快看!前方好像有什么人在争吵。
我这个文件上传了这么多,怎么又要重新开始上传啊?
我这个网页怎么又卡住了。
切图仔快来看看!
啊啊啊! 前方突然传来一声尖叫,只见一个年轻人"颤颤巍巍"地从工位上站起,指着他后方的同事,随后大喊一声:"你不要再叫我切图仔啦!"
话音刚落,只见后方同事表现出一副嗤之以鼻的样子,随后带着一丝轻蔑,对着那个年轻人又撂下一句:"切图仔!"。
随即,那个年轻人全身都在颤抖,仿佛就要......
引言
开始学习。
下文将带你打通从前端文件分片、文件哈希计算、Web Worker用法、文件断点续传和秒传,到后端分片接收、文件合并的完整技术链条。
后端 基于 Node.js + Express 框架,使用 formidable 库高效处理分片数据,最终将分片合并为完整文件。
前端 采用 Vue 3 + TS + Vite 构建,使用 Naive UI 写个好看点的上传进度监控界面,并利用 Web Worker 线程计算文件哈希。
关键词: 文件分片、文件秒传、断点续传、上传进度、文件hash、Web Worker、Node.js
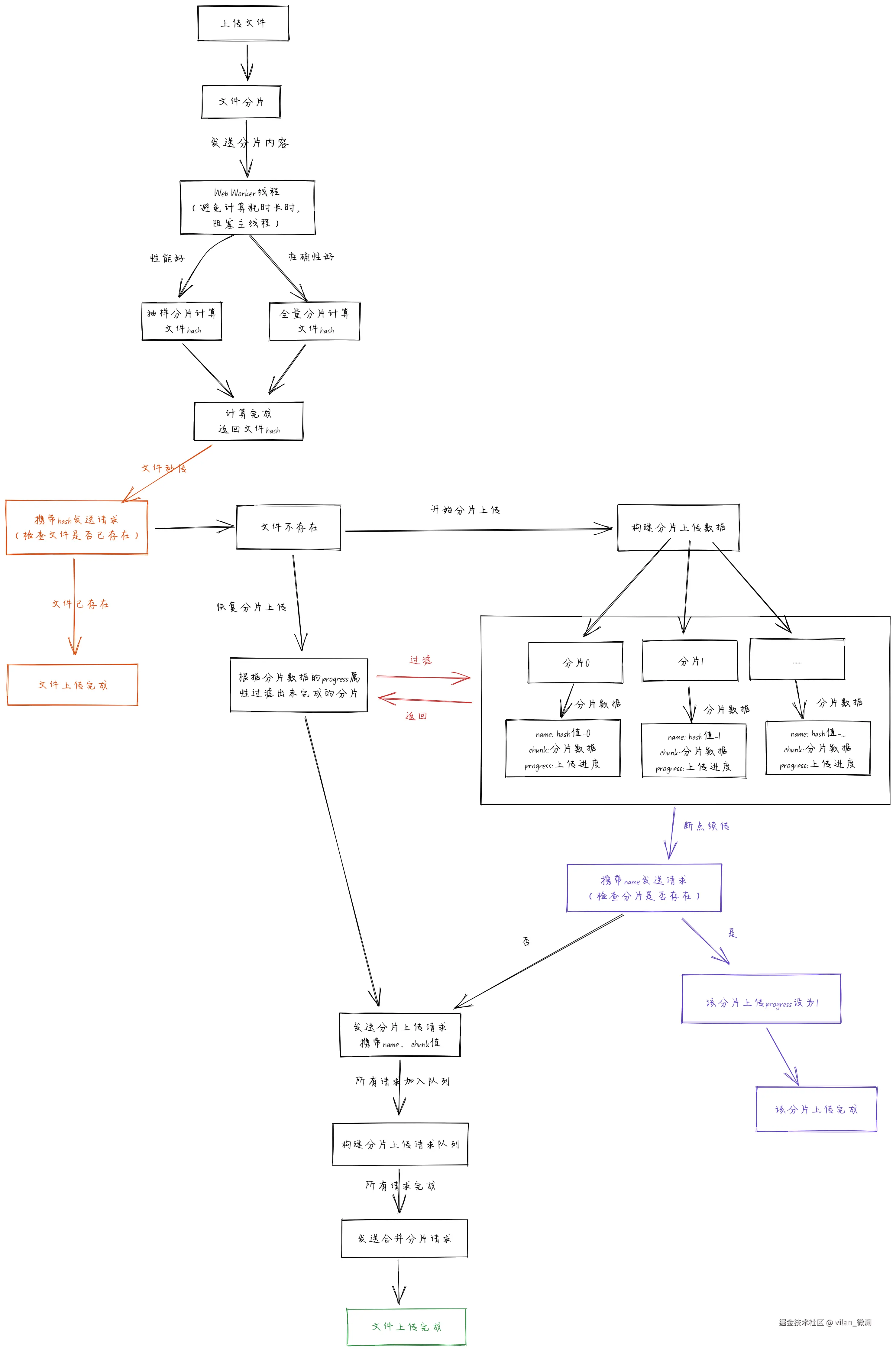
实现原理图解
下面两张图 展示了从前端 上传文件分片到后端 解析分片数据并写入文件、合并分片文件的全套功法。
前端实现图解
后端实现图解

看完图解大概理解实现流程就可以上手写代码了
前端实现代码
首先我们的目的是封装一个提供大文件上传功能的函数,由于函数中又涉及到页面的一些响应式状态 ,比如上传进度,那么我们姑且就叫它为hook函数吧,然后把它命名为useBigFileUpload.ts
下面先把需要用到的属性和类型先写上,其他方法后面再逐步完善。
ts
import axios, { type AxiosProgressEvent, type AxiosResponse } from "axios";
import { createDiscreteApi } from "naive-ui";
import { computed, markRaw, ref } from "vue";
const baseUrl = "http://localhost:3000";
// axios实例化
const http = axios.create({
baseURL: baseUrl,
});
const { message } = createDiscreteApi(["message"]);
type Props = {
chunkSize: number;
};
type ChunkRequestQueue = {
promise: Promise<AxiosResponse>;
abortController: AbortController;
};
export type Chunk = {
// 切片数据
chunk: Blob;
// 当前切片索引
index: number;
// 切片文件名
name: string;
// 总大小
size: number;
// 已上传大小
uploaded: number;
// 请求总进度
requestSize: number;
// 是否完成上传
completed: boolean;
// 上传进度
progress: number;
};
export const useBigFileUpload = (
props: Props = {
chunkSize: 1024 * 1024 * 1,
}
) => {
// 当前计算hash进度
const hashProgress = ref(0);
// 是否暂停了上传
const isPuase = ref(false);
// 当前上传的文件
let fileTarget: File | null = null;
// 文件哈希值+文件后缀名
let fileHash = "";
// 当前上传切片数组
const chunks = ref<Chunk[]>([]);
// 当前上传请求队列
let chunkReqQueueList: ChunkRequestQueue[] = [];
// 当前上传完成的切片/总切片数
const percentage = computed(() => {
const chunkSize = chunks.value.length;
if (chunkSize === 0) {
return 0;
}
