任务
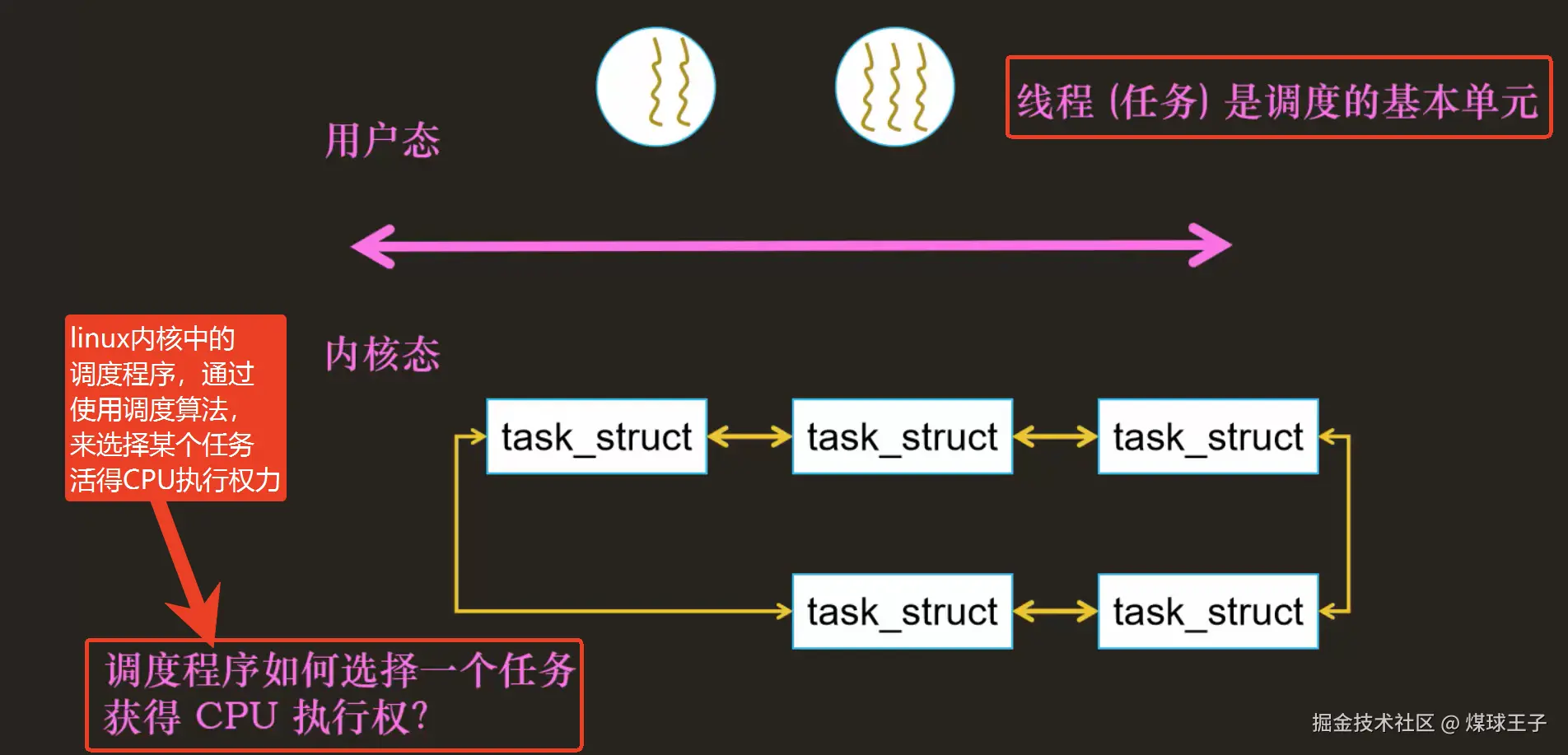
任务:Task , linux操作系统中,linux内核将 进程 、线程 ,统一用 task_struct 来抽象封装,我们叫: "任务_结构体", 也叫 "任务"
Linux内核的调度程序通过任务调度算法来决定哪个任务获得CPU执行权限
1. 任务的分类
任务(Task)分类------任务【进程】类型不同,那么调度算法肯定也是不一样
(1) 按场景划分
| 批处理任务(进程、线程) | 周期性任务(例如: 每天计算一次账户余额;每小时计算一下用户数据等) |
| 交互式任务(进程、线程) | 用户要在很短时间内得到你的进程响应(例如: 文本编辑器,计算器,web服务等) |
| 实时处理任务(进程、线程) | 任务必须在规定的时间内完成相应功能硬实时: 有绝对的截至时间(你的进程处理业务或任务时,你的进程不能超过规定的时间)软实时: 偶尔错过截至时间,可以容忍(你的进程处理业务或任务时, 偶尔超过了规定时间, 勉强接收) |
