数据迁移工具之 DataX + DataX-Web(windows)
- [一、DataX + DataX-Web 简介](#一、DataX + DataX-Web 简介)
-
- [1. DataX 核心特性](#1. DataX 核心特性)
- [2. DataX-Web 核心作用](#2. DataX-Web 核心作用)
- 二、DataX
-
- [1. 下载 (两种方式)](#1. 下载 (两种方式))
- [2. 设置 支持 python3(可选)](#2. 设置 支持 python3(可选))
- [3. 测试安装是否成功](#3. 测试安装是否成功)
- [4. 简单的入门测试(mysql案例)](#4. 简单的入门测试(mysql案例))
- [三、DataX-Web 下载](#三、DataX-Web 下载)
-
- [1. 下载源码](#1. 下载源码)
- [2. 创建数据库](#2. 创建数据库)
- [3. 修改项目配置](#3. 修改项目配置)
- [4. 启动项目](#4. 启动项目)
- [5. 启动成功](#5. 启动成功)
- [6. 实战](#6. 实战)
-
- [1. 项目管理-添加项目](#1. 项目管理-添加项目)
- [2. 配置数据源](#2. 配置数据源)
- [3. 创建执行器](#3. 创建执行器)
- [4. 创建DataX任务模板](#4. 创建DataX任务模板)
- [5. 构建任务生成同步 json](#5. 构建任务生成同步 json)
- [6. 任务管理](#6. 任务管理)
- 四、报错
- 五、参考文章
一、DataX + DataX-Web 简介
1. DataX 核心特性
DataX 是阿里开源的 基础数据迁移引擎(纯命令行工具,无界面),核心功能是跨数据源同步数据。
- 架构:通过 "Reader(读数据插件)+ Writer(写数据插件)" 实现跨数据源(MySQL、Oracle、HDFS 等)数据搬运;
- 局限性:本身不自带分表规则逻辑,需配合脚本预处理或自定义插件实现按分表规则拆分数据;
- 优势:轻量、开源免费、跨数据源兼容性强,适合中小规模数据迁移。
2. DataX-Web 核心作用
DataX-Web 是 DataX 的可视化调度管理平台,本质是对 DataX 的 "界面化包装",解决 DataX 命令行操作门槛高的问题。
- 核心功能:可视化配置迁移任务、定时调度(如每日增量同步)、迁移进度监控、日志查询与异常告警;
