CMP7(类Cloudera CMP 7 404版华为Kunpeng)用开源软件Label Studio做数据标注
Cloudera CMP(Cloudera Data Platform)本身并不直接提供数据标注( Data Labeling/Annotation )功能 ,因为 CMP 的核心定位是 企业级大数据平台,主要用于数据湖管理、批流处理、分析与机器学习(通过 CML - Cloudera Machine Learning),而非面向人工标注任务(如图像框选、文本分类、NER 等)。
不过,你可以将 CMP 与开源数据标注工具集成 ,构建端到端的 AI/ML 数据处理 pipeline。以下是 与 CMP 兼容性好、可私有化部署、支持企业级协作的开源数据标注工具推荐:
✅ 推荐 1 :Label Studio (最通用、生态最丰富)
- 开源地址:https://github.com/heartexlabs/label-studio
- 许可证:Apache 2.0(社区版免费)
- 支持数据类型:文本、图像、音频、视频、时序、表格等(多模态)
- 与 CMP 集成方式 :
- 部署在 CMP 边缘节点或 Kubernetes(CML 支持)
- 标注数据存储到 HDFS / S3A / ADLS(通过 Label Studio 的 Storage 后端)
- 导出为 JSON、CSV,供 Spark/Flink 处理
- 可通过 CML Jupyter Notebook 调用其 API 自动创建标注任务
- 优势 :
- 支持预标注(Pre-annotation) + 主动学习(Active Learning)
- 提供角色权限、审核流程、多人协作
- 有企业版(Label Studio Enterprise),但社区版已足够强大
📌 适用场景:NLP(文本分类、NER)、CV(目标检测)、语音转写等。
✅ 推荐 2 :Doccano (专注 NLP 文本标注)
- 开源地址:https://github.com/doccano/doccano
- 许可证:MIT
- 支持任务:文本分类、序列标注(NER)、序列到序列(翻译/摘要)
- 与 CMP 集成方式 :
- Docker 部署在 CMP 节点
- 数据导入/导出通过 CSV/JSON,可对接 Hive 表或 S3
- 适合与 CML 中的 NLP 模型训练 pipeline 衔接
- 优势 :
- 轻量、启动快、界面简洁
- 支持多语言、多人协作、项目管理
- 局限:仅支持文本,不支持图像/音频
📌 适用场景:构建 NER 数据集、情感分析、意图识别等。
✅ 推荐 3 :LabelU (国产开源,多模态强)
- 开源地址:https://github.com/opendatalab/labelU
- 许可证:Apache 2.0
- 支持数据类型:图像、视频、音频、文本(多模态)
- 特色功能 :
- 支持 大模型预标注 + 人工精修
- 一键导出 COCO、JSON、MASK 等格式
- 可本地部署,数据不出域
- 与 CMP 集成 :
- 部署在 CMP 私有云节点
- 标注结果存入 HDFS/S3,供 Spark 或 CML 使用
- 支持快捷键、自定义标签体系,适合大规模标注
📌 适用场景:计算机视觉(检测/分割)、音视频时间戳标注、LLM 对话评估。
✅ 推荐 4 :CVAT (Computer Vision Annotation Tool ,专注图像/ 视频)
- 开源地址:https://github.com/cvat-ai/cvat
- 许可证:MIT
- 支持任务:2D/3D 框、多边形、关键点、跟踪、视频分割
- 与 CMP 集成 :
- 可部署在 CMP 的 Kubernetes 集群(CML 支持 K8s)
- 导出为 COCO、YOLO、Pascal VOC,直接用于模型训练
- 支持 LDAP/SSO,适合企业安全集成
- 优势:工业级图像标注,性能强,支持自动标注(集成 SAM、YOLO 等)
📌 适用场景:自动驾驶、工业质检、医学影像等 CV 任务。
🔗 如何与 CMP 协同工作?(典型架构)