const conpletedChunks = chunks.value.filter((chunk) => chunk.completed);
return (conpletedChunks.length / chunkSize) * 100;
});
return {
percentage,
chunks,
isPuase,
hashProgress,
};
};文件切片
创建createChunks方法,对大文件进行切片
ts
// 创建切片,切片大小可根据自身需求调整
const createChunks = (
file: File,
chunkSize: number = props.chunkSize
): Blob[] => {
const chunks: Blob[] = [];
for (let i = 0, j = 0; i < file.size; i += chunkSize, j++) {
chunks.push(file.slice(i, i + chunkSize));
}
return chunks;
};通过分片计算文件hash值,其中有两种计算类型:
1.抽样分片计算。通过抽取文件的一部分分片进行一部分文件内容的hash值计算,这种方法可以节省计算耗时。
2.全量分片计算。通过所有分片计算完整的文件内容hash值,这个方法计算的值会比较准确,但是计算耗时相对多一些。
下面我们采用 的是第二种方法进行计算。
文件hash计算
在你的项目的utils工具包中创建file-hash.work.js文件,计算文件内容hash值的Web Worker方法
js
// 在 utils/workers/file-hash.work.js 中
// 引入 SparkMD5 计算文件内容hash
// importScripts('/spark-md5@3.0.2/spark-md5.min.js');
importScripts('https://cdn.jsdelivr.net/npm/spark-md5@3.0.2/spark-md5.min.js');
self.onmessage = function (e) {
// 从主线程接收分片数据
const { chunks } = e.data;
// 创建 SparkMD5 实例
const spark = new SparkMD5.ArrayBuffer();
// 读取切片
function readChunk(index) {
if (index >= chunks.length) {
// 所有分片处理完毕,计算最终哈希
const hash = spark.end();
// 向主线程发送最终计算的哈希值
self.postMessage({ index, hash });
// 所有分片处理完毕,关闭worker
self.close();
return;
}
// 创建 FileReader 实例, 用于读取分片数据
const fileReader = new FileReader();
// 读取分片数据
fileReader.readAsArrayBuffer(chunks[index]);
// 分片数据加载完成事件监听
fileReader.onload = (e) => {
// 追加到 SparkMD5 实例
spark.append(e.target.result);
// 向主线程发送计算进度索引
self.postMessage({ index });
// 读取下一个分片
readChunk(index + 1);
};
}
// 从索引0开始读取分片
readChunk(0);
};在utils文件夹下写好worker工具函数后,继续在useBigFileUpload函数当中添加getHashWorker方法异步获取文件hash值。
ts
/**
* 计算文件哈希值
* @param tempChunks 切片数组
* @returns 文件哈希值
*/
const getHashWorker = async (tempChunks: Blob[]): Promise<string> => {
hashProgress.value = 0;
return new Promise((resolve) => {
// 导入worker线程,计算文件哈希值
const worker = new Worker(
new URL("../utils/workers/file-hash.work.js", import.meta.url)
);
