一. 引言
本地部署最大的优势在于数据完全掌控。所有对话记录、学习内容都在本地处理,无需上传到云端,有效防止隐私泄露风险。对于教育场景尤其重要,学生的学习数据、提问内容都能得到充分保护。相比按使用量付费的云端API服务,本地部署只需一次性硬件投入。以Qwen1.5-1.8B模型为例,即使在普通笔记本电脑的CPU上也能流畅运行,大大降低了使用门槛。
今天我们提供一个基于本地大模型的AI学习助手,它能够在CPU上运行,并通过Gradio提供Web界面,主要功能包括:
- 智能对话:用户可以通过文本与AI助手进行交流,获取学习上的帮助。
- 学习示例生成:用户可以选择科目、主题和难度,生成相应的学习示例。
- 预设问题:提供了多个分类的预设问题,用户可以直接点击填入输入框。
主界面预览:
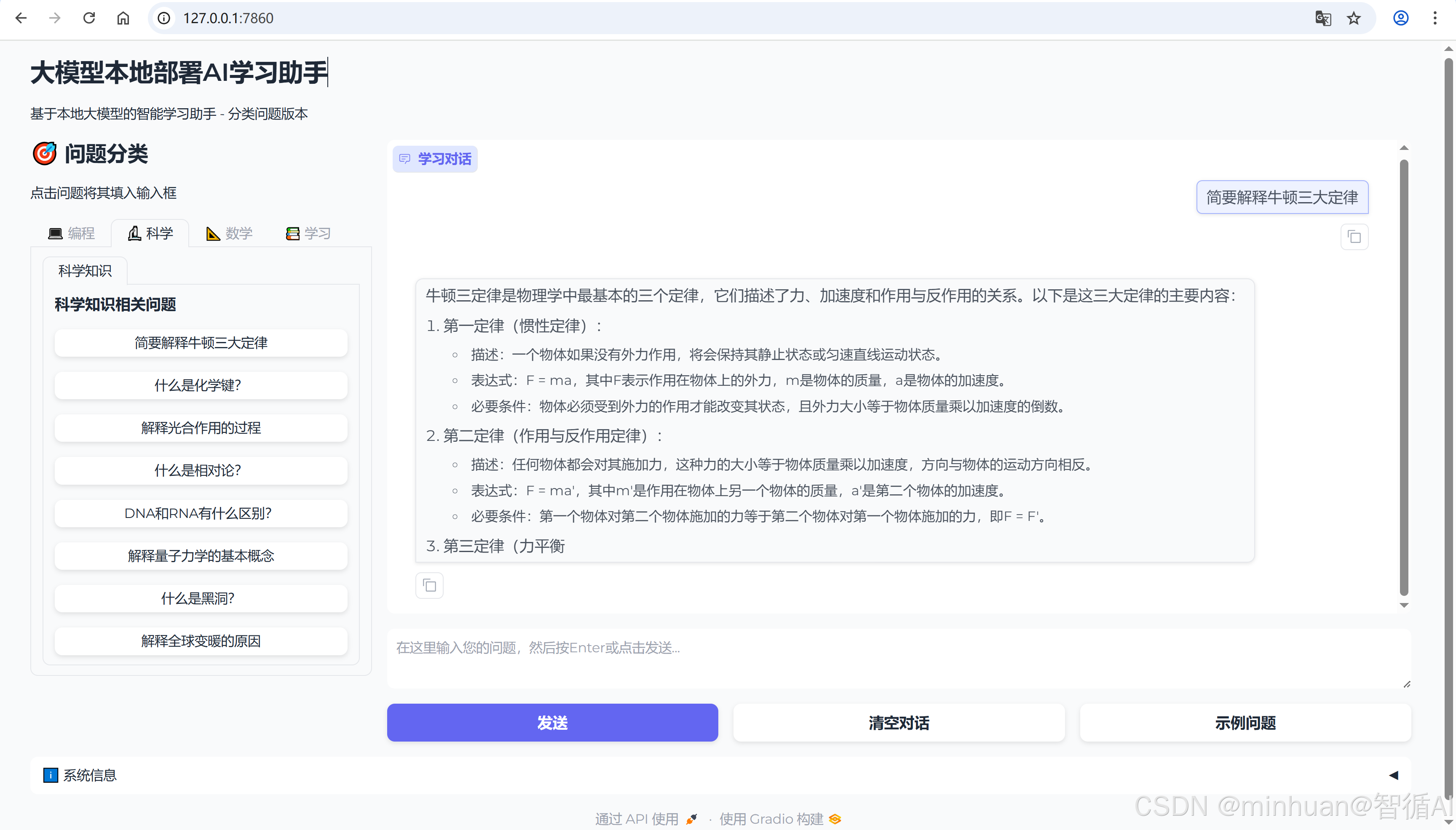
二、项目概述
1. 模型选择
| 模型名称 | 参数量 | CPU内存需求 | 推理速度 | 中文能力 | 推荐场景 |
|---|---|---|---|---|---|
| Qwen1.5-1.8B | 1.8B | ~4GB | 快速 | 优秀 | 教育助手、聊天机器人 |
| ChatGLM3-6B | 6B | ~12GB | 中等 | 优秀 | 复杂推理、专业问答 |
起初考虑的是ChatGLM3-6B,但由于配置原因,退而求其次还是用了对硬件环境友好的Qwen1.5-1.8B,如果大家有更好的配置空间,建议可以选择推理更强的模型,Qwen1.5-4B也是理想选择,相对来说Qwen1.5-1.8B也能满足我们的需求,同样也拥有优秀的中文理解和生成能力,相对较小的内存占用,按需选择,下面开始直入主题;
2. 代码结构
- LocalLearningAssistant类:负责加载模型、生成响应和创建学习示例。
- GradioInterface类:负责构建Gradio Web界面,并处理用户交互。
3. 系统架构
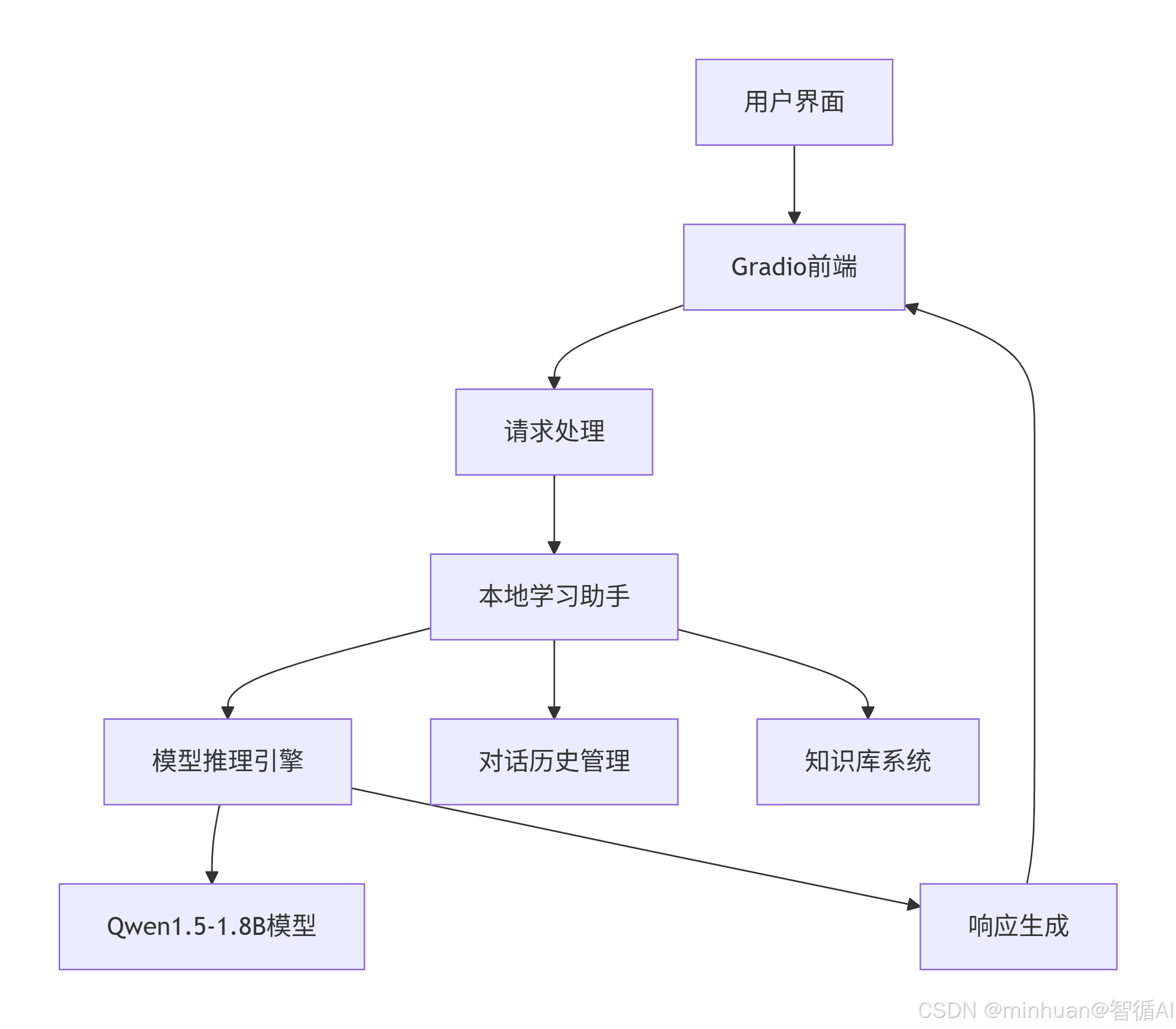
三、系统设计
1. 核心类设计
1.1 LocalLearningAssistant类
python
class LocalLearningAssistant:
"""本地学习助手核心类"""
def __init__(self, model_name="qwen/Qwen1.5-1.8B-Chat"):
self.model_name = model_name
self.device = "cpu"
self.conversation_history = []
def load_model(self):
"""模型加载方法"""
# 实现模型下载和初始化
def generate_response(self, prompt: str) -> str:
"""响应生成核心方法"""
# 实现文本生成逻辑
def create_learning_example(self, subject: str, topic: str) -> Dict:
"""学习示例生成方法"""
# 实现结构化内容生成我们首先需要明确LocalLearningAssistant类的核心作用:它负责加载大模型,并提供生成响应和创建学习示例的功能。接下来,我们将详细说明这个类的各个部分。
- 初始化方法:设置模型名称、设备类型(CPU),初始化对话历史和响应队列。
- 加载模型:从ModelScope下载并加载模型和tokenizer,配置模型以在CPU上运行。
- 生成响应:包括同步和异步两种方式,异步方式用于避免界面阻塞。
- 构建提示词:将系统提示和对话历史组合成模型所需的输入格式。
- 创建学习示例:根据给定的学科、主题和难度生成学习示例。
1.2 异步处理机制
异步生成响应,避免界面阻塞
python
def generate_response_async(self, prompt: str, callback):
def generate():
try:
response = self.generate_response(prompt)
callback(response)
except Exception as e:
callback(f"生成响应时出错: {str(e)}")
thread = threading.Thread(target=generate)
thread.daemon = True
thread.start()2. 提示词工程优化
2.1 基础提示词模板
python
def build_efficient_prompt(self, current_prompt: str) -> str:
system_prompt = "你是一个有帮助的学习助手。请用中文简洁回答。"
prompt = f"{system_prompt}\n\n"
# 添加上下文历史
if self.conversation_history:
last_user, last_assistant = self.conversation_history[-1]
prompt += f"用户: {last_user}\n助手: {last_assistant}\n\n"
prompt += f"用户: {current_prompt}\n助手:"
return prompt2.2 学习示例专用提示词
python
learning_example_prompt = """
请为{难度}级别的学习者创建一个关于{科目}中{主题}的学习示例。
要求:
1. 包含一个清晰的概念解释
2. 提供一个具体的代码示例或实际应用场景
3. 提出2-3个思考问题帮助巩固理解
4. 用中文回答,保持教育性
请按以下格式返回:
概念:
示例:
思考问题:
"""3. 用户交互界面设计
3.1 Gradio界面架构
python
class GradioInterface:
"""Gradio用户界面管理类"""
def create_interface(self):
"""创建完整的Web界面"""
with gr.Blocks(theme=gr.themes.Soft()) as demo:
# 标题区域
gr.Markdown("# 大模型本地部署AI学习助手")
with gr.Row():
# 左侧问题分类面板
with gr.Column(scale=1):
self.create_question_panel()
# 右侧聊天区域
with gr.Column(scale=3):
self.create_chat_interface()
return demo3.2 响应式布局设计
3.2.1 自适应宽度调整
python
# 左侧面板:固定宽度
with gr.Column(scale=1, min_width=350):
# 右侧聊天区域:自适应宽度
with gr.Column(scale=3):3.2.2 分类标签页设计
python
with gr.Tabs() as category_tabs:
with gr.TabItem("💻 编程"):
# 编程相关问题按钮
with gr.TabItem("🔬 科学"):
# 科学相关问题按钮
with gr.TabItem("📐 数学"):
# 数学相关问题按钮
with gr.TabItem("📚 学习"):
# 学习技巧问题按钮3.3 交互体验优化
3.3.1 实时状态反馈
python
def chat_interface(self, message, history):
"""带有加载状态的聊天接口"""
history.append([message, ""])
yield history, ""
# 显示思考状态
dots = 0
while not response_ready:
dots = (dots + 1) % 4
loading_text = "思考中" + "." * dots
history[-1][1] = loading_text
yield history, ""
time.sleep(0.5)3.3.2 预设问题快速输入
python
# 预设问题点击直接填入输入框
btn.click(
fn=lambda q=question: q,
inputs=[],
outputs=msg # 输入框组件
)4. 参数优化配置
4.1 模型加载优化参数
python
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float32, # 精度选择
trust_remote_code=True, # 代码信任
device_map=None, # 设备映射
low_cpu_mem_usage=True # 内存优化
).to(self.device)关键参数详解:
-
- torch_dtype=torch.float32
-
- 选项:float32, float16, bfloat16
-
- float32: 最高精度,适合CPU推理,稳定性最好
-
- float16: 半精度,减少50%内存,可能损失精度
-
- bfloat16: 脑浮点16位,兼顾精度和性能,需要硬件支持
-
- 推荐:CPU环境使用float32,GPU环境可尝试float16
-
- device_map=None
-
- 作用:在多GPU环境下自动分配模型层
-
- None: 手动指定设备,适合单设备
-
- "auto": 自动分配,适合多GPU
-
- 特定映射: 如{"": 0} 指定到第一个GPU
-
- CPU环境:必须设为None
-
- low_cpu_mem_usage=True
-
- 作用:减少模型加载时的峰值内存使用
-
- 原理:延迟加载模型权重,避免一次性加载所有参数
-
- 效果:可减少20-30%的加载内存
-
- 注意:可能会略微增加加载时间
4.2 输入处理参数
python
inputs = self.tokenizer(
