标题:EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
作者:Linrui Tian、Qi Wang、Bang Zhang、Liefeng Bo
单位:Institute for Intelligent Computing, Alibaba Group(阿里巴巴集团智能计算研究所)
发表:ECCV 2024
项目链接 :https://humanaigc.github.io/emote-portrait-alive/
论文链接 :https://arxiv.org/abs/2402.17485v3 / https://arxiv.org/pdf/2402.17485
代码链接 :https://github.com/HumanAIGC/EMO (暂无代码)
关键词:扩散模型(Diffusion Models)、视频生成(Video Generation)、会说话的头部(Talking Head)、音频到视频(Audio2Video)、弱条件(Weak Conditions)、表情肖像视频(Expressive Portrait Videos)、身份保持(Identity Preservation)
在数字人、虚拟交互等领域,音频驱动的肖像视频生成(尤其是 "会说话的头部" 视频)一直是研究热点。传统方法常依赖 3D 中间模型或面部特征点等强约束,导致生成视频表现力不足、自然度欠佳。来自阿里巴巴集团的团队提出了EMO(Emote Portrait Alive)框架,通过直接的音频到视频(Audio2Video)扩散模型,在弱条件引导下实现了高表现力、高真实感的肖像视频生成。
一、研究背景与问题提出
1.1 领域现状:扩散模型推动生成式视觉技术革新
扩散模型(Diffusion Models)已彻底改变生成式模型的格局,在高保真图像生成(如 Stable Diffusion)、视频合成等领域展现出卓越能力。其中,"会说话的头部"(Talking Head)视频生成作为人机交互、虚拟主播等场景的核心技术,旨在根据输入音频合成与音频同步的头部视频,需同时满足:
- 唇形与音频精准同步;
- 面部表情丰富且符合音频情感基调;
- 头部姿态自然,无帧间跳跃;
- 人物身份在视频中保持一致。
1.2 传统方法的局限性
现有 Talking Head 方法主要存在以下瓶颈:
- 依赖强约束,牺牲表现力:多数方法通过 3D 面部网格(如 3DMM)、2D 面部特征点或预定义姿态序列引导生成,虽提升了局部保真度(如唇同步),但限制了面部表情的丰富性(如自发手势、细微情绪表达丢失);
- 音频 - 视觉映射模糊:音频到面部动作(表情、姿态)的映射存在 "一对多" 歧义,传统方法难以捕捉两者间动态、细微的关联;
- 长视频生成困难:多数模型受限于固定帧数量,无法生成任意时长的视频,且帧间连续性、跨片段一致性难以保证;
- 身份一致性差:部分方法生成的视频中,人物面部特征易随帧变化,导致身份失真。
1.3 本文核心目标
提出EMO 框架,通过以下设计解决上述问题:
- 摒弃 3D 中间模型或预定义姿态等强约束,采用 "弱条件" 引导生成;
