Spring AI RAG 体验项目
一个rag应用包含如下几个阶段。为了方便搭建上线,很多阶段可以用云厂商的服务,不用自己准备资源、找开源实现啥的。本文会调用阿里云的百炼大模型。Embaddings、Rerank和LLM阶段调用阿里云的服务,会产生费用。
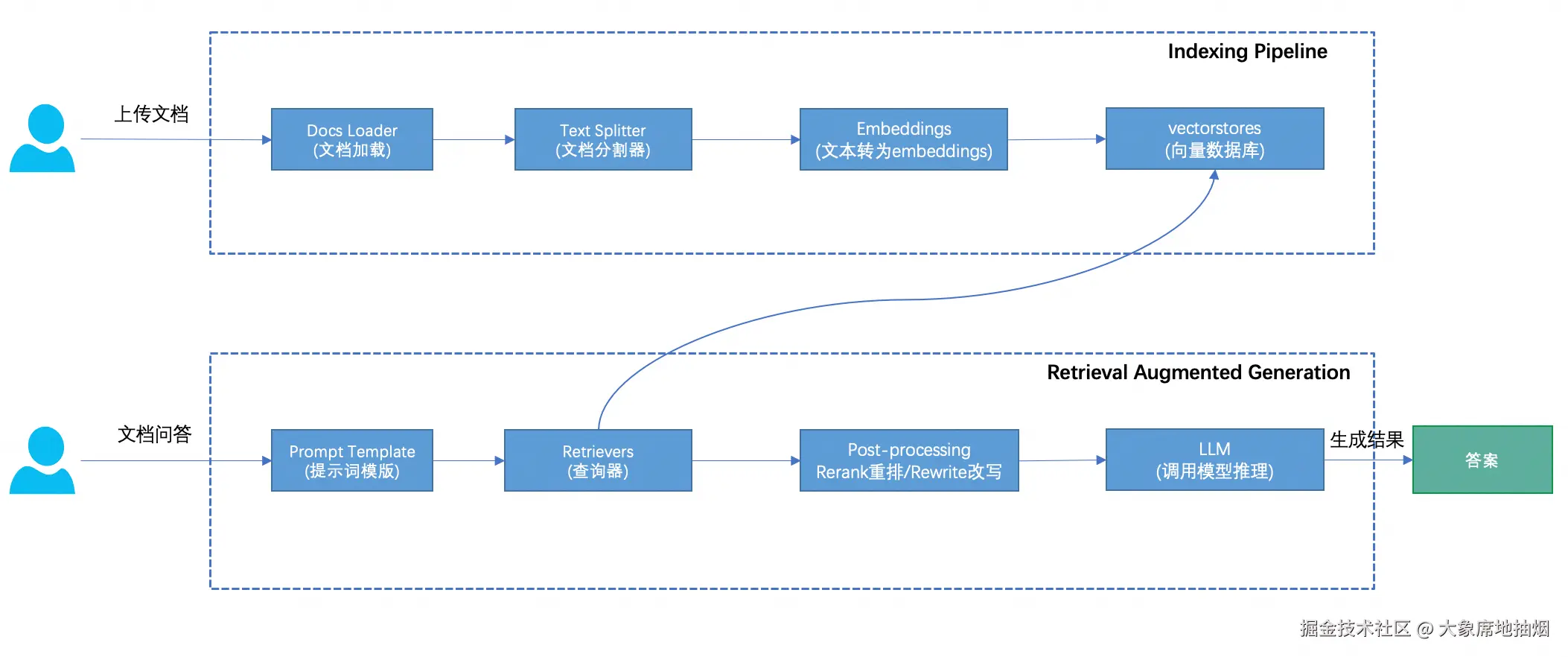
原图: java2ai.com/docs/dev/pr...