- 依赖关系:必须与 DataX 引擎配合使用(部署时需关联 DataX 安装路径,无法独立工作);
- 优势:降低操作门槛,支持多任务管理,适合非技术人员或批量任务场景。
二、DataX
1. 下载 (两种方式)
方式一:github 下载
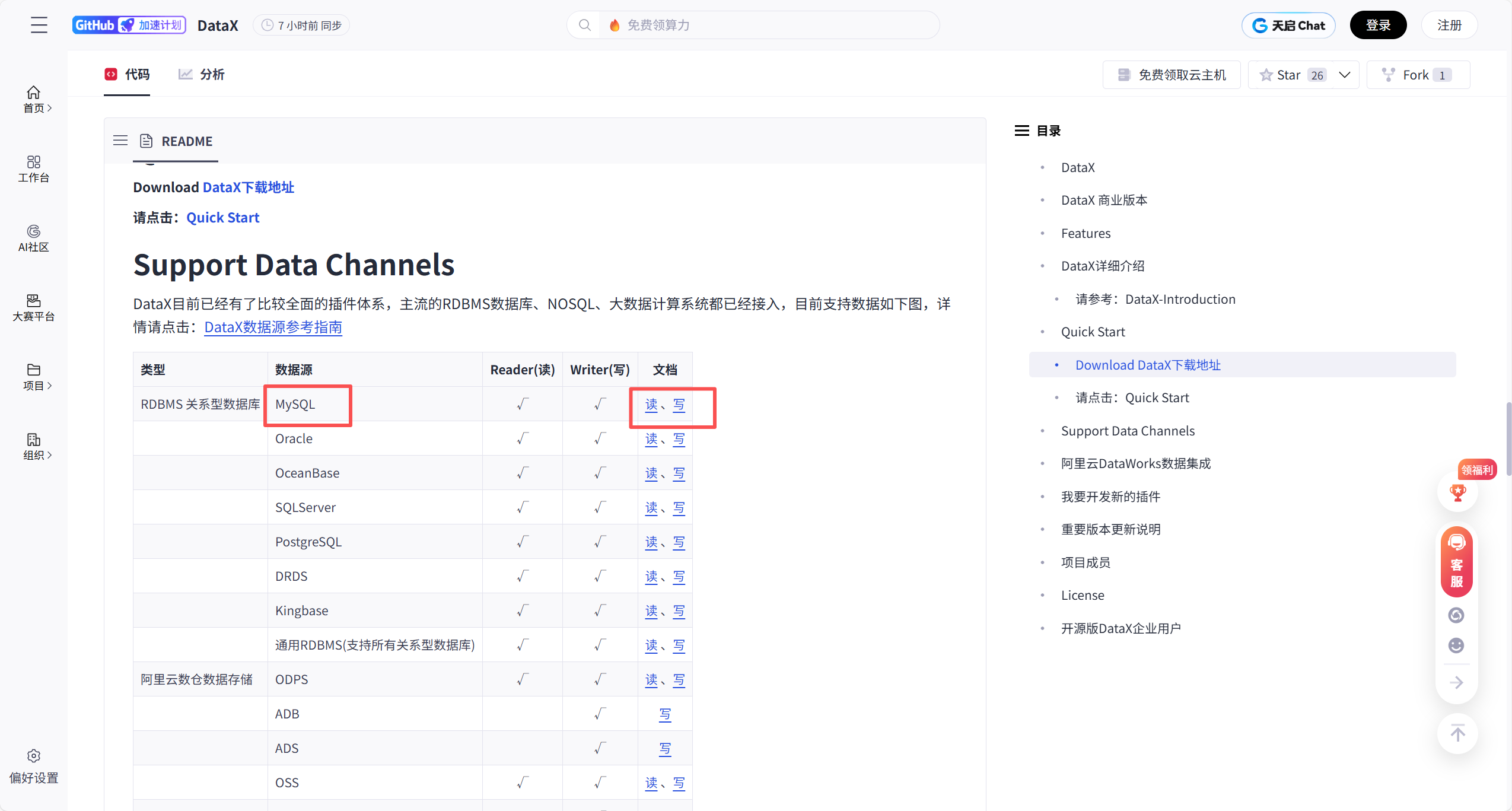
https://github.com/alibaba/DataX
外下滑动到 Quick Start 章节
方式二:gitcode 下载
https://gitcode.com/gh_mirrors/da/DataX
外下滑动到 Quick Start 章节
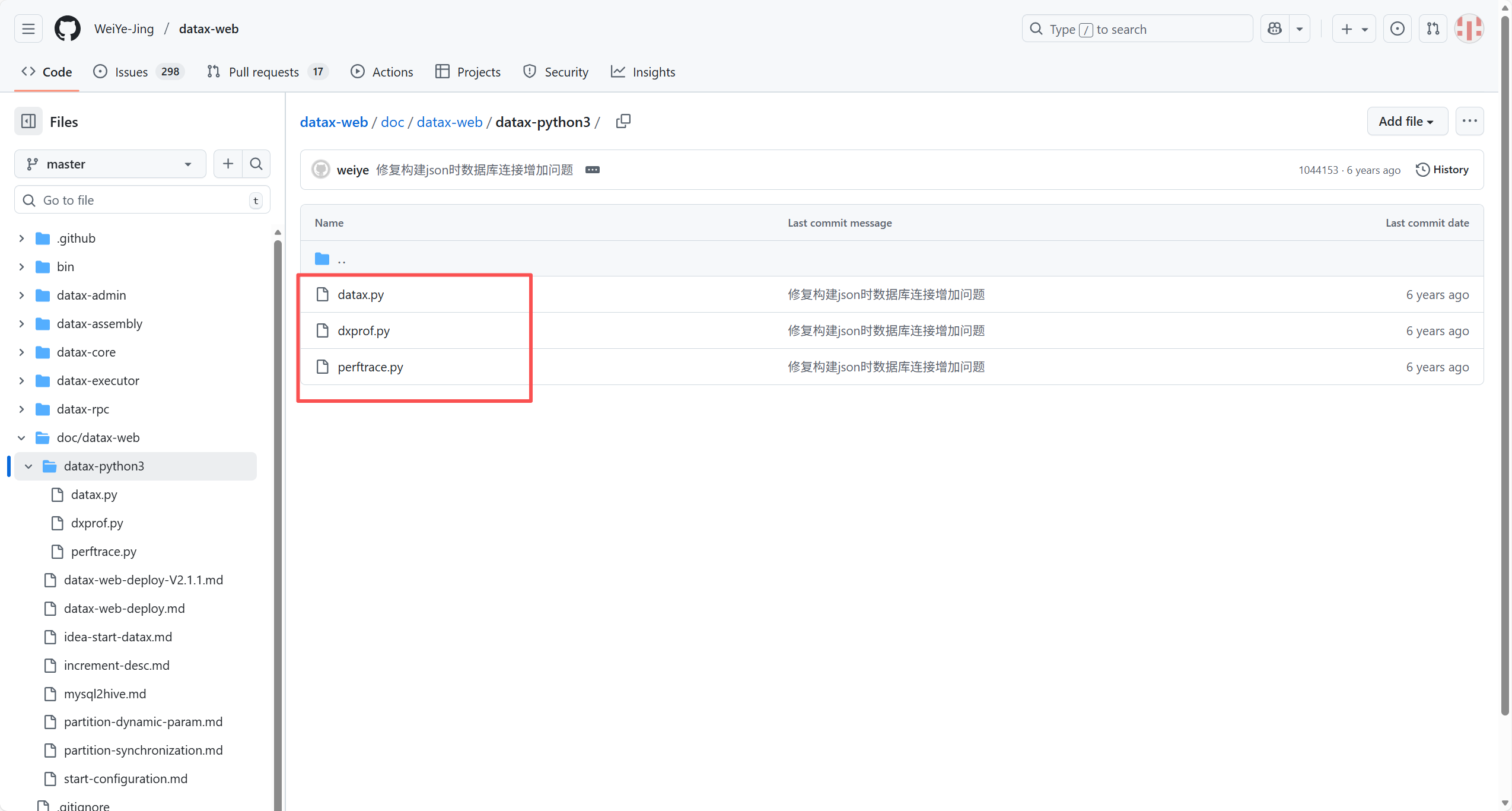
2. 设置 支持 python3(可选)
原因:从github上下载的版本只支持python2.x版本
如果你的python环境是python3.0以上的话,
请到 https://github.com/WeiYe-Jing/datax-web/tree/master/doc/datax-web/datax-python3
下载对应的三个.py文件代替datax文件夹中bin目录下的三个.py文件即可。
3. 测试安装是否成功
cd的安装位置的bin目录下执行
bash
//查看模板
python datax.py -r streamreader -w streamwriter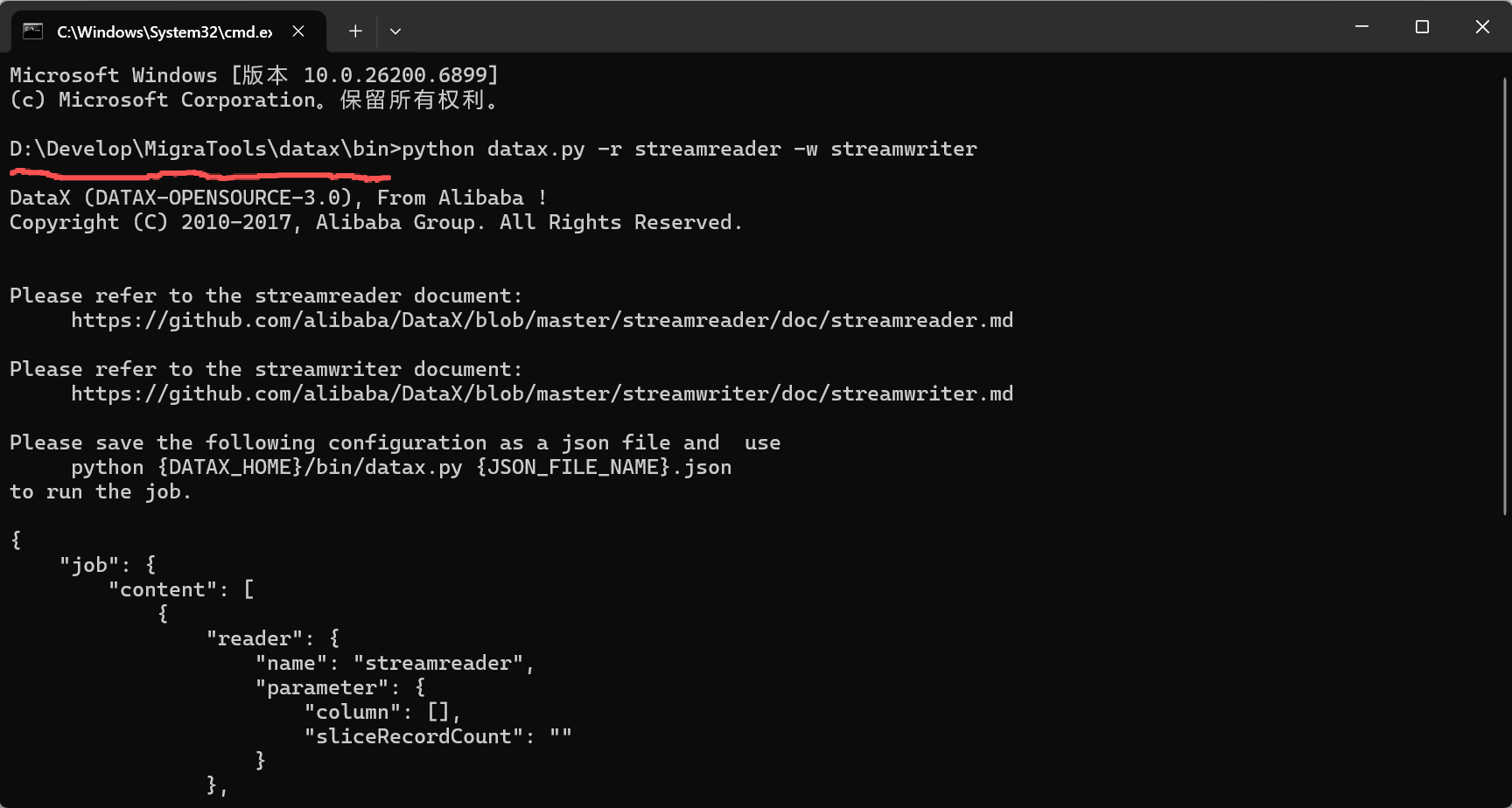
4. 简单的入门测试(mysql案例)
点击一下这个可以找到相关数据库的json脚本格式 进行参考
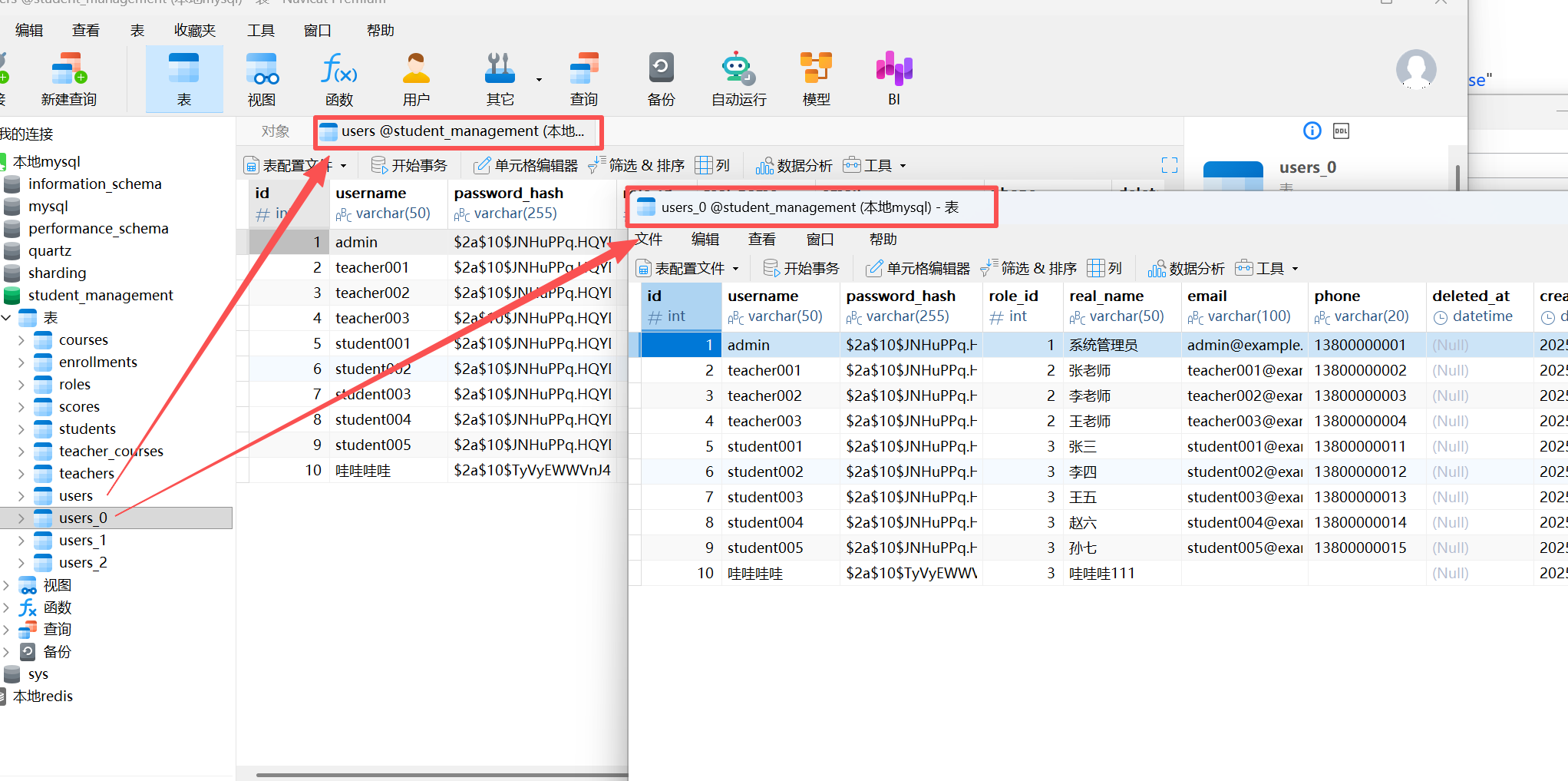
我这边就 把同一个库下面的 user表 里面的数据 写到 user_0 表里面,相关 json 如下:(我命名为job001.json)
bash
{
"job": {
"setting": {
"speed": {
"channel": 2
},
"errorLimit": {
"record": 5,
"percentage": 0.03
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"username",
"password_hash",
"role_id",
"real_name",
"email",
