文章目录
- 论元
- 时间论元
- 指导
-
- 一、什么是"时间抽取"
- 二、时间论元理论在其中的作用
-
- [1. **提供事件与时间的结构框架**](#1. 提供事件与时间的结构框架)
- [2. **指导时间关系建模(Temporal Relation Modeling)**](#2. 指导时间关系建模(Temporal Relation Modeling))
- [3. **统一多语言时间解释的理论基础**](#3. 统一多语言时间解释的理论基础)
- 三、理论指导来源
- [四、在 NLP 系统中的应用实例](#四、在 NLP 系统中的应用实例)
- 五、总结与启示
- 结论
- 整体框架
- 基于事件时间论元抽取的文档级时序抽取方法研究
-
- 模型
- 一、模型总体概述
- 二、四大模块功能详解
-
- [词嵌入生成模块(Event-Aware Embedding Module)](#词嵌入生成模块(Event-Aware Embedding Module))
- [文本理解模块(Contextual Encoding Module)](#文本理解模块(Contextual Encoding Module))
- [时间论元标注模块(Time Argument Labeling Module)](#时间论元标注模块(Time Argument Labeling Module))
- [篇章级事件时序关系计算模块(Document-Level Temporal Relation Module)](#篇章级事件时序关系计算模块(Document-Level Temporal Relation Module))
- 三、模型优势总结
- 指导2
-
- 一、会提升哪里?------和四模块逐一对齐
- [二、LoRA 怎么插?------轻量而有效的配置](#二、LoRA 怎么插?——轻量而有效的配置)
- 三、训练配方
- 四、推理阶段的"安全栅栏"
- 五、会提升到什么程度?
- 六、评测与消融怎么做?
- 七、两条落地路线)
- [八、常见坑 & 对策](#八、常见坑 & 对策)
- 结论
论元
一、基本定义
论元(Argument) 是语法学和语义学里的核心概念。简单来说,
论元是谓词所需要、才能完整表达意义的成分。
谓词(predicate)表示一个动作、状态或关系,而论元则是这个谓词所"要求参与"的实体。只有当谓词的论元都被提供后,句子的意义才完整。
例如:
"吃(predicate)"需要一个"吃的人"和"被吃的东西"。
"张三吃苹果"中:
- "张三" 是第一个论元(施事 / 主语 argument)
- "苹果" 是第二个论元(受事 / 宾语 argument)
如果只说"吃",听者会问"谁吃什么?"------因为谓词的论元还没补全。
二、论元与修饰语的区别
论元是谓词必须 要有的成分,而修饰语(adjunct)是附加信息 。
对比:
| 类型 | 举例 | 是否必须 | 作用 |
|---|---|---|---|
| 论元 | 张三吃苹果 | 是 | 组成事件的核心结构 |
| 修饰语 | 张三吃苹果在厨房里 | 否 | 提供附加背景,如地点、时间、方式 |
👉 若去掉修饰语,句子仍然语义完整;去掉论元,则句子语义残缺。
三、形式语义视角
在逻辑语义框架中,一个动词像函数一样,需要论元来"饱和":
- 谓词 = 函数
- 论元 = 函数的输入值
例如:
"吃(x, y)" 表示一个二元谓词,x 是施事,y 是受事。
若给出 x=张三, y=苹果,就得到一个完整命题:"张三吃苹果"。
同理,"下雨"是一个零论元谓词(没有参与者);"给"是三元谓词(给某人某物)。
四、论元的类型
常见论元角色(语义角色 Semantic Roles)包括:
- 施事(Agent):动作发出者(张三打球)
- 受事(Patient / Theme):受动作影响的对象(球被打)
- 受益者(Beneficiary):受益的人(张三给李四送礼物)
- 工具(Instrument):动作所用手段(用锤子敲钉子)
- 地点(Location):动作发生处(在厨房做饭)
- 时间(Time):动作发生时间(昨天见面)
其中地点和时间有时是论元,有时是修饰语------取决于谓词是否"要求"它们(例如"待在"要求地点论元)。
五、延伸到"时间论元理论"
在"时间论元理论"(Time Argument Theory)里,研究者认为时态和体也像动词一样需要论元,只不过这个论元不是人或物,而是"时间"。
举例:
"过去时"可以看作一个需要"时间"论元的谓词。
"过去(RT<UT)"就像"吃"需要"苹果"一样,需要一个"时间区间"来完成意义。
六、小结
| 概念 | 说明 |
|---|---|
| 论元 | 谓词语义上必需的参与成分 |
| 修饰语 | 非必需,添加背景信息 |
| 功能 | 让谓词"饱和",形成完整命题 |
| 时间论元 | 时间作为论元,用来解释时态和体 |
时间论元
核心想法是什么?
- 时态/体(tense/aspect)不是只加在动词上的"时态词缀" ,而是像普通谓词一样需要"时间"做论元(argument)来饱和 。换句话说,句子里除了主语、宾语等名词论元 ,还有时间论元 。时态把事件发生时间(ET)与参照时间(RT) (通常与说话时间 UT 有关)按先后或包含关系连起来。(Department of Linguistics - UCLA)
- 更强一条:时态、体、时间副词 都可看成时空谓词 ,它们把**"时间短语/区间"投射到句法结构里**(可显性也可隐性),像名词短语那样可被修饰、可发生照应/绑定关系。(sciencedirect.com)
与经典时间三分的关系
- 该理论通常与 Reichenbach 三分 协同使用:ET(事件时)/RT(参照时)/UT(发话时) 。例如,过去时把 ET < RT ,而一般默会 RT = UT (简单主句中)。(s-space.snu.ac.kr)
与"时态如代词(anaphor)"的联系
- Partee 等人的观点:时态像代词 ,能对前文或语境给出的时间进行回指/照应 。时间论元理论提供了句法-语义机制:时态标记 为谓词,以时间对象为论元 并允许跨句或从句里的时间照应 。(SpringerLink)
形式直觉(非技术公式版)
- 把PAST看成二元述词:PAST(RT, ET) ≈ "ET 在 RT 之前"。
- 内部论元≈ 带有 VP 的"事件时间"(ET)。
- 外部论元 ≈ 隐性的"参照时间"(RT),简单句里常取 UT 。(Department of Linguistics - UCLA)
英语例子
-
John left.
- 结构直觉:PAST(RT=UT, ET="John-leave") → ET < UT。
-
By 2010, John had left.(过去完成时)
- 有显性时间短语 by 2010 可充当/限制 RT;PAST 规定 ET < RT ,而 by 2010 限制 RT ≤ 2010 ,得出"2010 之前已离开"。(时间短语像名词短语那样限制时间论元 。)(sciencedirect.com)
汉语里的适配
-
标准观点:汉语无形态时态 ,但有时间解释 ;汉语通过体标记 (了/过/着)、时间副词 (昨天、已经、正在)、语境等来提供/限制时间论元 ,从而完成时态-体解释。时间论元理论把这些都看作对时间论元的饱和与约束 。(semanticsarchive.net)
-
例如:
- 我昨天见过他。 "昨天"显性提供 RT/ET 的上界;"过"给出经验体(事件在参照时间之前发生且与当下存在关联)。
- 他在吃饭。 "在"作为进行体,约束 ET 与 RT 的重叠 。以上都可被分析为把时间区间当作论元引入/限定 。(semanticsarchive.net)
为什么有用?
- 统一性 :把时态、体、时间副词纳入同一"论元-谓词"框架,解释它们如何组合 与相互约束 。(sciencedirect.com)
- 照应/连贯 :自然解释跨句的时间推进 与回指 (如叙事中 RT 的更新)。(SpringerLink)
- 跨语言 :既适配有形态时态的语言(英、德等),也适配"无形态时态"的语言(如汉语),仅仅让"时间论元"的显性/隐性与来源(副词、体标记、语境)不同。(semanticsarchive.net)
常见对比与补充
- Reichenbach/TT--TSit--TU(Klein)侧重时间关系的抽象表征 ;时间论元理论 进一步把这些时间点/区间当作句法-语义中的实体 ,进入组合运算。两者并行不悖,后者是可组合语义的"工程化"实现。(s-space.snu.ac.kr)
- 有学者提出动词本身具有**"论元-时间结构"**(argument--time structure),把动词对参与者与对时间的选择性约束合并考虑,用来统一解释时态、体、情状体(Aktionsart)互动。(De Gruyter Brill)
要点
- 时态/体/时间副词 = 需要时间区间做论元的谓词 。(sciencedirect.com)
- 时态把 ET、RT、UT 关联起来;常见默认 RT=UT (简单句)。(Department of Linguistics - UCLA)
- 时间短语可像名词短语一样 修饰、受限、发生时间照应 。(sciencedirect.com)
- 英语:形态时态 + 时间短语;汉语:体标记/副词/语境 → 供给或限制时间论元 。(semanticsarchive.net)
指导
一、什么是"时间抽取"
时间抽取(Temporal Information Extraction, TIE) 是自然语言处理(NLP)中的一个核心任务,目标是从文本中识别、解释和结构化时间信息 。
包括以下三个主要子任务:
- 时间表达识别(Temporal Expression Recognition):找到"昨天"、"2025年11月"、"三天后"这类时间短语。
- 时间归一化(Temporal Normalization):将自然语言表达转化为标准化的时间形式(如 ISO 8601 格式)。
- 时间关系抽取(Temporal Relation Extraction):确定事件之间或事件与时间点之间的关系(如"在......之前"、"同时发生")。
二、时间论元理论在其中的作用
1. 提供事件与时间的结构框架
在语义理论中,每个事件都有时间论元(event time argument)。
这意味着:任何动词、事件或状态都必然绑定某个时间区间或时间点。
在自然语言处理中,这个假设提供了结构基础:
- 当模型识别出一个动词(如"开始"、"完成"、"等待"),它隐含一个事件时间(ET);
- 当系统识别到时间短语(如"昨天"、"两周后"),它们可被视为对该时间论元的填充或约束。
因此,"时间论元理论"给了算法一个事件-时间映射的语义锚点:
每个事件都可被建模为一个谓词
e(t),其中 t 为其时间论元。
2. 指导时间关系建模(Temporal Relation Modeling)
在 Reichenbach(1947)的三分模型基础上,时间论元理论提供了形式化的依赖链:
- 事件时间 (ET):事件本身发生的时间
- 参照时间 (RT):叙述或语义上的参考点
- 说话时间 (UT):发话的时间
机器抽取任务中:
-
如果文本出现"他昨天去了北京",系统根据"去了"的动词时态和"昨天"修饰语,
可建立如下结构:
ET(去北京) < UT(现在) RT ≈ 昨天 -
这种结构化的时间关系来自"时间论元理论"对 ET--RT--UT 的明确区分。
3. 统一多语言时间解释的理论基础
在不同语言中,时间表达形式各异(如英语有形态时态,汉语无显式时态),但时间论元理论认为时间是普遍论元 。
因此:
- 英语的 "John had left by 2010" 和
- 汉语的 "他到2010年已经离开了"
都可以统一成:
PAST(RT, ET)且RT ≤ 2010
这种统一结构极大地有利于**跨语言时间抽取系统(multilingual temporal IE)**设计,使语义框架保持一致。
三、理论指导来源
| 理论方向 | 核心思想 | 对时间抽取的启发 |
|---|---|---|
| Reichenbach 时态三分模型 (1947) | 引入 ET, RT, UT 三种时间点 | 为时间关系抽取提供层次结构 |
| Partee (1973) 时态照应理论 | 时态如代词,可回指前文时间 | 启发跨句时间链抽取(temporal anaphora resolution) |
| Klein (1994) 体与时态的TT--TSit--TU 模型 | 区分情状时间、叙述时间与说话时间 | 提高事件时间区间标注的精度 |
| Time Argument Theory(时间论元理论) | 时态/体/时间副词都有时间论元 | 为语义解析与抽取算法提供形式约束 |
| Davidson事件语义 (1967) | 动词引入事件变量 e | 启发"事件 + 时间论元"联合抽取框架 |
四、在 NLP 系统中的应用实例
-
TimeML / ISO-TimeML 标注规范
-
每个事件(EVENT)节点都有
timeID绑定; -
时间论元理论的结构被形式化为
MAKEINSTANCE与TLINK关系。 -
例如:
xml<EVENT eid="e1" class="OCCURRENCE">left</EVENT> <TIMEX3 tid="t1" type="DATE" value="2010-01-01">2010</TIMEX3> <TLINK eventInstanceID="e1" relatedToTime="t1" relType="BEFORE"/>→ 显式体现"事件时间论元 e1 的时间区间在 t1 之前"。
-
-
BERT + Time-Aware 模型(如 T-BERT, TempBERT)
- 在语义表示层引入时间向量嵌入 (temporal embeddings) ,
模拟时间论元与事件的联合表征。 - 通过训练,模型学会从上下文推断隐含时间论元。
- 在语义表示层引入时间向量嵌入 (temporal embeddings) ,
五、总结与启示
| 层面 | 作用 |
|---|---|
| 理论层 | 时间论元为时间抽取提供"事件---时间"语义结构的普遍框架 |
| 算法层 | 支撑事件与时间实体的联合建模、时间链解析 |
| 跨语言层 | 提供一致的抽象层,解释不同语言时态系统的差异 |
| 工程层 | 成为 TimeML、TempEval 等任务的数据建模标准 |
结论
时间论元理论使时间抽取不只是找"时间词",而是从语义上理解"事件发生在何时"。
整体框架
一、整体框架:从句法到语义
时间论元理论(Time Argument Theory)认为:
事件 (Event) 、时间 (Time Argument) 和 时态 (Tense) 构成一个层层嵌套、互相约束的系统。
在自然语言中,动词引入事件变量 e,时态和体系统则规定事件与时间的关系,时间短语或语境提供对时间论元的填充。
句子 (Sentence)
└── 时态层 (Tense Phrase)
└── 事件层 (Event Phrase)
└── 动词谓词 (Verb)语义组合形式(简化):
TENSE ( R T , U T ) ( ASPECT ( E T , R T ) ( V ( e ) ) ) \text{TENSE}(RT, UT)(\text{ASPECT}(ET, RT)(\text{V}(e))) TENSE(RT,UT)(ASPECT(ET,RT)(V(e)))
其中:
- ET (Event Time):事件发生的时间区间
- RT (Reference Time):语义上被叙述/定位的参照点
- UT (Utterance Time):说话时刻(由语境提供)
二、三个时间层的核心关系
| 层次 | 名称 | 符号 | 定义 | 在句子中的体现 |
|---|---|---|---|---|
| ① | 事件时间 | ET | 动词所表示事件的实际发生时间 | "去北京"这一行为何时发生 |
| ② | 参照时间 | RT | 时态计算所依据的语义时间点 | "昨天"、"那时" 等短语限定 |
| ③ | 说话时间 | UT | 说话行为发生的时间 | 当前时刻 |
三者的相对位置决定了时态解释:
| 时态类型 | 时间关系 | 示例句 |
|---|---|---|
| 一般过去时 | ET < UT(RT ≈ UT) | 他昨天去了北京。 |
| 现在进行时 | ET ≈ RT = UT | 他正在去北京。 |
| 过去完成时 | ET < RT < UT | 他昨天到达时,飞机已经降落。 |
| 将来时 | UT < RT ≈ ET | 他明天会去北京。 |
三、图示关系(文字版)
时间线:←───────────────→
过去 现在 将来
| | |
|<---ET--->| |UT |
|<----RT---->| |- 在 过去完成时:ET 早于 RT,RT 又早于 UT
- 在 过去时:ET 早于 UT,RT 通常等于 UT
- 在 现在时:ET 与 UT 重合
- 在 将来时:ET 晚于 UT
时态标记(Tense) 就是规定 ET、RT、UT 之间的排序规则 。
而 体(Aspect) 再进一步规定 ET 的内部结构(是否完成、持续、起点/终点是否包含等)。
四、事件与时间论元的绑定
在形式语义上:
- 动词(谓词)引入事件变量
e - 时态/体层引入时间变量
t(即时间论元) - 它们之间通过 λ 抽象绑定:
⟦ 过去时 ⟧ = λ P . ∃ t t \< t s p e e c h ∧ P ( t ) ⟦过去时⟧ = λP. ∃t t \< t_{speech} ∧ P(t) \[过去时]=λP.∃tt\
⟦ 去北京 ⟧ = λ t . ∃ e G O ( e , J o h n , B e i j i n g ) ∧ T I M E ( e ) = t ⟦去北京⟧ = λt. ∃e GO(e, John, Beijing) ∧ TIME(e) = t \[去北京]=λt.∃eGO(e,John,Beijing)∧TIME(e)=t
组合后:
∃ t ∃ e t \< t s p e e c h ∧ G O ( e , J o h n , B e i j i n g ) ∧ T I M E ( e ) = t ∃t∃e t \< t_{speech} ∧ GO(e, John, Beijing) ∧ TIME(e) = t ∃t∃et\
意义:"存在一个时间 t,在说话时间之前,约翰去北京的事件发生于 t。"
可见 :时间论元 t 是事件 e 的必要参数;
时态标记 则规定 t 与说话时间 t_speech 的关系。
五、语言实例对照
| 语言 | 句子 | 时间论元显性形式 | 说明 |
|---|---|---|---|
| 英语 | John had left by 2010. | by 2010 | 限定 RT;时态为 PAST.PERFECT:ET < RT < UT |
| 汉语 | 他到2010年已经离开了。 | 到2010年 | 体标记"了"表达完成;时间副词提供 RT |
| 日语 | 彼は2010年までに出発した。 | 2010年までに | 日语时态系统也用时间副词约束 RT |
六、在自然语言处理与时间抽取中的意义
| 层面 | 应用 | 理论指导 |
|---|---|---|
| 时间识别 | 识别"昨天、两天后"等填充 RT 的表达 | 时间论元显性化 |
| 事件抽取 | 每个动词都引入一个事件时间 ET | 事件语义与时间论元绑定 |
| 时间关系识别 | 判断事件间"先后"、"重叠" | 由时态决定 ET--RT--UT 的顺序 |
| 时间推理 | 结合上下文更新 RT(叙述时间推进) | 时间照应理论(temporal anaphora) |
七、小结
| 概念 | 含义 | 与时间抽取的对应 |
|---|---|---|
| 事件 (Event) | 动词所指的动作或状态 | 事件识别 |
| 时间论元 (Time Argument) | 事件所绑定的时间区间/点 | 时间归一化 |
| 时态 (Tense) | 约束事件时间与说话时间的关系 | 时间关系推断 |
一句话总结:
时态决定"事件时间"如何相对于"参照时间/说话时间"排列,
时间论元是这一排列的语义"接口",
它让事件与时间得以计算化表示与抽取。
基于事件时间论元抽取的文档级时序抽取方法研究

模型
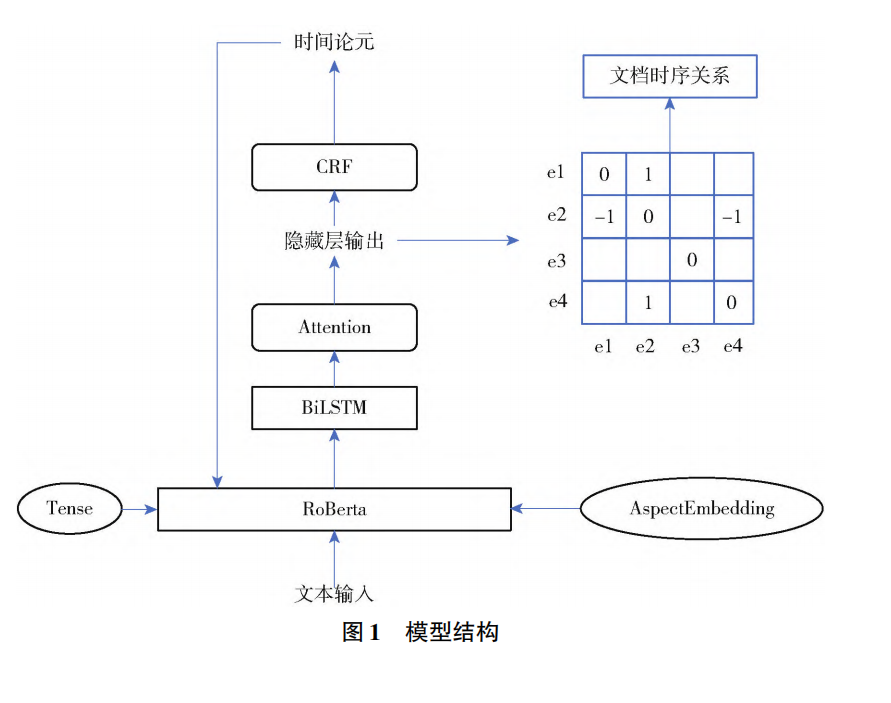
一、模型总体概述
该模型旨在从文本中自动识别时间论元 并计算事件之间的时序关系 ,从而实现更精确的时间语义理解与抽取 。
模型整体由 四个主要功能模块 组成,分别在词级、句级与篇章级三个层次协同工作:
词嵌入生成 → 文本理解 → 时间论元标注 → 篇章级时序计算
二、四大模块功能详解
词嵌入生成模块(Event-Aware Embedding Module)
功能定位:
对预训练词向量进行时态与时间特征的再编码,使嵌入包含丰富的时间语义信息。
核心机制:
- 基于事件的 时态 (tense) 、体态 (aspect) 和 时间副词 (temporal adverbs) 等信息;
- 对预训练词嵌入(如 Word2Vec、BERT)进行权重调整或特征融合;
- 输出的词嵌入不仅包含词义,还显式编码事件发生时间的语义维度。
作用:
为后续时间论元抽取和事件时序推理提供时间敏感的输入特征。
关键贡献:捕捉时间线索 → 增强时序感知能力。
文本理解模块(Contextual Encoding Module)
技术框架:
采用 双向长短期记忆网络 (BiLSTM) 处理词序列。
主要功能:
- 结合上下文信息(前后语境),提取句内与句间的语义依赖;
- 通过门控机制 (gating mechanism) 对来自词嵌入模块的输入进行动态更新;
- 多层 BiLSTM 输出最终的上下文语义表示序列。
作用:
提供上下文敏感的语义表示,使模型更准确地理解句子中的时间线索与事件关系。
关键贡献:深层语义理解 → 为时间论元标注打基础。
时间论元标注模块(Time Argument Labeling Module)
算法核心:
使用 条件随机场 (Conditional Random Field, CRF) 进行序列标注。
输入输出:
- 输入:来自文本理解模块的词语向量序列;
- 已知:事件触发词(即事件中心已确定);
- 输出:每个事件对应的时间论元边界与类别(如时间点、时间区间等)。
特点与优势:
- CRF 利用上下文依赖性优化标签序列;
- 可避免单词独立分类造成的标注不连贯问题;
- 仅对"时间论元"部分进行预测,提高效率与准确率。
关键贡献:精确识别事件的时间属性。
篇章级事件时序关系计算模块(Document-Level Temporal Relation Module)
目标:
在篇章层面上建立所有事件之间的时序关系图谱。
方法流程:
- 构建事件触发词的 时序关系计算矩阵;
- 将篇章中所有事件两两配对,形成候选事件对;
- 对每对事件进行时序分类(如 Before , After , Simultaneous 等);
- 综合所有事件对的结果,生成整体篇章的事件时间序结构。
作用:
实现跨句、跨段落的时间逻辑推理。
✅ 关键贡献:构建篇章级时间链 → 实现全局时序理解。
三、模型优势总结
| 模块 | 理论支撑 | 实际贡献 |
|---|---|---|
| 词嵌入生成 | 时间论元理论(Time Argument Theory) | 将时态、体态嵌入语义表示 |
| 文本理解 | BiLSTM 上下文建模 | 捕获时间语义的上下文依赖 |
| 时间论元标注 | CRF 序列标注理论 | 精确识别事件的时间论元 |
| 篇章级计算 | 时间关系逻辑与事件语义 | 实现跨句时序推理与全局结构重建 |
指导2
用LLM和LoRA
一、会提升哪里?------和四模块逐一对齐
- 词嵌入生成模块(Event-aware Embedding)
- 用 LLM 的上下文表示(如 Transformer encoder 的最后或倒数几层拼接)替代/增强原始词向量,天然携带时态、体态与时间副词的分布式线索。
- 在 LLM 的注意力层上 插 LoRA(q_proj/v_proj/ffn) ,少量参数即可对"过去/将来/完成/进行/时间副词"等触发的注意力模式进行领域适配。
- 效果:时间词与事件触发词的耦合更强,对隐含时间(省略时间、语境时间)更敏感。
- 文本理解模块(BiLSTM)
- 方案A:保留 BiLSTM,用 LLM 表示作为输入(最小改造)。
- 方案B(建议):直接用 LLM encoder 取代 BiLSTM,句内/跨句依赖更稳;或"LLM→轻量BiLSTM"作细化。
- 效果:长距离依赖与跨句指代(temporal anaphora)更好,利于篇章级时序。
- 时间论元标注模块(CRF)
- 把 LLM+LoRA 的 token 表示 喂给 CRF;或用 LLM 的span分类头(BIO→span)再接CRF做全局约束。
- 效果:时间论元边界更准(特别是"到2010年前""三周左右"这类复杂边界)。
- 篇章级时序关系模块
- 用 LLM 的对偶/多项对比表示 做事件对分类(Before/After/Overlap/Inclusion...),支持跨句 与跨段;
- 在输出层加入 符号一致性约束(见下)避免"环"和自相矛盾。
- 效果:复杂叙事里的全局一致性明显提升。
二、LoRA 怎么插?------轻量而有效的配置
-
插入位置 :多头注意力的 q_proj / v_proj ,以及 MLP/FFN(可先只做人少钱少的 q/v)。
-
秩 r :8--32(中文领域推荐先从 r=16 起步)。
-
α(lora_alpha) :16--64,常用 32。
-
Dropout:0.05--0.1。
-
微调范围 :仅训练 LoRA + 新增任务头(CRF / 分类头);可选解冻 LayerNorm/bias 少量参数做"微解冻"。
-
多任务头:
- Token 级(BIO+CRF)做 TIMEX/时间论元;
- Span 级(开始/结束)做补充;
- 事件对分类头做 TLINK;
- 三头联合训练共享同一套 LoRA,显著提升鲁棒性。
三、训练配方
数据组织
- 统一 TimeML/ISO-TimeML 风格:TIMEX3(时间表达)、EVENT、TLINK(关系)。
- 生成 三类样本:序列标注样本、span 样本、事件对样本(负样本用距离/句间隔分层采样,控制类不平衡)。
目标函数
-
L = L_CRF(token) + λ1·L_span + λ2·L_pair + λ3·L_consistencyL_CRF:BIO+CRF 序列负对数似然L_span:起止点二分类/指针网络(可用 Focal Loss)L_pair:事件对时序多类交叉熵L_consistency:时序闭包一致性正则(如 A<B&B<C ⇒ 惩罚预测 A≮C)
超参起步
- 学习率:LoRA 与头部 1e-4 ;若基底是指令模型可降到 5e-5
- 批量:16--32(梯度累积到等效≥64)
- 训练轮次:3--10(看验证集早停)
- 序列长度:512/1024(篇章任务尽量拉长,或分块+跨块缓存)
数据增强(很关键)
- 时态改写:过去↔将来、完成↔进行;保持事实不变、仅改时间形态
- 指代/省略重写:把"那时/随后/之前"互替,锻炼时间照应
- 合成对抗:制造容易混淆的相邻时间表达(如"到2010年前/到2010年")
四、推理阶段的"安全栅栏"
- 符号闭包修复:基于 Allen 关系/传递性做后处理,自动修正少量矛盾 TLINK。
- 约束解码 :CRF 已管 token 层;关系层再加 ILP/DP 小优化,保证全局无环。
- 规则+神经混合归一化:时间标准化(ISO 8601)仍建议保留轻规则/词典辅助,抵消 LLM 偶发"自由发挥"。
五、会提升到什么程度?
- 在边界识别 (时间论元 BIO)与跨句时序(TLINK)两块通常更明显;
- 领域外迁移(新闻→社媒/专利)也更稳,因为 LLM 的泛化与 LoRA 的快速域适配。
具体涨幅取决于基线与数据量;经验上,采用"LLM+LoRA+一致性约束+多任务"后,F1/Acc 往往出现稳定提升,尤其在复杂时间短语与长距离关系上。
六、评测与消融怎么做?
指标
- 时间论元:Precision / Recall / F1(严格/宽松边界)
- 时间归一化:准确率(值级别)
- 关系:微/宏平均 Acc 或 F1;加 一致性率(是否无环、传递闭包正确)
消融
- -LoRA(只用冻住的 LLM)
- -Consistency(移除时序闭包正则/解码)
- -Multi-task(只做CRF或只做关系)
- Encoder 替换(BiLSTM vs LLM)
七、两条落地路线)
- 路线A(低改造) :保留你的 BiLSTM+CRF ,用 LLM+LoRA 产出的上下文向量替代原词嵌入;篇章关系头单独接在 LLM 句向量池化上。
- 路线B(建议) :LLM 直接替代 BiLSTM,共享 LoRA 做多任务;CRF 保留;关系层加一致性解码。性能更高、代码更简。
八、常见坑 & 对策
- 灾难性遗忘:LoRA 只训增量参数,必要时冻结前 N 层或只训 q/v。
- 数据稀疏/类不平衡:对"Overlap/Includes"等小众关系做重采样或 Focal Loss。
- 长文超长:滑窗+跨窗记忆(事件表征缓存)或 Longformer 类长上下文基模。
- 幻觉归一化:时间标准化始终保留规则核验与格式检查。
结论
能提升。 用 LLM 作为上下文编码器 + LoRA 参数高效微调 + CRF/一致性约束 + 多任务联合 ,在时间论元边界 与篇章级时序关系 上通常带来稳定且可复现的准确率提升,并显著增强跨域鲁棒性。