依赖
java 21, spring boot 3.3.3, milvus 2.6.4.
spring ai alibaba 的仓库 github.com/spring-ai-a... , 包含许多 Example 模块项目来介绍 Spring AI 和 Spring AI Alibaba 从基础到高级的各种用法和 AI 项目的最佳实践。
主要依赖如下: pom.xml
xml
<properties>
<spring-ai.version>1.0.0-M5</spring-ai.version>
<spring-ai-alibaba.version>1.0.0-M5.1</spring-ai-alibaba.version>
</properties>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>${spring-ai-alibaba.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store</artifactId>
<version>${spring-ai.version}</version>
</dependency>
</dependencies>项目配置
application.yaml
yaml
spring:
debug: true
application:
name: handbook
ai:
dashscope:
api-key: ${MY_APP_API_KEY}
milvus:
host: mydevcvm # 域名,配置了hosts
port: 19530
token: "root:Milvus"
database: "ragtestdatebase"
collection: "ragtestcollection"MY_APP_API_KEY是配置在环境变量中的密钥,在百炼大模型的控制台取得,如下

向量数据库
单机部署的,参考 milvus基本概念和使用
java
@Configuration
public class VectorStoreConfig {
/**
* 定义一个名为 milvusServiceClient 的Bean,用于创建并返回一个 MilvusServiceClient 实例。
*/
@Bean
public MilvusServiceClient milvusServiceClient() {
try {
// 创建 MilvusServiceClient 实例
MilvusServiceClient client = new MilvusServiceClient(ConnectParam.newBuilder().withHost(host).withPort(port).build());
// 测试连接状态 - 尝试列出所有数据库
R<ListDatabasesResponse> response = client.listDatabases();
if (response.getStatus() == R.Status.Success.getCode()) {
logger.info("Milvus 连接成功! 服务器上的数据库数量: {}", response.getData().getDbNamesCount());
} else {
logger.error("Milvus 连接失败! 错误信息: {}", response.getMessage());
throw new RuntimeException("Failed to connect to Milvus server: " + response.getMessage());
}
return client;
} catch (Exception e) {
logger.error("创建 MilvusServiceClient 失败! 主机: {}, 端口: {}", host, port, e);
throw new RuntimeException("Failed to create MilvusServiceClient", e);
}
}
/**
* 定义一个名为 vectorStore2 的Bean,用于创建并返回一个 VectorStore 实例。
*/
@Bean(name = "vectorStore2")
public VectorStore vectorStore(MilvusServiceClient milvusClient, EmbeddingModel embeddingModel) {
return MilvusVectorStore.builder(milvusClient, embeddingModel) // 嵌入模型实例,用于将文本转换为向量表示
.collectionName(collection)
.databaseName(database)
.embeddingDimension(1536) // 向量嵌入维度,设置为1536,这通常与使用的嵌入模型(如OpenAI的text-embedding-ada-002)匹配
.indexType(IndexType.IVF_FLAT) // 设置为IVF_FLAT(倒排文件Flat索引),是一种常用的近似最近邻搜索索引
.metricType(MetricType.COSINE)
.batchingStrategy(new TokenCountBatchingStrategy())
.initializeSchema(false).build();
}
}- @Bean(name = "vectorStore2") 起一个名字,否则会跟默认的冲突
- 启动器
spring-ai-alibaba-starter包含了阿里百炼(DashScope)相关模型的自动配置类,会根据配置自动创建EmbeddingModel的实现类实例, 是一个文本嵌入模型 initializeSchema参数控制在构建MilvusVectorStore时是否自动初始化数据库架构。启动项目时要事先在Milvus创建database, 不用创建collection。第一次运行项目时,initializeSchema参数为True,之后为False。
解析文档并存到向量数据库
向量数据库中的数据,可以在应用上线之前生成(可能数据量很大),也可以项目上线之后,不断调用接口投喂。
本例项目的 resources/docs/ 目录下放置了一个名为 handbook.pdf 文件,是22年的一份关于疫情奥密克戎的问答。该文件将被解析并进行向量化处理,以便后续的检索增强生成(RAG)流程能够基于此文档内容进行检索和验证。通过这一过程,可以评估RAG在本地知识库检索中的准确性和有效性。
java
@GetMapping("/insertDocuments")
public String insertDocuments() throws IOException {
// 1. parse document
DocumentReader reader = new PagePdfDocumentReader(springAiResource);
List<Document> documents = reader.get();
logger.info("{} documents loaded", documents.size());
// 2. split trunks
List<Document> splitDocuments = new TokenTextSplitter().apply(documents);
logger.info("{} documents split", splitDocuments.size());
// 3. create embedding and store to vector store
logger.info("create embedding and save to vector store");