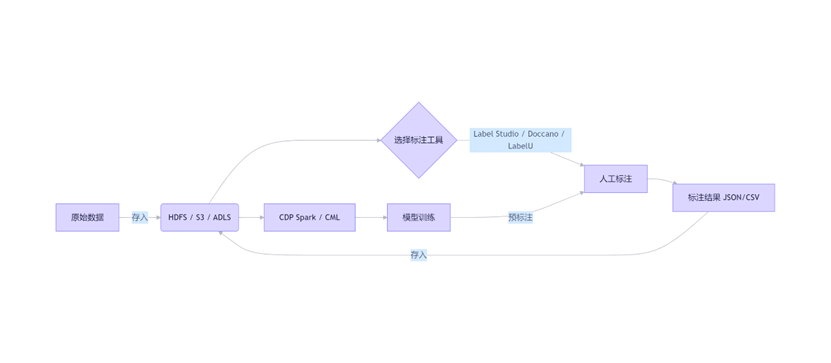
模型训练
- 数据存储 :所有原始数据和标注结果统一存放在 CMP 管理的 数据湖(如 HDFS、S3A)
- 标注平台:独立部署开源工具,通过 Web UI 或 API 访问数据湖
- 模型训练 :在 Cloudera Machine Learning (CML) 中使用 PySpark/TensorFlow/PyTorch 训练
- 预标注闭环:用训练好的模型生成预标注,回流到标注工具供人工修正
❌ 不推荐的组合
- 直接在 CMP 内" 安装" 标注工具作为服务 :CMP 不是应用托管平台,应将标注工具视为 外部协作系统。
- 使用仅支持公有云的标注 SaaS(如 Scale AI、Amazon SageMaker Ground Truth):不符合私有化、数据不出域要求。
✅ 总结:选型建议
| 需求 | 推荐工具 |
|---|---|
| 多模态(图/ 文/ 音/ 视频) + 大模型预标注 | LabelU (国产,易部署) |
| 通用性最强 + 企业协作 + API 丰富 | Label Studio |
| 纯 NLP 文本任务(NER/ 分类) | Doccano |
| 专业图像/ 视频标注(工业级) | CVAT |
所有上述工具均可 私有化部署 ,与 CMP Base / CMP Public Cloud 通过 共享存储(HDFS/S3 ) 和 CML 无缝集成。
在 Cloudera Machine Learning (CML) 中启动 Label Studio 容器是完全可行的,因为 CML 原生支持 Docker 容器化工作负载 (通过 Sessions、Jobs 或 Model API)。下面提供 完整、可运行的步骤 ,适用于 CDP Private Cloud Base 7.1.7+ 或 CDP Public Cloud 环境。
✅ 目标
在 CML 中:
- 启动一个持久化、可访问的 Label Studio 服务
- 数据存储在 CDP 数据湖(如 HDFS/S3)或 CML 项目存储中
- 支持多人协作(可选)
一、前提条件
| 项目 | 要求 |
|---|---|
| CML 环境 | CDP Private Cloud Base 7.1.7+ 或 CDP Public Cloud |
| 权限 | CML 项目成员(至少 Developer 角色) |
| 存储 | CML 项目已挂载 HDFS/S3(通过 External Volume)或使用默认项目存储 |
| 网络 | 允许外部访问(CML 自动分配 *.ds.<domain> 域名) |
二、方法:使用 CML Session 启动 Label Studio (推荐用于开发/ 测试)
✅ 优点:快速启动、自动 HTTPS、内置身份认证
⚠️ 注意:Session 默认 不持久化,需配置持久化存储
步骤 1 :创建 CML 项目
- 在 CML 控制台 → New Project → 选择 "Python 3" 或 "Custom Engine"
步骤 2 :编写启动脚本 start_label_studio.sh
在项目根目录创建:
Bash:
#!/bin/bash
start_label_studio.sh
安装 Label Studio(仅首次需要)
pip install label-studio==1.15.0
设置数据目录(指向 CML 持久化存储)
export LABEL_STUDIO_LOCAL_FILES_SERVING_ENABLED=true
export LABEL_STUDIO_LOCAL_FILES_DOCUMENT_ROOT=/home/cdsw/data
启动服务(CML 会自动代理 9999 端口)
label-studio start \
--host 0.0.0.0 \
--port 9999 \
--no-browser \
--database-url sqlite:////home/cdsw/data/label_studio.db
🔐 安全提示:生产环境建议使用 PostgreSQL 而非 SQLite。
步骤 3 :配置持久化存储(关键!)