(2) 按密集型划分
几乎所有的进程 I/O 请求(如:读写磁盘或网络) 和 CPU计算 都是交替发生的。进而第二种分类如下
| 计算密集型任务(进程、线程) | 也叫CPU密集型任务啊,绝大多数时间花在CPU计算上了 |
| I/O密集型任务(进程、线程) | 在I/O等待上花费了绝大多数时间 |
2.Linux内核何时需要调度执行一个任务
第一: 当任务(进程),创建的时候,需要决定是继续执行父进程,还是调度执行子进程
第二: 在一个任务退出时(让出CPU时间片),需要做出调度决策,需要从所有处在TASK_RUNNING状态的任务队列中选择一个任务来执行
第三:当一个任务阻塞在I/O上,或者因为其他原因,让出CPU时间片了,必须调度另一个任务来执行
第四:在一个I/O中断发生时,必须做出调度决策 I/O中断来源于I/O设备,说明I/O的工作结束了,需要唤醒正在阻塞在这次I/O上的进程, 这时候,内核调度程序要决策是否调度这个被唤醒的任务(进程|线程)
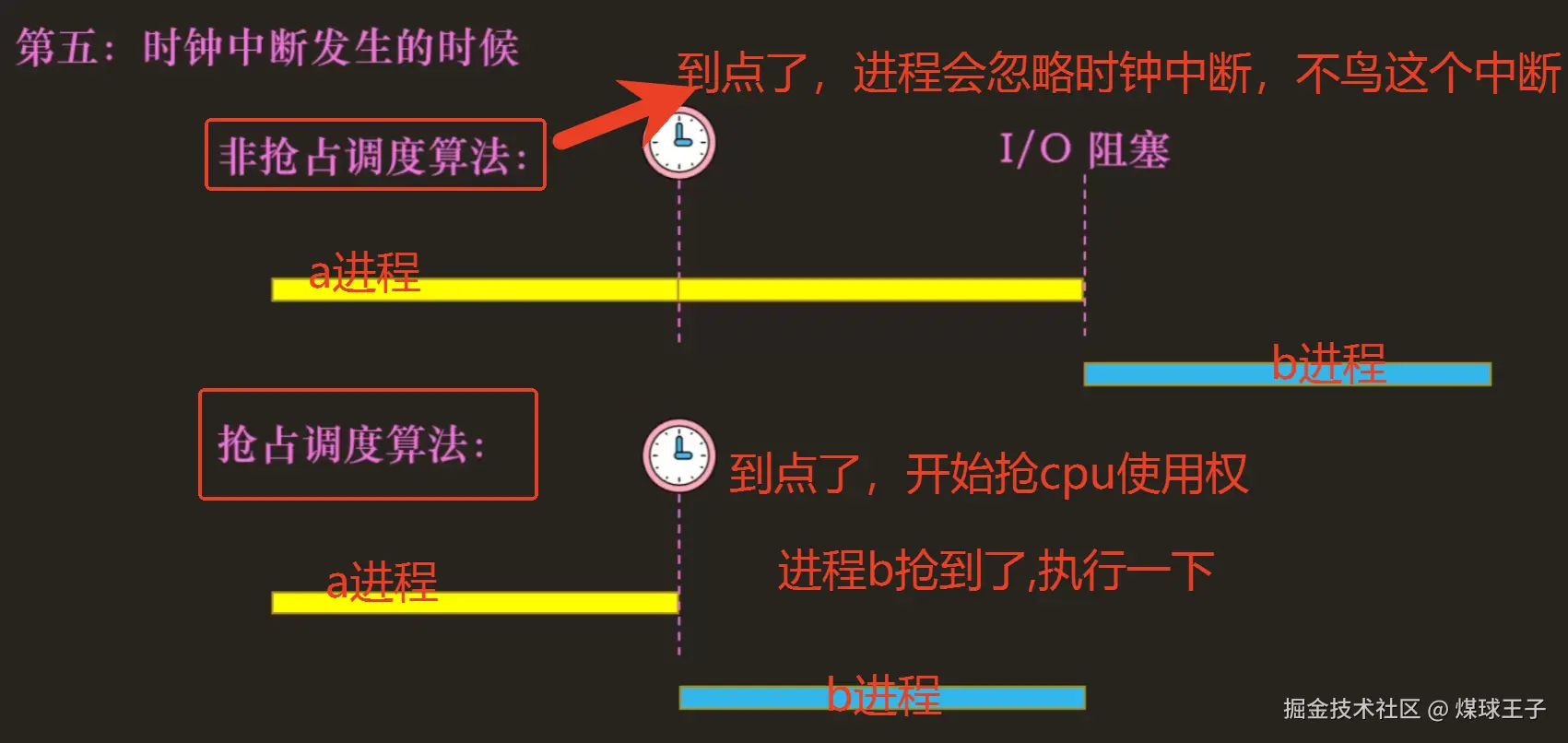
第五:时钟中断发生的时候
通用的任务调度算法(与具体系统无关)
调度指标: 响应时间,周转时间
根据不同的场景,进行合理的权衡:
(1)如果想要响应时间的话,那么就要以牺牲周转时间为代价
(2)如果想要周转时间的话,那么就要以牺牲响应时间为代价
鱼和熊掌不可兼得啊!!!!
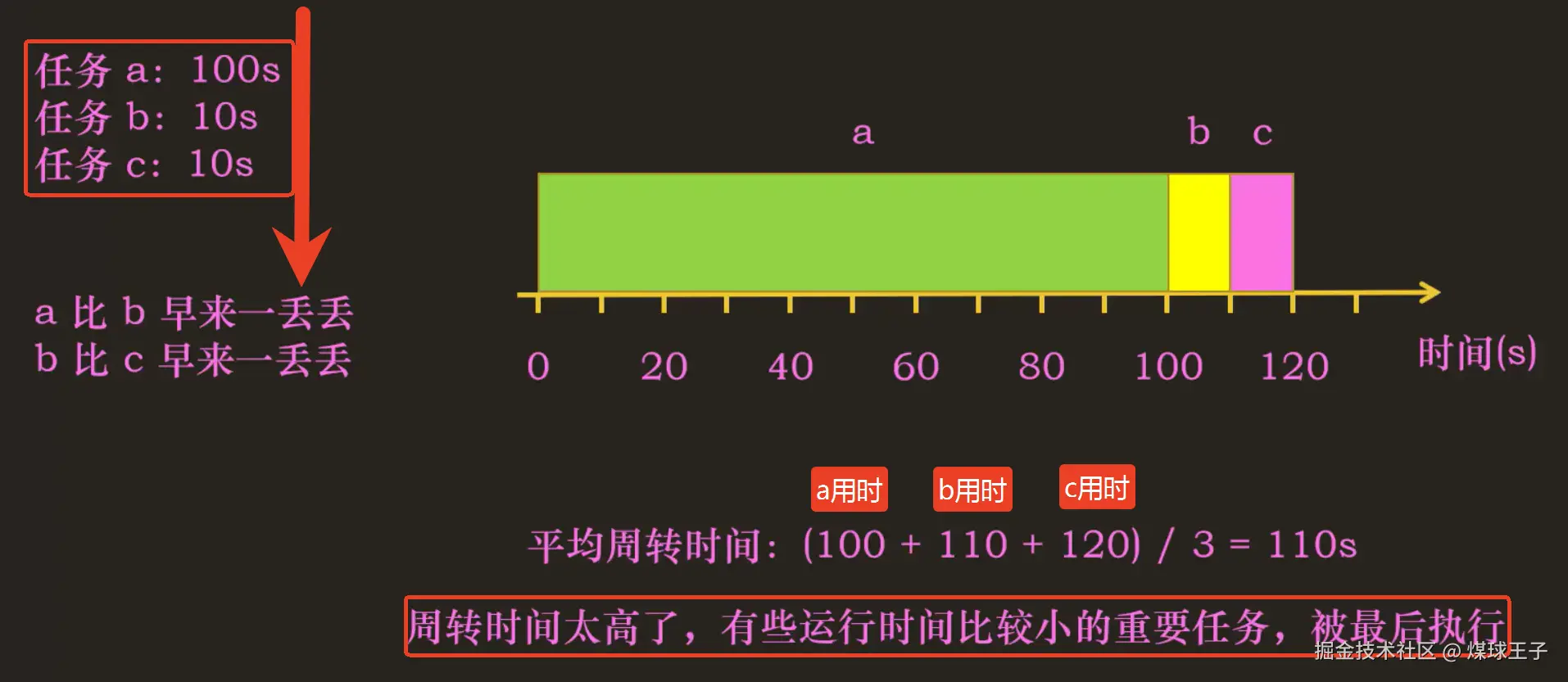
1.先进先出(FIFO)算法
先来先服务(First come First served 简称:FCFS), 简单,易于实现
2.最短任务优先(SJF)算法
最短任务优先(Shortest Job First------SJF)算法
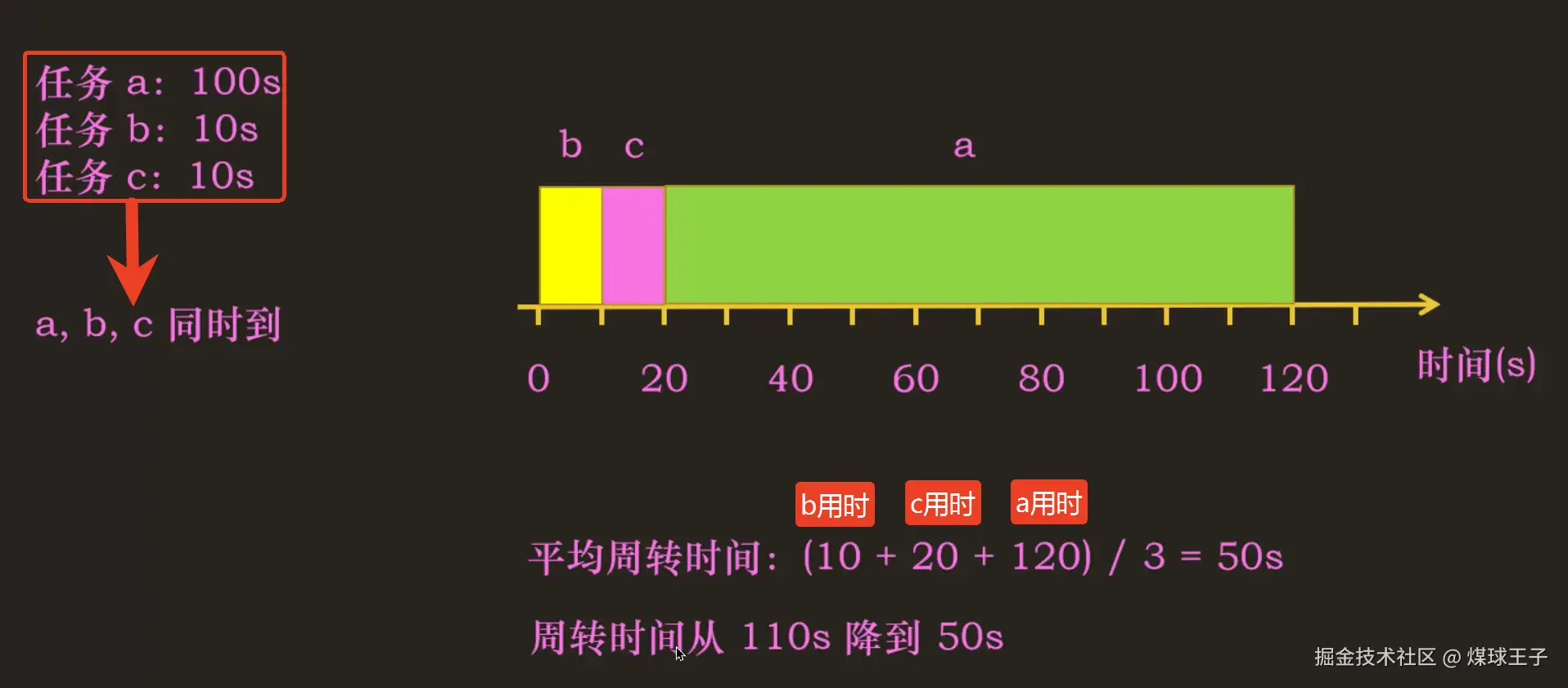
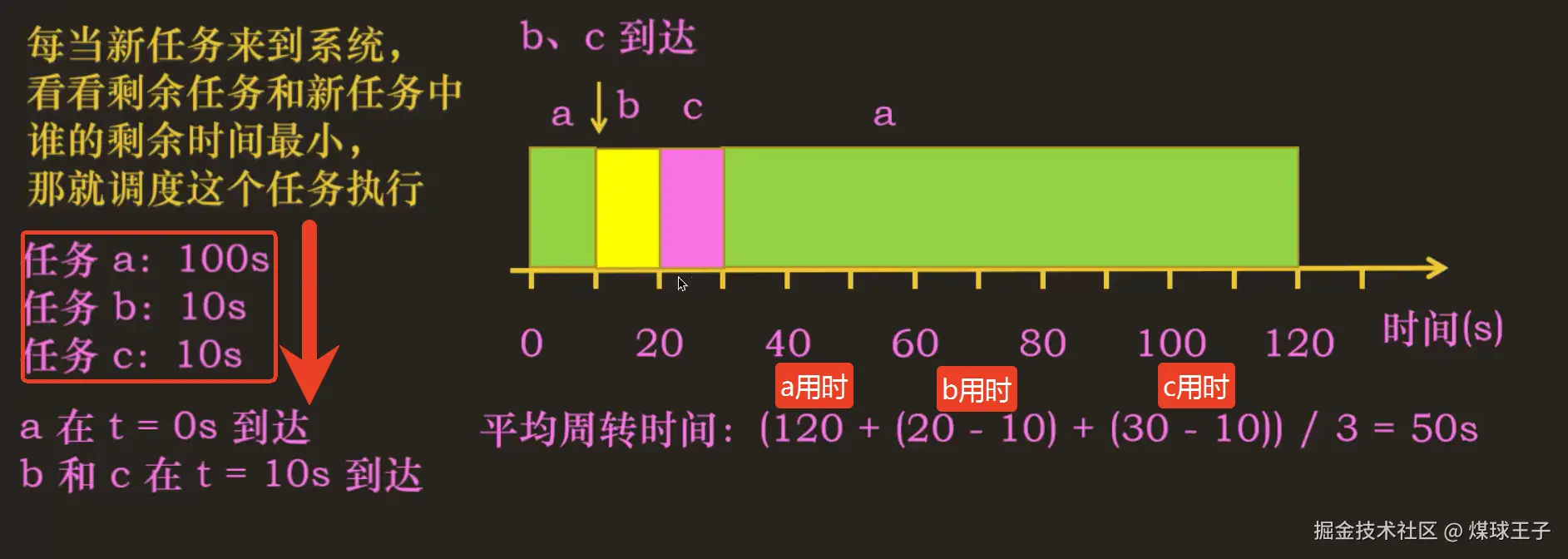