"phone",
"deleted_at",
"created_at",
"updated_at"
],
"connection": [
{
"table": ["users"],
"jdbcUrl": ["jdbc:mysql://localhost:3306/student_management?characterEncoding=utf8&useSSL=false"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"username",
"password_hash",
"role_id",
"real_name",
"email",
"phone",
"deleted_at",
"created_at",
"updated_at"
],
"connection": [
{
"table": ["users_0"],
"jdbcUrl": "jdbc:mysql://localhost:3306/student_management?characterEncoding=utf8&useSSL=false"
}
]
}
}
}
]
}
}放到 datax\job 目录下,然后 到 datax\bin 下 打开 cmd 窗口,执行
bash
python datax.py ../job/job001.json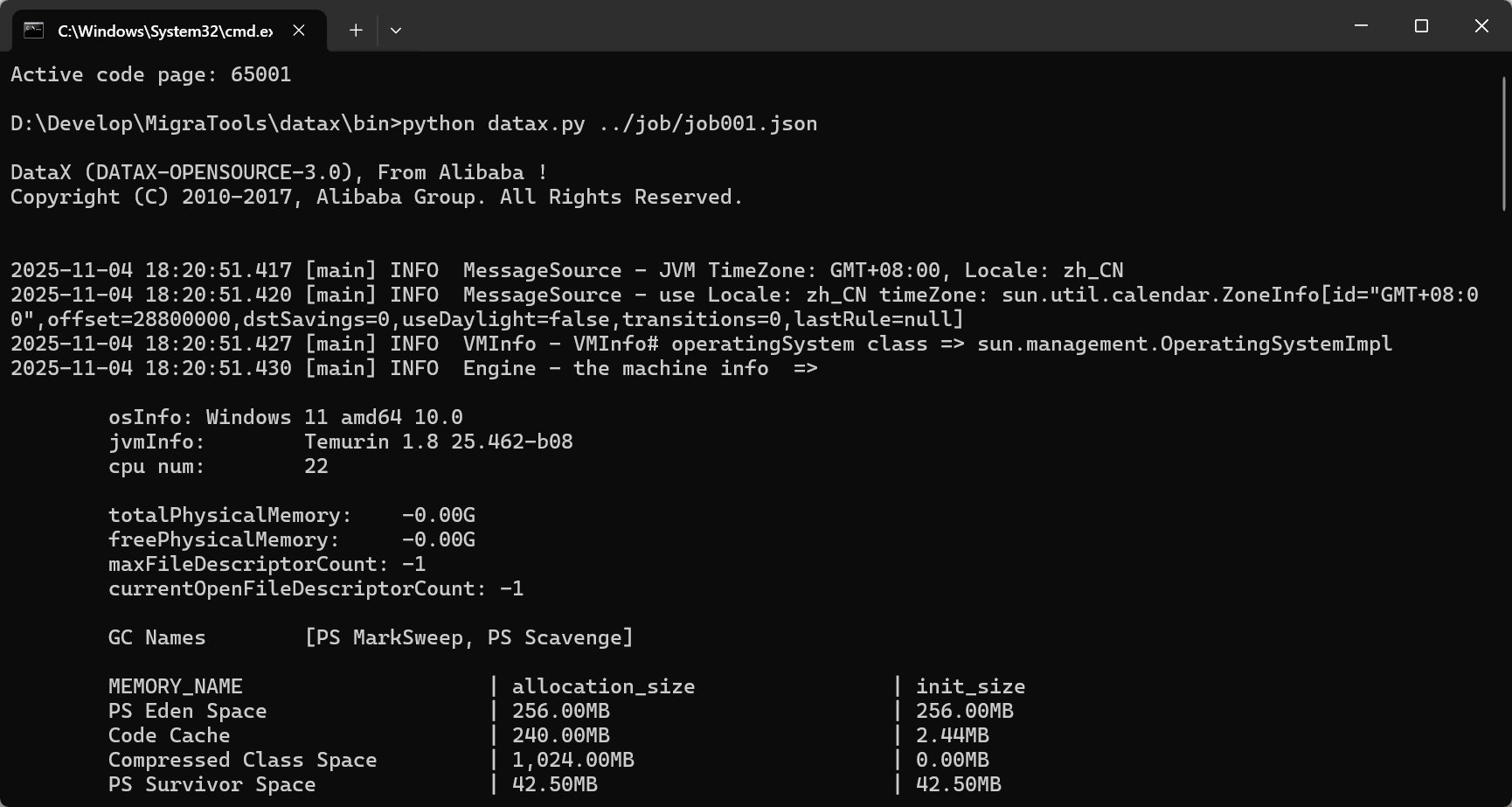
成功 复制过去了
三、DataX-Web 下载
1. 下载源码
bash
git clone https://github.com/WeiYe-Jing/datax-web.git2. 创建数据库
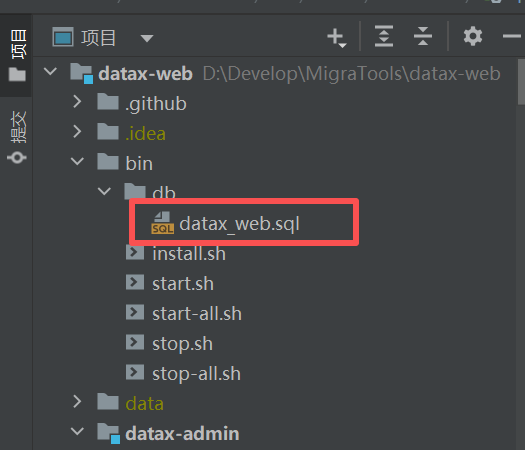
执行bin/db下面的datax_web.sql文件
先自己创建一个datax_web的数据库,再把这个脚本执行一下
3. 修改项目配置
1.修改datax_admin下resources/application.yml文件(按需调整)
yaml
server:
port: 8080
# port: ${server.port}
spring:
#数据源
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/datax_web?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
