作者:来自 Elastic Joseph McElroy

了解混合检索、语义分块和代理搜索如何通过高效管理上下文相关性来提升 LLM 性能。
Agent Builder 现已作为技术预览版提供。你可以通过 Elastic Cloud 试用开始使用,并在此查看 Agent Builder 的文档。
在过去几年里,提示工程一直主导着 AI 领域的讨论。重点是寻找完美的词汇和表达方式,以从 LLM 中引出正确的回答。但随着我们构建出能够处理多步骤、复杂任务的更复杂的 AI 代理,焦点正在转移,话题也转向了如何管理上下文的挑战。
LLM 的上下文就像人类的短期记忆。试图将所有可能相关的信息都塞进去是有挑战性的。这会导致 "上下文腐烂 - context rot " ------ 一种模型的 "注意力预算" 被耗尽、从而失去焦点并干扰自身推理的现象。例如,最近在 NOLIMA: Long-Context Evaluation Beyond Literal Matching 中的 "大海捞针 - needle in a haystack"(NIAH) 基准测试指出,随着上下文长度的增加,性能 "显著下降",观察到在 32K token 时,"有 11 个模型低于其短上下文基线的 50%"。上下文窗口内的低效直接影响代理的可靠性。
解决方案不仅仅是更好的提示,而是一门新兴的学科:上下文工程。这是一种管理模型有限注意力的艺术。
超越 RAG:AI 代理向 "即时上下文 - just-in-time" 的转变
过去的标准方法是 RAG,它涉及在推理前进行一种检索,将所有可能相关的数据提前处理并输入到系统提示中供模型推理。
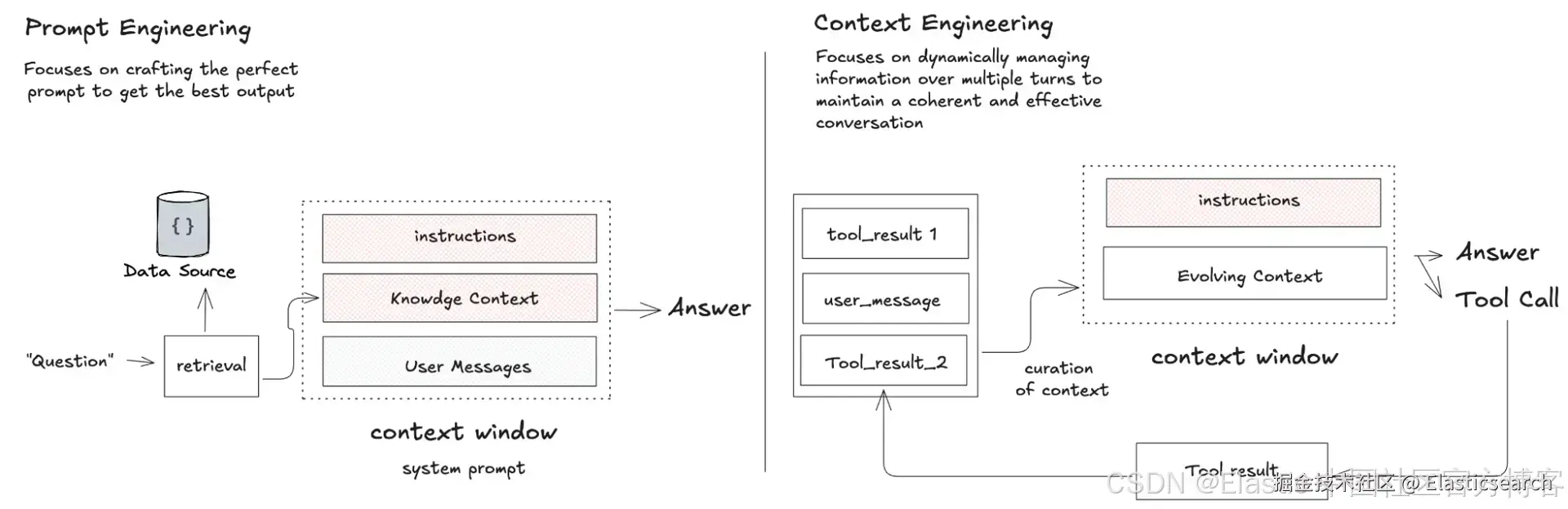
