在当今的数字化时代,以音视频等多媒体内容为代表的非结构化数据呈现出爆炸式增长。这类数据无法简单地用传统数据库中的行列数据来表示,因此向量检索技术应运而生。非结构化数据通常被转换为向量表示,并存储在向量数据库中。这种向量化模型能够提取并捕捉到数据中的特征,在多维的向量空间中进行有效表示。
一个形象的例子是:embedding(king)−embedding(man)+embedding(woman)≈embedding(queen)
13 倍的速度,背后到底藏着什么秘密?
在最新的 OpenSearch 实践中,我们引入 GPU 并行计算能力 与 NN-Descent 索引构建算法 ,成功将亿级数据规模下的向量索引构建速度 提升至原来的 13 倍。
在算法性能部分,GPU 上的 NN-Descent 比 32 核 CPU 快约 20 倍 ,结合产品集成优化后整体速度提升约 10 倍。更重要的是,GPU 构建几乎不占用 CPU 资源,腾出的算力还可用于其他任务,实现更高资源利用率。
在生产环境中,客户数据规模常常达到数亿,经典 HNSW 算法的索引构建往往需要花费半天,甚至数天的时间来完成,用户体验较差。
针对这一问题,我们进行了创新性的技术尝试,把 GPU 加速的 NN-Descent 算法引入到索引构建阶段,替代传统的 HNSW 算法。这种基于 GPU 的算法能够充分利用其大规模并行计算能力,从而显著加快索引构建速度。
通过在亿级数据集上进行测试,我们观察到了高达 13 倍的提速。这项技术不仅有效降低了部署成本,缓解了计算资源的压力,同时也提升了用户体验,维护了性能与成本的
理想平衡。
向量检索算法简介
向量检索的核心任务是从向量索引中找出与查询向量最相似的向量集合。为了平衡效率与精度,实际应用中通常采用 近似算法 代替精确匹配,以降低计算成本。
这些 近似算法 按 实现方式 可以主要分为以下几类:
- **图索引:**包括 HNSW 和 DiskANN。这类算法通过构建图结构以便数据点快速访问和检索.
- 量化索引:如 PQ(乘积量化)、HC(层次量化)、QC(量化聚类),以数据量化压缩来提升效率。
- 哈希索引:如 LSH(局部敏感哈希),利用哈希函数将数据散列到不同的桶中,加快检索速度。
其中,HNSW 是目前最为广泛使用的算法,其索引结构与跳表(Skip List)类似,拥有多层图,上一层节点是下一层节点的稀疏表示。底层图提供最详尽的数据点,而上层图则简化了移动计算,允许在向量空间中快速接近目标。在向量检索过程中,上层图可加速初步邻近目标的定位,而底层图负责精细化查找,确保准确性。
在后续小节中,本文将先对 GPU 进行介绍,随后探讨如何利用其计算特性推进向量索引的构建加速方法。
GPU 基础知识
最初,GPU 被设计用于图形绘制,但随着开发者逐渐认识到其在通用并行计算中的优势,GPU 演变为深度学习和高性能计算的关键硬件。本节将主要围绕广泛使用的英伟达(Nvidia)GPU 进行讨论。 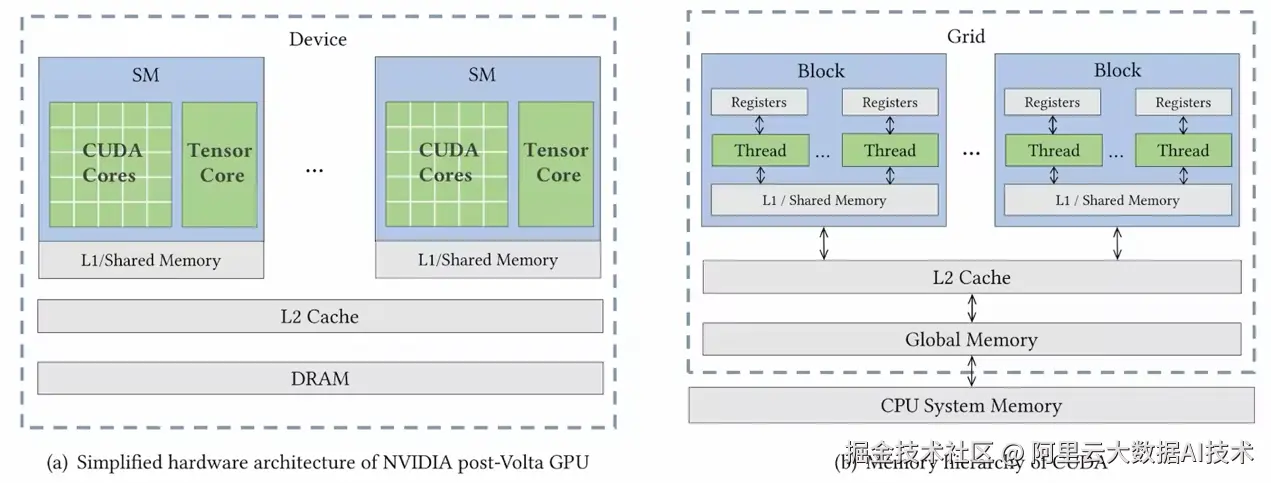
相比传统的中央处理单元(CPU),GPU 拥有数百甚至数千个核心,这些核心可以同时执行许多简单的计算任务。这种并行计算能力允许 GPU 以极高的效率处理大量数据,比如在深度学习中的大量矩阵运算。
随着 2017 年 Volta 架构的推出,Nvidia GPU 加入了 Tensor Core 硬件单元,该单元专门用于加速矩阵乘法计算,使得 GPU 的计算能力进一步提升。
下面的图示比较了一台家用 PC(Ryzen 9950X + 4090)中 CPU 与 GPU 的计算性能: 
- 在假设 CPU 的每周期指令数(IPC)为 4 、睿频为 5.7GHz 时,单核性能可达 22.8 GFLOPS(深蓝部分,图中几乎不可见)。如果使用全部 32 个核心并结合 AVX512 指令(单指令处理 16 个单精度浮点数),性能指标可以达到 10 TFLOPS(黄色部分)
- 另一方面,RTX 4090 的 CUDA Core 在 FP16 精度下的计算能力达到 82 TFLOPS(绿色部分)
- RTX 4090 的 Tensor Core 在 FP8 精度下的计算能力更是高达 660 TFLOPS(浅蓝部分)
如果我们以 H100 GPU 作为比较对象,GPU的优势将更加明显: 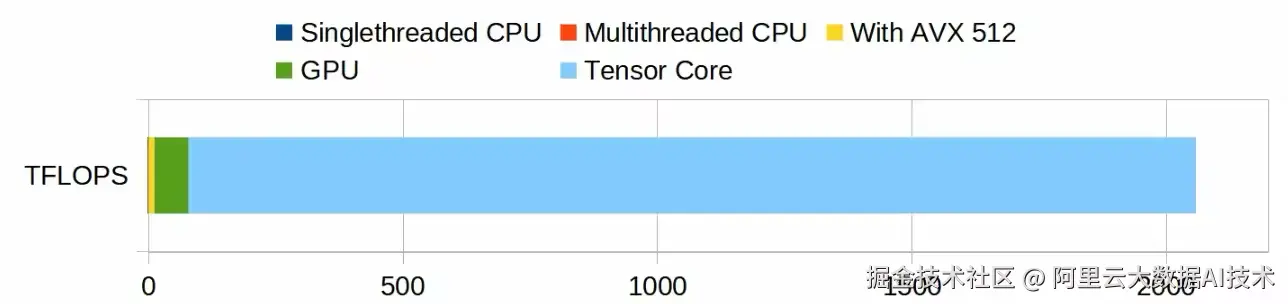
如何利用其计算特性推进向量索引的构建加速方法:
虽然在现实应用中,很多任务都无法充分利用如此高的并行度或依赖矩阵运算,但幸运的是,我们发现 NN-Descent 算法能够很好地发挥 GPU 的计算优势。
什么是 NN-Descent?
NN-Descent 是一种构建近邻图(proximity graph)的算法,简单来说,近邻图中点的邻居就是那些与其向量距离相近的点。与 HNSW 算法不同,NN-Descent 构建的图仅有一层,这可以理解为 HNSW 中包含所有点的第 0 层,此外,NN-Descent 图中所有点的邻居数量都是固定的,这是出于并行计算的考虑。
NN-Descent 算法的核心思想是"我邻居的邻居,可能是离我更近的邻居",其建图流程是一个迭代做全量更新的过程,在每轮迭代中,对每个点,都会去找它所有的二阶邻居(即邻居的邻居),尝试用这个集合去优化它原本的邻居集合(即我邻居的邻居,可能比我当前的邻居离我更近),如此迭代直到收敛。以下是对其计算流程一些关键问题的简化解释。
NN-Descent 关键问题的解释:
-
NN-Descent 如何将向量距离计算转化为矩阵乘问题? 以欧式距离 (a - b) ^ 2 为例,将其展开 a^2 + b^2 - 2ab,前两项都是天然并行的,而批量计算时,用向量集合 A 与集合 B 的内积(即第三项)完全等价于矩阵乘计算,这是 NN-Descent 能在 GPU 上高效执行的理论基础。
-
NN-Descent 具体是如何在 GPU 上运算的? 实际计算时,为提高效率,算法并不会遍历点的所有二阶邻居,而是去采样当前点的出边邻居与入边邻居(例如 {a, b} -> cur -> {c, d}),在采样集合({a, b, c, d})内两两计算距离,并尝试更新集合内各元素的邻居列表。
对每一轮迭代,假设数据集大小为 N,每个点的出边与入边采样数为 64,则更新所需的的总计算量为 N x 64 x 64 个向量内积,每个点的计算量为 64 x 64 个向量内积。每轮更新中,每个点会占用一个 GPU block,其 thread_num = 512,等价于 16 个 warp(GPU 以 32 个 thread 为最小执行单位,称为一个 warp),每个 warp 负责其中 16 x 16 个向量距离的计算。
NN-Descent 如何与 HNSW 进行对接:
NN-Descent 得到的图只有一层,而 HNSW 一般使用多层图去查询,所以该如何进行对接呢?对此,我们尝试了三种方案:
- 直接使用单层图,选取数个查询起点,查询时从距离查询结果最近的起点开始搜索;
- 走 hnsw 建图流程构建底层以外的层;
- 走 nn-descent 建图流程构建底层以外的层。
实测三种建图方式在建图速度、查询效果上没有明显差距。我们最终选择第三种方案,以便更好结合现有 HNSW 查询框架的查询逻辑。
OpenSearch 实践
我们在大小两个数据集上测试了算法的性能与效果表现,CPU 侧的比较对象为 OpenSearch 向量检索版 1.4.0 版本 的 HNSW 算法实现。
NN-Descent 核心需要调节的参数为 'intermediate_graph_degree '与 'graph_degree',前者为 GPU 建图时点的邻居数,后者是经过裁边后最终图的邻居数。
小数据集 为 100W 960 维 的 GIST 数据集,在开发机上进行测试,耗时上仅对比核心建图算法部分。A10 GPU 耗时 27s,32 核 CPU 图耗时 587s,是 GPU 的 21.74 倍。召回效果上,GPU 略弱于 CPU,但通过提升 ef,能够达到相似的召回率上限。
| 算法(框架) | Build Params | Time Used (s) | ef when Top10 Recall is 99.5% |
|---|---|---|---|
| HNSW(hnswlib 32Core) | M = 100 ef_construction = 500 | 619 | 500 |
| HNSW(OpenSearch 32Core) | M = 100 ef_construction = 500 | 587 | 110 |
| NN-Descent(OpenSearch) | graph_degree=96, intermediate_graph_degree=128 | 27 | 220 |
大数据集 为 1.13 亿 1024 维的 Cohere 数据集,在产品中进行测试(大数据集时不再对比 hnswlib 的结果):
| Build Params | Time Used | 分配的 CPU 核数 | Node Count |
|---|---|---|---|
| M = 100 ef_construction = 500 | ~13 hours | 16 | 5 |
| graph_degree=64, intermediate_graph_degree=96 | ~1 hour | 2 | 5 |
大数据集 Top100 相同召回率下的查询性能:
查询节点分配的资源为 ++16 核 * 10 分片++,实际环境可根据需求扩容
| Recall | 算法 | Query Param | Concurrency | QPS | Latency (ms) |
|---|---|---|---|---|---|
| 0.95 | HNSW | max_scan_ratio=0.001 ef=100 | 1 | 47 | 21 |
| 4 | 199 | 20 | |||
| 16 | 554 | 28 | |||
| NN-Descent | max_scan_ratio=0.001 ef=100 | 1 | 55 | 18 | |
| 4 | 202 | 19 | |||
| 16 | 574 | 27 | |||
| 0.98 | HNSW | max_scan_ratio=0.003 ef=100 | 1 | 40 | 24 |
| 4 | 152 | 26 | |||
| 16 | 413 | 38 | |||
| NN-Descent | max_scan_ratio=0.05 ef=130 | 1 | 31 | 32 | |
| 4 | 113 | 35 | |||
| 16 | 282 | 56 | |||
| 0.99 | HNSW | max_scan_ratio=0.05 ef=130 | 1 | 31 | 32 |
| 4 | 113 | 35 | |||
| 16 | 296 | 54 | |||
| NN-Descent | max_scan_ratio=0.05 ef=500 | 1 | 15 | 66 | |
| 4 | 55 | 71 | |||
| 16 | 132 | 120 | |||
| 0.995 | HNSW | max_scan_ratio=0.05 ef=300 | 1 | 17 | 57 |
| 4 | 64 | 62 | |||
| 16 | 156 | 102 | |||
| NN-Descent | max_scan_ratio=0.05 ef=1500 | 1 | 12 | 84 | |
| 4 | 44 | 90 | |||
| 16 | 104 | 153 |
参考文献
1.Initial CUDA Performance Surprises
2.NN-Descent
结尾
综合而言,基于 NN-Descent 算法的 GPU 向量索引构建 在理论上比传统 CPU 的性价比提升超过 10 倍。然而,由于前后处理与调度操作占用了部分时间,当前产品中 GPU 的实际利用率未达预期,其实际性价比约为 5 倍。
在算法性能方面,GPU 上的 NN-Descent 比传统 CPU 实现快约 20 倍 (基于 32 核的比较),产品集成后整体速度提升约 10 倍 。当然,这项技术也并非没有缺陷:
- 同查询参数时,GPU 建图的召回率比 CPU 建图低约 1 - 1.5 个百分点,但通过调节查询参数,可以达到相同水准。
- 相较于 32 核 CPU 机型,32 核 A10 GPU 机型的成本高约一倍,然而,由于算法几乎不占用 CPU 资源,CPU 可以用于运行其他任务。
未来,我们计划通过优化任务调度策略来进一步提高 GPU 的利用效率。此外,我们也将探索优化策略,尝试在适度牺牲构建性能的情况下,进一步提升召回率以满足更高精度需求。这些改进将有助于实现更为均衡的成本效益比,提高生产应用中的效率与效果。