认识make/makefile
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile 定义了一系列的规则来指定,哪些文件件需要先编译,哪些文件件需要后编译,哪些文件件需要重新编译,甚至进行更复杂的功能操作。
存在多个源文件,这些源文件经过编译器的处理之后变成 .o 文件,所有的 .o 文件再和库链接起来形成可执行程序。如何将这多个文件最终合成一个可执行程序呢?如何将这多个文件最终合成多个可执行程序呢?这个时候自动化构建的工具就帮大忙了,不需要我们在命令行中反复输入gcc/g++ 相关命令,手动构建。
在使用 vs 编译器编写代码时,main.c 和 test.c 这两个文件,最终合成一个可执行文件,其中的自动化构建就是vs帮助我们做了。makefile带来的好处就是 ------ "自动动化编译",一旦写好,只需要一个 make 命令,整个工程完全自动编译,极大的提高了软件开发的效率。
make/makefile的功能:自动化项目的构建(将源文件进行编译变成二进制文件)
make 是一个命令,makefile一个文件
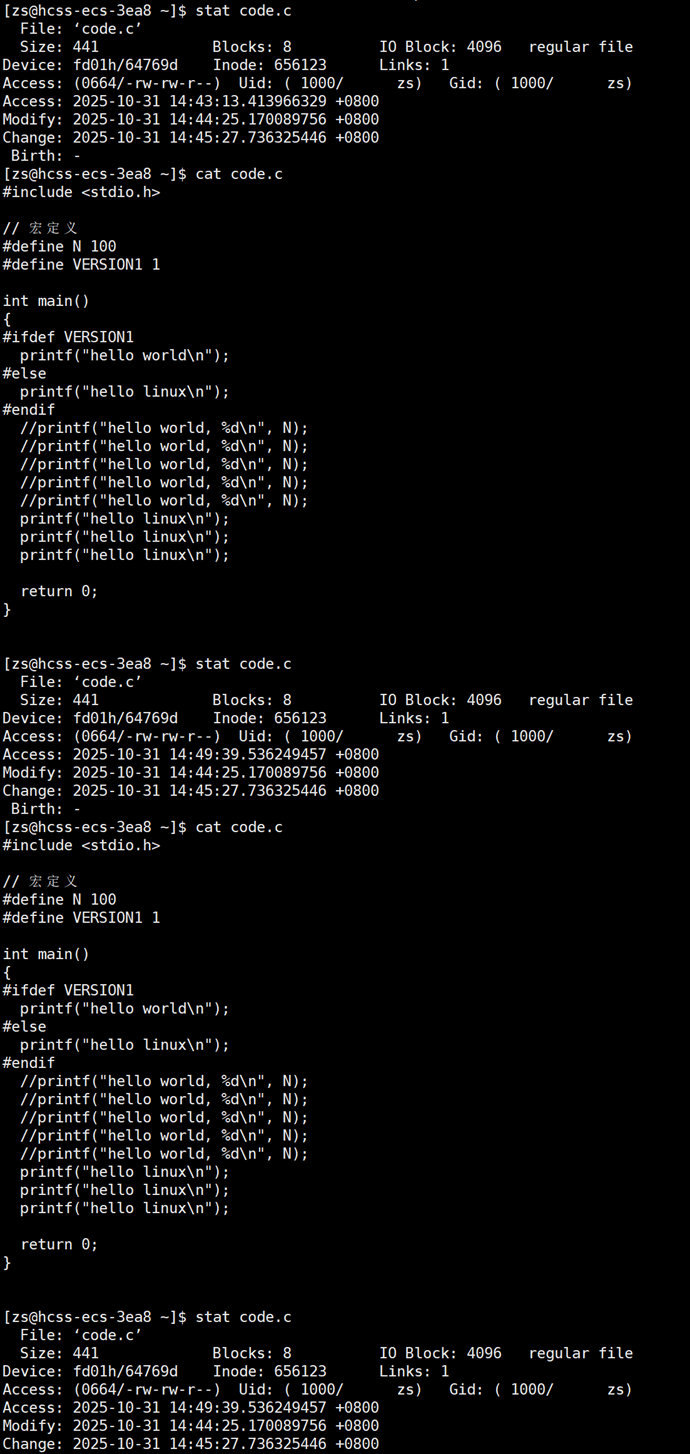
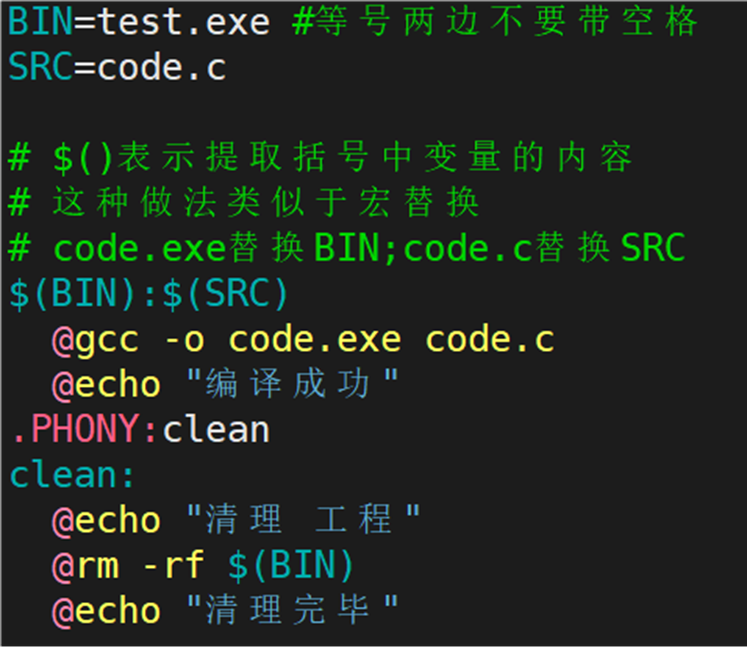
接下来看看 make/makefile 。在当前路径下创建 makefile/Makefile 文件(建议首字母大写),打开 Makefile 文件,写入以下代码:

推荐下面的写法:

这就是一个简单的 makefile。
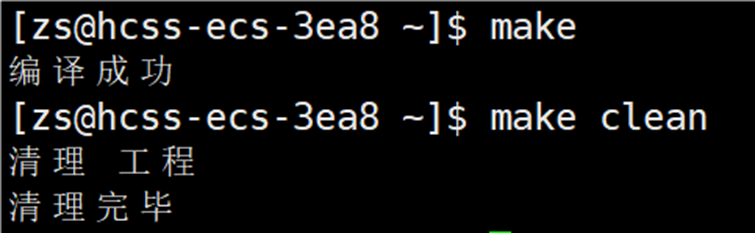
倘若想要执行该文件,直接输入 make 指令。结果如下图所示:
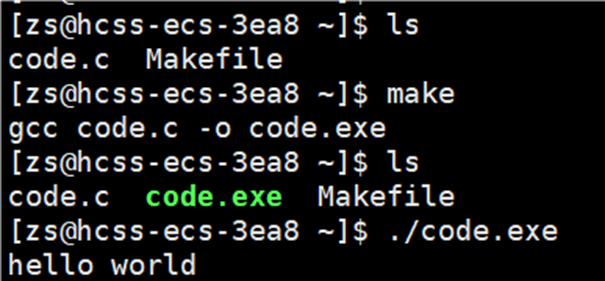
输入 make 指令后,自动执行 Makeflie 中的内容,并且自动帮助我们生成 code.exe 文件。所以说make 是个命令,makefile 是个文件。
实现 makefile
makefile 中的结构:
目标文件:依赖文件列表(依赖关系)
依赖方法(使用TAB键开头)
make 命令会解析 makefile 文件中的依赖关系和依赖方法,第一行 code.exe:code.c ,code.exe 的形成依赖 code.c,这种关系叫做依赖关系。第二行 gcc -o code.exe code.c 叫做依赖方法。Makefile 中重点包含的依赖关系和依赖方法。
依赖关系和依赖方法是成对的,是合理的。想要生成可执行程序,需要依赖源文件,仅有依赖关系还不够,还需要有将源文件翻译成可执行程序的正确的依赖方法。
依赖关系错误,不能执行依赖方法。


依赖方法不合理,不能执行依赖方法。

为了更好的理解 makefile,在 Makefile 文件中写入以下内容
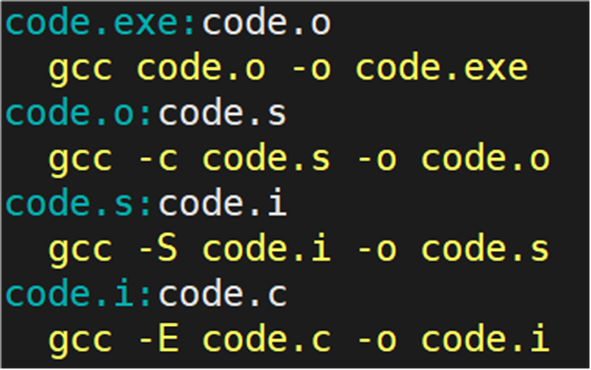
在命令行输入 make 指令,解析 makefile 中的依赖关系和依赖方法。
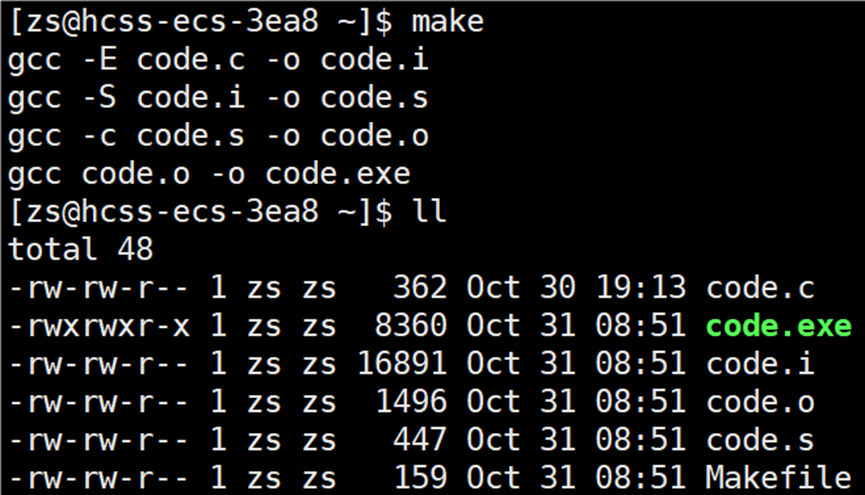
分析:
要生成 code.exe 文件,就需要依赖文件 code.o,code.o 文件在当前路径下没有,再往下找是否是依赖文件列表生成的目标文件,按照此道理类推,直到找到 code.i:code.c。code.c 在当前路径下存在,所以生成 code.i 目标文件
code.s:code.i 依赖关系中,依赖关系成立,code.i 依赖文件存在,生成目标文件 code.s
code.o:code.s 依赖关系中,依赖关系成立,code.s 依赖文件存在,生成目标文件code.o
code.exe:code.o 依赖关系中,依赖关系成立,code.o 依赖文件存在,生成目标文件code.exe
make 是一条命令,它会解析 Makefile 文件中的依赖关系和依赖方法,那么它是如何解析的?

make 会解析 Makefile 中的依赖关系和依赖方法,根据依赖关系形成推导栈,推导栈就是依赖方法的集合。
如果将这四个依赖关系和依赖方法的顺序打乱, 会根据入栈和出栈的顺序执行依赖关系和依赖方法(下图仅是方便分析,具体的入栈规则并不是这样)

