label_mapping.items():
count = np.sum(all_labels == class_id)
if count > 0: # 只统计有样本的类别
class_counts[class_name] = count
if class_counts:
plt.bar(class_counts.keys(), class_counts.values(), color='lightgreen', alpha=0.7)
plt.xlabel('Class')
plt.ylabel('Number of Samples')
plt.title('Sample Distribution per Class')
plt.xticks(rotation=45)
# 4. 准确率 vs 样本数量
plt.subplot(2, 2, 4)
sample_counts = [class_counts.get(cls, 0) for cls in classes]
# 只有在有足够数据点时才绘制趋势线
if len(sample_counts) > 1 and len(accuracies) > 1:
plt.scatter(sample_counts, accuracies, s=100, alpha=0.7)
# 添加趋势线
try:
z = np.polyfit(sample_counts, accuracies, 1)
p = np.poly1d(z)
plt.plot(sample_counts, p(sample_counts), "r--", alpha=0.8)
# 添加相关系数
correlation = np.corrcoef(sample_counts, accuracies)[0, 1]
plt.text(0.05, 0.95, f'Correlation: {correlation:.3f}',
transform=plt.gca().transAxes, bbox=dict(boxstyle="round", facecolor='wheat', alpha=0.5))
except:
print("警告:无法计算趋势线,跳过")
else:
plt.scatter(sample_counts, accuracies, s=100, alpha=0.7)
plt.text(0.05, 0.95, "数据点不足,无法计算趋势线",
transform=plt.gca().transAxes, bbox=dict(boxstyle="round", facecolor='wheat', alpha=0.5))
plt.xlabel('Number of Samples')
plt.ylabel('Accuracy (%)')
plt.title('Accuracy vs Sample Count')
plt.tight_layout()
plt.savefig(os.path.join(MODEL_PATH, 'classification_metrics.png'), dpi=300, bbox_inches='tight')
plt.show()
return class_accuracy, class_counts
def plot_error_analysis(all_predictions, all_labels, all_probabilities, label_mapping):
"""绘制误差分析"""
# 计算预测置信度
confidence = np.max(all_probabilities, axis=1)
# 识别错误预测
incorrect_mask = all_predictions != all_labels
correct_mask = all_predictions == all_labels
plt.figure(figsize=(15, 10))
# 1. 置信度分布
plt.subplot(2, 3, 1)
if np.sum(correct_mask) > 0:
plt.hist(confidence[correct_mask], bins=20, alpha=0.7, label='Correct', color='green')
if np.sum(incorrect_mask) > 0:
plt.hist(confidence[incorrect_mask], bins=20, alpha=0.7, label='Incorrect', color='red')
plt.xlabel('Prediction Confidence')
plt.ylabel('Frequency')
plt.title('Confidence Distribution')
plt.legend()
plt.grid(True, alpha=0.3)
# 2. 错误率 vs 置信度
plt.subplot(2, 3, 2)
confidence_bins = np.linspace(0, 1, 11)
error_rates = []
for i in range(len(confidence_bins) - 1):
bin_mask = (confidence >= confidence_bins[i]) & (confidence < confidence_bins[i + 1])
if np.sum(bin_mask) > 0:
error_rate = np.sum(incorrect_mask[bin_mask]) / np.sum(bin_mask) * 100
else:
error_rate = 0
error_rates.append(error_rate)
plt.plot(confidence_bins[:-1] + 0.05, error_rates, 'ro-', linewidth=2)
plt.xlabel('Confidence Bin')
plt.ylabel('Error Rate (%)')
plt.title('Error Rate vs Confidence')
plt.grid(True, alpha=0.3)
# 3. 校准曲线
plt.subplot(2, 3, 3)
from sklearn.calibration import calibration_curve
try:
prob_true, prob_pred = calibration_curve(all_labels == all_predictions, confidence, n_bins=10)
plt.plot(prob_pred, prob_true, 's-', label='Model')
plt.plot([0, 1], [0, 1], '--', color='gray', label='Perfectly calibrated')
plt.xlabel('Mean Predicted Probability')
plt.ylabel('Fraction of Positives')
plt.title('Calibration Plot')
plt.legend()
except:
plt.text(0.5, 0.5, "无法计算校准曲线", ha='center', va='center', transform=plt.gca().transAxes)
plt.title('Calibration Plot (Not Available)')
plt.grid(True, alpha=0.3)
# 4. 各类别错误率
plt.subplot(2, 3, 4)
class_error_rates = {}
for class_id, class_name in label_mapping.items():
class_mask = all_labels == class_id
if np.sum(class_mask) > 0:
error_rate = np.sum(incorrect_mask[class_mask]) / np.sum(class_mask) * 100
