源代码目录: react-source-code-learning
基于
requestIdleCallback实现的简易 Fiber 架构------ 一次搞懂:为什么要拆任务?为什么要让出时间?怎么暂停和恢复渲染?
🧩 一、问题出发:为什么要拆任务?
当我们的页面节点非常多(比如成千上万个 DOM),如果你一次性去执行所有渲染逻辑:
js
root.appendChild(allDomNodes)浏览器就会卡死几百毫秒甚至几秒,用户看到的就是:
"页面白屏一阵,然后一下子全部出来"。
这是因为浏览器主线程是单线程的 ,JS 执行会阻塞渲染。
而我们希望浏览器能在执行 JS 的同时,保持流畅的渲染和响应用户操作 。
这就要求我们把"大任务"拆成一个个"小任务"去执行。
💡 二、解决思路:时间切片(Time Slicing)
"每次做一点点,然后让浏览器喘口气。"
浏览器提供了一个非常好用的 API:
scss
requestIdleCallback(callback)它会在浏览器空闲的时候执行回调函数。
并且回调会带一个参数:deadline,其中的 deadline.timeRemaining() 告诉我们------
👉 浏览器这一帧还有多少空闲时间(毫秒)。
于是我们可以做这样的逻辑:
- 我先拿一点任务出来做。
- 如果空闲时间还多(
> 1ms),继续做。 - 如果时间不够了(
< 1ms),先暂停,下一帧再继续。
这就像我们把一次性吃完的"大餐",分成了"几口几口慢慢吃"。
⚙️ 三、核心实现流程(主循环 workLoop)
🔁 工作循环思路
每一帧浏览器空闲时,requestIdleCallback 会帮我们调用 workLoop(deadline),
我们就可以在里面不断处理 fiber 节点(一个 fiber 节点代表一个 DOM 节点的任务):
js
function workLoop(deadline) {
let shouldYield = false; // 是否需要让出时间片
while (!shouldYield && nextWorkOfUnit) {
nextWorkOfUnit = performWorkOfUnit(nextWorkOfUnit);
shouldYield = deadline.timeRemaining() < 1;
}
requestIdleCallback(workLoop);
}🧠 为什么要有 shouldYield?
- 为什么要让出时间?
因为浏览器要渲染、动画、响应点击,不能被你霸占主线程。 - 如果不让出时间?
页面会掉帧甚至冻结,用户点什么都没反应。 - 用
deadline.timeRemaining()的好处?
浏览器告诉我们还能工作多久,我们自己不用猜。
🌳 四、Fiber 单元任务执行(performWorkOfUnit)
performWorkOfUnit 就是每个"小任务"的执行函数。
一个 fiber 节点对应一个虚拟 DOM 节点。
每次执行这个函数,我们:
- 创建真实 DOM 节点
- 更新属性
- 挂到正确的父节点上
- 找下一个要处理的节点(child / sibling / parent.sibling)
✨ 1. 创建真实 DOM
js
if (!fiber.dom) {
fiber.dom = createDom(fiber);
updateProperties(fiber.dom, fiber.props);
}- 为什么要判断 fiber.dom 是否存在?
因为 fiber 可能已经创建过了(比如中断过一次任务)。
不判断就会重复创建同一个 DOM。 - 不这么做会怎样?
DOM 会被重复添加,导致页面结构错乱或性能浪费。
✨ 2. 挂载 DOM 到容器
js
appendDomToContainer(fiber.dom, fiber.parent);这里抽成了一个函数:appendDomToContainer。
- 为什么要抽离?
因为副作用逻辑(操作 DOM)最好和计算逻辑分离。
方便测试、维护,也贴近 React 的「Render + Commit」分阶段思想。 - 为什么要回退到 root?
