RabbitMQ 保证消息顺序消费的核心原则是:确保 "同一业务序列的消息" 只能被单一线程按顺序处理。由于 RabbitMQ 本身的消息分发机制(如多消费者并行拉取)可能打破顺序,需通过特定方案规避,以下是具体实现方式:
基础原理:为什么顺序会乱?
默认情况下,消息顺序可能被打乱的原因:
- 多消费者竞争同一队列:队列中的消息会被多个消费者并行拉取,导致先发送的消息可能后被处理。
- 消息重发 / 死信:消息处理失败后重发或进入死信队列,可能改变原有的顺序。
- 优先级队列:高优先级消息会被提前消费,打破原有顺序。
因此,保证顺序的核心是 "同一业务序列的消息只能由单消费者按顺序处理" 。
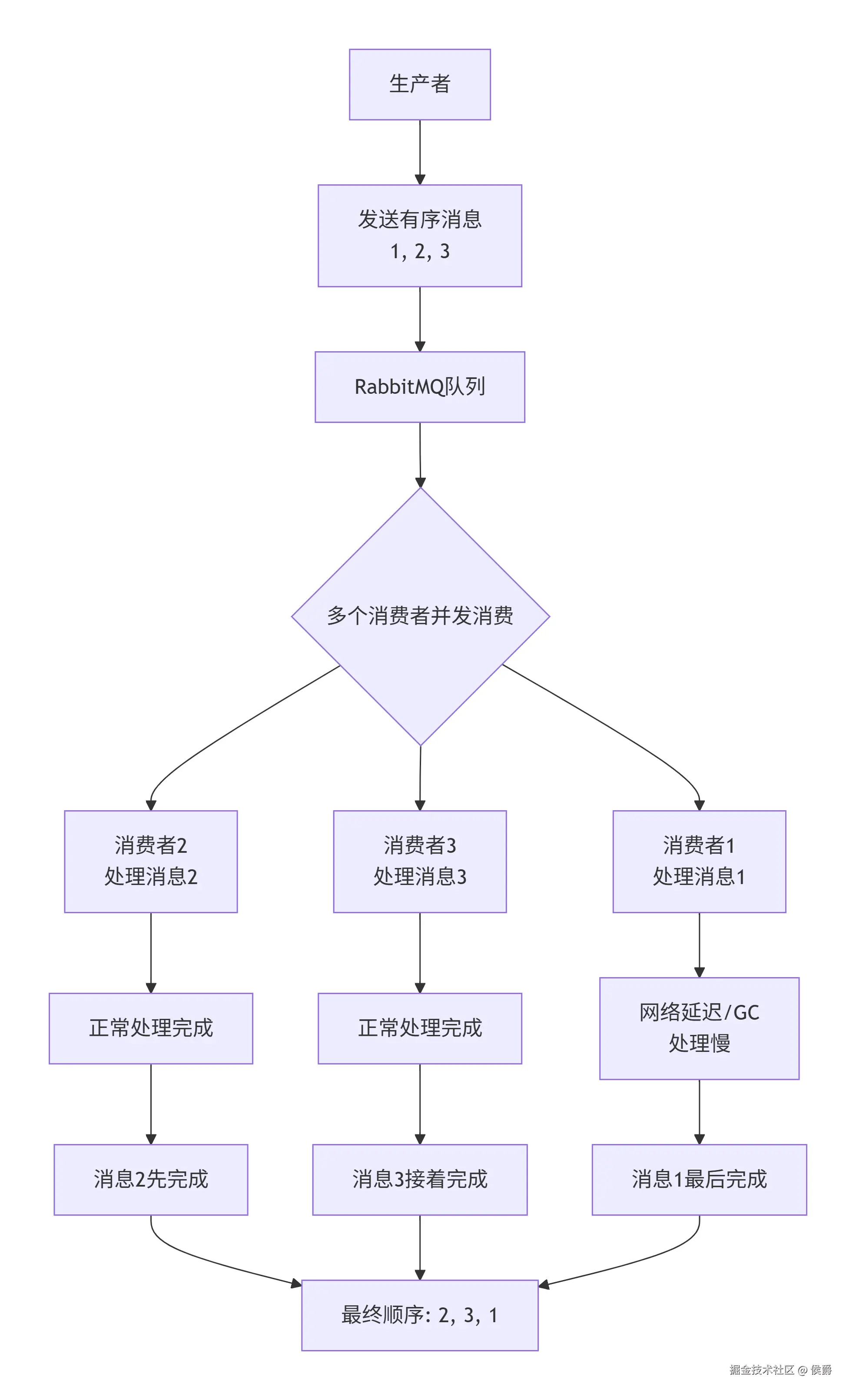
以下是具体实现方案:
1. 单队列 + 单消费者(最简单,适合低吞吐量场景)
-
原理:一个队列只绑定一个消费者,且消费者单线程处理消息,消息按发送顺序进入队列,天然保证顺序。
-
实现步骤:
- 声明一个专用队列(如
order_seq_queue),确保持久化(避免消息丢失)。 - 生产者按业务顺序发送消息到该队列。
- 消费者配置为单线程(
concurrency = "1"),并手动确认消息(处理完一条再确认下一条)。
- 声明一个专用队列(如
-
适用场景:对吞吐量要求不高,但顺序性要求严格的场景(如日志同步)。
-
优缺点:
- 优点:实现简单,绝对保证顺序。
- 缺点:吞吐量低(单消费者瓶颈),且多实例部署时需额外控制(避免多实例同时消费)。
2. 多队列 + 分区有序(兼顾性能与顺序)
当需要提高吞吐量时,可通过按 "业务标识" 分区的方式,将同一标识的消息路由到固定队列,每个队列对应一个消费者。
原理
- 按 "业务标识"(如订单 ID、用户 ID)将消息分片到多个队列,同一标识的消息始终进入同一个队列。
- 每个队列绑定一个单线程消费者,保证队列内消息顺序;多队列并行处理提升整体吞吐量。
实现步骤
- 创建多个队列 :根据业务并发需求创建 N 个队列(如
queue_0到queue_9)。 - 消息路由规则 :发送消息时,通过业务标识哈希计算队列索引(如
index = hash(业务ID) % N),确保同一业务的消息路由到固定队列。 - 单消费者绑定队列:每个队列仅对应一个消费者(单线程),确保队列内消息按顺序处理。
具体实现:
- 步骤 1:拆分多个队列 创建多个队列(如
queue_order_0、queue_order_1、...、queue_order_n),数量根据业务并发需求设定。 - 步骤 2:消息发送时按 "业务标识" 路由 发送消息时,根据消息中的 "业务唯一标识"(如订单 ID、用户 ID)计算哈希值,将同一标识的消息路由到固定队列。例如:
队列索引 = hash(业务ID) % 队列数量,确保同一业务的消息始终进入同一个队列。
java
// 示例:发送消息时指定路由规则
// 1. 声明10个队列
@Configuration
public class QueueConfig {
@Bean
public Queue[] queues() {
Queue[] queues = new Queue[10];
for (int i = 0; i < 10; i++) {
queues[i] = QueueBuilder.durable("order_queue_" + i).build();
}
return queues;
}
}
// 2. 生产者:按业务ID路由到固定队列
@Component
public class Producer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void send(String orderId, String message) {
int index = Math.abs(orderId.hashCode() % 10); // 哈希取模计算队列索引
rabbitTemplate.convertAndSend("order_queue_" + index, message);
}
}
// 3. 消费者:每个队列对应一个单线程消费者
@Component
public class Consumer {
@RabbitListener(queues = "order_queue_0", concurrency = "1")
public void consume0(String message) { process(message); }
@RabbitListener(queues = "order_queue_1", concurrency = "1")
public void consume1(String message) { process(message); }
// ... 其他队列的消费者(共10个)
}- 步骤 3:每个队列绑定单个消费者每个队列仅对应一个消费者,确保该队列内的消息按顺序被处理。
- 优点:通过多队列 + 多消费者提高吞吐量,同时保证同一业务标识的消息有序。
- 缺点:队列和消费者数量需提前规划,哈希分布不均可能导致部分队列负载过高(可通过一致性哈希优化)。
3. 利用 RabbitMQ 的消息属性与确认机制辅助
- 消息持久化 :确保消息不会因 broker 宕机丢失,避免顺序断层(
durable=true)。 - 单条确认 :消费者处理完一条消息后,再发送
basicAck确认,避免消息被提前移除队列导致顺序混乱(禁止批量确认)。
java
// 关闭自动确认,手动单条确认
