
问题起源
一个普通的周一上午,我像往常一样打开了 ServerCat(Mac 上的 SSH 监控工具)来查看家庭实验室服务器的状态。服务器的 CPU 使用率图表突然从平时的 20%左右飙升到了 90%以上,系统负载达到了 16。而我关闭 ServerCat 后,服务器的负载很快就恢复正常;重新打开,负载再次飙升。这种"一开就炸,一关就好"的现象,让我意识到这绝不是偶然的服务器问题,而是一个值得深入研究的系统性问题。
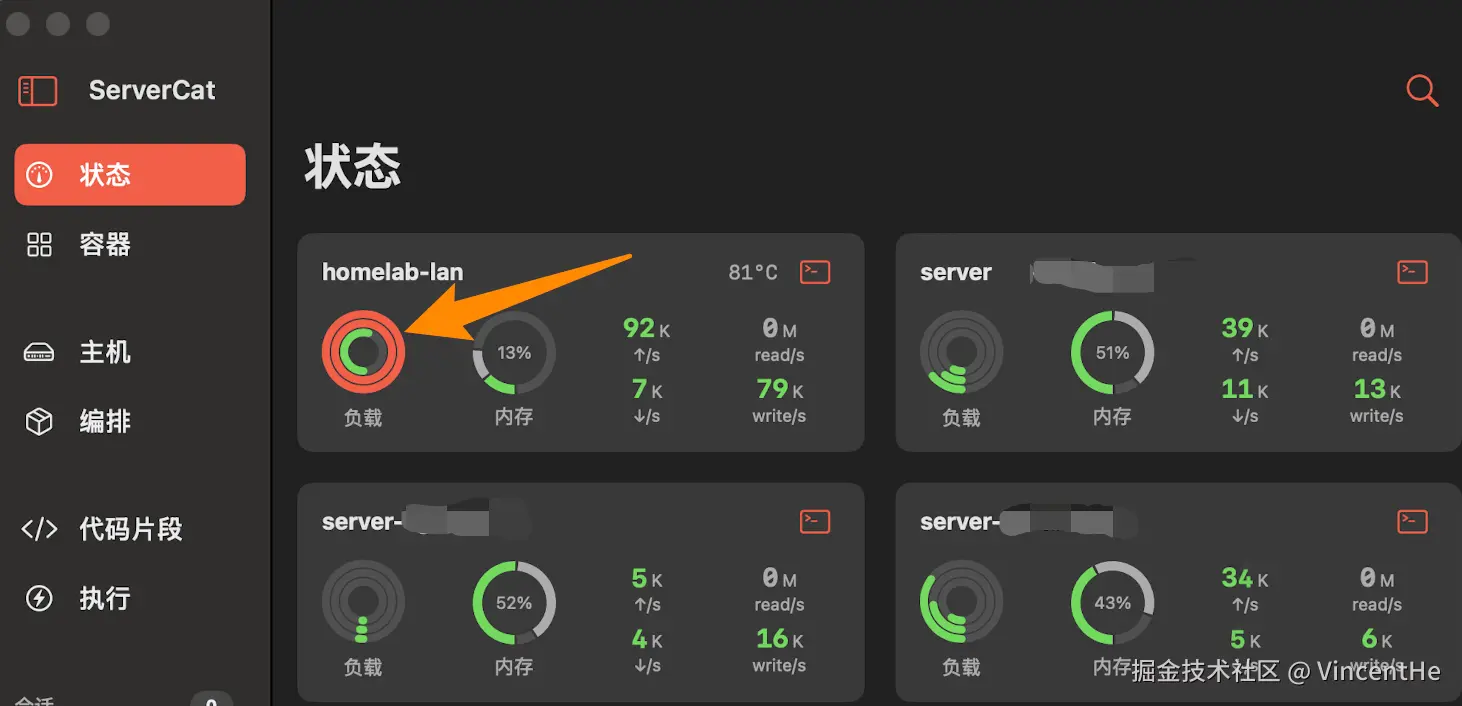 图:ServerCat 监控界面显示服务器 CPU 使用率异常飙升的截图
图:ServerCat 监控界面显示服务器 CPU 使用率异常飙升的截图
初步排查:表象还是根因?