# password: ${DB_PASSWORD:password}
# username: ${DB_USERNAME:username}
# url: jdbc:mysql://${DB_HOST:127.0.0.1}:${DB_PORT:3306}/${DB_DATABASE:dataxweb}?serverTimezone=Asia/Shanghai&useLegacyDatetimeCode=false&useSSL=false&nullNamePatternMatchesAll=true&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
hikari:
## 最小空闲连接数量
minimum-idle: 5
## 空闲连接存活最大时间,默认600000(10分钟)
idle-timeout: 180000
## 连接池最大连接数,默认是10
maximum-pool-size: 10
## 数据库连接超时时间,默认30秒,即30000
connection-timeout: 30000
connection-test-query: SELECT 1
##此属性控制池中连接的最长生命周期,值0表示无限生命周期,默认1800000即30分钟
max-lifetime: 1800000
# datax-web email
mail:
host: smtp.qq.com
port: 25
username: xxx@qq.com
password: xxx
# username: ${mail.username}
# password: ${mail.password}
properties:
mail:
smtp:
auth: true
starttls:
enable: true
required: true
socketFactory:
class: javax.net.ssl.SSLSocketFactory
management:
health:
mail:
enabled: false
server:
servlet:
context-path: /actuator
mybatis-plus:
# mapper.xml文件扫描
mapper-locations: classpath*:/mybatis-mapper/*Mapper.xml
