作者:高玉龙(元泊)
背景介绍
当用户使用 App 时产生不好的体验,问题往往出现在以下场景:
- 打开复杂页面时出现黑屏/白屏延迟
- 列表滑动时偶发性卡顿
- 图片加载时界面响应滞后
- 网络请求密集时出现操作卡死等现象
这些场景不仅出现在低端设备上,在中高端机型中同样存在。如果主线程无法响应用户的交互就会造成卡顿,卡顿时间比较长是比较影响 App 的功能和用户体验的。在移动应用开发中,卡顿问题也始终是影响用户体验的核心痛点。
通常情况下,导致主线程阻塞并引发卡顿的原因主要有以下几种:
- 繁重的 UI 渲染:当界面包含复杂的视图层级、大量的图文混排内容时,计算布局和绘制到屏幕上的工作量会急剧增加,超出单次刷新周期的处理能力。
- 主线程同步网络请求:在主线程中发起同步的网络调用,意味着整个应用必须等待网络数据返回后才能继续执行,期间无法响应任何用户操作。
- 大量的文件读写(I/O):在主线程上直接进行大规模的数据读取或写入操作,例如读写数据库或本地文件,会因为磁盘速度的限制而消耗大量时间。
- 高负荷的计算任务:将复杂的算法或大量数据的处理逻辑直接放在主线程执行,会导致 CPU 持续处于高占用状态,无暇顾及 UI 事件。
- 线程锁使用不当:当主线程需要等待其他线程释放某个锁资源时,它会被挂起,如果等待时间过长,便会造成卡顿。在极端情况下,不同线程间的相互等待还会引发"死锁",导致应用彻底无响应。
由于这些问题的偶发性和环境依赖性,传统的线下调试手段往往难以奏效。为了能够精确、高效地定位并解决这些线上卡顿,我们进行一些卡顿监控技术的探索。