channel.basicConsume(queueName, false, (consumerTag, delivery) -> {
// 处理消息
processMessage(delivery.getBody());
// 处理完成后手动确认当前消息
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}, consumerTag -> {});4. 避免使用可能破坏顺序的特性
- 禁止使用优先级队列:优先级高的消息会被提前消费,打破原有序列。
- 谨慎使用消息重发 / 死信队列:若消息处理失败需重发,需确保重发的消息仍进入原队列,且处理顺序正确(可通过消息序号标记辅助)。
- 避免多消费者竞争同一队列:多消费者会并行拉取消息,导致顺序混乱。
总结
保证 RabbitMQ 消息顺序消费的核心是 "同一业务序列的消息只能被单消费者按顺序处理" 。实际应用中,推荐使用 "多队列 + 按业务标识分区" 的方案,在顺序性和吞吐量之间取得平衡。
在生产环境中部署多台服务器(多实例)时,若要继续使用 "单队列 + 单消费者" 方案保证消息顺序,核心挑战是避免多个实例同时消费同一个队列(否则多消费者会打乱顺序)。解决方案是通过 **"分布式抢占" 机制确保同一时刻只有一个实例的消费者能消费队列 **,其他实例的消费者处于 "待命" 状态,仅在主消费者故障时接管。
方案1:实现思路:多台服务器 + 分布式锁(实现单消费者)
利用分布式锁(如 Redis、ZooKeeper)控制消费者的启停:
- 所有实例启动时尝试获取分布式锁,只有获取到锁的实例才启动消费者(成为 "主消费者")。
- 未获取到锁的实例,消费者处于 "关闭" 或 "待命" 状态。
- 主消费者所在实例故障时,分布式锁释放,其他实例竞争锁并启动消费者(自动接管),保证可用性。
基于 Redis 分布式锁确保全局只有一个活跃消费者
若希望将 Redis 分布式锁直接嵌入消费者方法中(而非通过动态启停消费者),核心思路是:每个实例的消费者在处理消息前先尝试获取分布式锁,只有获取到锁的实例才能处理消息,未获取到锁则跳过处理。这样既能保证同一时刻只有一个消费者处理消息,又能利用多实例实现故障冗余。
实现方案(Spring Boot + Redisson)
1. 依赖与配置(同前文)
确保引入 spring-boot-starter-amqp、spring-boot-starter-data-redis 和 redisson-spring-boot-starter,并配置 RabbitMQ 和 Redis 连接。
2. 消费者方法直接集成分布式锁
在 @RabbitListener 方法中,先尝试获取分布式锁,获取成功才处理消息,失败则直接确认消息(避免消息重复阻塞)。
java
import com.rabbitmq.client.Channel;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.concurrent.TimeUnit;
@Component
public class OrderMessageConsumer {
// 分布式锁的 key(与队列绑定,确保唯一)
private static final String LOCK_KEY = "order_queue_process_lock";
@Autowired
private RedissonClient redissonClient;
// 多实例都启动消费者,但通过锁控制只有一个实例处理消息
@RabbitListener(
queues = "order_queue",
concurrency = "1" // 单线程处理,避免实例内并发
)
public void handleOrderMessage(String message, Channel channel, Message amqpMessage) throws IOException {
RLock lock = redissonClient.getLock(LOCK_KEY);
boolean isLocked = false;
try {
// 尝试获取锁(最多等待1秒,获取后持有30秒,自动续期)
// 等待时间设短,避免未获取锁的实例长期阻塞
isLocked = lock.tryLock(1, 30, TimeUnit.SECONDS);
if (isLocked) {
// 1. 获取锁成功:处理消息(保证顺序性)
System.out.println("实例 " + getInstanceId() + " 处理消息:" + message);
// 模拟业务处理
Thread.sleep(100);
// 处理完成,手动确认消息
channel.basicAck(amqpMessage.getMessageProperties().getDeliveryTag(), false);
} else {
// 2. 未获取锁:拒绝消息并重新入队(关键修正)
// requeue = true:消息放回队列,等待其他实例处理
channel.basicNack(amqpMessage.getMessageProperties().getDeliveryTag(), false, true);
}
} catch (Exception e) {
// 3. 处理失败:拒绝消息并放回队列(重试)
channel.basicNack(amqpMessage.getMessageProperties().getDeliveryTag(), false, true);
