Elastic Stack
Elastic Stack 概念
现代系统通常由多台服务器、多个应用(如 Web 服务、数据库、缓存、容器等)组成,日志分散在不同节点的本地文件中(如/var/log/nginx/access.log、/var/log/mysql/error.log),且格式各异(文本、JSON、自定义格式等)。
- 传统方式需要登录每台机器手动查找日志,效率极低。
- ELK 通过 Filebeat/Logstash 将分散的日志集中采集,统一处理为结构化数据。
- Elasticsearch 基于分布式架构和倒排索引,支持 PB 级数据存储,且能在毫秒级完成全文检索。
- ELK 通过 Logstash 的数据清洗转换和 Elasticsearch 的聚合分析,可轻松实现多维度统计(如按时间、IP、状态码分组),并通过 Kibana 可视化呈现。
ELK 指的是 Elasticsearch(数据存储)、Logstash(数据收集、过滤), Kibana(数据展示),三者共同组成了一套强大的日志收集、存储、分析与可视化解决方案,也被称为 "ELK Stack",现在常扩展为 "Elastic Stack",加入了轻量采集工具 Beats)。
-
Elasticsearch(核心存储与检索)
-
定位:分布式、高扩展、高实时的全文搜索引擎,基于 Lucene 构建。
-
功能:
- 负责存储结构化 / 非结构化数据(如日志、指标、文档等),数据以 "文档" 形式存在,支持海量数据(PB 级)存储。
- 提供实时检索与分析能力,通过倒排索引实现快速全文搜索,支持复杂的聚合分析(如统计、分组、排序)。
- 天然分布式,可通过集群扩展(横向增加节点)提升存储和处理能力,保证高可用。
-
-
Logstash(数据处理管道)
-
定位:开源的数据收集与处理引擎,主要用于日志的 "采集 - 转换 - 传输"。
-
功能:
- 输入(Input):从多种来源收集数据,如服务器日志文件、数据库、消息队列(Kafka)、API 等。
- 过滤(Filter):对原始数据进行清洗、转换(如提取字段、格式化时间、过滤无用信息),输出结构化数据。
- 输出(Output):将处理后的数据发送到目标存储,最常见的是 Elasticsearch,也可输出到数据库、文件等。
-
-
Kibana(可视化与分析平台)
-
定位:Elasticsearch 的可视化前端工具,用于数据的 "展示、分析、监控"。
-
功能:
- 通过直观的界面连接 Elasticsearch,支持全文搜索(快速定位特定日志)。
- 提供丰富的可视化组件:折线图、柱状图、饼图、地图、仪表盘等,可将分析结果转化为直观图表。
- 支持自定义告警规则(如当错误日志数量超过阈值时触发通知),常用于实时监控系统状态。
-
ELK 典型工作流程
-
数据采集:Logstash(或更轻量的 Beats,如 Filebeat 采集日志文件)从服务器、应用、设备等源头收集原始日志。
-
数据处理:Logstash 对原始日志进行清洗(如去除冗余字段)、转换(如解析 JSON 格式、提取 IP / 时间等关键信息)。
-
数据存储:处理后的结构化数据被发送到 Elasticsearch 集群,进行分布式存储和索引。
-
数据可视化与分析:用户通过 Kibana 连接 Elasticsearch,查询、分析数据,生成仪表盘或监控告警,实现对系统状态、业务趋势的实时洞察。
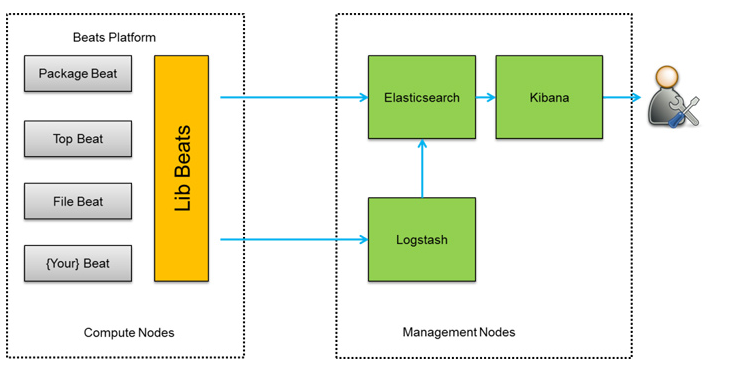
扩展:Elastic Stack(ELK + Beats)
随着场景复杂化,ELK Stack 扩展为 "Elastic Stack",加入了 Beats(轻量级数据采集器家族):
- Filebeat:专门采集日志文件,比 Logstash 更轻量(资源占用低),适合部署在边缘节点。
- Metricbeat:采集系统 / 应用指标(如 CPU、内存、服务响应时间)。
- Packetbeat:采集网络流量数据,用于网络监控。
Beats 通常作为 "前置采集器",将数据发送给 Logstash 处理(或直接发送到 Elasticsearch),进一步优化了数据采集的效率。早期的ELK架构中使用 Logstash 收集、解析日志,但是 Logstash 对内存、cpu、io 等资源消耗比较高。相比 Logstash,Beats 所占系统的CPU和内存几乎可以忽略不计。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。

Elastic Stack 搭建
ELK Stack 通常包括 Elasticsearch、Logstash 和 Kibana。Filebeat 是一个轻量级的日志传输工具,用于将日志数据发送到 Logstash 或 Elasticsearch。
搭建步骤:
-
安装 Java
ELK 需要 Java 环境,建议安装 OpenJDK 8 或更高版本。
bash# 安装Java(ELK需要Java环境) sudo apt update sudo apt install openjdk-11-jdk -y # 验证Java安装 java -version -
安装 Elasticsearch
-
下载并安装 Elasticsearch。