主流卡顿监控方案
在 iOS 开发中,以下是几种常见的主流卡顿监控方案:
- Ping 线程方案
- FPS 监控方案
- RunLoop 监控方案
Ping 线程方案简介
Ping 线程方案的核心思想是:
- 创建一个子线程,通过子线程来"探测"主线程的响应能力。
- 子线程每次 ping 主线程时设置标记位为 YES,然后派发任务到主线程中,主线程把标记位设置为 NO。
- 子线程 sleep 指定时间,超时后判断标记位是否设置为 NO,如果没有说明主线程发生了卡顿。
如下图所示:
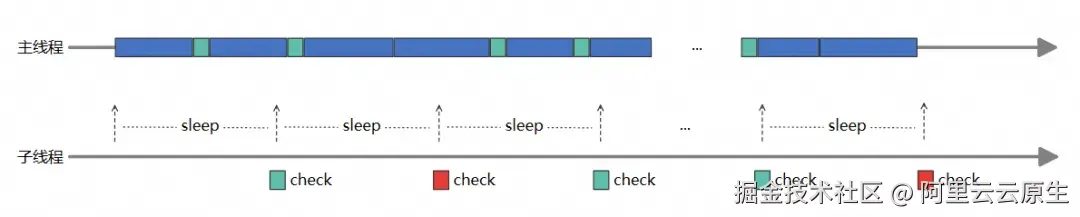
关键实现步骤:
-
创建子线程:启动一个独立的监控线程。
-
定时派发任务:子线程定期向主线程派发一个简单的任务,并设置一个等待标记。
-
等待主线程响应:主线程执行该任务时,会回调子线程,并清除等待标记。
-
超时判断:如果子线程在派发任务后的一小段时间内,发现等待标记仍未被清除,则判定主线程卡顿。
-
捕获与上报:执行堆栈捕获和上报流程。
Ping 线程的方案逻辑相对比较简单,也比较容易理解。但精度较差,Ping 之间可能存在漏查的情况。同时,Ping 线程会不停唤醒主线程 RunLoop,也会存在一定的性能损耗。
FPS 监控方案简介
通常情况下屏幕会保持 60Hz/s 的刷新速度(新的 iOS 设备甚至会保持 120Hz/s 的刷新速度),每次刷新时会发出一个屏幕刷新信号,CADisplayLink 允许开发者注册一个与刷新信号同步的回调处理。