e.printStackTrace();
} finally {
// 释放锁(仅释放当前线程持有的锁)
if (isLocked && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
// 获取实例唯一标识(如主机名+进程ID,用于日志区分)
private String getInstanceId() {
return String.format("%s:%d", java.net.InetAddress.getLocalHost().getHostName(), ProcessHandle.current().pid());
}
}方案说明
核心逻辑
- 多实例同时监听队列:所有实例的消费者都启动并监听同一个队列(打破 "动态启停" 的思路)。
- 消费前抢锁 :每个实例处理消息前必须先获取 Redis 分布式锁,只有一个实例能抢到锁并处理消息。
- 未抢锁则确认消息 :未抢到锁的实例通过
basicNack(requeue = true)拒绝消息,让消息重新回到队列头部,等待持有锁的实例再次拉取处理(而非被删除)。此时持有锁的实例会再次从队列拉取消息并处理,保证消息不会丢失。 - 锁自动续期 :Redisson 的
RLock会自动续期(看门狗机制),避免处理长耗时任务时锁过期。
优点
- 无需动态启停消费者:实现更简单,所有实例的消费者始终处于运行状态。
- 高可用性:主实例故障后,锁自动释放,其他实例可立即抢锁并接管处理。
- 顺序性保证:同一时刻只有一个实例处理消息,严格保证顺序。
关键注意事项
- 锁等待时间设置 :
tryLock的等待时间(如 1 秒)需尽可能短,避免未抢到锁的实例长期阻塞(导致队列消息堆积)。 - 必须确认未处理的消息 :未抢到锁的实例必须调用
basicAck确认消息,否则消息会被标记为 "未处理",导致队列中消息堆积(RabbitMQ 会认为消息仍在处理中)。 - 避免重复消费 :由于未抢到锁的实例会确认消息,消息会重新回到队列,可能被持有锁的实例再次拉取,需确保业务逻辑幂等(重复处理不影响结果)。
- 锁过期时间:需大于单条消息的最大处理耗时(如 30 秒),结合 Redisson 自动续期,防止处理中锁过期。
- 实例内单线程 :
concurrency = "1"确保单个实例内只有一个线程处理消息,避免实例内并发抢锁导致的资源浪费。
适用场景
此方案适合顺序性要求高、需要多实例冗余,且能接受轻微的 "消息重复拉取"(因未抢锁实例确认后消息重回队列)的场景。相比 "动态启停消费者",实现更简单,但会产生少量无效的消息拉取(可通过合理设置锁等待时间优化)。
可能的问题与优化
-
消息重复入队导致的性能损耗多实例同时抢锁时,未抢到锁的实例会频繁将消息放回队列,可能导致消息在队列中 "震荡"。优化方式:
- 减少实例数量(如仅部署 2 个实例,降低抢锁冲突)。
- 给队列设置
x-max-priority为 1(无优先级),避免消息入队顺序混乱。
-
消息处理延迟消息可能被多个实例 "拒绝 - 入队" 多次后才被处理,产生延迟。可通过监控队列消息堆积情况,动态调整实例数量或锁持有时间。
-
幂等性要求由于消息可能被多次拉取(不同实例抢锁时),业务逻辑必须保证幂等(如通过消息 ID 去重),避免重复处理导致数据错误。
方案2:业务分片(最推荐、最常用)
这是 RabbitMQ 生态中的标准答案。核心思想是:放弃全局顺序,保证分组顺序。
实现原理:
- 选择分片键 :选择一个业务ID作为分片键,保证需要顺序处理的消息拥有相同的分片键。例如:
订单ID、用户ID、会话ID。 - 按分片键路由 :将相同分片键的消息,通过交换器始终路由到同一个队列。
- 每个队列单消费者 :为每个队列分配一个独占的消费者实例(或线程) 。
这样,对于同一个订单(分片键)的消息,它们会在同一个队列中被同一个消费者顺序处理。
具体技术实现:
方法1:使用 x-consistent-hash 交换器
这是最优雅的方式,使用一致性哈希算法将消息均匀分布到多个队列。
1. 配置类
java
@Configuration
public class RabbitConfig {
// 定义业务分片队列 - 这里创建4个队列用于分片
@Bean
public Queue orderQueue0() {
return new Queue("order.queue.0", true);
}
@Bean
public Queue orderQueue1() {
return new Queue("order.queue.1", true);
}
@Bean
public Queue orderQueue2() {
return new Queue("order.queue.2", true);
}
@Bean
public Queue orderQueue3() {
return new Queue("order.queue.3", true);
}
// 分片交换器
@Bean
public DirectExchange orderExchange() {
return new DirectExchange("order.exchange");
}
// 绑定队列到交换器
@Bean
public Binding binding0(Queue orderQueue0, DirectExchange orderExchange) {
return BindingBuilder.bind(orderQueue0).to(orderExchange).with("0");
}
@Bean