// 向worker线程发送消息,计算文件哈希值
worker.postMessage({
chunks: tempChunks,
});
// 监听worker线程消息,获取计算文件哈希值结果
worker.onmessage = (e) => {
const { index, hash } = e.data;
// 计算当前计算hash进度
if (tempChunks.length) {
hashProgress.value = (index / tempChunks.length) * 100;
}
if (hash) {
// 完成计算哈希值
resolve(hash);
}
};
});
};拿到hash值后就可以通过该值查询服务器是否存在该文件,来实现大文件秒传
文件秒传
通过hash查询服务器是否存在该文件,前端根据返回结果判断是否需要进行文件上传,已存在则直接显示上传完成,否则接着下面进行分片上传。
ts
/**
* 检查文件是否已经上传
* @param fileHash 文件哈希值
* @returns 检查结果
*/
const checkFileApi = async (fileHash: string) => {
// 通过文件hash检查是否已经上传了该文件
const res = await http.get(`${baseUrl}/check/file?fileHash=${fileHash}`);
// 返回检查结果
return res.data.hasExist
}文件断点续传
主要是通过检查服务器是否已经存在该分片,并返回查询结果,前端根据查询结果判断是否需要调用分片上传请求方法。
ts
/**
* 检查切片是否已经上传
* @param chunkName 切片名
* @returns 检查结果
*/
const checkChunkApi = async (chunkName: string) => {
// 创建中断请求器
const abortController = new AbortController();
// 发生请求前先验证切片是否已经上传
const res: AxiosResponse<{
code: number;
message: string;
hasExist: boolean;
}> = await http.get(`${baseUrl}/chunk/check?chunkName=${chunkName}`, {
signal: abortController.signal,
});
return {
res: res,
abortController,
}
};分片上传请求
创建开始分片上传请求方法uploadChunkApi
ts
/**
* 上传切片
* @param data 切片数据
* @returns ChunkRequestQueue 上传请求对象
*/
const uploadChunkApi = (data: Chunk): ChunkRequestQueue => {
const { name, index, chunk } = data;
const formData = new FormData();
formData.append("chunk", chunk);
// 创建中断请求器
const abortController = new AbortController();
const promise = http.post(`${baseUrl}/chunk?chunkName=${name}`, formData, {
signal: abortController.signal,
onUploadProgress: (progressEvent: AxiosProgressEvent) => {
// 计算上传进度
if (
chunks.value[index] &&
progressEvent.total &&
progressEvent.progress
) {
// 记录当前上传切片请求进度。
// 注意,由于网络请求具有额外开销,上传进度可能会和切片大小不一样
chunks.value[index].uploaded = progressEvent.loaded;
// 记录当前上传切片请求总大小
// 注意,由于网络请求具有额外开销,上传进度可能会和切片大小不一样
chunks.value[index].requestSize = progressEvent.total;
// 计算上传进度