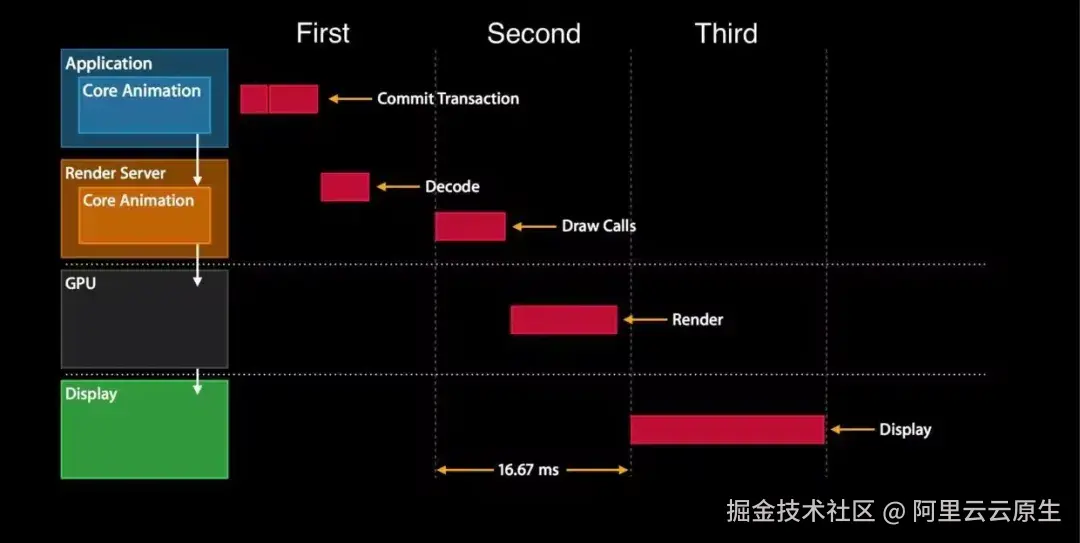
我们可以通过计算它 1 秒内调用多少次来查看界面的流畅度。虽然 CADisplayLink 更轻量,但需要在 CPU 稍微清闲时才能够回调,严重卡顿的堆栈获取不一定及时,并且就算 50fps 以下通过肉眼来看也是连贯的。所以,简单的通过监控 FPS 很难确定是否出现了卡顿问题。
RunLoop 方案简介
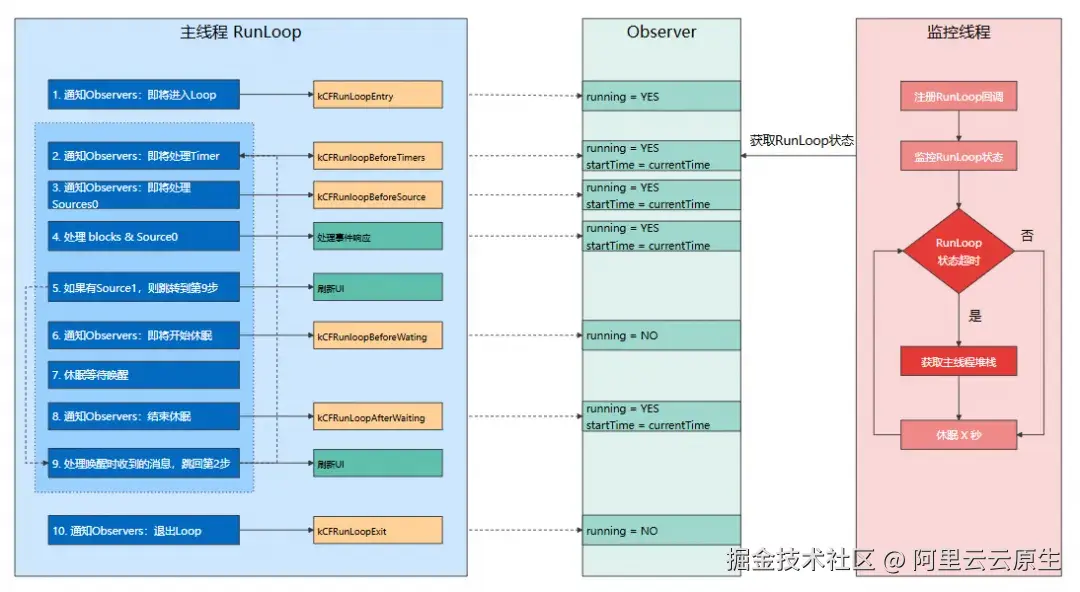
基于 RunLoop 的监控方案,是目前比较主流的可用于生产环境的监控方案。其原理是利用 CFRunLoopObserver 来观察主线程 RunLoop 的状态变化。这里通过引用戴铭关于 RunLoop 原理的图,来对 RunLoop 方案的原理进行简单介绍:
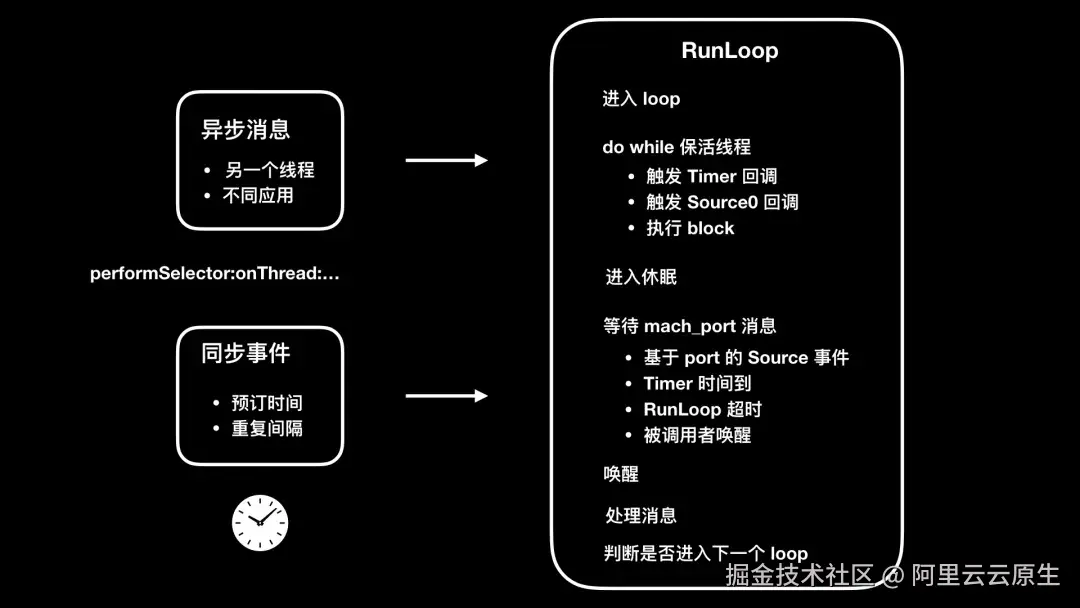
- 通知 observers:RunLoop 即将开始"进入 loop"
- 随后,会开启一个 do while 来保活线程
- 通知 obersers:RunLoop 会触发 Timer、Source0 回调,紧接着执行加入的 block
- 如果 Source1 是 ready 状态,会跳转到"处理消息"流程
- 通知 observers:RunLoop 即将进入休眠状态
- 等待 mach_port 消息,以再次唤醒
- 基于 port 的 Source 事件
- Timer 时间到
- RunLoop 超时
- 被调用者唤醒
