在今天的大数据时代,企业的数据管理和处理变得愈发重要。企业也越来越依赖于数据仓库和数据湖来提取、转换和加载(ETL)关键业务信息。一个高效、灵活的ETL解决方案不仅能提升数据处理能力,还能为企业决策提供有力支持。然而,市场上ETL工具和解决方案琳琅满目,如何选择最适合企业需求的解决方案成为了许多IT部门和数据分析师面临的难题。以下是一些关键步骤和考量因素,帮助您在众多选项中作出明智的选择。
1.明确业务需求
首先,企业需要清晰地定义其ETL需求。这包括数据来源、数据量、处理频率、转换复杂度以及目标存储系统。例如,如果您的企业处理的是大量实时数据,那么对实时ETL功能的需求就会高于那些处理批量数据的企业。明确需求可以帮助您筛选出那些能够直接解决您特定问题的解决方案。
2.数据源和目标系统的兼容性
一个优秀的ETL解决方案应该能够无缝集成多种数据源,包括关系型数据库、非关系型数据库、云存储服务以及各种SaaS应用。同时,它还应该能够将数据加载到多种数据仓库和数据湖平台。
3.可扩展性和灵活性
随着企业数据量的增长,ETL解决方案需要具备良好的可扩展性,以适应不断变化的数据需求。此外,解决方案应该提供灵活的工作流设计,允许企业根据业务需求自定义数据转换逻辑。
4.性能和可靠性
性能是衡量ETL解决方案的另一个重要指标。企业需要确保所选解决方案能够处理大规模数据量,并且在高并发情况下保持稳定。同时,解决方案应该提供故障恢复和数据备份功能,确保数据的可靠性。
5.用户体验、客户支持和社区资源
ETL解决方案应该提供直观的用户界面,使得非技术用户也能轻松管理和监控数据集成过程。同时一个有良好技术支持和活跃用户社区的供应商,可以在遇到问题时获得及时帮助。了解供应商的客户服务响应时间、技术支持级别、更新频率以及用户社区的活动情况。
6.ETL解决方案推荐
虽然市面上的ETL工具众多,鱼龙混杂,但是不乏一些有出色的ETL工具。在这些ETl工具中有三款是最为流行的,它们分别是ETLCloud、DataX和Kettle。
Kettle
Kettle是一款国外开源的ETL工具,是一款在ETL(Extract, Transform, Load)领域使用最广泛的ETL工具。它有着直观易用的图形化界面和功能全面的转换组件,但是它的学习曲线非常陡峭,在面对复杂的数据转换任务时,用户最好具备一定的数据处理和编程知识。