随着推理模型变得更智能、更便宜、并且更擅长处理长上下文,趋势正在转向使用工具进行 "即时检索 - just-in-time" 的代理。这使代理能够迭代地探查信息源,分解并重构查询,以在学习过程中调整搜索。工程重点从繁琐的数据预处理转向为代理配备合适的工具,并提高它自主发现和引导到最相关上下文的能力。
上下文工程不仅仅是我们给代理的指令,还关乎在任何时刻为模型策划和管理上下文窗口。当代理在循环中运行时,它会生成一个不断演变的信息宇宙 ------ 用户消息、工具输出以及它自身的内部思考。上下文工程是一门艺术,也是一门科学,决定了这个宇宙中哪些信息能进入代理有限的"工作记忆"。
这正是检索相关性成为高效上下文工程基石的地方。无论是在金融研究还是客户支持中,要让代理可靠地工作,它都需要访问大量特定领域的知识。检索的相关性是连接代理强大推理能力与赋予其意义的数据之间的重要桥梁。
在这篇文章中,我们将解析掌握上下文工程的关键检索策略。我们将展示,如何通过专注于相关性来构建更智能、更高效、更可靠的 AI 代理。
上下文检索中的相关性
为了在工程上实现高相关性 ------ 同时提升召回率和精确度 ------ 我们建议从混合搜索(hybrid search)策略开始检索。该方法将用于特定标识符的词汇搜索精确性与向量搜索(vector search)的语义召回相结合,最大化检索上下文的信噪比。
这种混合方法是防止上下文腐烂的第一道防线,确保只有最有价值的信息进入代理有限的工作记忆。
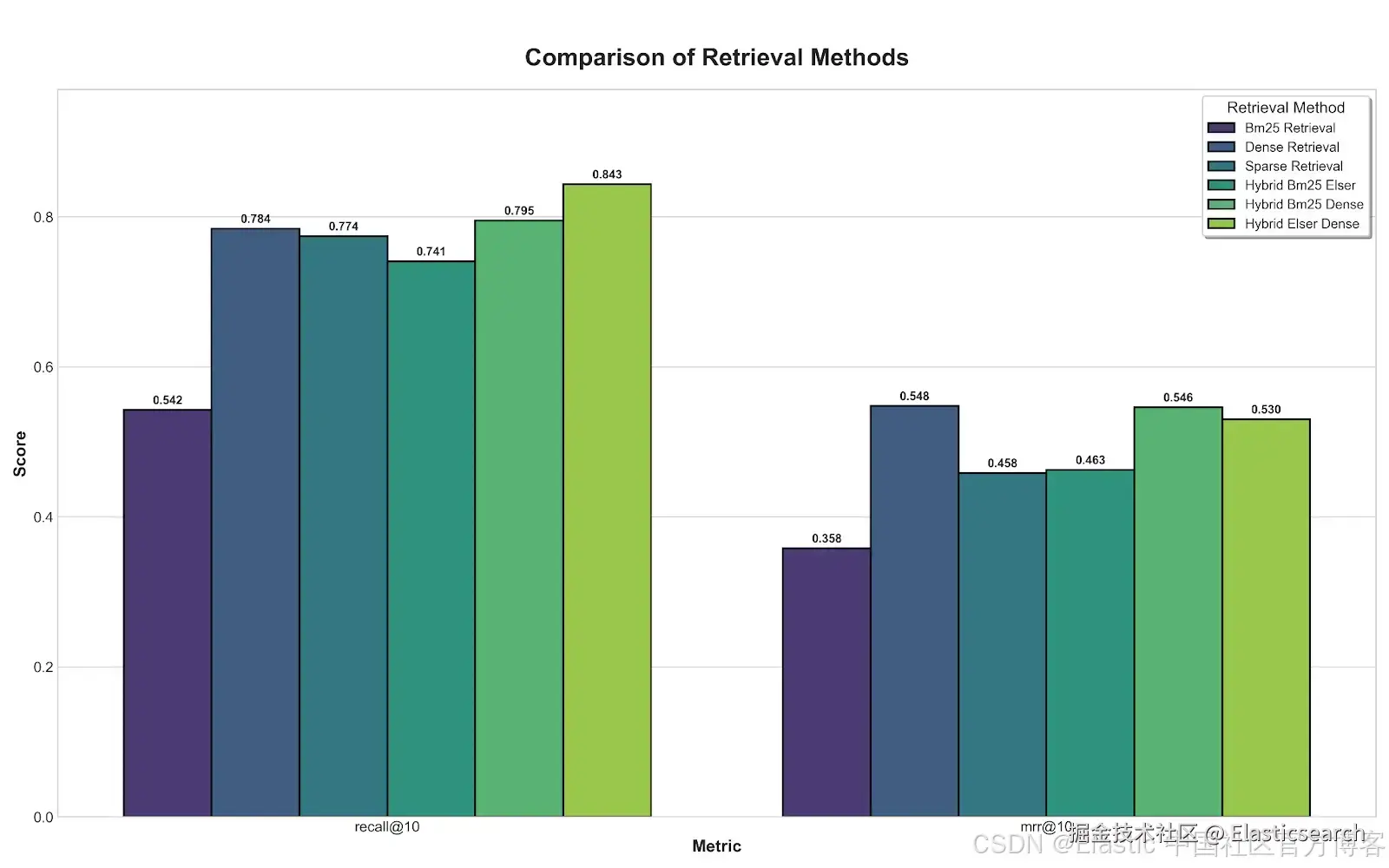
使用 recall@10 和 mrr@10 指标对不同策略的比较