有时候 parentFiber.dom 还没创建好,直接挂 root 避免报错。
✨ 3. 构建 fiber 树关系(child / sibling / parent)
执行完当前 fiber 后,我们要告诉系统下一个该干谁。
js
if (fiber.child) return fiber.child;
let nextFiber = fiber;
while (nextFiber) {
if (nextFiber.sibling) return nextFiber.sibling;
nextFiber = nextFiber.parent;
}这段逻辑是 fiber 遍历的精髓:
- child 优先:深度优先遍历。
- 没有子节点,就找兄弟节点。
- 没有兄弟,再往上找父节点的兄弟节点。
👉 这就是 React Fiber 的「可中断遍历」逻辑。
🧬 五、createNestedFibers ------ 构建测试用 Fiber 树
这是一个生成深层嵌套节点的函数。
我们可以设定 depth,例如 createNestedFibers(100) 表示嵌套 100 层。
js
function createNestedFibers(depth = 10) {
const root = { type: 'div', props: { id: 'test-root', children: [] } };
let parent = root;
for (let i = 1; i <= depth; i++) {
const textFiber = { type: 'TEXT_ELEMENT', props: { nodeValue: `level ${i}` } };
const divFiber = { type: 'div', props: { id: `node-${i}` } };
parent.child = textFiber;
textFiber.sibling = divFiber;
divFiber.parent = parent;