chunks.value[index].progress = progressEvent.progress;
}
},
});
return {
promise,
abortController,
};
};在发送分片上传http请求的方法中,监听了axios的onUploadProgress回调方法,在该方法里面可以拿到请求的完成进度,其中记录了AxiosProgressEvent的3个属性:uploaded、total、progress。主要是progress页面显示上传进度需要,其他如果页面不需要显示,可有可无吧。
最后把当前请求的promise对象和中断请求的abortController对象返回,放入请求队列当中。
当需要暂停上传时,可以使用abortController进行中断请求。
分片合并请求
创建合并切片请求方法mergeChunksApi,当请求队列中的分片都成功上传后,调用该方法并携带fileHash文件标识,用于服务器找到该文件分片所在位置,合并成功后,文件即上传完成。
ts
/**
* 合并切片
* @param fileHash 文件哈希值
* @returns 合并结果
*/
const mergeChunksApi = (fileHash: string) => {
return http.post(`/merge-chunk`, {
fileHash,
});
};开始上传文件
上面的准备工作就绪后,就可以创建上传文件方法了。
ts
/**
* 开始上传
* @param file
* @param resume 是否恢复上传
*/
const startUpload = async (file: File, resume: boolean = false) => {
if (!file) {
message.error("请先选择文件!");
return;
}
// 恢复上传不用重新创建切片,延续之前的切片进度
if (!resume) {
// 保存文件,用于后续恢复上传
fileTarget = file;
// 重置暂停状态,避免重复上传时暂停状态为true导致问题
isPuase.value = false;
// 创建切片
const tempChunks = createChunks(file);
// 计算文件哈希值,并拼接文件后缀名
fileHash =
(await getHashWorker(tempChunks)) + "." + file.name.split(".").pop();
// 构建切片对象数组
chunks.value = tempChunks.map((chunk, i) => {
return {
name: buildChunkName(fileHash, i),
chunk: markRaw(chunk),
index: i,
size: props.chunkSize,
uploaded: 0,
requestSize: 0,
progress: 0,
get completed() {
return this.progress === 1;
},
};
});
}
// 通过文件hash检查是否已经上传了该文件
const hasExist = await checkFileApi(fileHash);
if (hasExist) {
message.warning("文件已存在,无需重复上传");
return;
}
// 如果是暂停后恢复上传时,过滤出未上传完成的切片
const waitUploadChunks = chunks.value
.filter((chunk) => {
return !chunk.completed;
});
// 遍历未完成上传的切片
for (let i = 0; i < waitUploadChunks.length; i++) {
const chunk = waitUploadChunks[i] as Chunk;
const name = chunk.name;
// 创建中断请求器
const abortController = new AbortController();
// 发生请求前先验证切片是否已经上传
const res: AxiosResponse<{
code: number;
message: string;
hasExist: boolean;
}> = await http.get(`${baseUrl}/chunk/check?chunkName=${name}`, {
