引言
最近一段时间,回收团队一直坚持用Cursor来辅助开发,并在AI开发模式上进行了多次迭代。今天,我想和大家分享一些我们在AI编程方面的实践心得。
首先要明确的是,AI编程并不能取代程序员的独立编码能力,也不是说简单配置几个MCP就能让AI的编程能力发生质的飞跃。今天我将重点从实际应用出发,分享一些AI编程的思路与流程优化经验,帮助各位真正的在项目开发中,把AI用起来。
我们到底能用Cursor干什么
我一直在思考,作为一个月使用成本超过100块的"权威"工具来说,如果只让他做一些bean的生成,mapper的生成,未免太过于浪费。但是如果直接把需求文档喂给他,生成的代码距离我们的期望又太大。我们总说,想让AI生成符合要求的代码,需要详细的将我们的需求写成提示词告诉AI,但是到底如何才算详细呢?如何才能写出这份详细的提示词呢?
下面是我使用Cursor进行项目开发的三步走:
- 由Cursor帮助开发者拆分项目------初步完成提示词框架
- 由开发者帮助Cursor理解项目------丰富提示词内容
- 完成开发后由Cursor帮助开发者进行回归验证
一、让cursor帮助你更好的拆分项目
既然直接生成代码难度太大,我们能不能先尝试让AI做一些更简单的事情,比如分析一下需求文档。
一般来讲,对于一个项目的分析主要分两步:
- 对于项目新流程的分析
- 对于相关现状的分析
上述步骤步完成后我们期望Cursor能够基于需求PRD文档,帮我们总结一份兼容当下系统逻辑的初步的功能分析文档(不需要功能的具体实现方案,只需要确定有哪些功能即可),包括一些实体类、VO对象的定义,接口定义,数据库表定义等等。
1、针对新流程(PRD文档)的分析
Cursor可以很好的分析并总结PRD文档的内容,但产品给出的PRD文档中不可避免的会对一些"众所周知"的上下文进行省略,Cursor也因此无法得知项目的全貌,单纯把PRD文档喂给Cursor并不能让他直接生成符合我们期望的代码。
但这不代表我们在这一阶段完全无法让Cursor为我们创造价值。我们可以利用Cursor的分析总结能力,梳理PRD文档中的功能点与要点,加速自己理解项目,并结合自己对prd的理解进行双向验证。避免后期开发时出现与产品理解不符或者遗漏功能点。
使用Cursor读取并分析本次需求PRD文档的内容时,为了不被上下文长度所限制,我们需要让Cursor将他的思考结果进行记录。例如下面的提示词:
ini
https://dashen.zhuanspirit.com/pages/viewpage.action?pageId=xxxxxxxx
提取一下上面链接的文档中的内容。帮我提炼【XXXXX账单】部分相关功能,有哪些需要开发的功能点,注意,我们本次仅需要查询XXXX列表以及查询XXXX流水详情,其余相关功能和组件已经实现完成。
分析你需要拆分出多少个功能点以及接口