vectorStore.add(splitDocuments);
return "success";
}当调用 vectorStore.add(splitDocuments) 时,内部会执行以下操作:
- 遍历文档集合:对传入的
splitDocuments列表中的每个Document对象进行处理 - 调用 EmbeddingModel:使用初始化时注入的
EmbeddingModel对文档内容生成向量表示 - 向量存储:将生成的向量与文档元数据一起存储到 Milvus 向量数据库中
/resouces/docs/目录下面还包含了system-sa.st文件,内容如下。
你是一个专业的智能问答助手。请根据以下提供的上下文信息来回答用户的问题。
如果上下文信息不足以回答用户的问题,请直接告知用户"根据我掌握的知识,暂时无法回答这个问题",不要编造答案。
上下文信息如下:
{{question_answer_context}}- 第二句:
如果上下文信息不足以回答用户的问题,请直接告知用户"根据我掌握的知识,暂时无法回答这个问题",不要编造答案。存在与否对结果影响很大,因为handbook.pdf文档内容很少,非常容易匹配不到。 question_answer_context是默认的一个占位符
ChatModel
chatModel是基于Spring AI框架的标准聊天模型接口,通过Spring AI Alibaba自动配置机制初始化,具体实现来自阿里通义千问(DashScope)大模型服务。
打印了一下具体调用的那个LLM, 是qwen-plus。
java
// Bean构建完成后执行
@PostConstruct
public void printInfo() {
logger.info("Bean构建完成!打印信息:{}", chatModel.getDefaultOptions().toString());
}
bash
Bean构建完成!打印信息:DashScopeChatOptions: {"proxyToolCalls":false,"model":"qwen-plus","temperature":0.8,"enable_search":false,"incremental_output":true,"multi_model":false}文档问答
java
/**
* 根据用户输入的消息生成JSON格式的聊天响应。
* 创建一个 SearchRequest 对象,设置返回最相关的前2个结果。
* 从 systemResource 中读取提示模板。
* 使用 ChatClient 构建聊天客户端,调用 RetrievalRerankAdvisor 进行检索和重排序,并生成最终的聊天响应内容。
*/
@GetMapping(value = "/ragJsonText", produces = MediaType.APPLICATION_STREAM_JSON_VALUE + ";charset=UTF-8")
public String ragJsonText(@RequestParam(value = "message", defaultValue = "今夕是何年?") String message) throws IOException {
SearchRequest searchRequest = SearchRequest.builder().topK(2).build();
String promptTemplate = systemResource.getContentAsString(StandardCharsets.UTF_8);
return ChatClient.builder(chatModel)
.defaultAdvisors(new RetrievalRerankAdvisor(vectorStore, rerankModel, searchRequest, promptTemplate, 0.8))
.build().prompt().user(message).call().content();
}RetrievalRerankAdvisor(com.alibaba.cloud.ai.advisor.RetrievalRerankAdvisor)是ChatClient的默认增强顾问,这里在使用的时候只是调整了一下参数。它的两个核心方法是before和doRerank:before方法在调用大模型前执行预处理操作:
- 它接收用户原始查询和提示模板
- 调用vectorStore检索与用户查询相关的文档
- 调用doRerank方法对检索结果进行重排序
- 构建包含重排序后文档的上下文信息
- 将上下文信息注入到提示模板中,生成完整的提示内容
- 返回增强后的提示,供大模型生成回答使用
从vectorStore检索到的数据,需要先进行重排序,目的是规避向量检索的一些局限性。重排序依赖的rerankModel要调用百炼的服务。
下面是不使用重排序的一个版本。基本上是对before方法的一个重新实现。期望它能够根据handbook中的Q/A回答。
yaml
public String ragJsonText2(@RequestParam(value = "message", defaultValue = "今夕是何年?") String message) throws IOException {
SearchRequest searchRequest = SearchRequest.builder().query(message).topK(2).build();
String promptTemplate = systemResource.getContentAsString(StandardCharsets.UTF_8);
logger.info("使用的Prompt模板: {}", promptTemplate);
logger.info("用户输入: {}", message);
// 检索相关文档用于日志
List<Document> relevantDocs = vectorStore.similaritySearch(searchRequest);
logger.info("检索到的文档数量: {}", relevantDocs.size());
StringBuilder contextBuilder = new StringBuilder();
for (Document doc : relevantDocs) {
// 可以添加文档相似度分数的日志
Double score = doc.getScore();
if (score instanceof Double) {
logger.info("文档相似度分数: {}", score);
if (score > 0.8) {
contextBuilder.append(doc.getContent()).append("\n\n");
}
}
}
String context = contextBuilder.toString();
logger.info("构建的上下文内容: {}", context);
// 构建最终提交给大模型的完整prompt
String finalPrompt = promptTemplate.replace("{{question_answer_context}}", context);
logger.info("最终提交给大模型的完整Prompt:\n{}", finalPrompt);
return ChatClient.builder(chatModel).build().prompt().user("用户问题: " + message + "\n" + finalPrompt).call().content();
}测试验证
不使用重排序
http://localhost:8080/milvus2/ragJsonText2?message="现在我们身边一些老年人感染后病情就很重,那是不是老年人感染后一定会走向重症和危重症?"