full_prompt,
return_tensors="pt", # 返回PyTorch张量
truncation=True, # 启用截断
max_length=512, # 最大输入长度
padding=True # 启用填充
)参数深度解析:
-
- max_length=512
-
- 技术背景:Transformer模型有上下文窗口限制
-
- Qwen1.5-1.8B: 支持32K上下文,但为性能考虑限制为512
-
- 影响因素:
- 内存占用:长度增加,内存平方级增长 (O(n²))
- 推理速度:长度增加,推理时间线性增长
-
- 优化建议:
- 教育场景:512-1024足够
- 长文档处理:需要调整到2048或更高
-
- truncation=True
-
- 作用:当输入超过max_length时自动截断
-
- 策略:默认从末尾截断,保留最重要的开头部分
-
- 替代方案:可设置truncation_side='left'从开头截断
-
- padding=True
-
- 作用:将序列填充到相同长度
-
- 批量推理:必须启用,保证输入形状一致
-
- 单条推理:可设为False节省计算
4.3 生成策略参数
python
outputs = self.model.generate(
**inputs,
max_new_tokens=256, # 最大生成长度
temperature=0.7, # 温度参数
do_sample=True, # 采样模式
pad_token_id=self.tokenizer.eos_token_id, # 填充token
repetition_penalty=1.1, # 重复惩罚
num_beams=1, # 束搜索大小
early_stopping=True # 提前停止
)- temperature=0.7 温度参数详解:
- 范围:0.0 ~ 2.0(通常0.1~1.0)
- 低温 (0.1-0.3): 确定性高,选择概率最高的token
- 适合:事实问答、代码生成
- 优点:一致性好
- 缺点:可能枯燥、重复
- 中温 (0.5-0.8): 平衡创造性和一致性
- 适合:创意写作、对话
- 推荐:0.7是很好的平衡点
- 高温 (0.9-1.2): 创造性高,多样性好
- 适合:诗歌创作、头脑风暴
- 风险:可能生成无关内容
- do_sample=True 采样模式:
- do_sample=True: 使用温度采样
- do_sample=False: 使用贪婪搜索(temperature无效)
- 组合使用:
- do_sample=False, num_beams>1: 束搜索
- do_sample=True, num_beams=1: 纯采样
- do_sample=True, num_beams>1: 束搜索采样
- repetition_penalty=1.1 重复惩罚机制:
- 原理:对已出现过的token降低其选择概率
- 范围:1.0 ~ 2.0
- 1.0: 无惩罚
- 1.1-1.3: 轻度惩罚,适合对话
- 1.5-2.0: 重度惩罚,适合长文本生成
- 数学公式:调整后概率 = 原始概率 / (惩罚因子 ^ 出现次数)
- 注意:设置过大会导致生成困难,出现不连贯
- num_beams=1 束搜索 (Beam Search) 详解:
- num_beams=1: 贪婪搜索,速度最快
- num_beams=2-5: 平衡质量和速度
- num_beams>5: 高质量,但速度慢
- 束搜索工作原理:
-
- 保持多个候选序列(beam_size个)
-
- 每步扩展所有候选序列
-
- 选择概率最高的beam_size个继续
-
- 直到生成结束
-
4.4 布局参数详解
python
with gr.Row(equal_height=False):
with gr.Column(scale=1, min_width=350): # 左侧面板
with gr.Column(scale=3): # 右侧聊天区域布局参数深度解析:
-
- scale参数:
- 作用:定义列之间的相对宽度比例
- scale=1, scale=3: 表示1:3的比例
- 计算:总比例 = 1+3=4,左侧占1/4,右侧占3/4
- 优势:响应式布局,适应不同屏幕尺寸
-
- min_width参数:
- 作用:设置组件的最小宽度
- 单位:像素
- 必要性:确保在小屏幕上仍有可用的最小宽度
- 推荐:根据内容重要性设置合适的min_width
-
- equal_height=False:
- 作用:允许行内列有不同的高度
- 默认:True,强制等高
- 设置为False:让内容自然决定高度
4.5 组件参数优化
python
chatbot = gr.Chatbot(
label="学习对话",
height=500, # 固定高度
show_copy_button=True, # 复制功能