在我让你写代码之前不要生成代码,先逐步分析需求,再说明你打算怎么做
将你的思考以md的形式保存在.docs/技术设计.md下也许你的在线PRD文档需要登陆才可查看,这里给出两个解决方案:
- 找到你的本地cookie,让Cursor带着cookie对你的在线文档进行访问
- 使用mcp,具体方法这里不进行展开
然后,反复与AI进行沟通,明确告诉他我们需要什么,不需要什么,例如下面的提示词。
我们不做数据同步与保存相关的工作,从设计方案中剔除,所有的数据已经准备就绪,我们只需要查询就可以了
帮我设计这个接口的查询的参数与返回值下面是基于Cursor进行PRD文档分析的基本流程:
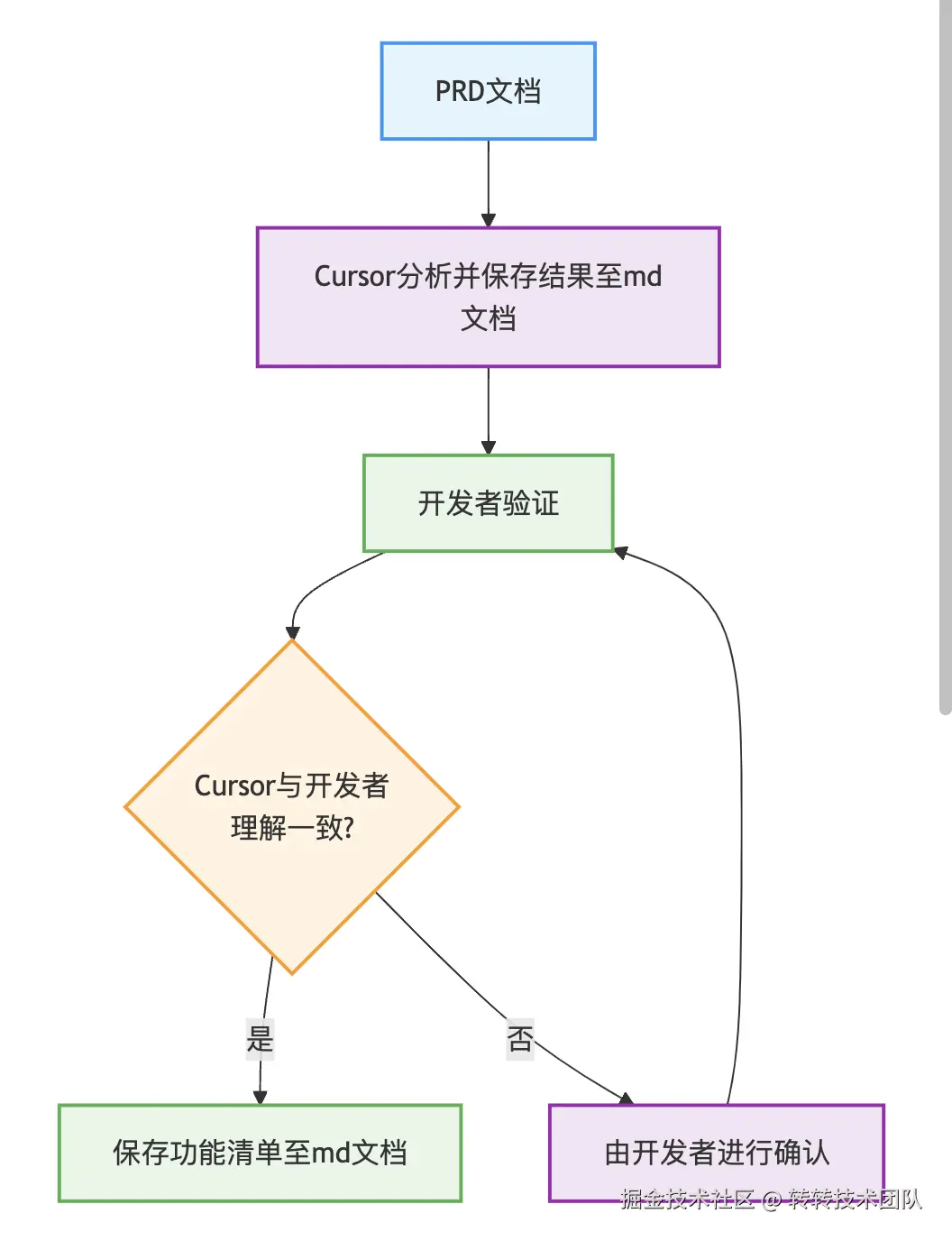
首先明确一点:不要试图让Cursor来教我们如何做项目,而是让它协助完成每个环节。所以如果觉得自己可以更快更准确的修改文档的某一部分,主动去修改,不要让AI来做。比如,AI帮忙设计了一个实体对象,但是其中部分字段命名不符合我们的业务要求,我们就不要让AI来修改了,直接动手修改md文档。
另外,如果你亲自改动的内容很多,建议下次跟Cursor沟通的时候新开启一个对话框,重新让他读取PRD文档及对应的分析文档,否则Cursor会保留之前生成的记忆,导致你的改动可能不会生效。
下面是此阶段生成的功能分析文档的部分展示:


2、对于目前已有代码的分析,以及影响范围分析
相比于开发者来说,Cursor会更贴近代码。我们可以在Cursor的协助下更好的完成现有业务流程的梳理。 更具体的讲,我们可以从需求的目标改动点开始,梳理其所属功能和实现方式,包含数据管理、交互流程等等。 这里介绍一下我们常用的Cursor插件: Mermaid Preview插件,与Markdown Preview Enhanced插件。
流程图生成插件


安装完插件并重启cursor后我们便可以通过如下提示词进行流程图生成了。
arduino
com.xxx.xxx.xxx.xxx.facade.SxxxxxxxxFacade#getxxxxxx
针对该方法帮我生成一个.md的业务流程图对于复杂的系统流程来说,我们可以基于此种方法生成流程图,辅助确定本次改动的代码的影响范围。
二、帮助Cursor更好的理解项目,并生成代码
我们总是希望有一个工具来帮助我们挖掘AI的潜力,让他更好的明白我们的系统,了解我们的业务,例如各种知识库,各种Rule。即使AI的思维能力可以与真人媲美,我们也很难想象让你身边的某一位经验丰富的同事仅依靠产品文档就可以准确的完成项目开发。项目过程中必然会经历多次沟通,多次方案修正,最终多方达成一致,再进入开发阶断。 同样,在正式进行开发前,我们也需要有一份技术文档来指导Cursor进行开发。不同于前面需求文档的简单分析,这一部分的分析需要对每一个功能有详细的描述。我们可以基于之前落地md文档继续进行完善。这一阶段的主要目标是为Cursor补充上下文细节并核验Cursor结论的过程。我们需要针对每一个功能点:
- 调整AI的命名方式与代码生成位置(可以使用Rule进行简化)。
- 调整AI使用的工具类与服务类。
- 调整AI的逻辑细节(例如调整校验规则,判断顺序等)。
- 调整AI的业务细节(优先从PRD文档上节选原文,尝试让Cursor理解。如果PRD文档没有写清业务流程,就自己动手描述流程或者干脆直接让Cursor跳过生成并预留方法,方便后面自己动手补充逻辑)。
最终我们得到了这样一份详细描述了业务功能的md文档: 
如此一来,得到的这份文档实际上是我们与Cursor都能理解,并且达成一致的。我们终于得到了那份可以供我们用作"生成提示词"的功能分析文档,基于这份文档后续Cursor生成的代码也都基本可以满足要求。
下图为使用Cursor生成代码的整体逻辑流程: 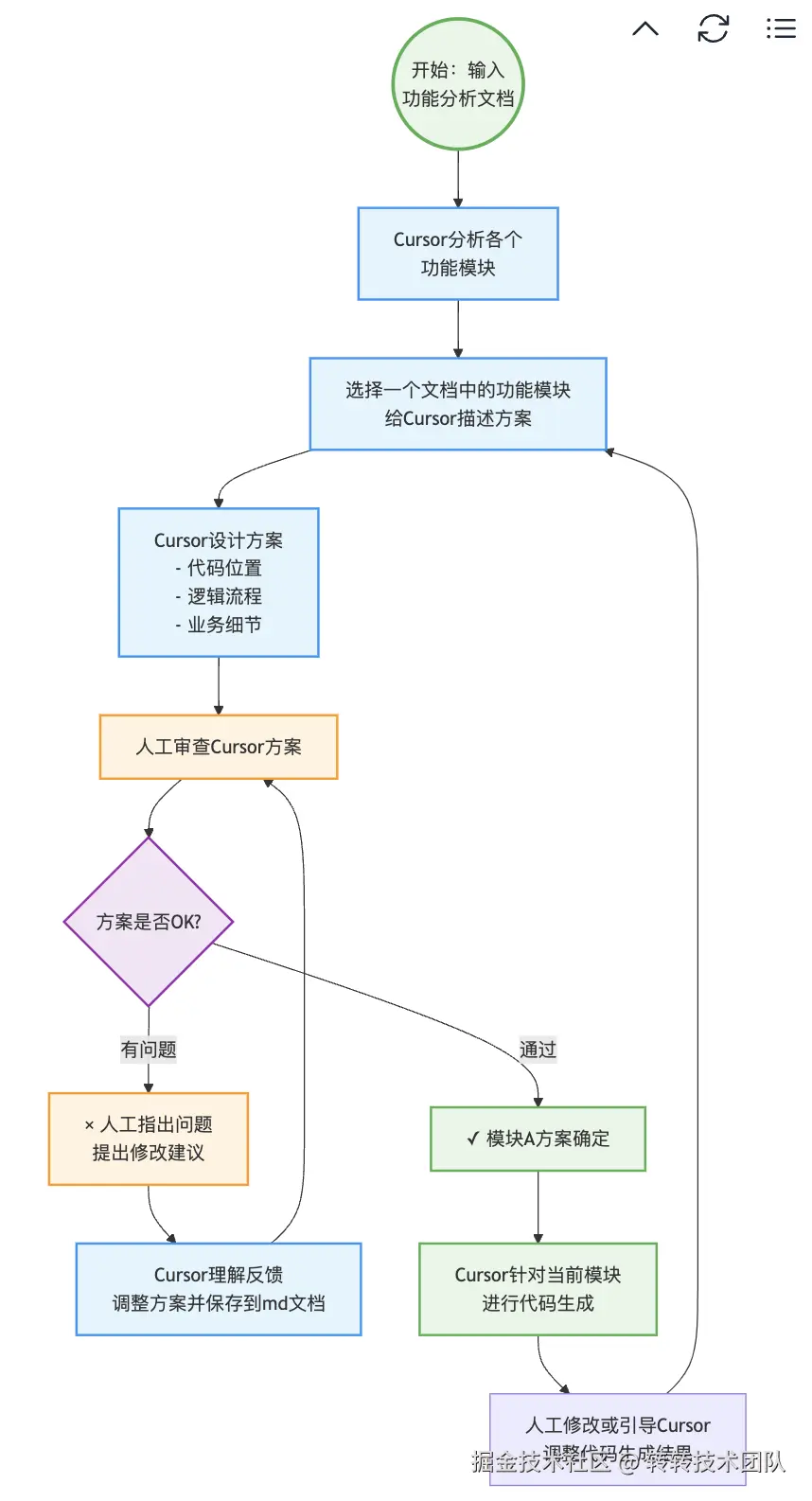
需要注意的是,我们每次只就一个功能点进行分析,并且一旦你觉得这个功能点已经相对完善,尽快落地成代码,不要留在一起,让AI最后一起生成。 一方面AI在处理过多的内容时会不可避免的产生偏差,另一方面,如果项目过大,我们也容易忘记一些细节,导致花费额外的时间来进行回忆与验证。
三、Cursor帮助开发者进行回归验证
除去开发阶段的辅助作用,Cursor另一大作用体现在开发后的辅助质量保证上。通常体现在以下两个方面:
- 改动影响评估
- 功能验证
为了实现上述能力,我们按照三步走的方式来进行
1、改动范围整理
使用下面的命令逐个文件分析当前分支改动点并输出到cr.diff 文件中,随后在md文件末尾进行总结:git diff origin/master > cr.diff
2、基本代码审查
我们可以使用下面的提示词引导Cursor进行基本代码审查:
markdown
扫描diff 文件中的差异代码。reviwe 的规则如下
1. 方法体行数应少于100行, 不包括空行,和注释
2. 枚举定义需要有两个以上属性, code, name, 并且需要有通过code获取枚举项的方法
3. 接口返回false , 前端是否有对false进行处理
4. throw 了异常的位置, 一定要打log日志
5. 所有的public 公有方法都要打印入参log.info日志
6. 所有的public 公有方法, 结束都要打印结束日志
7. 所有调用rpc的方法, 都要打印日志
8. 所有方法都要有方法级别的注释
9. try catch异常后, 如果在catch 中又抛出了新创建的异常时, 需要将原异常赋值给新异常
10. 不能调用被标记@Deprecated 的属性或方法或类
11. 定义的常量值, 给出清晰的注释说明用途, 避免硬编码