3.最短完成时间优先(STCF)算法
向SJF算法中添加"抢占cpu"功能------得到------最短完成时间优先(Shortest Time-to-Completion First---STCF)算法
市面上也有另一种称呼: 抢占式最短作业优先(Preemptive Shortest Job First---PSJF)算法
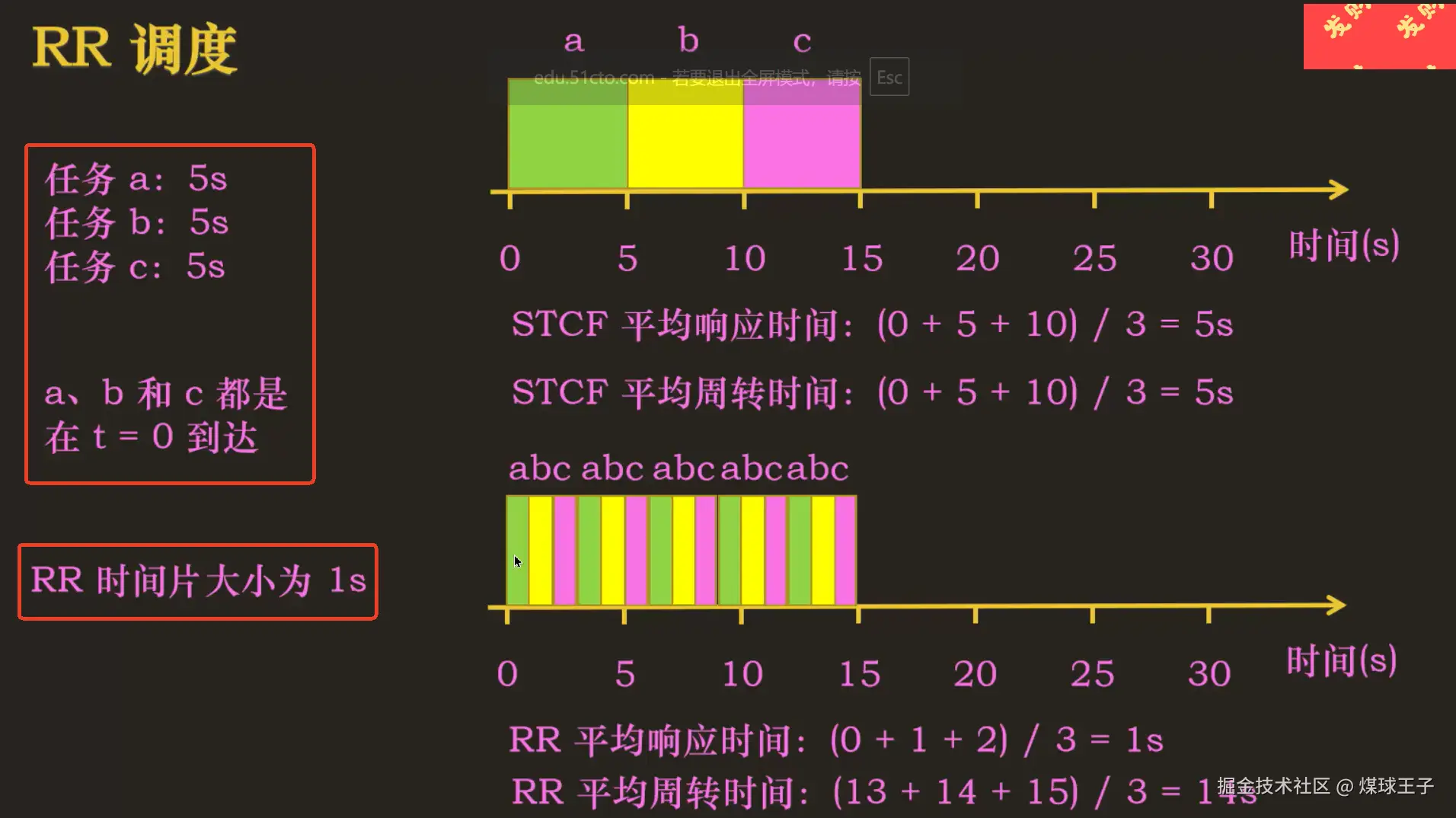
4.轮转(Round-Robin)调度算法
基本思想:在一个时间片内(如:0~10s内)运行一个任务,时间片结束,然后切换到下一个任务(而不是运行一个任务直到结束),这样反复执行,直到所有任务完成
Round-Robin 有时被称为时间切片, 时间片长度必须是 "操作系统---时钟中断" 周期的倍数。如果时钟中断时每10ms中断一次,则时间片可以是10ms、20ms、30ms等等
5.多级反馈队列(MLFQ)算法