placeholder="对话将显示在这里...",
show_label=True,
bubble_full_width=False # 气泡样式
)组件参数详解:
-
- height=500:
-
- 作用:固定聊天区域高度
-
- 单位:像素
-
- 考虑:在有限屏幕空间内平衡输入和显示区域
-
- 替代方案:可使用min_height和max_height
-
- show_copy_button=True:
-
- 功能:在每条消息旁显示复制按钮
-
- 用户体验:方便用户保存重要回答
-
- 技术实现:Gradio自动处理复制逻辑
-
- bubble_full_width=False:
-
- 作用:控制消息气泡宽度
-
- False:气泡宽度根据内容自适应
-
- True:气泡占满整个容器宽度
-
- 推荐False:视觉上更美观
四、模块实现
1. 编程助手
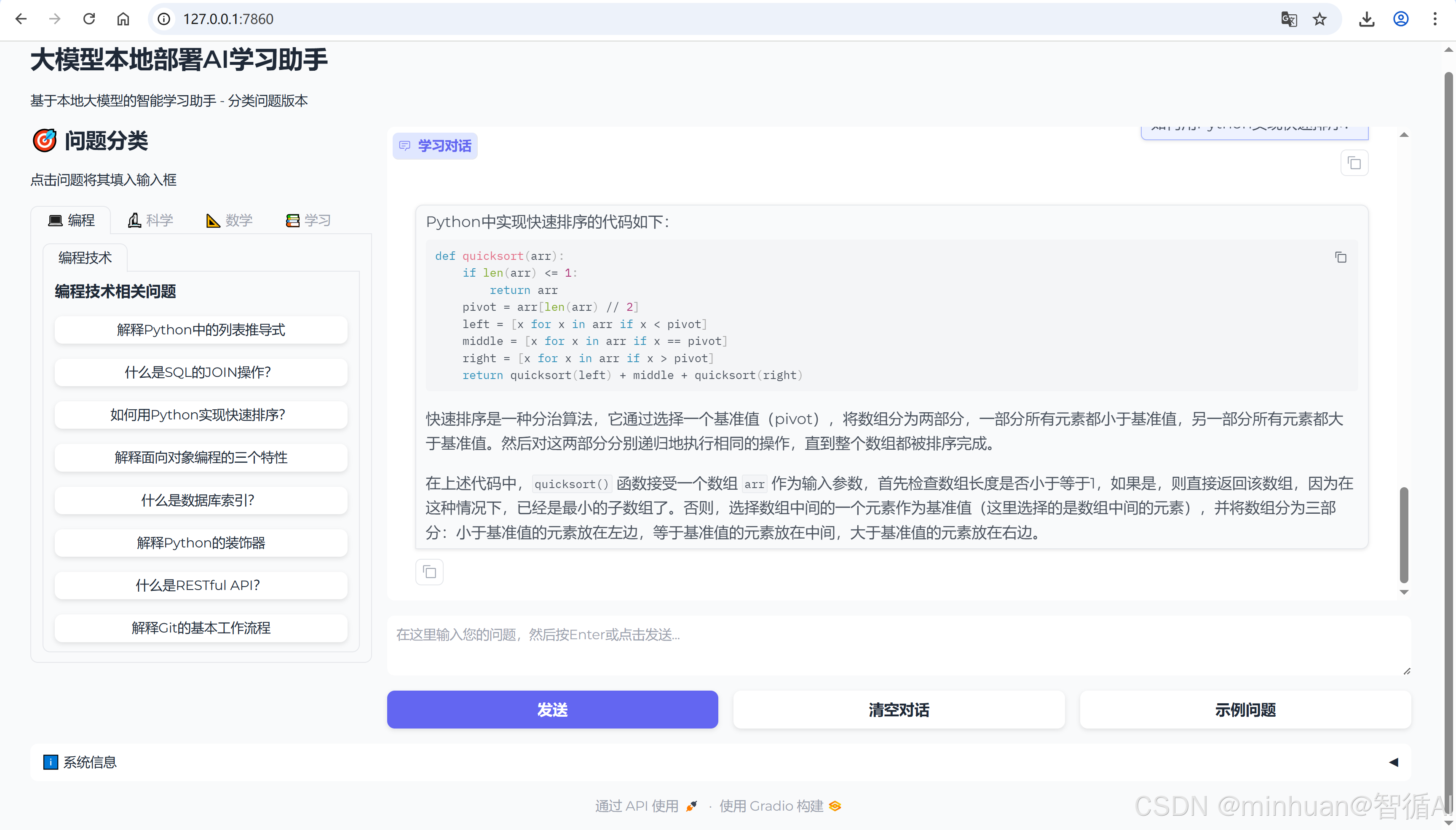
2. 科学助手
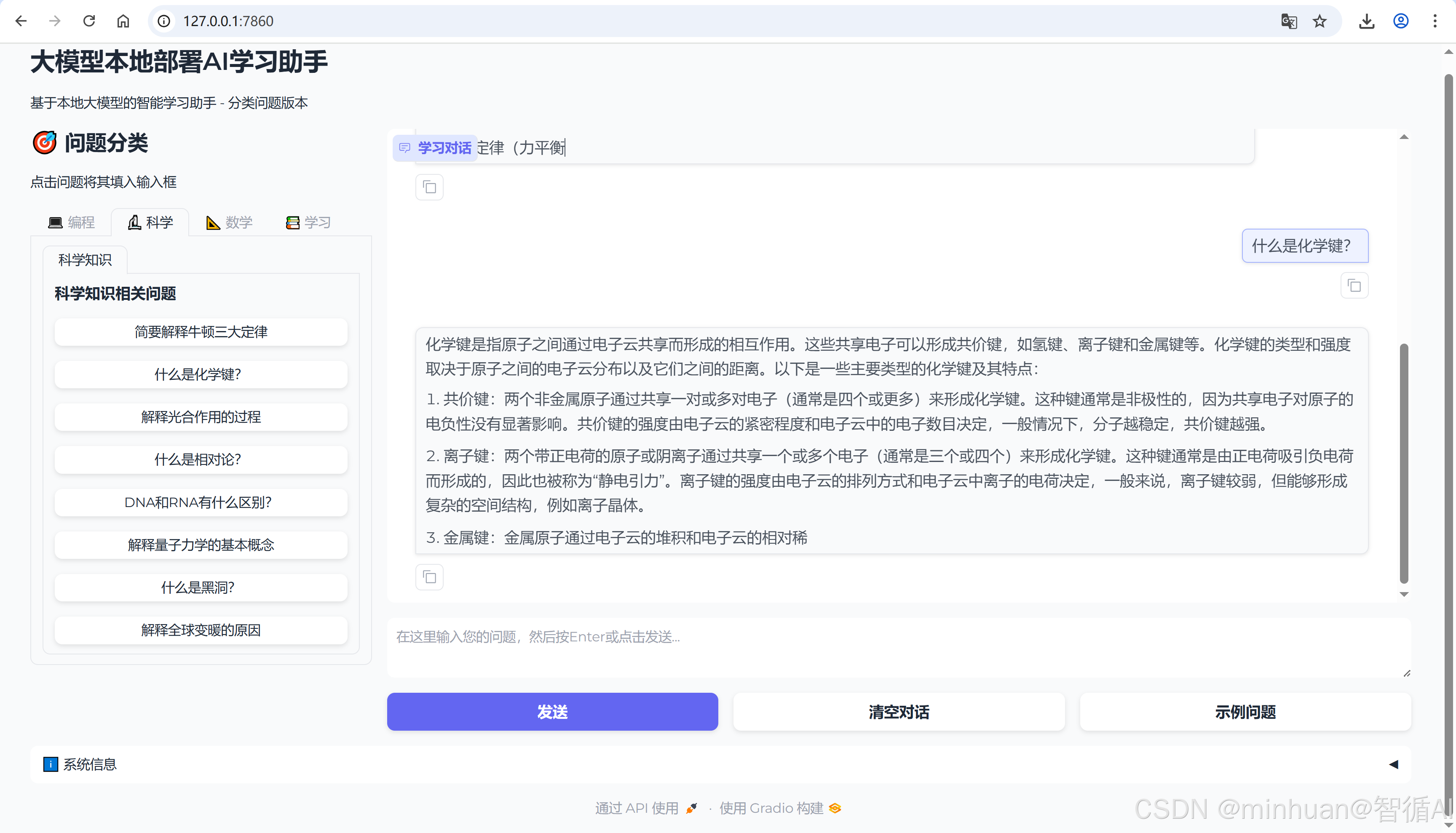
3. 数学助手
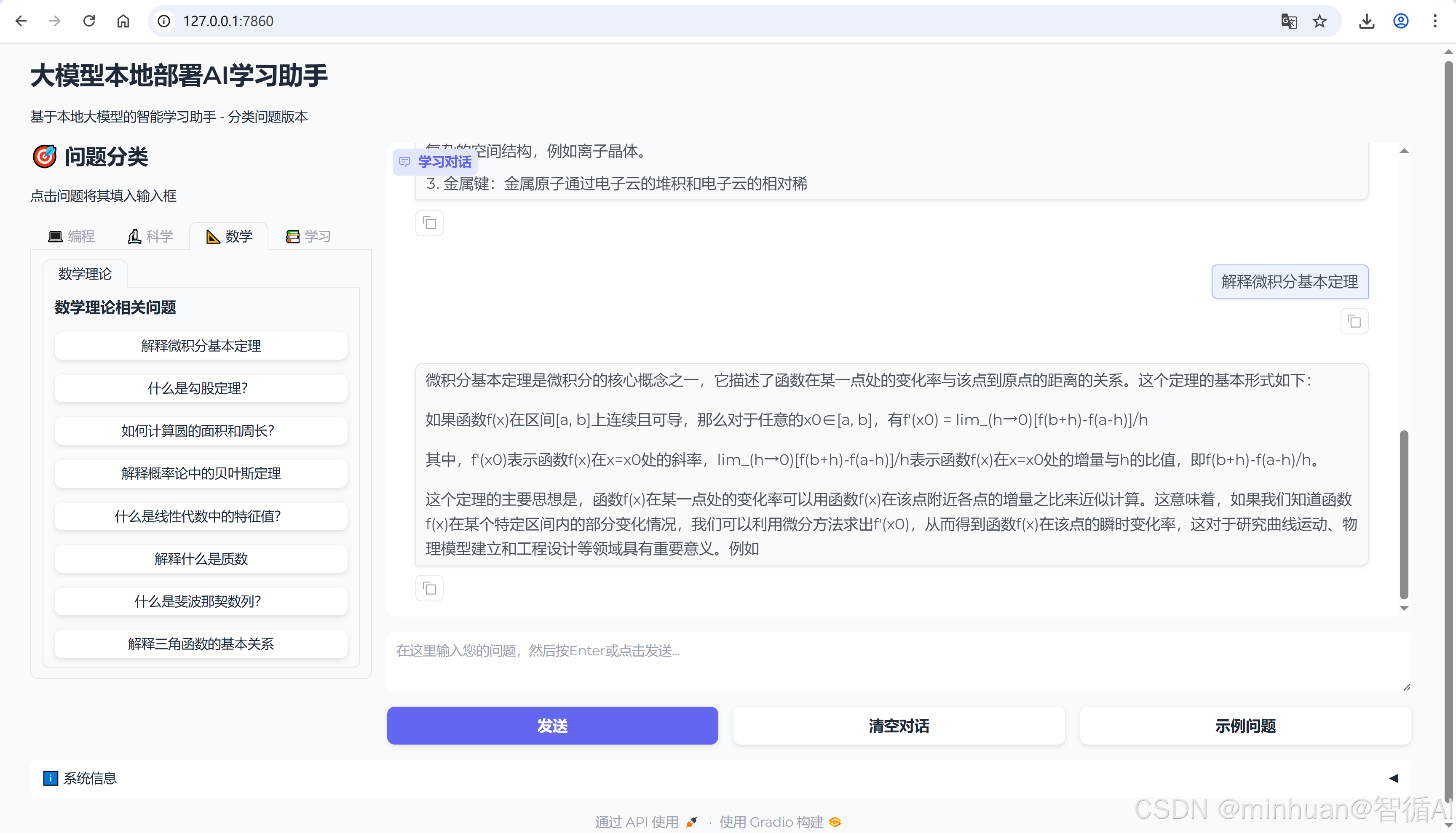
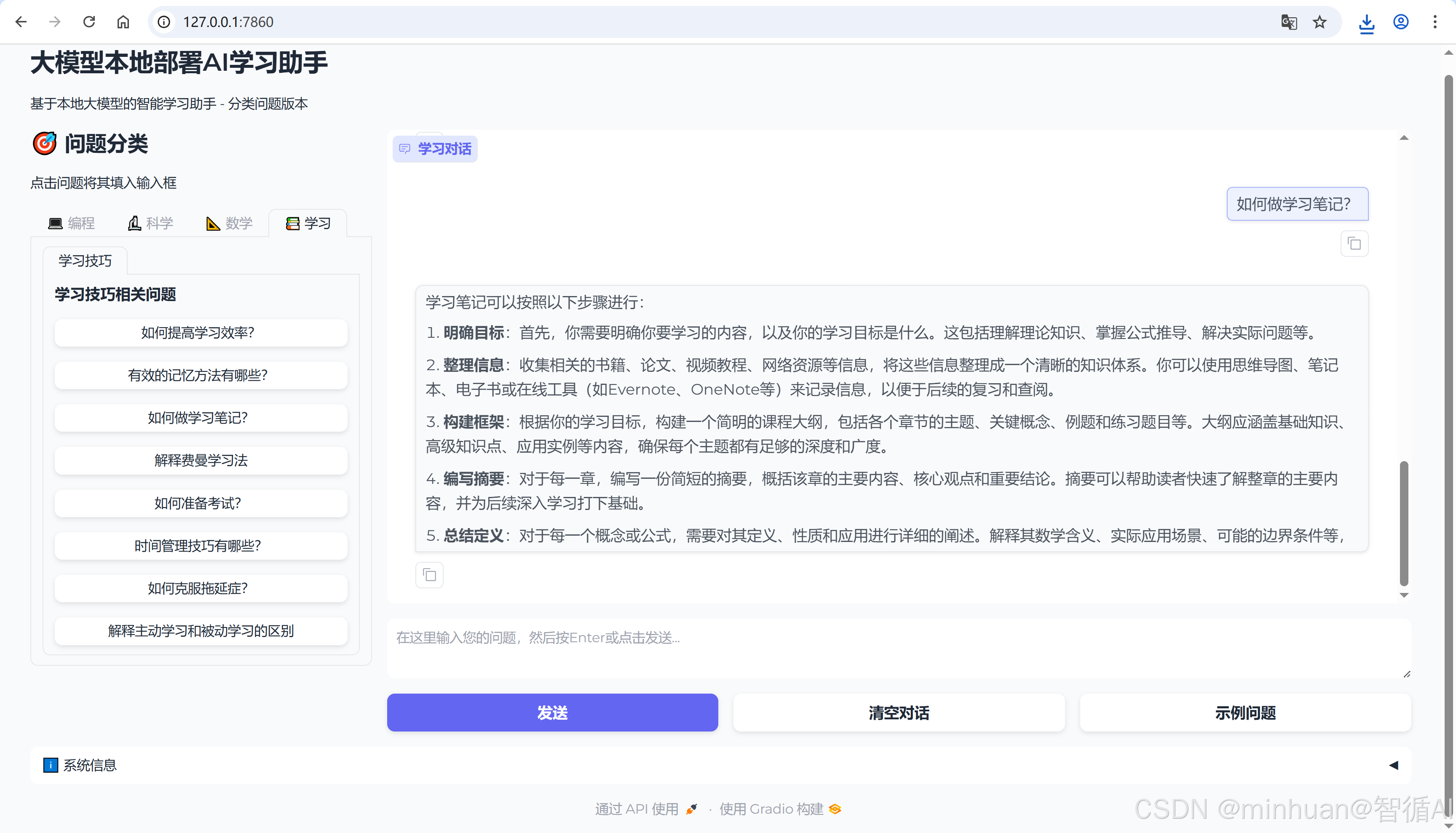
4. 学习助手
五、总结
这个项目成功实现了在消费级硬件上部署智能学习助手,基于Qwen1.5-1.8B大模型在CPU环境稳定运行。核心突破在于将复杂的AI技术简化为易用接口,通过精心优化的参数配置在有限资源下实现实用性能。系统具备智能对话、多学科问答、学习示例生成等教育功能,Gradio界面提供友好的分类提问和上下文对话体验。让我们能在自己的电脑上运行一个智能学习助手,就像拥有一个24小时在线的私人教师。它完全在本地运行,保护我们的隐私,不需要网络就能使用。
通过简单的网页界面,我们可以提问任何学习问题,比如编程、数学、科学等。系统预设了大量常见问题,一键点击就能提问。AI助手会在几秒内给出详细解答,还能记住对话上下文,让学习更连贯。
附录:完整示例参考
python
import torch
import json
import logging
from typing import Dict, List, Any
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
import gradio as gr
import os
import time
import threading
from queue import Queue
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("ai_assistant.log"),
logging.StreamHandler()
]
)
logger = logging.getLogger("LocalAIAssistant")
class LocalLearningAssistant:
"""本地学习助手 - 优化响应速度版本"""
def __init__(self, model_name="qwen/Qwen1.5-1.8B-Chat"):
self.model_name = model_name
self.device = "cpu"
self.conversation_history = []
self.response_queue = Queue()
# 加载模型
self.load_model()
logger.info("本地学习助手初始化完成")
def load_model(self):
"""加载本地模型"""
try:
logger.info(f"正在加载模型: {self.model_name}")
# 下载模型(如果尚未下载)
model_path = snapshot_download(self.model_name, cache_dir="D:\\modelscope\\hub")
# 加载tokenizer和模型
self.tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
# 设置pad_token
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
self.model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float32,
trust_remote_code=True,
device_map=None,
low_cpu_mem_usage=True # 减少内存使用
).to(self.device)
self.model.eval()
logger.info("模型加载成功")
except Exception as e:
logger.error(f"模型加载失败: {e}")
