IDEA版本是: IntelliJ IDEA 2025.2
机器是: Mac M1 16G
可以使用IDEA自带的监控来观察在IDEA 中到底是啥进程占用了CPU的资源
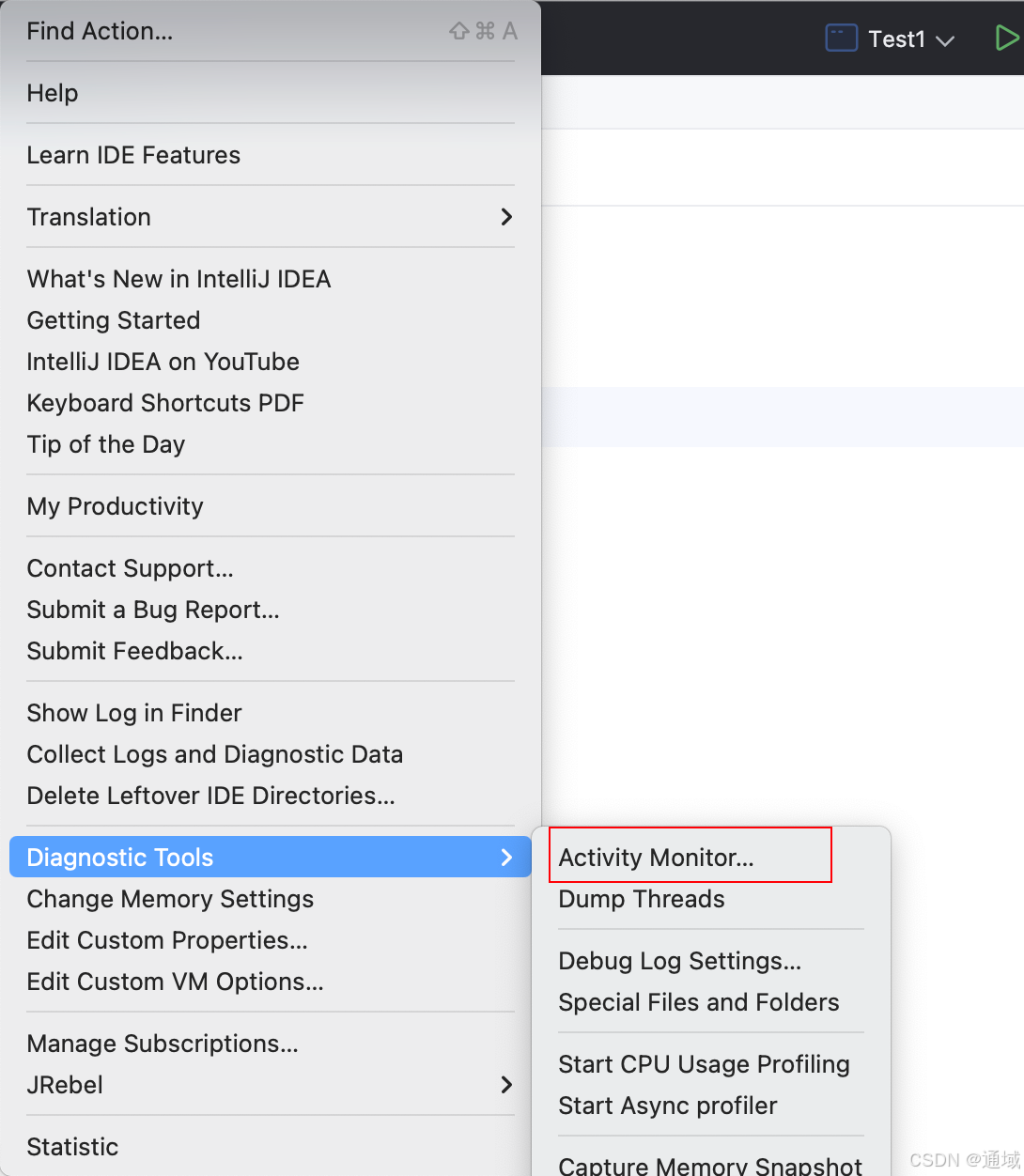
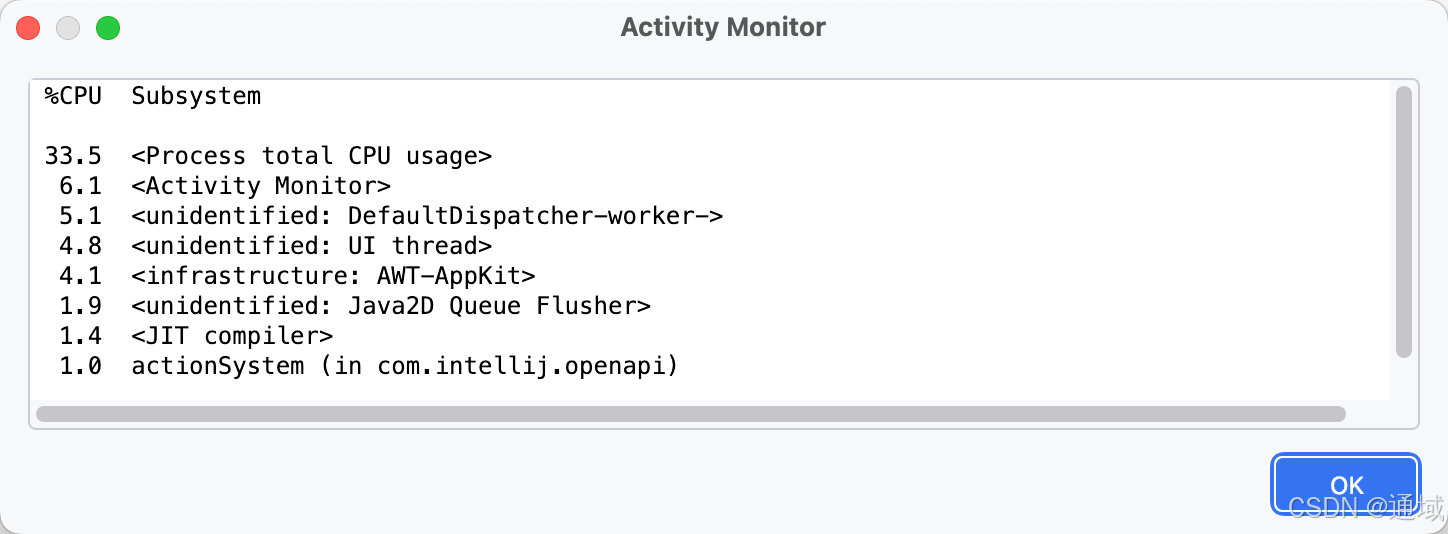
网络上大部分讲的都是因为JIT(just in time,即时编译技术)导致CPU飙升,但是经过检测发现,JIT也仅仅是IDEA卡顿的一部分原因。
观测到CPU还是会飙升,但是经过配置后,JIT所占用的CPU 确实大幅下降,说明还是有效果
shell
# JIT 参数
# 限制 JIT 编译线程数为 2,避免占用过多 CPU
-XX:CICompilerCount=2
# JIT 编译只到第一级,减少高级优化带来的编译延迟
-XX:TieredStopAtLevel=1
# 限制 inline 展开层级,降低编译复杂度
-XX:MaxInlineLevel=3
# 表示一个方法至少被调用 10 万次 之后,才会被考虑进入 Tier4 编译(最高级别的 JIT 优化)
-XX:Tier4MinInvocationThreshold=100000
# 设置 热点方法被调用多少次后 触发 Tier4 编译
-XX:Tier4InvocationThreshold=110000
# 也就是说方法需要运行 12 万次 之后才会进入最高级别的编译优化
-XX:Tier4CompileThreshold=120000后续除了JIT相关的配置,还参考了网上其它相关的配置,如栈堆配置
shell
#堆栈设置
# 设置 JVM 的初始与最大堆内存为 4 GB,最大和最小内存都保持一致,避免频繁的扩容和缩容
-Xms4096m
-Xmx4096m
# 将新生代(Young Generation)设置为 2 GB
-Xmn1024m
# 元空间(Metaspace)大小设置:通过 -XX:MetaspaceSize 与 -XX:MaxMetaspaceSize 设置为 1 GB,避免因类加载频繁导致的扩容。
-XX:MetaspaceSize=1024m
-XX:MaxMetaspaceSize=1024m
# 启动时预先访问分配的内存页,以减少运行时的内存分配延迟和分页
-XX:+AlwaysPreTouch
# JVM 的代码缓存(JIT 编译后生成的本地机器码)设置得较大,可减少运行期间对代码缓存的频繁扩容。
-XX:InitialCodeCacheSize=1200m
# JVM 的代码缓存(JIT 编译后生成的本地机器码)设置得较大,可减少运行期间对代码缓存的频繁扩容。
-XX:ReservedCodeCacheSize=1200m
# 启用压缩指针,降低对象指针占用空间,提升性能
-XX:+UseCompressedOops