class_error_rates[class_name] = error_rate
if class_error_rates:
plt.bar(class_error_rates.keys(), class_error_rates.values(), color='salmon', alpha=0.7)
plt.xlabel('Class')
plt.ylabel('Error Rate (%)')
plt.title('Error Rate per Class')
plt.xticks(rotation=45)
# 5. 混淆矩阵热力图(仅显示错误)
plt.subplot(2, 3, 5)
error_cm = confusion_matrix(all_labels[incorrect_mask], all_predictions[incorrect_mask])
if error_cm.size > 0 and np.sum(error_cm) > 0: # 确保有错误样本
sns.heatmap(error_cm, annot=True, fmt='d', cmap='Reds',
xticklabels=label_mapping.values(),
yticklabels=label_mapping.values())
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix (Errors Only)')
plt.xticks(rotation=45)
plt.yticks(rotation=0)
else:
plt.text(0.5, 0.5, "没有错误样本", ha='center', va='center', transform=plt.gca().transAxes)
plt.title('Confusion Matrix (No Errors)')
# 6. 模型不确定性
plt.subplot(2, 3, 6)
entropy = -np.sum(all_probabilities * np.log(all_probabilities + 1e-8), axis=1)
if np.sum(correct_mask) > 0:
plt.hist(entropy[correct_mask], bins=20, alpha=0.7, label='Correct', color='blue')
if np.sum(incorrect_mask) > 0:
plt.hist(entropy[incorrect_mask], bins=20, alpha=0.7, label='Incorrect', color='orange')
plt.xlabel('Prediction Entropy')
plt.ylabel('Frequency')
plt.title('Uncertainty Analysis')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig(os.path.join(MODEL_PATH, 'error_analysis.png'), dpi=300, bbox_inches='tight')
plt.show()
return class_error_rates
def generate_comprehensive_report(model, test_loader, label_mapping, checkpoint):
"""生成综合报告"""
# 评估模型性能
all_predictions, all_labels, all_probabilities, accuracy = evaluate_model_performance(
model, test_loader, label_mapping)
# 生成各种图表
plot_training_history()
cm = plot_confusion_matrix(all_predictions, all_labels, label_mapping)
class_accuracy, class_counts = plot_classification_metrics(all_predictions, all_labels, label_mapping)
class_error_rates = plot_error_analysis(all_predictions, all_labels, all_probabilities, label_mapping)
# 生成文本报告
report = classification_report(all_labels, all_predictions,
target_names=label_mapping.values(),
output_dict=True)
# 创建综合报告
plt.figure(figsize=(12, 8))
plt.axis('off')
# 准备报告文本
report_text = f"""
模型性能综合分析报告
{'=' * 50}
基本统计信息:
- 测试集准确率: {accuracy:.2f}%
- 验证集最佳准确率: {checkpoint['val_accuracy']:.2f}%
- 类别数量: {len(label_mapping)}
- 测试样本数量: {len(all_labels)}
"""
# 只有在有数据时才添加这些分析
if class_accuracy:
report_text += f"""
准确率分析:
- 最高准确率类别: {max(class_accuracy, key=class_accuracy.get)} ({max(class_accuracy.values()):.1f}%)
- 最低准确率类别: {min(class_accuracy, key=class_accuracy.get)} ({min(class_accuracy.values()):.1f}%)
- 平均类别准确率: {np.mean(list(class_accuracy.values())):.1f}%
"""
if class_error_rates:
report_text += f"""
误差分析:
- 最高错误率类别: {max(class_error_rates, key=class_error_rates.get)} ({max(class_error_rates.values()):.1f}%)
- 平均错误率: {np.mean(list(class_error_rates.values())):.1f}%
"""
if class_counts:
report_text += f"""
样本分布:
- 最大样本类别: {max(class_counts, key=class_counts.get)} ({max(class_counts.values())} 样本)
- 最小样本类别: {min(class_counts, key=class_counts.get)} ({min(class_counts.values())} 样本)
- 样本分布标准差: {np.std(list(class_counts.values())):.1f}
"""
report_text += f"""
模型评估:
- 是否存在过拟合: {'是' if 'train_accuracy' in checkpoint and checkpoint['train_accuracy'] - checkpoint['val_accuracy'] > 10 else '否'}
- 预测置信度: {np.mean(np.max(all_probabilities, axis=1)):.3f}
建议:
"""
# 根据分析结果给出建议
if accuracy < 80:
report_text += "- 模型性能有待提升,建议增加训练数据或调整模型架构\n"
elif accuracy >= 95:
report_text += "- 模型性能优秀,可以考虑部署使用\n"
