为什么需要非连续内存分配?
连续内存分配的缺点:内存利用率低,容易产生内碎片或外碎片。
非连续内存优点:
一个程序的物理地址空间是非连续的
更好的内存利用和管理
允许共享代码与数据(共享库等)
支持动态加载和动态链接
缺点:内存地址转换的开销
建立虚拟地址和物理地址之间的转换
软件方案和硬件方案
硬件方案:分段和分页
非连续内存分配:分段
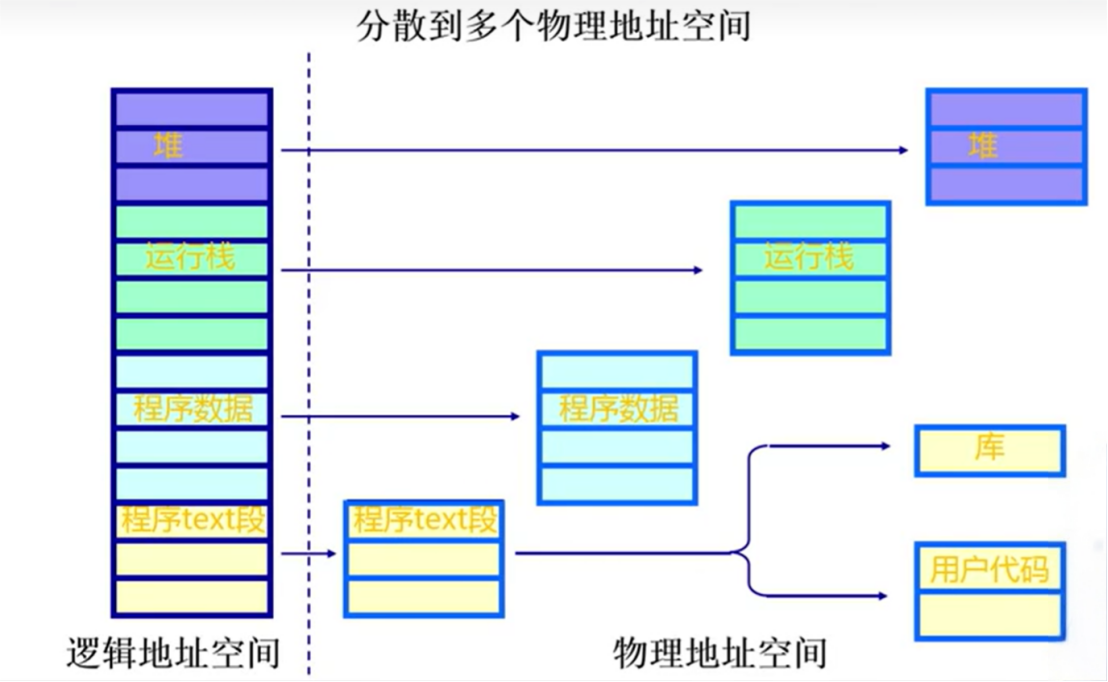
需要映射机制,把逻辑地址转换为物理地址空间