public Binding binding1(Queue orderQueue1, DirectExchange orderExchange) {
return BindingBuilder.bind(orderQueue1).to(orderExchange).with("1");
}
@Bean
public Binding binding2(Queue orderQueue2, DirectExchange orderExchange) {
return BindingBuilder.bind(orderQueue2).to(orderExchange).with("2");
}
@Bean
public Binding binding3(Queue orderQueue3, DirectExchange orderExchange) {
return BindingBuilder.bind(orderQueue3).to(orderExchange).with("3");
}
// 配置并发消费者为1,确保每个队列只有一个消费者线程
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(
ConnectionFactory connectionFactory) {
SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();
factory.setConnectionFactory(connectionFactory);
factory.setConcurrentConsumers(1); // 关键:每个监听器只有1个消费者
factory.setMaxConcurrentConsumers(1);
factory.setPrefetchCount(1); // 关键:每次只预取1条消息
return factory;
}
}2. 生产者服务
java
@Service
public class OrderMessageProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
@Autowired
private DirectExchange orderExchange;
/**
* 发送订单消息
* @param orderId 订单ID - 作为分片键
* @param message 消息内容
*/
public void sendOrderMessage(Long orderId, String message) {
// 计算分片键:orderId % 队列数量
int shardKey = (int) (orderId % 4);
OrderMessage orderMessage = new OrderMessage(orderId, message, System.currentTimeMillis());
rabbitTemplate.convertAndSend(
orderExchange.getName(),
String.valueOf(shardKey), // 使用分片键作为路由键
orderMessage
);
System.out.println("Sent message for order " + orderId + " to shard " + shardKey);
}
}
// 消息对象
@Data
@AllArgsConstructor
@NoArgsConstructor
public class OrderMessage implements Serializable {
private Long orderId;
private String content;
private Long timestamp;
}3. 消费者服务
java
@Service
public class OrderMessageConsumer {
private static final Logger logger = LoggerFactory.getLogger(OrderMessageConsumer.class);
/**
* 监听分片队列0
*/
@RabbitListener(queues = "order.queue.0", containerFactory = "rabbitListenerContainerFactory")
public void consumeShard0(OrderMessage message) {
processMessage(message, 0);
}
/**
* 监听分片队列1
*/
@RabbitListener(queues = "order.queue.1", containerFactory = "rabbitListenerContainerFactory")
public void consumeShard1(OrderMessage message) {
processMessage(message, 1);
}
/**
* 监听分片队列2
*/
@RabbitListener(queues = "order.queue.2", containerFactory = "rabbitListenerContainerFactory")
public void consumeShard2(OrderMessage message) {
processMessage(message, 2);
}
/**
* 监听分片队列3
*/