在一次内部的检索策略基准测试中,我们发现混合方法通常在信息检索指标(如 Recall(完整性)和 MRR(排序))之间提供了最佳平衡。图表显示,结合稀疏的 ELSER 与稠密向量搜索的混合方法,在前 10 个结果中成功找到了 84.3% 的所有相关文档(Recall@10 为 0.843)。此外,MRR 为 0.53,表明最重要的单个文档平均位于前两个位置内。
语义分块与检索
然而,最佳结果还取决于上下文的结构方式。当 LLM 模型被提供连贯的上下文时,表现会更好。通过将内容分块,把相关概念分组在一起,然后不仅检索目标块,还检索其相邻部分,我们为代理提供了更丰富、更完整的上下文。这有助于缓解由碎片化或脱节上下文引起的性能下降和脆弱性,使推理更加可靠和高效。
这种策略可适用于不同类型的代理:
- 一个处理法律文档的知识代理可以按段落或章节进行分块。当检索到特定条款时,提供其前后段落与章节可确保代理理解完整的法律论证。这些块可以通过轻量级标识符链接回其源文档和页码。
- 一个编码代理可以通过语义方式对代码库进行分块 ------ 按函数、类或逻辑块。当某个函数被识别为相关时,检索其所属的整个类及其 import 语句和 docstring,可为代理提供一个完整且可执行的逻辑单元,供其他工具访问。
css
`
1. PUT semantic-index
2. {
3. "mappings": {
4. "properties": {
5. "content": {
6. // we use ELSER, our sparse embedding model by default
7. // we support other embedding models from OpenAI, E5, Cohere
8. "type": "semantic_text"