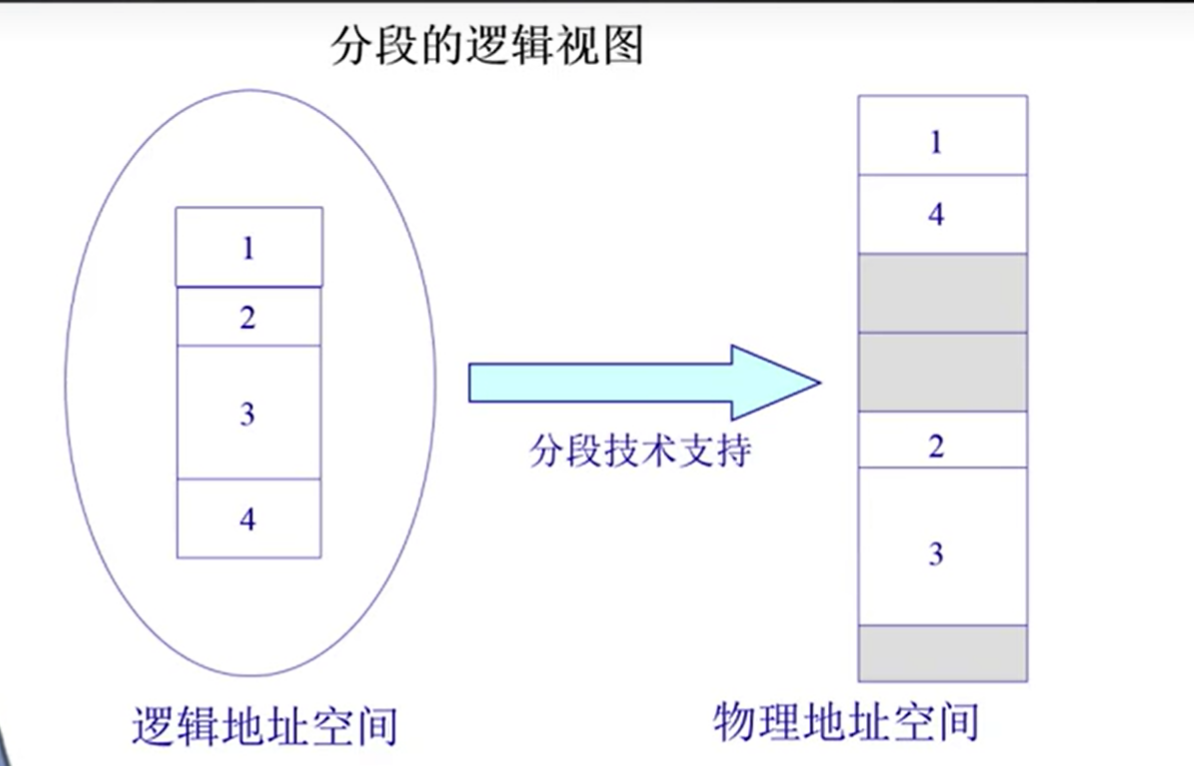
通过段映射机制,可以映射到不同的物理地址中去。
段关联机制可以实现逻辑地址到物理地址映射。
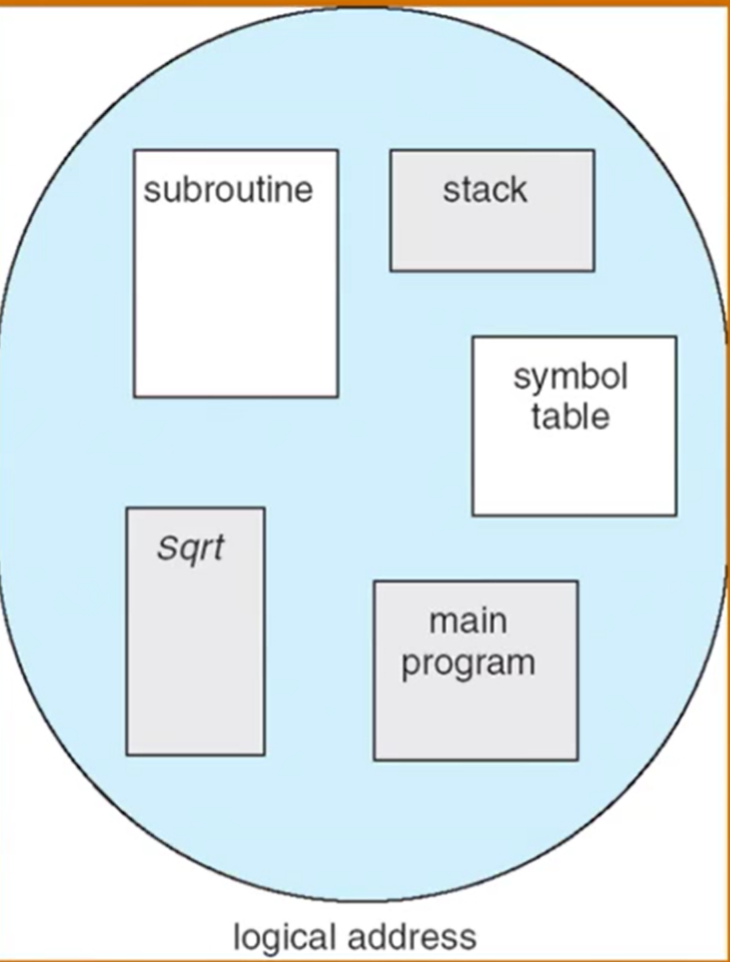
程序的分段地址空间
分段寻址方案
地址怎么来表示?
X86:段寄存器+地址寄存器
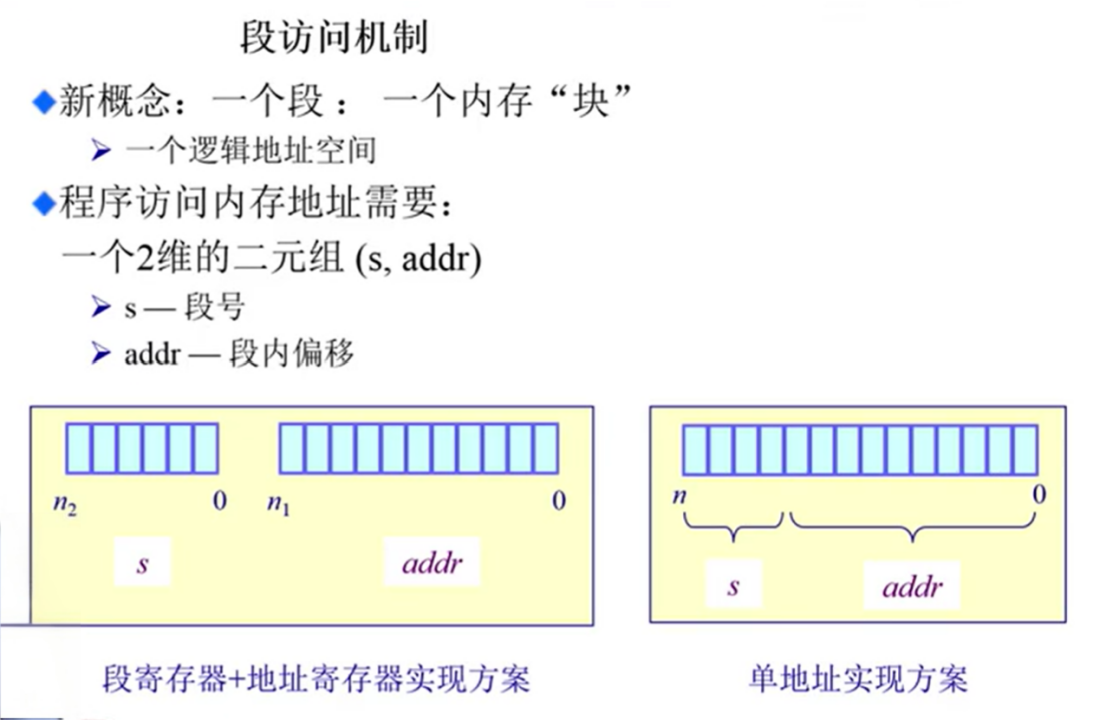