- 通知 observers:RunLoop 被唤醒
- 处理消息
- 继续下一个 loop
基于 RunLoop 的方案实现中,一般会包含下面几个关键步骤:
-
注册 Observer:向主线程 RunLoop 注册 Observer 来监听其状态。
-
创建监控线程:用于监控主线程切换状态。
-
状态标记与超时判断:子线程根据 RunLoop 的状态变化来设置标记,并循环检测该标记是否在预设的阈值内被更新,否则判定为卡顿。
-
堆栈捕获与上报:判定为卡顿时,捕获主线程的调用堆栈,并上报服务器进行分析。
基于 RunLoop 的方案能够精准捕获到由主线程阻塞导致的各类卡顿,适用于线上卡顿问题的监控和诊断分析。
方案对比
基于主流方案对比分析,三种性能监控策略分别聚焦不同维度,如下表:
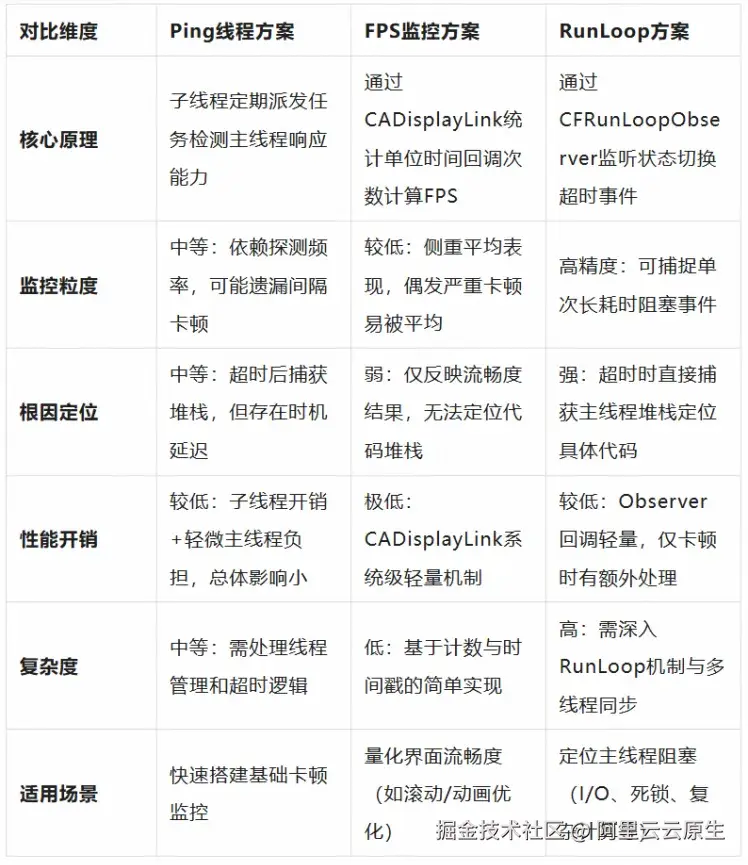
- Ping 线程方案通过子线程周期性探测主线程响应时间识别卡顿,但精度低于 RunLoop 方案。
- FPS 监控作为全局性能指标,通过帧率波动反映应用流畅度并判断卡顿,却无法定位性能瓶颈。
- RunLoop 方案则介入主线程事件循环机制,实现单次阻塞事件的毫秒级捕捉,可精准识别主线程阻塞源。
卡顿监控方案实现
卡顿监控方案的核心目标在于精准捕获并定位导致用户操作中断、体验显著下降的"阻塞型"卡顿。当卡顿发生时,不仅包括识别卡顿事件的发生,更需追溯具体代码行级的执行路径以定位问题根源。