周转时间 和 响应时间,二者不能兼得,我们可以折中,找平衡,于是有了MLFQ算法
多级反馈队列------Multi-level Feedback Queue; MLFQ通过任务历史运行数据预测任务运行时间
Linux操作系统任务调度实现
1.Linux内核中任务调度------数据结构
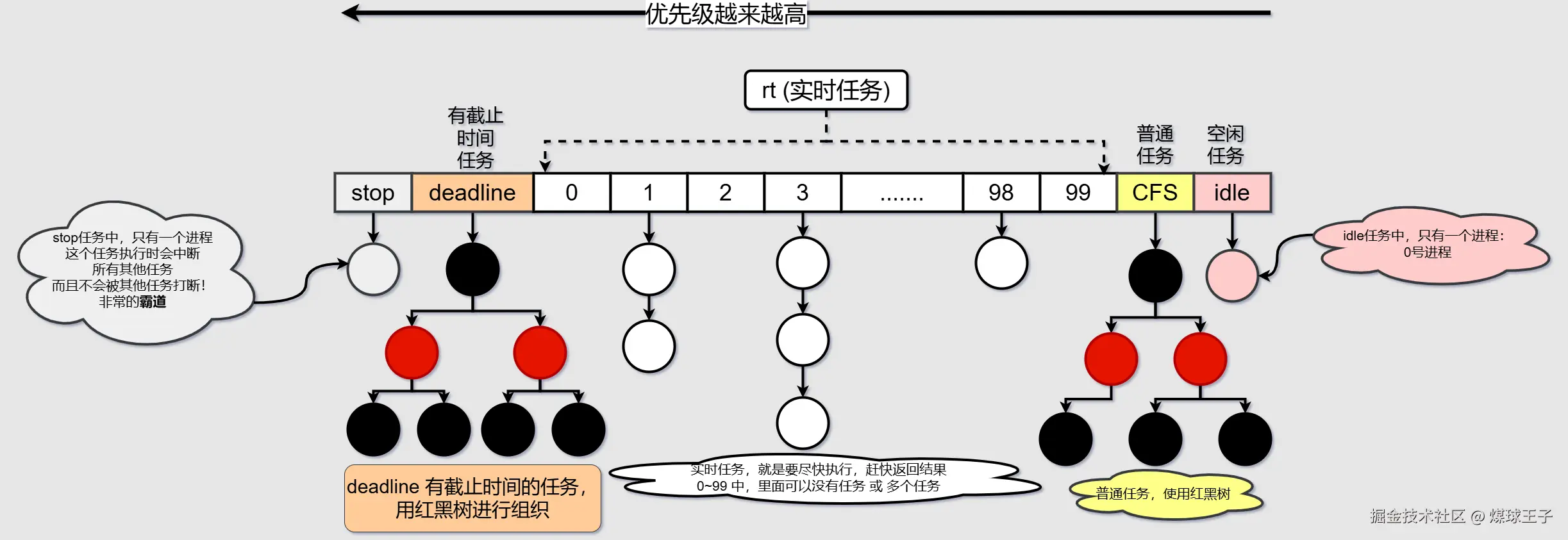
(1) 实时任务 分为0~99等级,从图中可知 0级 优先级最高
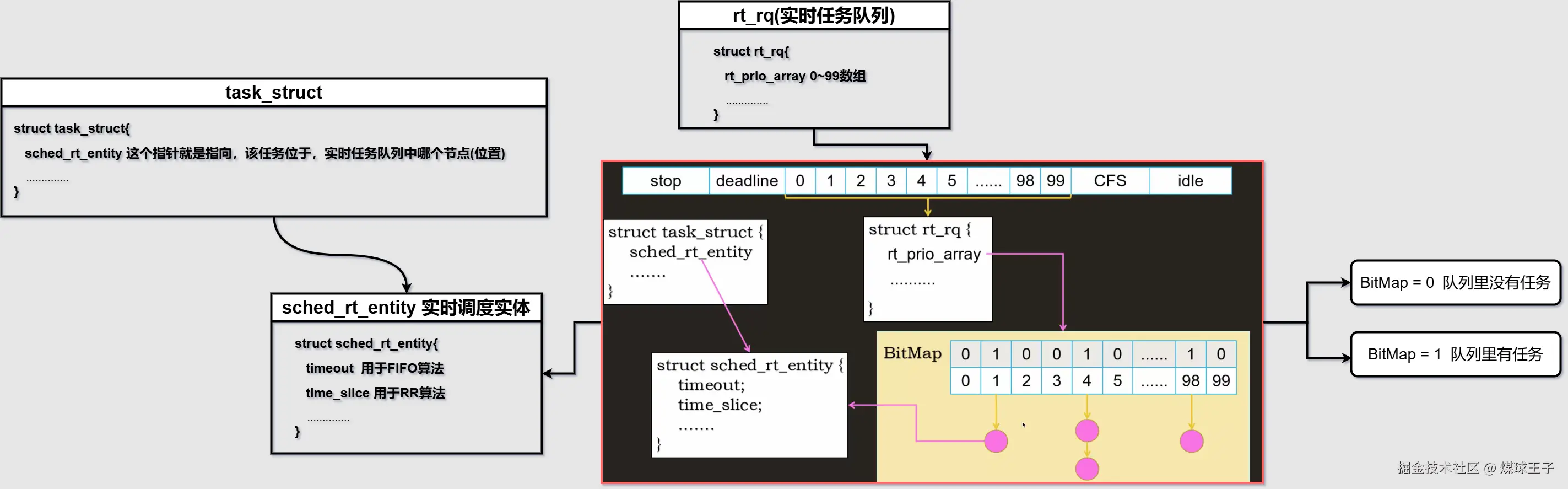
实时任务数据结构如下: 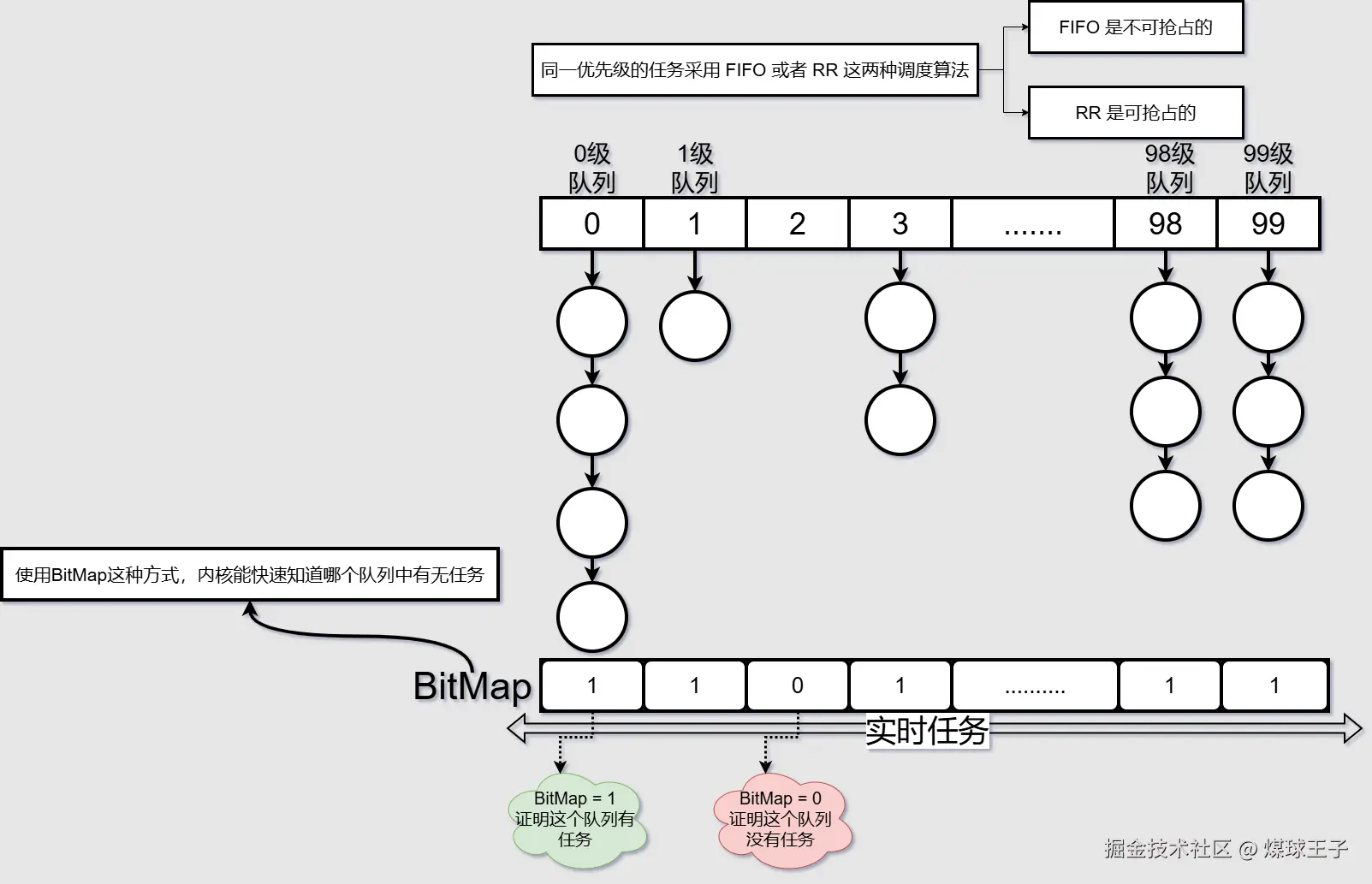
(2) 普通任务 CFS: Complete Fair Scheduler(翻译:完全公平调度)。 公平:给每个进程公平的CPU时间
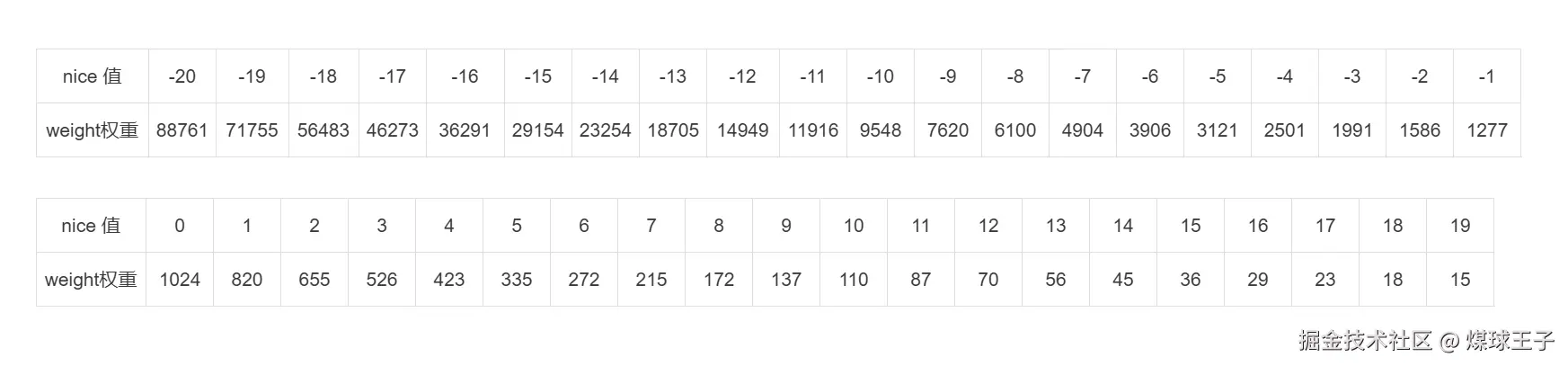
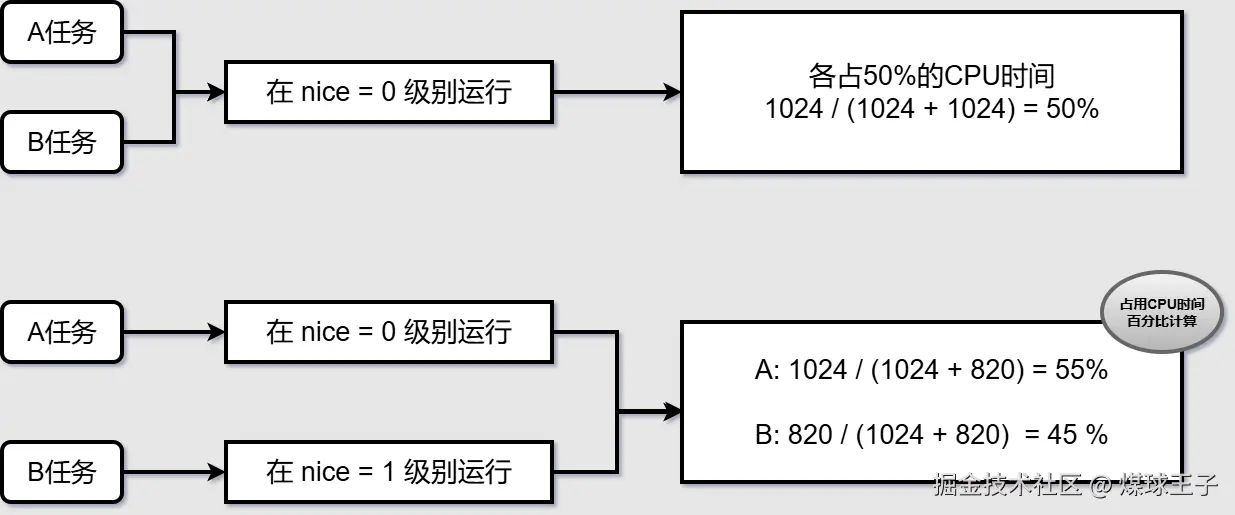
优先级: 100~139; 通过 nice 系统调用来设置优先级(nice值:-20 ~ 19), 每降低一个nice值,则多获得10%的CPU时间。 每升高一个nice值,则放弃10%的CPU时间。
优先级越高获得的cpu时间越多,优先级越低获得的cpu时间越短。  Linux内核中
Linux内核中 nice 值对应的权重,封装在 sched_prio_to_weight 数组中, 通过这个权重能计算出每个任务能公平占用CPU时间百分比,每降低一个nice值,则多获得10%的CPU时间。 每升高一个nice值,则放弃10%的CPU时间。 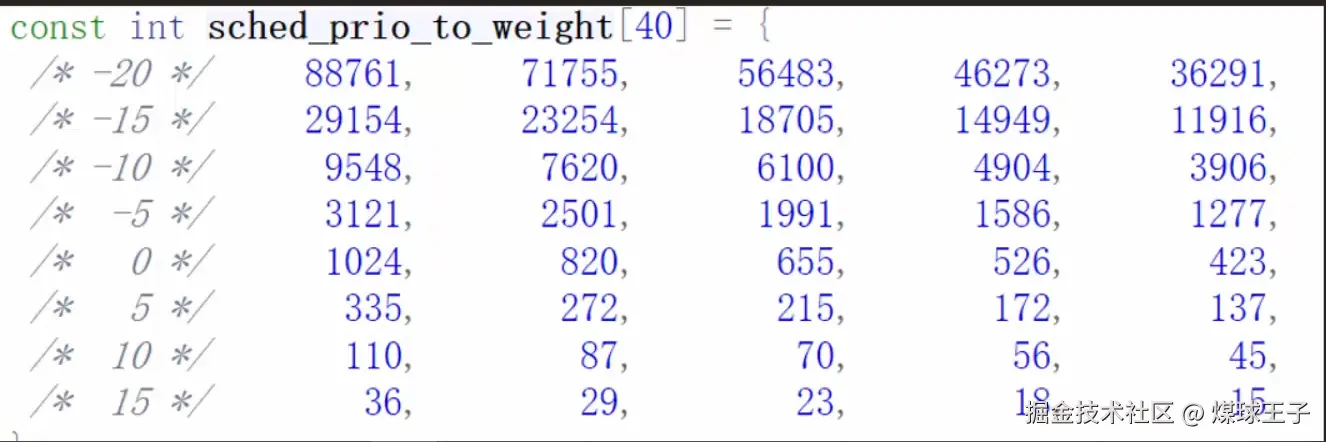
linux内核里维护了任务的两个时间:
每次任务被调度执行的真实时间 : delta_exec = now --- exec_start
(进程或线程被执行的真实时间 = 当前时间点 --- 任务刚开始执行的时间点)
