TL;DR
- 场景:电商/IoT/监控等需要分钟级指标刷新,同时保留历史明细做 OLAP。
- 结论:TimedJsonStreamParser + 时间分区维度 + 微批构建,稳态 3--5 分钟刷新取决于资源与合并策略。
- 产出:Kafka→Kylin Streaming Cube 全流程、REST/Crontab 调度与 SQL 示例,含常见坑位与修复。

版本矩阵
| 状态 | 说明 |
|---|---|
| ✅ | TimedJsonStreamParser 解析三段式 JSON(dimensions/metrics/timestamp)按示例可用;嵌套字段建议采集端扁平化或自定义解析器。 |
| ✅ | 时间分区列(如 minute_start)作为维度并在 RowKeys 前置,可显著缩小扫描范围。 |
| ✅ | REST .../cubes/{cube}/build2 + crontab 触发微批构建流程可用;注意并发与段合并策略。 |
| ✅ | Aggregation Groups/RowKeys 配置与离线 Cube 基本一致,但对时间维度顺序更敏感。 |
| ✅ | 基于示例的 Kafka 主题创建/采样/消费链路跑通;命令行与参数按示例工作。 |

基本概念
实时数据更新在现代数据分析领域是一种普遍且日益增长的需求,特别是在金融交易监控、物联网设备管理和电商实时推荐等场景中。企业需要快速捕捉和分析数据趋势,才能在瞬息万变的市场环境中做出及时、正确的决策。
Apache Kylin V1.6版本针对这一需求发布了重要的StreamingCubing功能扩展。该功能采用创新的架构设计,通过整合Hadoop生态系统的处理能力来实时消费Kafka消息队列中的数据。具体实现方式包括:
- 建立专用的Kafka消费者组
- 实现增量数据分区处理
- 采用微批次(mini-batch)计算模式
这种架构能够构建出支持分钟级(通常3-5分钟)更新的Cube,相比传统的每日批处理模式有了质的飞跃。例如,在零售行业,商家可以实时监控各门店的销售数据变化,及时调整促销策略;在电信行业,运营商可以即时分析网络流量异常,快速定位故障点。