parent = divFiber;
}
return root;
}- 为什么要先建 textFiber 再建 divFiber?
模拟 React 中的文本 + 元素结构。 - 为什么循环而不是递归?
因为递归会占用调用栈,深层嵌套可能导致栈溢出。
🕹️ 六、完整执行流程图
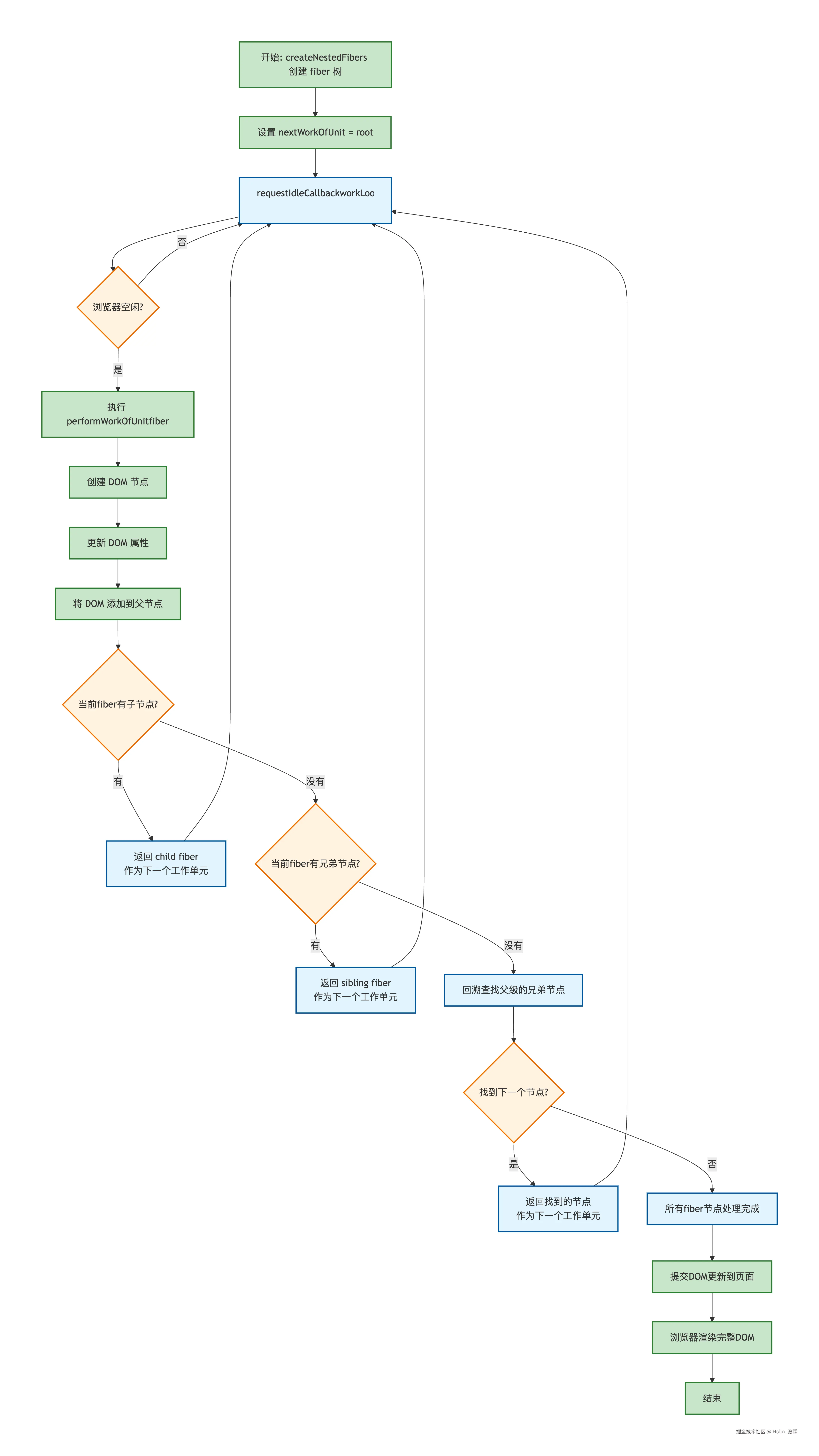
简易图:
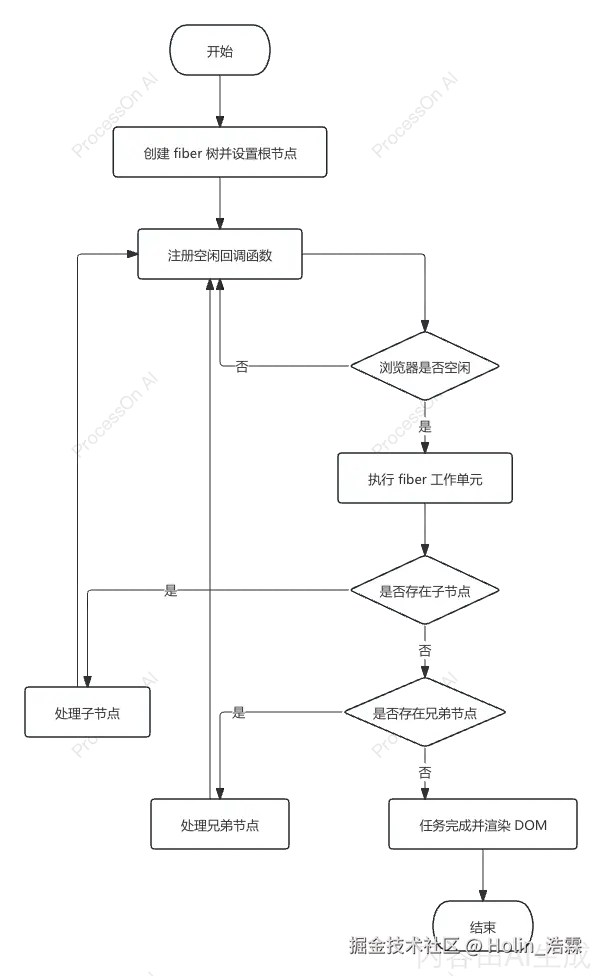
🧠 七、知识脑图(Mermaid 结构图)
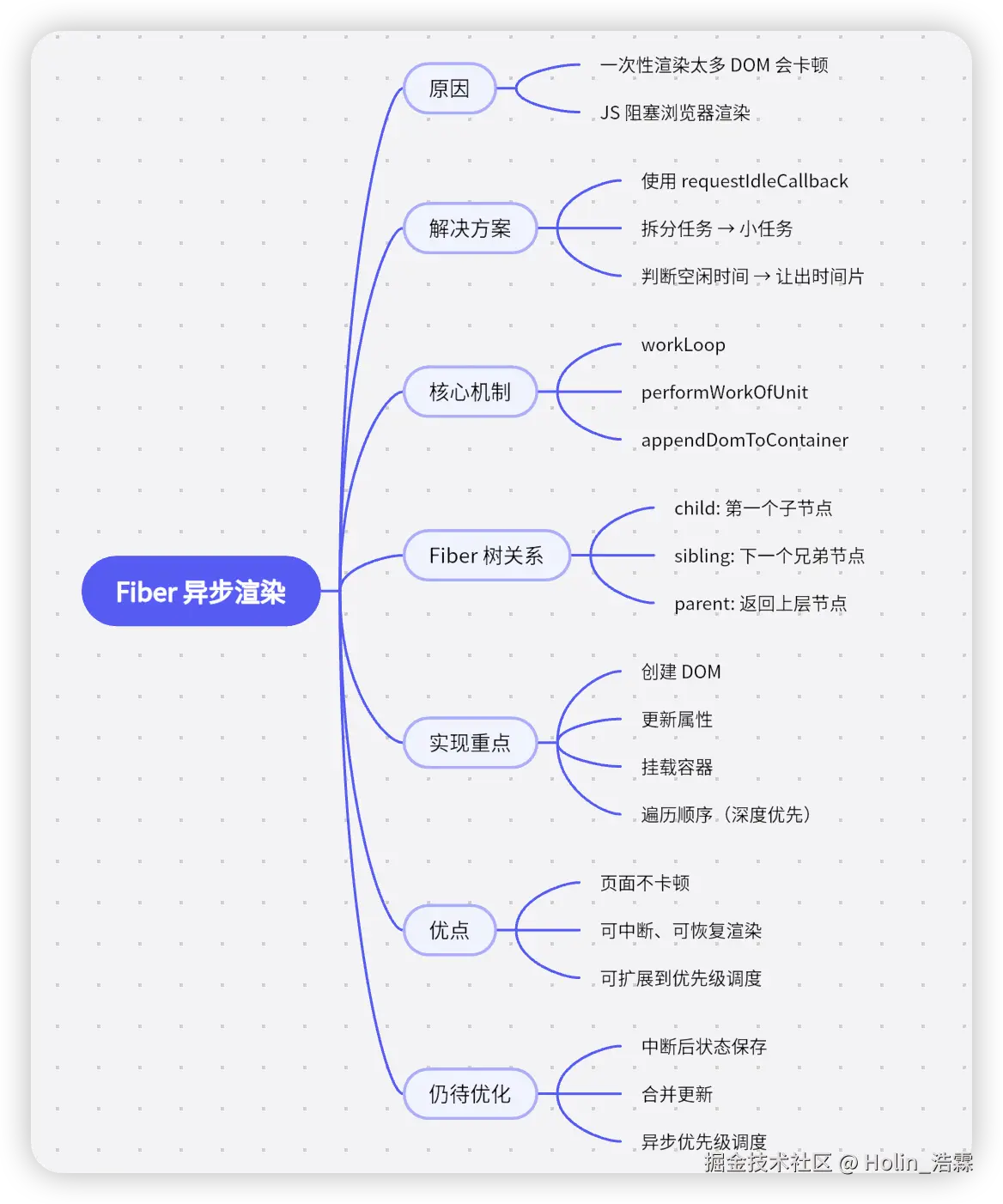
🔍 八、还有哪些问题?
源代码注释里提到的两点非常关键:
❓1. 如何高效创建大量嵌套 fiber 节点?
可以用循环构造 而不是递归,并在构造过程中建立好 parent/child/sibling 链接。
未来 React 甚至在「创建」这步也会拆任务(Concurrent 模式)。
❓2. 渲染中断后,如何保存状态以便恢复?