@RabbitListener(queues = "order.queue.3", containerFactory = "rabbitListenerContainerFactory")
public void consumeShard3(OrderMessage message) {
processMessage(message, 3);
}
private void processMessage(OrderMessage message, int shard) {
logger.info("Shard[{}] Processing order {}: {}", shard, message.getOrderId(), message.getContent());
try {
// 模拟业务处理
Thread.sleep(1000);
logger.info("Shard[{}] Completed order {}: {}", shard, message.getOrderId(), message.getContent());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
logger.error("Processing interrupted for order {}", message.getOrderId(), e);
}
}
}方案3:使用 SingleActiveConsumer(Spring AMQP 2.0+)
SingleActiveConsumer 是 RabbitMQ 3.8+ 和 Spring AMQP 2.2.1+ 提供的原生功能,可以在多个消费者中自动选举一个活跃消费者,其他消费者作为备用。
工作机制
java
// SingleActiveConsumer 的工作原理:
// 1. 多个消费者实例监听同一个队列
// 2. RabbitMQ 自动选举一个活跃消费者
// 3. 只有活跃消费者接收消息
// 4. 当活跃消费者断开时,自动故障转移到另一个消费者
// 5. 消息顺序在单个消费者内保证架构图
text
[生产者] → [RabbitMQ队列] → [多个消费者实例]
│
├── ✅ [活跃消费者] - 处理消息
├── 🔄 [备用消费者1] - 等待
└── 🔄 [备用消费者2] - 等待配置类
java
@Configuration
public class SingleActiveConsumerConfig {
// 使用 SingleActiveConsumer 的队列
@Bean
public Queue orderQueue() {
return QueueBuilder.durable("order.single.queue")
.singleActiveConsumer() // 关键:只有一个活跃消费者
.build();
}
@Bean
public DirectExchange orderSingleExchange() {
return new DirectExchange("order.single.exchange");
}
@Bean
public Binding singleBinding(Queue orderQueue, DirectExchange orderSingleExchange) {
return BindingBuilder.bind(orderQueue).to(orderSingleExchange).with("order");
}
}
// 消费者
@Service
public class SingleActiveConsumer {
private static final Logger logger = LoggerFactory.getLogger(SingleActiveConsumer.class);
@RabbitListener(queues = "order.single.queue")
public void consumeOrder(OrderMessage message) {
logger.info("SingleActiveConsumer Processing order {}: {}",
message.getOrderId(), message.getContent());
try {
// 模拟业务处理
Thread.sleep(1000);
logger.info("SingleActiveConsumer Completed order {}", message.getOrderId());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}方案4:动态分片配置(更灵活)
1. 动态配置类
java
@Configuration
public class DynamicShardingConfig {
private static final int SHARD_COUNT = 4;
@Bean
public Declarables declarables() {
List<Declarable> declarables = new ArrayList<>();
// 创建分片交换器
DirectExchange shardExchange = new DirectExchange("order.shard.exchange");
declarables.add(shardExchange);
// 动态创建队列和绑定
for (int i = 0; i < SHARD_COUNT; i++) {