markdown
不是所有老年人感染后都会发展为重症或危重症,但老年人确实是高风险人群。
根据第九版诊疗指南,60岁以上的老年人被列为新冠病毒感染的高危人群,尤其是年龄越大、合并有基础疾病(如高血压、糖尿病、心衰等)的人,发展为重症的风险更高。但这并不意味着一旦感染就一定会走向重症。
关键在于**及时评估和密切观察病情变化**。老年人不必等到症状非常严重才就医,建议适当放宽住院评估标准。例如:
- 体温超过39℃持续3天;
- 活动后出现明显心慌、气促、胸闷;
- 原有基础疾病(如高血压、高血糖)控制不佳;
特别是糖尿病患者,由于高血糖环境容易导致继发感染且难以控制,感染后进展为重症的风险更高,更应加强监测。
因此,老年人感染后不必过度恐慌,但也不能掉以轻心,应密切观察身体状况,一旦出现预警信号,应及时就医,做到早干预、早治疗。使用重排序
http://localhost:8080/milvus2/ragJsonText?message="现在我们身边一些老年人感染后病情就很重,那是不是老年人感染后一定会走向重症和危重症?"
不是的,老年人感染后并不一定会走向重症或危重症。虽然老年人由于免疫力相对较弱、常伴有基础疾病(如高血压、糖尿病、心脑血管病等),确实是新冠病毒感染后发展为重症的高风险人群,但并不是所有老年感染者都会发展成重症。
通过及时接种疫苗、做好个人防护、早期监测和干预,很多老年人可以平稳度过感染期。临床数据显示,绝大多数老年感染者表现为轻症或普通型,只有少数未接种疫苗、有严重基础疾病或未能及时就医的人群才可能发展为重症或危重症。
因此,关键在于预防、早期识别症状和及时治疗。建议老年人尽早完成新冠疫苗全程接种和加强针,保持良好的生活习惯,感染后密切观察病情变化,一旦出现呼吸困难、持续高热、血氧饱和度下降等情况,应及时就医。原文中的一页
css
Q:现在我们身边一些老年人感染后病情就很重,那是不是老年人感染后一定会
走向重症和危重症?
A:文丹宁介绍,第九版指南说的高危人群,第一个就是 60 岁以上的老人。对
老人来说,年龄越大,有基础疾病的,风险就越大。但也并不是老年人一感染了,
就马上要去住院,这里需要做一个风险评估。老年人可以把评估指标放宽一点。
比如说,我们普通人说高烧 5 天才去医院,那么老年人如果体温超过了 39℃有
3 天,或者在活动之后有心慌、气促、胸闷,或者基础疾病如高血压、高血糖、
心衰等控制不好了,还是建议及时去医院。
糖尿病人因为糖尿病更容易继发感染,出现感染后特别不容易控制。人的血
糖升高,血液就像一个病原体的培养基。所以糖尿病人很容易继发感染。我们现
在碰到的重症,糖尿病人会多一点。所以,老年人或者患有糖尿病等基础疾病的
中青年感染了奥密克戎后,一定要密切观察病情变化,不能一味硬扛。比较而言,不使用的好一些。
其他
- 看了一些博客、仓库发现,在提示模板中加
"如果上下文信息不足以回答用户的问题,请直接告知用户"根据我掌握的知识,暂时无法回答这个问题",不要编造答案。"是QA这一类rag的通用的做法 - 文档内容不够丰富是回答质量差的主要原因