signal: abortController.signal,
});
// 暂停了直接退出for循环,且不再执行for循环后面的代码
if (isPuase.value) return;
if (res.data.hasExist) {
chunkReqQueueList[i] = {
// 返回校验结果
promise: Promise.resolve(res),
// 校验切片是否存在中断器
abortController,
};
chunk.progress = 1;
} else {
// 切片不存在,继续上传
chunkReqQueueList[i] = uploadChunkApi(chunk);
}
}
if (chunkReqQueueList.length > 0) {
await Promise.all(
chunkReqQueueList.map((item) => item.promise)
);
// 合并切片
await mergeChunksApi(fileHash);
}
};buildChunkName方法
构建和服务器达成约定的分片名称,服务器可通过-分割获取分片所属文件;在合并分片时可根据index索引进行排序合并,保证文件的完整性。
ts
/**
* 构建切片名
* @param hash 文件哈希值
* @param index 切片索引
* @returns 切片名
*/
const buildChunkName = (hash: string, index: number) => {
return `${hash}-${index}`;
};在开始上传的startUpload方法中具有两种情况,分别为开始上传 和恢复上传。
开始上传时,执行完整的步骤;在恢复上传时,可根据开始上传时的状态,过滤出未上传的分片waitUploadChunks数组,再发送分片上传请求,避免不必要的性能损耗。
暂停上传文件
ts
// 暂停切片上传
const pauseUpload = () => {
if (!isPuase.value) {
isPuase.value = true;
chunkReqQueueList.forEach((req) => {
if (req.abortController) {
req.abortController.abort("用户取消上传!");
}
});
// 清空上传队列
chunkReqQueueList = [];
} else {
message.warning("文件已暂停上传!");
}
};恢复上传文件
ts
// 恢复切片上传
const resumeUpload = () => {
if (fileTarget && isPuase.value) {
isPuase.value = false;
startUpload(fileTarget, true);
} else {
message.warning("文件正在上传中!");
}
};ui页面构建(用法)
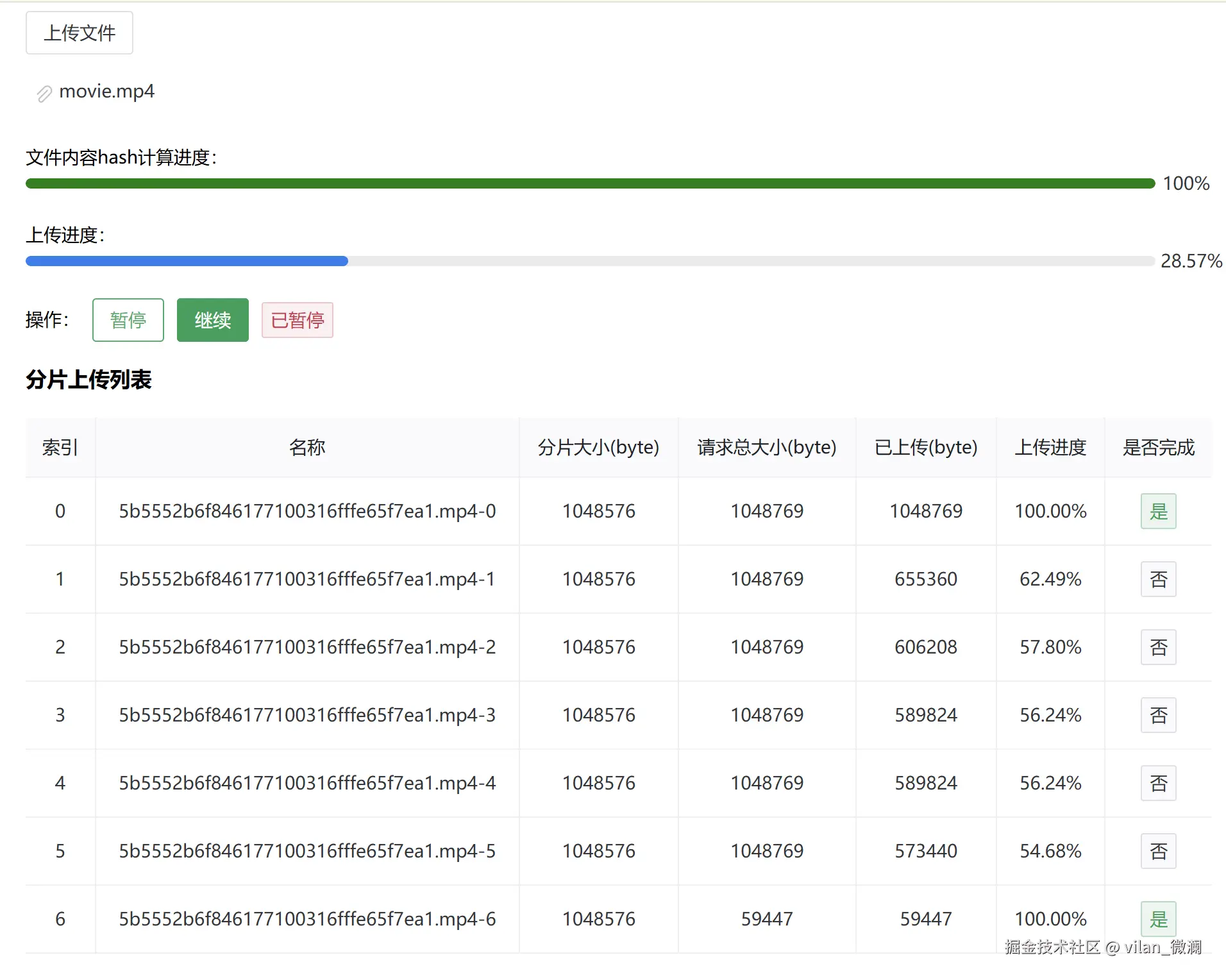
BigFileUpload.vue
ts
<template>
<div class="upload-file">
<n-upload @before-upload="onUpload">
<n-button>上传文件</n-button>
</n-upload>
<div class="section">
<div>
<span>文件内容hash计算进度:</span>
<n-progress type="line" color="green" :percentage="hashProgress" />
</div>
</div>
<div class="percentage section">
<div>
<span>上传进度:</span>
<n-progress type="line" :percentage="progress" />
</div>
</div>
<div class="actions section">
<span>操作:</span>
<n-button type="default" @click="onPause">暂停</n-button>
<n-button type="primary" @click="onResume">继续</n-button>
<n-tag type="error" v-if="isPuase">已暂停</n-tag>
</div>