分析:
gcc -c code.s -o code.o 依赖文件 code.s 当前路径下不存在,故依赖方法不执行,出栈
gcc -E code.c -o code.i 依赖文件 code.c 当前路径下存在,生成文件 code.i,执行依赖方法,执行完毕后出栈
gcc code.o -o code.exe 依赖文件 code.o 当前路径下不存在,故依赖方法不执行,出栈
gcc -S code.i -o code.s 依赖文件 code.i 当前路径下存在,生成 code.s 文件,执行依赖方法,执行完毕后出栈
所以最后生成了code.i 和 code.s 文件。
make命令的执行结果如下图所示:
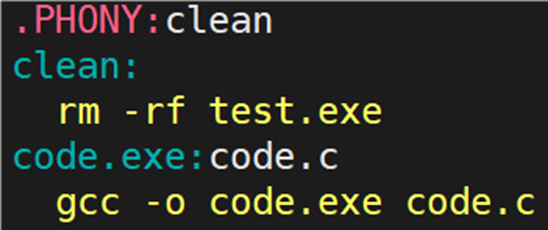
.PHONY
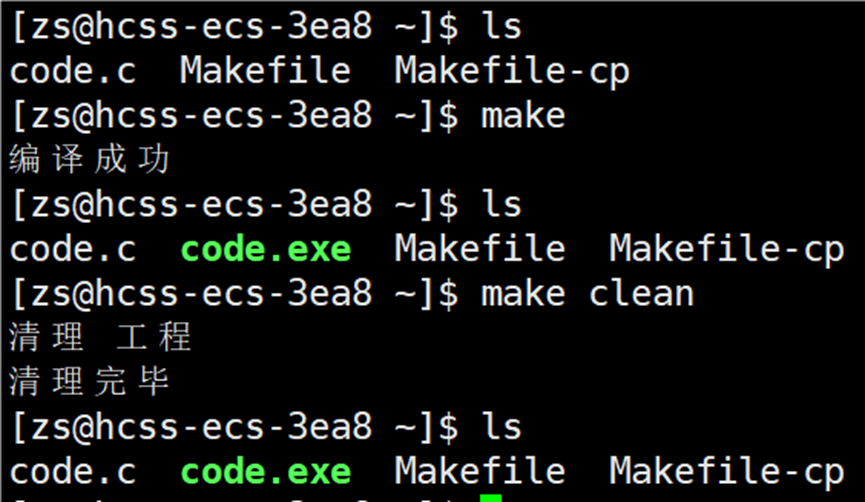
Makefile 不仅需要可以生成可执行文件的功能,也需要可以清理可执行文件的功能,所以需要清理,代码如下图所示:
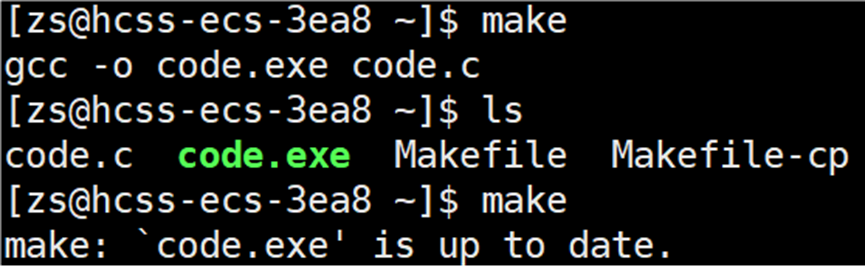
连续输入两次 make 指令
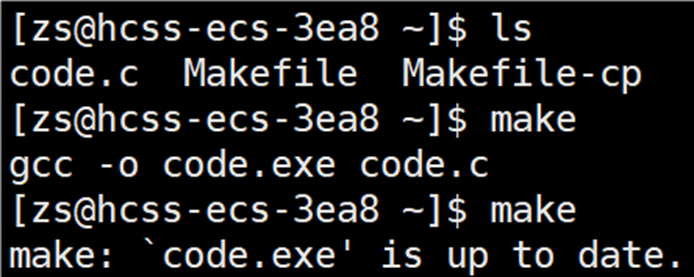
会显示当前的 code.exe 已经是最新,如果想要 make 指令能够执行,可以输入 make clean,这样就可以再次执行 make 指令。

由上图可以知道,clean 确实将生成的可执行文件给删除了,这样就简单的完成了 makefile 的构建和清理过程。
PHONY 是 makefile 提供的一个关键字。PHONY 是假的,伪造的的意思,它的作用是声明一个符号(符号的符号名可以随意命名,最好能直观知道它的功能),表明该符号是一个伪目标,伪目标也是目标文件,只是使用 .PHONY 修饰,以此来告知 make,该目标文件与其他目标文件不一样。既然伪目标也是目标,那么它也有自己的依赖关系和依赖方法。
从这个伪目标的结构,总结出以下几点:
•依赖关系必须存在,但是依赖文件列表可以为空
•依赖方法可以是任何 shell 命令
•clean 目标只是利用 make 的自动推导的能力,让它执行了 rm 命令。在构建工程的视角,看起来就是清理项目,本质就是删除不需要的临时文件
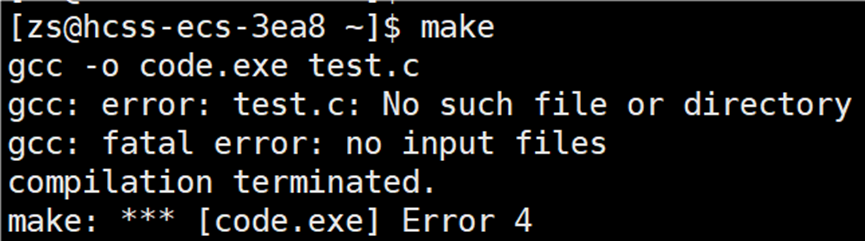
之前解析 makefile 文件的依赖关系和依赖方法时,都是直接输入 make 指令。但是解析 clean 文件的依赖关系和依赖方法时,为什么要输入 make clean 呢?为什么解析 code.exe 文件的依赖关系和依赖方法时,不输入 make code.exe 呢?其实输入 make code.exe 指令也可以,如下图所示:
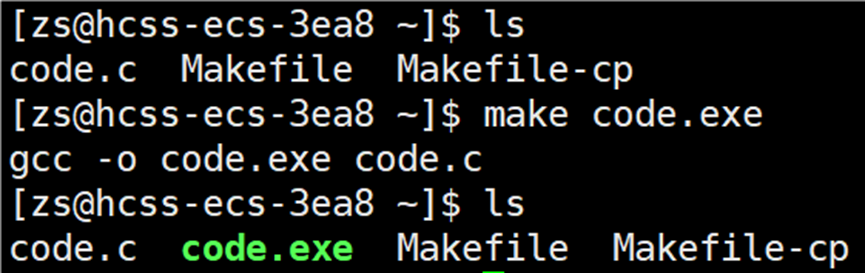
由此我们可以得出:make 命令后可以跟目标名,跟谁就解析谁的依赖关系和依赖方法。
为什么单独输入 make code.exe 指令,它只解析 code.exe 文件的依赖关系和依赖方法?输入make clean 指令,只解析 clean 文件的依赖关系和依赖方法,而不执行 code.exe 文件的依赖关系和依赖方法呢?因为 clean 和 code.exe 这两个推导链之间并没有依赖关系,clean 和 code.exe 推导链是一个独立的依赖关系和依赖方法,make默认只会推导一条完整的推导链。
但是为什么单独输入 make 指令,它只推导 code.exe 推导链,而不推导 clean 推导链呢?将clean 和 code.exe 的推导链交换位置。
输入make指令,结果如下图所示:

由此我们可以知道:make 默认只会推导第一个依赖关系对应的推导链。但是在实际使用中,通常将清理工程放在后面。
在前面曾提到 .PHONY 修饰的文件是一个伪目标文件,那么伪目标文件是什么?伪目标文件的本质功能是总是被执行。如何理解"总是被执行"?
当连续输入 make 命令时,命令行会显示 code.exe 已经是最新的。
不允许 make 指令根据依赖关系推导依赖方法了。
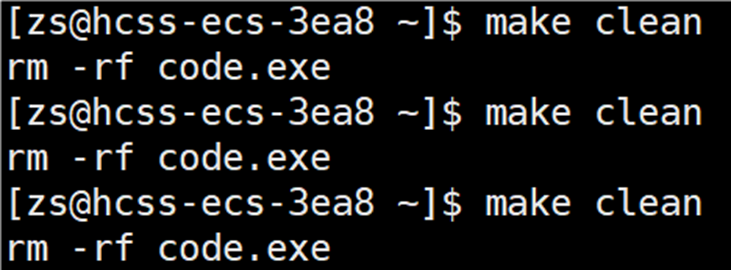
然而 make clean 可以反复被执行,如下图所示:
如果用 .PHONY 修饰 code.exe 文件,将 code.exe 声明成伪目标,再连续输入 make 指令,结果如下图所示:
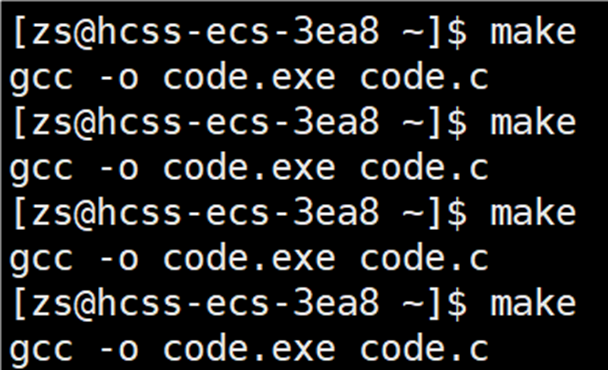
code.exe 目标文件也可以反复执行了。
为什么 clean 目标文件需要被 .PHONY 修饰?因为清理工作需要时刻执行,如果不清理程序运行的临时文件,可能会出现错误。
为什么 code.exe 目标文件就默认不需要被 .PHONY 修饰呢?因为在执行完 make 指令后,会生成code.exe 文件,再输入 make 指令后,会显示 code.exe 已经是最新版本,这也就表明了 code.c没有被修改,不需要重新生成一份新的 code.exe 文件。既然如此,如果 code.exe 文件被 .PHONY 修饰,不论 code.c 是否被修改,都会重新在再生成一份一模一样的 code.exe 文件,这样会造成不必要的浪费。所以 .exe 可执行程序不用 .PHONY 修饰,这样可以加速编译的效率。只有源文件发生更改才会重新编译生成新的 .exe 可执行程序。
既然 .PHONY 修饰的文件总是被执行的,那么 .PHONY 是怎么做到的呢?
我们知道一个文件的建立是有时间的,可以使用 stat 指令来查看文件的三个时间:access,modify,change
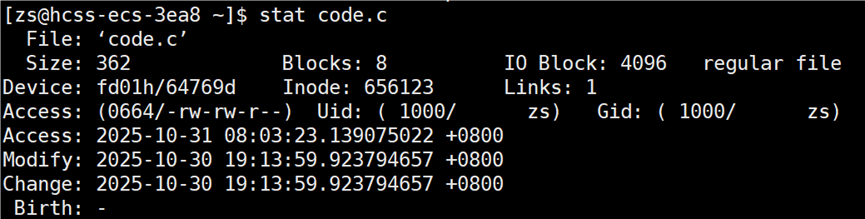
modify 表示文件新建或者内容被修改的最近时间。
源文件经过编译器后生成可执行文程序 code.exe,可执行程序也是文件,它也有自己的三个时间。
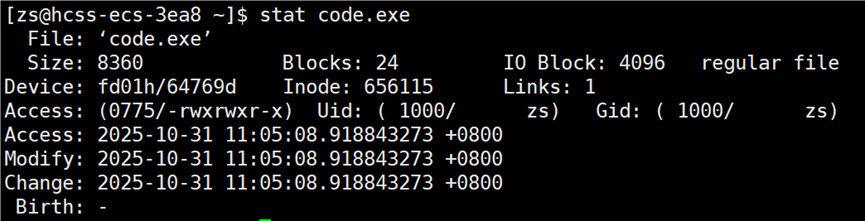
因为先有的源文件,再有的可执行程序,所以可执行程序的 modify 时间一定比源文件的 modify 时间更新。在时间轴上的表示情况如下所示:

一旦源文件的内容被修改,随即源文件的时间就会更新。重新编译,编译器识别到源文件的 modify 时间比当前可执行程序的 modify 时间更新,就会重新再次生成可执行程序,这样可执行程序的 modify 时间又比源文件的 modify 时间更新了。如果再次编译,编译器识别到当前可执行程序的 modify 时间已经比源文件的 modify 时间更新了,就不会再编译了。