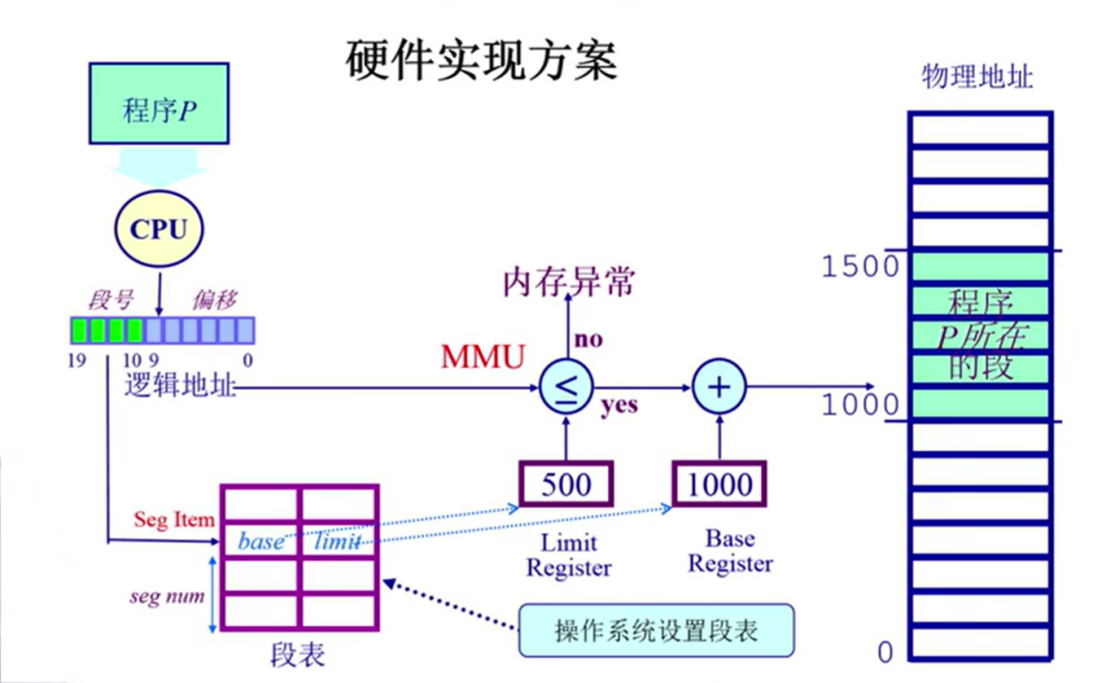
段表:逻辑地址和物理地址之间的映射关系
seg num 作为段表的index :段的起始地址和段的长度限制。
操作系统在正式寻址之前,操作系统需要先建立好段表。
非连续内存分配:分页
名词区分:
帧(frame):表示物理页
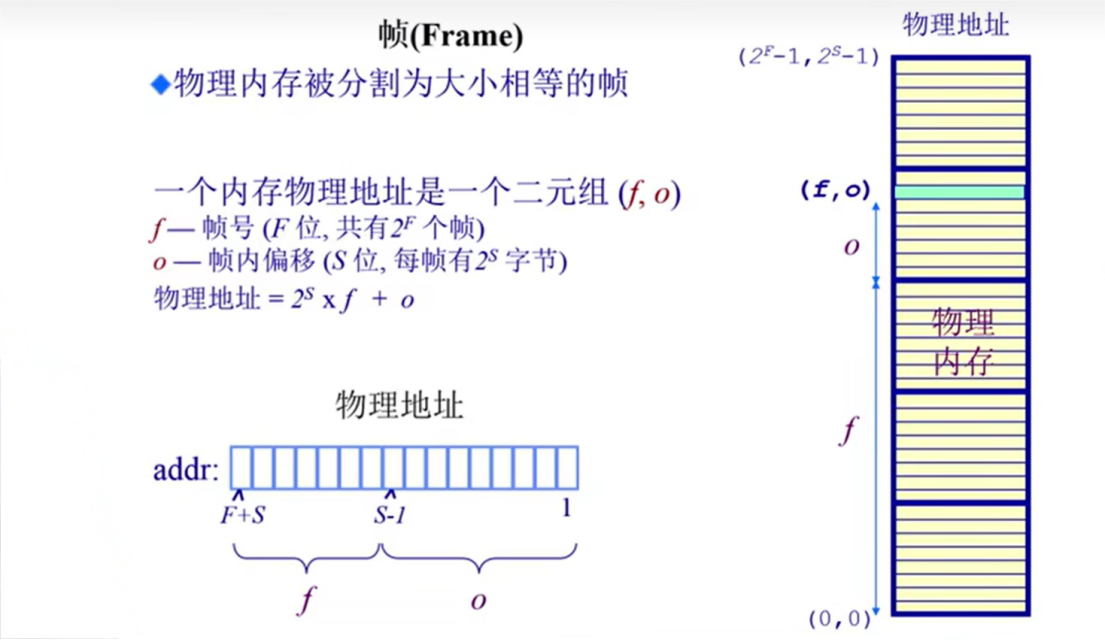
页(page):表示逻辑页

分页地址空间