<div class="chunk-list">
<h3>分片上传列表</h3>
<ChunkDetail
:list="chunks"
></ChunkDetail>
</div>
</div>
</template>
<script setup lang="ts">
import { NUpload, NButton, useMessage, NProgress, NTag } from "naive-ui";
import type { UploadFileInfo } from "naive-ui";
import { useBigFileUpload } from "@/hooks/useBigFileUpload";
import ChunkDetail from "./ChunkDetail.vue";
import { computed } from "vue";
const {
percentage,
startUpload,
pauseUpload,
resumeUpload,
chunks,
isPuase,
hashProgress
} = useBigFileUpload();
const message = useMessage();
const progress = computed(() => {
return parseFloat(percentage.value.toFixed(2))
})
const onUpload = (data: {
file: UploadFileInfo;
fileList: Array<UploadFileInfo>;
event?: Event;
}) => {
console.log(data);
const file = data.file.file;
if (!file) {
message.error("请选择文件!");
return;
}
startUpload(file);
};
const onPause = () => {
pauseUpload();
};
const onResume = () => {
resumeUpload();
};
</script>
<style scoped>
.upload-file {
width: 1000px;
padding: 20px;
}
.actions {
display: flex;
align-items: center;
gap: 10px;
}
.chunk-list {
height: 600px;
overflow-y: auto;
}
.section {
margin-top: 20px;
}
</style>ChunkDetail.vue
ts
<template>
<div class="chunk">
<n-table :bordered="false" :single-line="false">
<thead>
<tr align="center">
<th>索引</th>
<th>名称</th>
<th>分片大小(byte)</th>
<th>请求总大小(byte)</th>
<th>已上传(byte)</th>
<th>上传进度</th>
<th>是否完成</th>
</tr>
</thead>
<tbody>
<tr v-for="data in list" :key="data.index" align="center">
<td>{{ data.index }}</td>
<td>{{ data.name }}</td>
<td>{{ data.size}}</td>
<td>{{ data.requestSize }}</td>
<td>{{ data.uploaded }}</td>
<td>{{ (data.progress * 100).toFixed(2) }}%</td>
<td>
<n-tag v-if="data.completed" type="success">是</n-tag>
<n-tag v-else>否</n-tag>
</td>
</tr>
</tbody>
</n-table>
</div>
</template>
<script setup lang="ts">
import { NTable, NTag } from "naive-ui";
import type { Chunk } from "@/hooks/useBigFileUpload";
defineProps<{
list: Chunk[];