- 基于扩散模型构建直接的 Audio2Video 生成路径,捕捉音频 - 视觉的细粒度关联;
- 引入多模块保证帧间连续性、身份一致性与长视频生成能力;
- 在真实感与表现力上超越现有 SOTA 方法,支持说话、唱歌等多场景。
二、相关工作梳理
为更好理解 EMO 的创新点,需先明确领域内两类核心相关工作的优劣:
| 类别 | 代表方法 | 核心思路 | 优势 | 劣势 |
|---|---|---|---|---|
| 扩散模型 | Stable Diffusion、AnimateDiff、DiT | 基于 UNet/Transformer 架构,通过迭代去噪生成图像 / 视频 | 高保真、强泛化性,支持文本 / 图像引导 | 视频生成需额外处理时间维度,Audio2Video 映射需专门设计 |
| 音频驱动 Talking Head | Wav2Lip(基于视频)、SadTalker(基于单图)、DreamTalk(基于扩散) | 基于视频:编辑输入视频唇形;基于单图:通过 3D 中间模型生成视频 | Wav2Lip 唇同步好;SadTalker 姿态可控 | Wav2Lip 头部姿态固定;SadTalker 依赖 3DMM,表现力弱;DreamTalk 仍用 3DMM 系数,自然度不足 |
EMO 的关键突破在于:首次在单图输入的 Talking Head 任务中,完全摒弃 3D 中间模型,基于扩散模型直接实现 Audio2Video 生成,并通过弱条件平衡稳定性与表现力。
三、EMO 框架核心技术详解
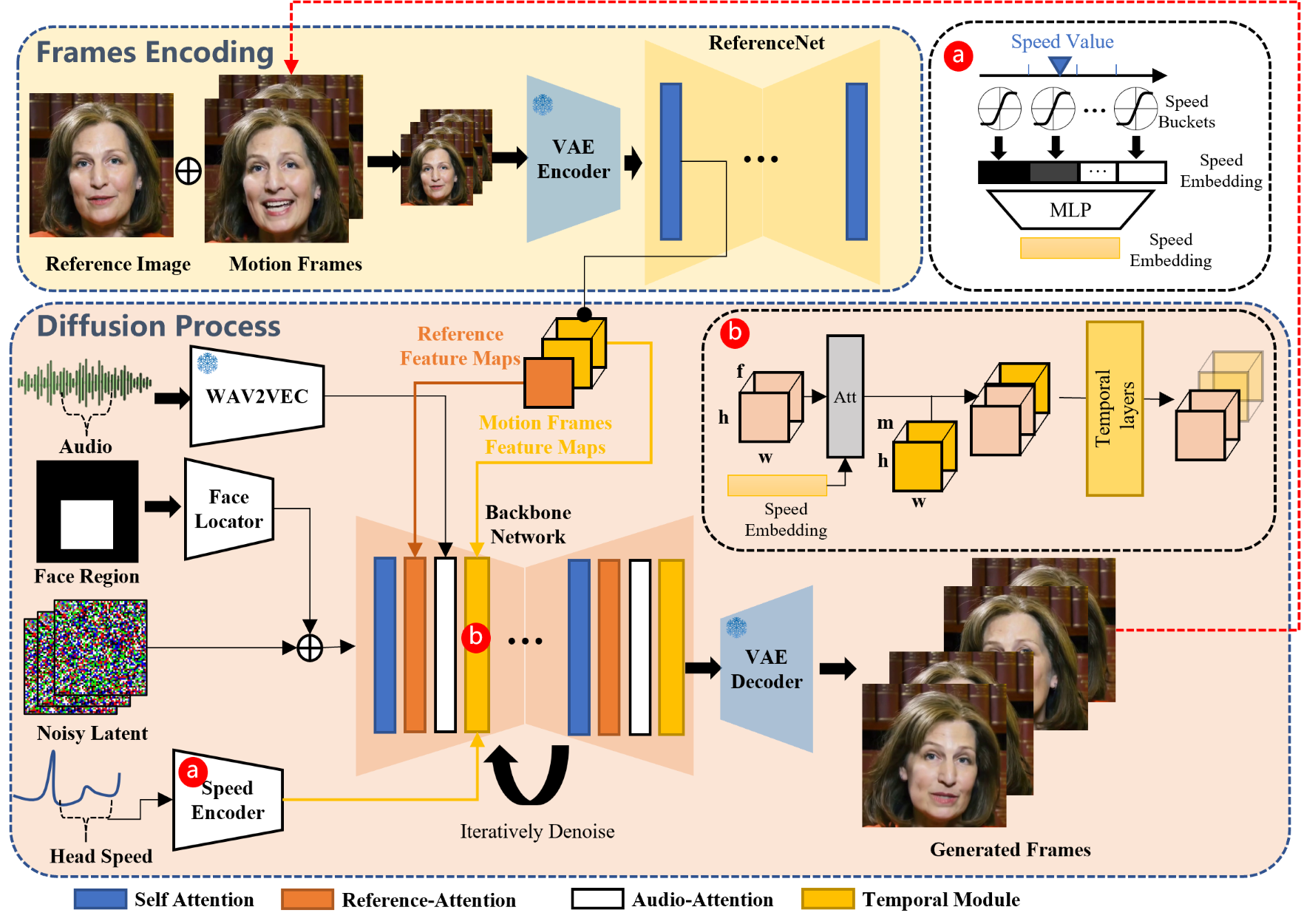
EMO 的整体架构分为帧编码阶段 与扩散生成阶段,核心目标是:以单张参考肖像图和音频为输入,生成任意时长、表情丰富、身份一致的视频。其网络 pipeline 如图 2 所示:
3.1 基础:基于 Stable Diffusion 的视频生成扩展
EMO 以Stable Diffusion(SD)1.5为基础框架,其核心是将图像生成扩展到视频领域:
- ** latent 空间降维 **:通过变分自编码器(VAE)将图像映射到低维 latent 空间(
),降低计算成本;
- 扩散去噪过程 :遵循 DDPM/DDIM 逻辑,向 latent
3.2 核心模块设计
EMO 通过 5 个关键模块解决 "表现力 - 稳定性 - 身份一致性" 三角问题,以下逐一解析:
模块 1:Backbone Network(骨干网络)------ 视频生成的核心
骨干网络基于 SD 1.5 的 UNet 架构改造,核心改进是:
- 移除文本注意力,替换为参考注意力:SD 原有的文本交叉注意力层被改为 "参考注意力层",输入来自 ReferenceNet 的参考图特征,确保生成视频与参考图身份一致;
- 嵌入时间模块(Temporal Modules) :借鉴 AnimateDiff,将输入特征图
模块 2:ReferenceNet------ 身份一致性保障
ReferenceNet 与骨干网络结构完全一致,且共享 SD UNet 的预训练权重,其作用是:
- 输入单张参考肖像图,提取各层自注意力输出的 "身份特征图";
- 在骨干网络去噪过程中,参考注意力层将 latent 特征与 ReferenceNet 的身份特征图进行交叉注意力计算,强制生成帧的面部特征与参考图对齐;
- 额外支持 "运动帧输入":生成长视频时,将前一段视频的最后
模块 3:Audio Layers(音频层)------ 视频生成的 "驱动力"
音频层的核心是建立 "音频 - 面部动作" 的细粒度映射,设计细节包括:
- 音频特征提取 :采用预训练的 wav2vec 模型,提取音频序列中每个帧f的特征
- 上下文感知的音频特征拼接 :考虑到面部动作(如说话前吸气)依赖上下文音频,将当前帧
- 音频注意力注入 :在骨干网络的每个参考注意力层后,添加 "音频注意力层",通过交叉注意力将音频特征
模块 4:Face Locator(面部定位器)------ 弱约束下的位置稳定
为避免生成视频中面部位置偏移,但又不限制头部姿态灵活性,EMO 设计了 "弱约束" 的面部定位器:
- 输入:面部边界框掩码M:M是视频片段中所有帧的面部边界框(bbox)的并集,由 MediaPipe 检测得到;
- 轻量级编码与注入 :通过轻量级卷积层将M编码为 "位置特征",并添加到带噪声的 latent
- 弱约束优势:如图 7 所示,输入不同大小的M可控制头部运动范围(如宽M允许头部左右摆动,高M允许点头),而统一白色掩码(无位置引导)则允许面部在任意位置生成,兼顾稳定性与灵活性。

模块 5:Speed Layers(速度层)------ 跨片段运动一致性
长视频生成中,不同片段的头部运动速度易出现突变(如前一段慢、后一段快),Speed Layers 通过 "弱速度约束" 解决此问题:
- 速度量化与嵌入:
- 计算每帧头部旋转速度
- 将速度范围划分为
- 将
- 类似音频特征,拼接前后
- 计算每帧头部旋转速度
- 速度注意力注入:在时间模块中,将F与时间维度特征进行交叉注意力计算,引导当前片段的运动速度与目标速度匹配(如说话场景速度 0.1-1.0,唱歌场景 1.0-1.3);
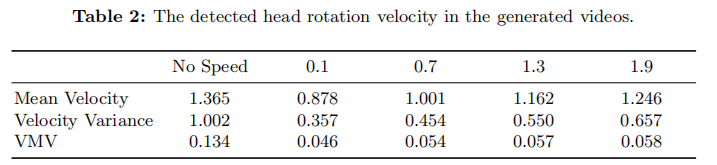
- 弱约束验证:如表 2 所示,加入 Speed Layers 后,"速度方差"(单片段内速度波动)和 "平均速度方差(VMV)"(跨片段速度波动)显著降低,且可通过调整目标速度控制运动快慢(速度 > 1.5 会导致不自然抖动)。
3.3 分阶段训练策略
为避免各模块间的干扰(如音频与速度特征争夺对运动的控制权),EMO 采用三阶段训练,具体流程如下:
阶段 1:图像预训练
训练模块:Backbone、ReferenceNet、Face Locator
输入数据:单帧图像(参考图 + 目标帧)
目标:夯实身份一致性与面部位置稳定性
阶段 2:视频训练
训练模块:加入 Temporal Modules、Audio Layers
输入数据:帧连续视频(
= 运动帧,
= 生成帧,实验中
,
)
目标:学习音频 - 视觉映射与帧间连续性
阶段 3:速度训练