该功能不仅满足了企业对数据时效性的需求,还保持了Kylin原有的高性能OLAP查询能力,实现了实时分析与历史数据分析的无缝结合。
实现步骤
步骤:项目 => 定义数据源(Kafka)=> 定义Model => 定义Cube => Build Cube => 作业调度(频率高)
生成数据
从Kafka消费消息时,为确保数据分析的一致性和处理效率,每条消息需要遵循以下标准化数据结构要求:
-
维度信息:
- 包含业务实体的分类属性,用于数据分组和筛选
- 示例:产品类别、地区代码、用户等级等
- 建议采用键值对形式,如:"product_category":"electronics"
-
度量信息:
- 包含可量化的业务指标数值
- 示例:销售额、点击量、库存数量等
- 建议格式:"sales_amount":1250.50
-
业务时间戳:
- 记录业务实际发生的时间点
- 必须采用ISO 8601标准格式:YYYY-MM-DDTHH:MM:SSZ
- 示例:"biz_timestamp":"2023-05-15T14:30:00Z"
消息体应采用统一JSON结构,例如:
json
{
"dimensions": {
"region": "APAC",
"product_line": "smartphone"
},
"metrics": {
"order_count": 42,
"revenue": 12500.00
},
"timestamp": "2023-05-15T09:15:30Z"
}当前系统默认配置的分析器为org.apache.kylin.source.kafka.TimedJsonStreamParser,该解析器能够:
- 自动识别JSON消息体中的三个标准部分
- 将维度信息映射到OLAP模型的维度表
- 将度量信息聚合到事实表
- 根据业务时间戳进行时间分区处理
使用建议:
- 生产环境应确保所有生产者使用相同的消息模板
