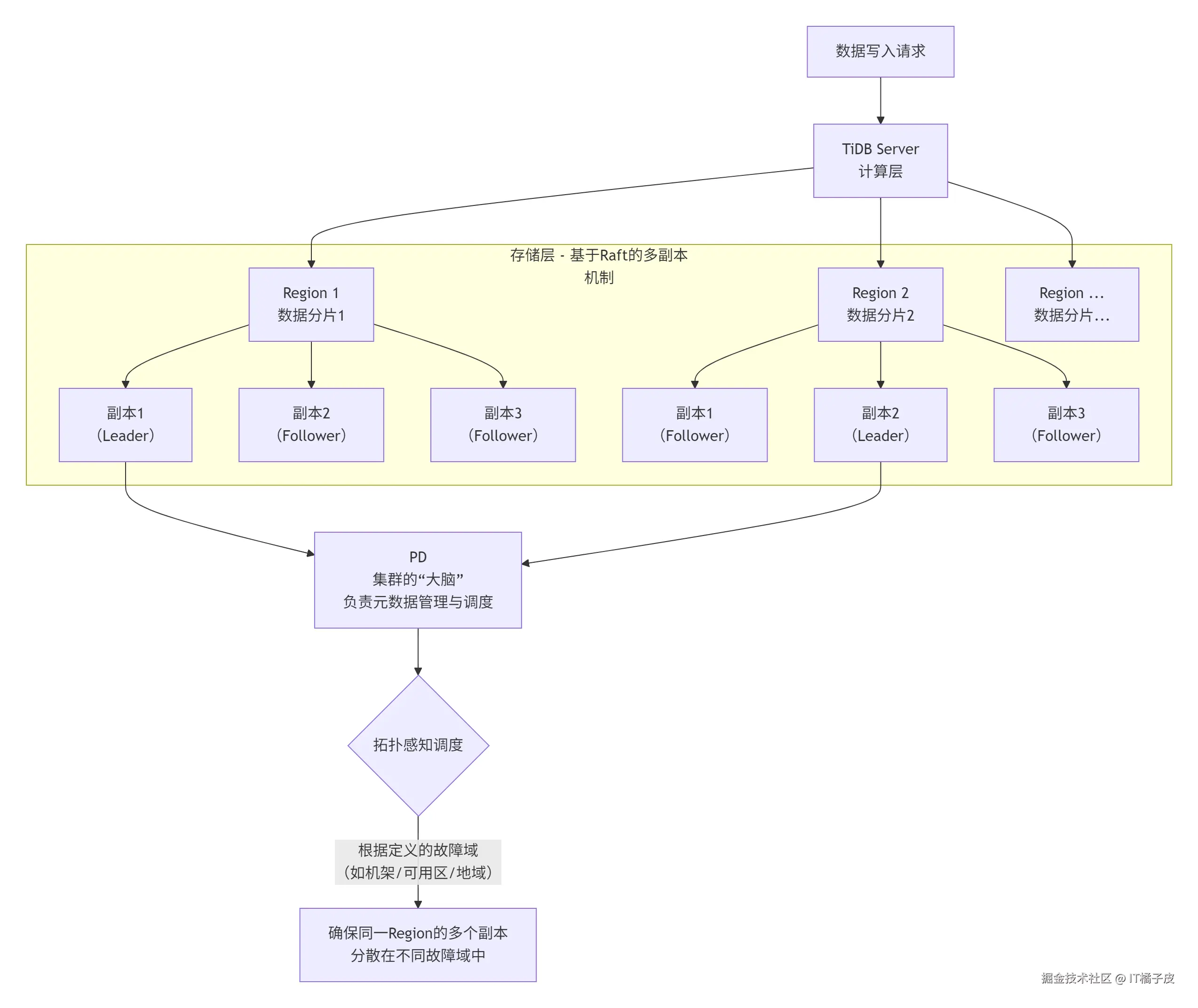
Region多副本容灾是现代分布式数据库(如 TiDB)的核心高可用特性。它通过将数据分成多个逻辑单元(Region),每个单元自动维护多个物理副本并分散在不同故障域,确保即使部分硬件或机房故障,数据库仍能安全运行。下面这张图可以帮你直观理解其数据分布和调度的核心机制。
💡 核心实现机制
图示流程展现了Region多副本容灾的核心。要实现它,需要以下几个关键机制协同工作:
-
副本放置策略与拓扑感知调度
这是实现容灾能力的基础。你需要为TiKV节点打上描述其物理位置的标签(label) ,例如
zone=z1, host=h1,并在PD(Placement Driver,集群大脑)配置对应的位置标签(location-labels) ,如["zone", "rack", "host"],以定义故障域的层级关系。PD调度器会根据这些标签,尽可能将同一个Region的多个副本分散到不同的、最隔离的故障域 中。你还可以通过设置强制隔离级别(isolation-level) ,例如isolation-level = "zone",来要求PD必须保证同一个Region的副本分布于不同的可用区(AZ),否则宁愿不调度,从而满足最严格的容灾需求。 -
自动故障切换与数据恢复
每个Region的副本组成一个Raft组 ,通过Raft协议在副本间同步数据并选举一个Leader(负责读写)。当少数副本故障时,存活的副本会通过Raft协议自动选举出新Leader,保证服务持续可用。PD会检测到副本缺失,并在健康的节点上自动补足副本,维持设定的副本数。这个过程对应用基本透明。
-
灵活的数据分布与流量调度
你可以利用Placement Rules in SQL 功能,通过SQL语句为特定数据库或表指定数据(包括副本和Leader)的放置策略。例如,你可以将核心业务表的主副本(Leader)强制固定在某个地域,确保关键业务的读写性能。这实现了数据分布与流量路由的精细控制,支持同城双活、两地三中心等多种部署模式。