bash# 导入Elasticsearch GPG密钥 wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - # 添加Elasticsearch仓库 echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list # 安装Elasticsearch sudo apt update sudo apt install elasticsearch -
配置 Elasticsearch。
yaml# 集群名称(所有节点必须一致,用于集群识别) cluster.name: my-elk-cluster # 节点名称(当前节点的唯一标识,建议与主机名一致) node.name: elk-node-1 # 数据存储路径(默认/var/lib/elasticsearch,建议单独挂载磁盘) path.data: /var/lib/elasticsearch # 日志存储路径 path.logs: /var/log/elasticsearch # 绑定网络地址(0.0.0.0允许所有IP访问,生产环境建议指定内网IP) network.host: 0.0.0.0 # 服务端口(默认9200,用于HTTP访问;9300为节点间通信端口) http.port: 9200 # 集群发现配置(单节点时填当前节点IP,多节点填所有候选主节点IP) discovery.seed_hosts: ["127.0.0.1"] # 初始主节点(首次启动时选举主节点的候选列表,单节点填当前node.name) cluster.initial_master_nodes: ["elk-node-1"] # 允许跨域访问(Kibana连接需要,生产环境可限制来源) http.cors.enabled: true http.cors.allow-origin: "*" # 安全配置(8.x默认开启HTTPS和密码认证,按需关闭或配置) xpack.security.enabled: false # 测试环境可关闭,生产环境建议开启并配置证书 xpack.security.http.ssl.enabled: false -
启动 Elasticsearch 服务。
bash# 启动服务并设置开机自启 systemctl daemon-reload systemctl start elasticsearch systemctl enable elasticsearch # 验证(返回节点信息即为成功) curl http://localhost:9200
-
-
安装 Logstash
-
下载并安装 Logstash。
bashyum install -y logstash # 基于已添加的elastic.repo -
配置 Logstash 管道(pipelines)来处理数据。
ruby# 输入:从Filebeat接收数据(默认端口5044,需与Filebeat输出一致) input { beats { port => 5044 # 监听端口,需开放防火墙 codec => "json" # 假设Filebeat发送JSON格式数据 } } # 过滤:清洗/转换数据(以Nginx日志为例) filter { # 仅处理Nginx相关日志(通过Filebeat的fields区分) if [fields][log_type] == "nginx" { # 解析Nginx日志(格式:$remote_addr [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent") grok { match => { "message" => '%{IP:client_ip} \[%{HTTPDATE:log_time}\] "%{WORD:method} %{URIPATH:uri}(?:\?%{DATA:query})? %{DATA:http_version}" %{NUMBER:status:int} %{NUMBER:bytes:int} "%{DATA:referer}" "%{DATA:user_agent}"' } add_field => { "service" => "nginx" } # 新增字段标记服务 } # 转换时间格式(适配Elasticsearch的@timestamp) date { match => [ "log_time", "dd/MMM/yyyy:HH:mm:ss Z" ] # 匹配Nginx的time_local格式 target => "@timestamp" # 覆盖默认时间字段 } } } # 输出:发送到Elasticsearch output { elasticsearch { hosts => ["http://localhost:9200"] # Elasticsearch地址 index => "logstash-%{[fields][log_type]}-%{+YYYY.MM.dd}" # 按日志类型和日期创建索引(如logstash-nginx-2024.11.06) # user => "elastic" # 若开启安全认证,需填写用户名密码 # password => "your_password" } # 同时输出到控制台(调试用,生产环境可注释) stdout { codec => rubydebug } } -
启动 Logstash 服务。
bash# 测试配置文件语法 /usr/share/logstash/bin/logstash --config.test_and_exit -f /etc/logstash/conf.d/filebeat-pipeline.conf # 启动服务并设置开机自启 systemctl start logstash systemctl enable logstash # 验证端口是否监听 netstat -tunlp | grep 5044 # 应显示Logstash监听5044端口
-
-
安装 Kibana
-
下载并安装 Kibana。
bashyum install -y kibana -
配置 Kibana,指定 Elasticsearch 的地址。
yaml# 服务绑定地址(0.0.0.0允许外部访问) server.host: "0.0.0.0" # Kibana端口(默认5601) server.port: 5601 # 连接的Elasticsearch地址(需与Elasticsearch配置一致) elasticsearch.hosts: ["http://localhost:9200"] # 索引模式时间字段(默认即可,后续可在界面配置) kibana.index: ".kibana" # 界面语言(设置为中文) i18n.locale: "zh-CN" # 若Elasticsearch开启认证,需配置用户名密码 # elasticsearch.username: "kibana_system" # elasticsearch.password: "your_password" -
启动 Kibana 服务。
bashsystemctl start kibana systemctl enable kibana # 验证(访问http://服务器IP:5601,出现Kibana界面即为成功)
-
-
安装 Filebeat
-
下载并安装 Filebeat。
bashyum install -y filebeat -
配置 Filebeat 以收集日志并发送到 Logstash 或 Elasticsearch。
yaml# 开启模块(可选,如nginx、mysql等预设模块,这里用自定义配置) filebeat.modules: - module: nginx access: enabled: false # 关闭预设模块,使用自定义采集 # 输入:定义需要采集的日志 filebeat.inputs: - type: log # 采集类型为日志文件 enabled: true # 启用该输入 paths: # 日志文件路径(支持通配符) - /var/log/nginx/access.log # Nginx访问日志 fields: # 自定义字段(用于Logstash过滤区分) log_type: nginx # 标记为nginx类型日志 fields_under_root: false # 字段嵌套在fields下(避免与日志原有字段冲突) ignore_older: 72h # 忽略72小时前的旧日志 close_inactive: 5m # 5分钟无更新则关闭文件句柄 # 输出:发送到Logstash(而非直接到Elasticsearch,便于Logstash处理) output.logstash: hosts: ["localhost:5044"] # Logstash地址和端口(需与Logstash input一致) # 若Logstash开启认证,可配置用户名密码 # username: "logstash_system" # password: "your_password" # 关闭Elasticsearch输出(默认可能开启,需注释或禁用) # output.elasticsearch: # hosts: ["localhost:9200"] # 日志配置(可选,默认即可) logging.level: info logging.to_files: true logging.files: path: /var/log/filebeat rotateeverybytes: 10485760 # 10MB轮转 keepfiles: 7 -
启动 Filebeat 服务。
bash# 测试配置文件 filebeat test config -c /etc/filebeat/filebeat.yml # 启动服务并设置开机自启 systemctl start filebeat systemctl enable filebeat # 验证(查看Filebeat日志,确认无错误) tail -f /var/log/filebeat/filebeat
-
数据流转验证与 Kibana 使用
-
生成测试日志
bash# 向Nginx访问日志写入测试数据(模拟用户访问) echo '192.168.1.1 [06/Nov/2024:10:00:00 +0800] "GET /index.html HTTP/1.1" 200 1024 "https://example.com" "Mozilla/5.0"' >> /var/log/nginx/access.log -
在 Kibana 中查看数据
- 访问 Kibana 界面(
http://服务器IP:5601),进入左侧菜单 "Management"→"Stack Management"→"索引模式"。 - 点击 "创建索引模式",输入索引匹配规则(如
logstash-*),点击 "下一步"。 - 选择时间字段(默认
@timestamp),点击 "创建索引模式"。 - 进入左侧菜单 "Analytics"→"Discover",即可看到 Filebeat 采集、Logstash 处理后的数据,包括解析出的
client_ip、method等字段。
- 访问 Kibana 界面(