同时原生的kettle本身不直接支持CDC(Change Data Capture)实时数据采集功能,需要用户频繁的调度任务来近似实现实时数据传输。
ETLCloud
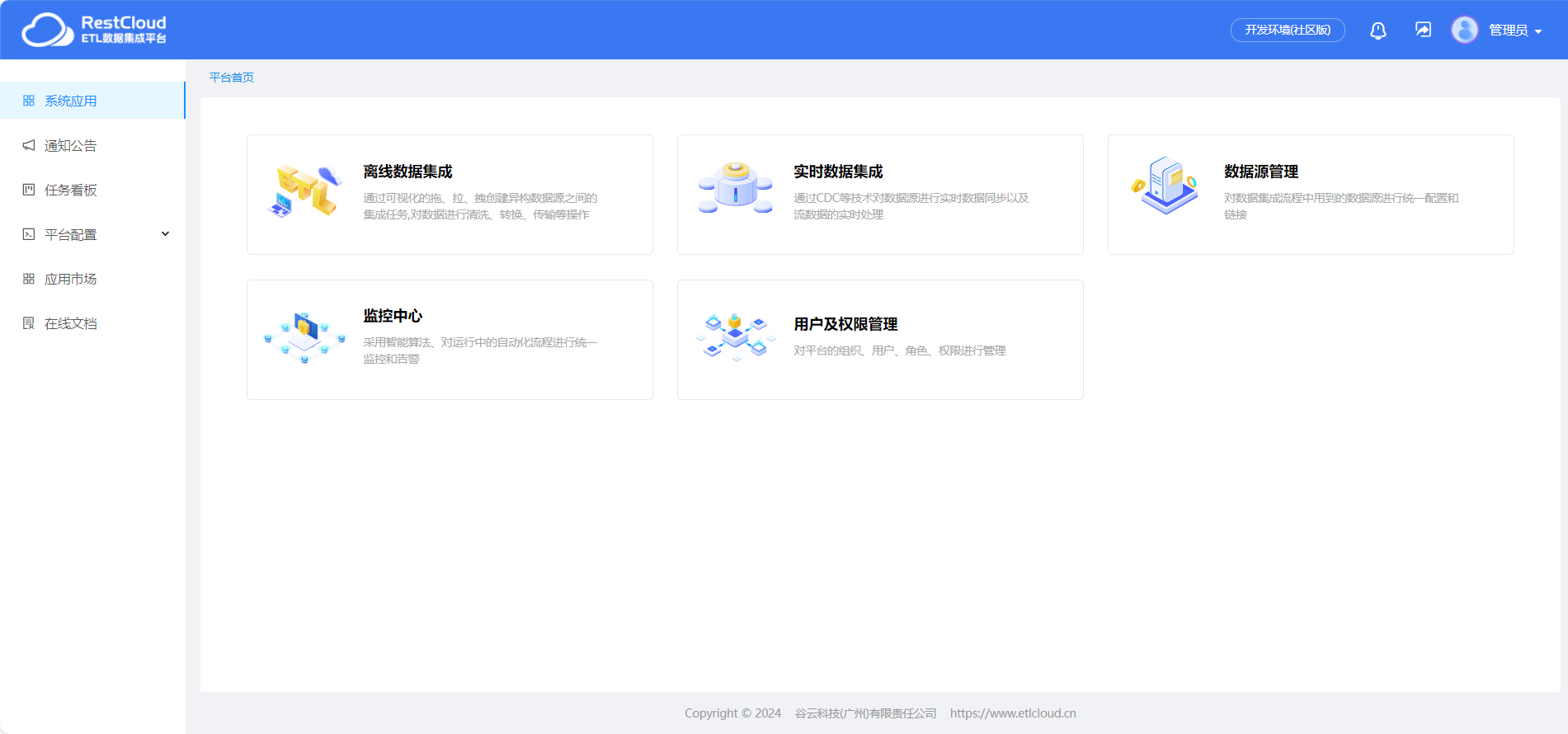
ETLCloud提供了一站式的数据集成解决方案,支持ETL、ELT、CDC和API等多种数据集成能力。企业可以在一个统一的平台上完成数据的提取、转换、加载,也可以灵活地进行数据的抽取、加载、转换,实时数据的监听和传输,以及API服务的发布。
1.支持丰富的数据源和目标系统兼容
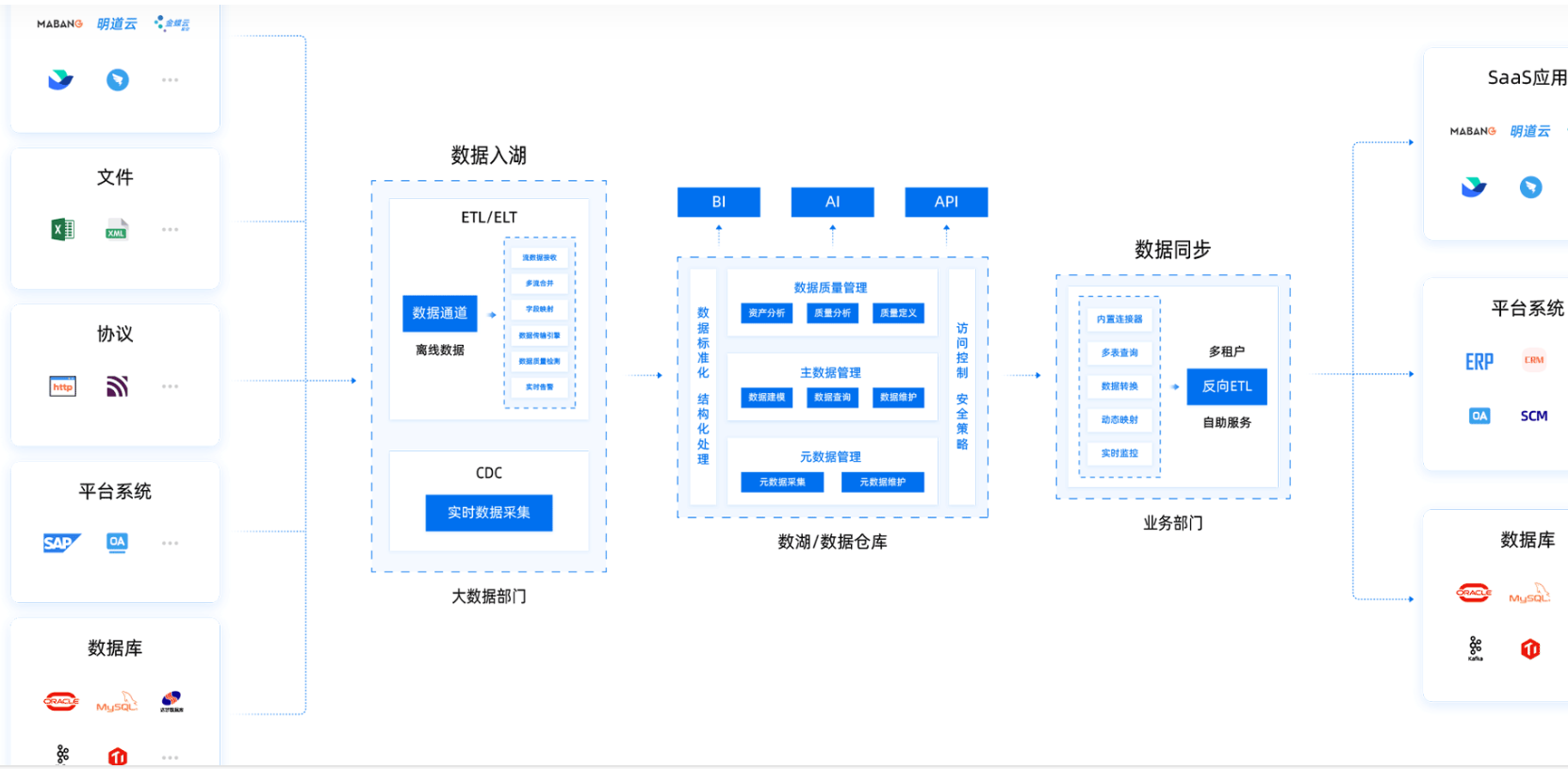
提供对数十种SQL和NOSQL数据库的读写支持,使得企业可以轻松地对接内部多种数据源。支持国内主流的国产数据库数据的读写操作,例如达梦、阿里OB、华为高斯DB、人大金仓、南大通用、Doris、TiDB等等。以及信创环境的安装,方便用户快速搭建数据处理平台。

2.还有着强大的系统兼容性,兼容HRM、SCM、CRM等市面上常见的SaaS应用。