每个任务被调度执行的虚拟运行时间 : vruntime += delta_exec * ( NICE_0_LOAD / curr->load.weight )
【虚拟运行时间 = 任务执行的真实时间 * (nice为0的权重1024 / 当前任务的权重 )】
每个任务都有 vruntime , 并且可能实时改变,为了保证公平,内核需要快速拿到 vruntime 值最小的哪个任务,去调度执行。
普通任务数据结构如下: 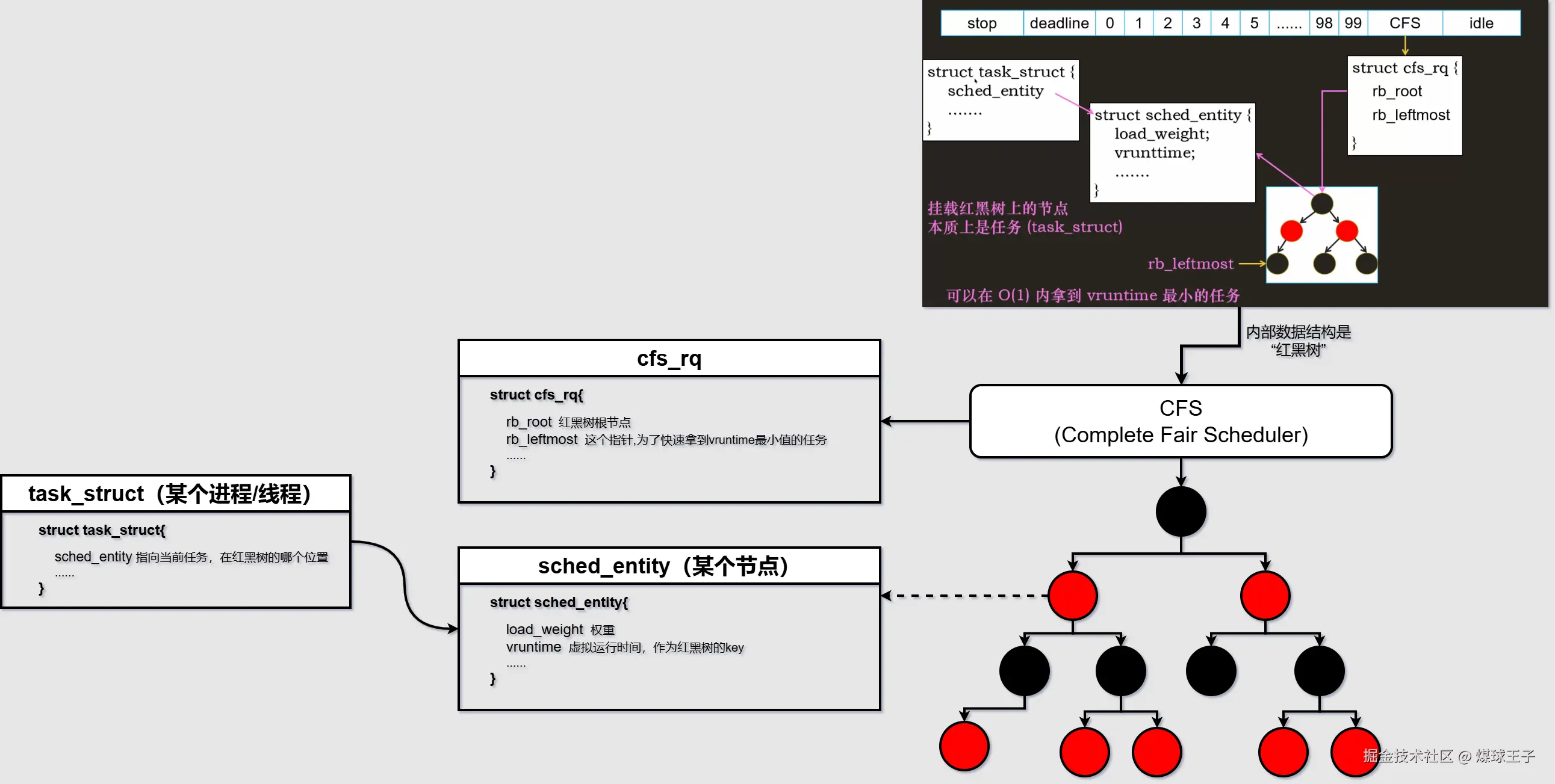
(3) deadline有截止时间的任务数据结构 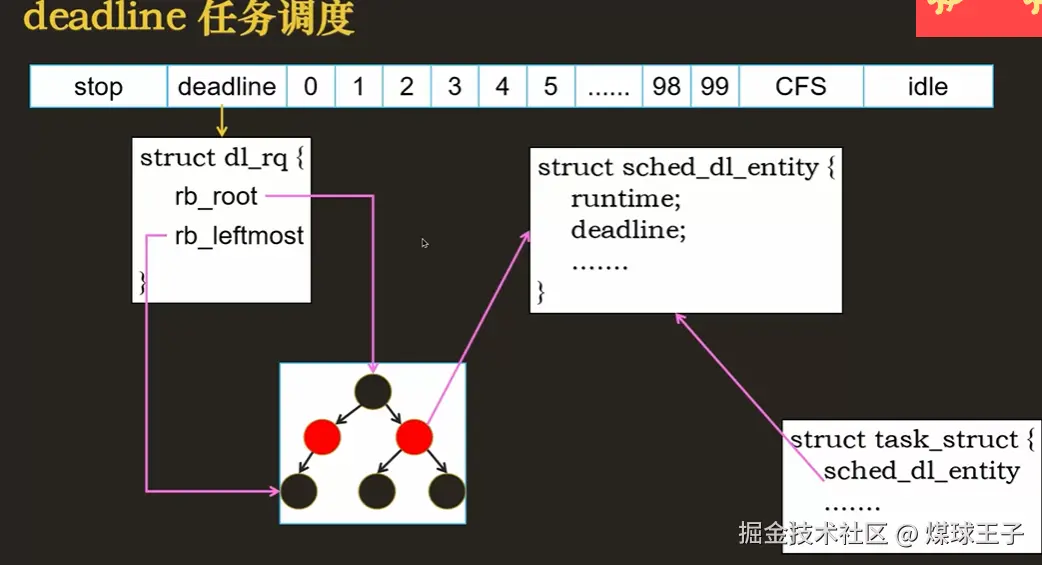
2.Per CPU多级调度队列------数据结构
arduino
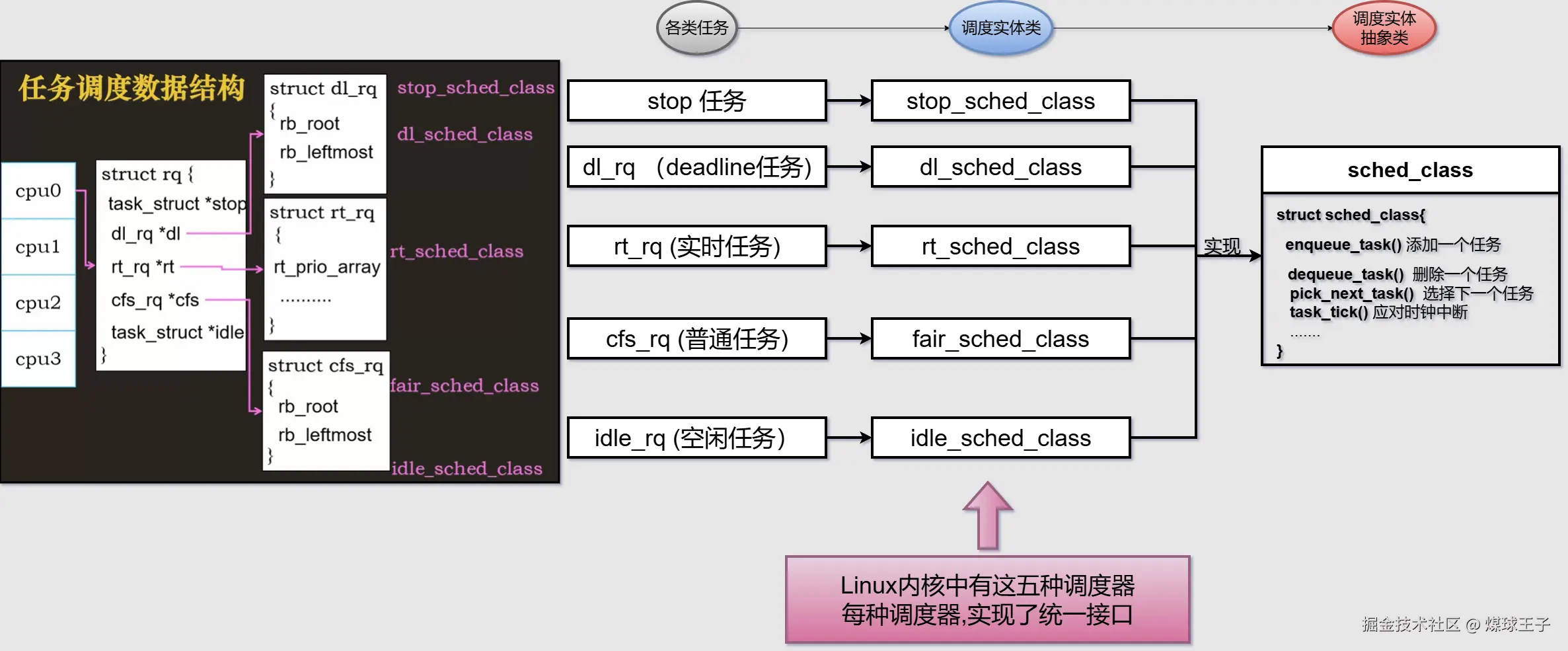
Per CPU多级调度队列,数据结构rq
struct rq{
struct dl_rq
struct rt_rq