我们现在只是"中断了下次从头来",但 React 会在 Fiber 对象中保存工作进度(workInProgress) 。
下次继续时,就能从上次中断的 fiber 开始,而不是从 root 重新跑。
🌈 九、总结:一图看懂 Fiber 时间切片渲染
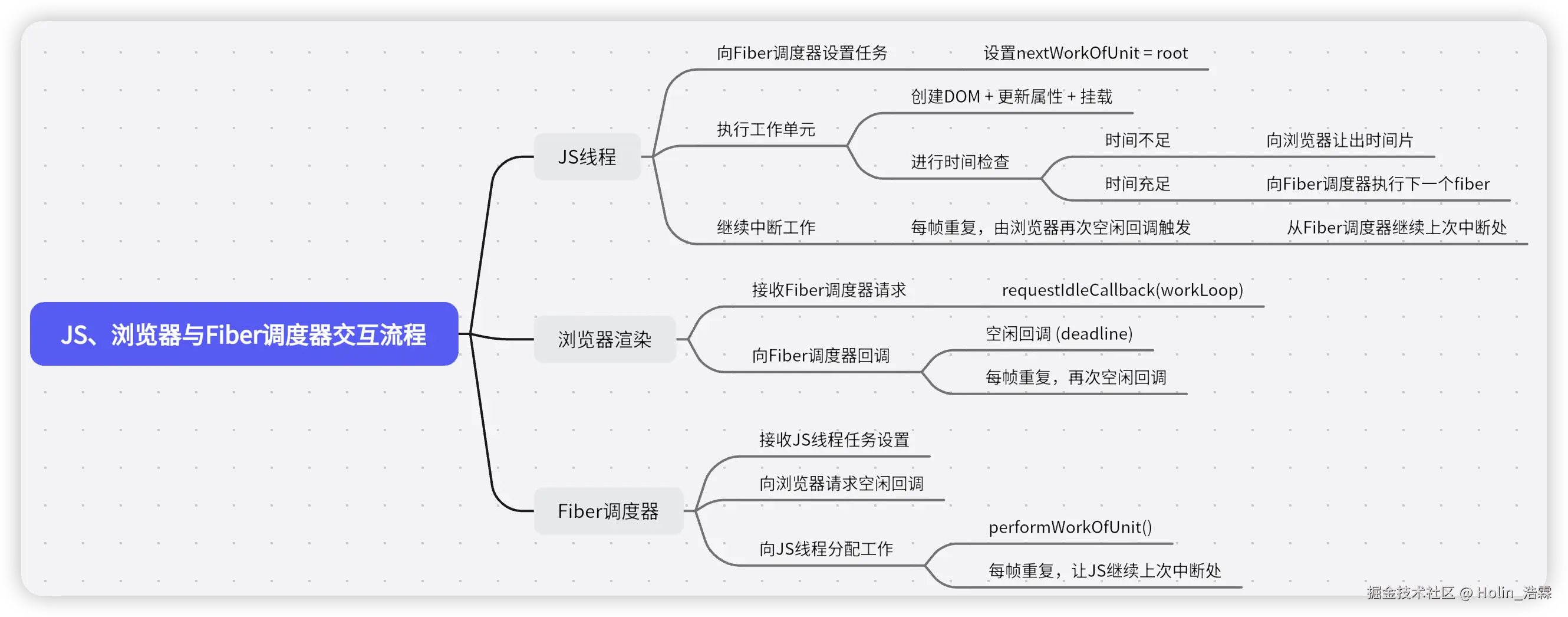
🧭 十、思考延伸
-
requestIdleCallback其实不是 React 的最终方案(因为兼容性差),React 用自己的 Scheduler 调度器 模拟了相同逻辑。 -
Fiber 本质上是"任务分片 + 可中断 + 可恢复"的架构思想。
-
这套机制还可以扩展出「优先级调度」:
- 用户输入 > 动画更新 > 低优先渲染。
💬 总结一句话:
Fiber 就像一个"任务分配器",它会在浏览器喘口气时偷偷继续干活,让用户感觉页面一直在流畅地加载。