引言
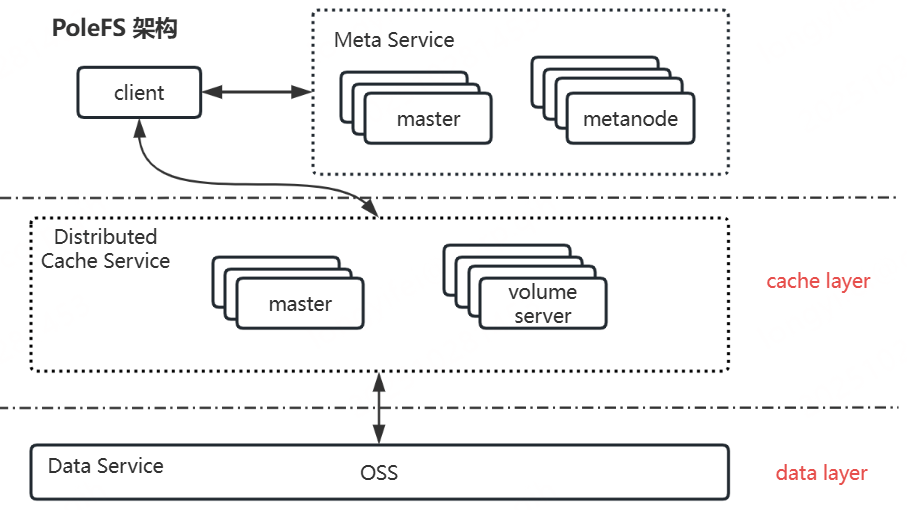
PoleFS是公司自研的一款面向云原生设计的高性能分布式文件系统,其主要包括客户端、元数据服务、分布式缓存服务、数据服务四大部分。本文将从更详细的角度介绍分布式缓存服务的系统架构、系统特性以及系统设计。阅读本篇文章之前,你需要了解PoleFS的系统架构,以及各个关键组件的职责和系统的名词概念。
相关名词概念说明:
-
卷:逻辑上的概念,由元数据和数据组成。从客户端的角度看,卷可以被看作是可被访问的文件系统实例;从存储的角度来看,一个卷对应着缓存的一个collection以及底层对象存储OSS的一个bucket。
-
collection:用户为卷创建的缓存集合,包含若干vid,与上层文件系统卷和底层对象存储OSS的bucket一一对应。
-
vid:数据管理的基本单元。
-
needle:数据存储的最小单元,与底层对象存储OSS的object一一对应。
分布式缓存系统架构
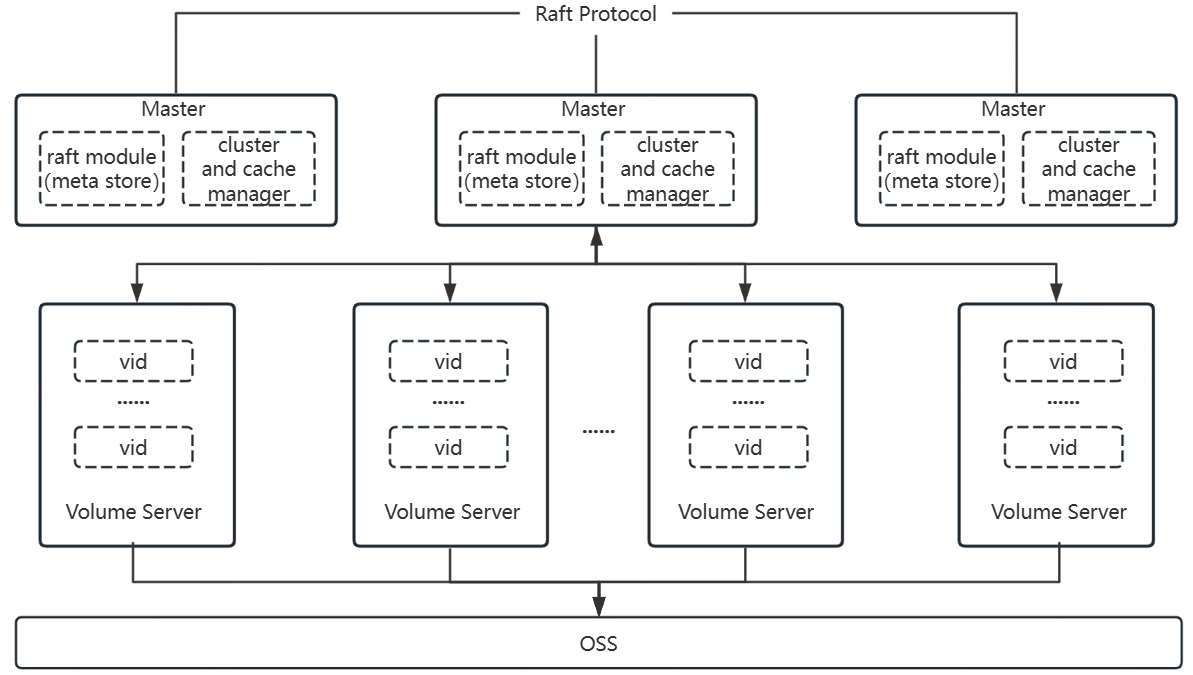
blobcache是PoleFS的分布式缓存子系统,能够为PoleFS提供高性能、高可靠、高可用的分布式缓存服务。其介于客户端与OSS(基于S3协议的对象存储)中间,充当数据缓存层;核心职责主要包括两部分,一部分是要保障上层写入数据安全可靠地转存到底层对象存储OSS,另一部分则是要高效地利用缓存空间提高上层对数据的访问性能。blobcache具体包括master和volume server两个组件,其中,master组件主要负责集群以及缓存信息的管理(内部通过raft协议保障数据的可靠性);volume server组件主要负责缓存数据的存储、下刷以及访问。
PoleFS整体架构图如下:
blobcache整体架构图如下:
分布式缓存系统特性
-
读、写缓存分离(用户可根据实际需求配置不同的读、写缓存大小)
-
读、写缓存弹性(系统能够根据缓存实际使用情况,弹性地调整缓存占用空间)
-
高可用(系统具备故障自愈机制,能够在部分节点故障的情况下保障服务的可用性)
-
高可靠(采用写三读一的设计并支持CRC校验,能够保障数据下刷完成前的可靠性)
-
可扩展(用户可根据实际需求对缓存数据节点进行水平扩展)
-
多租户(不同用户的卷缓存之间相互独立)
分布式缓存系统设计
关键结构
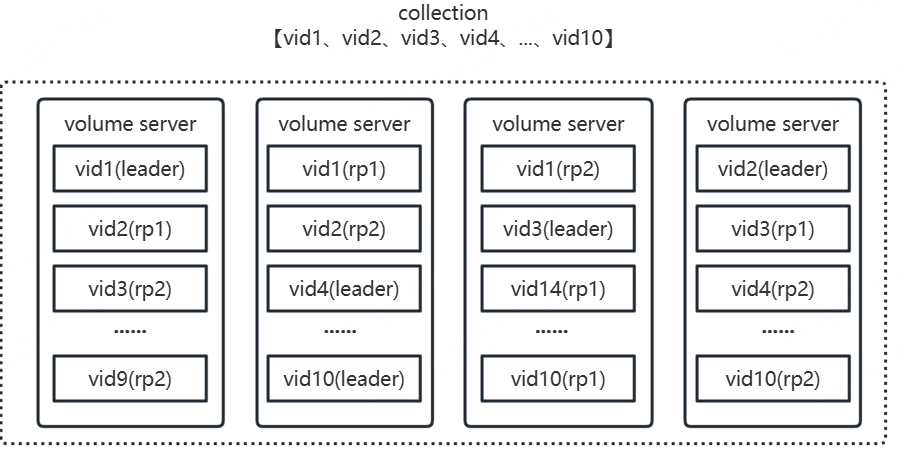
collection
collection是用户为文件系统卷创建的缓存集合,由若干vid(3副本,一主两从)组成,根据分配策略每个vid副本在满足故障域的情况下会均匀散列在集群的各个volume server上。其中,选择volume server的策略是基于节点的权重值,权重值与volume server剩余未使用的逻辑空间大小呈正相关,剩余逻辑空间越大,权重越大,以保障每个volume server使用的逻辑空间均衡。
eg:
用户创建了一个包含10个vid的collection,大体如下图所示:
collection对应vid个数计算公式:
vidCount=⌊ cacheCap/cacheBase**⌋***vidBase+vidBase
变量说明:
vidCount:vid个数。
cacheCap:用户配置的缓存大小(读缓存和写缓存之和)。
cacheBase:系统配置的基本缓存大小。
vidBase:系统配置的基本vid数量。
eg:
用户创建一个150GB缓存(写缓存:50GB,读缓存:100GB),即cacheCap=150GB。
集群默认配置:cacheBase=100GB,vidBase=10。
collection对应vid个数:vidCount=⌊ 150/100**⌋***10+10=20。
根据vid个数可以计算出每个vid所对应的缓存容量(写缓存:2.5GB,读缓存:5GB)。
vid
vid是数据管理的基本单元,具体包括写缓存和读缓存(只有vid leader有)以及manifest文件。其中,写缓存采用多buf设计,每个buf都包含有一对dat(用于存储数据)和idx(用于存储数据对应索引)文件,buf内最小数据存储单元为needle,相应一个buf包含若干needle;读缓存对应一个目录,目录下包含若干数据文件(与底层对象存储OSS的object一一对应);manifest文件主要用于记录vid缓存相关信息。整体如下图所示:
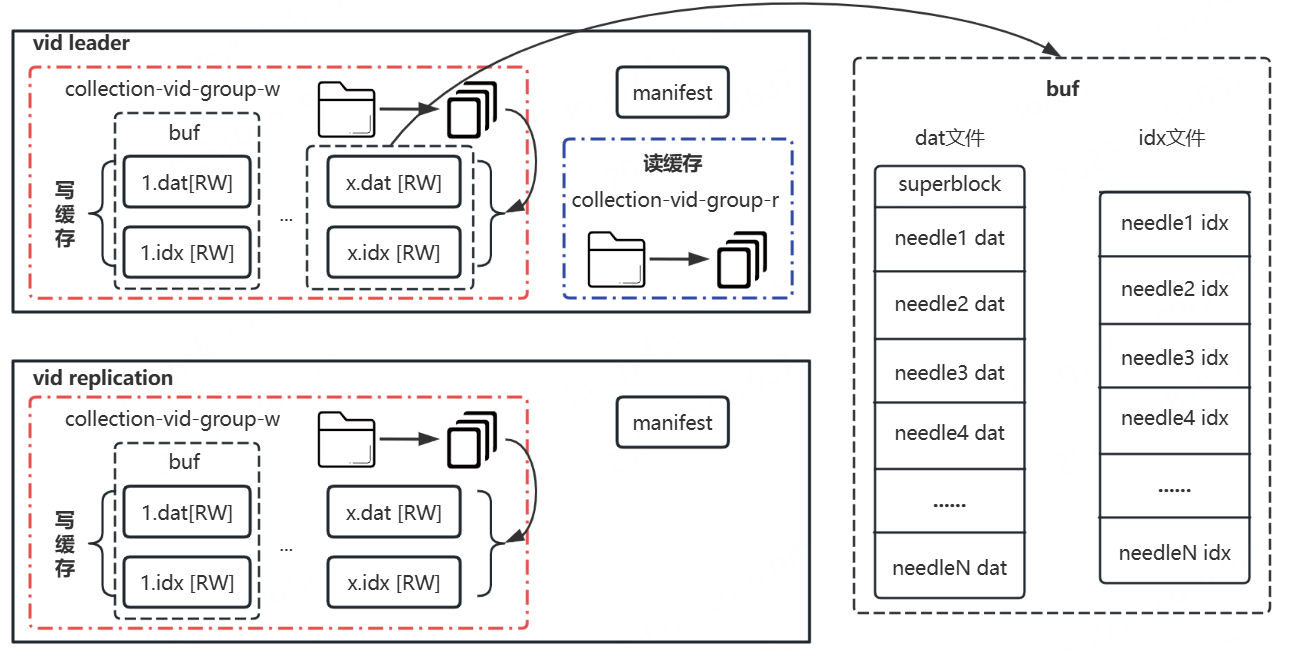
vid写缓存对应buf数量计算公式:
bufCount=writeCacheCap/datCapLimit
变量说明:
bufCount:buf个数。
writeCacheCap:写缓存容量。
datCapLimit:系统配置的dat文件容量限制。
eg:
每个vid所对应的缓存容量(写缓存:2.5GB,读缓存:5GB),即writeCacheCap=2.5GB。
集群默认配置:datCapLimit=0.1GB。
vid写缓存对应buf个数:bufCount=2.5GB/0.1GB=25。
数据读写
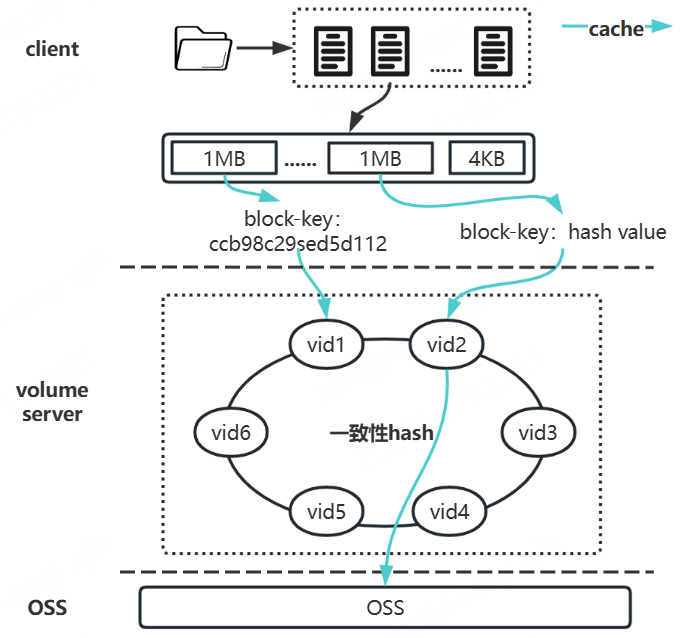
分布式缓存的数据读写主要采用一致性哈希策略,以保障请求的负载均衡。其中,缓存collection包含的若干vid分别对应hash环上的若干节点,每个vid节点负责一段range,读写数据则按照一致性哈希算法对数据的key(卷内唯一)进行计算,根据结果判断其所在range,最终确定读写的vid。
-
写数据:请求vid leader节点,vid leader节点写成功后,会同时写数据到其副本节点,都写成功后才会返回成功,否则返回失败。其中,写成功的数据会按照写缓存下刷策略进行下刷,已下刷的数据会移动到读缓存中。
-
读数据:请求vid leader节点,内部按照写缓存、读缓存、底层对象存储OSS顺序依次进行读取,直到读成功后返回(如果从底层对象存储OSS读的,则异步将数据写到读缓存中)。
eg:
用户创建一个collection,上层文件系统写到分布式缓存的数据默认会按照1MB大小切分成若干block,每个block会被分配一个卷内唯一的key,通过一致性哈希算法对key进行计算可获取其对应的vid,请求master拿到vid leader节点后,即可对vid进行读写。大体如下图所示:
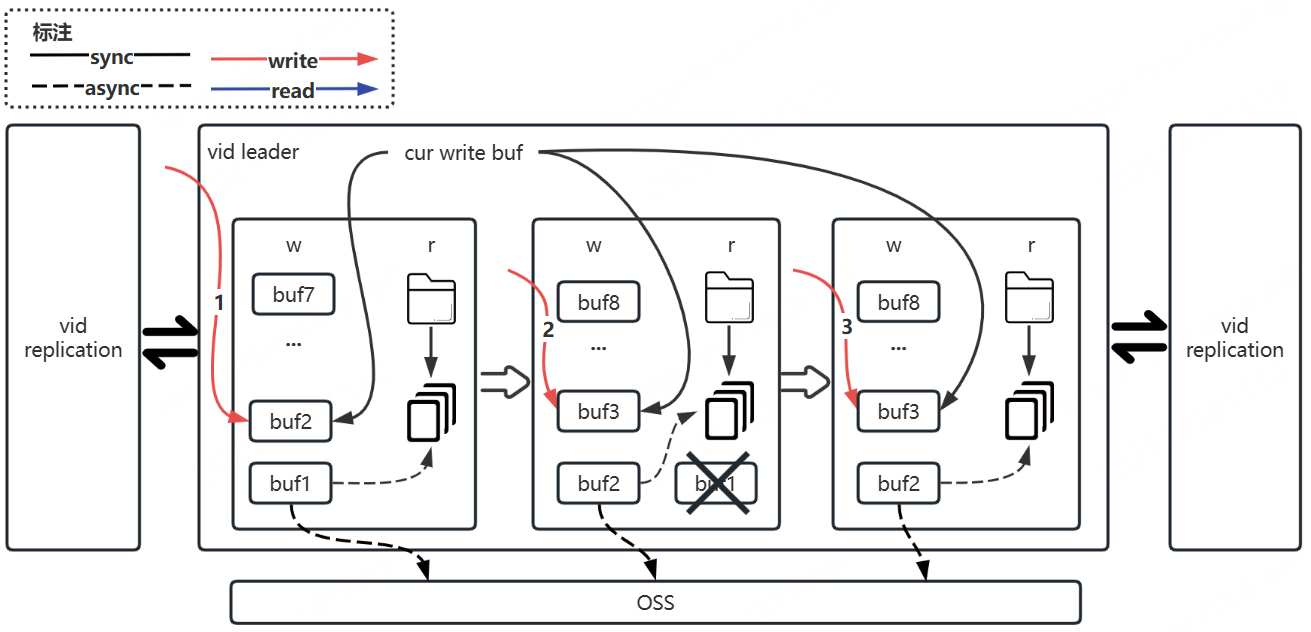
其中,往vid leader写数据,根据当前写buf文件指向按照buf编号从小到大写,buf写到上限则切换到下一个buf,已写满的buf数据全部下刷后将移除同时新增一个buf。大体如下图所示:
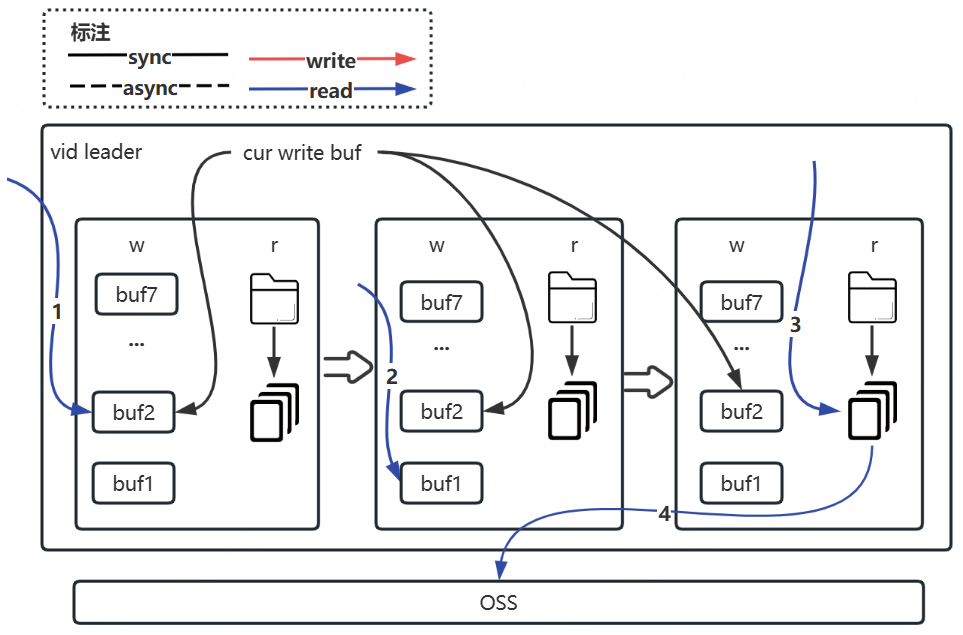
其中,从vid leader读数据,先根据当前写buf文件指向按照buf编号从大到小检索读取,如若未读到则继续从读缓存中检索读取,还未读到在从OSS中读取。大体如下图所示:
缓存扩缩容
根据用户调整后的缓存大小,重新计算其collection对应vid数量实现。
-
vid数量如果不变,则直接修改所有vid读、写缓存容量配置。
-
vid数量如果改变,则生成一组新的vid(即新hash环),然后异步淘汰旧的vid(即旧hash环),最终只保留最新的一组vid。
缓存弹性
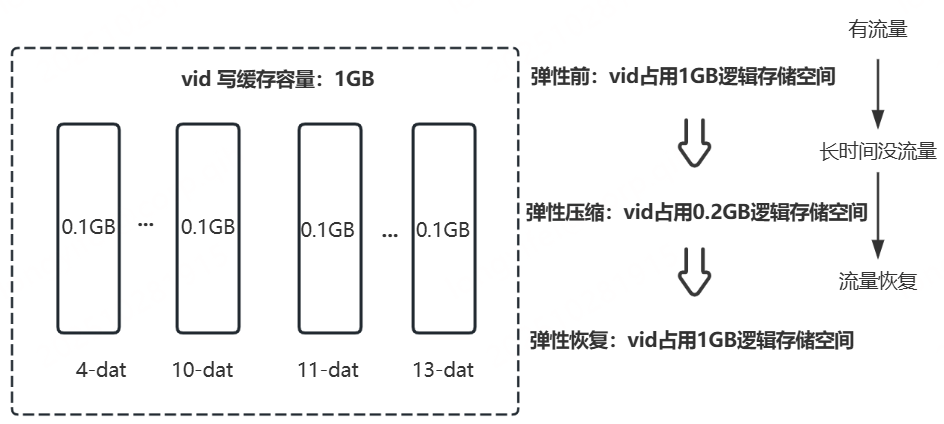
-
当用户申请缓存后超过一定时间(默认:1h)未使用(即没有读、写、删流量),底层则会回收部分分配的逻辑存储空间,只保留最低可提供服务的存储空间(即每个vid写缓存只保留双buf所需存储空间,读缓存则按实际占用存储空间计算),以便集群创建更多的缓存。
-
当长时间未使用的缓存突然使用,底层检测到流量则会将缓存占用的空间大小弹性调整到其配置的大小,以保障用户正常使用所需的缓存空间。
eg:
当用户创建缓存大小为20GB(写缓存:10GB,读缓存:10GB)时,弹性前缓存占用逻辑空间40GB(写3副本+读1副本),长时间没流量情况下,弹性后缓存占用逻辑空间最小可缩小至6GB(读缓存数据全部淘汰情况下),此时集群超额创建缓存比例可达6.7倍。