else:
report_text += "- 模型性能良好,可以进一步优化提升\n"
if class_accuracy and np.std(list(class_accuracy.values())) > 15:
report_text += "- 类别间性能差异较大,建议检查数据平衡性\n"
if class_error_rates and max(class_error_rates.values()) > 30:
report_text += f"- 类别 '{max(class_error_rates, key=class_error_rates.get)}' 错误率较高,需要重点关注\n"
plt.text(0.05, 0.95, report_text, fontsize=10, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.8))
plt.tight_layout()
plt.savefig(os.path.join(MODEL_PATH, 'comprehensive_report.png'), dpi=300, bbox_inches='tight')
plt.show()
# 保存详细报告到文件
detailed_report = {
'overall_accuracy': accuracy,
'best_val_accuracy': checkpoint['val_accuracy'],
'class_accuracy': class_accuracy,
'class_error_rates': class_error_rates,
'class_counts': class_counts,
'confusion_matrix': cm.tolist() if 'cm' in locals() else [],
'classification_report': report
}
with open(os.path.join(MODEL_PATH, 'detailed_report.json'), 'w') as f:
json.dump(detailed_report, f, indent=2)
print(f"详细报告已保存到: {os.path.join(MODEL_PATH, 'detailed_report.json')}")
def main():
"""主函数"""
print("=" * 60)
print("模型可视化分析")
print("=" * 60)
# 加载模型和数据
model, test_loader, label_mapping, checkpoint = load_model_and_data()
if model is None:
print("无法加载模型,请确保模型文件存在")
return
# 生成综合报告
generate_comprehensive_report(model, test_loader, label_mapping, checkpoint)
print("\n" + "=" * 60)
print("分析完成!")
print("=" * 60)
print("生成的文件:")
print(f"- 训练分析图: {os.path.join(MODEL_PATH, 'training_analysis.png')}")
print(f"- 混淆矩阵: {os.path.join(MODEL_PATH, 'confusion_matrix.png')}")
print(f"- 分类指标: {os.path.join(MODEL_PATH, 'classification_metrics.png')}")
print(f"- 误差分析: {os.path.join(MODEL_PATH, 'error_analysis.png')}")
print(f"- 综合报告: {os.path.join(MODEL_PATH, 'comprehensive_report.png')}")
print(f"- 详细报告: {os.path.join(MODEL_PATH, 'detailed_report.json')}")
if __name__ == "__main__":
main()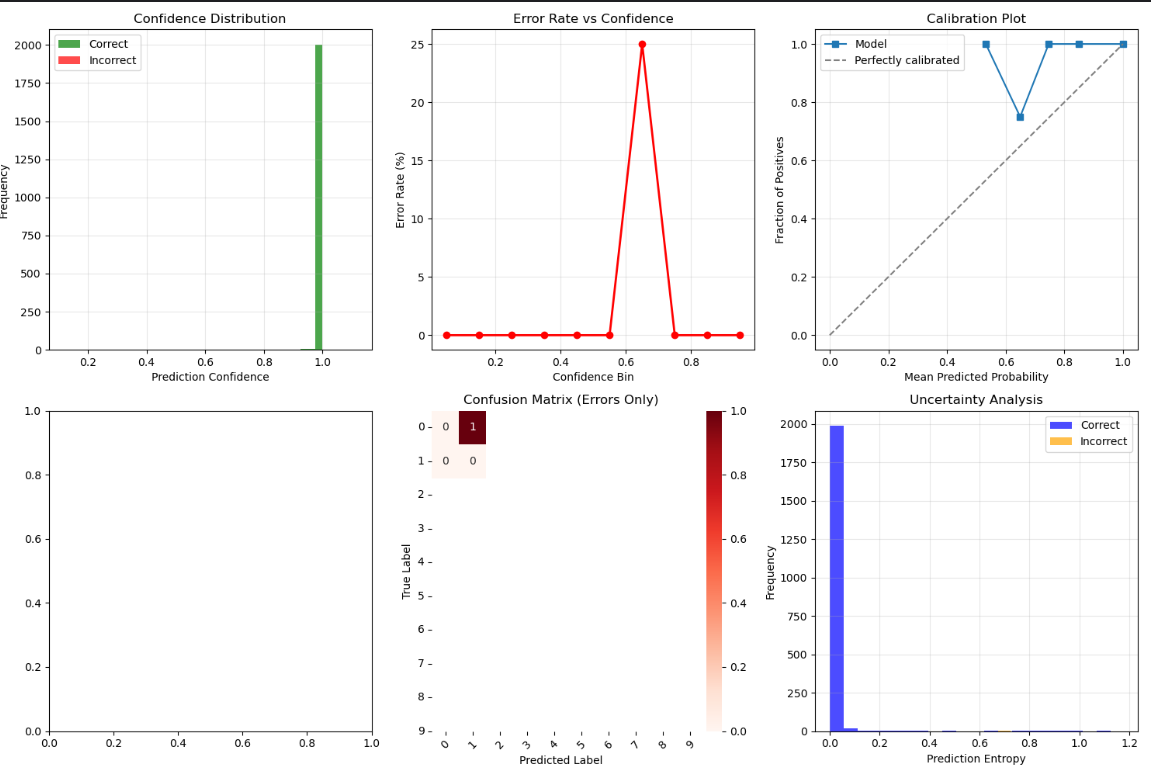
置信度与校准分析:模型预测可靠性高;
高置信度:正确预测集中在置信度1.0附近;
低错误率:错误预测频率几乎为0;
校准良好:实际校准曲线接近理想对角线。
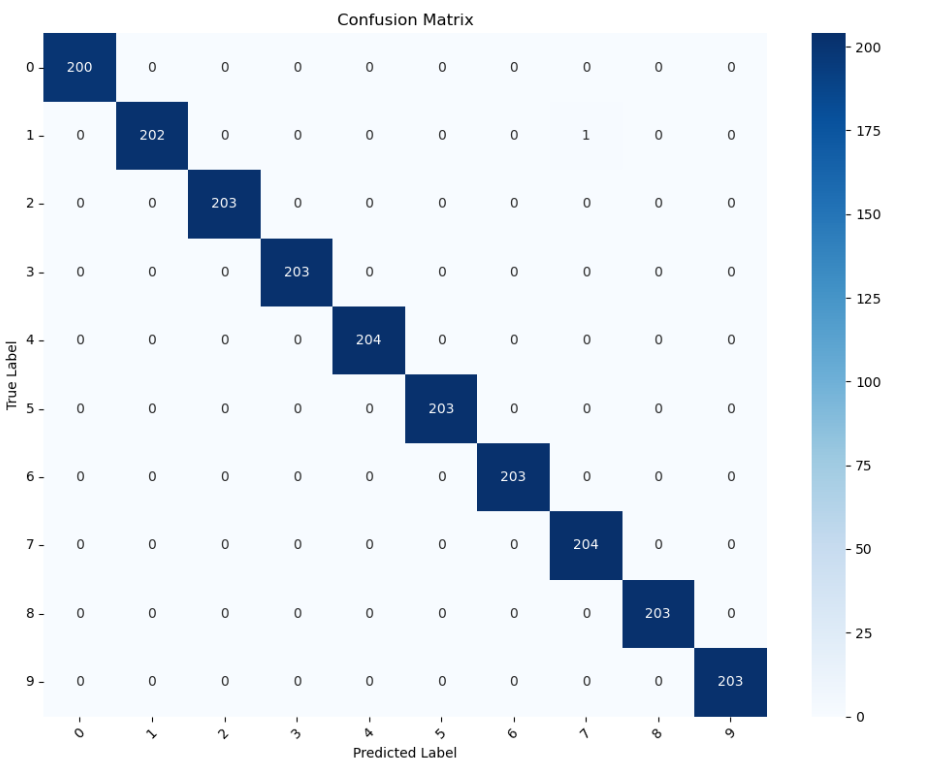
混淆矩阵分析:分类性能优秀,错误率极低;
对角线元素值高(约200),表明各类别分类准确;
非对角线元素接近0,说明类别间混淆极少;
模型在0-9数字识别上表现均衡,无明显类别偏好。
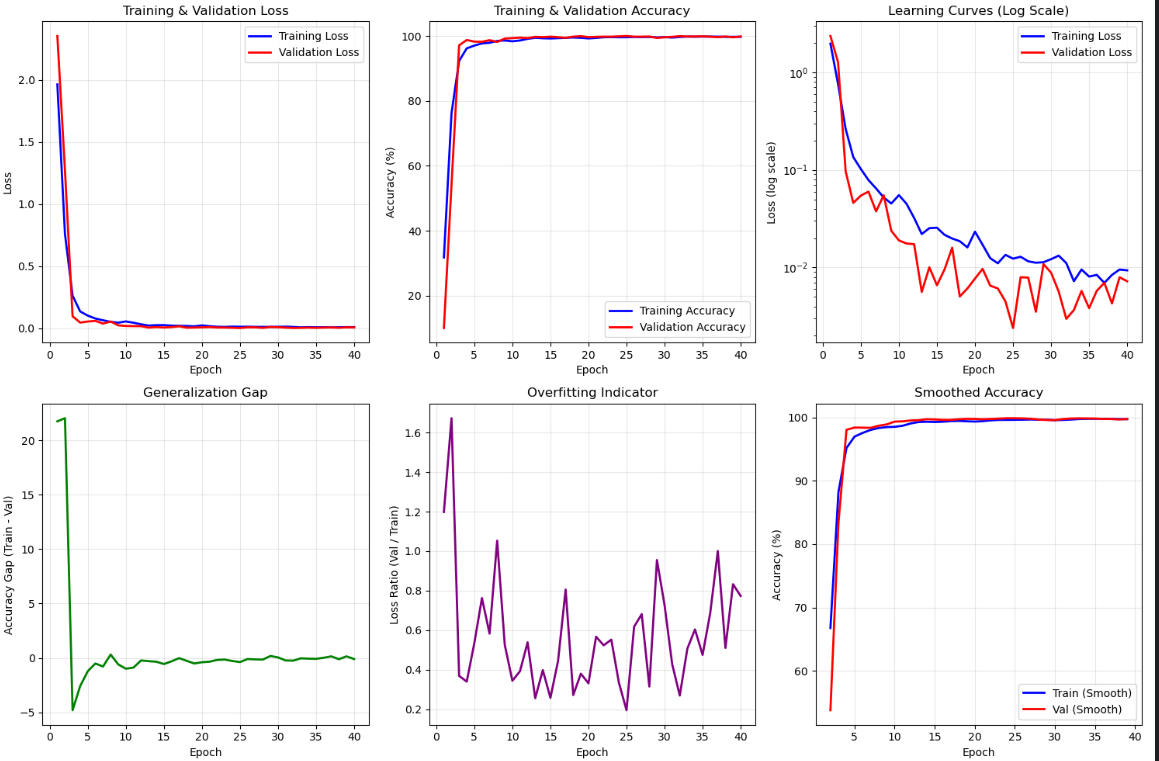
训练过程分析:模型表现优异,收敛良好;
训练稳定性:训练和验证损失同步快速下降,表明模型学习效率高;
收敛效果:40个epoch内准确率从60%迅速提升至接近100%,收敛速度快;
泛化能力:训练与验证准确率曲线接近,差距小,说明模型泛化能力强;
过拟合控制:过拟合指标后期稳定,无明显过拟合迹象。
2.2 增加字母数据
加入字母的识别与训练,数据较大:
j
import os
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms, datasets
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import shutil
import json
from sklearn.model_selection import train_test_split
from collections import Counter
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
# 配置参数
DATA_PATH = './DataSets'
SPLIT_DATA_PATH = './split_dataset'
MODEL_PATH = './Models'
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
BATCH_SIZE = 512
EPOCH = 40
print(f"Using device: {DEVICE}")
def organize_alphabet_dataset():
"""
重新组织字母数据集,将Sample011-062重命名为对应的字母A-Z和a-z
"""
print("=" * 50)
print("字母数据集重组")
print("=" * 50)
# 字母映射表:Sample011 -> A, Sample012 -> B, ..., Sample036 -> Z, Sample037 -> a, ..., Sample062 -> z
alphabet_mapping = {}
# 大写字母 A-Z (Sample011-Sample036)
for i in range(26):
sample_num = f"Sample{str(11 + i).zfill(3)}" # Sample011, Sample012, ..., Sample036
uppercase_letter = chr(65 + i) # A, B, C, ..., Z
alphabet_mapping[sample_num] = uppercase_letter
# 小写字母 a-z (Sample037-Sample062)
for i in range(26):
sample_num = f"Sample{str(37 + i).zfill(3)}" # Sample037, Sample038, ..., Sample062
lowercase_letter = chr(97 + i) # a, b, c, ..., z
alphabet_mapping[sample_num] = lowercase_letter
print("字母映射关系:")
for sample, letter in alphabet_mapping.items():
print(f" {sample} -> {letter}")
# 检查并重命名文件夹
renamed_count = 0
for sample_folder, letter in alphabet_mapping.items():
sample_path = os.path.join(DATA_PATH, sample_folder)
letter_path = os.path.join(DATA_PATH, letter)
if os.path.exists(sample_path):
if not os.path.exists(letter_path):
os.rename(sample_path, letter_path)
print(f"重命名: {sample_folder} -> {letter}")
renamed_count += 1
else:
print(f"目标文件夹已存在: {letter}, 跳过重命名")
else:
print(f"源文件夹不存在: {sample_folder}")
print(f"成功重命名 {renamed_count} 个文件夹")
return alphabet_mapping
def get_all_classes():
"""
获取所有类别(数字0-9 + 大写字母A-Z + 小写字母a-z)
"""
# 数字类别
digit_classes = [str(i) for i in range(10)]
# 大写字母类别
uppercase_classes = [chr(i) for i in range(65, 91)] # A-Z
# 小写字母类别
lowercase_classes = [chr(i) for i in range(97, 123)] # a-z
all_classes = digit_classes + uppercase_classes + lowercase_classes
print(f"总类别数: {len(all_classes)}")
print(f"数字类别 (10个): {digit_classes}")
print(f"大写字母类别 (26个): {uppercase_classes}")
print(f"小写字母类别 (26个): {lowercase_classes}")
return all_classes
def split_image_dataset(input_dir, output_dir, test_size=0.2, val_size=0.2, random_state=42):
"""将多类别图像数据集划分为训练集、验证集和测试集"""
# 首先重组字母数据集
organize_alphabet_dataset()
# 获取所有类别
class_names = get_all_classes()
print(f"发现 {len(class_names)} 个类别: {class_names}")
# 创建标签映射字典
label_to_name = {i: name for i, name in enumerate(class_names)}
name_to_label = {name: i for i, name in enumerate(class_names)}
print("标签映射:")
for label, name in label_to_name.items():
print(f" 标签 {label} -> 类别 '{name}'")
# 收集所有图像路径和对应的标签
image_paths = []
labels = []
class_counts = {}
for class_name in class_names:
class_dir = os.path.join(input_dir, class_name)
if os.path.exists(class_dir):
# 获取该类别下所有图像文件
image_files = [f for f in os.listdir(class_dir)
if f.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.tiff'))]
# 记录每个类别的数量
class_counts[class_name] = len(image_files)
# 添加路径和标签
for image_file in image_files:
image_paths.append(os.path.join(class_dir, image_file))
labels.append(name_to_label[class_name])
print(f"\n总图像数量: {len(image_paths)}")
print("各类别分布:")
for class_name, count in class_counts.items():
print(f" {class_name}: {count} 张图像")
# 转换为numpy数组
X = np.array(image_paths)
y = np.array(labels)
# 划分数据集
X_temp, X_test, y_temp, y_test = train_test_split(
X, y, test_size=test_size, random_state=random_state, stratify=y
)
# 计算验证集比例(相对于剩余数据的比例)
val_ratio = val_size / (1 - test_size)
X_train, X_val, y_train, y_val = train_test_split(
X_temp, y_temp, test_size=val_ratio, random_state=random_state, stratify=y_temp
)
print(f"\n划分结果:")
print(f"训练集: {len(X_train)} 样本 ({len(X_train) / len(X):.1%})")
print(f"验证集: {len(X_val)} 样本 ({len(X_val) / len(X):.1%})")
print(f"测试集: {len(X_test)} 样本 ({len(X_test) / len(X):.1%})")
# 创建划分后的目录结构
splits = ['train', 'val', 'test']
for split in splits:
for class_name in class_names:
os.makedirs(os.path.join(output_dir, split, class_name), exist_ok=True)
print(f"\n已在 {output_dir} 中创建目录结构")
# 复制文件到相应的划分目录
splits_data = {
'train': (X_train, y_train),
'val': (X_val, y_val),
'test': (X_test, y_test)
}
for split_name, (X_split, y_split) in splits_data.items():
print(f"正在复制 {split_name} 集文件...")
for img_path, label in zip(X_split, y_split):
class_name = label_to_name[label]
filename = os.path.basename(img_path)
dest_path = os.path.join(output_dir, split_name, class_name, filename)
# 复制文件
shutil.copy2(img_path, dest_path)
print("文件复制完成!")
# 保存标签映射信息
label_json_path = os.path.join(output_dir, 'label_mapping.json')
with open(label_json_path, 'w') as f:
json.dump(label_to_name, f, indent=2)
print(f"标签映射已保存到: {label_json_path}")
return label_to_name
# 改进的卷积神经网络(支持62个类别)
class ImprovedCNN(nn.Module):
def __init__(self, num_classes=62): # 修改为62个类别(10个数字 + 26个大写字母 + 26个小写字母)
super(ImprovedCNN, self).__init__()
# 第一个卷积块
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 32, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(32)
# 第二个卷积块
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(64)
self.conv4 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(64)
# 第三个卷积块
self.conv5 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn5 = nn.BatchNorm2d(128)
# 全连接层(增加神经元数量以适应更多类别)
self.fc1 = nn.Linear(128 * 3 * 3, 512) # 增加神经元数量
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(512, 256) # 增加神经元数量
self.dropout2 = nn.Dropout(0.3)
self.fc3 = nn.Linear(256, num_classes)
def forward(self, x):
# 第一个卷积块: 28x28 -> 14x14
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.max_pool2d(x, 2)
# 第二个卷积块: 14x14 -> 7x7
x = F.relu(self.bn3(self.conv3(x)))
x = F.relu(self.bn4(self.conv4(x)))
x = F.max_pool2d(x, 2)
# 第三个卷积块: 7x7 -> 3x3
x = F.relu(self.bn5(self.conv5(x)))
x = F.max_pool2d(x, 2)
# 展平
x = x.view(x.size(0), -1)
# 全连接层
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = F.relu(self.fc2(x))
x = self.dropout2(x)
x = self.fc3(x)
return x
def create_data_loaders(data_path, batch_size=512, target_size=(28, 28)):
"""创建数据加载器"""
# 数据转换
train_transform = transforms.Compose([
transforms.Resize(target_size),
transforms.Grayscale(num_output_channels=1),
transforms.RandomRotation(10),
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)),
transforms.RandomPerspective(distortion_scale=0.1, p=0.3),
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
val_transform = transforms.Compose([
transforms.Resize(target_size),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载数据集
train_dataset = datasets.ImageFolder(
root=os.path.join(data_path, 'train'),
transform=train_transform
)
val_dataset = datasets.ImageFolder(
root=os.path.join(data_path, 'val'),
transform=val_transform
)
test_dataset = datasets.ImageFolder(
root=os.path.join(data_path, 'test'),
transform=val_transform
)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True, num_workers=4
)
val_loader = torch.utils.data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=False, num_workers=4
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False, num_workers=4
)
return train_loader, val_loader, test_loader, train_dataset.class_to_idx
def calculate_bias_variance(model, data_loader, num_classes, device):
"""计算模型的偏差和方差"""
model.eval()
all_predictions = []
all_targets = []
with torch.no_grad():
for images, labels in data_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
probabilities = F.softmax(outputs, dim=1)
all_predictions.append(probabilities.cpu().numpy())
all_targets.append(labels.cpu().numpy())
all_predictions = np.vstack(all_predictions)
all_targets = np.hstack(all_targets)
predicted_classes = np.argmax(all_predictions, axis=1)
bias = np.mean(predicted_classes != all_targets)
variance = np.var(all_predictions, axis=1).mean()
return bias, variance, all_predictions, all_targets
def plot_bias_variance_analysis(train_losses, val_losses, train_accuracies, val_accuracies,
test_predictions, test_targets, num_classes, label_mapping):
"""绘制偏差-方差分析图表"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
# 1. 训练和验证损失曲线
axes[0, 0].plot(train_losses, 'b-', label='Training Loss', linewidth=2)
axes[0, 0].plot(val_losses, 'r-', label='Validation Loss', linewidth=2)
axes[0, 0].set_xlabel('Epoch')
axes[0, 0].set_ylabel('Loss')
axes[0, 0].set_title('Training vs Validation Loss')
axes[0, 0].legend()
axes[0, 0].grid(True, alpha=0.3)
# 2. 训练和验证准确率曲线
axes[0, 1].plot(train_accuracies, 'b-', label='Training Accuracy', linewidth=2)
axes[0, 1].plot(val_accuracies, 'r-', label='Validation Accuracy', linewidth=2)
axes[0, 1].set_xlabel('Epoch')
axes[0, 1].set_ylabel('Accuracy (%)')
axes[0, 1].set_title('Training vs Validation Accuracy')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# 3. 偏差-方差权衡图
generalization_gap = [val_loss - train_loss for train_loss, val_loss in zip(train_losses, val_losses)]
accuracy_gap = [train_acc - val_acc for train_acc, val_acc in zip(train_accuracies, val_accuracies)]
axes[0, 2].plot(generalization_gap, 'g-', label='Loss Gap (Val - Train)', linewidth=2)
axes[0, 2].set_xlabel('Epoch')
axes[0, 2].set_ylabel('Loss Gap', color='g')
axes[0, 2].tick_params(axis='y', labelcolor='g')
axes[0, 2].grid(True, alpha=0.3)
ax2 = axes[0, 2].twinx()
ax2.plot(accuracy_gap, 'purple', label='Accuracy Gap (Train - Val)', linewidth=2)
ax2.set_ylabel('Accuracy Gap (%)', color='purple')
ax2.tick_params(axis='y', labelcolor='purple')
lines1, labels1 = axes[0, 2].get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
axes[0, 2].legend(lines1 + lines2, labels1 + labels2, loc='upper right')
axes[0, 2].set_title('Generalization Gap (Bias-Variance Tradeoff)')
# 4. 预测置信度分布
test_confidences = np.max(test_predictions, axis=1)
axes[1, 0].hist(test_confidences, bins=50, alpha=0.7, color='skyblue', edgecolor='black')
axes[1, 0].set_xlabel('Prediction Confidence')
axes[1, 0].set_ylabel('Frequency')
axes[1, 0].set_title('Distribution of Prediction Confidences')
axes[1, 0].axvline(x=0.5, color='red', linestyle='--', label='50% Confidence')
axes[1, 0].legend()
axes[1, 0].grid(True, alpha=0.3)
# 5. 各类别准确率分析
predicted_classes = np.argmax(test_predictions, axis=1)
class_accuracy = []
class_names = [label_mapping[i] for i in range(num_classes)]
for class_idx in range(num_classes):
class_mask = test_targets == class_idx
if np.sum(class_mask) > 0:
accuracy = np.mean(predicted_classes[class_mask] == test_targets[class_mask])
class_accuracy.append(accuracy)
else:
class_accuracy.append(0)
bars = axes[1, 1].bar(range(num_classes), class_accuracy, color='lightgreen', alpha=0.7)
axes[1, 1].set_xlabel('Class')
axes[1, 1].set_ylabel('Accuracy')
axes[1, 1].set_title('Per-Class Accuracy')
axes[1, 1].set_xticks(range(num_classes))
axes[1, 1].set_xticklabels(class_names, rotation=45)
axes[1, 1].grid(True, alpha=0.3)
# 在柱状图上添加数值标签
for bar, acc in zip(bars, class_accuracy):
height = bar.get_height()
axes[1, 1].text(bar.get_x() + bar.get_width() / 2., height,
f'{acc:.2f}', ha='center', va='bottom')
# 6. 混淆矩阵热力图(只显示前20个类别,避免过于拥挤)
cm = confusion_matrix(test_targets, predicted_classes)
# 如果类别太多,只显示前20个
display_classes = min(20, num_classes)
im = axes[1, 2].imshow(cm[:display_classes, :display_classes], interpolation='nearest', cmap=plt.cm.Blues)
axes[1, 2].set_title('Confusion Matrix (First 20 Classes)')
axes[1, 2].set_xlabel('Predicted Label')
axes[1, 2].set_ylabel('True Label')
axes[1, 2].set_xticks(range(display_classes))
axes[1, 2].set_yticks(range(display_classes))
axes[1, 2].set_xticklabels(class_names[:display_classes], rotation=45)
axes[1, 2].set_yticklabels(class_names[:display_classes])
thresh = cm[:display_classes, :display_classes].max() / 2.
for i in range(display_classes):
for j in range(display_classes):
axes[1, 2].text(j, i, format(cm[i, j], 'd'),
ha="center", va="center",
color="white" if cm[i, j] > thresh else "black")
plt.colorbar(im, ax=axes[1, 2])
plt.tight_layout()
plt.savefig(os.path.join(MODEL_PATH, 'bias_variance_analysis.png'), dpi=300, bbox_inches='tight')
plt.show()
return fig
def generate_detailed_analysis_report(model, test_loader, label_mapping, device):
"""生成详细的偏差-方差分析报告"""
bias, variance, test_predictions, test_targets = calculate_bias_variance(
model, test_loader, len(label_mapping), device
)
predicted_classes = np.argmax(test_predictions, axis=1)
class_report = classification_report(test_targets, predicted_classes,
target_names=[label_mapping[i] for i in range(len(label_mapping))],
output_dict=True)
report = {
'bias': bias,
'variance': variance,
'bias_variance_tradeoff': bias + variance,
'overfitting_indicator': variance / (bias + 1e-8),
'average_confidence': np.max(test_predictions, axis=1).mean(),
'classification_report': class_report,
'test_predictions': test_predictions,
'test_targets': test_targets
}
print("\n" + "=" * 60)
print("偏差-方差分析报告")
print("=" * 60)
print(f"偏差 (Bias): {bias:.4f} (越低越好)")
print(f"方差 (Variance): {variance:.4f} (适中为好)")
print(f"偏差-方差权衡: {bias + variance:.4f} (越低越好)")
print(f"过拟合指标: {report['overfitting_indicator']:.4f} (>1可能表示过拟合)")
print(f"平均预测置信度: {report['average_confidence']:.4f}")
print("\n诊断建议:")
if bias > 0.3:
print("✓ 高偏差检测: 模型可能欠拟合,考虑:")
print(" - 增加模型复杂度")
print(" - 增加训练轮数")
print(" - 减少正则化")
elif variance > 0.1 and report['overfitting_indicator'] > 1:
print("✓ 高方差检测: 模型可能过拟合,考虑:")
print(" - 增加正则化(Dropout, L2)")
print(" - 使用更多训练数据")
print(" - 数据增强")
print(" - 早停")
else:
print("✓ 偏差-方差平衡良好")
return report
def train_model():
"""训练模型的主函数(包含偏差-方差分析)"""
print("=" * 50)
print("第一步:数据划分")
print("=" * 50)
if not os.path.exists(SPLIT_DATA_PATH) or len(os.listdir(SPLIT_DATA_PATH)) == 0:
print("执行数据划分...")
label_mapping = split_image_dataset(
input_dir=DATA_PATH,
output_dir=SPLIT_DATA_PATH,
test_size=0.2,
val_size=0.2,
random_state=42
)
else:
print("使用已划分的数据集...")
with open(os.path.join(SPLIT_DATA_PATH, 'label_mapping.json'), 'r') as f:
label_mapping = json.load(f)
label_mapping = {int(k): v for k, v in label_mapping.items()}
print(f"总类别数: {len(label_mapping)}")
print(f"标签映射: {label_mapping}")
print("\n" + "=" * 50)
print("第二步:创建数据加载器")
print("=" * 50)
train_loader, val_loader, test_loader, class_to_idx = create_data_loaders(
SPLIT_DATA_PATH, BATCH_SIZE
)
print(f"训练集: {len(train_loader.dataset)} 样本")
print(f"验证集: {len(val_loader.dataset)} 样本")
print(f"测试集: {len(test_loader.dataset)} 样本")
print(f"批次数量: {len(train_loader)}")
print("\n" + "=" * 50)
print("第三步:模型训练")
print("=" * 50)
# 创建模型实例(62个类别)
model = ImprovedCNN(num_classes=len(label_mapping)).to(DEVICE)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
print('\n-----------------\n'
'Num of epoch: {}\n'
'Batch size: {}\n'
'Num of batch: {}\n'
'Target image size: 28x28\n'
'Num classes: {}\n'
'Model: Improved CNN'.format(
EPOCH, BATCH_SIZE, len(train_loader), len(label_mapping)))
print('-----------------\n')
print('Start training...')