划分物理内存至固定大小的帧:大小为2的幂次,e.g. 512 4096 8192
划分逻辑地址空间至相同大小的页:大小为2的幂次,e.g. 512 4096 8192
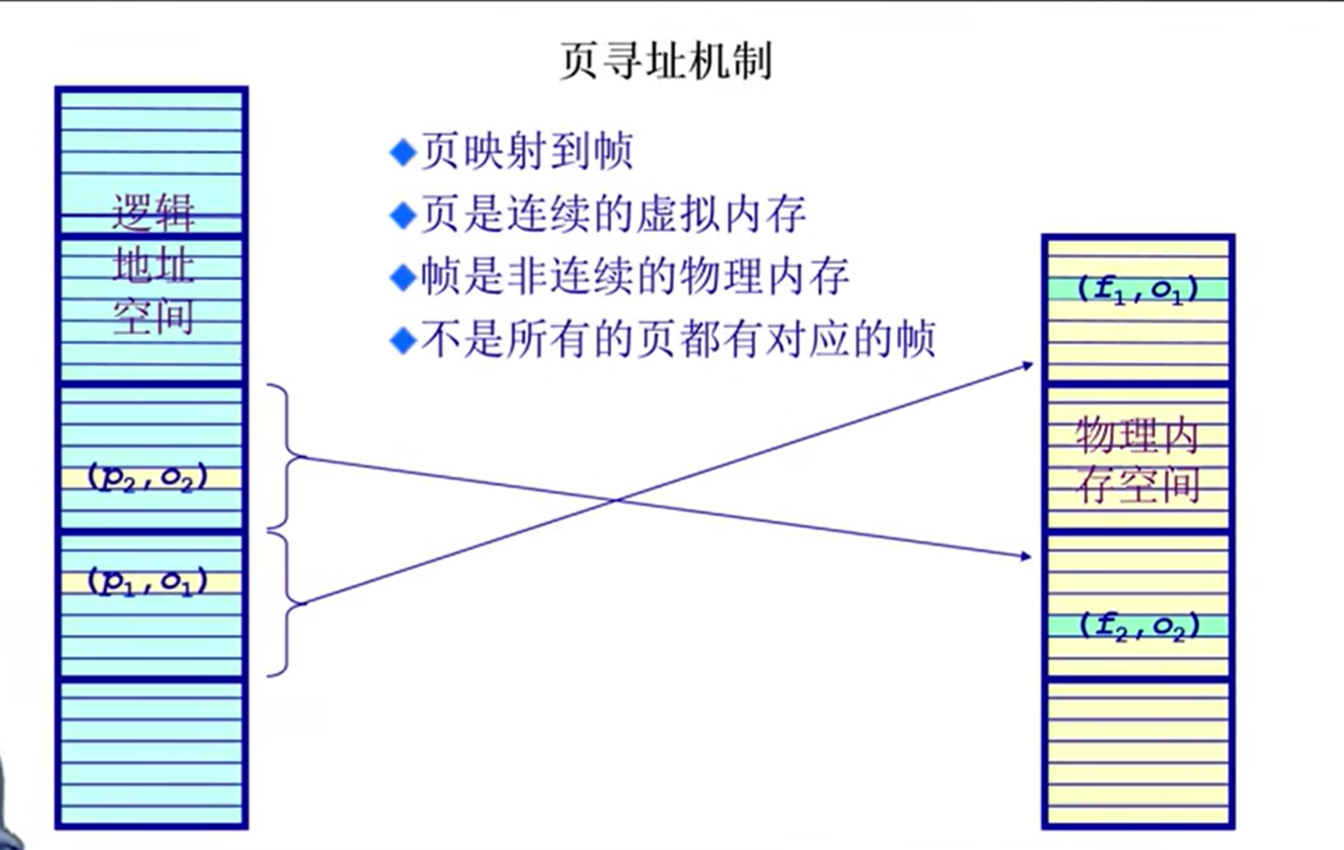
建立方案:转换逻辑地址为物理地址(pages to frames)
- 页表
- MMU、TLB
页寻址方案
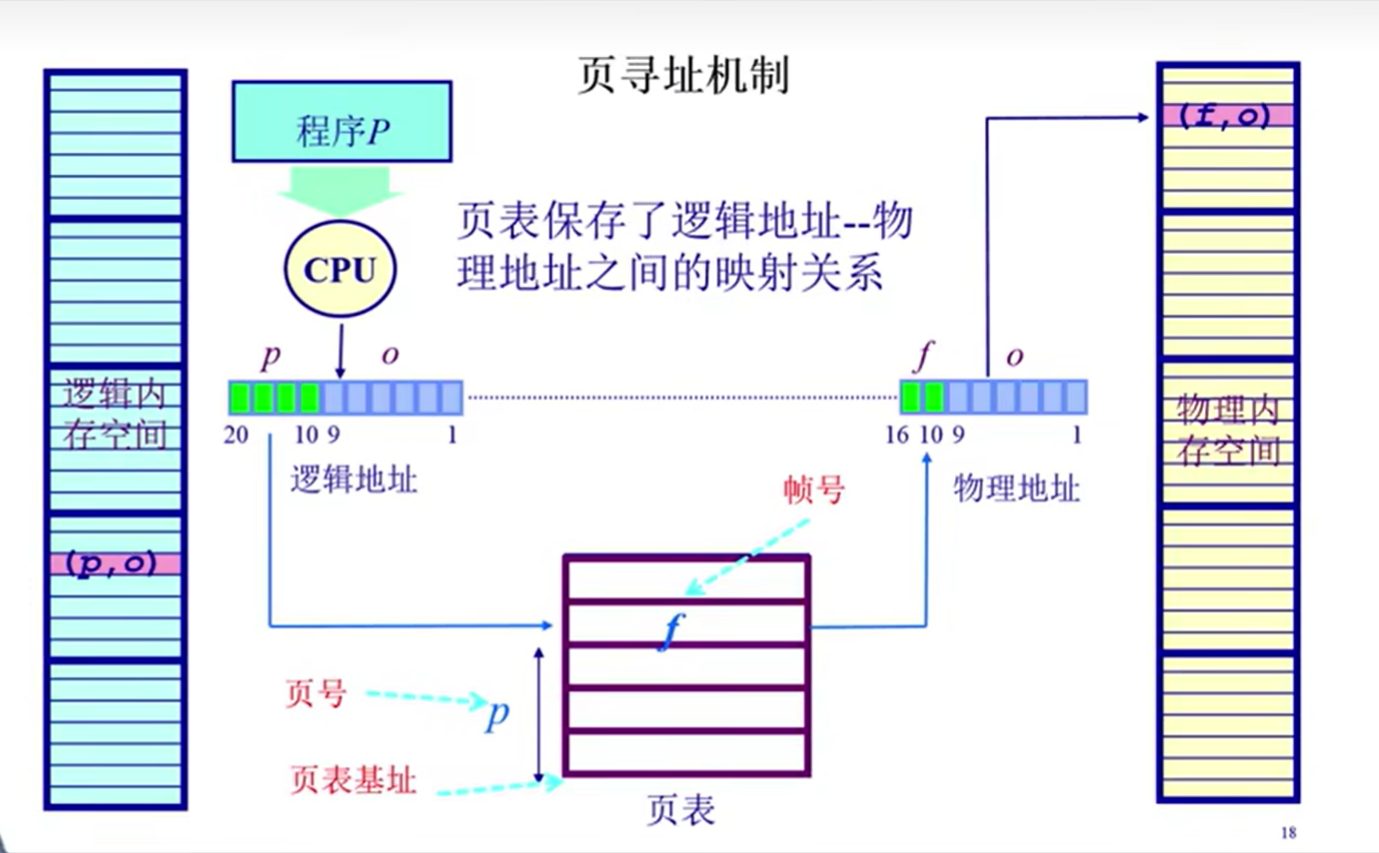
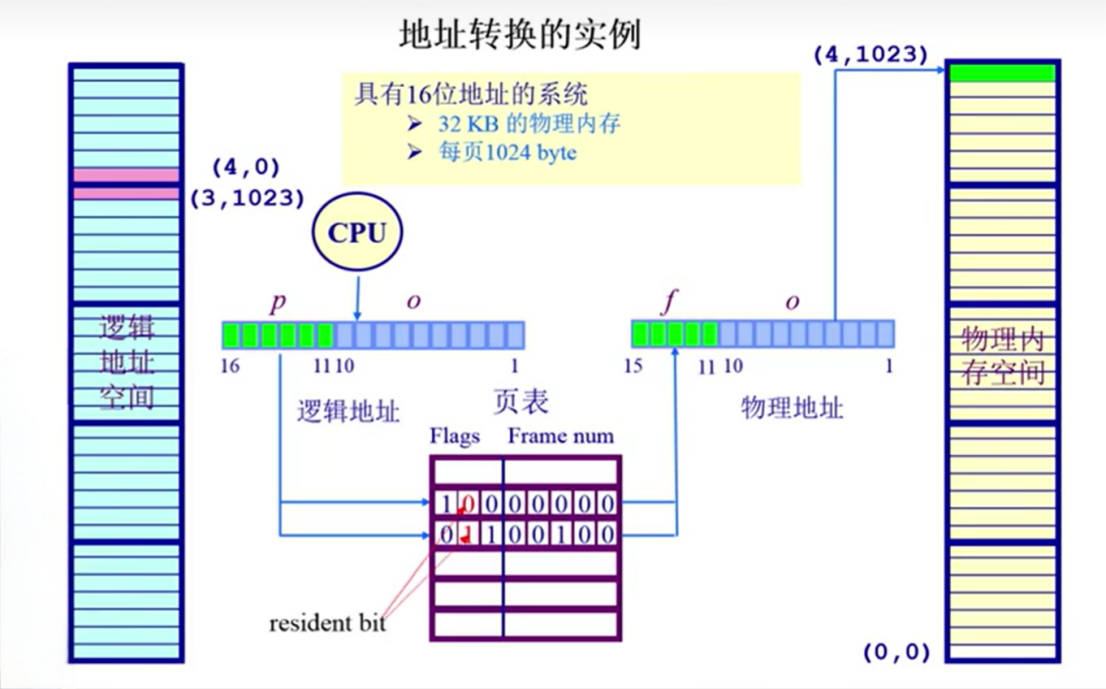