相较于其他主流方案,RunLoop 监控方案通过持续追踪主线程任务执行耗时,能够精确捕获卡顿事件并同步采集完整的上下文调用堆栈信息。尽管其技术实现复杂度较高,但考虑到可部署于线上环境,以及对卡顿根因的诊断价值,最终被选定为核心实现方案。
上文中已经对 RunLoop 的原理有过大致的介绍,下文中将主要介绍如何具体实现。
监控 RunLoop 状态
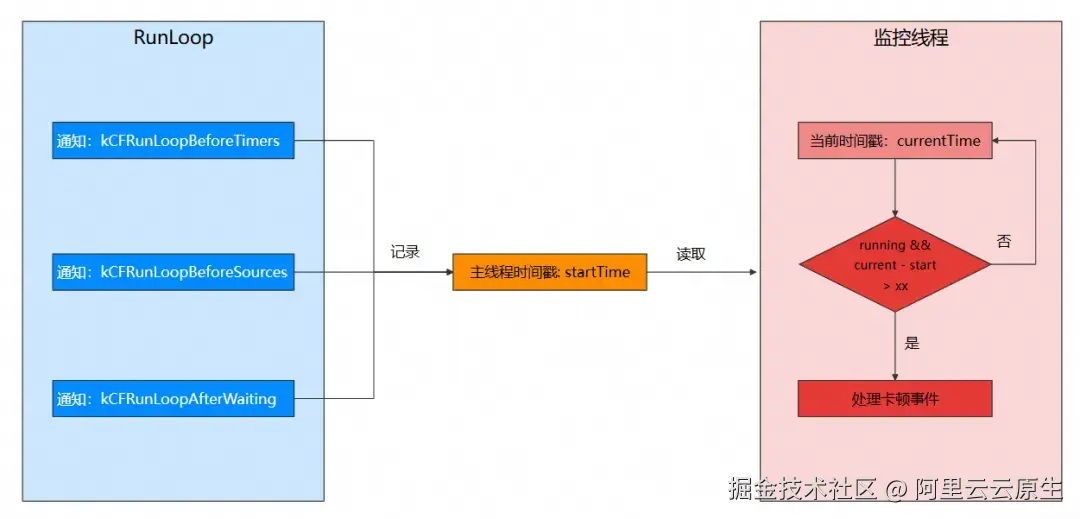
基于 RunLoop 实现卡顿监控方案,需要先监控 RunLoop 的状态切换。如下图,通过注册的 Observer 可以监听到主线程 RunLoop 状态的切换事件,并通过 running 和 startTime 来记录关联的状态和时间戳信息。监控线程通过读取 running 状态,以及 startTime 来判断是否产生了状态超时:
当主线程在执行某个任务的耗时较长时,RunLoop 的状态切换就会延时。通过在子线程监控 RunLoop 关键状态之间的时间差,就可以判断主线程是否发生了阻塞。
方案实现中:
- 当 Observer 收到
kCFRunloopBeforeTimers、kCFRunloopBeforeSource、kCFRunLoopAfterWaiting通知时,会把running状态置为 YES,并通过startTime记录当前时间戳。 - 当 Observer 收到
kCFRunloopBeforeWaiting和kCFRunLoopExit通知时,把running状态置为 NO。 - 监控线程需要持续读取