9. }
10. }
11. }
12. }
14. POST semantic-index/_doc/1
15. {
16. "content": "<Long Document Text>"
17. }
19. GET semantic-index/_search
20. {
21. "query": {
22. "match": {
23. "content": {
24. "query": "<my_query>"
25. }
26. }
27. },
28. "highlight": {
29. "fields": {
30. "content": {}
31. }
32. }
33. }
`AI写代码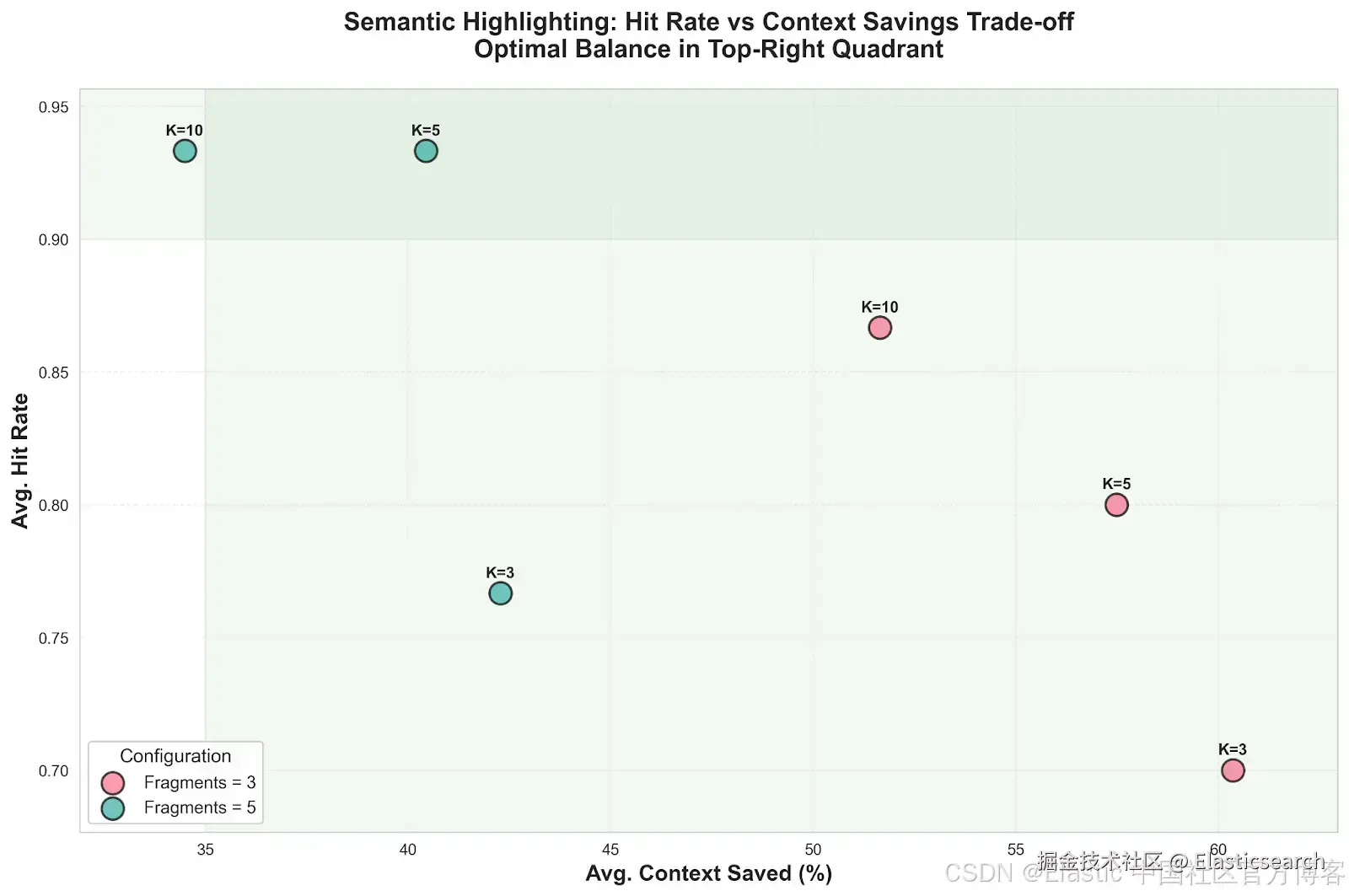
在另一项针对长上下文 RAG 的内部基准测试中,我们评估了语义高亮在从文档中检索最相关块方面的有效性,从而减少将整个文档传递给 agent 的需求。如图表所示,我们尝试了不同的文档数量与高亮块数量组合,衡量它们对检索准确性(命中率)和上下文效率的影响。命中率是一个二元指标,用于表示 agent 是否获得完成任务所需的所有信息。
对于我们的数据集,最佳方案是从前五个文档中检索五个语义片段(K=5)。该设置使 agent 在 93.3% 的情况下能够访问所需的全部信息,同时将上下文大小减少超过 40%,显著降低了 agent 的处理负荷。
Agentic search
对于需要广泛探索的更复杂问题,简单的相关性搜索是不够的。回答这些查询需要更深层次的理解,而这种理解只能通过发现和筛选的过程实现。传统的检索工具通常受限于固定的查询模板,缺乏进行动态源选择和探索的智能。相反,agent 需要对其找到的信息进行推理,过滤噪声,并在洞察出现时以迭代循环的方式探索新的路径。