Queue queue = new Queue("order.shard.queue." + i, true);
Binding binding = BindingBuilder.bind(queue).to(shardExchange).with(String.valueOf(i));
declarables.add(queue);
declarables.add(binding);
}
return new Declarables(declarables);
}
}2. 动态生产者
java
@Service
public class DynamicShardProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
private final int shardCount = 4;
public void sendShardMessage(String businessKey, Object message) {
// 使用业务键的哈希值计算分片
int shard = Math.abs(businessKey.hashCode()) % shardCount;
rabbitTemplate.convertAndSend(
"order.shard.exchange",
String.valueOf(shard),
message
);
System.out.println("Sent message with key " + businessKey + " to shard " + shard);
}
}方案5:使用自定义消息序列器
1. 带序列号的消息
java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class SequencedMessage implements Serializable {
private String messageId;
private Long sequenceNumber; // 全局序列号
private String businessKey; // 业务分片键
private Object payload;
private Long timestamp;
}2. 序列化消费者(简化版)
java
@Service
public class SequencedConsumer {
private final Map<String, PriorityBlockingQueue<SequencedMessage>> messageQueues = new ConcurrentHashMap<>();
private final Map<String, Long> expectedSequences = new ConcurrentHashMap<>();
@RabbitListener(queues = "order.sequenced.queue")
public void consumeSequenced(SequencedMessage message) {
String businessKey = message.getBusinessKey();
// 初始化业务键的队列和期望序列号
messageQueues.putIfAbsent(businessKey, new PriorityBlockingQueue<>(
11, Comparator.comparingLong(SequencedMessage::getSequenceNumber)));
expectedSequences.putIfAbsent(businessKey, 1L);
// 将消息加入对应业务键的优先级队列
messageQueues.get(businessKey).offer(message);
// 处理有序消息
processOrderedMessages(businessKey);
}
private void processOrderedMessages(String businessKey) {
PriorityBlockingQueue<SequencedMessage> queue = messageQueues.get(businessKey);
Long expectedSequence = expectedSequences.get(businessKey);
while (!queue.isEmpty() && queue.peek().getSequenceNumber().equals(expectedSequence)) {
SequencedMessage message = queue.poll();
// 处理消息
System.out.println("Processing in order: " + message.getSequenceNumber() +
" - " + message.getPayload());
expectedSequence++;
}
expectedSequences.put(businessKey, expectedSequence);
}
}测试控制器
java
@RestController
@RequestMapping("/api/order")
public class OrderController {
@Autowired
private OrderMessageProducer orderMessageProducer;
@PostMapping("/send")
public String sendOrderMessage(@RequestParam Long orderId,