训练模块:加入 Speed Layers,仅训练 Temporal Modules 与 Speed Layers
输入数据:同阶段 2
目标:保证跨片段速度一致性,避免音频驱动能力被削弱
关键设计:阶段 3 不训练音频层,因为音频是面部动作的核心驱动(如表情、唇形),若同时训练音频与速度层,模型可能优先依赖速度信号,导致音频 - 动作同步性下降。
四、实验验证:定量与定性双重证明
4.1 实验设置
数据集
- 训练集:250 小时互联网语音 / 唱歌视频(多语言、多表情)+ HDTF(15.8 小时高保真 Talking Head 视频)+ VFHQ(16k 高分辨率无音频视频,仅用于阶段 1);
- 测试集:HDTF 的 10%(无身份重叠)+ 1k 个 4 秒互联网视频片段(高表情多样性、大头部运动范围);
- 预处理:视频裁剪为 512×512,30 FPS;用 MediaPipe 标注面部 bbox,用 6DoF 姿态计算头部速度。
对比方法
选取 4 类 SOTA 方法:
- Wav2Lip(视频基,唇同步优先);
- SadTalker(单图基,3DMM 引导);
- DreamTalk(扩散基,3DMM 系数生成);
- MakeItTalk(单图基,特征点引导);
- 额外定性对比 Diffused Heads(扩散基,但依赖绿色背景,帧间误差累积)。
评价指标
- 帧级质量:FID(越低越好,衡量生成帧与真实帧的分布差异);
- 身份一致性:F-SIM(越高越好,生成帧与参考图的面部特征相似度);
- 视频级质量:FVD(越低越好,衡量视频动态一致性);
- 唇同步:SyncNet(越高越好,音频与唇形的同步度);
- 表现力:E-FID(越低越好,本文提出,衡量生成表情与真实表情的分布差异)。
4.2 定量结果:全面超越 SOTA
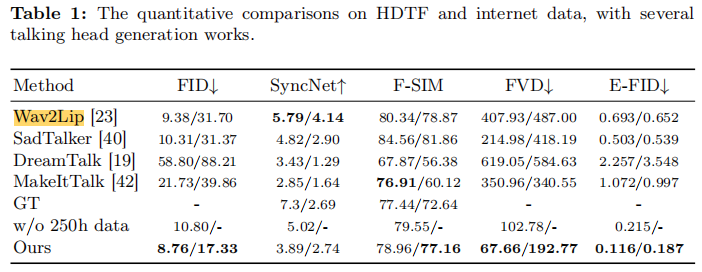
如表 1 所示,EMO 在关键指标上显著优于对比方法:
- FID/FVD:EMO 在 HDTF 测试集上 FID=8.76(最低),FVD=67.66(最低),说明帧质量与视频连续性最优;
- E-FID:EMO 的 E-FID=0.116(HDTF)/0.187(互联网数据),远低于 SadTalker(0.503/0.539),证明表现力最强;
- SyncNet:虽低于 Wav2Lip(Wav2Lip 专门优化唇同步),但 EMO 在表情与姿态多样性上弥补了这一差距;
- 消融实验:无 250 小时数据时,EMO 仍保持低 FVD(102.78)与 E-FID(0.215),证明框架鲁棒性。
4.3 定性结果:表现力与多样性突出
1. 与 SOTA 方法的视觉对比
如图 3 所示,EMO 的优势体现在:
- Wav2Lip:唇形模糊,头部姿态固定,无眼部运动;
- DreamTalk:面部风格失真,表情与头部运动僵硬;
- SadTalker:表情单一,头部运动范围小;
- EMO:唇形清晰,表情丰富(如微笑、挑眉),头部姿态自然(如侧头)。

2. 多风格肖像的适配能力
EMO 虽仅在真实风格数据上训练,但可适配动漫、3D 等多种风格的参考图(如图 4)。同一音频输入下,不同风格的生成视频均保持唇形同步与身份一致,证明其泛化性。

3. 长视频与强情感音频的生成能力
如图 5 (上侧)所示,EMO 可生成 1 分钟的长视频,且在高情感音频(如唱歌)驱动下,能持续生成丰富表情(如张嘴、仰头);与 Diffused Heads(图 6,下侧)相比,EMO 无帧间误差累积,分辨率更高。


4. 用户研究:主观体验最优
20 名参与者(男女各半,20-60 岁)对 "唇同步" 与 "生动性" 打分(1-5 分),结果显示:
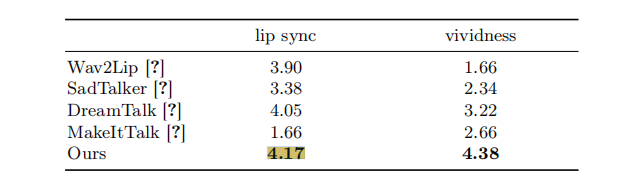
- EMO 唇同步得分 4.17,生动性得分 4.38,均为最高;
- 生动性得分远超其他方法(如 SadTalker 为 2.34,DreamTalk 为 3.22),证明用户对 EMO 的表现力认可度最高。
五、局限性与未来方向
5.1 现有局限性
- 无关身体部位生成:当音频情感强烈时,模型可能误生成手部、躯干等部位(如下图),原因是训练数据中仅 3% 的帧包含手部,数据不足导致生成失真;
- 字幕类伪影:部分互联网训练数据含字幕,导致生成视频中出现类似字幕的纹理(如下图),此问题在 T2I 模型中也普遍存在;
- 音频驱动的不确定性:模型仅依赖音频推导表情,可能生成与用户预期不符的表情(如欢快音频生成严肃表情);
- 推理速度慢:在 A100 GPU 上,生成 12 帧(1 个片段)需 18 秒(40 步去噪),慢于非扩散方法(如 SadTalker)。

5.2 未来研究方向
- 引入身体部位约束:借鉴 Face Locator 的思路,用掩码控制身体部位生成,避免无关区域失真;
- 字幕伪影去除:在训练中加入字幕检测与掩码,或在推理阶段用后处理模型去除字幕纹理;
- 情感控制机制:添加文本或标签输入(如 "开心""愤怒"),引导模型生成预期表情,增强可控性;
- 推理加速:通过模型压缩(如蒸馏)、量化或优化扩散步骤(如减少去噪步数),提升生成速度;
- 多模态融合:结合文本(如 "挥手")、姿态(如预定义头部角度)等多模态输入,扩展应用场景(如虚拟主播互动)。
六、总结:EMO 的核心贡献与领域价值
EMO 作为首个完全摒弃 3D 中间模型的单图 Audio2Video Talking Head 框架,其核心贡献可概括为三点:
- 方法论创新:提出 "弱条件引导的扩散生成" 范式,通过 Face Locator 与 Speed Layers 平衡稳定性与表现力,避免强约束对创造力的限制;
- 技术突破:设计 ReferenceNet 保障身份一致性,Audio Layers 建立细粒度音频 - 视觉映射,Temporal Modules 支持长视频生成,形成完整的技术闭环;
- 性能领先:在定量指标(FID、FVD、E-FID)与定性体验(用户研究)上全面超越 SOTA,支持多风格、长时长、强情感场景,为虚拟交互、数字人等领域提供核心技术支撑。
EMO 的局限性也为后续研究指明了方向:如何在扩散模型的高表现力基础上,进一步提升可控性与推理速度,将是 Talking Head 领域的关键探索点。