running状态和startTime时间戳,通过判断当前时间与startTime的差异来确定是否发生了卡顿,如下图:
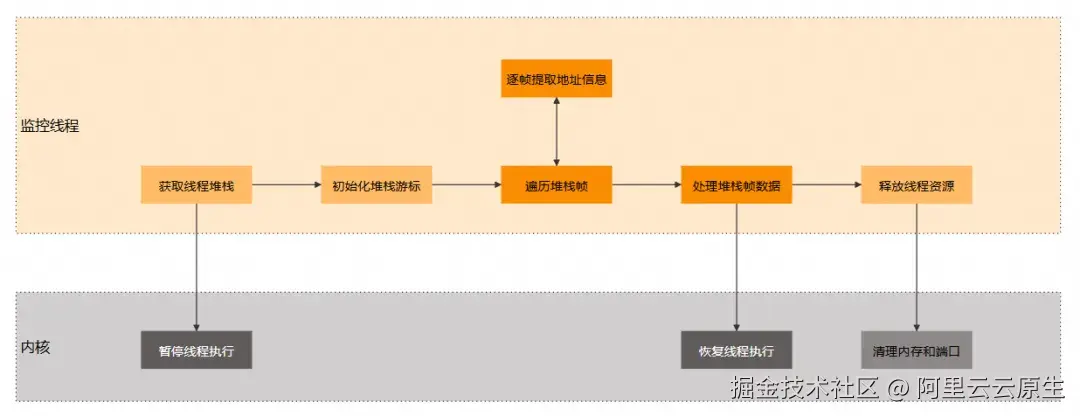
堆栈提取
当 RunLoop 状态超时,即检测到卡顿时,需要提取主线程堆栈并保存到内存中。堆栈的提取方案基于业界知名的 KSCrash 实现。相比通过系统函数获取堆栈,通过 KSCrash 获取的堆栈可以配合 dSYM 进行符号还原,能够定位到具体的代码位置,而且性能消耗也不大。
耗时堆栈提取
当监控线程监测主线程 RunLoop 时,会获取主线程的线程快照作为卡顿堆栈。但是,这个主线程堆栈不一定是最耗时的堆栈,也不一定是导致主线程超时的主要原因。为了对这个问题进行优化,需要在检测到主线程发生卡顿时,通过对保存在循环队列中的堆栈进行回溯(间隔 50ms 获取一次),获取最近最耗时堆栈。
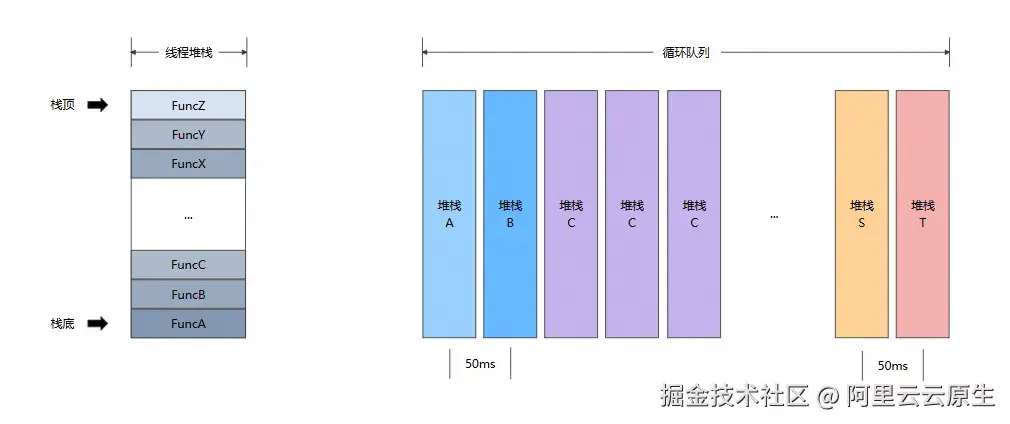
如上图所示,通过以下特征找出最近最耗时堆栈:
- 以栈顶函数为特征,栈顶函数相同的,整个堆栈就是相同的,如:
- 堆栈 A 的栈顶调用函数为 FuncA
- 堆栈 B 的栈顶调用函数为 FuncB
- 栈顶函数 FuncA 与 FuncB 不同,因此堆栈 A 和堆栈 B 为不同的堆栈
- 获取堆栈间隔相同,堆栈的重复次数近似作为堆栈的调用耗时,重复越多耗时越多,如:
- 堆栈 A 重复一次,近似耗时为 50ms
- 堆栈 B 重复一次,近似耗时为 50ms
- 堆栈 C 重复三次,近似耗时为 150ms
- 堆栈 C 为最耗时堆栈