我的第一反应是:是不是服务器上有什么进程在疯狂运行?通过 SSH 连接到服务器,执行了基本的系统监控命令:
bash
# 查看系统负载
$ uptime
08:38:59 up 22:48, 3 users, load average: 1.02, 0.71, 0.43
# 查看进程排行
$ top -bn1 | head -15
Tasks: 195 total, 1 running, 193 sleeping, 1 stopped, 0 zombie
%Cpu(s): 12.1 us, 19.7 sy, 0.0 ni, 68.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
731018 root 20 0 13372 3928 3308 R 6.2 0.0 0:00.01 top
1 root 20 0 171544 16080 8856 S 0.0 0.1 5:16.01 systemd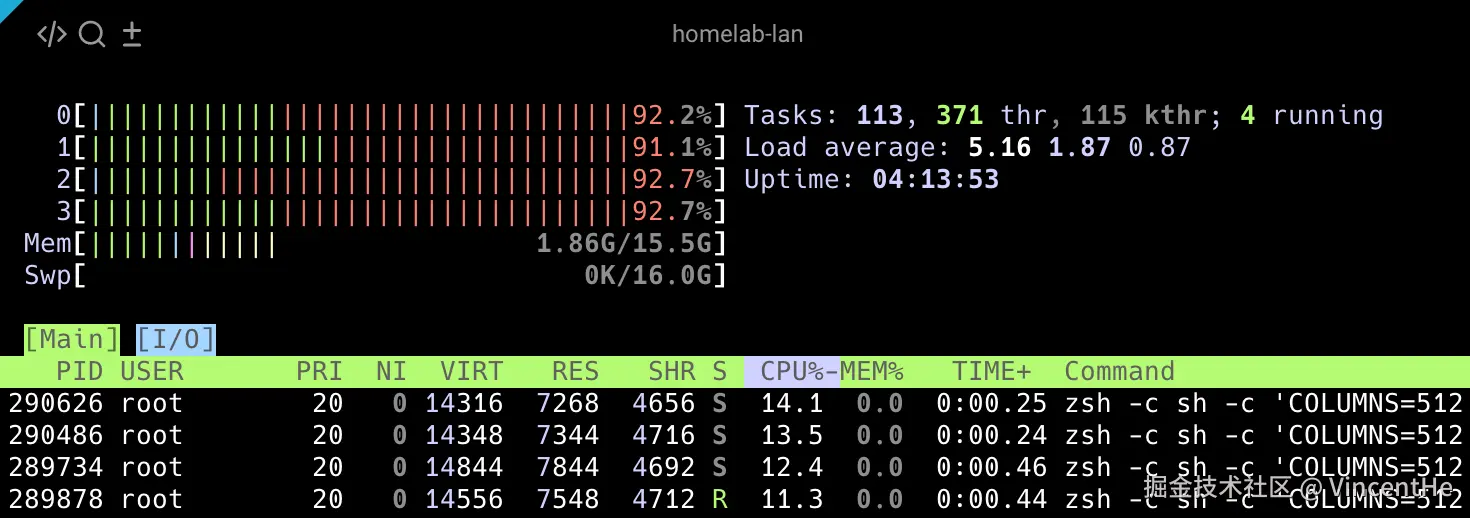 图:htop 显示服务器 CPU 使用率异常飙升的截图
图:htop 显示服务器 CPU 使用率异常飙升的截图
奇怪的是,在 ServerCat 关闭时,这些指标都显示系统很健康。但当我重新打开 ServerCat,再次执行同样的命令时发现:
bash
$ ps aux --sort=-%cpu | head -15
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
734768 46.0 0.0 14004 7068 ? Ss 08:38 0:00 zsh -c ps aux --sort=-%cpu | head -15
735173 25.0 0.0 13788 6784 pts/7 Rs+ 08:38 0:00 zsh -c cat /proc/meminfo
691642 2.7 0.0 11820 4784 pts/0 S+ 08:36 0:03 htop
688672 2.1 1.0 338300 172096 ? Sl 08:33 0:07 /usr/local/bin/python3 -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_fd=10, pipe_handle=12) --multiprocessing-fork大量的zsh -c进程在疯狂运行,CPU 使用率分别达到了 46%、25%...这绝对不正常...
深入分析:Shell 启动模式的关键差异
这时候我开始思考:为什么 ServerCat 会启动这么多 zsh 进程?这些进程在执行什么命令?