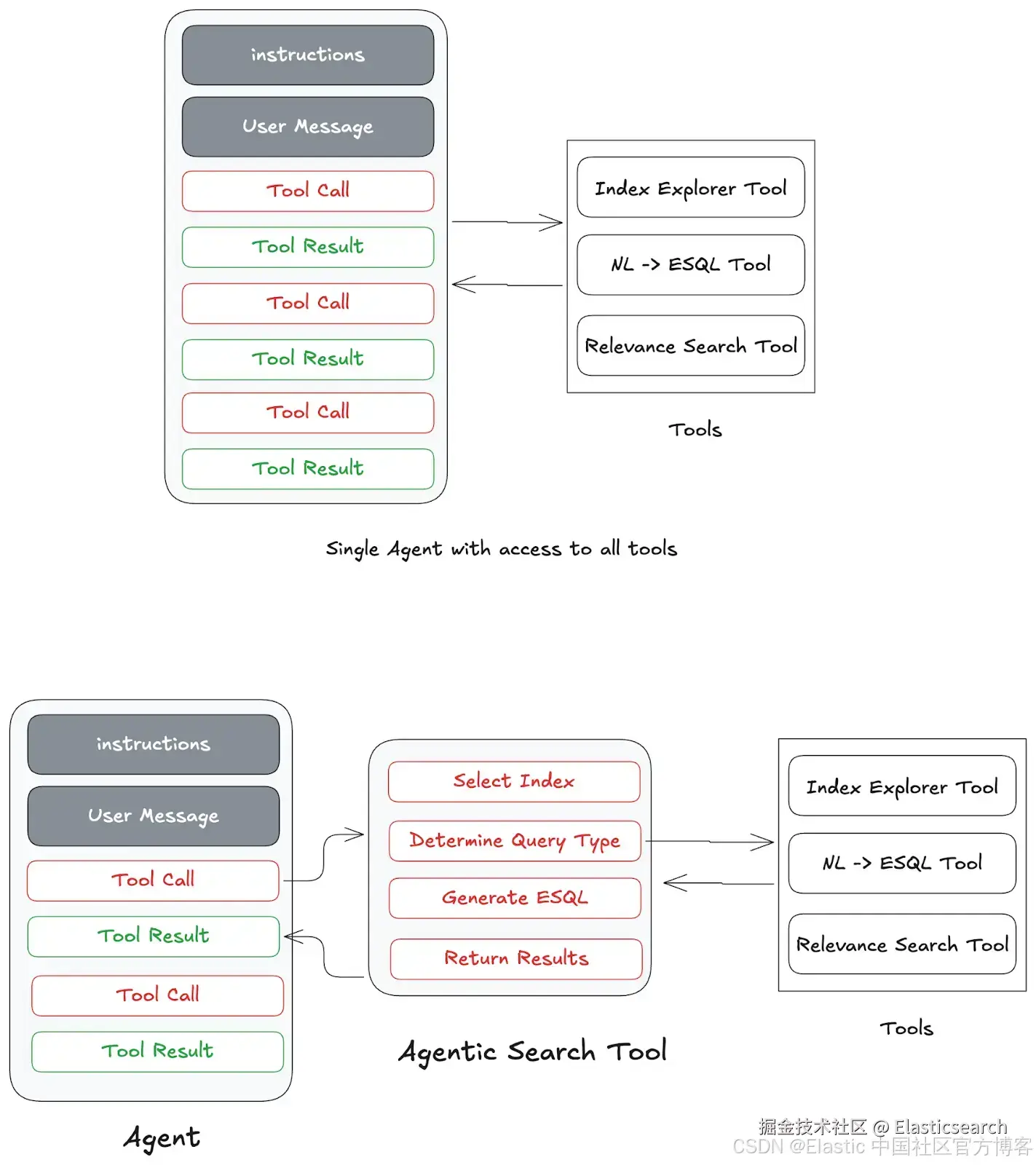
为了实现这一点,我们可以利用在主 agent 上下文窗口之外运行的基于 agent 的检索工具。这可以被概念化为一种专门的 "sub-agent" 架构,如一些多 agent 系统中所描述的。这个子 agent 负责密集的探索工作。其核心功能是将主 agent 的高级自然语言请求重写为针对所选数据源的精确、结构化查询。例如,它可以将用户的问题转换为特定的 ESQL 查询,以从 Elasticsearch 索引或数据流中检索相关内容。整个发现、推理和筛选的来回过程都发生在这个子 agent 的独立上下文中。然后它返回结果或聚合,保持主 agent 的 "工作记忆" 整洁,使其能够专注于高级计划。
这种策略可适用于不同类型的 agent:
- 一个负责复杂搜索的编码 agent 可以使用搜索子 agent 来探索大型代码库。这个 sub-agent 会花费计算周期遍历文件夹、搜索代码块嵌入,并追踪依赖关系以找到特定文件或函数。它不会返回数千行原始代码,而是提供相关文件路径和代码片段的简明摘要。
- 一个研究某个主题的知识 agent 可以使用 sub-agent 来筛选庞大的文档库。它会自主探索数据,忽略无用文档,并综合多个来源的关键发现。主 agent 然后接收经过策划的重点摘要,而不是每个检索到文档的完整文本。
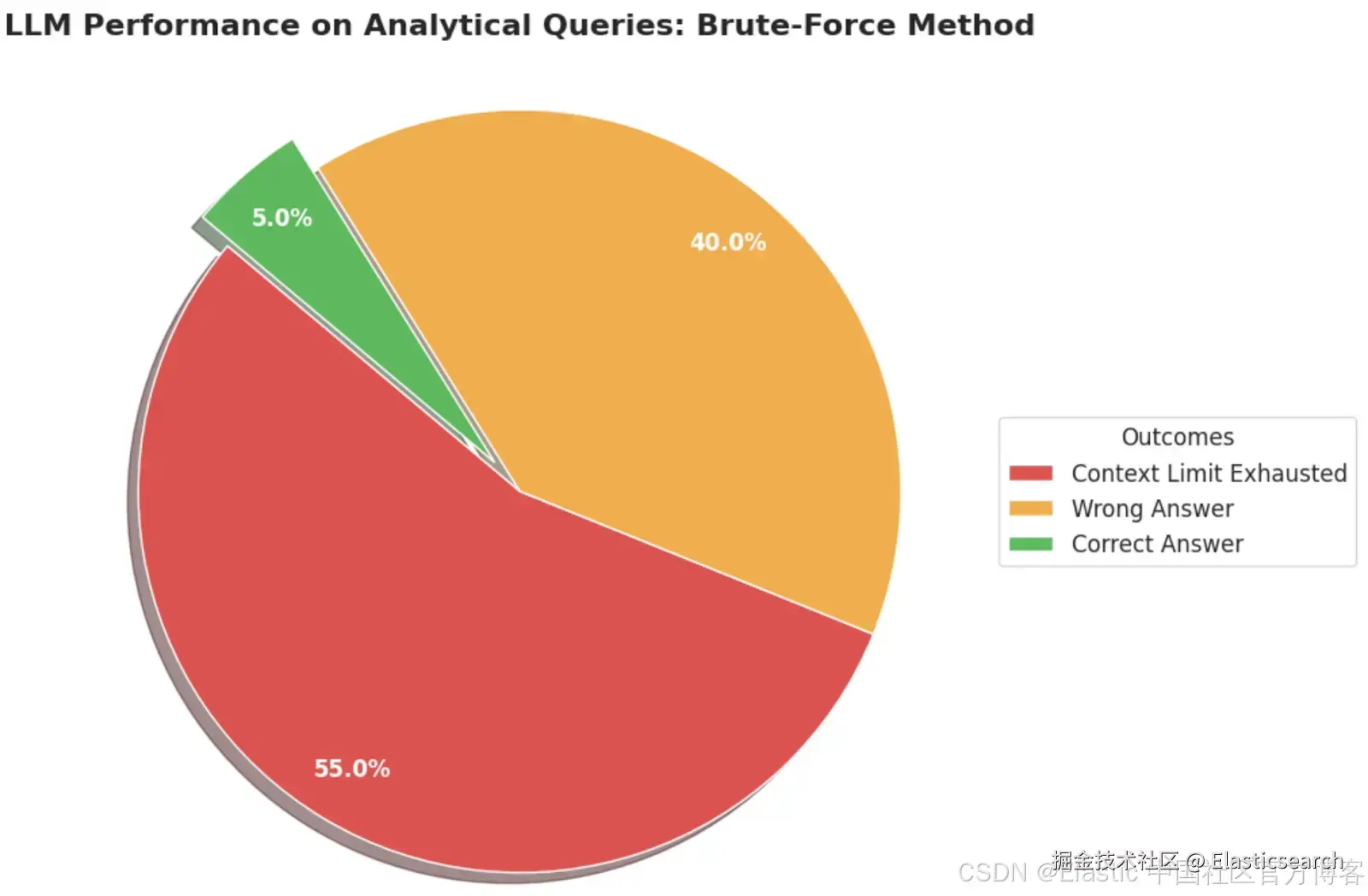