}>();
</script>后端实现代码
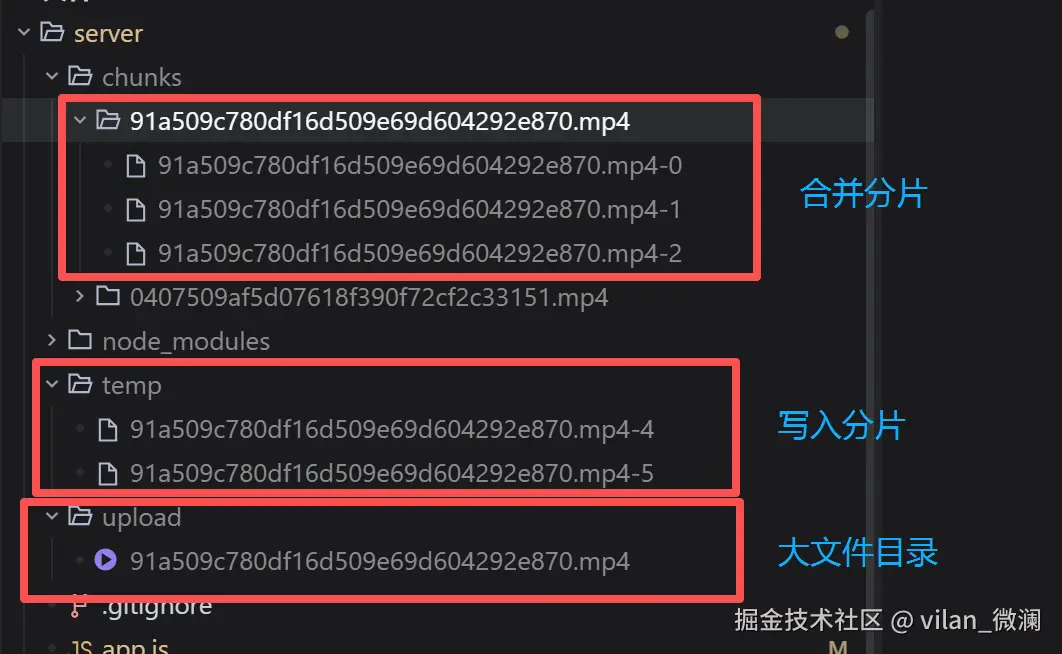
文件上传目录示例
temp: 解析分片数据写入的临时目录,写入的分片可能不完整;
chunks: 写入完成的分片文件目录;
upload: 分片合并完成的文件目录;
查询文件是否存在接口
在upload文件夹下,通过文件hash查询,是否存在该hash文件名的文件
js
// 查询mergeDir目录下是否存在上传的文件
app.get('/check/file', (req, res) => {
const fileHash = req.query.fileHash;
const filePath = path.join(mergeDir, fileHash);
const hasExistFile = fs.existsSync(filePath);
if (hasExistFile) {
res.json({
code: 200,
message: '文件已存在',
hasExist: true
})
} else {
res.json({
code: 200,
message: '文件不存在',
hasExist: false
})
}
})查询分片是否存在接口
在chunks目录下的文件hash所属目录下,查询是否存在该hash索引的分片。
js
// 验证切片是否已存在接口
app.get('/chunk/check', (req, res) => {
// 切片文件名称
const chunkName = req.query.chunkName
// 从切片文件名称中提取文件hash
const fileHash = extractFileHash(chunkName);
// 待合并的分片目录路径
const chunkPath = path.join(chunkDir, fileHash, chunkName);
// 检查当前切片文件是否已经存在
const hasExistFile = fs.existsSync(chunkPath);
console.log('hasExistFile', hasExistFile, chunkPath);
if (hasExistFile) {
// 直接响应。不再执行后续中间件,如后面的回调upload.single('chunk')、切片上传成功回调
res.json({
code: 200,
message: '切片已存在,跳过该切片上传',
hasExist: true
})
return
} else {
// 切片不存在
res.json({ code: 200, message: '切片不存在,继续上传', hasExist: false })
}
return hasExistFile
})分片上传接口
js
// 从分片名称提取文件hash
// 如:chunkName: 91a509c780df16d509e69d604292e870.mp4-0
function extractFileHash(chunkName) {
return chunkName.split('-')[0];
}
// 分片存放路径
const chunkDir = path.join(process.cwd(), 'chunks');
// 处理分片文件上传。
app.post('/chunk', async (req, res) => {
const chunkName = req.query.chunkName;
const fileHash = extractFileHash(chunkName);
// 判断当前目录没有temp文件夹,则创建
if (!fs.existsSync('./temp')) {
fs.mkdirSync('./temp', { recursive: true });
}
// 使用formidable解析表单数据
const form = formidable({
uploadDir: './temp', // 临时存储路径
keepExtensions: true,
filename: () => {
return chunkName
}
});
try {
// 解析表单数据,并把分片写入临时目录中
const [fields, files] = await form.parse(req);
const chunkFile = files.chunk[0];
if (!fs.existsSync(chunkDir)) {