通过操作系统建立起页表,以此来建立起逻辑地址和物理地址的映射,而其建立的时机是在初始化时就需要先将页表初始化。
页内偏移大小是一致的,与段中不同段的偏移量大小是不一致的是不同的。
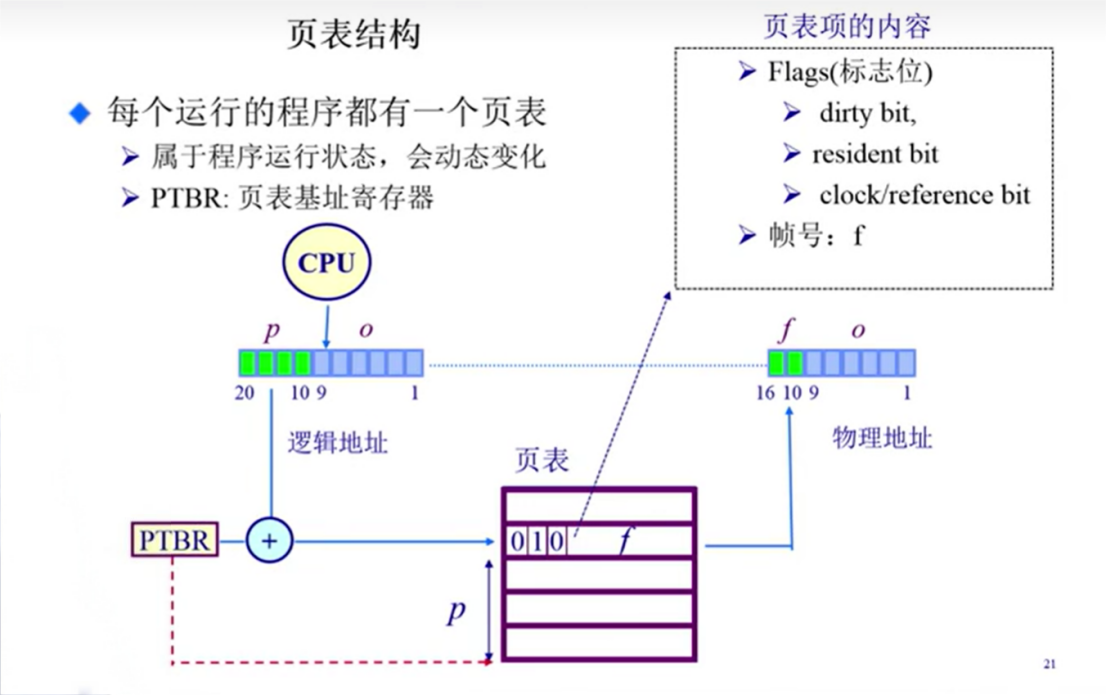
页表
页表概述
页表本质上是一个大数组,索引对应页号(page number)内容对应帧号(frame number);
那么就会出现这么一个问题?