raise
def generate_response_async(self, prompt: str, callback):
"""异步生成响应"""
def generate():
try:
response = self.generate_response(prompt)
callback(response)
except Exception as e:
callback(f"生成响应时出错: {str(e)}")
thread = threading.Thread(target=generate)
thread.daemon = True
thread.start()
def generate_response(self, prompt: str, max_length: int = 256) -> str:
"""生成模型响应 - 优化速度版本"""
try:
# 使用更简洁的提示词
full_prompt = self.build_efficient_prompt(prompt)
# 编码输入
inputs = self.tokenizer(
full_prompt,
return_tensors="pt",
truncation=True,
max_length=512, # 减少输入长度
padding=True
)
inputs = {k: v.to(self.device) for k, v in inputs.items()}
# 生成响应 - 使用更快的参数
with torch.no_grad():
outputs = self.model.generate(
**inputs,
max_new_tokens=max_length, # 减少生成长度
temperature=0.7,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id,
repetition_penalty=1.1,
num_beams=1, # 使用贪婪搜索提高速度
early_stopping=True
)
# 解码响应
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取新生成的部分
if response.startswith(full_prompt):
response = response[len(full_prompt):].strip()
return response
except Exception as e:
logger.error(f"生成响应失败: {e}")
return f"抱歉,生成响应时出现错误: {str(e)}"
def build_efficient_prompt(self, current_prompt: str) -> str:
"""构建高效的提示词"""
# 简化的系统提示
system_prompt = "你是一个有帮助的学习助手。请用中文简洁回答。"
# 只使用最近一轮对话历史
prompt = f"{system_prompt}\n\n"
if self.conversation_history:
last_user, last_assistant = self.conversation_history[-1]
prompt += f"用户: {last_user}\n助手: {last_assistant}\n\n"
prompt += f"用户: {current_prompt}\n助手:"
return prompt
def create_learning_example(self, subject: str, topic: str, difficulty: str = "beginner") -> Dict[str, Any]:
"""创建学习示例 - 简化版本"""
prompt = f"请创建一个关于{subject}中{topic}的{difficulty}级别学习示例,包含概念解释、示例和思考问题。"
response = self.generate_response(prompt, max_length=300)
# 简化解析
example = {
"subject": subject,
"topic": topic,
"difficulty": difficulty,
"content": response,
"timestamp": time.time()
}
return example
class GradioInterface:
"""Gradio用户界面 - 分类标签页版本"""
def __init__(self, assistant):
self.assistant = assistant
self.preset_questions = self.load_preset_questions()
self.active_generations = {}
self.chat_width = "100%" # 设置聊天区域宽度为100%