- 开发阶段可以使用Schema Registry进行消息结构验证
- 对于特殊业务场景,可通过继承TimedJsonStreamParser实现自定义解析逻辑
典型应用场景:
- 电商交易分析:维度包含商品类目、支付方式;度量包含交易金额、优惠金额
- 用户行为分析:维度包含用户属性、访问渠道;度量包含停留时长、点击次数
- IoT设备监控:维度包含设备类型、地理位置;度量包含温度读数、运行时长
创建数据
shell
# 创建名为kylin_streaming_topic的topic
kafka-topics.sh --create --zookeeper h121.wzk.icu:2181 --replication-factor 1 --partitions 1 --topic kylin_streaming_topic1执行结果如下图所示: 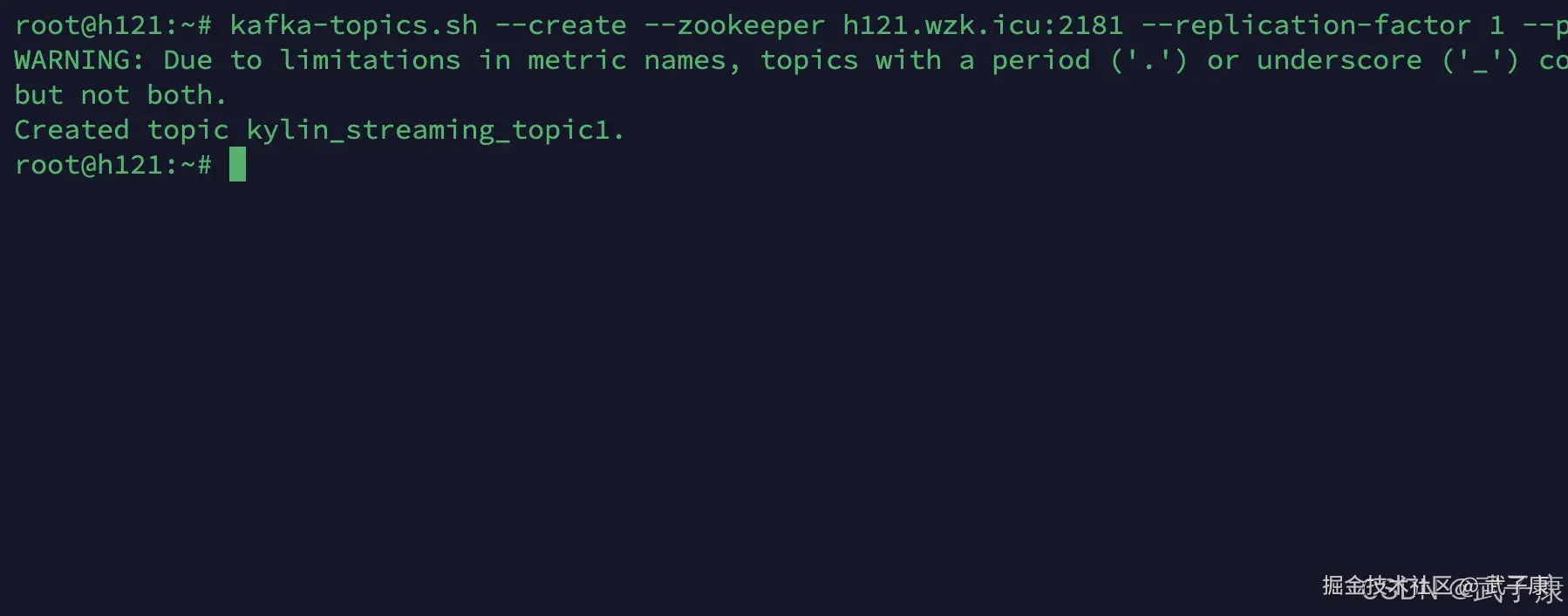
数据采样
设置采样器
shell
kylin.sh org.apache.kylin.source.kafka.util.KafkaSampleProducer --topic kylin_streaming_topic1 --broker h121.wzk.icu:9092发了一大批数据,如下图所示: 
检查数据
检查数据是否发送成功:
shell
kafka-console-consumer.sh --bootstrap-server h121.wzk.icu:9092 --topic kylin_streaming_topic1 --from-beginning数据样例如下所示:
json
{"country":"INDIA","amount":44.47793969871658,"qty":3,"currency":"USD","order_time":1723358207350,"category":"TOY","device":"iOS","user":{"gender":"Female","id":"1c54f68e-f89a-b5d2-f802-45b60ffccf60","first_name":"unknown","age":15}}
{"country":"AUSTRALIA","amount":64.86505054935878,"qty":9,"currency":"USD","order_time":1723358207361,"category":"TOY","device":"iOS","user":{"gender":"Female","id":"de11d872-e843-19c9-6b35-9263f1d1a2a1","first_name":"unknown","age":19}}
{"country":"CANADA","amount":90.1591854077722,"qty":4,"currency":"USD","order_time":1723358207371,"category":"Other","device":"Andriod","user":{"gender":"Male","id":"4387ee8b-c8c1-1df4-f2ed-c4541cb97621","first_name":"unknown","age":26}}
{"country":"INDIA","amount":59.17956535472526,"qty":2,"currency":"USD","order_time":1723358207381,"category":"TOY","device":"Andriod","user":{"gender":"Female","id":"d8ded433-8f1c-c6e7-99b2-854695935764","first_name":"unknown","age":11}}定义数据源
数据源选择Add Streaming Table:  点击之后,把刚才的JSON填写进去,就可以解析出来:
点击之后,把刚才的JSON填写进去,就可以解析出来: 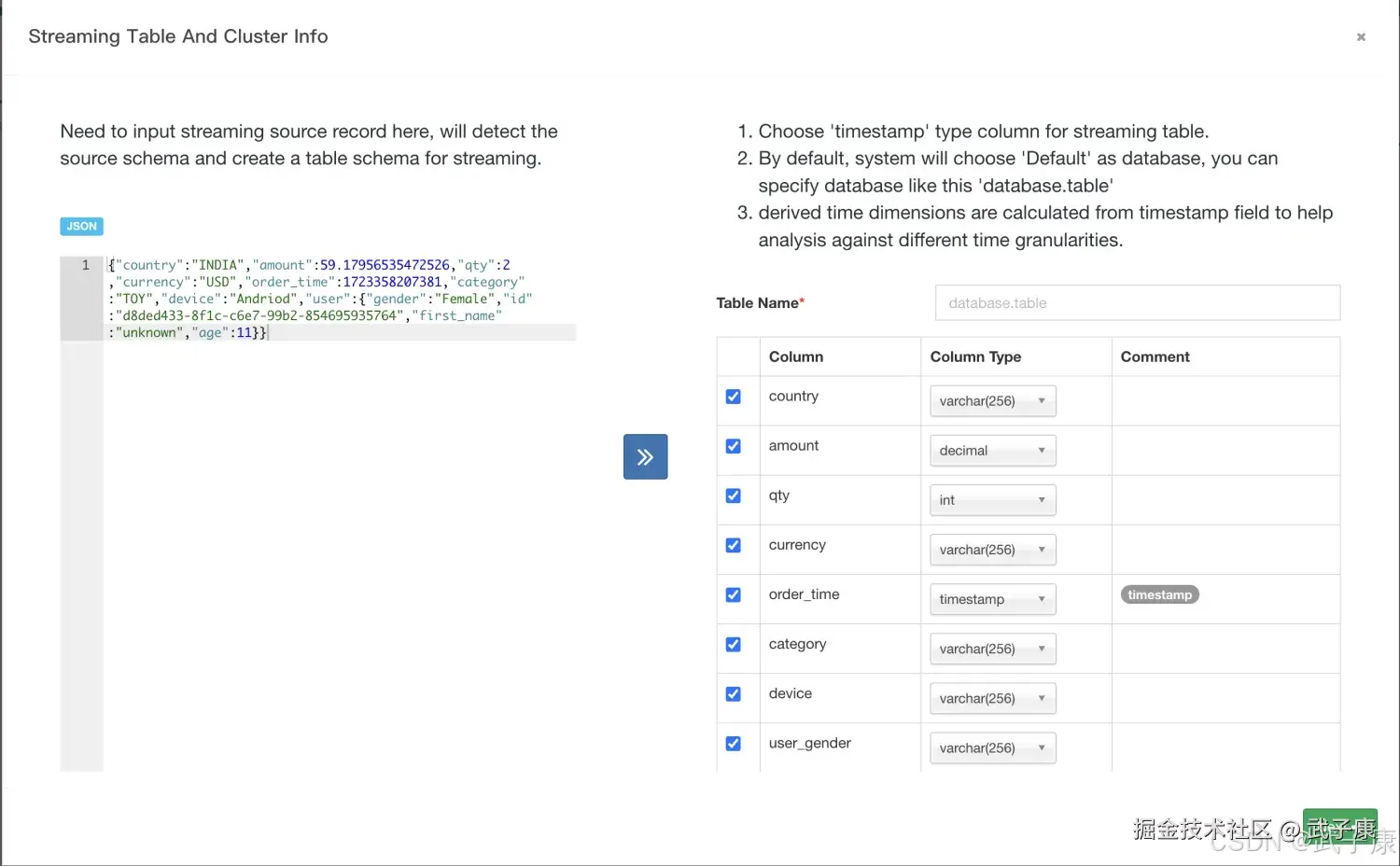 定义Kafka信息,填写对应的内容,如下图所示:
定义Kafka信息,填写对应的内容,如下图所示: 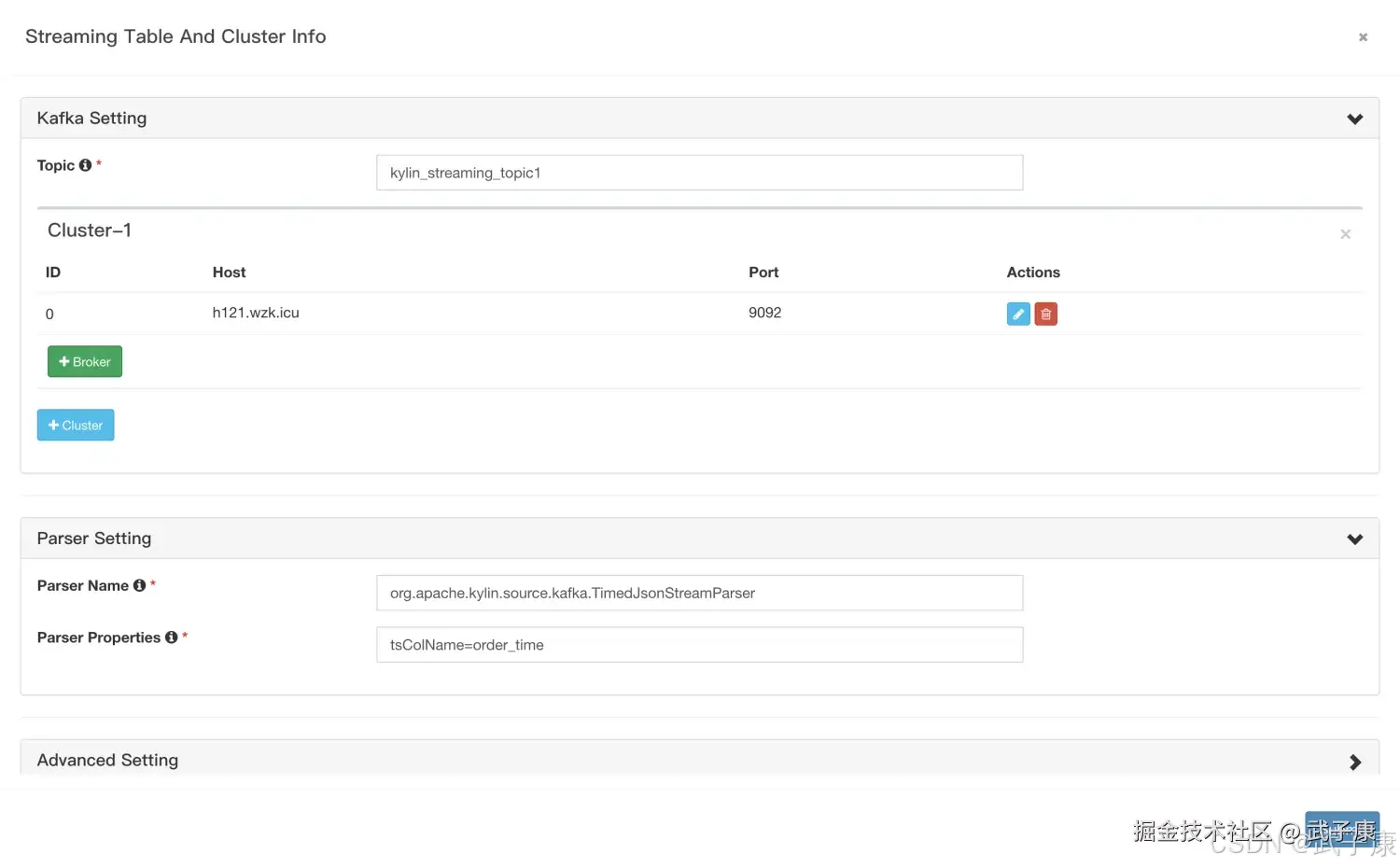 可以看到我们刚才添加的内容如下图所示:
可以看到我们刚才添加的内容如下图所示: 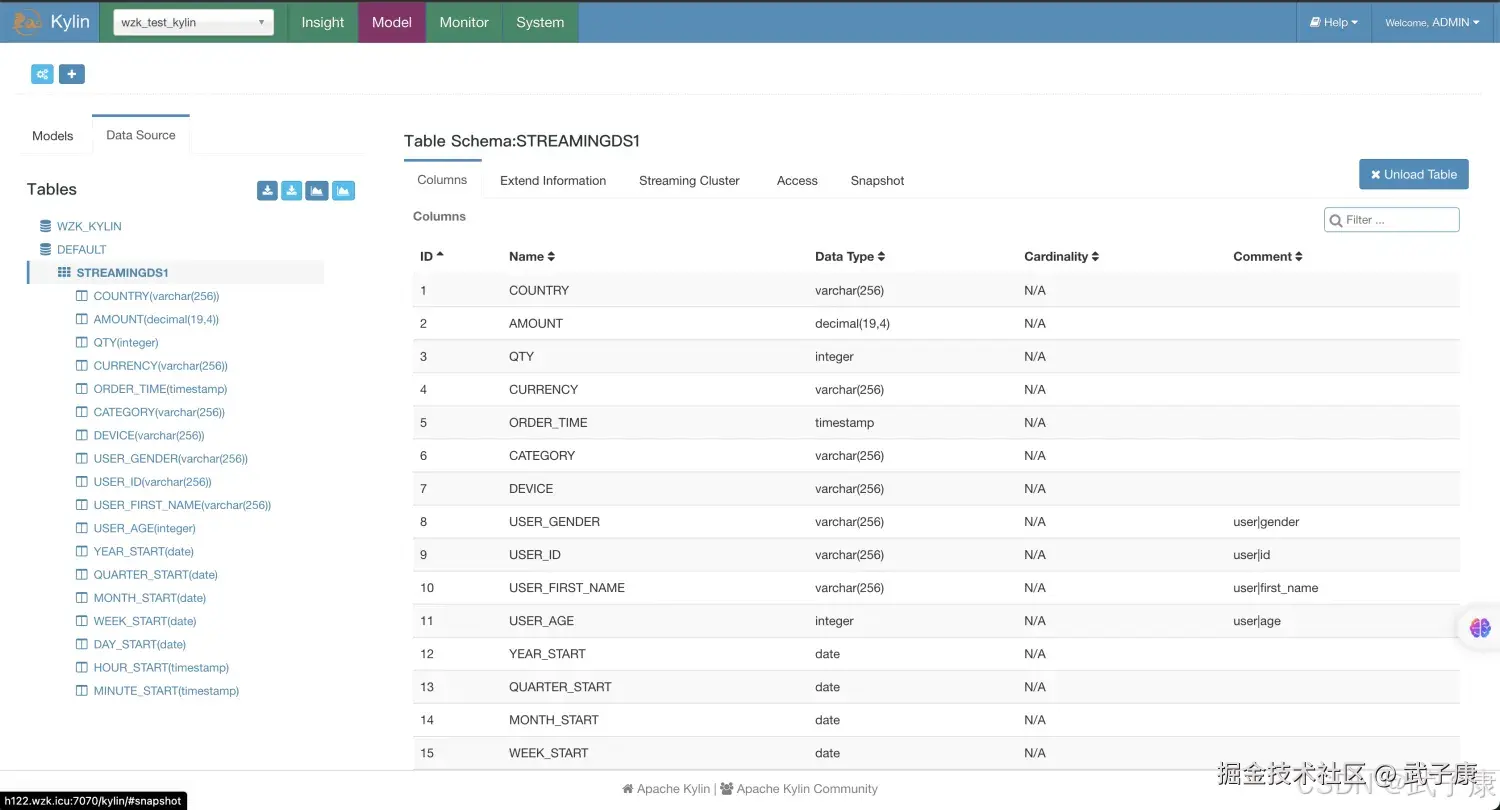
定义Model
新建Model,如下图所示,名称随意: 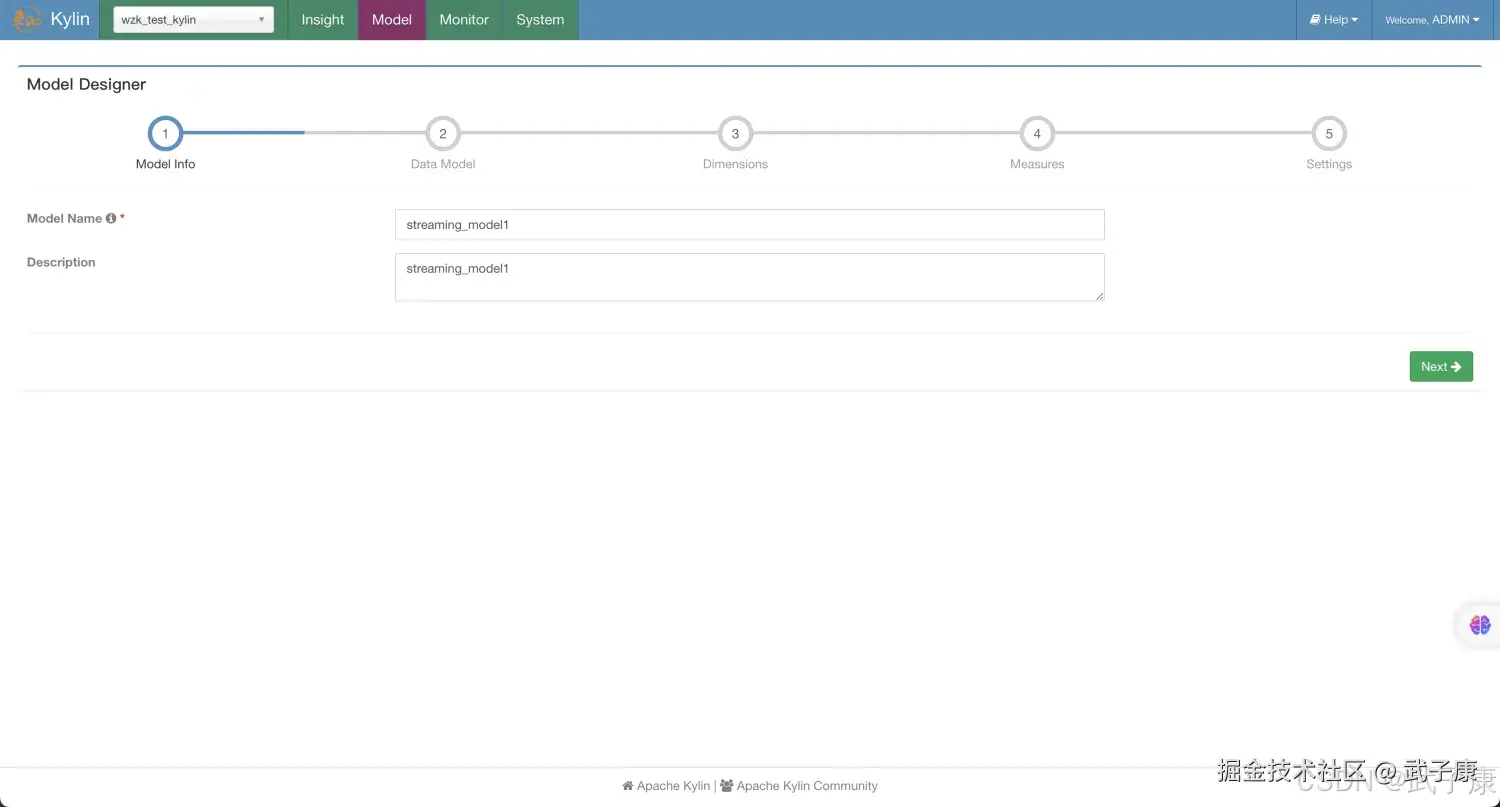 原则DataModel,如下图所示:
原则DataModel,如下图所示: 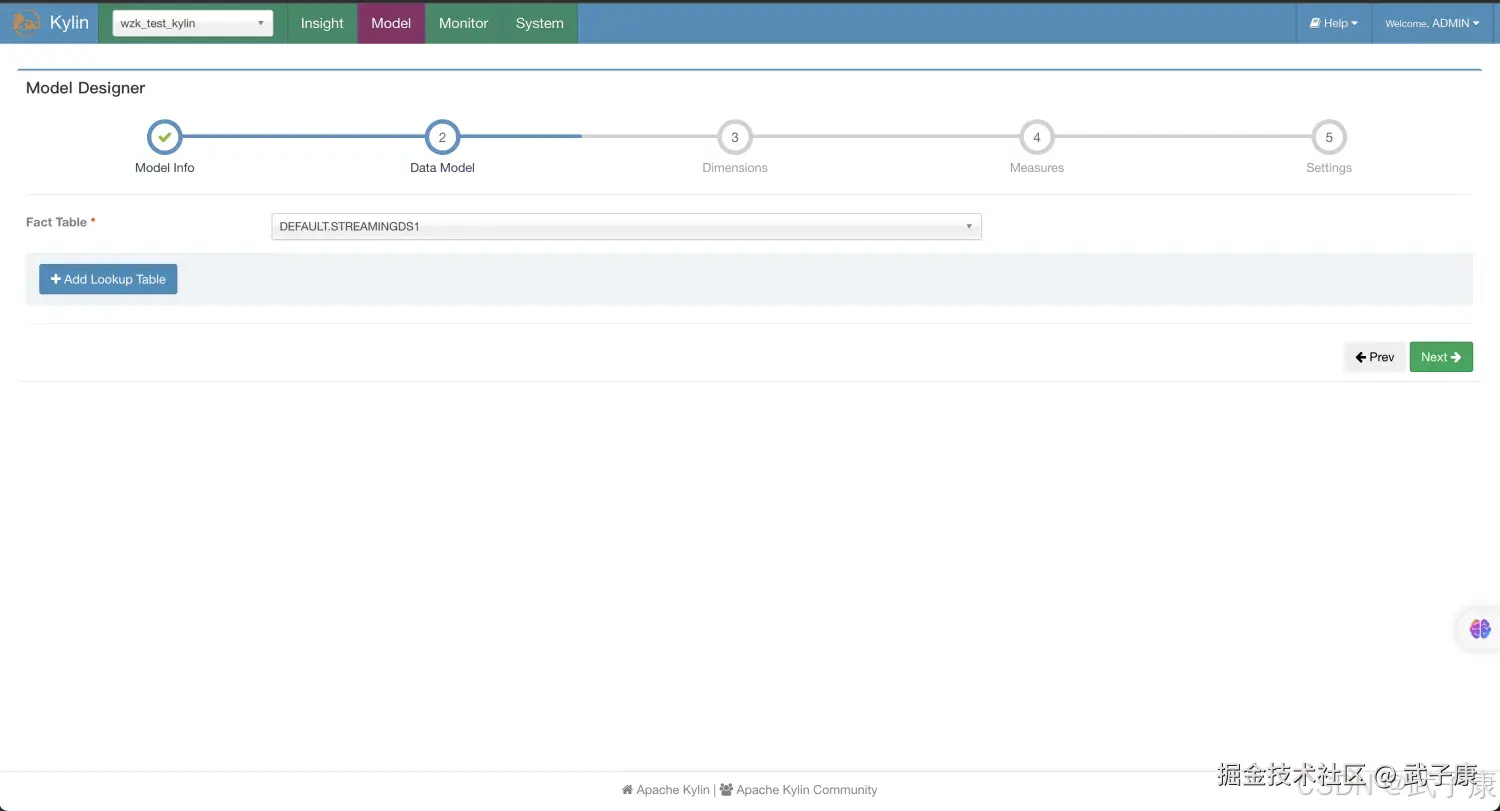 选择维度Dimension信息:
选择维度Dimension信息: 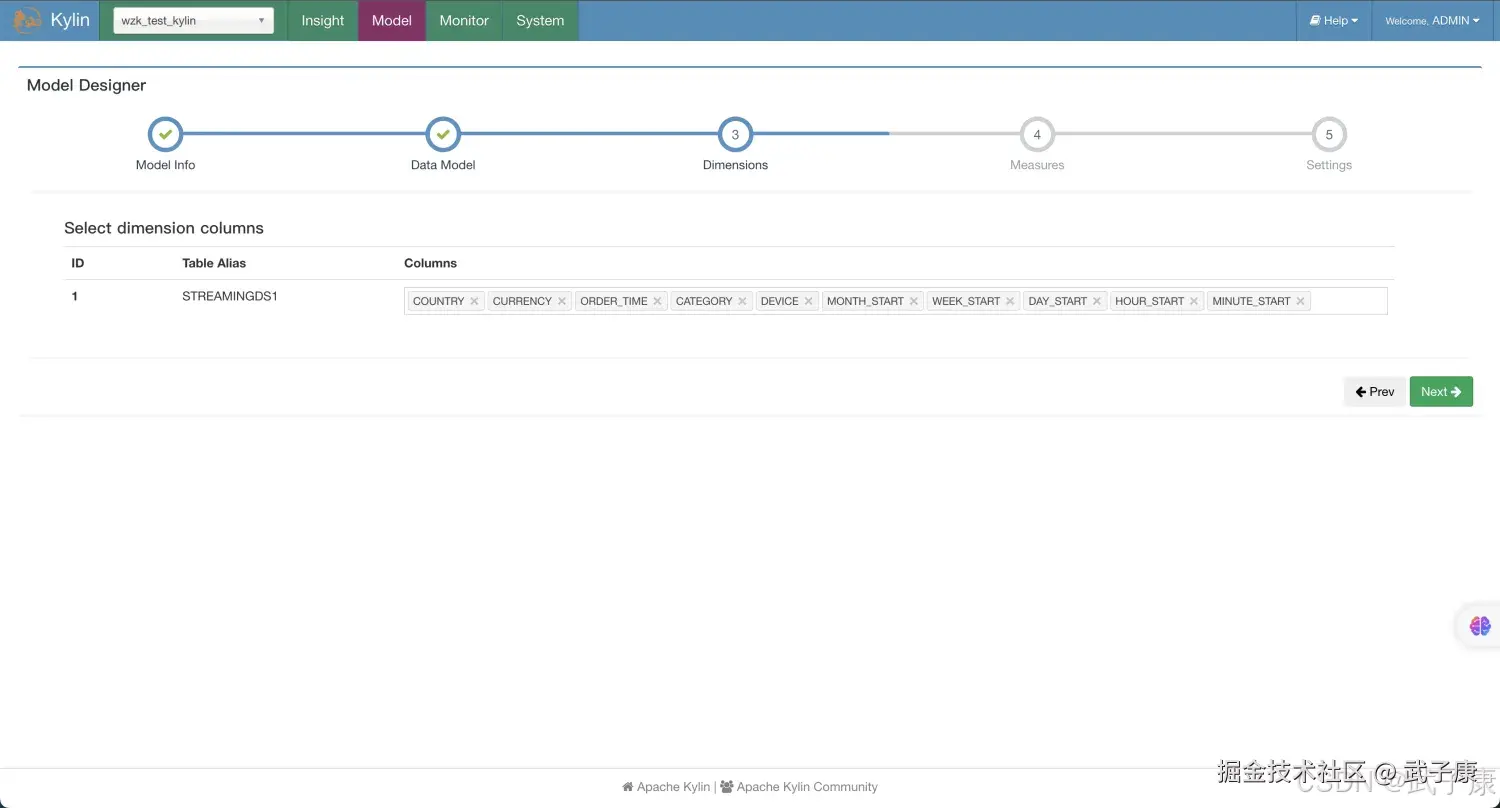 选择度量Measures,如下图所示:
选择度量Measures,如下图所示:  设置Setting中,设置对应的PartitionDateColumn信息,如下图:
设置Setting中,设置对应的PartitionDateColumn信息,如下图: 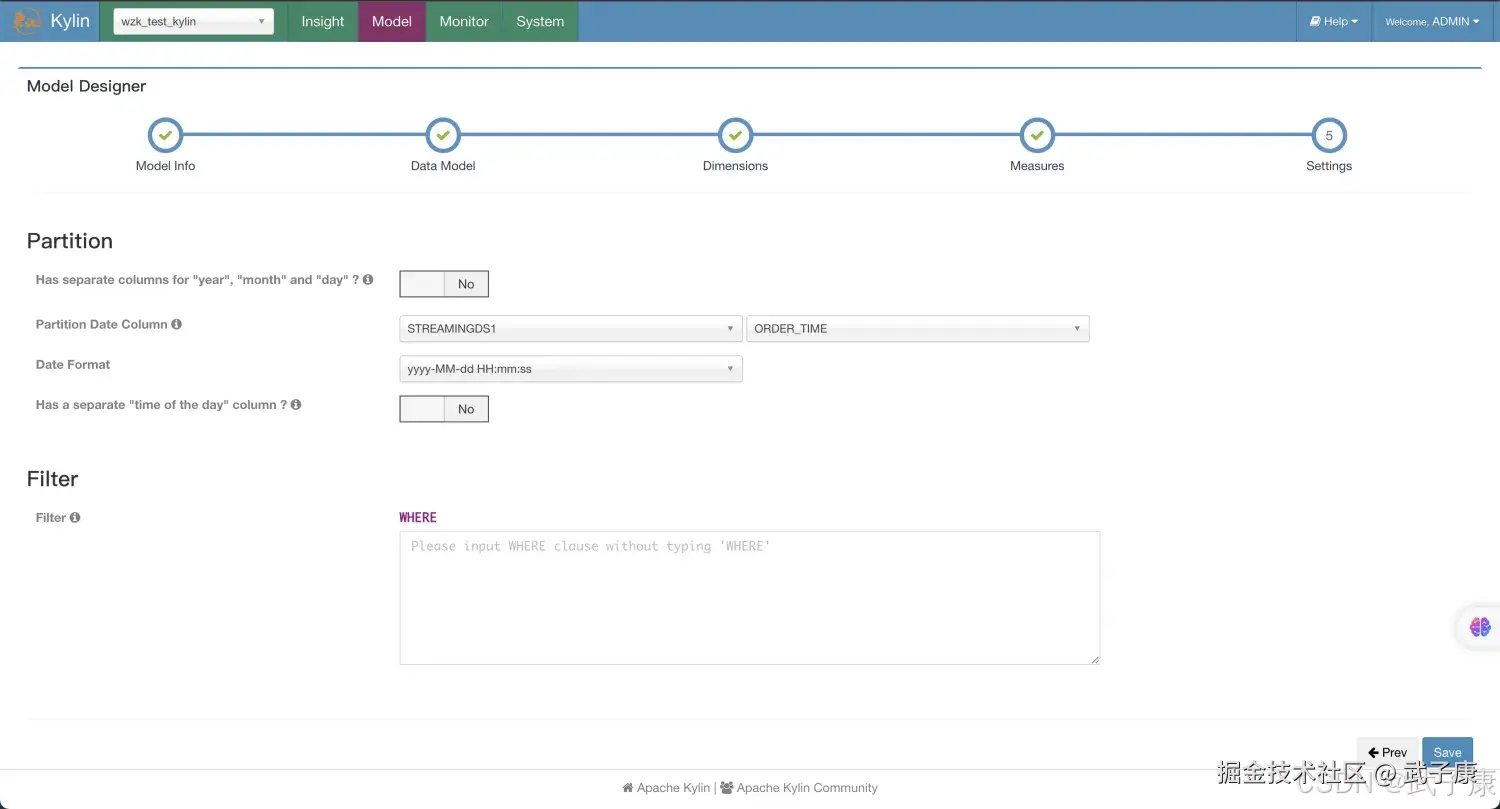
定义Cube
名字随意,自己能分清就可以,如下图:  设置Dimensions信息如下图所示:
设置Dimensions信息如下图所示: 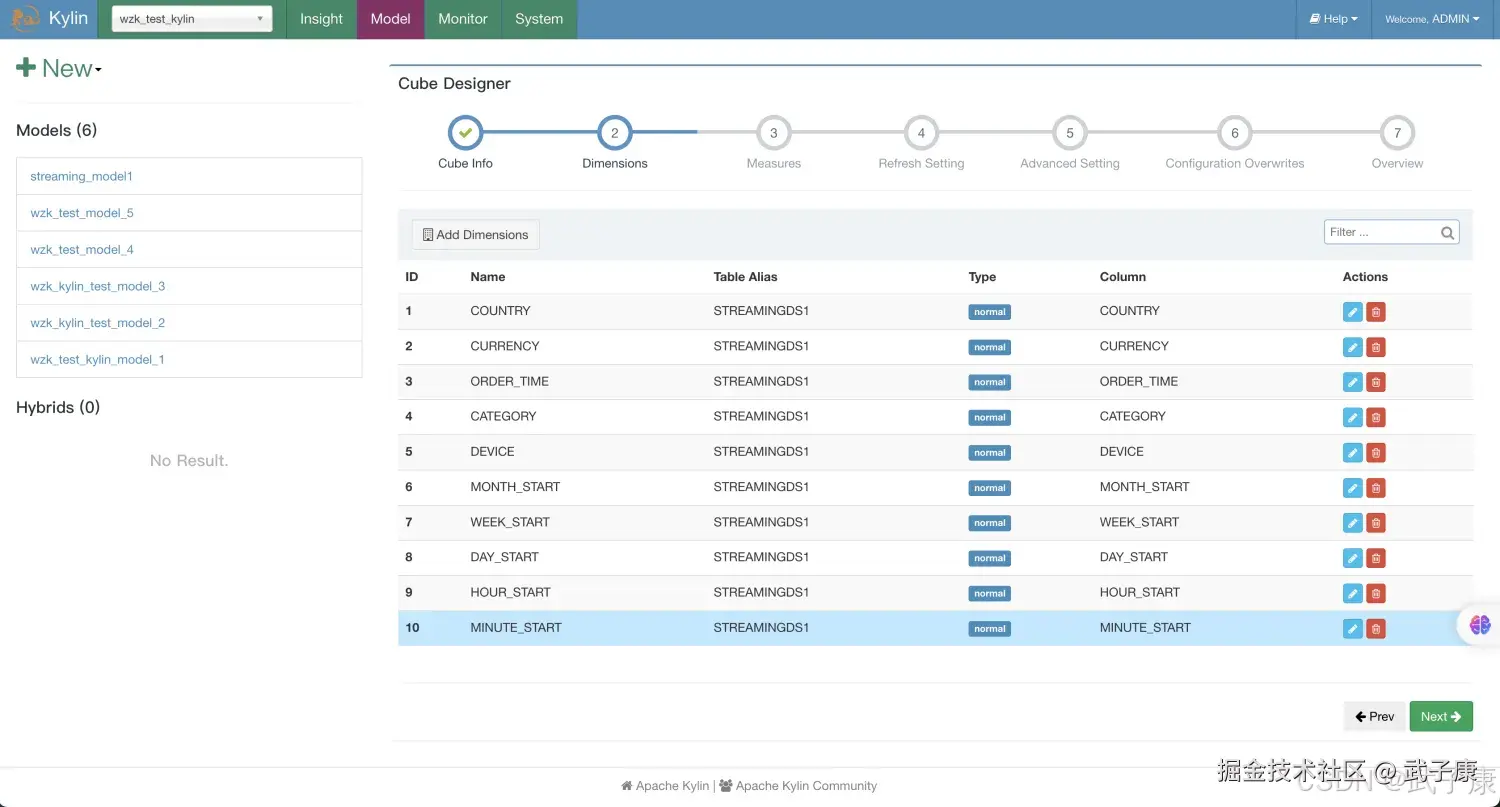 设置度量Measure信息如下图所示:
设置度量Measure信息如下图所示: 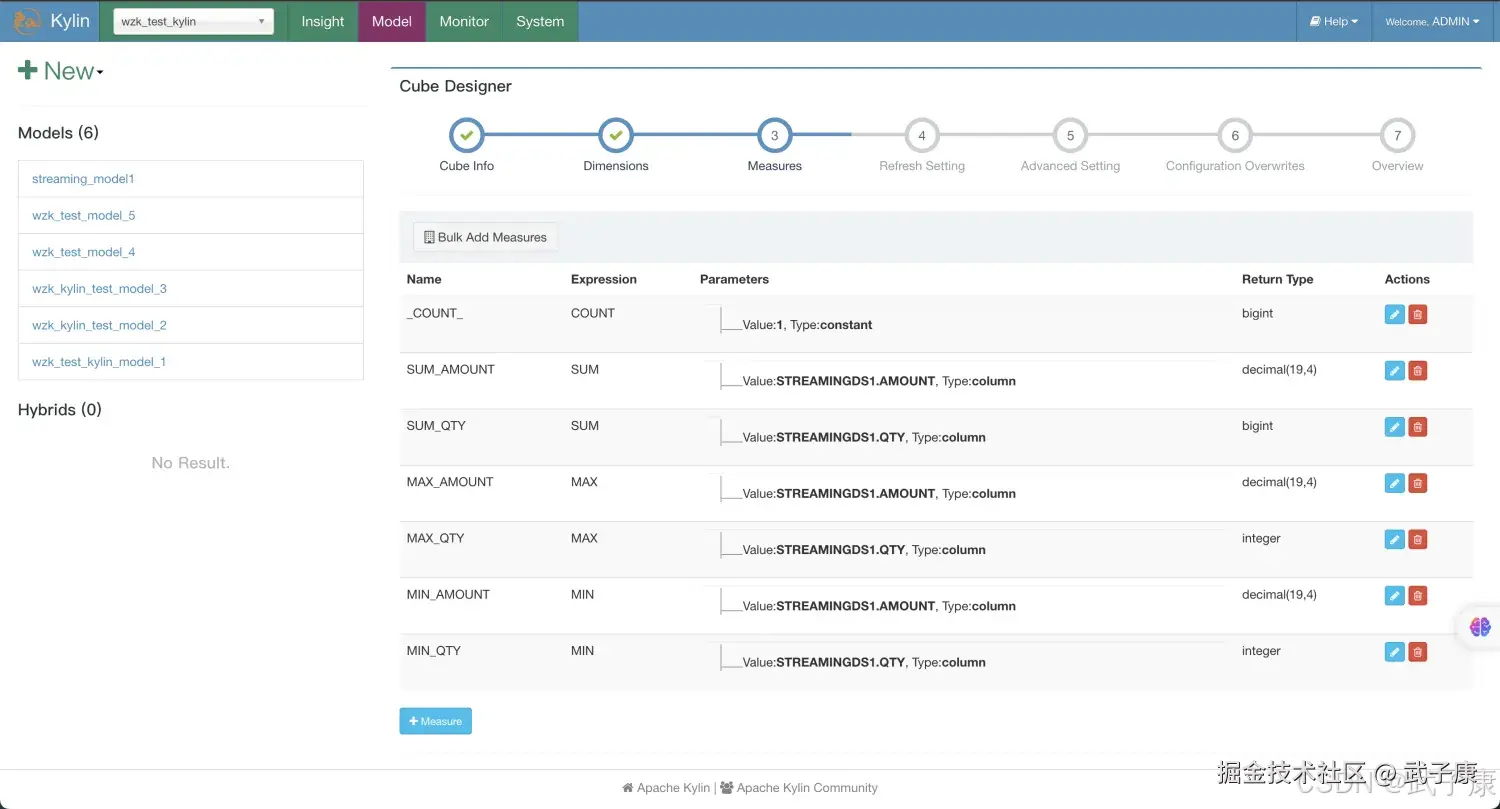 RefreshSetting设置信息如下图所示:
RefreshSetting设置信息如下图所示: 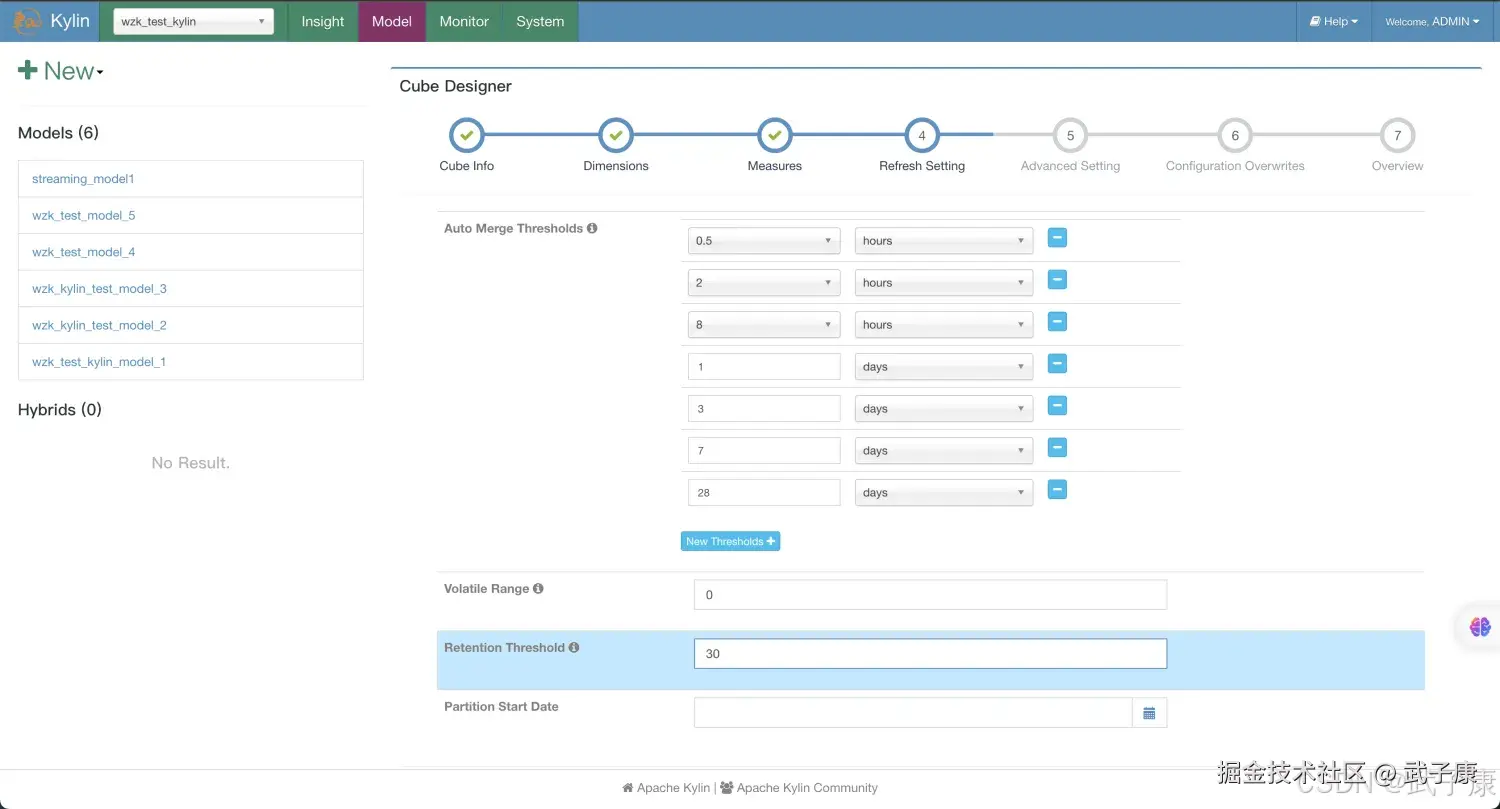 设置Aggregation Groups信息:
设置Aggregation Groups信息: 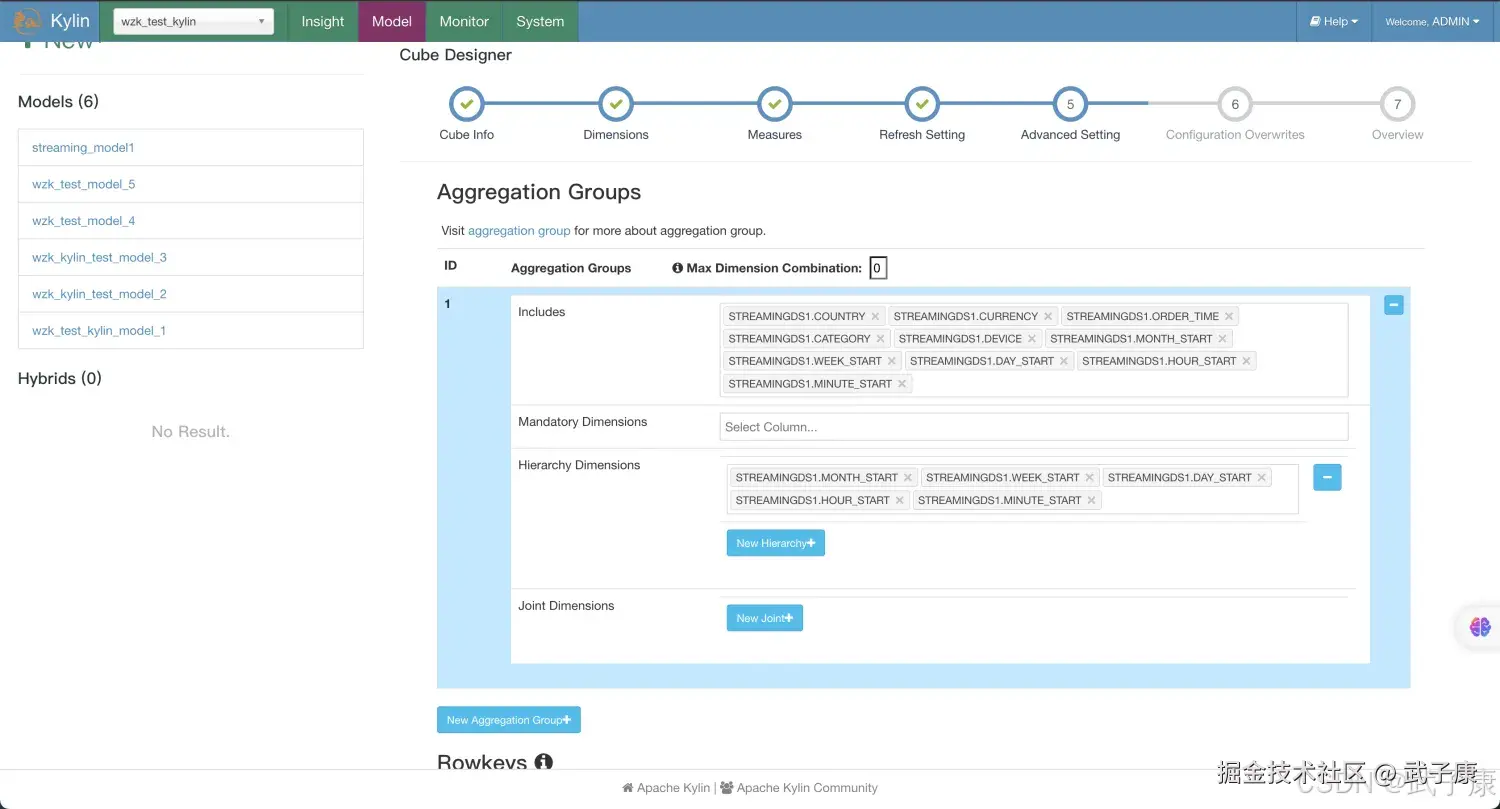 RowKeys的设置如下图所示:
RowKeys的设置如下图所示: 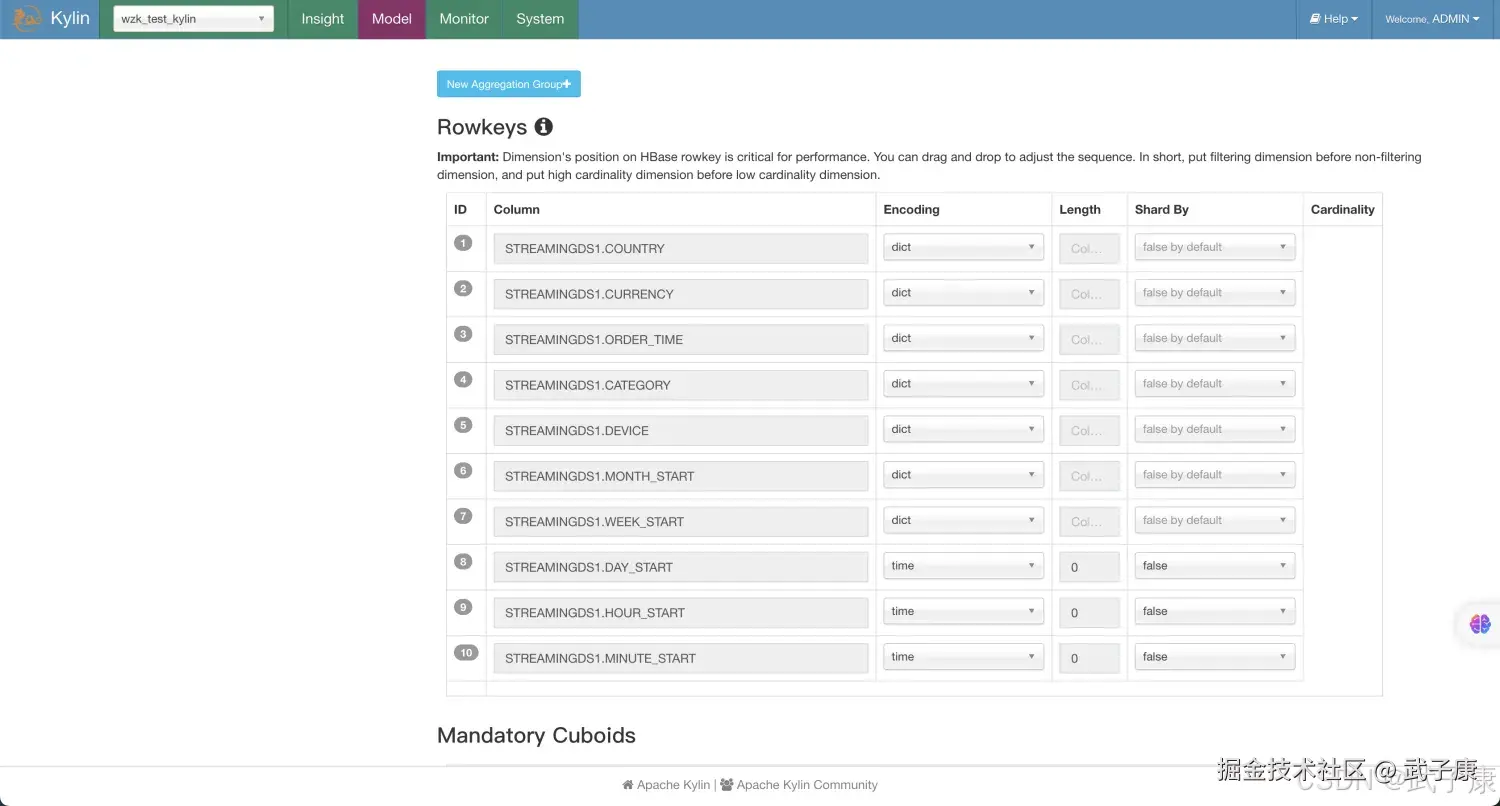 StreamingCube 和 普通的Cube大致上一样,以下几点需要注意:
StreamingCube 和 普通的Cube大致上一样,以下几点需要注意:
- 分区时间列应该Cube的一个Dimension,在SteamingOLAP中时间总是一个查询条件,Kylin利用它来缩小扫描分区的范围
- 不要使用order time作为dimmension 因为它非常精细,建议使用minute_start、hour_start或其他,取决于用户如何查询数据
- 定义 year_start、quarter_start、month_start、day_start、hour_start、minute_start或其他,取决于用户如何查询数据
- 在RefreshSetting设置中,创建更多合并的范围,如0.5时、4小时、1天、7天,这样设置有助于控制CubeSegment的数量
- 在RowKeys部分,拖拽minute_start到最上面的位置,对于Streaming查询,时间条件会一直显示,将其放到前面将会缩小扫描范围。
构建Cube
可以通过 HTTP 的方式完成构建
shell
curl -X PUT --user ADMIN:KYLIN -H "Content-Type:
application/json;charset=utf-8" -d '{ "sourceOffsetStart": 0, "sourceOffsetEnd": 9223372036854775807, "buildType": "BUILD"}' http://h122.wzk.icu:7070/kylin/api/cubes/streaming_cube1/build2也可以使用WebUI,我比较喜欢用页面来构建: 
执行查询
sql
select minute_start, count(*), sum(amount), sum(qty) from streamingds1
group by minute_start
order by minute_start自动构建
用 crontab 来定时任务,让其定时执行:
shell
crontab -e */20 * * * * curl -X PUT --user ADMIN:KYLIN -H "Content-Type:application/json;charset=utf-8" -d '{ "sourceOffsetStart": 0, "sourceOffsetEnd": 9223372036854775807, "buildType": "BUILD"}' http://h122.wzk.icu:7070/kylin/api/cubes/streaming_cube1/build2错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| Cube 无新数据 | 消费组 offset 越界/Topic 名错误 | Kylin Job 日志、kafka-consumer-groups | 重置 offset;校验 topic/分区;确保消费者组一致 |
| 解析失败"缺少时间戳/字段" | 字段名与解析器不匹配;格式不符 | Kylin 解析日志 | 统一字段命名;在采集端转换时间戳格式或自定义 Parser |
| 查询全表扫/极慢 | 未加时间过滤;时间分区列未前置 RowKey | 查询计划/扫描段数 | SQL 强制时间条件;调整 RowKeys 顺序 |
| 段数量爆炸 | 微批过细、合并窗口过小 | Segment 列表 | 调整 Refresh 合并:0.5h/4h/1d/7d;降低触发频率 |