分页机制的性能问题
问题:访问一个内存单元需要2次内存访问
- 一次用于获取页表项
- 一次用于访问数据
页表可能非常大
- 64位机器如果每页1024字节,那么一个页表的大小会是多少?

如何处理?
- 缓存(时间)
- 间接访问
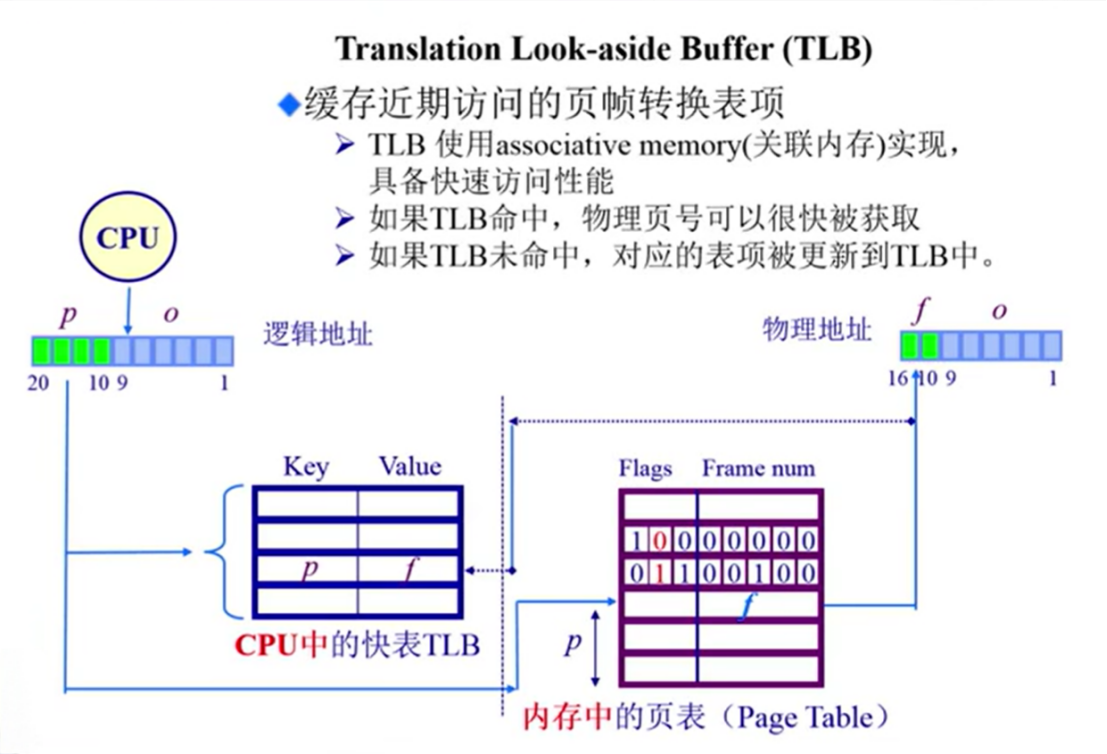
转译后备缓冲区(TLB)
时间上解决(缓存机制):
把经常使用的地址映射直接放入到TLB中。