def load_preset_questions(self):
"""加载分类预设问题"""
return {
"编程技术": [
"解释Python中的列表推导式",
"什么是SQL的JOIN操作?",
"如何用Python实现快速排序?",
"解释面向对象编程的三个特性",
"什么是数据库索引?",
"解释Python的装饰器",
"什么是RESTful API?",
"解释Git的基本工作流程"
],
"科学知识": [
"简要解释牛顿三大定律",
"什么是化学键?",
"解释光合作用的过程",
"什么是相对论?",
"DNA和RNA有什么区别?",
"解释量子力学的基本概念",
"什么是黑洞?",
"解释全球变暖的原因"
],
"数学理论": [
"解释微积分基本定理",
"什么是勾股定理?",
"如何计算圆的面积和周长?",
"解释概率论中的贝叶斯定理",
"什么是线性代数中的特征值?",
"解释什么是质数",
"什么是斐波那契数列?",
"解释三角函数的基本关系"
],
"学习技巧": [
"如何提高学习效率?",
"有效的记忆方法有哪些?",
"如何做学习笔记?",
"解释费曼学习法",
"如何准备考试?",
"时间管理技巧有哪些?",
"如何克服拖延症?",
"解释主动学习和被动学习的区别"
]
}
def chat_interface(self, message, history):
"""聊天界面处理函数 - 优化版本"""
if not message or not message.strip():
yield history, ""
return
# 添加用户消息到历史
history.append([message, ""])
yield history, ""
# 生成唯一ID用于跟踪生成状态
gen_id = str(time.time())
self.active_generations[gen_id] = {"done": False, "response": ""}
def update_callback(response):
self.active_generations[gen_id] = {"done": True, "response": response}
# 异步生成响应
self.assistant.generate_response_async(message, update_callback)
# 等待响应完成,同时更新界面
dots = 0
while not self.active_generations[gen_id]["done"]:
dots = (dots + 1) % 4
loading_text = "思考中" + "." * dots
history[-1][1] = loading_text
yield history, ""
time.sleep(0.5)
# 获取最终响应
response = self.active_generations[gen_id]["response"]
history[-1][1] = response
# 更新对话历史
self.assistant.conversation_history.append((message, response))
# 清理
del self.active_generations[gen_id]
yield history, ""
def preset_question_handler(self, question):
"""预设问题处理 - 直接返回问题文本"""
return question
def quick_example_handler(self, subject, topic, difficulty):
"""快速示例处理"""
if not topic.strip():
return "请输入学习主题"
example = self.assistant.create_learning_example(subject, topic, difficulty)
return example["content"]
def create_question_tab(self, category_name, questions):
"""创建问题标签页"""
with gr.Tab(category_name):
gr.Markdown(f"### {category_name}相关问题")
for question in questions:
btn = gr.Button(
question,
size="sm",
variant="secondary",
min_width=350,
scale=0
)
yield btn
def create_interface(self):
"""创建Gradio界面 - 分类标签页版本"""
with gr.Blocks(theme=gr.themes.Soft(), title="本地AI学习助手") as demo:
gr.Markdown("# 大模型本地部署AI学习助手")
gr.Markdown("基于本地大模型的智能学习助手 - 分类问题版本")
with gr.Row(equal_height=False):
# 左侧问题分类面板
with gr.Column(scale=1, min_width=350):
gr.Markdown("## 🎯 问题分类")
gr.Markdown("点击问题将其填入输入框")
# 创建分类标签页
with gr.Tabs() as category_tabs:
question_buttons = []
# 编程技术标签页
with gr.TabItem("💻 编程"):
for btn in self.create_question_tab("编程技术", self.preset_questions["编程技术"]):
question_buttons.append(btn)
# 科学知识标签页
with gr.TabItem("🔬 科学"):
for btn in self.create_question_tab("科学知识", self.preset_questions["科学知识"]):
question_buttons.append(btn)
# 数学理论标签页
with gr.TabItem("📐 数学"):
for btn in self.create_question_tab("数学理论", self.preset_questions["数学理论"]):
question_buttons.append(btn)
# 学习技巧标签页
with gr.TabItem("📚 学习"):
for btn in self.create_question_tab("学习技巧", self.preset_questions["学习技巧"]):
question_buttons.append(btn)
# 右侧聊天区域
with gr.Column(scale=3):
chatbot = gr.Chatbot(
label="学习对话",
height=500,
show_copy_button=True,
placeholder="对话将显示在这里...",
show_label=True
)
with gr.Row():
msg = gr.Textbox(
label="输入您的问题",
placeholder="在这里输入您的问题,然后按Enter或点击发送...",
scale=4,
container=False,
lines=2,
max_lines=5
)
with gr.Row():
submit_btn = gr.Button("发送", variant="primary", scale=1)
clear_btn = gr.Button("清空对话", variant="secondary", scale=1)
gr.Button("示例问题", variant="secondary", scale=1).click(
fn=lambda: "生成一个Python函数定义的示例",
inputs=[],
outputs=msg
)
# 系统信息区域
with gr.Accordion("ℹ️ 系统信息", open=False):
with gr.Row():
with gr.Column():
gr.Markdown("**系统状态**")
gr.Markdown(f"模型: {self.assistant.model_name}")
gr.Markdown(f"设备: {self.assistant.device}")
gr.Markdown(f"对话记录: {len(self.assistant.conversation_history)} 条")
with gr.Column():
gr.Markdown("**使用提示**")
gr.Markdown("""
- 响应可能需要几秒钟时间
- 问题越具体,回答越准确
- 使用分类问题快速开始
- 生成示例时请填写具体主题
""")
# 连接事件处理
for i, btn in enumerate(question_buttons):
# 找到对应的问题文本
question_text = None
for category, questions in self.preset_questions.items():
if i < len(questions):
question_text = questions[i]
break
i -= len(questions)
if question_text:
btn.click(
fn=lambda q=question_text: q,
inputs=[],
outputs=msg
)
# 主要交互事件
submit_event = msg.submit(
self.chat_interface,