12. 标注了@transactional的方法要明确回滚异常类型, 对于只读操作要标注只读readOnly=true 提高性能
13. 3次以上字符串拼接使用StringBuilder代替字符串拼接
14. 检查是否存在其他破坏兼容性的改动或逻辑上的错误
15. 检查是否存在循环调用导致的逻辑问题
16、新增的页面提交和支付相关流程要考虑幂等处理
17、接口可能被重复调用和mq消息重复接收场景要考虑并发和事务冲突和数据覆盖,要善用分布式锁
18、针对数据库单一字段的修改,尽可能要精确修改,使用整体对象进行修改
19、是否存在重复代码
20、修改逻辑是否设计到计数系统口径的修改
21、数据交互过程中(数据库和外部调用)的空指针判断和处理
22、状态流转过程和涉及资产损失的部分要对前置状态进行校验
23、涉及数据库和外部事务的接口,要保证整体事务的一致性,无法保证的要有补偿机制
24、涉及异步回调的场景,要考虑中间态的处理
25、不允许把配置规则交给运营同学
26、返回的list类型,要给定默认值,不能给null
27、主键必须设置自增或者使用分布式id
28、数据库表是否建立了索引
29、异常场景要打印报警,尽可能优先多打印
遍历所有规则, 一个规则一个规则的去检查增量代码的规范性, 每个规则进行Review时, 使用独立的上下文, 最后归纳所有的Review结果.
输出违反规则的文件位置, 在我说可以修改之前不要修改文件3、功能辅助验证
在完成代码生成与初步审查后,我们进入功能验证阶段。此时可利用Cursor分析代码变更,自动生成自测用例清单。通过提示词引导Cursor结合业务逻辑、接口输入输出及异常分支,输出覆盖核心路径、边界条件和错误处理的测试场景。
例如:
基于当前代码变更,列出需要自测的功能点和边界情况,包括正常流程、异常输入、状态校验等,输出为表格形式,包含用例编号、场景描述、预期结果。该过程不仅是测试准备,更是对整体逻辑的再确认。通过Cursor辅助验证,提升自测完整性,减少后期回归成本,确保交付质量。
小结
至此,本文分享了回收团队在AI编程实践中的经验,重点介绍了如何高效使用Cursor辅助开发。通过分阶段协作------从需求分析,现状梳理到技术设计,代码生成,再到测试验证。
AI时代,开发者的核心竞争力正从"掌握知识"转向"提出问题"。工具如Cursor并非替代开发人员,而是通过人机协同,提升需求理解、技术设计与代码质量的效率。我们要以专业积累构建清晰上下文,引导AI完成拆解、分析、生成与验证,最终实现高效、高质量的开发闭环。
关于作者,黄敬乾,侠客汇Java开发工程师。
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。 关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~