通过进一步分析,我发现了关键线索:
bash
# 检查SSH连接状态
$ who -u
root pts/0 2025-11-06 08:36 00:05 689771 (192.168.1.177)
root pts/4 2025-11-06 08:36 00:05 690093 (192.168.1.177)
root pts/7 2025-11-06 08:42 . 810596 (192.168.1.177)
# 检查SSH进程
$ ps aux | grep -E '(notty|pts/)' | grep -v grep
root 779834 2366 0 08:41 ? 00:00:00 sshd: root@notty
root 789804 2366 0 08:41 ? 00:00:00 sshd: root@notty
root 805261 2366 0 08:42 ? 00:00:00 sshd: root@notty注意到那些notty的 SSH 连接,这些就是 ServerCat 建立的监控连接。
登录 Shell vs 非登录 Shell:关键差异
这里就涉及到了 Linux/Unix 系统中一个重要但容易被忽视的概念:Shell 的启动模式。
什么是登录 Shell?
登录 Shell 是用户完整登录系统时启动的第一个 Shell 进程,典型场景包括:
- 通过 SSH 登录:
ssh user@server - 本地终端登录:在物理服务器输入用户名密码
- 使用
su - username切换用户
登录 Shell 会加载完整的用户环境配置:
bash
# Bash登录Shell加载顺序:
1. /etc/profile # 系统级配置
2. ~/.bash_profile # 用户登录配置
3. ~/.bashrc # 通常在profile中被调用
# Zsh登录Shell加载顺序:
1. /etc/zsh/zprofile # 系统登录配置
2. ~/.zprofile # 用户登录配置
3. ~/.zshrc # Zsh配置文件什么是非登录 Shell?
非登录 Shell 是在已登录状态下启动的 Shell 子进程,典型场景包括:
- 打开新的终端窗口
- 执行脚本:
bash script.sh - ServerCat 监控:
ssh user@server "command"
非登录 Shell 的配置加载方式:
bash
# Bash非登录Shell:
1. ~/.bashrc # 只加载用户配置
# Zsh非登录Shell:
1. ~/.zshenv # 环境变量配置 ← 关键!
2. ~/.zshrc # Zsh配置文件SSH 参数组合对比表
不同的 SSH 参数组合会产生不同的 Shell 环境和配置加载效果:
| 命令 | TTY | Shell 模式 | 配置加载 | 适用场景 |
|---|---|---|---|---|
ssh user@server "cmd" |
❌ 无 | 非登录 Shell | 最小配置 | ServerCat 监控 |
ssh user@server "bash -l -c 'cmd'" |