[msg, chatbot],
[chatbot, msg]
)
submit_btn.click(
self.chat_interface,
[msg, chatbot],
[chatbot, msg]
)
clear_btn.click(
fn=lambda: [],
inputs=[],
outputs=[chatbot]
)
return demo
def check_system_resources():
"""检查系统资源"""
import psutil
import platform
print("🔍 系统资源检查:")
print(f" 操作系统: {platform.system()} {platform.release()}")
print(f" 处理器: {platform.processor()}")
print(f" 内存: {psutil.virtual_memory().total / (1024**3):.1f} GB")
print(f" 可用内存: {psutil.virtual_memory().available / (1024**3):.1f} GB")
print(f" Python: {platform.python_version()}")
def main():
"""主函数"""
print("🚀 启动本地AI学习助手...")
# 检查系统资源
check_system_resources()
try:
# 初始化学习助手
print("正在加载AI模型,这可能需要几分钟...")
assistant = LocalLearningAssistant()
# 初始化Gradio界面
print("正在初始化用户界面...")
gradio_interface = GradioInterface(assistant)
# 启动Gradio服务
print("🌐 启动Gradio Web界面...")
print("✅ 服务启动后,请在浏览器中访问 http://localhost:7860")
print("💡 如果端口7860被占用,将自动使用其他端口")
demo = gradio_interface.create_interface()
demo.launch(
server_name="127.0.0.1", # 使用本地地址
server_port=7860,
share=False,
show_error=True,
inbrowser=True, # 自动打开浏览器
quiet=False
)
except Exception as e:
print(f"❌ 系统运行失败: {e}")
logger.error(f"系统运行失败: {e}")
# 命令行版本(备用)
def cli_main():
"""命令行版本的主函数"""
print("🚀 启动本地AI学习助手(命令行版本)...")
check_system_resources()
try:
assistant = LocalLearningAssistant()
print("\n" + "="*50)
print("🤖 本地AI学习助手(命令行模式)")
print("="*50)
print("输入 'quit' 退出")
print("-"*50)
while True:
try:
user_input = input("\n🎯 你的问题: ").strip()
if user_input.lower() in ['quit', 'exit', '退出']:
print("👋 再见!祝你学习愉快!")
break
if not user_input:
continue
start_time = time.time()
response = assistant.generate_response(user_input)
end_time = time.time()
print(f"\n🤖 助手 ({end_time - start_time:.2f}秒): {response}")
assistant.conversation_history.append((user_input, response))
except KeyboardInterrupt:
print("\n\n程序被用户中断")
break
except Exception as e:
print(f"\n❌ 错误: {str(e)}")
except Exception as e:
print(f"❌ 系统运行失败: {e}")
if __name__ == "__main__":
# 检查是否安装了gradio
try:
import gradio
# 使用Web界面版本
main()
except ImportError:
print("❌ 未安装Gradio,使用命令行版本")
print("💡 要使用Web界面,请运行: pip install gradio")
cli_main()