# 实体扫描,多个package用逗号或者分号分隔
#typeAliasesPackage: com.yibo.essyncclient.*.entity
global-config:
# 数据库相关配置
db-config:
# 主键类型 AUTO:"数据库ID自增", INPUT:"用户输入ID", ID_WORKER:"全局唯一ID (数字类型唯一ID)", UUID:"全局唯一ID UUID";
id-type: AUTO
# 字段策略 IGNORED:"忽略判断",NOT_NULL:"非 NULL 判断"),NOT_EMPTY:"非空判断"
field-strategy: NOT_NULL
# 驼峰下划线转换
column-underline: true
# 逻辑删除
logic-delete-value: 0
logic-not-delete-value: 1
# 数据库类型
db-type: mysql
banner: false
# mybatis原生配置
configuration:
map-underscore-to-camel-case: true
cache-enabled: false
call-setters-on-nulls: true
jdbc-type-for-null: 'null'
type-handlers-package: com.wugui.datax.admin.core.handler
# 配置mybatis-plus打印sql日志
logging:
level:
com.wugui.datax.admin.mapper: info
path: ./data/applogs/admin
# level:
# com.wugui.datax.admin.mapper: error
# path: ${data.path}/applogs/admin
#datax-job, access token
datax:
job:
accessToken:
#i18n (default empty as chinese, "en" as english)
i18n:
## triggerpool max size
triggerpool:
fast:
max: 200
slow:
max: 100
### log retention days
logretentiondays: 30
datasource:
aes:
key: AD42F6697B035B752.修改datax_executor下resources/application.yml文件(按需调整)