方案 A :使用 CML 默认项目存储(简单)
- 所有写入 /home/cdsw/ 的内容在 Session 重启后保留(CML 自动持久化)
方案 B :挂载 HDFS/S3 (推荐用于生产)
- 在 CML 项目设置中 → Engines → External Volumes
- 添加 HDFS 路径(如 hdfs://<namenode>:8020/user/cdsw/label_data)
- 挂载到容器内路径:/mnt/label_data
- 修改脚本中的 --database-url 和 DOCUMENT_ROOT 为 /mnt/label_data
步骤 4 :启动 Session
- 在 CML 项目中 → New Session
- Engine: Python 3.x
- Script: ./start_label_studio.sh
- Port: 9999
- 点击 Launch Session
步骤 5 :访问 Label Studio
- Session 启动后,点击 "Open in Browser"(CML 会生成类似 https://<session-id>.ds.example.com 的 URL)
- 首次访问需设置管理员账号
三、方法:使用 CML Job (推荐用于长期运行)
✅ 优点:可设置为常驻服务、支持自动重启、资源隔离
创建 job.yaml
Yaml:
job.yaml
name: label-studio-service
dockerImage: python:3.9-slim
script: |
#!/bin/bash
pip install label-studio==1.15.0
label-studio start \
--host 0.0.0.0 \
--port 9999 \
--no-browser \
--database-url sqlite:////home/cdsw/data/label_studio.db
port: 9999
cpu: 2
memory: 4
environment:
LABEL_STUDIO_LOCAL_FILES_SERVING_ENABLED: "true"
LABEL_STUDIO_LOCAL_FILES_DOCUMENT_ROOT: "/home/cdsw/data"
启动 Job
Bash:
cdsw job run job.yaml
💡 CML Job 同样支持 External Volumes,配置方式同上。
四、高级配置(生产建议)
1. 使用 PostgreSQL 替代 SQLite
Bash:
在 CML 外部部署 PostgreSQL(如 RDS 或本地)
label-studio start \
--database-url postgresql://user:pass@pg-host:5432/label_studio
2. 启用 LDAP/SSO (企业集成)
Label Studio 支持 OAuth2、LDAP,可通过环境变量配置:
Bash:
export LABEL_STUDIO_OAUTH2_LOGIN=true
export LABEL_STUDIO_OIDC_CLIENT_ID=...
3. 自动加载数据集
- 将原始数据(图片/文本)放在 /mnt/label_data/raw/
- 在 Label Studio 项目中配置 "Local Files" 数据源,路径为 /raw
4. 导出标注结果到 Hive
- 标注完成后,导出为 JSON/CSV 到 /mnt/label_data/export/
- 在 CML Notebook 中用 PySpark 读取并写入 Hive:
Python:
df = spark.read.json("/mnt/label_data/export/project-123.json")
df.write.mode("overwrite").saveAsTable("labeled_data.ner_results")
五、注意事项
| 问题 | 解决方案 |
|---|---|
| Session 停止后数据丢失 | 务必使用 /home/cdsw/ 或 External Volume |
| 无法上传大文件 | 在 CML 项目设置中调高 max_upload_size |
| 多人协作冲突 | 使用 PostgreSQL + 启用 Label Studio 的 Collaborative Mode |
| 性能慢 | 为 Session/Job 分配更多 CPU/Memory(Label Studio 推荐 2C4G 起) |
六、验证是否成功
- 访问 CML 生成的 URL
- 创建新项目 → 选择 "Upload Files"
- 上传测试文件(如 sample.txt)
- 检查 /home/cdsw/data/ 是否生成 media/ 目录和 label_studio.db
总结
✅ 在 CML 中运行 Label Studio 完全可行,推荐:
- 开发/ 测试 :用 Session + 脚本
- 生产/ 长期服务 :用 Job + PostgreSQL + External Volume (HDFS/S3 )
这样,你的标注平台就与 CDP 数据湖、CML 模型训练无缝集成,形成闭环。