# 训练循环
train_losses = []
train_accuracies = []
val_losses = []
val_accuracies = []
batch_losses = []
best_val_acc = 0.0
# 设置matplotlib实时更新
plt.ion()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
for epoch in range(EPOCH):
print(f'Epoch {epoch + 1}/{EPOCH}')
model.train()
running_loss = 0.0
running_correct = 0
total_samples = 0
for batch_idx, (images, labels) in enumerate(train_loader):
images = images.to(DEVICE)
labels = labels.to(DEVICE)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 统计信息
running_loss += loss.item() * images.size(0)
_, predicted = torch.max(outputs.data, 1)
running_correct += (predicted == labels).sum().item()
total_samples += images.size(0)
batch_losses.append(loss.item())
# 打印batch信息
if (batch_idx + 1) % 10 == 0:
batch_accuracy = 100 * (predicted == labels).sum().item() / images.size(0)
print(
f'Batch {batch_idx + 1}/{len(train_loader)}, Loss: {loss.item():.6f}, Accuracy: {batch_accuracy:.2f}%')
# 验证集评估
model.eval()
val_running_loss = 0.0
val_running_correct = 0
val_total_samples = 0
with torch.no_grad():
for images, labels in val_loader:
images = images.to(DEVICE)
labels = labels.to(DEVICE)
outputs = model(images)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
val_running_loss += loss.item() * images.size(0)
val_running_correct += (predicted == labels).sum().item()
val_total_samples += images.size(0)
# 更新学习率
scheduler.step()
# 计算统计信息
epoch_loss = running_loss / total_samples
epoch_accuracy = 100 * running_correct / total_samples
val_epoch_loss = val_running_loss / val_total_samples
val_epoch_accuracy = 100 * val_running_correct / val_total_samples
train_losses.append(epoch_loss)
train_accuracies.append(epoch_accuracy)
val_losses.append(val_epoch_loss)
val_accuracies.append(val_epoch_accuracy)
print(f'Epoch {epoch + 1}: Train Loss: {epoch_loss:.6f}, Train Acc: {epoch_accuracy:.2f}%, '
f'Val Loss: {val_epoch_loss:.6f}, Val Acc: {val_epoch_accuracy:.2f}%, '
f'LR: {scheduler.get_last_lr()[0]:.6f}\n')
# 实时更新图表
if len(train_losses) > 1:
ax1.clear()
ax1.plot(train_losses, 'r-', label='Train Loss', linewidth=2)
ax1.plot(val_losses, 'r--', label='Val Loss', linewidth=2)
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss', color='r')
ax1.tick_params(axis='y', labelcolor='r')
ax1.grid(True, alpha=0.3)
ax1.legend()
ax2.clear()
ax2.plot(train_accuracies, 'g-', label='Train Acc', linewidth=2)
ax2.plot(val_accuracies, 'g--', label='Val Acc', linewidth=2)
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy (%)', color='g')
ax2.tick_params(axis='y', labelcolor='g')
ax2.grid(True, alpha=0.3)
ax2.legend()
ax1.set_title('Training & Validation Loss')
ax2.set_title('Training & Validation Accuracy')
plt.tight_layout()
plt.pause(0.01)
# 保存最佳模型
if val_epoch_accuracy > best_val_acc:
best_val_acc = val_epoch_accuracy
best_model_path = os.path.join(MODEL_PATH, 'ImprovedCNN_Alphanumeric_best.pkl')
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'val_accuracy': best_val_acc,
'val_loss': val_epoch_loss,
'label_mapping': label_mapping
}, best_model_path)
print(f'保存最佳模型,验证集准确率: {best_val_acc:.2f}%')
print("\n" + "=" * 50)
print("第四步:测试集评估")
print("=" * 50)
model.eval()
test_running_loss = 0.0
test_running_correct = 0
test_total_samples = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(DEVICE)
labels = labels.to(DEVICE)
outputs = model(images)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
test_running_loss += loss.item() * images.size(0)
test_running_correct += (predicted == labels).sum().item()
test_total_samples += images.size(0)
test_loss = test_running_loss / test_total_samples
test_accuracy = 100 * test_running_correct / test_total_samples
print(f'测试集结果: Loss: {test_loss:.6f}, Accuracy: {test_accuracy:.2f}%')
print("\n" + "=" * 50)
print("第五步:偏差-方差分析")
print("=" * 50)
# 加载最佳模型进行详细分析
best_model_path = os.path.join(MODEL_PATH, 'ImprovedCNN_Alphanumeric_best.pkl')
checkpoint = torch.load(best_model_path)
model.load_state_dict(checkpoint['model_state_dict'])
analysis_report = generate_detailed_analysis_report(
model, test_loader, label_mapping, DEVICE
)
plot_bias_variance_analysis(
train_losses, val_losses, train_accuracies, val_accuracies,
analysis_report['test_predictions'], analysis_report['test_targets'],
len(label_mapping), label_mapping
)
# 保存最终模型
print('Saving the final model...')
final_model_path = os.path.join(MODEL_PATH, 'ImprovedCNN_Alphanumeric_final.pkl')
torch.save({
'epoch': EPOCH,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'train_accuracy': train_accuracies[-1],
'val_accuracy': val_accuracies[-1],
'test_accuracy': test_accuracy,
'train_loss': train_losses[-1],
'val_loss': val_losses[-1],
'test_loss': test_loss,
'train_losses': train_losses,
'train_accuracies': train_accuracies,
'val_losses': val_losses,
'val_accuracies': val_accuracies,
'batch_losses': batch_losses,
'label_mapping': label_mapping
}, final_model_path)
# 保存分析报告
report_path = os.path.join(MODEL_PATH, 'bias_variance_report.json')
serializable_report = {
'bias': float(analysis_report['bias']),
'variance': float(analysis_report['variance']),
'bias_variance_tradeoff': float(analysis_report['bias_variance_tradeoff']),
'overfitting_indicator': float(analysis_report['overfitting_indicator']),
'average_confidence': float(analysis_report['average_confidence']),
'classification_report': analysis_report['classification_report']
}
with open(report_path, 'w') as f:
json.dump(serializable_report, f, indent=2)
print(f"偏差-方差分析报告已保存到: {report_path}")
# 关闭交互模式
plt.ioff()
# 生成最终图表
generate_final_plots(train_losses, train_accuracies, val_losses, val_accuracies,
batch_losses, EPOCH, BATCH_SIZE, DEVICE, best_val_acc, test_accuracy,
analysis_report)
print('Training completed!')