TLB(Translation Look-side Buffer)
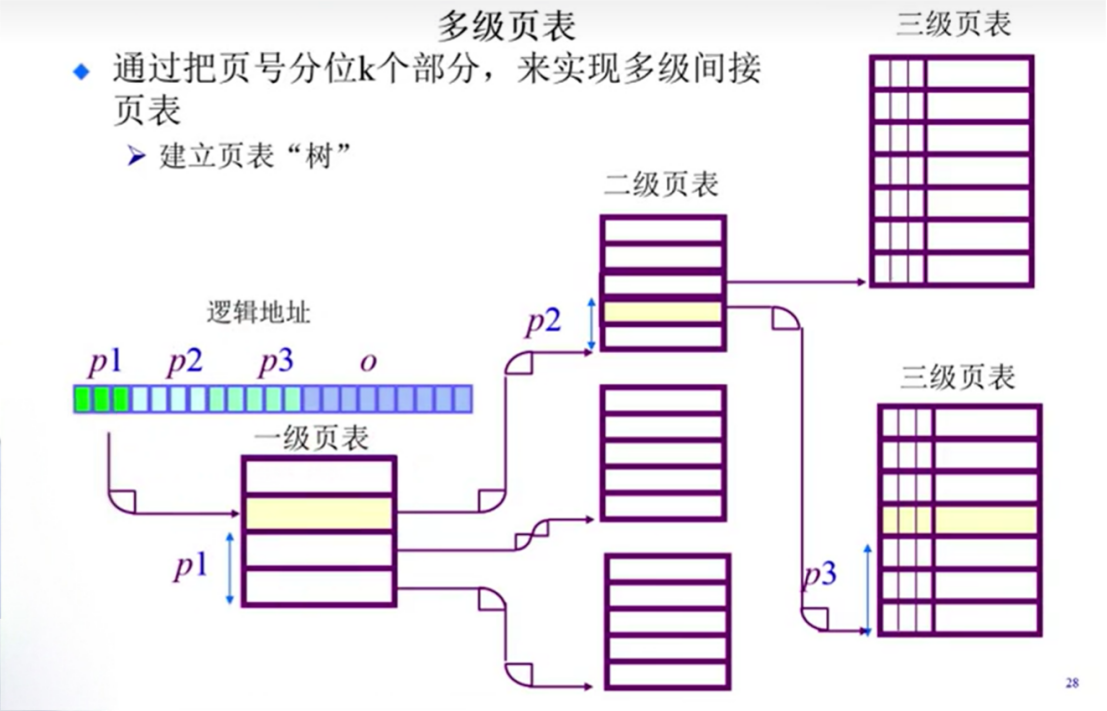
二级、多级 页表
空间太大,如何将页表的存储变得小一些。
采用将页表分级的方式,也就是逻辑地址对应的页表起始地址按位做分级。
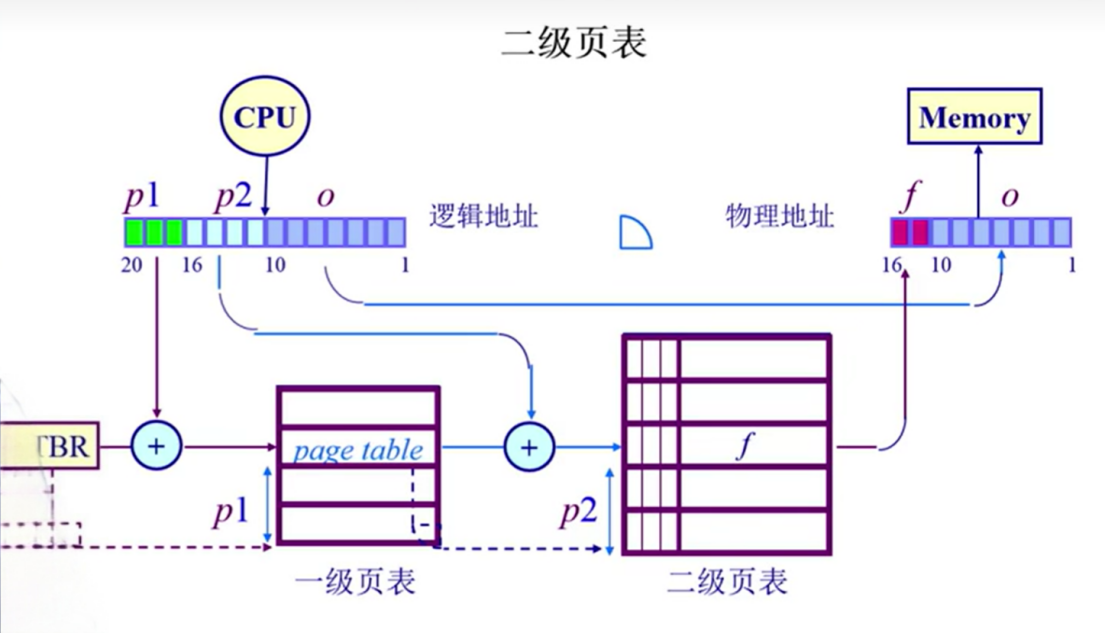
那么可以接着推广:推广为多级页表,也就形成了一颗树。