3.优秀的可扩展性和灵活性
内置大量组件面对不断变化的数据处理需求。通过对组件的组合使用能灵活轻松地解决复杂的数据处理需求。同时ETL的官网中还有大量的新组件来满足多元的用户需求。
4.性能和可靠性
在100万至1000万不同数据量级的测试中,ETLCloud的性能比Kettle快了24.16%,比DataX快了27.8%。在不同数据量下,ETLCloud和Kettle展现出更稳定的性能表现。
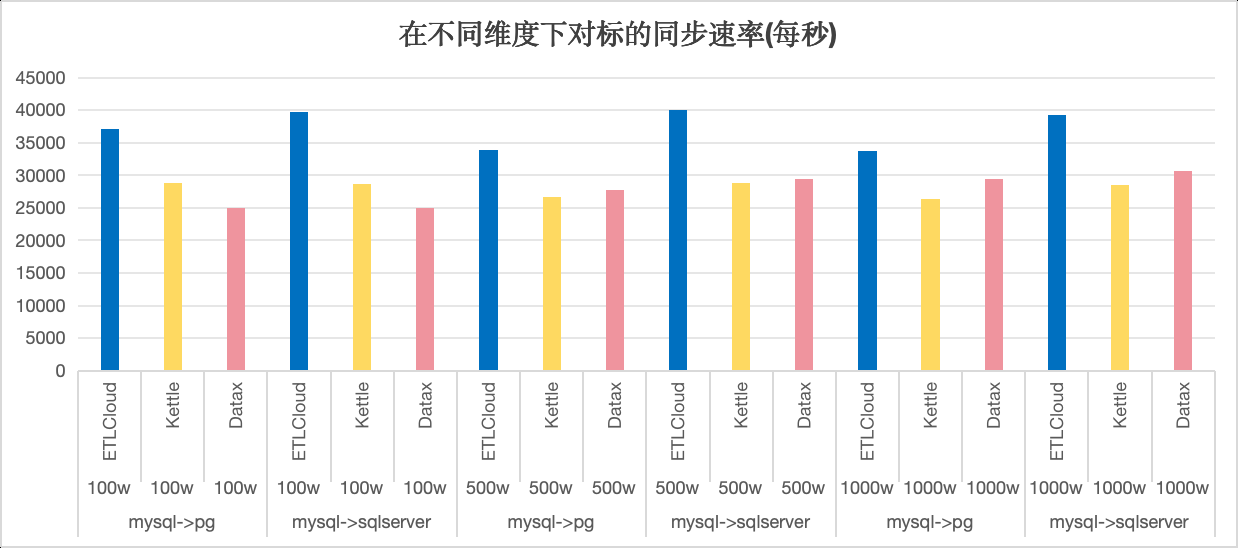
同时ETLCloud还拥有一键备份系统数据的功能,以便企业能轻松备份数据和保证数据的安全性
具体的测评实验过程,请点击下方视频观看: https://www.bilibili.com/video/BV1qx4y1t7xW/
5.用户体验、客户支持和社区资源
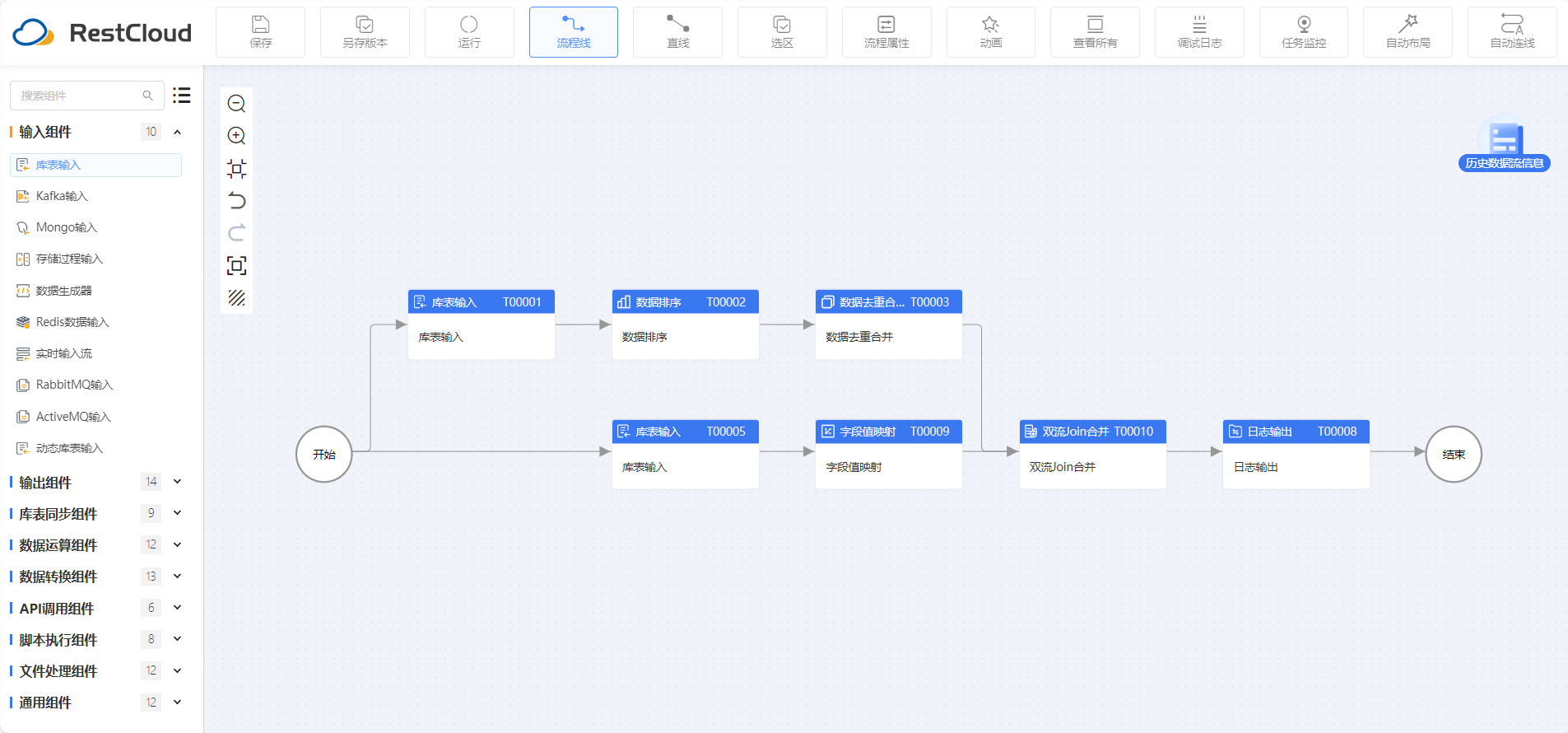