总结:
源文件是否需要重新被编译,看源文件和可执行文件哪个文件的修改时间更新。
可执行程序的 modify 时间一定比源文件的 modify 时间更新。
如果源文件的 modify 时间更新,则源文件需要重新编译;如果可执行程序的 modify 时间更新,则源文件不需要重新编译
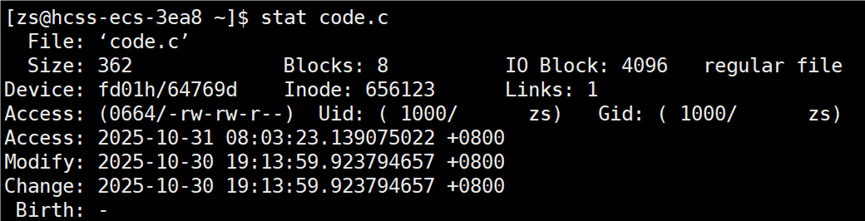
证明上述的总结是对的
code.c 的时间
code.exe 的时间
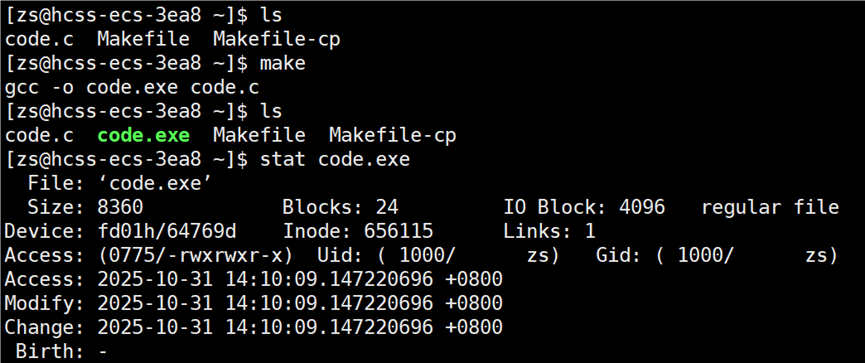
从两图的 modify 时间比较中可知,code.exe 的时间更新,所以再次编译 code.c 文件,编译不通过。

接下来打开 code.c 文件,修改文件中内容(增或删),再次查看 code.c 的时间。
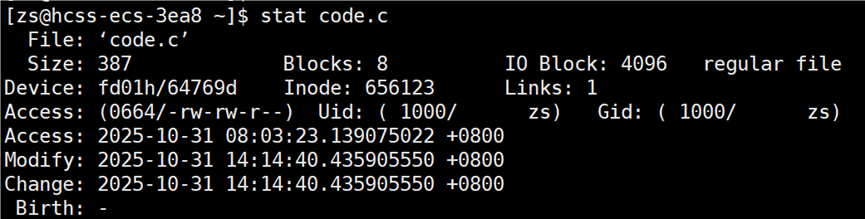
比较此时 code.c 和 code.exe 文件的 modify 时间,源文件的 modify 时间更新,允许再次编译源文件。