反向页表
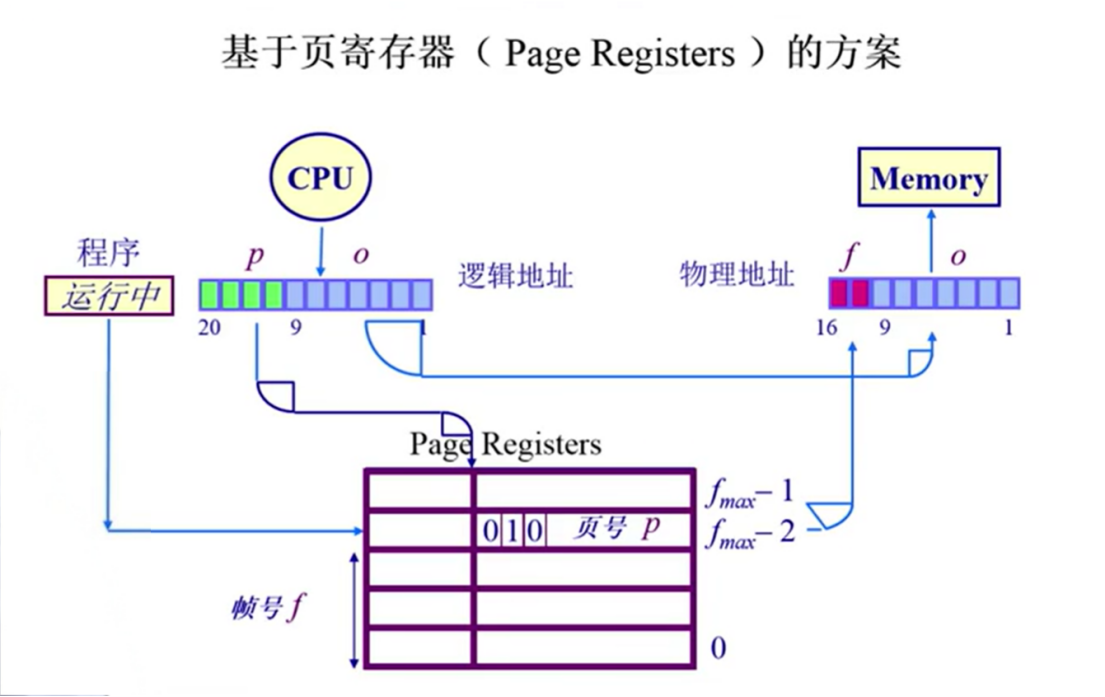

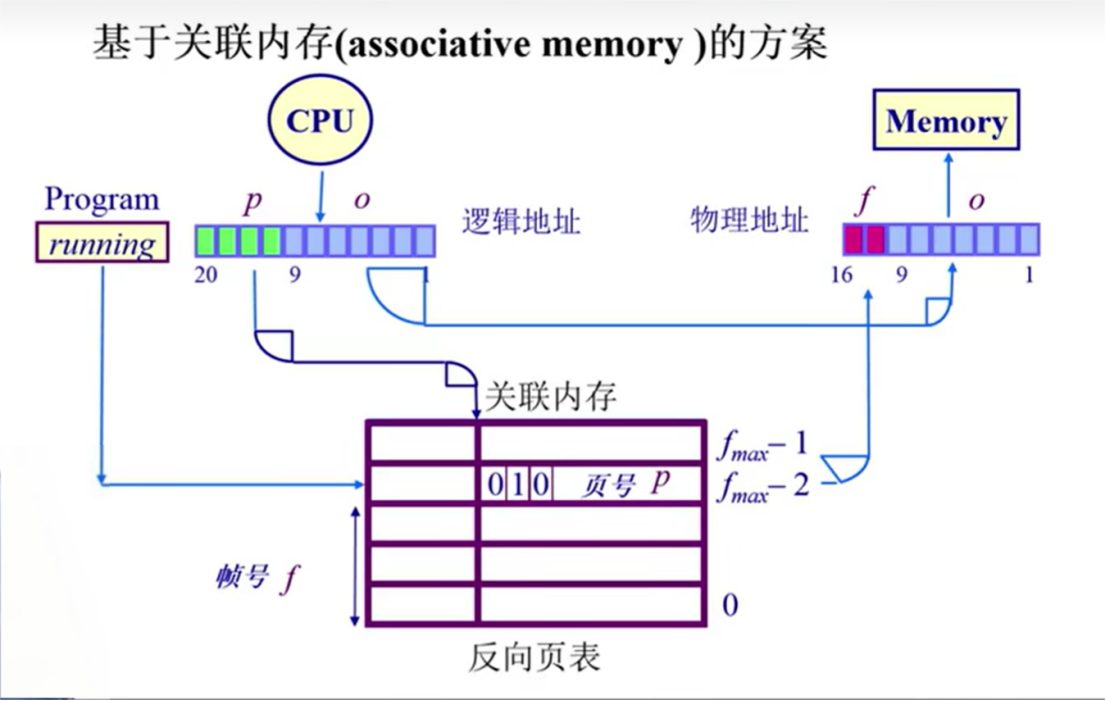

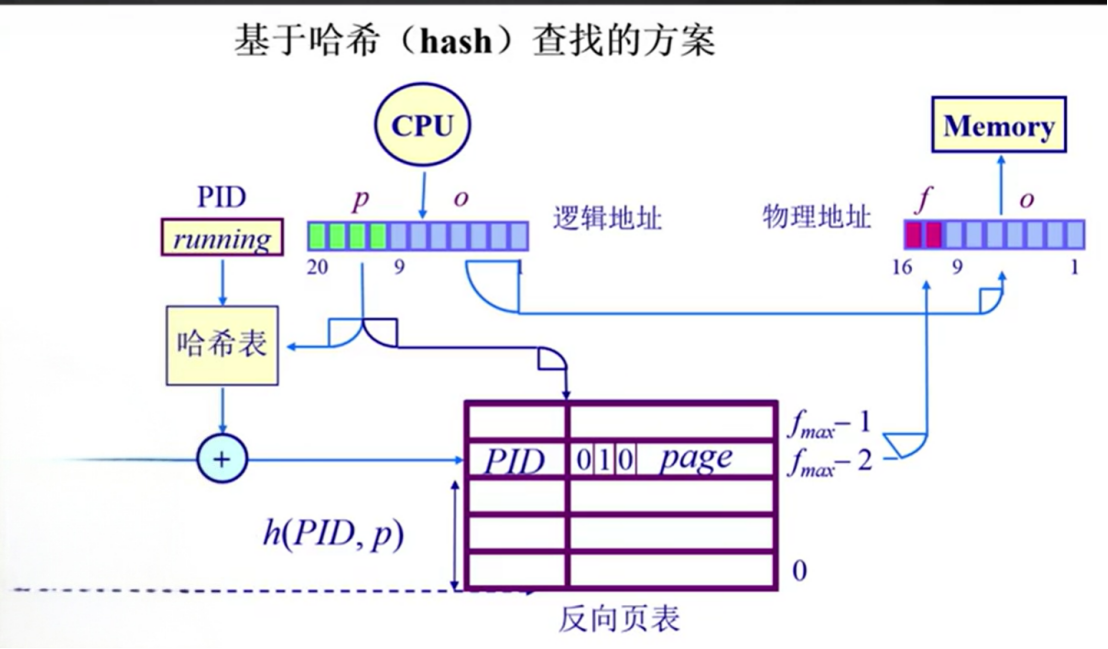
为什么在hash转换的时候需要加PID,就是为了减少hash碰撞带来的影响。

总结
非连续内存分配的策略:分段和分页。