# 确保 IDEA 以 UTF-8 编码运行
-Dfile.encoding=UTF-8在配置了栈堆之后,发现还是不行,有找了找资料,发现可能和GC收集器有关,所以,将垃圾回收器配置成 G1(之前配置的是CMS)
shell
# 使用G1
-XX:+UseG1GC
# 开启字符串去重功能,允许JVM在堆内存中识别出内容相同的多个字符串对象,并将它们合并为单一实例以节省空间。此选项仅与G1垃圾收集器一起使用有效。
-XX:+UseStringDeduplication
# 设置自动装箱缓存的最大大小。具体来说,就是控制Integer、Short等基本类型到其包装类转换时可以缓存的对象数量上限。这里设置为20000意味着对于-20000到20000之间的整数,系统会直接从缓存中获取相应的Integer对象而不是创建新的对象。这有助于减少内存消耗和提高性能。
-XX:AutoBoxCacheMax=20000
# 使用 4 个线程来处理垃圾回收任务,提高收集效率
-XX:ParallelGCThreads=4
# 控制软引用的回收策略,降低内存压力
-XX:SoftRefLRUPolicyMSPerMB=50
-ea # 启用断言,便于调试以下是完整的配置
shell
#堆栈设置
# 设置 JVM 的初始与最大堆内存为 4 GB
-Xms4096m
-Xmx4096m
# 将新生代(Young Generation)设置为 2 GB
-Xmn1024m
# 元空间(Metaspace)大小设置:通过 -XX:MetaspaceSize 与 -XX:MaxMetaspaceSize 设置为 1 GB,避免因类加载频繁导致的扩容。
-XX:MetaspaceSize=1024m
-XX:MaxMetaspaceSize=1024m
# 启动时预先访问分配的内存页,以减少运行时的内存分配延迟和分页
-XX:+AlwaysPreTouch
# JVM 的代码缓存(JIT 编译后生成的本地机器码)设置得较大,可减少运行期间对代码缓存的频繁扩容。
-XX:InitialCodeCacheSize=1200m
# JVM 的代码缓存(JIT 编译后生成的本地机器码)设置得较大,可减少运行期间对代码缓存的频繁扩容。
-XX:ReservedCodeCacheSize=1200m
# 启用压缩指针,降低对象指针占用空间,提升性能
-XX:+UseCompressedOops
# 确保 IDEA 以 UTF-8 编码运行
-Dfile.encoding=UTF-8
# 采用何种垃圾回收参数
# 使用G1
-XX:+UseG1GC
# 开启字符串去重功能,允许JVM在堆内存中识别出内容相同的多个字符串对象,并将它们合并为单一实例以节省空间。此选项仅与G1垃圾收集器一起使用有效。
-XX:+UseStringDeduplication