struct cfs_rq
stop
idle
} 设备上可能有多个CPU, 每个CPU对应一个
设备上可能有多个CPU, 每个CPU对应一个 rq 调度队列  对上面的
对上面的 数据结构rq , 做增删改查动作,于是抽象了一个 sched_class
scss
struct sched_class{
enqueue_task() //添加一个任务
dequeue_task() //删除一个任务
pick_next_task() //选择(查)下一个任务
task_tick() //应对时钟中断
}
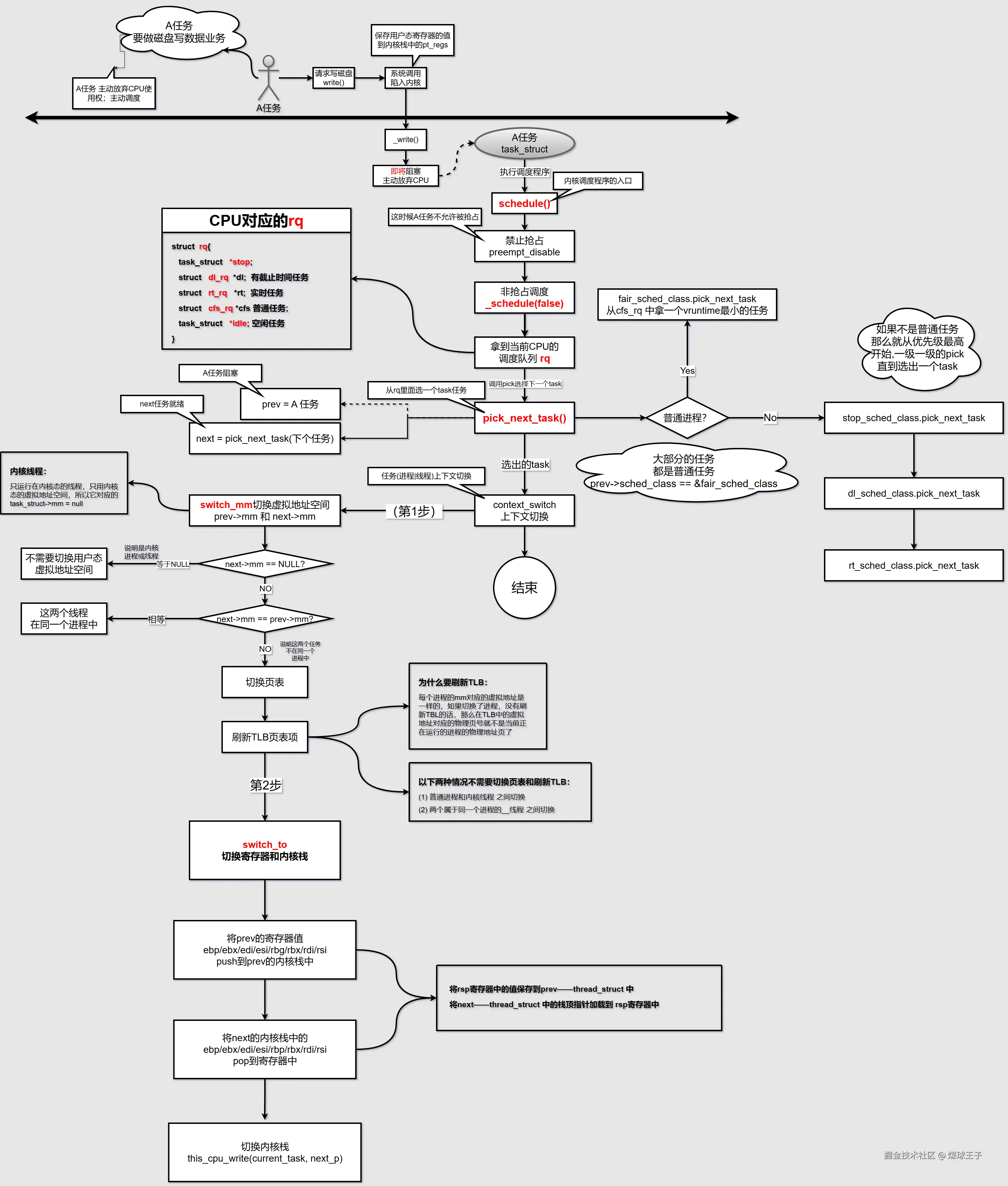
3.Linux内核基于上述数据结构做主动调度流程
任务主动放弃CPU使用权,主动调度粗略流程如下图
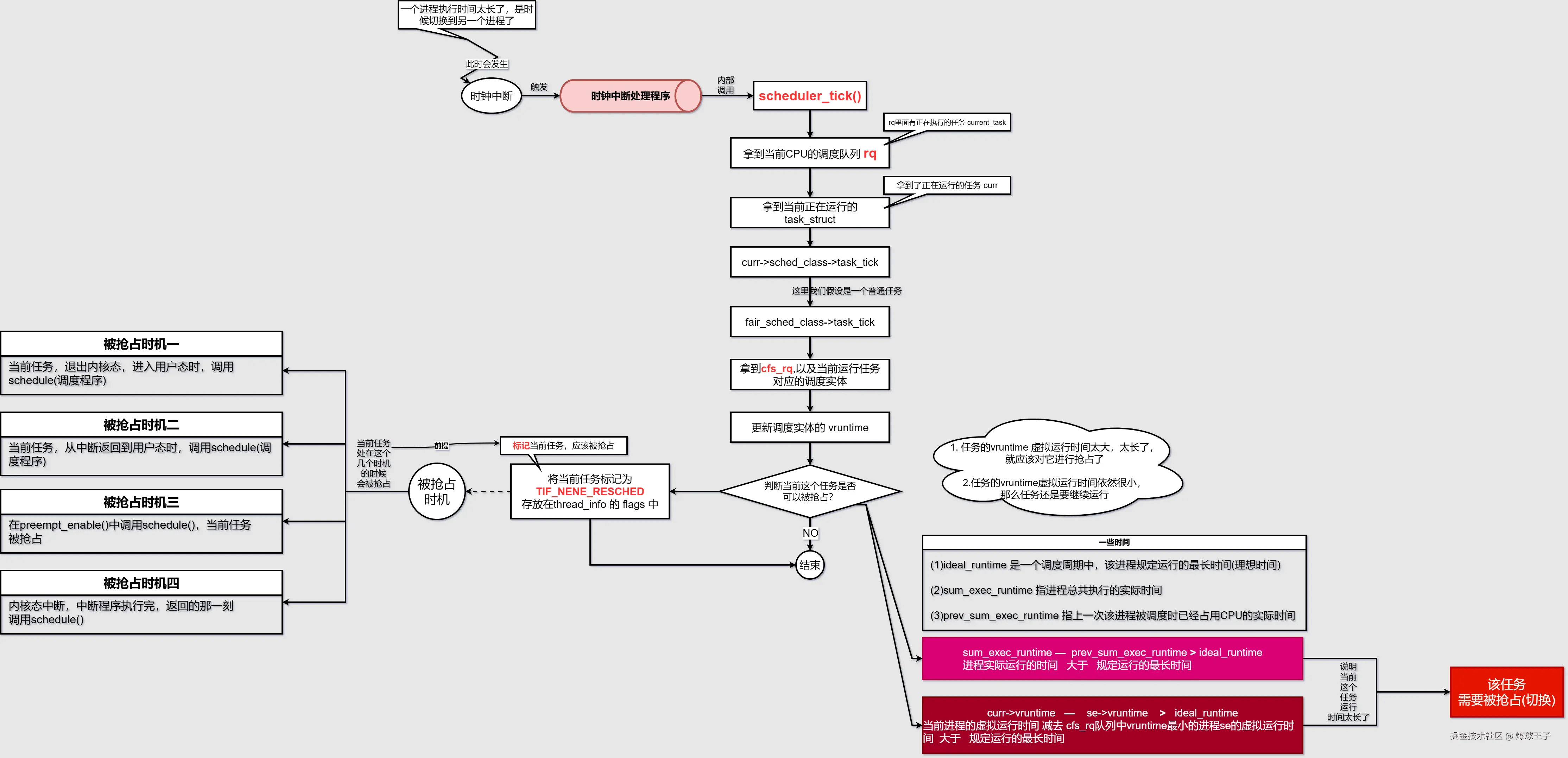
4.Linux内核基于上述数据结构做抢占调度流程
任务被抢占CPU使用权,被抢占调度粗略流程如下图