再次查看 code.exe 的三个时间:
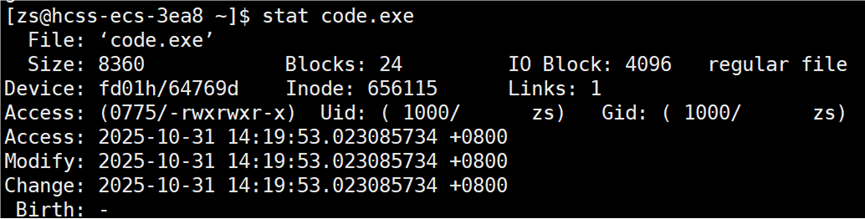
现在可执行程序的 modify 时间又比源文件的 modify 时间更新了。
前面更新 code.c 文件的时间,是打开该文件修改文件中的内容,有没有一种方法不用打开文件,就能将文件的时间更新到当前的最新时间呢?touch 已存在的文件名 指令,功能:更新已经存在的文件的三个时间。
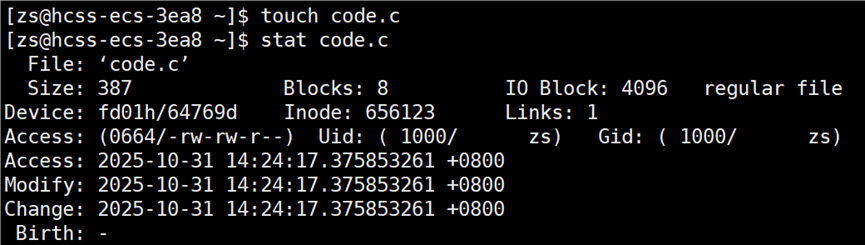
现在源文件的 modify 时间又比可执行程序的 modify 时间更新,允许再次编译源文件
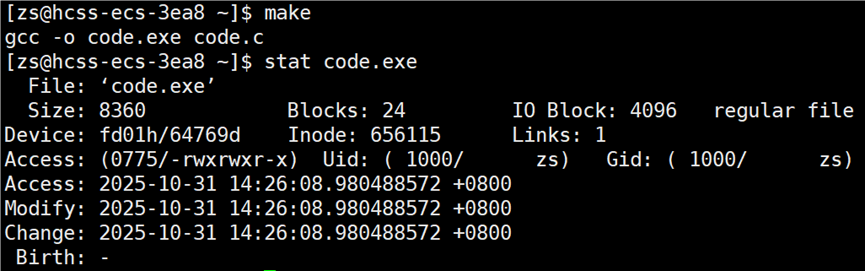
接下来再使用 .PHONY 修饰 code.exe 文件,就可以反复编译源文件了。
所以 .PHONY 如何做到由它修饰的文件总是被执行的?让编译器或者对应的命令忽略 modify 时间(有些命令是忽略文件的时间的,如rm命令)。
ACM 时间
acm 时间就是前面说的三个时间:access,modify,change。
modify 和change都是修改的意思,如何理解change时间?我们知道文件 = 文件内容+文件属性,modify 时间表示最近一次修改文件的内容的时间,change 时间表示最近一次修改文件的属性的时间。
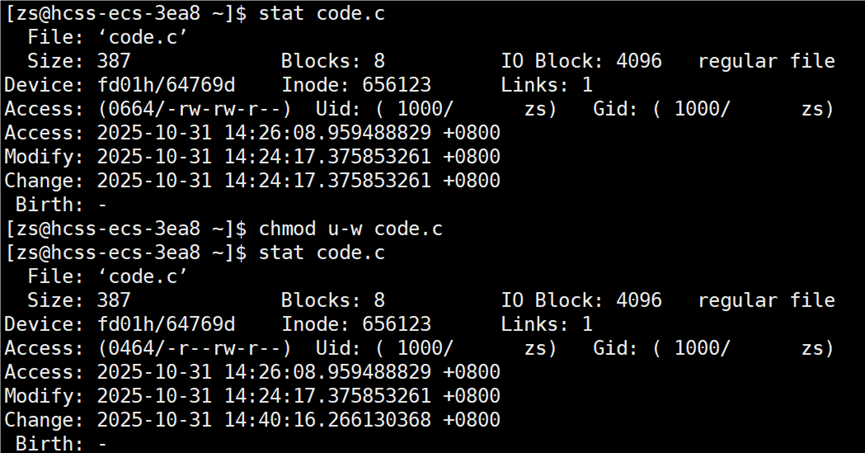
更改文件的权限,即更改文件的属性,文件的 change 时间也就更新了。
接下来打开 code.c 文件,修改文件中的内容,再次查看 code.c 的 acm 时间
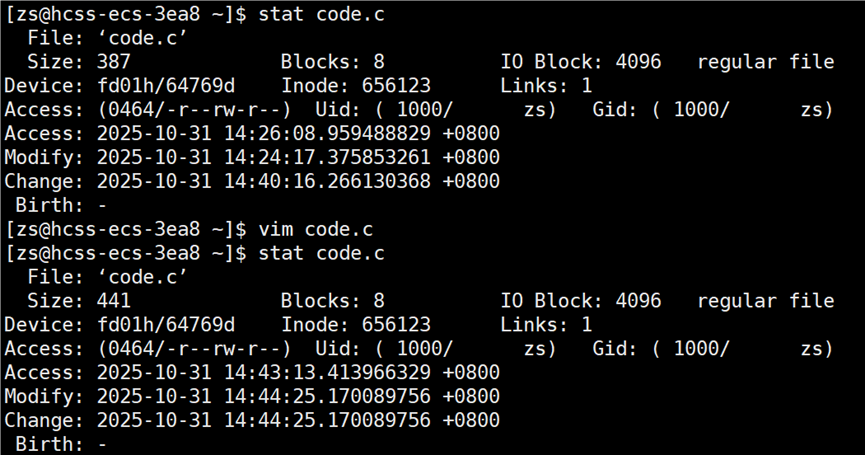
modify 和 change 时间都被修改了,为什么 change 时间也更新了?因为修改文件的内容,会影响文件的大小,文件的大小也是文件属性,并且 modify 时间也是文件属性,所以 change 时间更新了。
access 时间表示文件最近被访问的时间。怎样叫做访问文件呢?我们之前一直输入的 cat/stat 指令就是在访问文件。
看上图,起初输入 cat 指令,查看 code.c 文件中的内容,再输入 stat 指令查看文件的时间,发现access 时间被修改;然而再次输入 cat 指令,查看 code.c 文件的内容,再次输入 stat 指令查看文件的时间,会发现 access 时间没有被修改。为什么一开始访问文件时 access 时间被修改了,再次访问 code.c 文件时 access 时间却没有被修改呢?
一个文件的内容/属性被更改时,是需要刷新到磁盘上的。但是 linux 系统中这么多的文件,当我们新建文件时,修改文件的内容/属性,查看文件的内容/属性的次数一定会比修改文件的内容/属性的次数更多,查文件的比重是高于该文件的比重的(修改文件的前提是查看文件,无论对文件做什么,第一步都是查看文件)。并且 access 时间表示文件最近被访问的时间,每次访问文件,文件的 access 时间都会刷新到磁盘。如果我们每次访问文件,都会马上修改文件的时间,读写磁盘,如果频繁访问文件呢?岂不是要反复修改文件的时间,读写磁盘,这样肯定会增加访问磁盘的次数(磁盘是一个外设,效率低下),如此会降低操作系统的效率(时间都用到刷新磁盘上了)。
所以访问文件时,访问特定的次数之后(次数与操作系统的内核有关),才会更新一次access时间。至于上图中 access 时间更新了,是因为恰好访问到了特定的次数。
makefile 的语法
往 code.c 文件中写入以下代码:
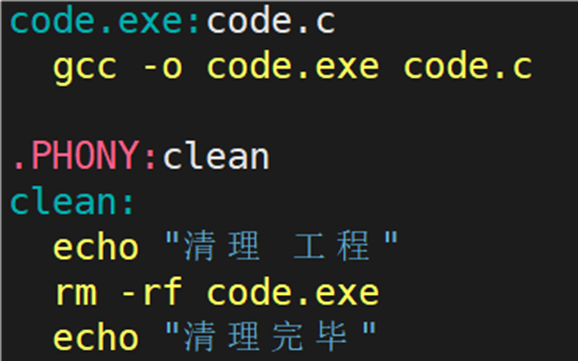
输入 make 指令,可以发现 makefile 中的内容会被显示在终端上
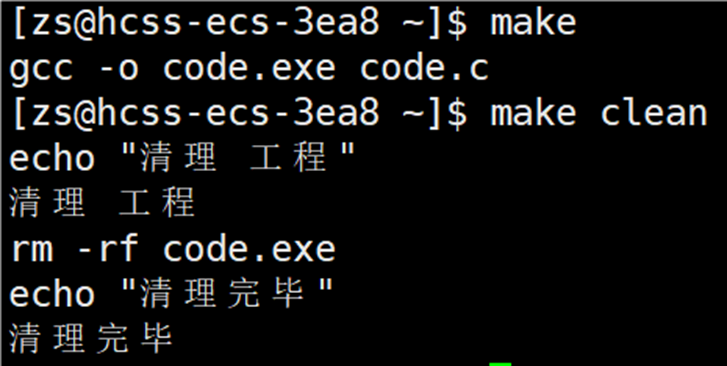
如果想要禁止命令显示在终端上,可以在 makefile 文件的依赖方法的前面加上@,如下图所示:
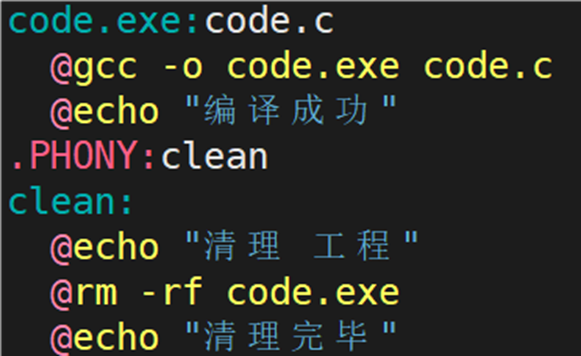
效果:
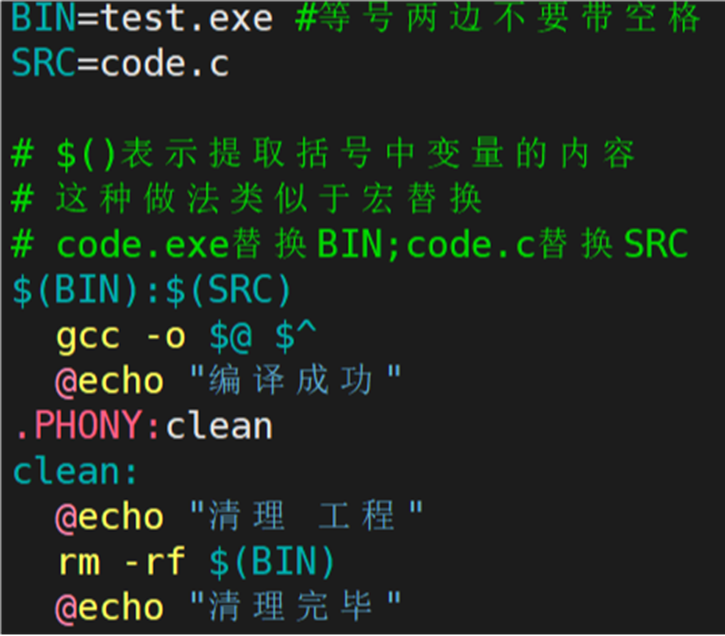
当前的 Makefile 文件编译的是 code.c 文件,如果之后想要编译其它.c文件呢?岂不是还要修改 Makefile 涉及 .c 文件的部分,这样效率也太低了。可以在 Makefile 文件的开头处定义变量,如下图所示:
如果想要将 code.c 文件编译成 test.exe ,像上面这样写是否有问题。查看 make 指令解析的结果:
为什么 code.c 编译的结果依旧是 code.exe ?因为依赖关系使用变量取代,但是依赖方法并没有使用变量取代。若想要达成目的,需要用变量取代依赖方法中的某些地方,如下图所示:
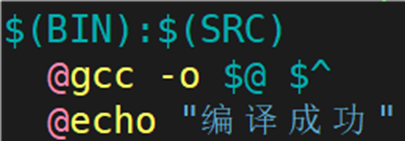
在 makefile 中,@ 和 ^ 中的 @ 和 ^ 是一个特殊的内置变量,@ 和 ^ 是变量, 表示取变量中的内容,@表示对应依赖关系的目标文件,\^表示对应依赖关系的依赖文件列表。makefile在解析make语法时,会将@解析成目标文件,$^解析成依赖文件列表
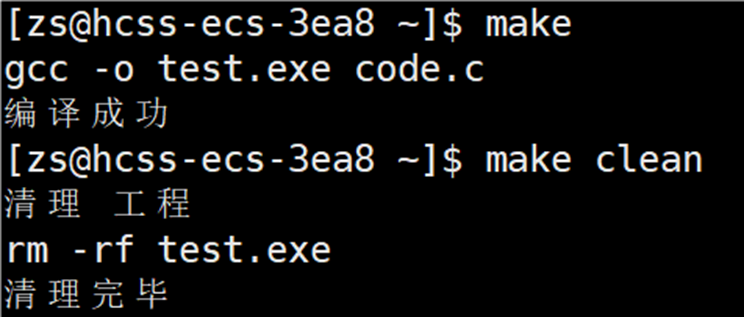
为了更好的理解 @ 和 ^,将 Makefile 文件中的内容更改成下图所示,便于看到命令的回显:
演示结果:
之前操作的都是一个源文件,如果有多个源文件呢?将 code.c 重命名为 main.c ,创建100个源文件,如何创建100个以 .c 结尾源文件,方法:touch xxx{1..100}.c,如下图所示:

如果要删除这100个源文件,rm src{1..100}.c 即可。

这100多个源文件应该怎么编译?将所有的源文件翻译成对应的 .o 文件,再将所有的 .o 文件进行链接形成可执行程序。
如此一来需要修改 Makefile,问题是依赖文件列表应该怎么写?一个个写,一直写到100?src1.c,src2.c,src3.c,......,src100.c。正确写法为:SRC=(shell ls \*.c)。** **(shell ls *.c) 的功能:罗列出当前目录下的所有以 .c 为后缀的文件。
测试代码:
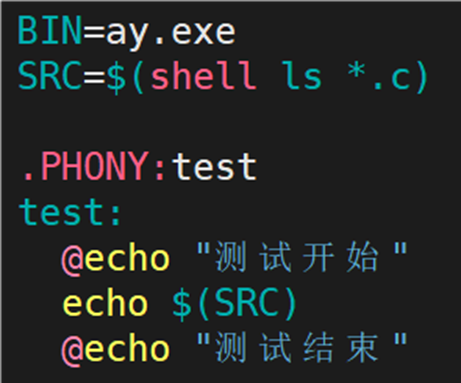
测试结果:

这个方法还不够好,推荐使用该方法:**SRC=$(wildcad *.c)。**wildcad 是一个函数,功能:获取当前目录下所有以 .c 为后缀的文件。
测试结果:

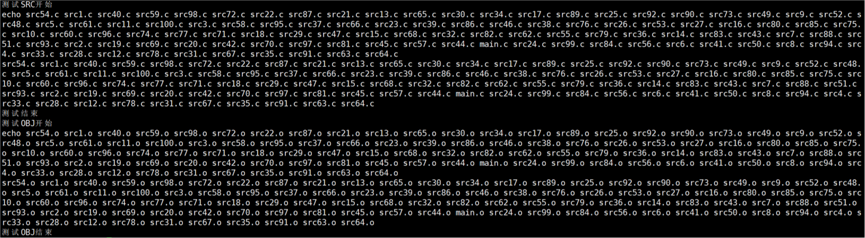
知道了依赖文件列表应该怎么写之后,怎么将所有的.c文件编译成.o文件呢?怎么一步到位呢?我们可以再定义一个 OBJ 变量:OBJ=$(SRC:.c=.o) 。 功能:将 SRC 的所有同名 .c 替换成为 .o 形成目标文件列表。
测试结果:
将所有的 .o 文件链接形成可执行程序,方法如下所示:
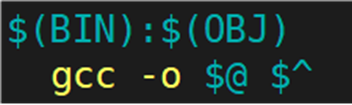
这样写就可以了吗?不可以。现在仅仅只是将所有的 .o 文件生成可执行程序,但是各个 .o 文件如何编译,并没有交待清楚。因为 .o 文件在当前目录下并不存在,需要将所有的 .c 文件编译成 .o 文件。写法为:%.o:%.c。 %是makefile中的一个解析符,%.c 展开当前目录下所有的 .c;%.o: 同时展开同名 .o。
之前将 .c 文件编译成 .o 文件时,指令为:gcc -c src.c -o src.o,其实指令还可以写成:gcc -c src.c,编译器会自动形成同名的 .o 文件。所以 %.o:%.c 的依赖方法可以写成:gcc -c \<。** **< 表示对展开的依赖 .c 文件,一个一个的交给编译器。
为了便于测试,代码写成下图所示:
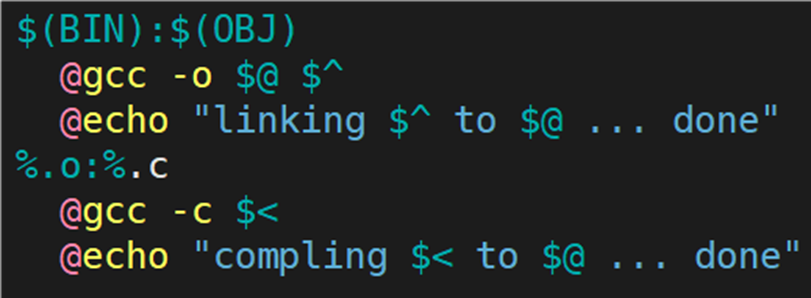
测试结果:

增加清理工程,清理中间产生的临时文件,也就是 .o 文件和可执行程序。代码如下所示:
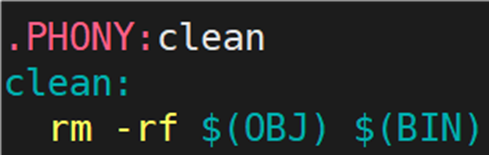
演示结果:
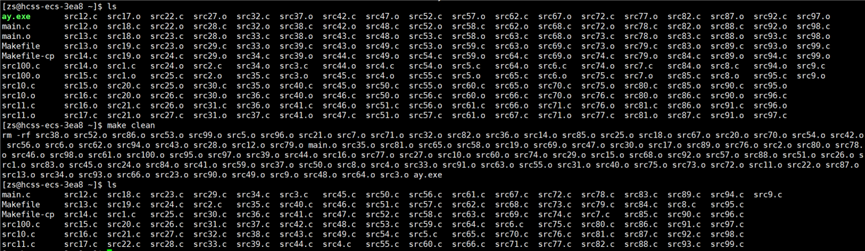
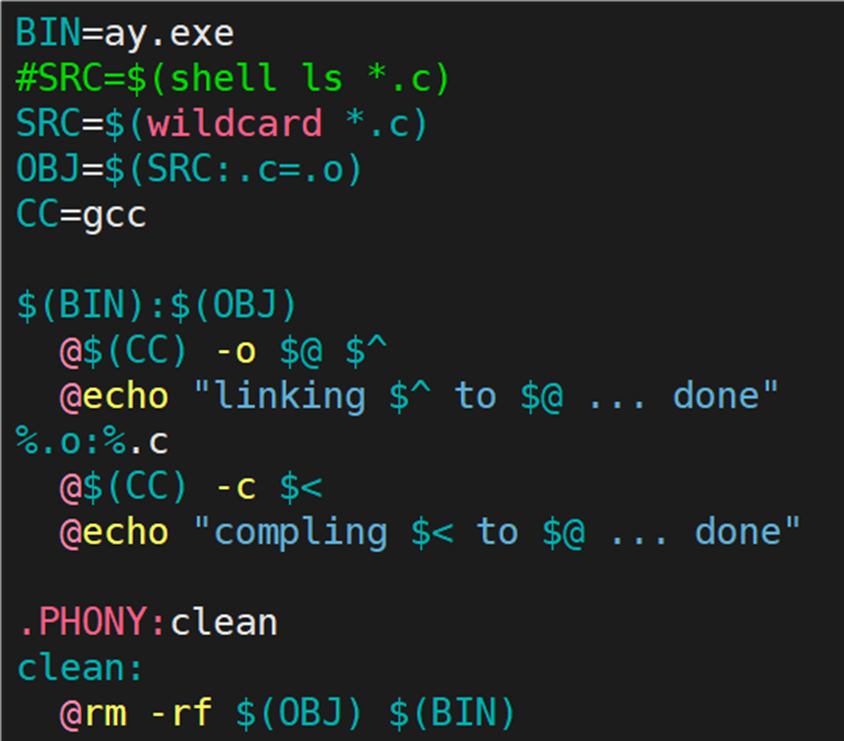
当前的 makefile 只能用于 C 语言,如果想让它用于 C++,岂不是还要一个个将 gcc 更改为 g++?我们可以定义一个变量 CC 用于控制编译器。
最终我们实现的 makefile 如下图所示: