Linux 优先级反转问题详解与处理方案
优先级反转(Priority Inversion)是指高优先级任务因等待某个资源(如锁)而被低优先级任务间接阻塞,并在此期间被中等优先级任务持续抢占,导致系统违反"高优先级先服务"的原则。该问题在实时系统(RT)中尤为致命,可能引发不可预期的延迟甚至错过截止期限(deadline)。
直观示意
下图展示了经典三任务场景:低优先级任务 L 先获取锁,随后高优先级 H 尝试访问同一锁而阻塞,期间中优先级 M 长时间运行,造成"优先级反转"。
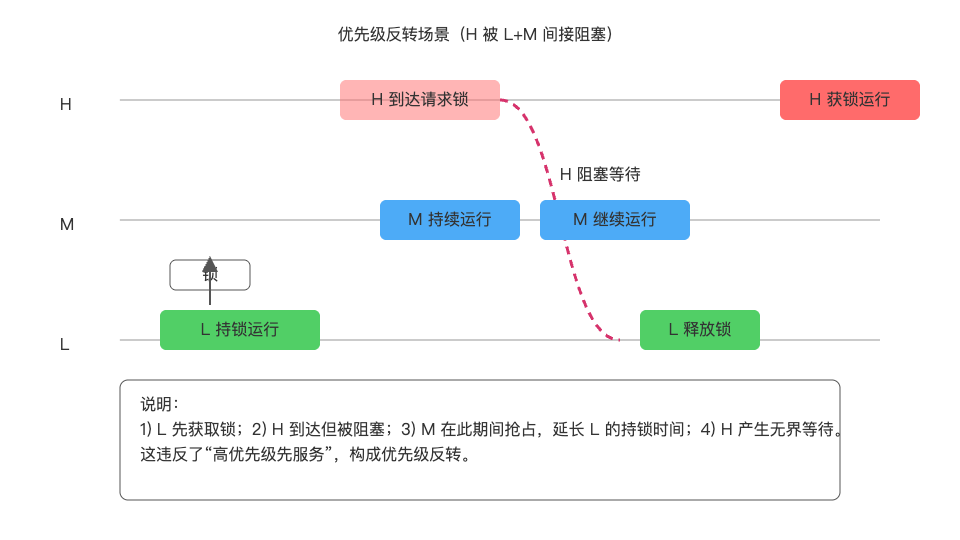
问题根因
- 共享资源存在互斥访问需求(如临界区、锁、资源句柄)。
- 高优先级任务在资源上发生阻塞(等待持有者释放)。
- 调度器允许中优先级任务抢占低优先级持有者,延长持有者的占用时间,形成"无界"延迟。
危害与症状
- 无界延迟:当中优先级任务持续出现时,高优先级任务的等待时间没有上限。
- 抖动与违约:响应时间抖动增大,可能错过实时截止期限。
- 饥饿:高优先级任务被长期饥饿;系统表面看似"很忙"却无法满足关键任务。
处理与缓解方案
1) 优先级继承(Priority Inheritance, PI)
核心思想:当高优先级任务 H 因锁阻塞在低优先级任务 L 上时,临时将 L 的调度优先级提升到不低于 H,让 L尽快运行并释放锁,随后 L 恢复原优先级。
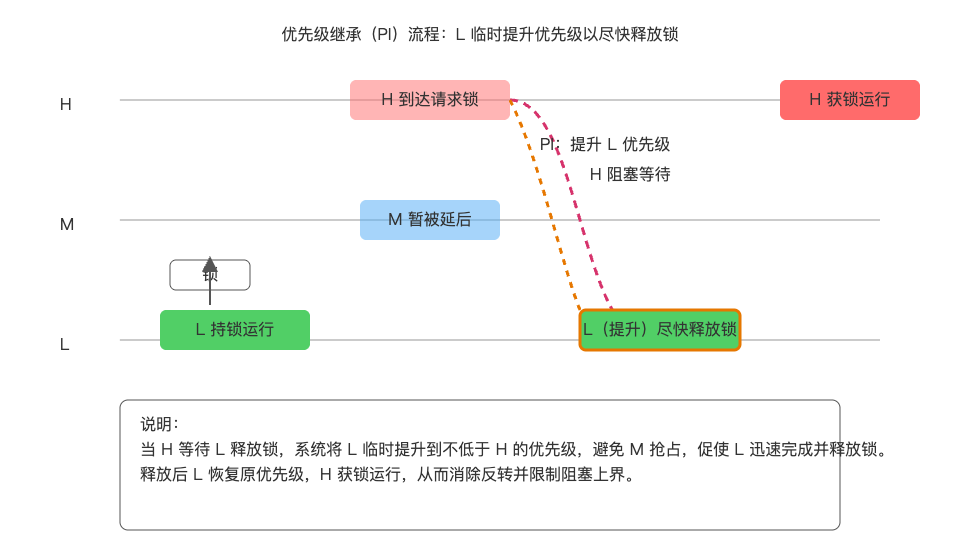
适用要点:
- 适合互斥锁(mutex)与可睡眠锁;不能用于自旋锁(spinlock),因其不睡眠且在 RT 场景中需谨慎使用。
- 需要系统/库支持 PI(Linux 内核的
rt_mutex与用户态的futexPI 变体、pthread的PTHREAD_PRIO_INHERIT)。
局限:
- 继承链复杂度:多任务链式等待时可能形成"级联提升"。实现需正确处理入队、出队与优先级传播。
- 不解决"锁设计不当"问题:频繁长临界区仍会导致大延迟,只是被"加速释放"。
2) 优先级上限/天花板协议(Priority Ceiling Protocol, PCP)
核心思想:为每个共享资源设定一个"优先级上限"(Ceiling),任务在进入临界区时临时提升至该上限或限制其它任务对相关资源的进入,提前避免反转与死锁。
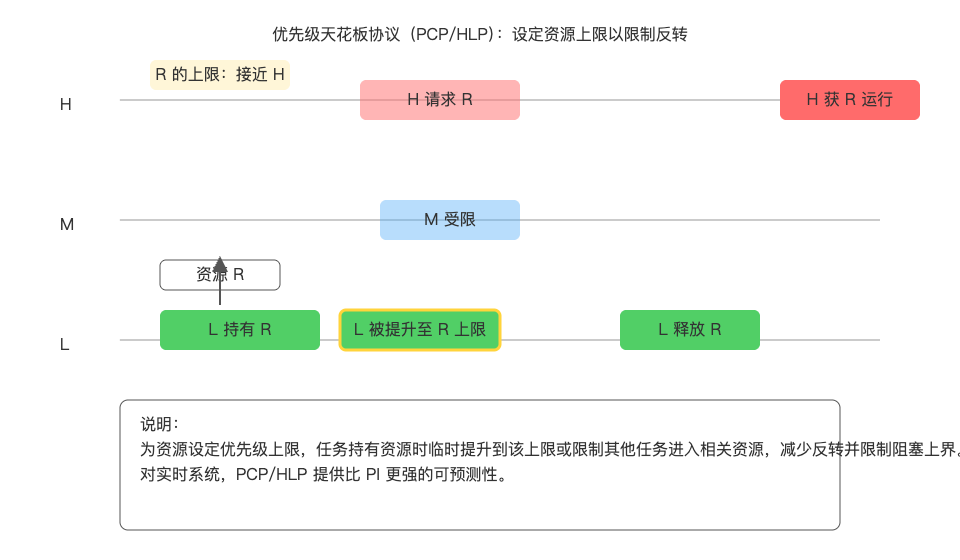
变体:
- Original/Immediate PCP(OIPP/PCP):任务持有资源期间被临时提升到该资源的上限。
- Highest Locker PCP(HLP):按锁的最高访问者设定等级,策略更简单、易实现。
优点:
- 比 PI 更强的静态保证,可有效限制继承链与阻塞时间的上界。
3) 设计与工程化技巧
- 缩短临界区:将耗时操作移出锁内;使用无锁结构或 RCU 等读多写少方案。
- 锁分层与分割:将"大锁"拆分为多把细粒度锁;避免跨优先级共享同一把锁。
- 使用合适的锁:高优先级任务尽量使用可 PI 的互斥锁;慎用信号量(semaphore)与条件变量导致的长等待。
- 调度与亲和:为关键任务设定
SCHED_FIFO/RR与 CPU 亲和(isolcpus,cpuset),减少中等优先级干扰。 - 避免主动抢占关键路径:中优先级任务避免在关键资源热路径上抢占(降低优先级或迁出)。
Linux 内核与用户态实战
内核态
rt_mutex:内核提供的支持优先级继承的可睡眠互斥锁,RT 场景推荐在关键路径使用。futexPI:用户态通过FUTEX_LOCK_PI使用支持 PI 的 futex,与内核协作进行优先级提升。- PREEMPT_RT:在实时内核(PREEMPT_RT)中,大量内核内部锁转换为可睡眠并支持 PI 的实现,显著降低反转风险。
用户态(POSIX 线程)
启用 pthread 的优先级继承:
c
#include <pthread.h>
pthread_mutex_t mtx;
void init_mutex_with_pi() {
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
// 启用优先级继承
pthread_mutexattr_setprotocol(&attr, PTHREAD_PRIO_INHERIT);
// 可选:设置为实时、避免自旋过长
// pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_NORMAL);
pthread_mutex_init(&mtx, &attr);
pthread_mutexattr_destroy(&attr);
}设定实时调度策略与优先级(示例):
c
#include <sched.h>
void set_rt_priority(int prio) {
struct sched_param sp = { .sched_priority = prio };
// SCHED_FIFO 或 SCHED_RR:严格按优先级调度
sched_setscheduler(0, SCHED_FIFO, &sp);
}注意事项:
- 仅在确有实时需求时启用 PI;对锁过多的设计进行重构更有效。
- 评估阻塞上界,结合 PCP/HLP 可获得更可预测的延迟。
CFS 与优先级反转
结论
- 在严格"固定优先级"的意义上,CFS(
SCHED_OTHER)按权重公平而非固定优先级抢占,不容易出现经典的"调度级无界反转"。 - 但在"资源级"层面,高重要度线程阻塞在低权重线程持有的锁上、期间其他线程持续运行,会造成功能上等价的反转:高重要度线程的等待显著拉长。
机理概览
- CFS 用
nice→weight并以每个实体的vruntime(虚拟运行时间)选择最小者运行,追求长期公平,而不是"谁优先级高谁先跑"。 - 可运行实体多、锁持有者权重低时,其得到的时间片变小,释放锁所需的"墙钟时间"增加,从而放大被阻塞高重要度线程的等待。
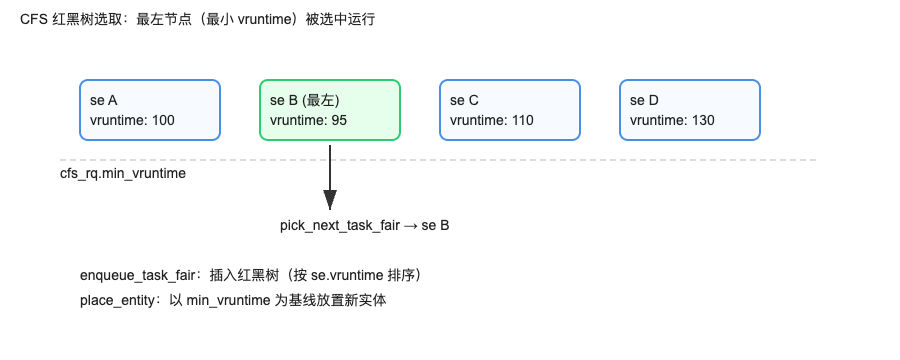
- 唤醒抢占:CFS 的交互唤醒抢占倾向让"落后"的任务更容易获得立即运行机会,有利于降低交互延迟,但并不会针对"让锁持有者尽快跑"做优先级继承。
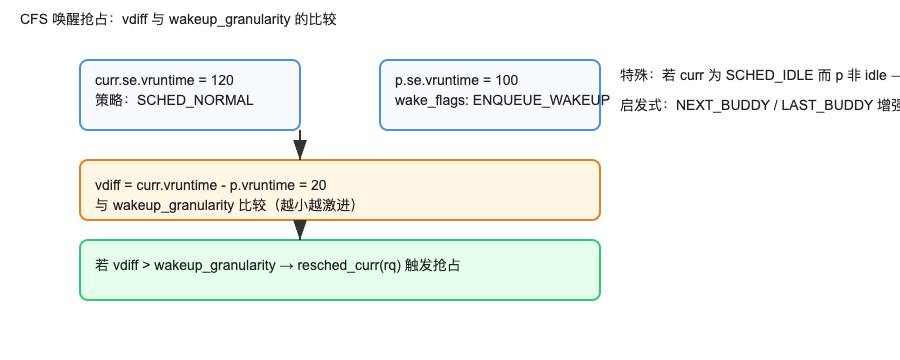
边界与系统参数
- 调度窗口与最小粒度:
kernel.sched_latency_ns控制一个调度周期长度,kernel.sched_min_granularity_ns控制每任务最小时间片。可运行者越多、权重越低,锁持有者每轮分到的时间越少。 kernel.sched_wakeup_granularity_ns影响唤醒抢占,能降低交互延迟,但对"资源释放加速"作用有限。- CFS 不做优先级继承(PI),无法在
H阻塞于L时自动把L提升至H的级别。
在 CFS 下的工程化建议
- 缩短临界区:把 I/O、复杂分配、耗时计算移出锁内;细粒度加锁或采用 RCU/无锁结构(读多写少)。
- 权重调节:提高锁持有者或关键路径线程的权重(降低
nice值),降低后台任务权重(提高nice值或用SCHED_IDLE)。 - 隔离干扰:用
sched_setaffinity/taskset绑定关键线程到独立 CPU;用 cgroups v2 的cpu.weight/cpu.max、cpuset控制与隔离负载;必要时isolcpus做物理隔离。 - 系统参数谨慎:在理解负载前提下调整
sched_latency_ns、sched_min_granularity_ns、sched_wakeup_granularity_ns,权衡整体抖动与吞吐副作用。
与实时策略的关系
- 若需要"反转消除与可预测上界",应将关键线程切到实时策略(
SCHED_FIFO/SCHED_RR)并结合支持 PI 的互斥(用户态pthread_mutexattr_setprotocol(PTHREAD_PRIO_INHERIT)或futex(FUTEX_LOCK_PI),内核态使用rt_mutex)。 - 在 CFS 保持
SCHED_OTHER时,依赖设计优化与权重/隔离手段降低反转风险,而非指望调度器提供继承。
检测与定位思路
- 跟踪阻塞点:使用
perf,ftrace,bpftrace观察mutex_lock,futex等事件的阻塞时间与等待链。 - 采样调度:分析
sched_switch,识别H阻塞后M长时间运行的模式。 - 资源画像:统计各锁持有时间分布与热点临界区;识别"跨优先级共享"的锁。
工程化清单(Checklist)
- 明确关键任务与响应时间目标;为关键锁启用 PI。
- 缩短并隔离临界区;避免在锁内进行 I/O 或复杂内存分配。
- 采用 PCP/HLP 为关键资源设定上限,限制反转上界。
- 为关键线程设置
SCHED_FIFO/RR与 CPU 亲和;隔离高负载中优先级任务。 - 建立阻塞链可视化与告警,持续监控反转与超时。
总结
优先级反转的本质是"高优先级任务被低优先级持有者与中优先级执行间接拖慢"。正确的应对策略是:在设计上减少阻塞与共享,在实现上启用优先级继承(必要时配合天花板协议),在系统层通过实时调度与资源隔离控制干扰,从而将关键任务的响应时间收敛到可预测的上界。