# 设置自动装箱缓存的最大大小。具体来说,就是控制Integer、Short等基本类型到其包装类转换时可以缓存的对象数量上限。这里设置为20000意味着对于-20000到20000之间的整数,系统会直接从缓存中获取相应的Integer对象而不是创建新的对象。这有助于减少内存消耗和提高性能。
-XX:AutoBoxCacheMax=20000
# 使用 4 个线程来处理垃圾回收任务,提高收集效率
-XX:ParallelGCThreads=4
# 控制软引用的回收策略,降低内存压力
-XX:SoftRefLRUPolicyMSPerMB=50
-ea # 启用断言,便于调试
# JIT 参数
# 限制 JIT 编译线程数为 2,避免占用过多 CPU
-XX:CICompilerCount=2
# JIT 编译只到第一级,减少高级优化带来的编译延迟
-XX:TieredStopAtLevel=1
# 限制 inline 展开层级,降低编译复杂度
-XX:MaxInlineLevel=3
# 表示一个方法至少被调用 10 万次 之后,才会被考虑进入 Tier4 编译(最高级别的 JIT 优化)
-XX:Tier4MinInvocationThreshold=100000
# 设置 热点方法被调用多少次后 触发 Tier4 编译
-XX:Tier4InvocationThreshold=110000
# 也就是说方法需要运行 12 万次 之后才会进入最高级别的编译优化
-XX:Tier4CompileThreshold=120000
# 控制 JVM 内部 路径规范化(canonicalization)缓存 的开关
-Dsun.io.useCanonPrefixCache=false
# 让 JVM 优先使用 IPv4 协议栈,而不是 IPv6
-Djava.net.preferIPv4Stack=true
# 默认情况下,JDK 会禁用一些 HTTP 认证隧道的协议(比如 Basic、Digest)
-Djdk.http.auth.tunneling.disabledSchemes=""
# 当 JVM 抛出 OutOfMemoryError 时,自动生成一个 堆转储文件 (.hprof)
-XX:+HeapDumpOnOutOfMemoryError
# 默认 JVM 对某些高频异常(如 NullPointerException, ArrayIndexOutOfBoundsException)会优化:重复抛时 不再生成完整的栈轨迹,提高性能。
-XX:-OmitStackTraceInFastThrow
# 允许 JVM 附加(attach)到自身进程。这通常用于 Profiler、诊断工具(如 jconsole、jvisualvm、YourKit、Async Profiler) 等需要 attach 的场景。
-Djdk.attach.allowAttachSelf