print(f'最佳验证集准确率: {best_val_acc:.2f}%')
print(f'最终测试集准确率: {test_accuracy:.2f}%')
return model, test_accuracy, analysis_report
def generate_final_plots(train_losses, train_accuracies, val_losses, val_accuracies,
batch_losses, epochs, batch_size, device, best_val_acc, test_acc,
analysis_report=None):
"""生成最终训练结果图表(集成偏差-方差分析)"""
# 创建最终的可视化图表
plt.figure(figsize=(18, 12))
# 1. 训练和验证损失
plt.subplot(2, 3, 1)
plt.plot(train_losses, 'r-', label='Training Loss', linewidth=2)
plt.plot(val_losses, 'r--', label='Validation Loss', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training & Validation Loss')
plt.grid(True, alpha=0.3)
plt.legend()
# 2. 训练和验证准确率
plt.subplot(2, 3, 2)
plt.plot(train_accuracies, 'g-', label='Training Accuracy', linewidth=2)
plt.plot(val_accuracies, 'g--', label='Validation Accuracy', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Training & Validation Accuracy')
plt.grid(True, alpha=0.3)
plt.legend()
# 3. 双Y轴图表
plt.subplot(2, 3, 3)
ax1 = plt.gca()
ax1.plot(train_losses, 'r-', label='Train Loss', linewidth=2)
ax1.plot(val_losses, 'r--', label='Val Loss', linewidth=2)
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss', color='r')
ax1.tick_params(axis='y', labelcolor='r')
ax1.grid(True, alpha=0.3)
ax2 = ax1.twinx()
ax2.plot(train_accuracies, 'g-', label='Train Acc', linewidth=2)
ax2.plot(val_accuracies, 'g--', label='Val Acc', linewidth=2)
ax2.set_ylabel('Accuracy (%)', color='g')
ax2.tick_params(axis='y', labelcolor='g')
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc='center right')
plt.title('Training & Validation Metrics')
# 4. Batch损失
plt.subplot(2, 3, 4)
# 平滑处理batch损失
if len(batch_losses) > 100:
smooth_loss = np.convolve(batch_losses, np.ones(100) / 100, mode='valid')
plt.plot(smooth_loss, 'b-', alpha=0.7, linewidth=1, label='Smoothed Batch Loss')
else:
plt.plot(batch_losses, 'b-', alpha=0.7, linewidth=1, label='Batch Loss')
plt.xlabel('Batch')
plt.ylabel('Loss')
plt.title('Batch Loss (Smoothed)')
plt.grid(True, alpha=0.3)
plt.legend()
# 5. 学习率变化
plt.subplot(2, 3, 5)
learning_rates = [0.001 * (0.5 ** (i // 10)) for i in range(epochs)]
plt.plot(learning_rates, 'purple', linewidth=2)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Schedule')
plt.grid(True, alpha=0.3)
# 6. 训练总结(包含偏差-方差分析)
plt.subplot(2, 3, 6)
plt.axis('off')
if analysis_report is not None:
summary_text = f"""
Training Summary:
- Epochs: {epochs}
- Batch Size: {batch_size}
- Device: {device}
- Best Val Accuracy: {best_val_acc:.2f}%
- Test Accuracy: {test_acc:.2f}%
- Final Train Loss: {train_losses[-1]:.6f}
- Final Val Loss: {val_losses[-1]:.6f}
Bias-Variance Analysis:
- Bias: {analysis_report['bias']:.4f}
- Variance: {analysis_report['variance']:.4f}
- Bias-Variance Tradeoff: {analysis_report['bias_variance_tradeoff']:.4f}
- Overfitting Indicator: {analysis_report['overfitting_indicator']:.4f}
"""
else:
summary_text = f"""
Training Summary:
- Epochs: {epochs}
- Batch Size: {batch_size}
- Device: {device}
- Best Val Accuracy: {best_val_acc:.2f}%
- Test Accuracy: {test_acc:.2f}%
- Final Train Loss: {train_losses[-1]:.6f}
- Final Val Loss: {val_losses[-1]:.6f}
"""
plt.text(0.1, 0.9, summary_text, fontsize=10, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
plt.tight_layout()
plt.savefig(os.path.join(MODEL_PATH, 'training_visualization.png'), dpi=300, bbox_inches='tight')
plt.show()
# 保存训练数据为CSV文件
training_data = pd.DataFrame({
'epoch': range(1, epochs + 1),
'train_loss': train_losses,
'train_accuracy': train_accuracies,
'val_loss': val_losses,
'val_accuracy': val_accuracies
})
training_data.to_csv(os.path.join(MODEL_PATH, 'training_history.csv'), index=False)
print(f"训练历史数据已保存到: {os.path.join(MODEL_PATH, 'training_history.csv')}")
if __name__ == "__main__":
# 确保输出目录存在
os.makedirs(MODEL_PATH, exist_ok=True)
# 执行完整训练流程
model, test_accuracy, analysis_report = train_model()
# 输出最终结果
print('\n' + '=' * 60)
print('训练完成总结')
print('=' * 60)
print('✓ 数据划分完成')
print('✓ 字母数据集重组完成')
print('✓ 模型训练完成')
print('✓ 验证集评估完成')
print('✓ 测试集评估完成')
print('✓ 偏差-方差分析完成')
print('✓ 模型文件保存完成')
print('✓ 训练图表生成完成')
print(f'\n最终测试集准确率: {test_accuracy:.2f}%')
print(f'偏差-方差分析结果:')
print(f' 偏差: {analysis_report["bias"]:.4f}')
print(f' 方差: {analysis_report["variance"]:.4f}')
print(f' 过拟合指标: {analysis_report["overfitting_indicator"]:.4f}')
print(f'模型文件保存在: {MODEL_PATH}')
print(f'划分数据保存在: {SPLIT_DATA_PATH}')
还没跑完。可视化下周做。
MNIST手写数字识别(入门)
这个项目差不多了,接下来的目标是:
-
CIFAR-10图像分类(基础)
-
ImageNet图像分类(进阶)
-
COCO目标检测(高级)
-
自定义项目(实战)
总结
深度学习内容马上需要换课程学习,下周计划多找些内容,CNN需要进行新的项目-图像分类(基础)。pytorch实践本周并没进行,下周加上。论文学习需要加上。