fs.mkdirSync(chunkDir, { recursive: true });
}
// 将临时文件移动到 chunkDir 目录
const fileHashDir = path.join(chunkDir, fileHash);
const targetPath = path.join(fileHashDir, chunkName);
if (!fs.existsSync(fileHashDir)) {
fs.mkdirSync(fileHashDir, { recursive: true });
}
fs.renameSync(chunkFile.filepath, targetPath)
} catch (error) {
return res.status(500).json({ msg: '分片上传失败', error: error });
}
res.send({
code: 200,
message: '分片上传成功',
file: req.file
});
});合并分片接口
js
// 合并切片
app.post('/merge-chunk', (req, res) => {
const { fileHash } = req.body;
if (!fileHash) {
return res.status(400).send({ success: false, message: '缺少fileHash参数' });
}
// 合并后的文件路径,如果不存在则创建该目录
if (!fs.existsSync(mergeDir)) {
fs.mkdirSync(mergeDir, { recursive: true });
}
const mergeFilePath = path.join(mergeDir, fileHash);
const chunkHashDir = path.join(chunkDir, fileHash);
// 读取目录下所有切片文件,按 index 排序
const chunkFilenames = fs.readdirSync(chunkHashDir)
// 按 index 排序
.sort((a, b) => {
const indexA = parseInt(a.split('-').pop(), 10);
const indexB = parseInt(b.split('-').pop(), 10);
return indexA - indexB;
});
// 创建可写流,合并切片
const writeStream = fs.createWriteStream(mergeFilePath);
let mergedSize = 0;
try {
for (const chunkname of chunkFilenames) {
// 创建可读流,读取切片
const chunkPath = path.join(chunkHashDir, chunkname);
// 读取切片
const data = fs.readFileSync(chunkPath);
// 写入合并后的文件
writeStream.write(data);
// 累加合并后的文件大小
mergedSize += data.length;
// 删除已合并的切片
fs.unlinkSync(chunkPath);
}
// 删除空目录
fs.rmdirSync(chunkHashDir);
// 合并完成后关闭流
writeStream.end();
} catch (err) {
return res.status(500).send({ success: false, message: '合并失败!', error: err.message });
}
res.send({
success: true,
message: '文件合并成功',
file: {
fileHash,
size: mergedSize,
path: mergeFilePath,
chunkFilenames
}
});
});总结
本文使用文件对象的slice方法对大文件进行分片,使用SparkMD5对文件内容进行hash计算,并把计算过程执行在Web Worker线程当中,避免阻塞主线程;
实现分片上传 的核心 是使用文件hash和分片索引 ,对分片名称进行标识 和排序,方便后端查找和排序分片,最后合并分片为一个完整的文件。
前后端完整源码
github地址:大文件上传示例代码