在一次内部实验中,我们比较了两种方法来回答分析性问题,例如:"今天是 2025 年 7 月 8 日。在过去 365 天里创建了多少支持票,并且其中有多少仍然未关闭"。要回答这个问题,LLM 必须根据日期列筛选包含 360 条记录和 12 个字段(包括文本、日期和整数类型)的一个小索引,然后按状态统计票数以提供必要信息。
-
暴力方法:直接将整个 CSV 输入到最先进 LLM 的上下文窗口中。
-
Agentic 方法:这种方法为 agent 提供了一个能够将自然语言转换为精确 ESQL 查询的工具,然后在包含 CSV 的索引上运行该查询。图表显示,当 LLM 将整个索引作为上下文时,大多数情况下会发生灾难性失败。而配备 ESQL 工具的 agent 则实现了 100% 的成功率。
领域特定工具与工作流
虽然 agentic search 在处理复杂、开放性问题时具有强大的探索能力,但它并不总是最高效或最可靠的方法。对于许多业务关键操作,尤其是在受监管的领域如金融中,任务遵循可预测、可重复的顺序。在这些场景中,每次都让通用 agent 从零推理和探索不仅在 token 消耗和延迟上浪费,还会引入不必要的变异。
这就是使用领域特定工具与工作流提供更确定性解决方案的地方。与单一 sub-agent 不同,工作流工具是一系列预定义步骤按顺序执行。agent 的角色从规划者转变为这些高级工作流的高效执行者。工作流由领域专家提前设计,确保每一步都从前一步获得所需的精确上下文。
客户支持工具示例:获取类似已解决的客户工单
该查询通过首先筛选高质量数据(如 "已解决" 工单),然后使用相关性搜索定位最佳解决方案,同时策划返回给模型用于上下文的精确字段,从而优化工作流。
bash
`
1. POST /api/agent_builder/tools
2. {
3. "id": "find_similar_customer_resolved_tickets",
4. "type": "esql",
5. "description": "Searches for the top 5 most relevant 'resolved' support tickets based on a new issue description to find previous solutions.",
6. "configuration": {
7. "query": "FROM support_tickets | WHERE status = 'resolved' AND customer_email = ?email | MATCH(issue_title, issue_description, ?problem_description) | KEEP ticket_id, issue_title, resolution | LIMIT 5",
8. "params": {
9. "email": {
10. "type": "keyword",
11. "description": "The customer's email address used to file the support tickets."
12. },
13. "problem_description": {
14. "type": "text",
15. "description": "A natural language description of the customer's current problem, e.g., 'laptop wifi not connecting after update'."