- 重复次数相同的堆栈中,取最近的一个作为最耗时堆栈
监控线程退火算法
卡顿检测机制在无异常场景下性能开销可忽略,但遭遇持续数秒级卡顿时,频繁采集主线程堆栈信息时将引发显著性能损耗。且连续重复的堆栈记录无分析价值,完全没有必要。为了降低卡顿监测带来的性能损耗,SDK 采用了退火算法递增时间间隔,避免因同一个卡顿问题带来的性能问题。
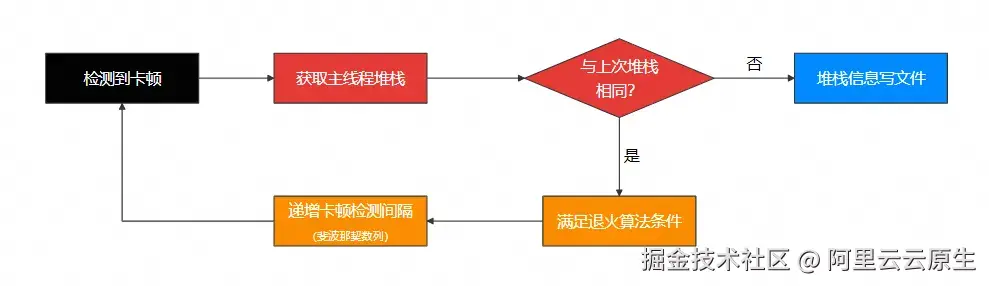
- 每次子线程检测到主线程卡顿,会先获取主线程的堆栈,并保存到内存中
- 把获得的主线程堆栈与上次卡顿获得的线程堆栈进行比对
- 不同:获得当前线程快照并写入到文件
- 相同:跳过,并按照斐波那契数列把检测时间递增,直到没有卡顿或卡顿堆栈不同
以上算法可以避免同一个卡顿写入多个文件的情况,避免检测线程遇到主线程卡死的情况下,不断写线程快照文件。
性能开销
任何一个监控工具的首要原则是不能影响被监控对象的性能。因此,我们还需要测量基于 RunLoop 的卡顿监控方案对应用性能的实际影响。性能测量的核心是进行 A/B 对比测试。我们需要准备两个几乎完全相同的 App 版本:
- A 版本(基准版本):卡顿监控功能完全禁用。
- B 版本(监控版本):卡顿监控功能完全开启。
然后在完全相同的设备和环境下,对这两个版本执行相同的操作,并测量关键性能指标的差异。这个差异就是卡顿监控带来的性能开销。
测试设备:iPhone 12 Pro
测试系统:iOS 18.7
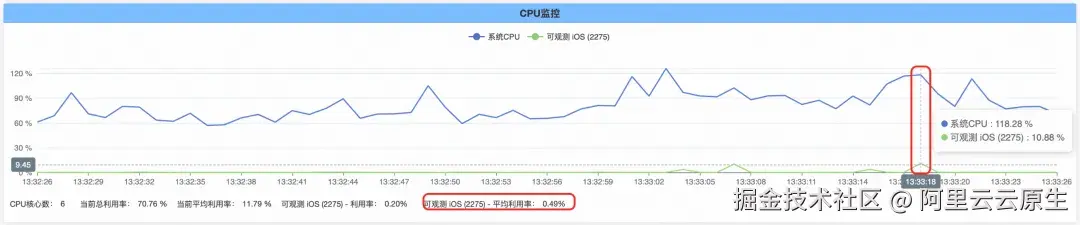