yaml
# web port
server:
# port: ${server.port}
port: 8081
# log config
logging:
config: classpath:logback.xml
# path: ${data.path}/applogs/executor/jobhandler
path: ./data/applogs/executor/jobhandler
datax:
job:
admin:
### datax admin address list, such as "http://address" or "http://address01,http://address02"
addresses: http://127.0.0.1:8080
# addresses: http://127.0.0.1:${datax.admin.port}
executor:
appname: datax-executor
ip:
#port: 9999
port: ${executor.port:9999}
### job log path
logpath: ./data/applogs/executor/jobhandler
# logpath: ${data.path}/applogs/executor/jobhandler
### job log retention days
logretentiondays: 30
### job, access token
accessToken:
executor:
jsonpath: D:\\temp\\executor\\json\\
# jsonpath: ${json.path}
pypath: D:\Develop\MigraTools\datax\bin\datax.py
# pypath: ${python.path}- admin.addresses datax_admin部署地址,如调度中心集群部署存在多个地址则用逗号分隔,执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";
- executor.appname 执行器AppName,每个执行器机器集群的唯一标示,执行器心跳注册分组依据;
- executor.ip 默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
- executor.port 执行器Server端口号,默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
- executor.logpath 执行器运行日志文件存储磁盘路径,需要对该路径拥有读写权限;
- executor.logretentiondays 执行器日志文件保存天数,过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
- executor.jsonpath datax json临时文件保存路径
- pypath DataX启动脚本地址,例如:xxx/datax/bin/datax.py(这个路径是上面搭建 dataX 已经创建好的启动脚本)
如果系统配置DataX环境变量(DATAX_HOME),logpath、jsonpath、pypath可不配,log文件和临时json存放在环境变量路径下。
4. 启动项目
- 1.运行datax_admin下 DataXAdminApplication
- 2.运行datax_executor下 DataXExecutorApplication
admin启动成功后日志会输出三个地址,两个接口文档地址,一个前端页面地址
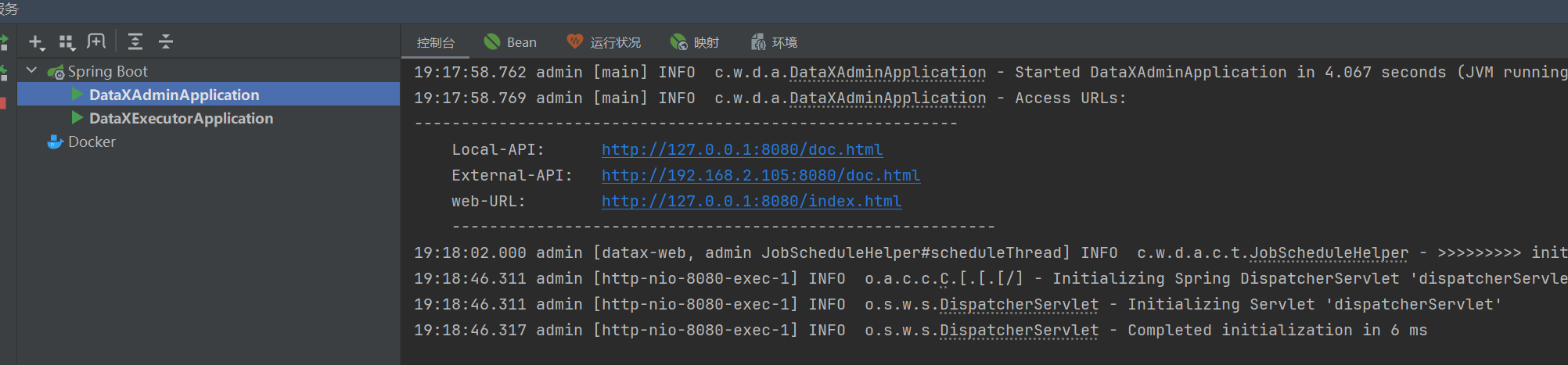
5. 启动成功
启动成功后打开页面(默认管理员用户名:admin 密码:123456)
http://127.0.0.1:8080/index.html
6. 实战
1. 项目管理-添加项目
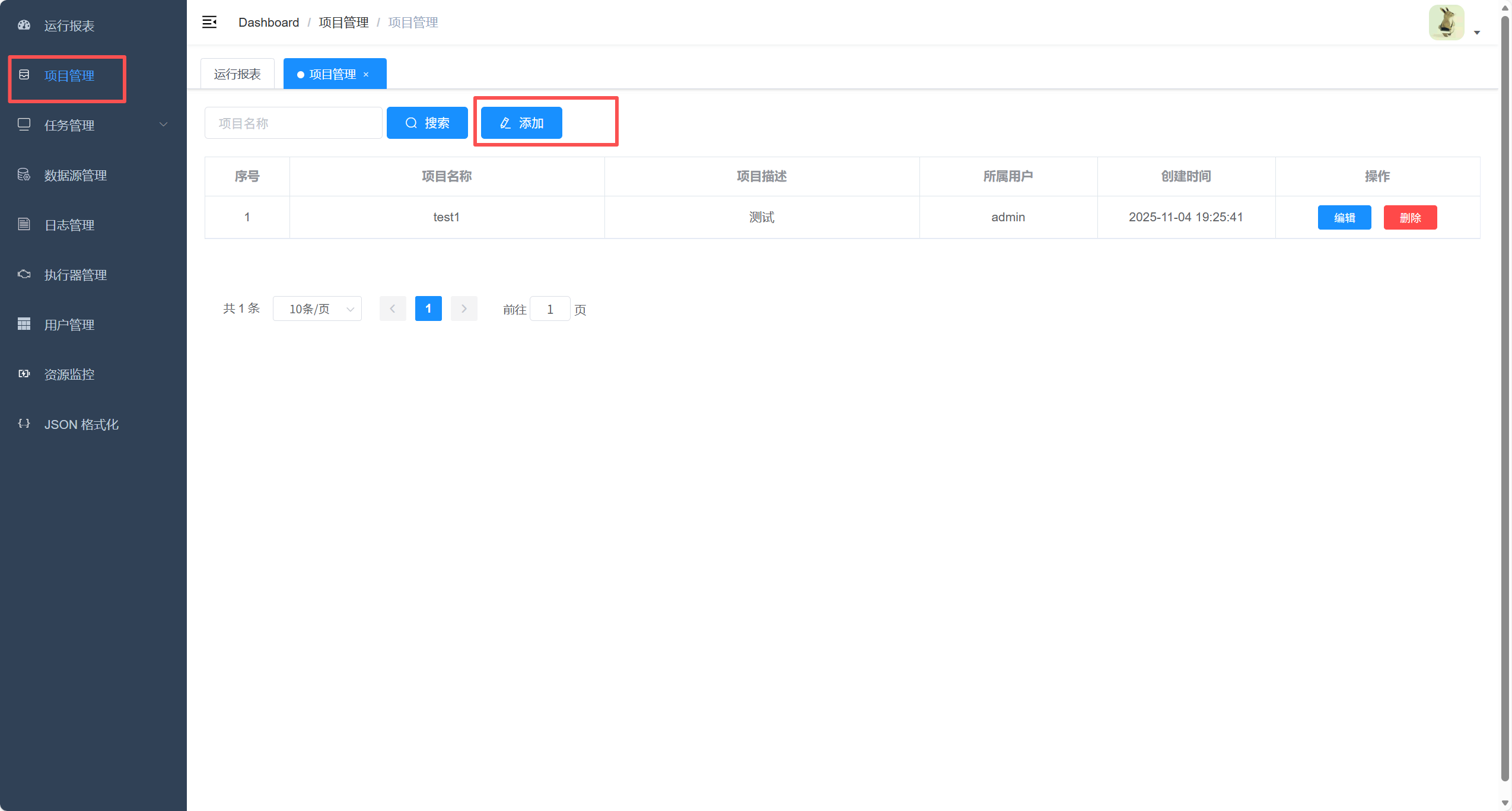
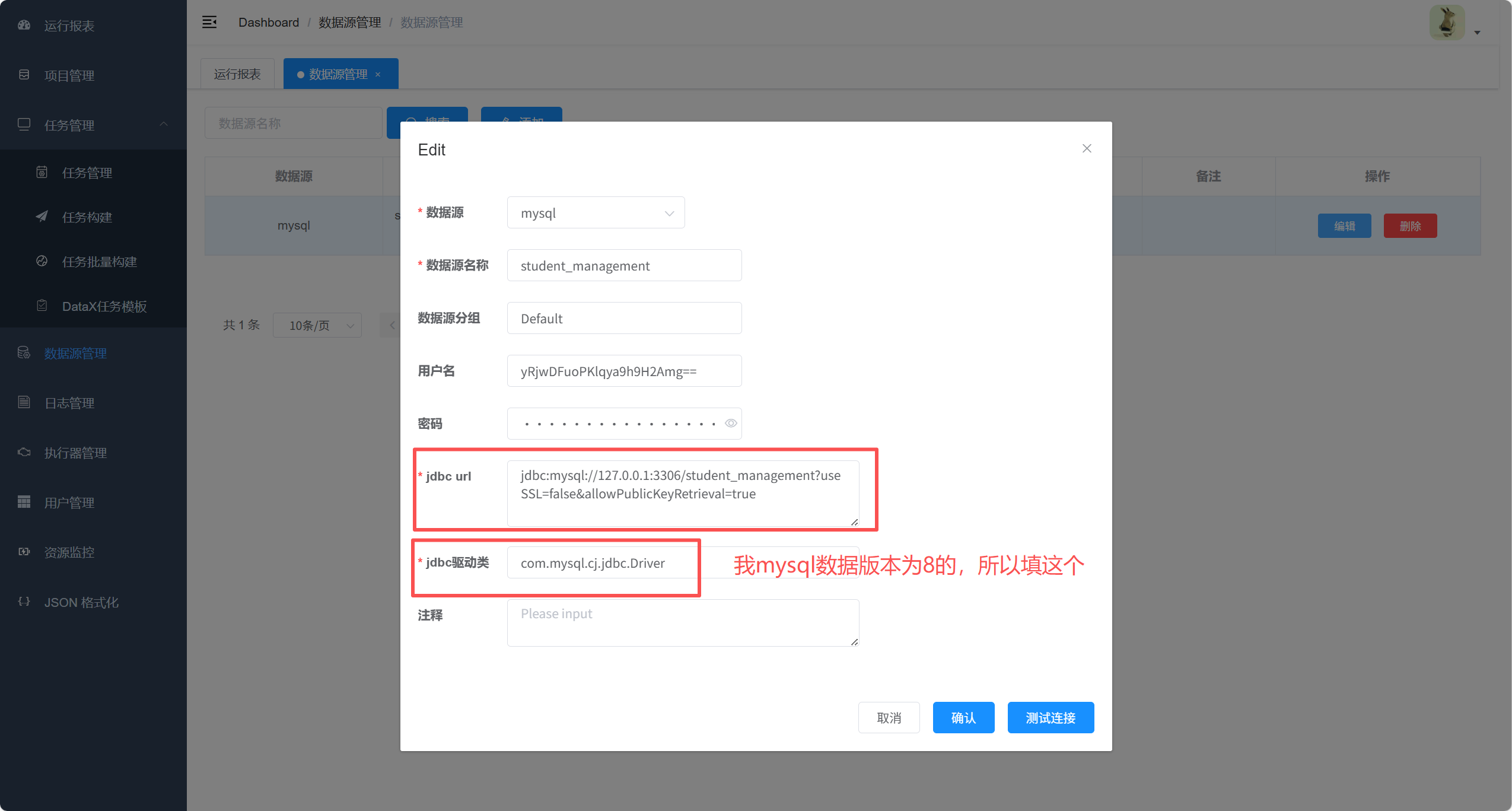
2. 配置数据源
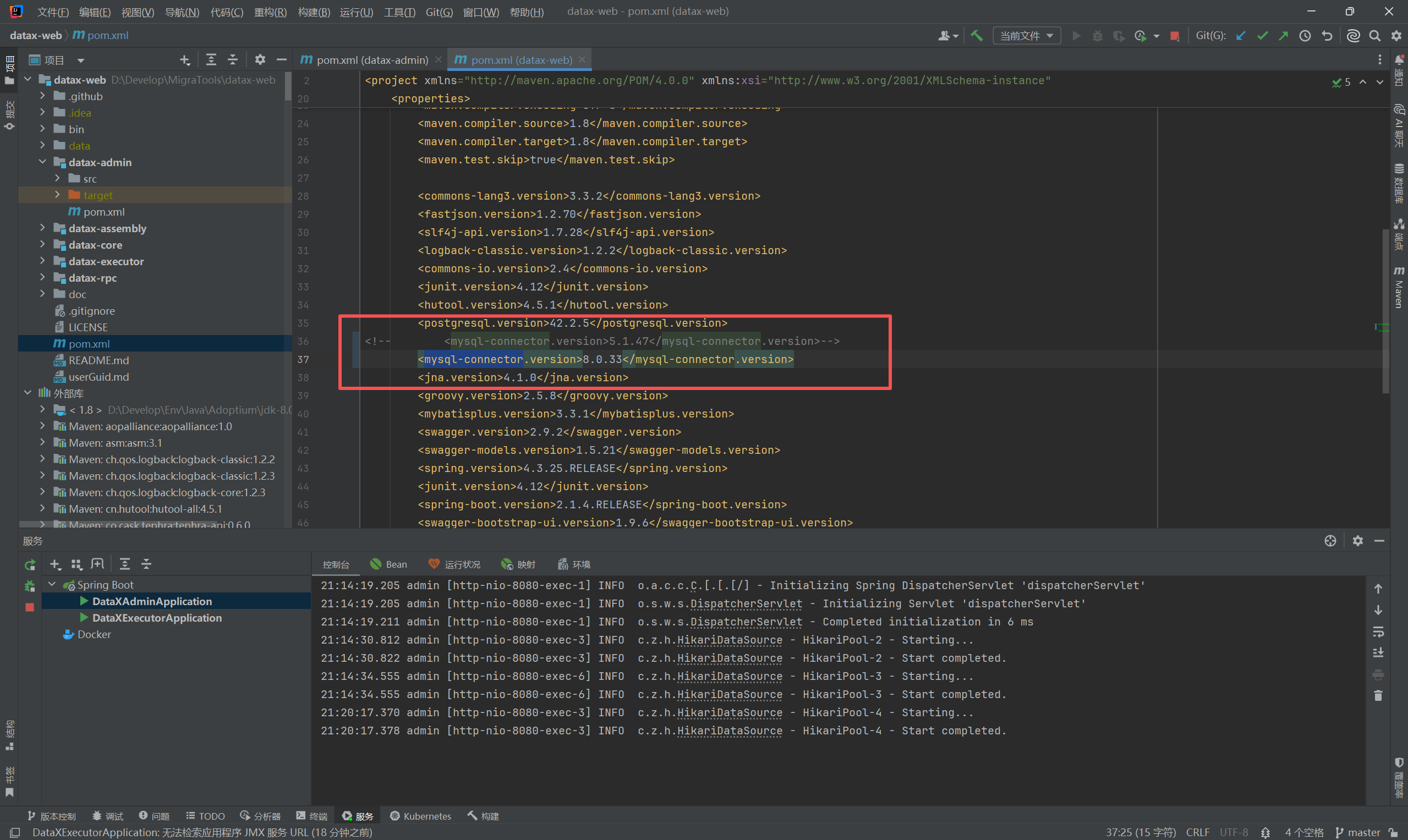
注意:驱动和数据库版本一定要一致!!!
DataX-Admin 的 MySQL 驱动默认是 用的 5.1.49 , DataX 的 mysqlreader 和 mysqlwriter 的 mysql 驱动插件 默认也是 5.1.49
而我的mysql数据库是8.0.44版本的,所以导致定时任务一直是在连接中,没有往下跑
所以我将 DataX-Admin 的 MySQL 驱动 和 DataX 的 mysqlreader 和 mysqlwriter 的 mysql 驱动插件 都换成了 8.0.33版本的