16. }
17. }
18. }
19. }
`AI写代码金融工作流工具示例:KYC 检查
"了解你的客户"(KYC)流程是一项不可妥协的清单。
- 验证身份:该工具将客户信息与银行内部记录进行核对。
- 外部筛查:然后查询外部 API,检查制裁名单和负面媒体报道。
- 生成报告:最后,将所有发现与 LLM 结合,编制成标准化的风险评估报告以供审计。
这种确定性的流程还确保每位客户都按照完全相同的标准进行审查,这对于监管机构至关重要。
通过执行确定性的执行路径,这种基于工作流的方法显著提高了操作可靠性,减轻了不可预测的 agentic 行为。因此,通过减少 token 消耗、降低延迟,并消除 agentic 行为中常见的不必要推理循环,实现了效率提升。
上下文压缩、长期记忆与语义检索
一种应对上下文限制的策略是通过上下文压缩或压缩管理。这涉及将现有对话历史(包括多次工具执行及其结果)浓缩为简明摘要。然后,这些压缩信息可以存储在外部,创建一个持久记忆,agent 可以在同一对话或不同会话中后续访问。
然而,这种压缩需要精细的平衡。核心挑战在于 agent 必须基于所有先前状态决定下一步操作,而无法预知哪些看似微小的观察将来可能变得关键。因此,任何不可逆的压缩都有丢失微妙但关键细节的风险。为应对这一权衡,Anthropic 提出建议:"首先最大化召回率,确保你的压缩提示捕获 trace 中的每一条相关信息,然后通过消除多余内容迭代以提高精确度 。" ------摘自《Effective context engineering for agents》。
先优先召回再优化精确度的原则,使得语义搜索(semantic search)等技术变得至关重要。通过使 agent 能够高效查询外部记忆,语义搜索帮助检索与当前任务最相关的上下文,确保其有限上下文窗口得到高效利用。
动态工具发现
随着可供 LLM 使用的外部工具和 API 数量爆炸性增长,有效的工具发现与选择成为重大挑战。当 LLM 面对庞大的函数库时,会出现两个主要问题:提示膨胀和决策负担。提示膨胀是因为在模型有限的上下文窗口内描述每个可用工具是不切实际的,会消耗大量 token。这不仅加大了模型的负荷,还引发决策负担,即 LLM 面对众多选择时容易混乱,尤其当许多工具具有相似或重叠功能时。这种复杂性增加了错误的可能性,使模型选择次优工具,甚至产生不存在的工具,从而降低性能。
为应对这一扩展问题,许多人探索使用语义搜索和检索来动态管理工具集。与一次性向模型展示所有工具不同,这种方法先利用检索系统理解用户查询的含义,再在庞大的外部工具索引中进行语义搜索,只检索与任务最相关的选项。通过预先筛选选择,并向 LLM 提供小而高度相关的子集,这种方法显著减小了提示大小,并简化了模型的决策过程。这种以相关性为核心的策略确保 LLM 不必在 "大海捞针",而是获得经过策划的工具包,从而提高选择正确工具的准确性。
这一方向已有早期研究,如《RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation》以及我们使用语义搜索选择与 agentic search 配合的正确索引的研究。
结论
向上下文工程的演进标志着我们今天使用 LLM 的一个关键成熟阶段。这意味着从单纯追求完美提示的艺术,转向构建和管理 agent 环境的艺术。挑战不再仅是我们问什么,而是如何帮助 agent 在有限上下文中高效且可靠地发现自身答案。
我们探讨的策略 ------ 从基础的混合检索和语义分块,到探索性的 agentic search 与可靠确定性工作流之间的复杂权衡 ------ 都是这门新学科的组成部分。每种技术都旨在更好地管理 agent 上下文。通过设计合适的检索工具、记忆系统和动态函数调用能力,我们可以提升 agent 在其环境中的有效性。上下文管理能力将决定 AI agent 是继续作为实验工具,还是发展为能够处理复杂生产级任务的可靠系统。
在本系列的下一部分,我们将进一步探讨 Elastic AI agent,以及我们在整个 agent 生命周期中管理上下文(从短期记忆到长期知识)的具体策略。
致谢
- Abhimanyu Anand,感谢整理基准以支持这些策略。
- Anthropic 工程团队,感谢其在上下文压缩策略及"先召回再精确"原则方面的基础性见解。
- Chroma 研究团队,感谢其在识别和推广 "上下文腐烂" 概念方面的工作。
- 《NOLIMA: Long-Context Evaluation Beyond Literal Matching》作者,感谢提供关于长上下文性能下降的宝贵基准。
- 《RAG-MCP: Mitigating Prompt Bloat in LLM Tool Selection via Retrieval-Augmented Generation》作者,感谢其在动态工具检索和提示膨胀方面的早期研究。