❌ 无 | 登录 Shell | 完整配置 | Agent 需要环境 |
ssh -t user@server "bash -l -c 'cmd'" |
✅ 伪 TTY | 登录 Shell | 完整配置+TTY | 交互式应用 |
ssh user@server |
✅ 真实 TTY | 登录 Shell | 完整配置+TTY | 人工登录 |
关键参数说明:
-t:强制分配伪终端,解决交互界面问题(颜色、编辑等)-l:登录 Shell 模式,加载完整的环境配置(PATH、变量、工具等)- 组合使用 :
ssh -t user@server "bash -l -c 'cmd'"最接近人工登录环境
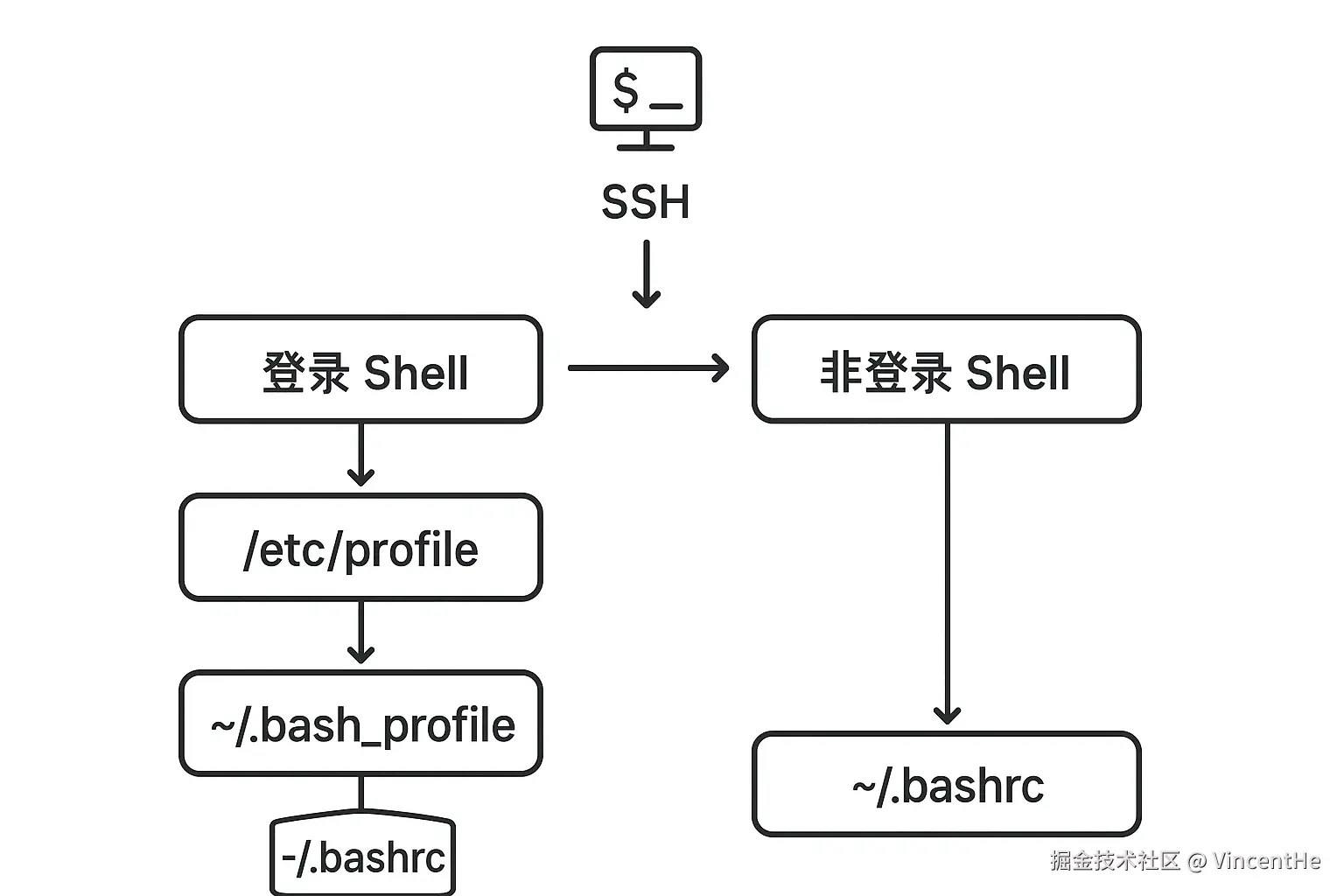 图:登录 Shell 与非登录 Shell 的配置文件加载流程对比
图:登录 Shell 与非登录 Shell 的配置文件加载流程对比
根因定位:雪崩效应的源头
现在问题变得清晰了。我检查了服务器上的.zshenv文件:
bash
# ~/.zshenv 的内容
if [ -f ~/.zshrc ]; then
source ~/.zshrc
fi就是这个配置!它导致了以下连锁反应:
- ServerCat 执行监控命令 :
ssh user@server "top -bn1" - 启动非登录 Shell:由于是通过 SSH 直接执行命令
- 读取~/.zshenv:Zsh 的特殊行为,非登录 Shell 也会读取.zshenv
- 加载完整.zshrc :由于.zshenv 中的
source ~/.zshrc - 初始化完整环境:包括 oh-my-zsh、插件、主题、函数等
- 资源雪崩:每次监控都重复这个过程
粗略统计了一下,当 ServerCat 运行时,系统中出现了 47 个 zsh 进程,每个进程都在重复加载完整的 Shell 环境,这就像 47 个人同时打开一个复杂软件,导致服务器 CPU 暴涨。
解决方案:分层优化策略
最直接的解决方法是修改~/.zshenv,避免非登录 Shell 加载复杂配置:
bash
# 原配置(问题配置)
if [ -f ~/.zshrc ]; then
source ~/.zshrc
fi
# 优化后配置
# 零配置 - 最小化ServerCat监控开销
# 只保留注释,不设置任何环境变量这个改动的效果立竿见影:
bash
# 修改后立即测试
$ uptime
08:48:30 up 22:58, 1 user, load average: 17.43, 17.45, 9.28
# 等待系统稳定后
$ uptime
09:15:04 up 23:25, 2 users, load average: 0.32, 0.47, 1.97系统负载从 17+降到了 0.32。
延展:设置正确的 Shell 环境
在排查过程中,我还发现了一个有趣的现象:为什么 SSH 登录后显示的是 bash 而不是 zsh?
bash
# 检查用户默认Shell
$ getent passwd root | cut -d: -f7
/bin/bash # 原来是bash!
# 修改为zsh
$ chsh -s /bin/zsh这里要澄清一个重要概念:
chsh -s /bin/zsh只影响登录 Shell的默认选择- 非登录 Shell 的行为由
.zshenv控制 - 我们的
.zshenv是零配置,所以 ServerCat 开销最小
这样就实现了完美的平衡:
- 手动 SSH 登录:享受完整的 zsh 功能和美观界面
- ServerCat 监控:保持最低的监控开销
知识点梳理:Shell 环境管理核心概念
通过这次排查,我系统性地梳理了几个重要的知识点:
1. TTY 与 Shell 的关系
很多人会混淆 TTY 和登录 Shell 的概念。TTY(TeleTypewriter)是终端设备,提供输入输出界面;而登录 Shell 是一种 Shell 启动模式。
| 场景 | TTY | Shell 模式 | 配置文件加载 |
|---|---|---|---|
ssh user@server |
✅ 有 TTY | 登录 Shell | profile + shellrc |
ssh user@server "cmd" |
❌ 无 TTY | 非登录 Shell | 只有 shellrc |
ssh user@server -t "cmd" |
✅ 临时 TTY | 非登录 Shell | 只有 shellrc |
2. SSH 参数详解
在排查过程中,我发现了一些重要的 SSH 参数:
ssh -t:强制分配伪终端,适合需要交互界面的命令top -bn1:-b批处理模式,-n1只显示一次,适合自动化监控
bash
# ServerCat使用的参数组合
ssh user@server "top -bn1"
# ↓
# 无TTY + 非登录Shell + 批处理模式 = 高效监控3. 配置文件的职责分离
最佳实践是明确不同配置文件的职责:
bash
# ~/.zshenv - 仅环境变量 (每次启动都加载)
# ~/.zshrc - 完整配置 (交互式使用)
# ~/.zprofile - 登录时配置 (PATH等)性能对比
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 系统负载 | 16-24 | 0.3-1.5 |
| CPU 使用率 | 72%+ sy | 20%以下 |
| zsh 进程数 | 47 个 | 监控时 2-3 个 |
| 监控响应 | 缓慢,卡顿 | 流畅,实时 |
结语
这个看似简单的 ServerCat 性能问题,实际上涉及到了 Shell 环境管理、SSH 连接机制、系统监控等多个方面的知识。通过系统性的排查和优化,我们不仅解决了当前的问题,还建立了一套更科学的服务器监控环境。
最重要的启示是:在追求功能丰富的同时,也要考虑性能开销的平衡。特别是在自动化和监控场景下,最小化的环境配置往往是更好的选择。
希望这次实战经验能够帮助其他遇到类似问题的开发者,也提醒大家在配置 Shell 环境时要更加谨慎和有目的性。
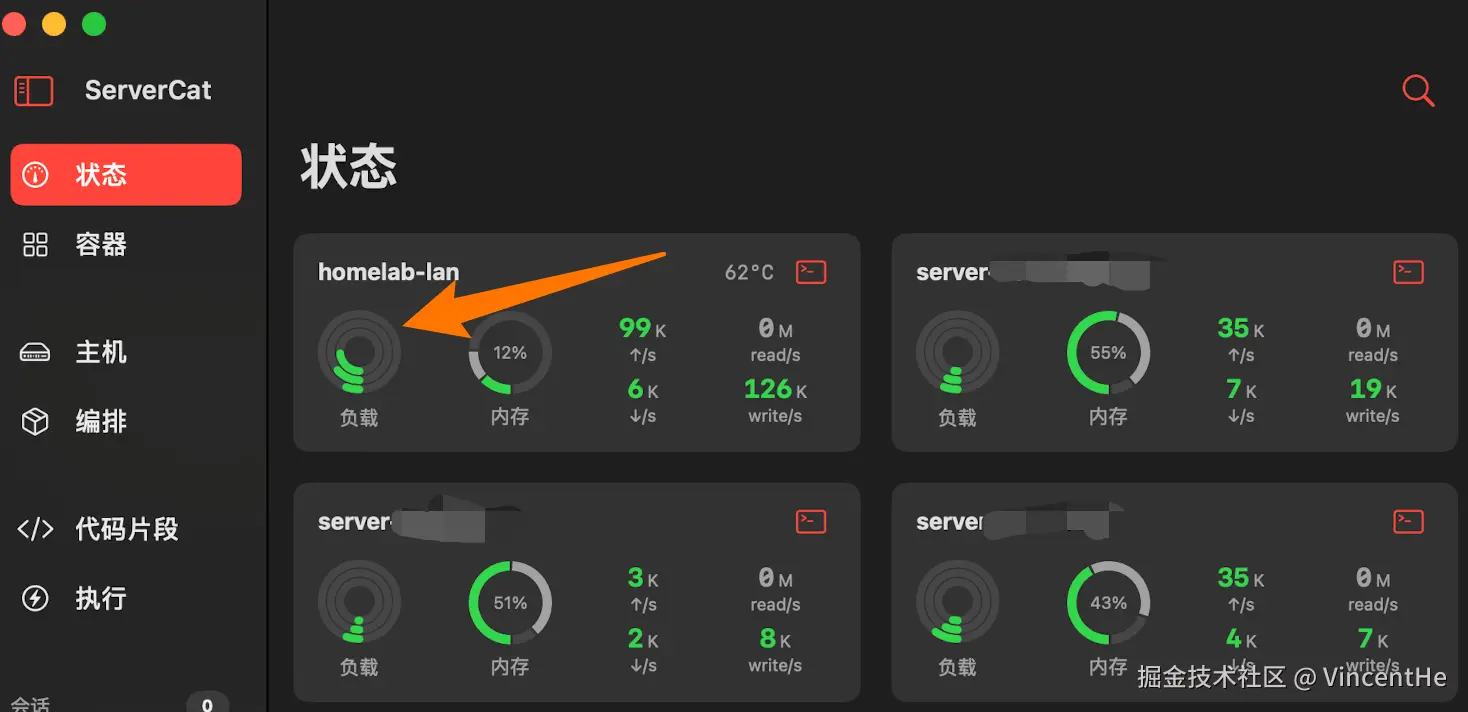 图:优化后的 ServerCat 监控界面,系统各项指标都恢复到健康水平
图:优化后的 ServerCat 监控界面,系统各项指标都恢复到健康水平
附录:系统负载指标解读指南