DataX-Admin 具体操作如下
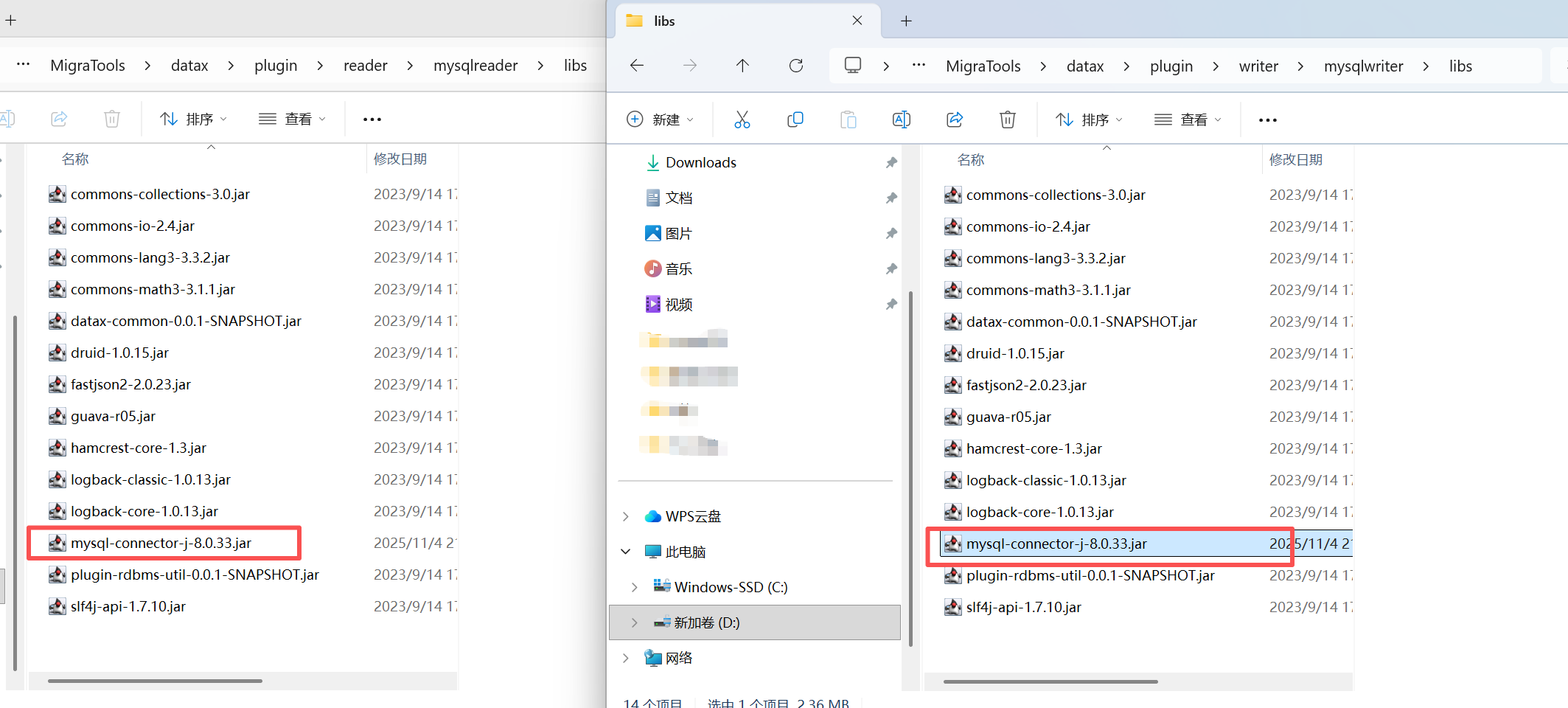
DataX 的 mysqlreader 和 mysqlwriter 的 操作如下
旧的mysql驱动版本我删除掉了
mysql8.0.33这个jar的下载地址为https://mvnrepository.com/artifact/com.mysql/mysql-connector-j/8.0.33
3. 创建执行器
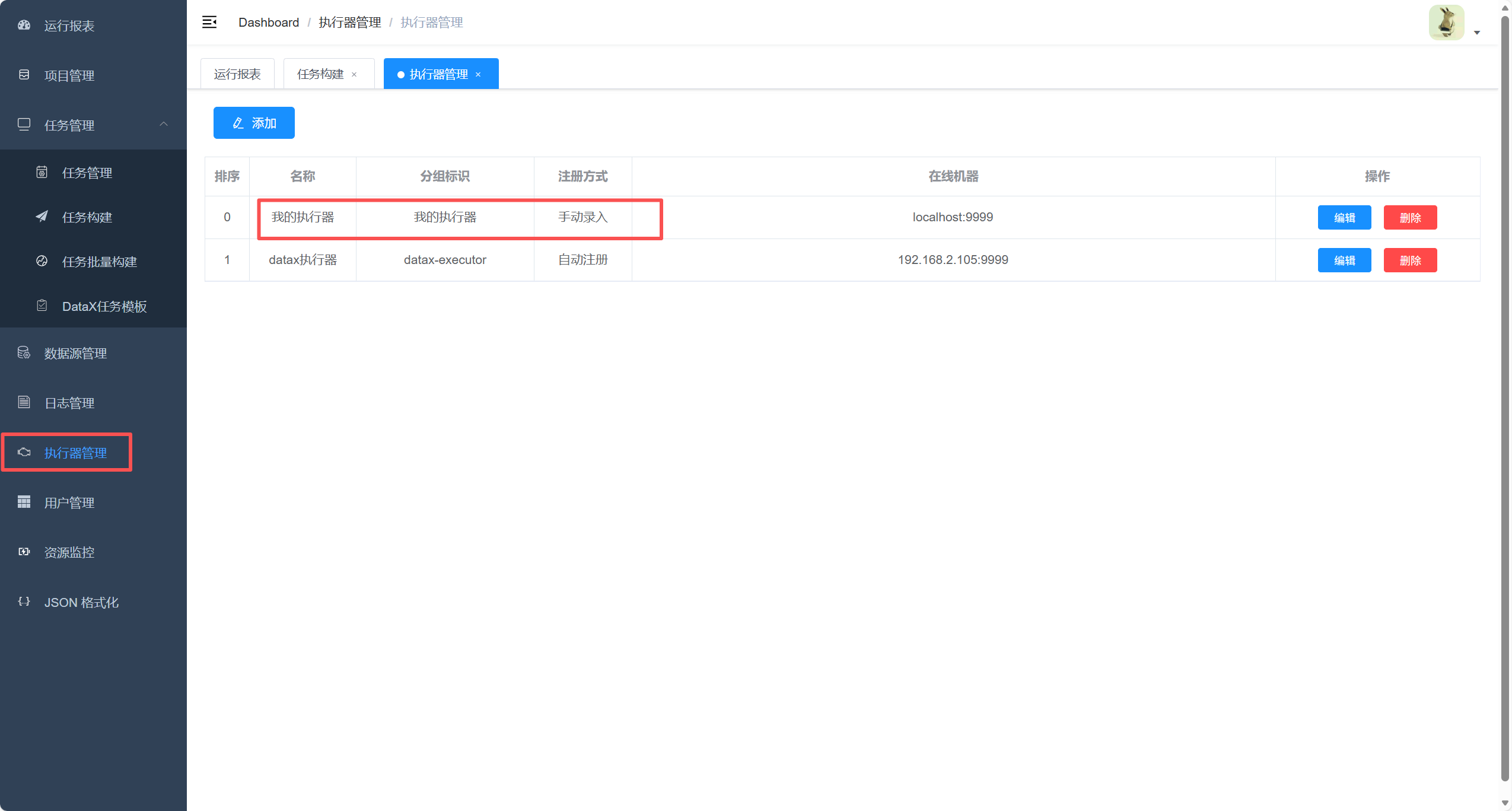
4. 创建DataX任务模板
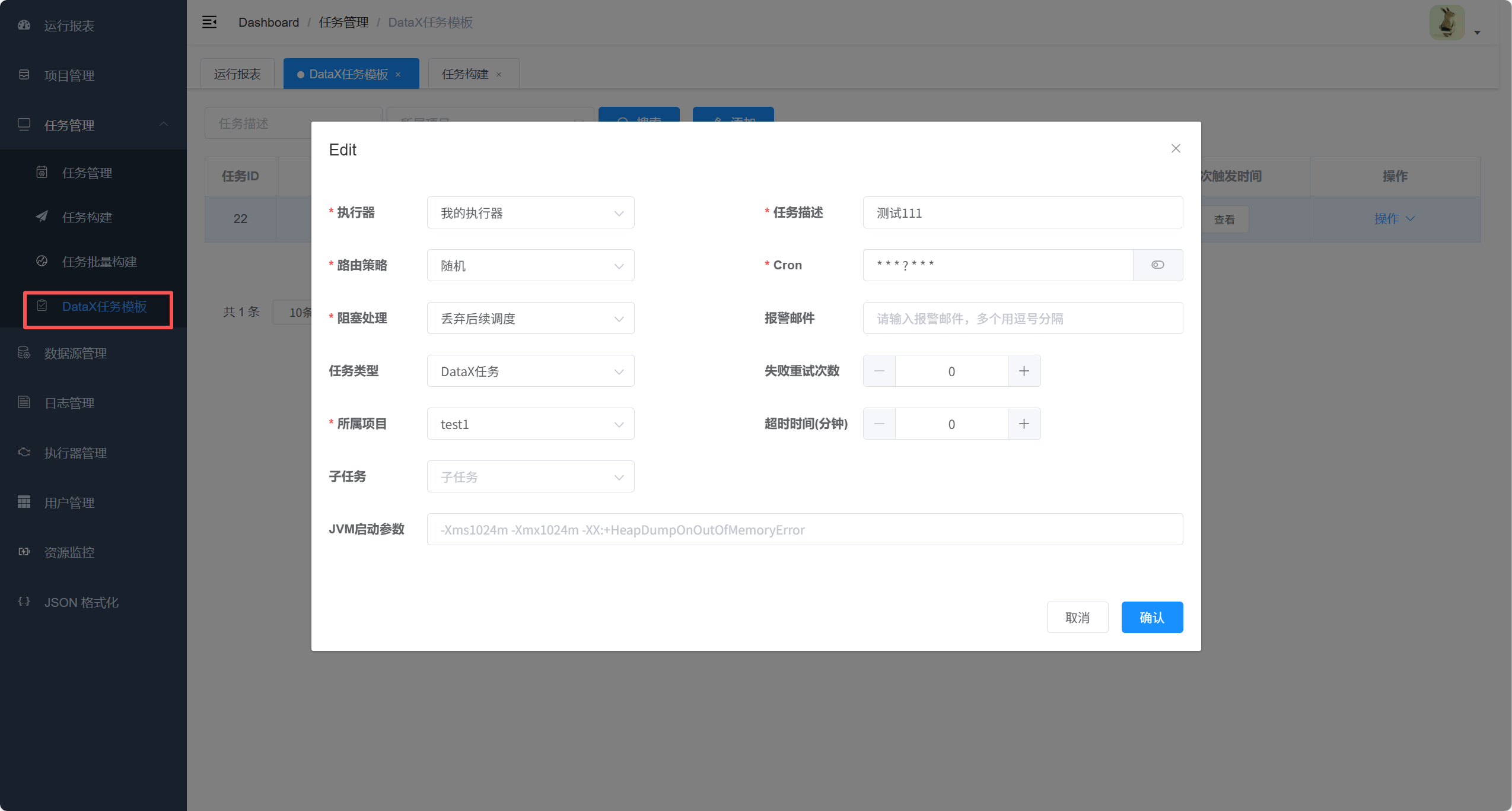
5. 构建任务生成同步 json
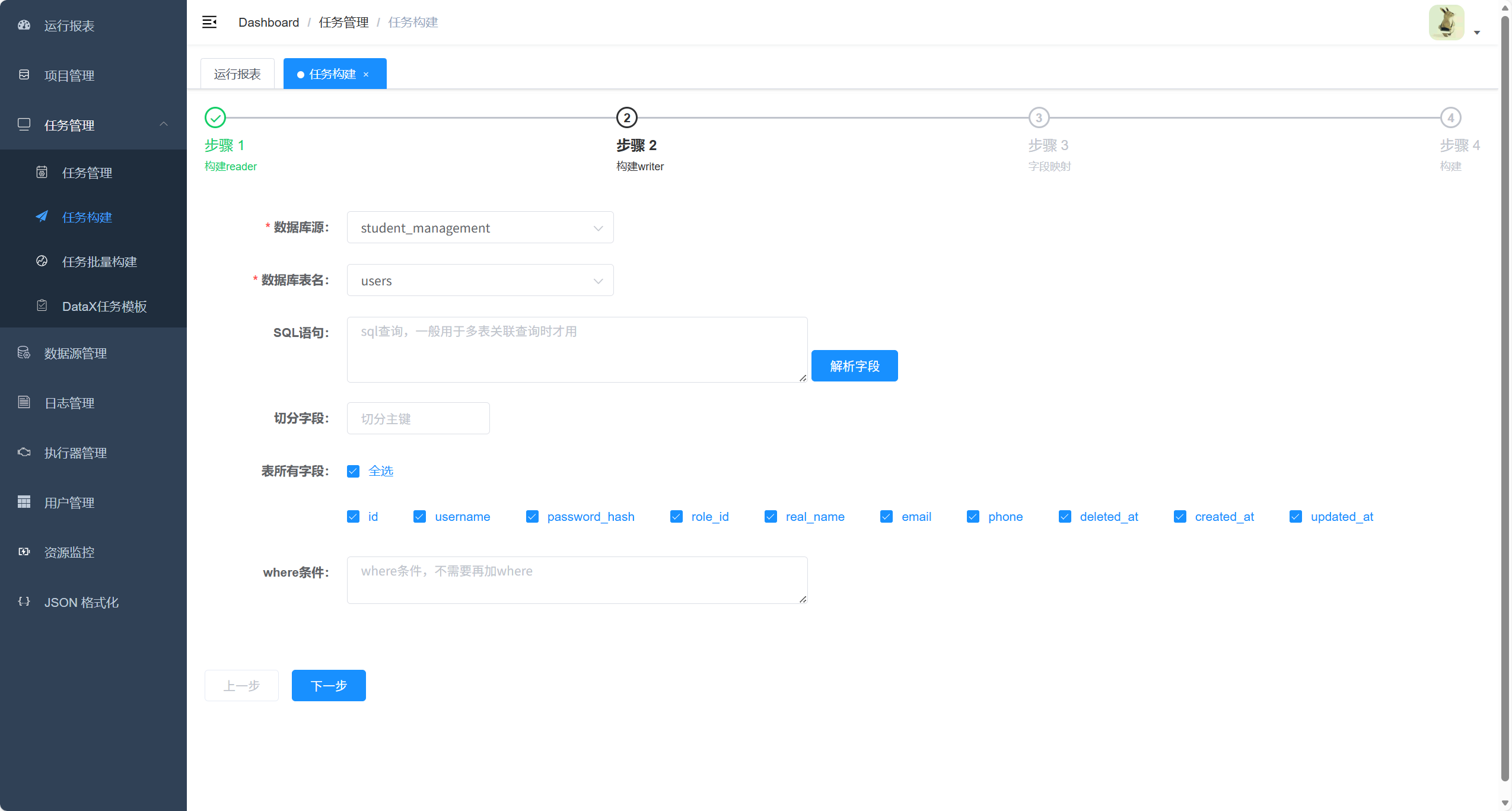
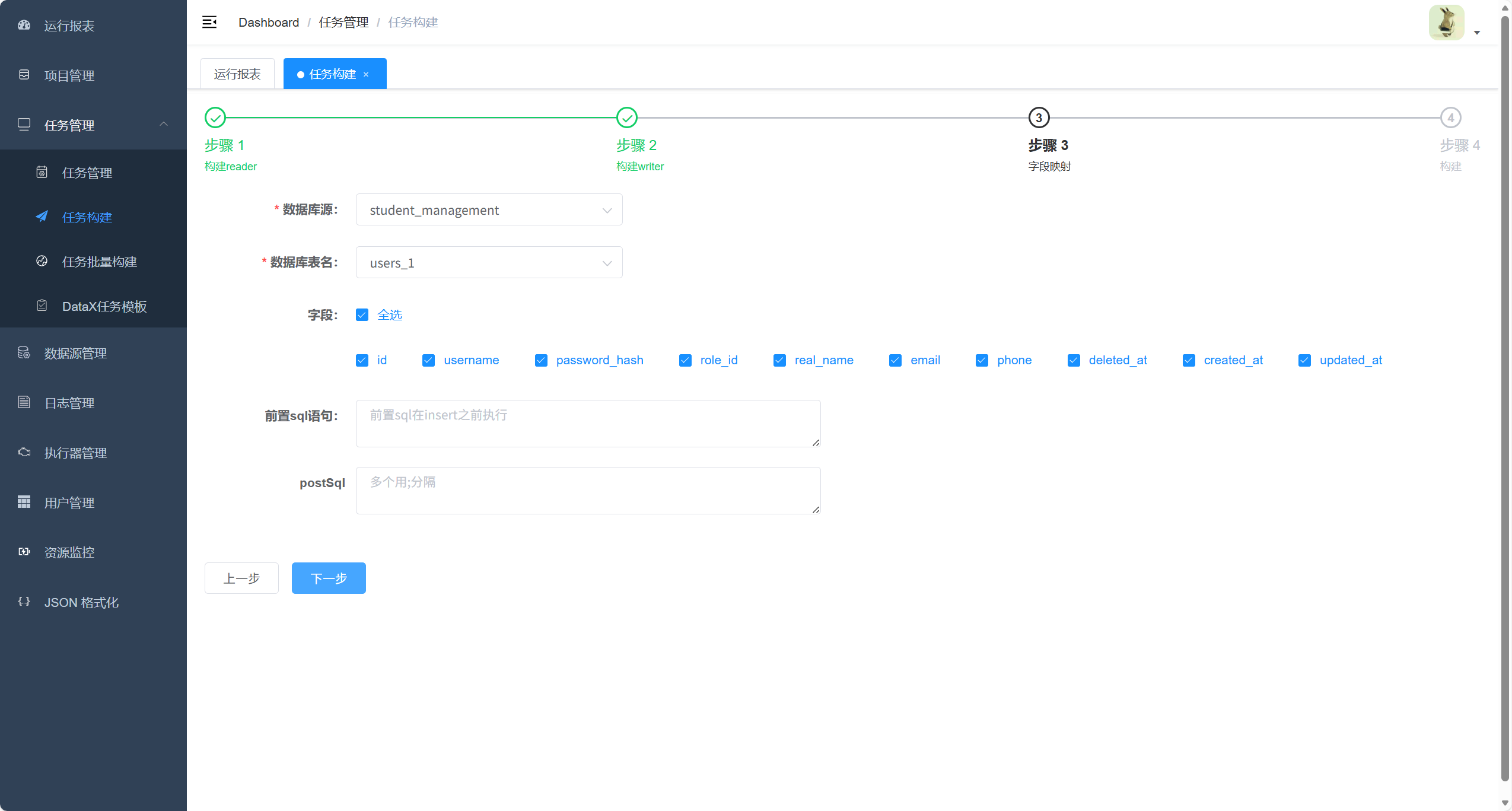
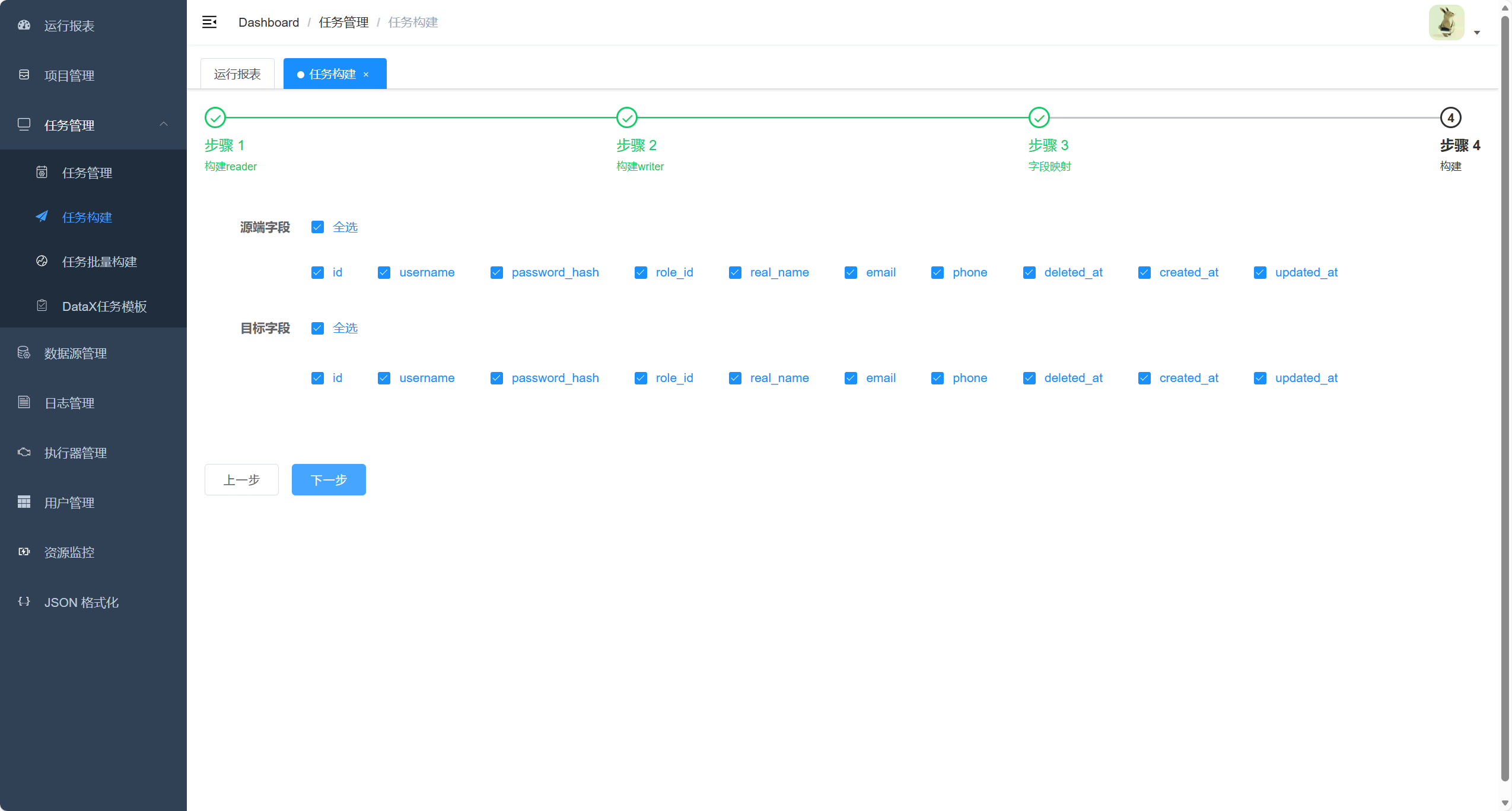
点击构建
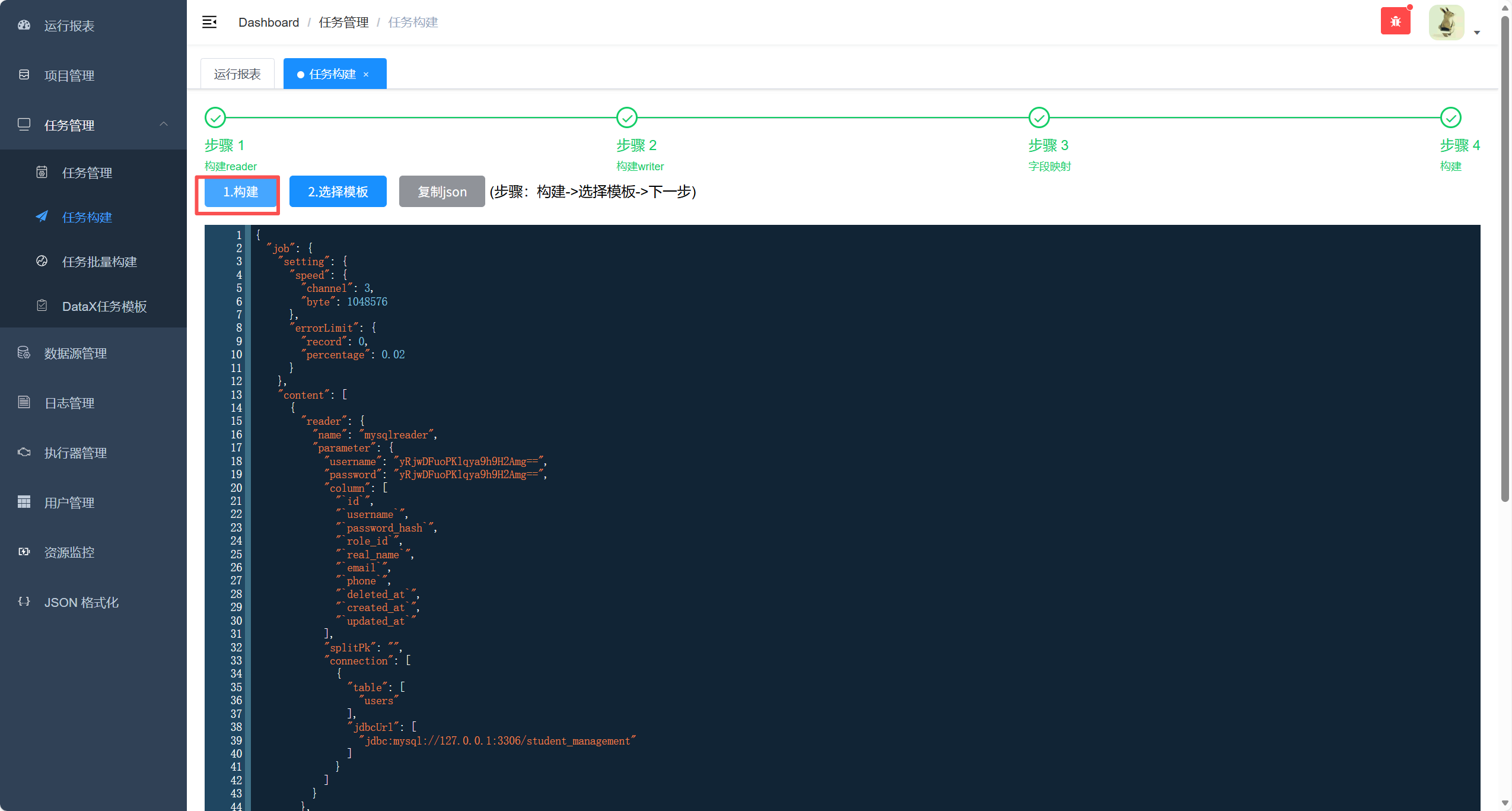
点击选择模板
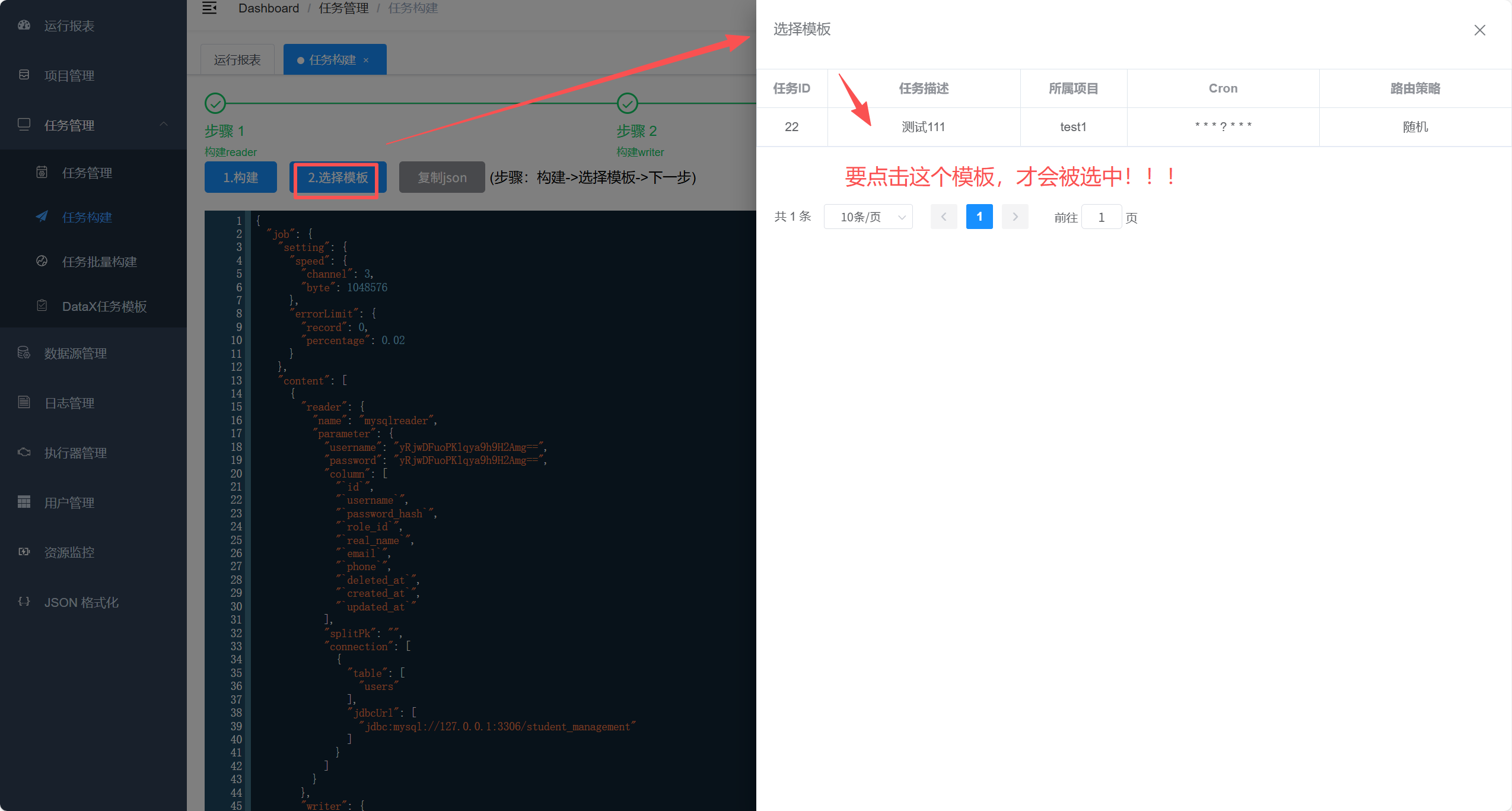
以下情况才是表示选中成功
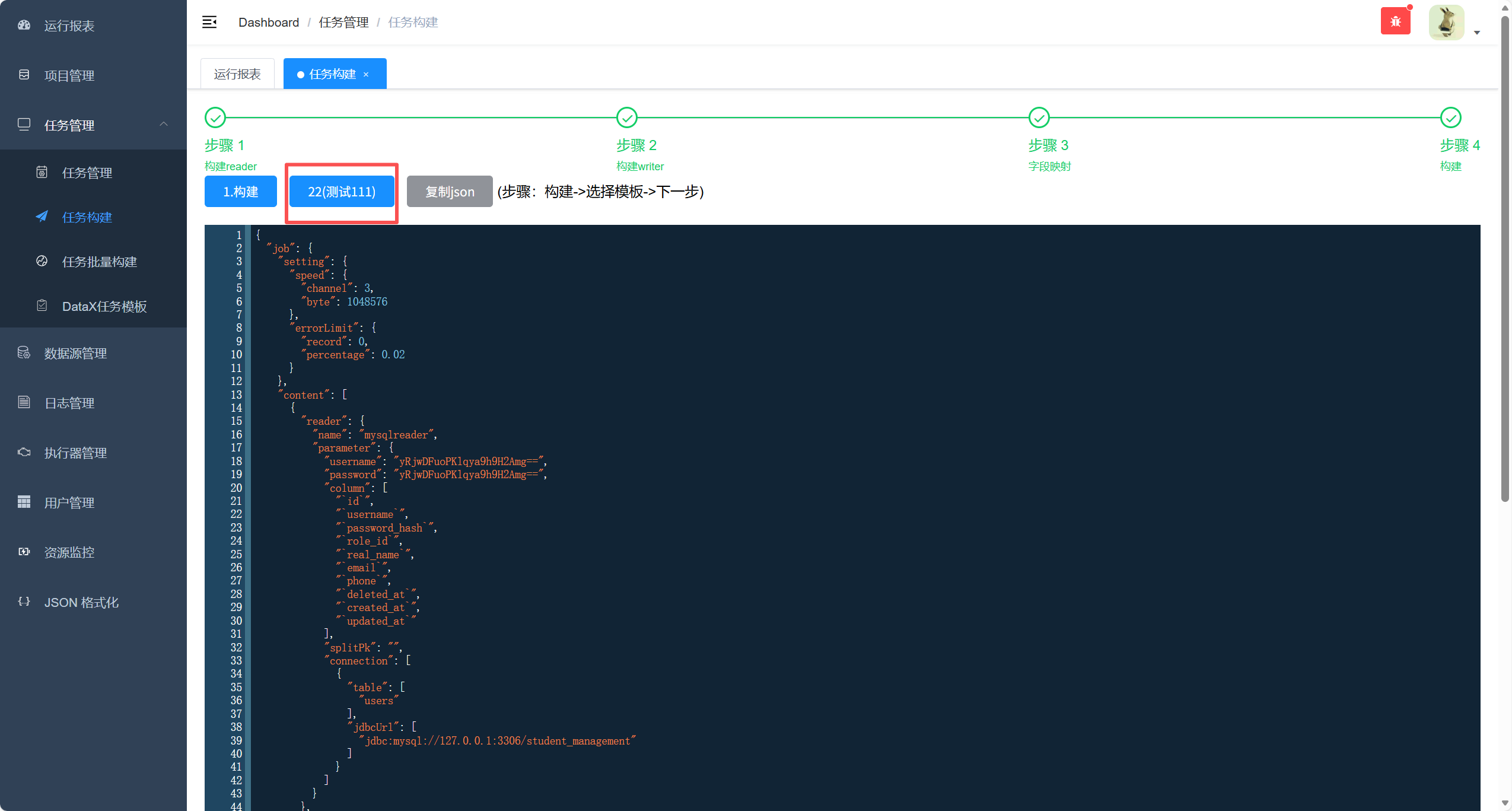
再点击下一步
6. 任务管理
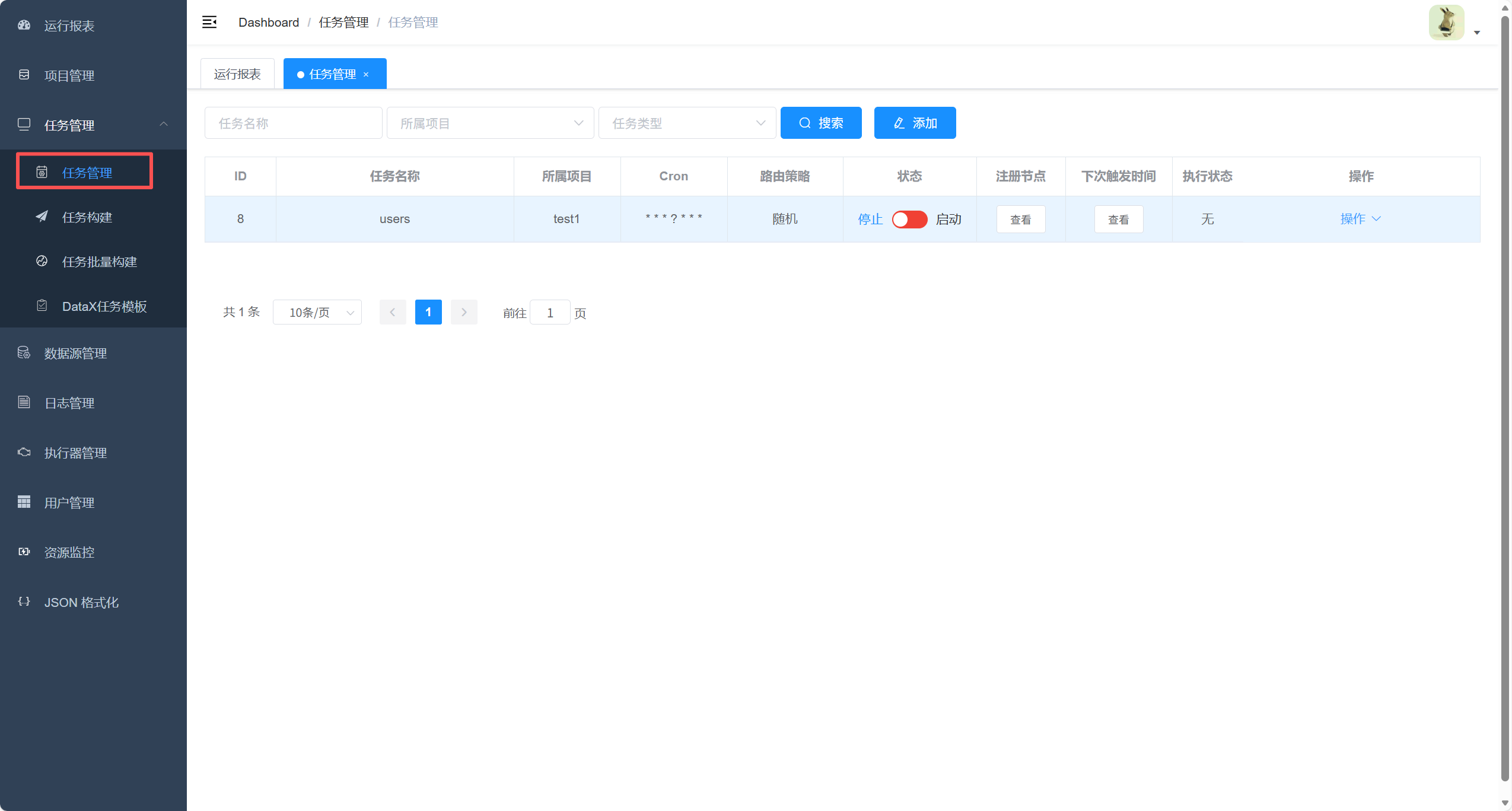
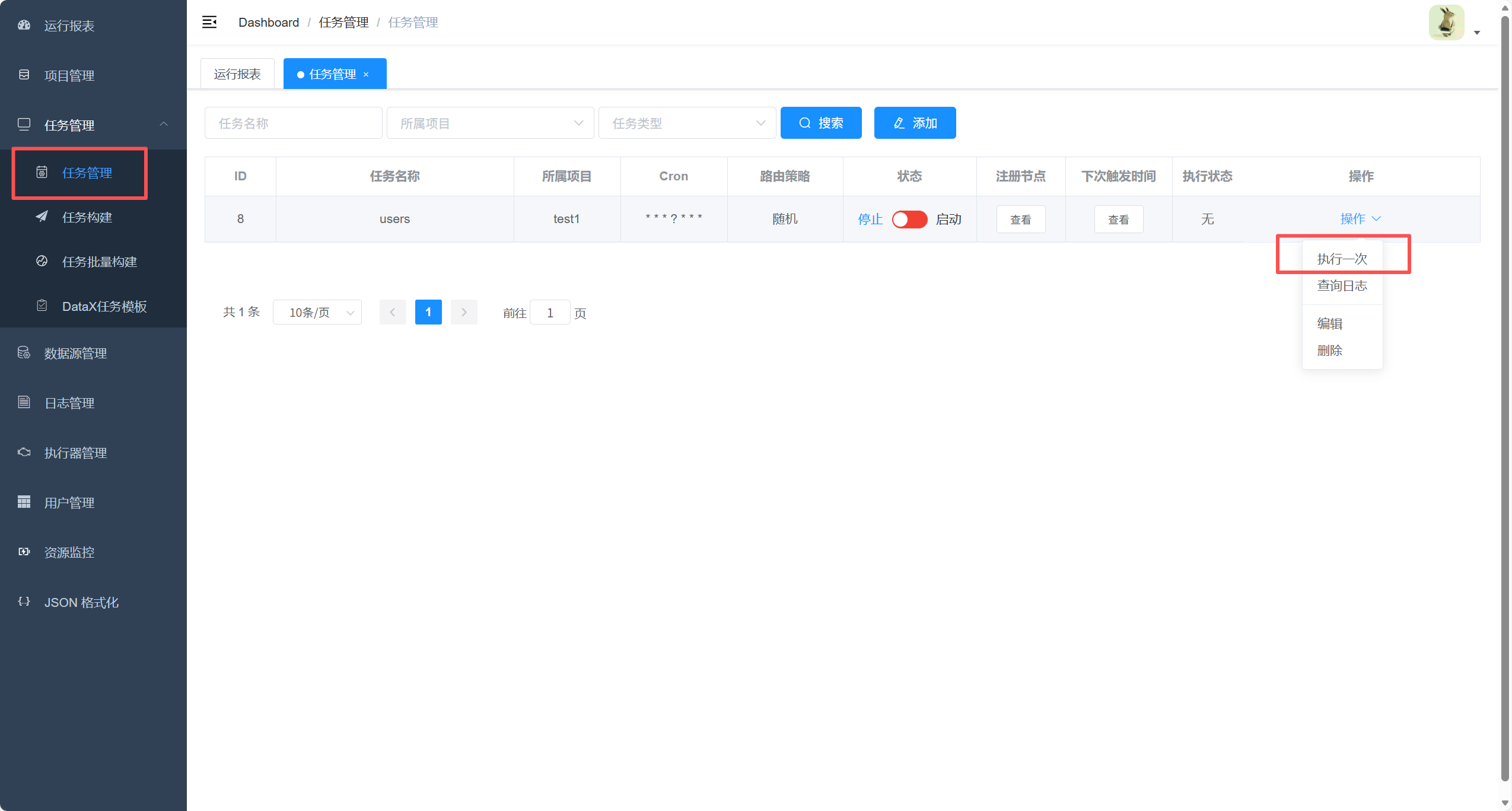
点击执行一次看看效果
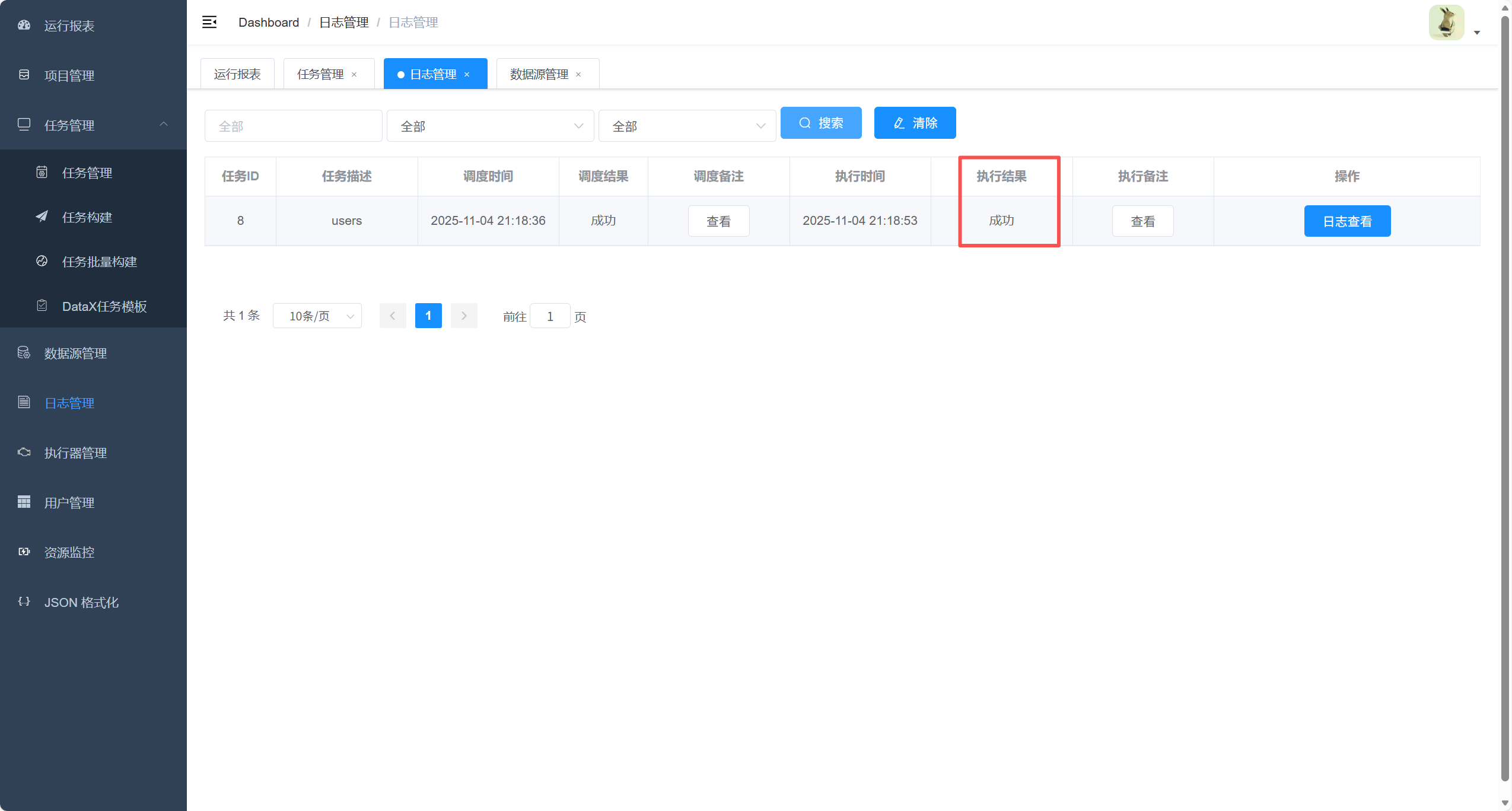
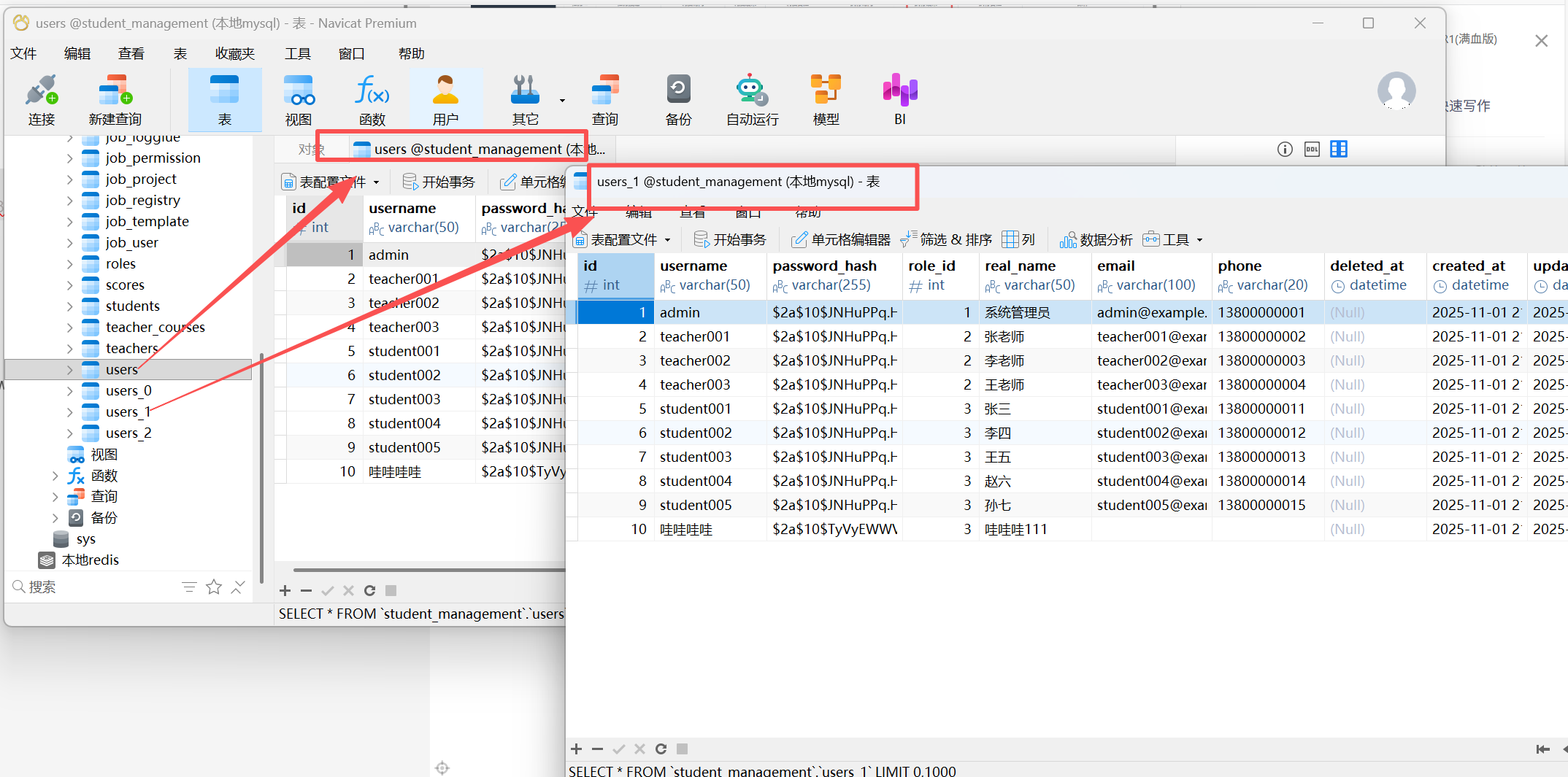
数据库的情况
四、报错
1.在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数
原来的如下:
yaml
"setting": {
"speed": {
"byte": 1048576,
"channel": 3
}
}删除 speed.byte 配置,仅保留 channel 数(由 DataX 自动适配):
yaml
"setting": {
"speed": {
"channel": 3
}
}