卡顿监控功能没有开启的情况下,App 持续运行一段时间并主动触发卡顿,App 整体的 CPU 占用如下图:
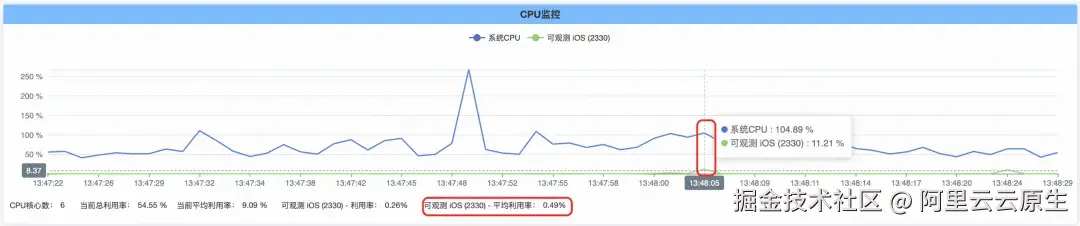
卡顿监控功能开启的情况下,App 持续运行一段时间并主动触发卡顿,App 整体的 CPU 占用如下图:
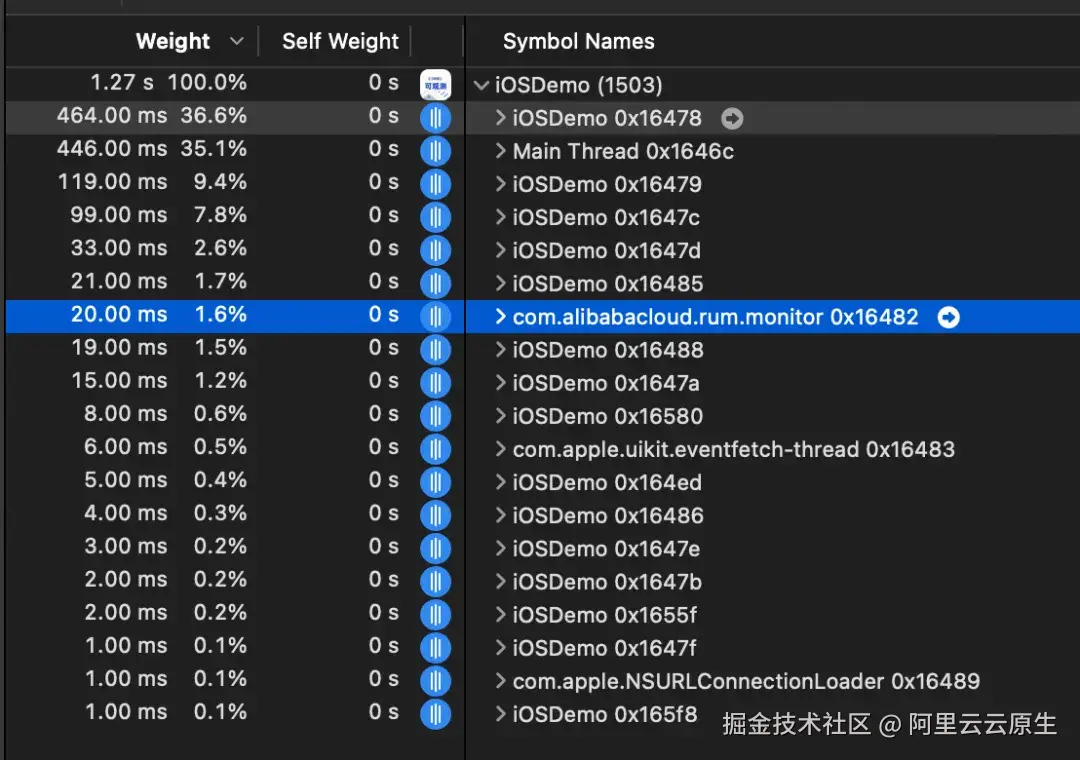
在卡顿监控开启情况下,监控线程的 CPU 占用如下。
有卡顿发生时:
无卡顿发生时:
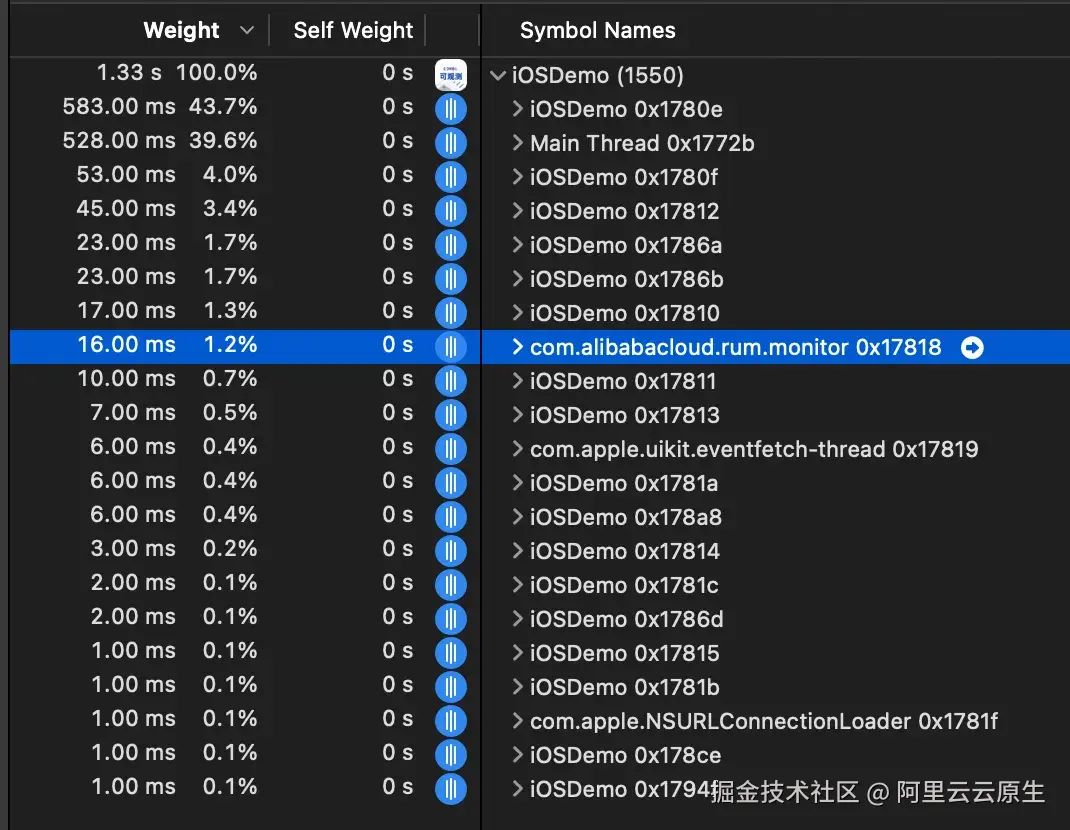
综上分析,App 引入卡顿监控能力后:
- 无卡顿发生时,对 App 性能几乎无影响
- 有卡顿发生时,App 整体 CPU 占用增加约 0.33%(不同设备的测试值会略有差异)
总结
本文主要介绍了当下主流的 iOS 卡顿监控方案,和基于 RunLoop 的卡顿监控实现细节,包括 RunLoop 状态的处理,堆栈以及耗时堆栈的提取,持续卡顿场景下的退火处理等。卡顿监控方案的实现过程中,通过融合行业成熟优秀的方案思路,实现了主线程阻塞卡顿的检测能力。卡顿监控能力还在持续进化,后续还有不少可以优化和提升的点,如支持高 CPU 占用卡顿、启动卡顿等的检测。目前这套方案已经应用在阿里云 ARMS 用户体验监控 iOS SDK 中,您可以参考接入文档 ** **1 体验使用。相关问题可以加入"RUM 用户体验监控支持群"(钉钉群号:67370002064)进行咨询。
相关链接:
1 接入文档