通过这次优化,我们不仅解决了性能问题,还学会了如何正确解读服务器的负载指标。以下是几个关键指标的含义:
Load Average(系统负载)
系统负载通常显示三个数字,如 0.32, 0.47, 1.97,分别代表:
- 第一个数字:1 分钟平均负载
- 第二个数字:5 分钟平均负载
- 第三个数字:15 分钟平均负载
如何判断负载是否健康?
bash
# 查看CPU核心数
$ nproc
4
# 健康标准:负载 < CPU核心数
# 4核服务器:负载 < 4.0 为健康
# 8核服务器:负载 < 8.0 为健康CPU 使用率分解
top命令中的 CPU 使用率包含多个组成部分:
bash
%Cpu(s): 4.6 us, 7.7 sy, 0.0 ni, 87.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st- us (user):用户进程占用 CPU 百分比
- sy (system):系统进程占用 CPU 百分比
- ni (nice):优先级进程占用 CPU 百分比
- id (idle):CPU 空闲百分比
- wa (I/O wait):等待 I/O 的 CPU 百分比
- hi/si (hardware/software interrupts):硬件/软件中断
- st (steal time):虚拟化环境下被偷走的时间
我们的优化效果对比
优化前的问题指标:
lua
Tasks: 289 total, 13 running, 274 sleeping
%Cpu(s): 19.6 us, 72.9 sy, 0.0 ni, 7.5 id, 0.0 wa
load average: 24.40, 13.03, 5.50- 问题分析:72.9%的 system CPU 使用率表明系统调用过多
- 严重程度:负载 24.40 远超 4 核服务器承受能力
优化后的健康指标:
lua
Tasks: 186 total, 1 running, 184 sleeping
%Cpu(s): 4.6 us, 7.7 sy, 0.0 ni, 87.7 id, 0.0 wa
load average: 0.67, 0.47, 0.39- 改善效果:system CPU 使用率从 72.9%降到 7.7%
- 负载情况:0.67 完全在 4 核服务器的健康范围内
实用监控技巧
- 实时监控趋势:
bash
# 持续监控负载变化
$ watch -n 1 'uptime'- 定位高 CPU 进程:
bash
# 按CPU使用率排序
$ top -o %CPU- 系统健康快速检查:
bash
# 一句话检查系统状态
$ echo "Load: $(uptime | awk '{print $NF}')" && \
echo "CPU Idle: $(top -bn1 | grep '%Cpu' | awk '{print $8}')" && \
echo "Mem Free: $(free -h | awk 'NR==2{print $4}')"掌握这些指标的解读方法,可以帮助我们及时发现和解决类似的服务器性能问题。
本文记录了一次真实的服务器性能优化过程,所有技术细节都经过实际验证。如果您在配置 Shell 环境或服务器监控时遇到类似问题,欢迎交流讨论。