@RequestParam String content) {
orderMessageProducer.sendOrderMessage(orderId, content);
return "Message sent for order: " + orderId;
}
@PostMapping("/send-batch")
public String sendBatchMessages() {
// 测试顺序性:发送同一订单的多个消息
Long orderId = 1001L;
for (int i = 1; i <= 5; i++) {
orderMessageProducer.sendOrderMessage(orderId, "Step " + i);
}
return "Batch messages sent for order: " + orderId;
}
}application.yml 配置
yaml
yaml
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener:
simple:
default-requeue-rejected: false
acknowledge-mode: auto
template:
retry:
enabled: true
initial-interval: 1000
max-attempts: 3
multiplier: 2.0
logging:
level:
com.example: DEBUG关键要点说明
- prefetch=1:确保消费者一次只处理一条消息
- concurrentConsumers=1:每个队列只有一个消费者线程
- 业务分片键:使用订单ID、用户ID等作为分片依据
- 队列数量:根据业务量和服务器数量合理设置分片数
- 监控:需要监控各个分片队列的堆积情况
部署建议
- 分片数量建议是服务器数量的整数倍
- 使用监控工具监控各个队列的消息堆积
- 为重要队列设置死信队列
- 在生产环境使用集群模式的RabbitMQ
这种方案可以在保证同一订单消息顺序处理的同时,充分利用多服务器的并行处理能力。
方案6:单队列 + 多消费者(基于消息序号的消费端排序)
原理
- 所有消息进入同一个队列,允许多个消费者并行拉取消息,但消息本身携带全局递增序号 (如
seq=1,2,3...)。 - 消费者拉取消息后不立即处理,而是先存入本地缓存(或分布式缓存),再按序号从小到大依次处理,确保顺序。
关键步骤
- 生产者生成序号:发送消息时,为每个消息添加唯一递增序号(可基于 Redis 自增、数据库自增 ID 等生成)。
java
// 生产者示例:消息格式包含序号
public void sendMessage(String content) {
long seq = redisTemplate.opsForValue().increment("msg_seq"); // 全局自增序号
String message = seq + "|" + content; // 序号+内容
rabbitTemplate.convertAndSend("order_queue", message);
}消费者缓存与排序 :消费者拉取消息后,按序号存入有序缓存(如 ConcurrentSkipListMap),并检查 "连续的最小序号" 是否存在,存在则处理。
java
@Component
public class OrderedConsumer {
// 有序缓存:key=序号,value=消息内容
private final ConcurrentSkipListMap<Long, String> cache = new ConcurrentSkipListMap<>();
private volatile long currentSeq = 1; // 当前待处理的最小序号
@RabbitListener(queues = "order_queue", concurrency = "5") // 多消费者并行拉取
public void consume(String message, Channel channel, Message amqpMsg) throws IOException {
// 解析序号和内容
String[] parts = message.split("\|", 2);
long seq = Long.parseLong(parts[0]);
String content = parts[1];
// 存入缓存
cache.put(seq, content);
// 循环处理连续的序号(如当前seq=1,若缓存有1则处理,然后处理2、3...)
while (cache.containsKey(currentSeq)) {
String toProcess = cache.remove(currentSeq);
process(toProcess); // 处理业务逻辑
currentSeq++; // 移动到下一个序号
}
// 手动确认消息(确保处理完成后再确认)
channel.basicAck(amqpMsg.getMessageProperties().getDeliveryTag(), false);
}
}优缺点
- 优点:单队列支持多消费者,吞吐量高于 "单队列 + 单消费者",适合消息序号易生成的场景。
- 缺点:依赖缓存(内存占用可能较高),若消费者故障可能导致缓存消息丢失(需结合 Redis 等持久化缓存);实现复杂度较高(需处理序号断层、缓存一致性等问题)。