🏗️ 常见部署架构与容灾能力
基于上述机制,可以构建不同容灾等级的架构:
| 架构模式 | 描述 | 容灾能力与特点 | 典型配置 |
|---|---|---|---|
| 同城三中心 (3AZ) | 三个副本部署在同一城市的三个可用区。 | RPO=0 ,可容忍单个AZ故障。网络延迟低,性能影响小,是最常规且运维成本较低的高可用方案。 | 3副本,max-replicas=3 |
| 两地三中心 (2-2-1) | 五个副本跨两个地域部署:生产地域两个AZ各2个有投票权副本,第三个地域1个投票副本。 | RPO=0 ,可容忍单个AZ故障或单个地域故障。通过配置优先级,确保主流量集中在生产地域,是金融级容灾的典型方案。 | 5副本,max-replicas=5,配合Placement Rules指定主备地域。 |
| 主备集群 (1:1) | 两个独立的TiDB集群,主集群通过TiCDC工具异步将数据变更同步到备集群。 | RPO <10秒 。主集群故障后,需手动或自动切换至备集群。部署相对简单,成本适中,适用于RPO要求非0的重要系统。 | 主备集群各3副本,通过TiCDC同步。 |
⚠️ 关键考量与最佳实践
- 副本数量与成本权衡:副本数越多,容灾能力越强,但存储成本和网络开销也越大。需根据业务重要性进行权衡。通常3副本可应对机架或单AZ故障,5副本用于地域级容灾。
- 网络延迟至关重要 :对于要求RPO=0 的多副本方案,副本间需同步复制 ,网络延迟必须低且稳定(通常要求 <30ms)。过高的延迟会严重影响写性能。
- 定期进行容灾演练:容灾能力需要验证。应定期模拟AZ或节点故障,观察故障转移过程是否符合预期,并熟悉手动切换流程,确保灾难发生时能快速响应。
希望这些解释能帮助你深入理解Region多副本容灾。如果你对特定部署架构(如两地三中心)的具体配置步骤或与其他容灾方案的结合应用有更深入的兴趣,我们可以继续探讨。