| 构建任务长时间 Pending | YARN/队列资源不足 | YARN UI/Kylin Job 状态 | 提升队列资源;串行化构建;控制并发 |
| 聚合结果异常偏大 | 重复消费/去重缺失 | 源数据与 segment 对比 | 引入唯一键与幂等;窗口去重或业务去重逻辑 |
| Kafka 命令报错 --zookeeper | 新版 Kafka 已改参 | CLI 输出 | 使用 --bootstrap-server;统一脚本 |
| Parser 找不到嵌套字段 | 默认不展开深层结构 | 解析日志 | 采集端扁平化(user_gender 等)或扩展 Parser |
| 构建 REST 401/403 | 认证配置错误 | HTTP 响应/网关日志 | 校验账户凭证;必要时改为 Token 或白名单 |
| SQL 命中率低/未走 Cube | 维度/AGG Group 不匹配 | 查询详情/推断器 | 调整 Aggregation Groups;增加派生维度/层级 |
| Cron 未触发 | 环境变量/语法问题 | /var/log/cron* | 使用绝对路径;*/20 * * * * 语法;补全 PATH |
| 时间戳错位 | ms/秒/ISO8601 混用 | 样例数据/Parser 输出 | 统一标准(ms 或 ISO8601);在采集端转换并校验 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-127 Qwen2.5-Omni 深解:Thinker-Talker 双核、TMRoPE 与流式语音 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-174 FastFDS 从单机到分布式文件存储:实战与架构取舍 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 正在更新,深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接