ETLCloud 提供图形化的界面和可视化的编排工具,支持通过拖拽和配置等简单操作完成集成流程的设计和开发,实现自动化集成,减少了手动工作的重复劳动。从而为用户友好的使用界面,这使得数据管道的设计和管理变得简单直观。即使是非技术用户也能轻松上手,通过可视化的方式构建复杂的数据流程。这些功能都极大优化了用户的使用体验。
有专门的技术交流群协作广大用户解决使用的问题,帮助用户快速上手使用。商业版用户还有专门的技术人员进行对接。同时还有着记载详细的帮助文档和活跃的社区论坛,大量的用户在论坛中发表自己的心得和疑问。
DataX
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,除了提供数据快速复制搬迁功能之外,还提供了丰富数据转换的功能,在大规模数据场景下还能提供稳定高效的数据同步功能。DataX主要通过脚本执行任务,这要求用户深入理解源代码才能有效调用,同时缺乏直观的用户界面用户需要手动编写脚本来进行配置。 因此datax学习曲线较为陡峭,对于非技术人员有较高的使用门槛。
总结
选择最适合企业的ETL解决方案是一个涉及多方面考量的过程。数据源和目标系统的兼容性、可扩展性和灵活性、性能和可靠性、用户体验、客户支持和社区资源,您可以大大提高选择成功率。